
LlamaIndex
LlamaIndex框架的一些使用
[官方文档]:LlamaIndex 🦙 v0.10.17
- 新版本大部分
llama_index都变成了llama_index.core
Document格式
documents = SimpleDirectoryReader("/home/wjm/projects/RAG/test_data").load_data()
[Document(id_='', embedding, metadata, excluded_embed_metadata_keys, excluded_llm_metadata_keys, relationships, text='txt文件内容', start_char_idx, end_char_idx, text_template='{metadata_str}\n\n{content}', metadata_template='{key}: {value}', metadata_seperator='\n'), Document(id...][Document(id_='4357a4df-eb75-435f-a63a-6e9bb0c9efba', embedding=None, metadata={'file_path': '/home/wjm/projects/RAG/test_data/变电工程电气分册.txt', 'file_name': '/home/wjm/projects/RAG/test_data/变电工程电气分册.txt', 'file_type': 'text/plain', 'file_size': 34775, 'creation_date': '2024-03-07', 'last_modified_date': '2024-03-07'}, excluded_embed_metadata_keys=['file_name', 'file_type', 'file_size', 'creation_date', 'last_modified_date', 'last_accessed_date'], excluded_llm_metadata_keys=['file_name', 'file_type', 'file_size', 'creation_date', 'last_modified_date', 'last_accessed_date'], relationships={}, text='国家电网有限公司输变电工程标准工艺\n变电工程电气分册\n国家电网有限公司基建部 组编\n正文设计:张俊霞\n项目号:XM88543 编辑:翟巧珍\n成品:210*297 版心:245mm*166mm\n字数:44字*44行 正文字号:5号\n天:27 地:25 订:24 切:20\n图数:调图 35 改图 29 画图 153 灰修 5 纯灰 331\n四色\n中国电力出版社\n为更好地适应输变电工程高质量建设及绿色建造要求,国家电网有限公司组织相关单位对\n原标准工艺体系进行了全面修编。将原《国家电网公司输变电工程标准工艺》(一)~(六)系\n列成果,按照变电工程、架空线路工程、电缆工程等专业进行系统优化、整合,单独成册。\n本书为《国家电网有限公司输变电工程标准工艺 变电工程电气分册》,包括主变压器系\n统设备安装、站用变压器及交流系统设备安装、配电装置安装、全站防雷及接地装置安装、主\n控及直流设备安装、全站电缆施工、通信系统设备安装、视频监控及火灾报警系统、智能变电\n站设备安装、换流设备安装10章62节。每节基本包括工艺流程、工艺标准、工艺示范、设计\n图例四部分内容,还有的节设置了工艺视频内容,扫码即可观看。\n本书适用于从事电力输变电工程施工、安装、验收、监理等的工人、技术人员和管理人员\n使用,也可供相关专业人员参考。\n图书在版编目(CIP)数据\n国家电网有限公司输变电工程标准工艺. 变电工程电气分册/国家电网有限公司基建部组编.—北京:中国电力出版社,\n2022.3\nISBN 978-7-5198-6334-0\nⅠ. ①国… Ⅱ. ①国… Ⅲ. ①电力工业−工业企业−变电所−电工技术 Ⅳ. ①TM7②TM63\n中国版本图书馆CIP数据核字(2021)第272999号\n出版发行:中国电力出版社\n地 址:北京市东城区北京站西街19号(邮政编码100005)\n网 址:http://www.cepp.sgcc.com.cn\n责任编辑:翟巧珍([email protected])\n责任校对:黄 蓓 李 楠\n装帧设计:张俊霞\n责任印制:石 雷\n印 刷:三河市万龙印装有限公司\n版 次:2022年3月第一版 2017年3月第三版\n印 次:2022年3月北京第一次印刷\n开 本:880毫米×1230毫米 16开本\n印 张:11\n字 数:337千字\n印 数:0001—5000册\n定 价:79.00元\n版 权 专 有 侵 权 必 究\n本书如有印装质量问题,我社营销中心负责退换\n《国家电网有限公司输变电工程标准工艺》\n......\n1. 工艺流程\n1.1 工艺流程图\n中性点系统设备安装工艺流程图见图1 − 2 − 1。\n8\n1.2 关键工序控制\n中性点系统设备安装:\n(1)设备吊装时应采取防倾倒措施,不得将吊绳捆绑在绝缘子上进行\n起吊,防止损坏设备。\n(2)放电间隙距离符合《交流电气装置的过电压保护和绝缘配合》\n(DL/T 620—1997)的要求。\n2. 工艺标准\n(1)中性点隔离开关安装工艺标准参见第3章第七节,中性点设备引\n下接地部位应采用两根接地体分别与主接地网的不同干线相连,截面\n满足设计要求。\n(2)中性点避雷器安装工艺标准参见第3章第九节。 图1 − 2 − 1 中性点系统设备\n(3)放电间隙横平竖直,固定牢固,并确保中心对准一致,接地应采 安装工艺流程图\n用两根接地引下线与接地网不同接地干线相连。\n3. 工艺示范\n中性点系统设备安装及接地安装分别见图1 − 2 − 2和图1 − 2 − 3。\n图1 − 2 − 2 中性点系统设备安装\n图1 − 2 − 3 中性点系统设备接地安装\n9', start_char_idx=None, end_char_idx=None, text_template='{metadata_str}\n\n{content}', metadata_template='{key}: {value}', metadata_seperator='\n')]SimpleDirectoryReader
from llama_index.core import SimpleDirectoryReader
documents = SimpleDirectoryReader("./data").load_data()LlamaHub
LlamaHub - LlamaIndex 🦙 v0.10.17
也可以直接用
from llama_index.core import Document
doc = Document(text="text")自定义prompt
访问/自定义高级模块中的提示 - LlamaIndex 🦙 v0.10.17
from llama_index.core import PromptTemplate
# reset
query_engine = index.as_query_engine(response_mode="tree_summarize")
# shakespeare!
new_summary_tmpl_str = (
"Context information is below.\n"
"---------------------\n"
"{context_str}\n"
"---------------------\n"
"Given the context information and not prior knowledge, "
"answer the query in the style of a Shakespeare play.\n"
"Query: {query_str}\n"
"Answer: "
)
new_summary_tmpl = PromptTemplate(new_summary_tmpl_str)
query_engine.update_prompts(
{"response_synthesizer:summary_template": new_summary_tmpl}
)# NOTE: here notice we use `my_context` and `my_query` as template variables
qa_prompt_tmpl_str = """\
Context information is below.
---------------------
{my_context}
---------------------
Given the context information and not prior knowledge, answer the query.
Query: {my_query}
Answer: \
"""
template_var_mappings = {"context_str": "my_context", "query_str": "my_query"}
prompt_tmpl = PromptTemplate(
qa_prompt_tmpl_str, template_var_mappings=template_var_mappings
)Context information is below.
---------------------
test_context
---------------------
Given the context information and not prior knowledge, answer the query asking about citations over different topics.
Please provide your answer in the form of a structured JSON format containing a list of authors as the citations. Some examples are given below.
Query: Which citation discusses the impact of safety RLHF measured by reward model score distributions?
Response: {'citations': [{'author': 'Llama 2: Open Foundation and Fine-Tuned Chat Models', 'year': 24, 'desc': 'Impact of safety RLHF measured by reward model score distributions. Left: safety reward model scores of generations on the Meta Safety test set. The clustering of samples in the top left corner suggests the improvements of model safety. Right: helpfulness reward model scores of generations on the Meta Helpfulness test set.'}]}
Query: Which citations are mentioned in the section on RLHF Results?
Response: {'citations': [{'author': 'Gilardi et al.', 'year': 2023, 'desc': ''}, {'author': 'Huang et al.', 'year': 2023, 'desc': ''}]}
Query: Which citations are mentioned in the section on Safety RLHF?
Answer:BM25
from llama_index.retrievers.bm25 import BM25Retriever
from llama_index.core.tools import RetrieverTool
vector_retriever = VectorIndexRetriever(index)
bm25_retriever = BM25Retriever.from_defaults(nodes=nodes, similarity_top_k=2)
retriever_tools = [
RetrieverTool.from_defaults(
retriever=vector_retriever,
description="Useful in most cases",
),
RetrieverTool.from_defaults(
retriever=bm25_retriever,
description="Useful if searching about specific information",
),
]
from llama_index.core.retrievers import RouterRetriever
retriever = RouterRetriever.from_defaults(
retriever_tools=retriever_tools,
llm=llm,
select_multi=True,
)
# will retrieve all context from the author's life
nodes = retriever.retrieve(
"Can you give me all the context regarding the author's life?"
)
for node in nodes:
display_source_node(node)混合检索+重排
BM25 猎犬 - LlamaIndex 🦙 v0.10.18.post1
设置数据
!curl https://www.ipcc.ch/report/ar6/wg2/downloads/report/IPCC_AR6_WGII_Chapter03.pdf --output IPCC_AR6_WGII_Chapter03.pdf
# !pip install pypdf
from llama_index.core import (
VectorStoreIndex,
StorageContext,
SimpleDirectoryReader,
Document,
)
from llama_index.core.node_parser import SentenceSplitter
from llama_index.llms.openai import OpenAI
# load documents
documents = SimpleDirectoryReader(
input_files=["IPCC_AR6_WGII_Chapter03.pdf"]
).load_data()
# initialize llm + node parser
# -- here, we set a smaller chunk size, to allow for more effective re-ranking
llm = OpenAI(model="gpt-3.5-turbo")
splitter = SentenceSplitter(chunk_size=256)
# limit to a smaller section
nodes = splitter.get_nodes_from_documents(
[Document(text=documents[0].get_content()[:1000000])]
)
# initialize storage context (by default it's in-memory)
storage_context = StorageContext.from_defaults()
storage_context.docstore.add_documents(nodes)
index = VectorStoreIndex(nodes, storage_context=storage_context)
from llama_index.retrievers.bm25 import BM25Retriever
# retireve the top 10 most similar nodes using embeddings
vector_retriever = index.as_retriever(similarity_top_k=10)
# retireve the top 10 most similar nodes using bm25
bm25_retriever = BM25Retriever.from_defaults(nodes=nodes, similarity_top_k=10)自定义检索器实现
from llama_index.core.retrievers import BaseRetriever
class HybridRetriever(BaseRetriever):
def __init__(self, vector_retriever, bm25_retriever):
self.vector_retriever = vector_retriever
self.bm25_retriever = bm25_retriever
super().__init__()
def _retrieve(self, query, **kwargs):
bm25_nodes = self.bm25_retriever.retrieve(query, **kwargs)
vector_nodes = self.vector_retriever.retrieve(query, **kwargs)
# combine the two lists of nodes
all_nodes = []
node_ids = set()
for n in bm25_nodes + vector_nodes:
if n.node.node_id not in node_ids:
all_nodes.append(n)
node_ids.add(n.node.node_id)
return all_nodes
index.as_retriever(similarity_top_k=5)
hybrid_retriever = HybridRetriever(vector_retriever, bm25_retriever)重新排名设置
!pip install sentence-transformers
from llama_index.core.postprocessor import SentenceTransformerRerank
reranker = SentenceTransformerRerank(top_n=4, model="BAAI/bge-reranker-base")取回
from llama_index.core import QueryBundle
retrieved_nodes = hybrid_retriever.retrieve(
"What is the impact of climate change on the ocean?"
)
reranked_nodes = reranker.postprocess_nodes(
nodes,
query_bundle=QueryBundle(
"What is the impact of climate change on the ocean?"
),
)
print("Initial retrieval: ", len(retrieved_nodes), " nodes")
print("Re-ranked retrieval: ", len(reranked_nodes), " nodes")
from llama_index.core.response.notebook_utils import display_source_node
for node in reranked_nodes:
display_source_node(node)完整查询引擎
from llama_index.core.query_engine import RetrieverQueryEngine
query_engine = RetrieverQueryEngine.from_args(
retriever=hybrid_retriever,
node_postprocessors=[reranker],
llm=llm,
)
response = query_engine.query(
"What is the impact of climate change on the ocean?"
)
from llama_index.core.response.notebook_utils import display_response
display_response(response)存储
存储index
index.storage_context.persist(persist_dir="<persist_dir>")from llama_index.core import StorageContext, load_index_from_storage
# rebuild storage context
storage_context = StorageContext.from_defaults(persist_dir="<persist_dir>")
# load index
index = load_index_from_storage(storage_context)重要提示:如果已使用自定义 、 等初始化了索引,则需要传入相同的 选项,或将其设置为全局设置。
transformations``embed_model``load_index_from_storage
使用向量存储
Milvus Vector Store - LlamaIndex 🦙 v0.10.18.post1
自定义LLM
HuggingFace LLM - StableLM - LlamaIndex 🦙 v0.10.18.post1
【RAG实践】基于LlamaIndex和Qwen1.5搭建基于本地知识库的问答机器人_langchain qwen1.5-CSDN博客
------ 🆕2024年06月17日🆕 ------
版本:stable
🚩自用自定义LLM
GLM4-9B
import os
from logger import logger
from typing import Optional, List, Mapping, Any
from llama_index.core import SimpleDirectoryReader, SummaryIndex, VectorStoreIndex
from llama_index.core.callbacks import CallbackManager
from llama_index.core.llms import (
CustomLLM,
CompletionResponse,
CompletionResponseGen,
LLMMetadata,
)
from llama_index.core.llms.callbacks import llm_completion_callback
from llama_index.core import Settings
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
from config import BASE_DIR, config
# "max_length": 8000, "do_sample": True, "top_k": 1
os.chdir(BASE_DIR)
class OurLLM(CustomLLM):
context_window: int = 32000
num_output: int = 8192
model_name: str = "GLM4-9B"
tokenizer: AutoTokenizer = None # 分词器
model: AutoModelForCausalLM = None # 模型
# gen_kwargs = {"max_length": 8192}
gen_kwargs = {"max_length": 8192, "do_sample": True, "top_k": 1}
def __init__(self, pretrained_model_name_or_path):
super().__init__()
self.tokenizer = AutoTokenizer.from_pretrained(pretrained_model_name_or_path, device_map="cuda", trust_remote_code=True)
self.model = AutoModelForCausalLM.from_pretrained(pretrained_model_name_or_path, device_map="cuda", torch_dtype=torch.bfloat16, trust_remote_code=True).eval()
@property
def metadata(self) -> LLMMetadata:
"""获取LLM元数据。"""
return LLMMetadata(
context_window=self.context_window,
num_output=self.num_output,
model_name=self.model_name,
)
def complete(self, prompt: str, **kwargs: Any) -> CompletionResponse:
"""LLM调用"""
logger.debug("LLM调用")
with torch.no_grad():
inputs = self.tokenizer.encode(prompt, return_tensors='pt').cuda()
# outputs = self.model.generate(inputs, max_length=self.num_output)
outputs = self.model.generate(inputs, **self.gen_kwargs)
response = self.tokenizer.decode(outputs[0], skip_special_tokens=True)
return CompletionResponse(text=response)
def my_complete(self, prompt: str, **kwargs: Any) -> CompletionResponse:
"""自定义LLM调用"""
logger.debug("自定义LLM调用")
inputs = self.tokenizer.apply_chat_template([{"role": "user", "content": prompt}],
add_generation_prompt=True,
tokenize=True,
return_tensors="pt",
return_dict=True
).to('cuda')
with torch.no_grad():
outputs = self.model.generate(**inputs, **self.gen_kwargs)
outputs = outputs[:, inputs['input_ids'].shape[1]:]
response = self.tokenizer.decode(outputs[0], skip_special_tokens=True)
return CompletionResponse(text=response)
def stream_complete(self, prompt: str, **kwargs: Any) -> CompletionResponseGen:
"""LLM流式调用"""
logger.debug("LLM流式调用")
with torch.no_grad():
inputs = self.tokenizer.encode(prompt, return_tensors='pt').cuda()
# outputs = self.model.generate(inputs, max_length=self.num_output)
outputs = self.model.generate(inputs, **self.gen_kwargs)
response = self.tokenizer.decode(outputs[0], skip_special_tokens=True)
for token in response:
yield CompletionResponse(text=token, delta=token)
# 定义自定义LLM
llm = OurLLM(config.MODEL_PATH)
# 定义嵌入模型
embed_model = config.EMBED_MODEL_PATH
if __name__ == "__main__":
# 读取文档数据
documents = SimpleDirectoryReader("data/director/License申请操作指南").load_data()
# logger.info(f'docs:\n{documents}')
Settings.llm = llm
Settings.embed_model = embed_model
# 创建向量存储索引
# index = VectorStoreIndex.from_documents(documents, show_progress=True)
from llama_index.vector_stores.milvus import MilvusVectorStore
vector_store = MilvusVectorStore(
uri=config.MILVUS,
collection_name='aiops',
dim=config.VECTOR_DIM,
overwrite=False,
similarity_metric='COSINE',
index_params = {
"index_type": "IVF_FLAT",
"metric_type": "COSINE",
"params": {
"nlist": 256
}
},
search_config={"metric_type": "COSINE", "params": {"nprobe": 20}}
)
index = VectorStoreIndex.from_vector_store(vector_store=vector_store)
# 创建查询引擎
query_engine = index.as_query_engine(similarity_top_k=1)
# 执行查询
response = query_engine.query("License申请操作指南")
logger.info(f'response:\n{response}')
# # 流式查询示例
# query_engine = index.as_query_engine(similarity_top_k=1, streaming=True)
# streaming_response = query_engine.query("License申请操作指南")
# streaming_response.print_response_stream()很重要
AutoModelForCausalLM.from_pretrained(pretrained_model_name_or_path, device_map="cuda", torch_dtype=torch.bfloat16, trust_remote_code=True).eval()中,不能设置 low_cpu_mem_usage=True,
接入xinference(未实践)
pip install llama-index-llms-xinference启动模型
# If Xinference can not be imported, you may need to restart jupyter notebook
from llama_index.core import SummaryIndex
from llama_index.core import (
TreeIndex,
VectorStoreIndex,
KeywordTableIndex,
KnowledgeGraphIndex,
SimpleDirectoryReader,
)
from llama_index.llms.xinference import Xinference
from xinference.client import RESTfulClient
from IPython.display import Markdown, display
# Define a client to send commands to xinference
client = RESTfulClient(f"http://localhost:{port}")
# Download and Launch a model, this may take a while the first time
model_uid = client.launch_model(
model_name="llama-2-chat",
model_size_in_billions=7,
model_format="ggmlv3",
quantization="q2_K",
)
# Initiate Xinference object to use the LLM
llm = Xinference(
endpoint=f"http://localhost:{port}",
model_uid=model_uid,
temperature=0.0,
max_tokens=512,
)
# create index from the data
documents = SimpleDirectoryReader("../data/paul_graham").load_data()
# change index name in the following line
index = VectorStoreIndex.from_documents(documents=documents)
# create the query engine
query_engine = index.as_query_engine(llm=llm)
# optionally, update the temperature and max answer length (in tokens)
llm.__dict__.update({"temperature": 0.0})
llm.__dict__.update({"max_tokens": 2048})
# ask a question and display the answer
question = "What did the author do after his time at Y Combinator?"
response = query_engine.query(question)
display(Markdown(f"{response}"))使用
from llama_index.llms.xinference import Xinference
# Set up Xinference with required parameters
llm = Xinference(
model_name="xinference-1.0",
app_id="ml",
user_id="xinference",
api_key="<YOUR XINFERENCE API KEY>"
temperature=0.5,
max_tokens=256,
)
# Call the complete function
response = llm.complete("Hello World!")
print(response)自定义embedding模型
pip install llama-index-embeddings-huggingfacefrom llama_index.embeddings.huggingface import HuggingFaceEmbedding
from llama_index.core import Settings
Settings.embed_model = HuggingFaceEmbedding(
model_name="BAAI/bge-small-en-v1.5"
)
ebd_model = HuggingFaceEmbedding(model_name=config.EMBED_MODEL_PATH)
ebd_model.get_text_embedding("test", True)
ebd_model.get_text_embedding_batch(text2ebd, True)嵌入模型最常见的用法是将其设置在全局 Settings 对象中,然后使用它构建索引和查询。输入文档将被分解为节点,嵌入模型将为每个节点生成一个嵌入。
使用 Langchain 的嵌入类从 Hugging Face 加载模型
pip install llama-index-embeddings-langchainfrom langchain.embeddings.huggingface import HuggingFaceBgeEmbeddings
from llama_index.core import Settings
Settings.embed_model = HuggingFaceBgeEmbeddings(model_name="BAAI/bge-base-en")完全自定义
from typing import Any, List
from InstructorEmbedding import INSTRUCTOR
from llama_index.core.embeddings import BaseEmbedding
class InstructorEmbeddings(BaseEmbedding):
def __init__(
self,
instructor_model_name: str = "hkunlp/instructor-large",
instruction: str = "Represent the Computer Science documentation or question:",
**kwargs: Any,
) -> None:
self._model = INSTRUCTOR(instructor_model_name)
self._instruction = instruction
super().__init__(**kwargs)
def _get_query_embedding(self, query: str) -> List[float]:
embeddings = self._model.encode([[self._instruction, query]])
return embeddings[0]
def _get_text_embedding(self, text: str) -> List[float]:
embeddings = self._model.encode([[self._instruction, text]])
return embeddings[0]
def _get_text_embeddings(self, texts: List[str]) -> List[List[float]]:
embeddings = self._model.encode(
[[self._instruction, text] for text in texts]
)
return embeddings
async def _get_query_embedding(self, query: str) -> List[float]:
return self._get_query_embedding(query)
async def _get_text_embedding(self, text: str) -> List[float]:
return self._get_text_embedding(text)加载数据
加载
- SimpleDirectoryReader,内置加载器,用于从本地目录加载各种文件类型
- LlamaParse,LlamaIndex 的官方 PDF 解析工具,作为托管 API 提供
- LlamaHub,数百个数据加载库的注册表,用于从任何来源获取数据
变换
Node Parser Usage Pattern - LlamaIndex
- 节点解析器使用模式
Node Parser Modules - LlamaIndex
- 节点解析器模块
管道允许设置可重复的、缓存优化的过程来加载数据
Ingestion Pipeline - LlamaIndex
抽象
文档和节点对象以及如何针对更高级的用例自定义它们
Documents / Nodes - LlamaIndex
Documents / Nodes
文档是任何数据源的通用容器
from llama_index.core import Document, VectorStoreIndex
text_list = [text1, text2, ...]
documents = [Document(text=t) for t in text_list]
# build index
index = VectorStoreIndex.from_documents(documents)metadata - 可附加到文本的注释字典
relationships - 包含与其他文档/节点的关系的字典
节点表示源文档的一个“块”,无论是文本块、图像还是其他块。与文档类似,它们包含元数据以及与其他节点的关系信息。
文档
from llama_index.core import Document, VectorStoreIndex
text_list = [text1, text2, ...]
documents = [Document(text=t) for t in text_list]
# build index
index = VectorStoreIndex.from_documents(documents)节点
from llama_index.core.node_parser import SentenceSplitter
# load documents
...
# parse nodes
parser = SentenceSplitter()
nodes = parser.get_nodes_from_documents(documents)
# build index
index = VectorStoreIndex(nodes)文档
from llama_index.core import SimpleDirectoryReader
documents = SimpleDirectoryReader("./data").load_data()手动构建文档
from llama_index.core import Document
text_list = [text1, text2, ...]
documents = [Document(text=t) for t in text_list]还可以使用一些默认文本快速创建文档:
document = Document.example()自定义
由于 Document 对象是 TextNode 对象的子类,因此所有这些设置和详细信息也适用于 TextNode 对象类。
metadata
文档还提供了包含有用元数据的机会。在每个文档上使用 metadata 字典,可以包含附加信息来帮助通知响应并跟踪查询响应的来源。此信息可以是任何内容,例如文件名或类别。如果要与矢量数据库集成,请记住,某些矢量数据库要求键必须是字符串,并且值必须是平面的( str 、 float 或 int)
在文档构造函数中:
document = Document(
text="text",
metadata={"filename": "<doc_file_name>", "category": "<category>"},
)文档创建后:
document.metadata = {"filename": "<doc_file_name>"}使用 SimpleDirectoryReader 和 file_metadata 挂钩自动设置文件名。这将自动在每个文档上运行挂钩以设置 metadata 字段:
from llama_index.core import SimpleDirectoryReader
filename_fn = lambda filename: {"file_name": filename}
# automatically sets the metadata of each document according to filename_fn
documents = SimpleDirectoryReader(
"./data", file_metadata=filename_fn
).load_data()自定义id
doc_id 用于实现索引中文档的高效刷新。使用 SimpleDirectoryReader 时,可以自动将文档 doc_id 设置为每个文档的完整路径:
from llama_index.core import SimpleDirectoryReader
documents = SimpleDirectoryReader("./data", filename_as_id=True).load_data()
print([x.doc_id for x in documents])还可以直接设置任何 Document 的 doc_id
document.doc_id = "My new document id!"ID 也可以通过 Document 对象的 node_id 或 id_ 属性来设置,类似于 TextNode 对象。
高级 - 元数据定制
自定义 LLM 元数据文本
通常,文档可能有许多元数据键,但可能不希望在响应合成期间所有元数据键都对 LLM 可见。在上面的示例中,可能不希望 LLM 读取文档的 file_name 。但是, file_name 可能包含有助于生成更好嵌入的信息。这样做的一个关键优点是在不改变 LLM 最终读取内容的情况下偏向检索的嵌入。
document.excluded_llm_metadata_keys = ["file_name"]可以使用 get_content() 函数并指定 MetadataMode.LLM 来测试 LLM 实际上最终会读取什么:
from llama_index.core.schema import MetadataMode
print(document.get_content(metadata_mode=MetadataMode.LLM)) # 读取文档数据
documents = SimpleDirectoryReader("data/director/License申请操作指南").load_data()
for doc in documents:
logger.info(f'metadata:\n {doc.get_content(metadata_mode=MetadataMode.LLM)}') # 现在metadata显示文件路径自定义嵌入元数据文本
可以自定义嵌入可见的元数据。在这种情况下,可以专门排除嵌入模型可见的元数据,以防不希望特定文本使嵌入产生偏差。
document.excluded_embed_metadata_keys = ["file_name"]使用 get_content() 函数并指定 MetadataMode.EMBED 来测试嵌入模型最终实际读取的内容:
from llama_index.core.schema import MetadataMode
print(document.get_content(metadata_mode=MetadataMode.EMBED))自定义元数据格式
节点
节点代表源文档的“块”,无论是文本块、图像还是更多。它们还包含元数据以及与其他节点和索引结构的关系信息。
Nodes are a first-class citizen in LlamaIndex.可以选择直接定义节点及其所有属性。还可以选择通过我们的 NodeParser 类将源文档“解析”为节点。
from llama_index.core.node_parser import SentenceSplitter
parser = SentenceSplitter()
nodes = parser.get_nodes_from_documents(documents)还可以选择手动构造 Node 对象并跳过第一部分
from llama_index.core.schema import TextNode, NodeRelationship, RelatedNodeInfo
node1 = TextNode(text="<text_chunk>", id_="<node_id>")
node2 = TextNode(text="<text_chunk>", id_="<node_id>")
# set relationships
node1.relationships[NodeRelationship.NEXT] = RelatedNodeInfo(
node_id=node2.node_id
)
node2.relationships[NodeRelationship.PREVIOUS] = RelatedNodeInfo(
node_id=node1.node_id
)
nodes = [node1, node2]如果需要, RelatedNodeInfo 类还可以存储额外的 metadata :
node2.relationships[NodeRelationship.PARENT] = RelatedNodeInfo(
node_id=node1.node_id, metadata={"key": "val"}
)每个节点都有一个 node_id 属性,如果没有手动指定,该属性会自动生成。该 ID 可用于多种目的;这包括能够更新存储中的节点、能够定义节点之间的关系(通过 IndexNode )等等。
print(node.node_id)
node.node_id = "My new node_id!"元数据提取
可以使用 Metadata Extractor 模块自动提取元数据
SummaryExtractor- 自动提取一组节点的摘要QuestionsAnsweredExtractor- 提取每个节点可以回答的一组问题TitleExtractor- 提取每个节点上下文的标题EntityExtractor- 提取每个节点内容中提到的实体(即地名、人物、事物的名称)
使用节点解析器链接 Metadata Extractor ** :**
from llama_index.core.extractors import (
TitleExtractor,
QuestionsAnsweredExtractor,
)
from llama_index.core.node_parser import TokenTextSplitter
text_splitter = TokenTextSplitter(
separator=" ", chunk_size=512, chunk_overlap=128
)
title_extractor = TitleExtractor(nodes=5)
qa_extractor = QuestionsAnsweredExtractor(questions=3)
# assume documents are defined -> extract nodes
from llama_index.core.ingestion import IngestionPipeline
pipeline = IngestionPipeline(
transformations=[text_splitter, title_extractor, qa_extractor]
)
nodes = pipeline.run(
documents=documents,
in_place=True,
show_progress=True,
)或插入索引:
from llama_index.core import VectorStoreIndex
index = VectorStoreIndex.from_documents(
documents, transformations=[text_splitter, title_extractor, qa_extractor]
)获取node.metadata
node.metadata
{'file_path': '/data1/wjm/projects/AIOPS/aiops-2024/data/director/License申请操作指南/1602298756694.txt', 'file_name': '1602298756694.txt', 'file_type': 'text/plain', 'file_size': 5087, 'creation_date': '2024-06-20', 'last_modified_date': '2024-06-20'}SimpleDirectoryReader
支持的格式
- .csv - comma-separated values
- .docx - Microsoft Word
- .epub - EPUB ebook format
- .hwp - Hangul Word Processor
- .ipynb - Jupyter Notebook
- .jpeg, .jpg - JPEG image
- .mbox - MBOX email archive
- .md - Markdown
- .mp3, .mp4 - audio and video
- .pdf - Portable Document Format
- .png - Portable Network Graphics
- .ppt, .pptm, .pptx - Microsoft PowerPoint
json解析器
LlamaIndex Readers Integration: Json (llamahub.ai)
用法
from llama_index.core import SimpleDirectoryReader
reader = SimpleDirectoryReader(input_dir="path/to/directory")
documents = reader.load_data()
documents = reader.load_data(num_workers=4) # 多线程- 默认情况下,
SimpleDirectoryReader只会读取目录顶层的文件。要从子目录中读取,请设置recursive=True:
SimpleDirectoryReader(input_dir="path/to/directory", recursive=True)- 使用
iter_data()方法在文件加载时迭代和处理文件
reader = SimpleDirectoryReader(input_dir="path/to/directory", recursive=True)
all_docs = []
for docs in reader.iter_data():
# <do something with the documents per file>
all_docs.extend(docs)限制加载的文件
SimpleDirectoryReader(input_files=["path/to/file1", "path/to/file2"])SimpleDirectoryReader(
input_dir="path/to/directory", exclude=["path/to/file1", "path/to/file2"]
)- 还可以将
required_exts设置为文件扩展名列表,以仅加载具有这些扩展名的文件:
SimpleDirectoryReader(
input_dir="path/to/directory", required_exts=[".pdf", ".docx"]
)- 使用
num_files_limit设置要加载的最大文件数:
SimpleDirectoryReader(input_dir="path/to/directory", num_files_limit=100)SimpleDirectoryReader期望文件采用utf-8编码,但可以使用encoding参数覆盖它:
SimpleDirectoryReader(input_dir="path/to/directory", encoding="latin-1")- 可以指定一个函数,该函数将读取每个文件并通过将函数作为
file_metadata传递来提取附加到每个文件的结果Document对象的元数据:
def get_meta(file_path):
return {"foo": "bar", "file_path": file_path}
SimpleDirectoryReader(input_dir="path/to/directory", file_metadata=get_meta)该函数应采用单个参数(文件路径)并返回元数据字典。
扩展到其他文件类型
可以通过将文件扩展名字典作为 file_extractor 传递给 BaseReader 实例来扩展 SimpleDirectoryReader 来读取其他文件类型。 BaseReader 应该读取文件并返回文档列表。例如,要添加对 .myfile 文件的自定义支持:
from llama_index.core import SimpleDirectoryReader
from llama_index.core.readers.base import BaseReader
from llama_index.core import Document
class MyFileReader(BaseReader):
def load_data(self, file, extra_info=None):
with open(file, "r") as f:
text = f.read()
# load_data returns a list of Document objects
return [Document(text=text + "Foobar", extra_info=extra_info or {})]
reader = SimpleDirectoryReader(
input_dir="./data", file_extractor={".myfile": MyFileReader()}
)
documents = reader.load_data()
print(documents)支持外部文件系统
SimpleDirectoryReader 采用可选的 fs 参数,可用于遍历远程文件系统
这可以是由 fsspec 协议实现的任何文件系统对象。 fsspec 协议具有针对各种远程文件系统的开源实现,包括 AWS S3、Azure Blob 和 DataLake、Google Drive、SFTP 等。
这是连接到 S3 的示例:
from s3fs import S3FileSystem
s3_fs = S3FileSystem(key="...", secret="...")
bucket_name = "my-document-bucket"
reader = SimpleDirectoryReader(
input_dir=bucket_name,
fs=s3_fs,
recursive=True, # recursively searches all subdirectories
)
documents = reader.load_data()
print(documents)数据连接器 Data Connectors(Reader)
数据连接器(又名 Reader )将来自不同数据源和数据格式的数据引入到简单 Document 表示形式(文本和简单元数据)中。
引入数据后,可以在顶部构建索引,使用查询引擎提问,并使用聊天引擎进行对话。
LlamaParse
LlamaParse 是由 LlamaIndex 创建的 API,用于使用 LlamaIndex 框架高效解析和表示文件,以实现高效检索和上下文增强。
❗️目前🆓
使用
- 登录并从
https://cloud.llamaindex.ai获取 api 密钥 - 安装最新的 LlamaIndex 版本
- 安装软件包
pip install llama-parse
import nest_asyncio
nest_asyncio.apply()
from llama_parse import LlamaParse
parser = LlamaParse(
api_key="llx-...", # can also be set in your env as LLAMA_CLOUD_API_KEY
result_type="markdown", # "markdown" and "text" are available
verbose=True,
)
# sync
documents = parser.load_data("./my_file.pdf")
# sync batch
documents = parser.load_data(["./my_file1.pdf", "./my_file2.pdf"])
# async
documents = await parser.aload_data("./my_file.pdf")
# async batch
documents = await parser.aload_data(["./my_file1.pdf", "./my_file2.pdf"])还可以将解析器集成为默认的 SimpleDirectoryReader ** PDF 加载器:**
import nest_asyncio
nest_asyncio.apply()
from llama_parse import LlamaParse
from llama_index.core import SimpleDirectoryReader
parser = LlamaParse(
api_key="llx-...", # can also be set in your env as LLAMA_CLOUD_API_KEY
result_type="markdown", # "markdown" and "text" are available
verbose=True,
)
file_extractor = {".pdf": parser}
documents = SimpleDirectoryReader(
"./data", file_extractor=file_extractor
).load_data()模块指南
支持的列表:
Simple Directory Reader
Simple Directory Reader - LlamaIndex
Parallel Processing SimpleDirectoryReader
Parallel Processing SimpleDirectoryReader - LlamaIndex
MilvusReader
Faiss Reader
Chroma Reader
Qdrant Reader
Database Reader
节点解析器
节点解析器是一个简单的抽象,它获取文档列表,并将它们分块为 Node 对象,因此每个节点都是父文档的特定块。当文档被分解为节点时,它的所有属性都继承到子节点(即 metadata 文本和元数据模板等)
单独使用:
from llama_index.core import Document
from llama_index.core.node_parser import SentenceSplitter
node_parser = SentenceSplitter(chunk_size=1024, chunk_overlap=20)
nodes = node_parser.get_nodes_from_documents(
[Document(text="long text")], show_progress=False
)节点解析器可以包含在具有引入管道的任何转换集中:
from llama_index.core import SimpleDirectoryReader
from llama_index.core.ingestion import IngestionPipeline
from llama_index.core.node_parser import TokenTextSplitter
documents = SimpleDirectoryReader("./data").load_data()
pipeline = IngestionPipeline(transformations=[TokenTextSplitter(), ...])
nodes = pipeline.run(documents=documents)索引用法
from llama_index.core import SimpleDirectoryReader, VectorStoreIndex
from llama_index.core.node_parser import SentenceSplitter
documents = SimpleDirectoryReader("./data").load_data()
# global
from llama_index.core import Settings
Settings.text_splitter = SentenceSplitter(chunk_size=1024, chunk_overlap=20)
# per-index
index = VectorStoreIndex.from_documents(
documents,
transformations=[SentenceSplitter(chunk_size=1024, chunk_overlap=20)],
)基于文件的节点解析器
最简单的流程是将 FlatFileReader 与 SimpleFileNodeParser 结合起来,自动为每种类型的内容使用最佳节点解析器。然后,可能希望将基于文件的节点解析器与基于文本的节点解析器链接起来,以考虑文本的实际长度。
**简单文件 解析器 **
from llama_index.core.node_parser import SimpleFileNodeParser
from llama_index.readers.file import FlatReader
from pathlib import Path
md_docs = FlatReader().load_data(Path("./test.md"))
parser = SimpleFileNodeParser()
md_nodes = parser.get_nodes_from_documents(md_docs)HTML 解析器
该节点解析器使用 beautifulsoup 解析原始 HTML
from llama_index.core.node_parser import HTMLNodeParser
parser = HTMLNodeParser(tags=["p", "h1"]) # optional list of tags
nodes = parser.get_nodes_from_documents(html_docs)JSON 解析器
from llama_index.core.node_parser import JSONNodeParser
parser = JSONNodeParser()
nodes = parser.get_nodes_from_documents(json_docs)Markdown 解析器
from llama_index.core.node_parser import MarkdownNodeParser
parser = MarkdownNodeParser()
nodes = parser.get_nodes_from_documents(markdown_docs)文本分割器
代码分割器
根据编写的语言拆分原始代码文本
from llama_index.core.node_parser import CodeSplitter
splitter = CodeSplitter(
language="python",
chunk_lines=40, # lines per chunk
chunk_lines_overlap=15, # lines overlap between chunks
max_chars=1500, # max chars per chunk
)
nodes = splitter.get_nodes_from_documents(documents)LangchainNodeParser
使用节点解析器包装来自 langchain 的任何现有文本分割器
from langchain.text_splitter import RecursiveCharacterTextSplitter
from llama_index.core.node_parser import LangchainNodeParser
parser = LangchainNodeParser(RecursiveCharacterTextSplitter())
nodes = parser.get_nodes_from_documents(documents)句子分割器
SentenceSplitter 尝试在尊重句子边界的同时分割文本。
from llama_index.core.node_parser import SentenceSplitter
splitter = SentenceSplitter(
chunk_size=1024,
chunk_overlap=20,
)
nodes = splitter.get_nodes_from_documents(documents)句子窗口节点分析器
SentenceWindowNodeParser 与其他节点解析器类似,只不过它将所有文档拆分为单独的句子。生成的节点还包含元数据中每个节点周围的句子“窗口”。请注意,此元数据对 LLM 或嵌入模型不可见。
这对于生成具有非常特定范围的嵌入最有用。然后,结合 MetadataReplacementNodePostProcessor ,可以在将节点发送到 LLM 之前将句子替换为其周围的上下文。
下面是使用默认设置设置解析器的示例。在实践中,通常只想调整句子的窗口大小。
import nltk
from llama_index.core.node_parser import SentenceWindowNodeParser
node_parser = SentenceWindowNodeParser.from_defaults(
# how many sentences on either side to capture
window_size=3,
# the metadata key that holds the window of surrounding sentences
window_metadata_key="window",
# the metadata key that holds the original sentence
original_text_metadata_key="original_sentence",
)SemanticSplitterNodeParser
“语义分块”是 Greg Kamradt 在他的关于 5 个级别的嵌入分块的视频教程中提出的一个新概念:https://youtu.be/8OJC21T2SL4?t=1933。
语义分割器不是使用固定块大小对文本进行分块,而是使用嵌入相似性自适应地选择句子之间的断点。这确保了“块”包含语义上彼此相关的句子。
from llama_index.core.node_parser import SemanticSplitterNodeParser
from llama_index.embeddings.openai import OpenAIEmbedding
embed_model = OpenAIEmbedding()
splitter = SemanticSplitterNodeParser(
buffer_size=1, breakpoint_percentile_threshold=95, embed_model=embed_model
)A full example can be found in our guide on using the SemanticSplitterNodeParser.
TokenTextSplitter
TokenTextSplitter 尝试根据原始令牌计数拆分为一致的块大小。
from llama_index.core.node_parser import TokenTextSplitter
splitter = TokenTextSplitter(
chunk_size=1024,
chunk_overlap=20,
separator=" ",
)
nodes = splitter.get_nodes_from_documents(documents)基于关系的节点解析器
分层节点解析器
该节点解析器将节点分块为分层节点。这意味着单个输入将被分块为多个块大小的层次结构,每个节点都包含对其父节点的引用。
当与 AutoMergingRetriever 结合使用时,这使我们能够在检索到大多数子节点时自动用其父节点替换检索到的节点。此过程为 LLM 提供了更完整的响应合成上下文。
from llama_index.core.node_parser import HierarchicalNodeParser
node_parser = HierarchicalNodeParser.from_defaults(
chunk_sizes=[2048, 512, 128]
)A full example can be found here in combination with the AutoMergingRetriever.
摄取管道
IngestionPipeline 使用应用于输入数据的 Transformations 概念。这些 Transformations 应用于输入数据,并且生成的节点将被返回或插入到向量数据库(如果给定)中。每个节点+转换对都会被缓存,因此使用相同节点+转换组合的后续运行(如果缓存已持久)可以使用缓存的结果并节省时间。
To see an interactive example of IngestionPipeline being put in use, check out the RAG CLI.
最简单的用法是实例化 IngestionPipeline
from llama_index.core import Document
from llama_index.embeddings.openai import OpenAIEmbedding
from llama_index.core.node_parser import SentenceSplitter
from llama_index.core.extractors import TitleExtractor
from llama_index.core.ingestion import IngestionPipeline, IngestionCache
# create the pipeline with transformations
pipeline = IngestionPipeline(
transformations=[
SentenceSplitter(chunk_size=25, chunk_overlap=0),
TitleExtractor(),
OpenAIEmbedding(),
]
)
# run the pipeline
nodes = pipeline.run(documents=[Document.example()])连接到矢量数据库
运行摄取管道时,还可以选择自动将生成的节点插入到远程向量存储中
然后,可以稍后从该向量存储构建索引
from llama_index.core import Document
from llama_index.embeddings.openai import OpenAIEmbedding
from llama_index.core.node_parser import SentenceSplitter
from llama_index.core.extractors import TitleExtractor
from llama_index.core.ingestion import IngestionPipeline
from llama_index.vector_stores.qdrant import QdrantVectorStore
import qdrant_client
client = qdrant_client.QdrantClient(location=":memory:")
vector_store = QdrantVectorStore(client=client, collection_name="test_store")
pipeline = IngestionPipeline(
transformations=[
SentenceSplitter(chunk_size=25, chunk_overlap=0),
TitleExtractor(),
OpenAIEmbedding(),
],
vector_store=vector_store,
)
# Ingest directly into a vector db
pipeline.run(documents=[Document.example()])
# Create your index
from llama_index.core import VectorStoreIndex
index = VectorStoreIndex.from_vector_store(vector_store)计算管道中的嵌入
嵌入是作为管道的一部分进行计算的。如果将管道连接到向量存储,则嵌入必须是管道的一个阶段,否则稍后的索引实例化将失败。
如果不连接到向量存储,即仅生成节点列表,则可以省略管道中的嵌入。
缓存
在 IngestionPipeline 中,每个节点 + 转换组合都经过哈希处理和缓存。这可以节省使用相同数据的后续运行的时间。
本地缓存管理
一旦有了管道,可能想要存储和加载缓存。
# save
pipeline.persist("./pipeline_storage")
# load and restore state
new_pipeline = IngestionPipeline(
transformations=[
SentenceSplitter(chunk_size=25, chunk_overlap=0),
TitleExtractor(),
],
)
new_pipeline.load("./pipeline_storage")
# will run instantly due to the cache
nodes = pipeline.run(documents=[Document.example()])如果缓存太大,可以清除它
# delete all context of the cache
cache.clear()异步支持
nodes = await pipeline.arun(documents=documents)文件管理
将 docstore 附加到摄取管道将启用文档管理。
使用 document.doc_id 或 node.ref_doc_id 作为接地点,摄取管道将主动查找重复文档。
它的工作原理是:
- Storing a map of
doc_id->document_hash
存储doc_id->document_hash的地图 - If a vector store is attached:
如果附加了矢量存储: - If a duplicate
doc_idis detected, and the hash has changed, the document will be re-processed and upserted
如果检测到重复的doc_id,并且哈希已更改,则将重新处理并更新插入文档 - If a duplicate
doc_idis detected and the hash is unchanged, the node is skipped
如果检测到重复的doc_id并且哈希值未更改,则跳过该节点 - If only a vector store is not attached:
如果仅未附加矢量存储: - Checks all existing hashes for each node
检查每个节点的所有现有哈希值 - If a duplicate is found, the node is skipped
如果发现重复节点,则跳过该节点 - Otherwise, the node is processed
否则,处理该节点
如果不附加向量存储,只能检查并删除重复的输入。
from llama_index.core.ingestion import IngestionPipeline
from llama_index.core.storage.docstore import SimpleDocumentStore
pipeline = IngestionPipeline(
transformations=[...], docstore=SimpleDocumentStore()
)并行处理
IngestionPipeline 的 run 方法可以通过并行进程执行。它通过使用 multiprocessing.Pool 将批量节点分布到多个处理器来实现这一点。
要使用并行处理执行,请将 num_workers 设置为要使用的进程数:
from llama_index.core.ingestion import IngestionPipeline
pipeline = IngestionPipeline(
transformations=[...],
)
pipeline.run(documents=[...], num_workers=4)Transformations
转换是将节点列表作为输入并返回节点列表的过程。每个实现 Transformation 基类的组件都具有同步 __call__() 定义和异步 acall() 定义。
目前,以下组件是 Transformation 对象:
TextSplitterNodeParserMetadataExtractorEmbeddingsmodel (check our list of supported embeddings)
使用
转换最好与 IngestionPipeline 一起使用,但它们也可以直接使用
from llama_index.core.node_parser import SentenceSplitter
from llama_index.core.extractors import TitleExtractor
node_parser = SentenceSplitter(chunk_size=512)
extractor = TitleExtractor()
# use transforms directly
nodes = node_parser(documents)
# or use a transformation in async
nodes = await extractor.acall(nodes)与索引结合
转换可以传递到索引或整体全局设置中,并将在对索引调用 from_documents() 或 insert() 时使用。
from llama_index.core import VectorStoreIndex
from llama_index.core.extractors import (
TitleExtractor,
QuestionsAnsweredExtractor,
)
from llama_index.core.ingestion import IngestionPipeline
from llama_index.core.node_parser import TokenTextSplitter
transformations = [
TokenTextSplitter(chunk_size=512, chunk_overlap=128),
TitleExtractor(nodes=5),
QuestionsAnsweredExtractor(questions=3),
]
# global
from llama_index.core import Settings
Settings.transformations = [text_splitter, title_extractor, qa_extractor]
# per-index
index = VectorStoreIndex.from_documents(
documents, transformations=transformations
)自定义转换
可以通过实现基类来自己实现任何转换
自定义转换将删除文本中的所有特殊字符或标点符号。
import re
from llama_index.core import Document
from llama_index.embeddings.openai import OpenAIEmbedding
from llama_index.core.node_parser import SentenceSplitter
from llama_index.core.ingestion import IngestionPipeline
from llama_index.core.schema import TransformComponent
class TextCleaner(TransformComponent):
def __call__(self, nodes, **kwargs):
for node in nodes:
node.text = re.sub(r"[^0-9A-Za-z ]", "", node.text)
return nodes然后可以直接使用它们或在任何 IngestionPipeline 中使用
# use in a pipeline
pipeline = IngestionPipeline(
transformations=[
SentenceSplitter(chunk_size=25, chunk_overlap=0),
TextCleaner(),
OpenAIEmbedding(),
],
)
nodes = pipeline.run(documents=[Document.example()])索引
Index 是一种数据结构,允许快速检索用户查询的相关上下文。对于 LlamaIndex 来说,它是检索增强生成 (RAG) 用例的核心基础
在高层次上, Indexes 是根据文档构建的。它们用于构建查询引擎和聊天引擎,从而可以通过数据进行问答和聊天
在底层, Indexes 将数据存储在 Node 对象(表示原始文档的块)中,并公开支持其他配置和自动化的 Retriever 接口
索引指南 - LlamaIndex --- Index Guide - LlamaIndex
向量索引
向量存储接受 Node 对象列表并从中构建索引
基本用法
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
# Load documents and build index
documents = SimpleDirectoryReader(
"../../examples/data/paul_graham"
).load_data()
index = VectorStoreIndex.from_documents(documents, show_progress=True)如果在命令行上使用 from_documents ,则可以方便地传递 show_progress=True 在索引构建期间显示进度条。
当使用 from_documents 时,文档将被分成块并解析为 Node 对象,即跟踪元数据和关系的文本字符串的轻量级抽象。
默认情况下,VectorStoreIndex 将所有内容存储在内存中。
默认情况下, VectorStoreIndex 将批量生成并插入 2048 个节点的向量。如果内存有限(或内存过剩),可以通过传递 insert_batch_size=2048 和想要的批量大小来修改它。
使用摄取管道创建节点
允许自定义节点的分块、元数据和嵌入
from llama_index.core import Document
from llama_index.embeddings.openai import OpenAIEmbedding
from llama_index.core.node_parser import SentenceSplitter
from llama_index.core.extractors import TitleExtractor
from llama_index.core.ingestion import IngestionPipeline, IngestionCache
# create the pipeline with transformations
pipeline = IngestionPipeline(
transformations=[
SentenceSplitter(chunk_size=25, chunk_overlap=0),
TitleExtractor(),
OpenAIEmbedding(),
]
)
# run the pipeline
nodes = pipeline.run(documents=[Document.example()])直接创建和管理节点
from llama_index.core.schema import TextNode
node1 = TextNode(text="<text_chunk>", id_="<node_id>")
node2 = TextNode(text="<text_chunk>", id_="<node_id>")
nodes = [node1, node2]
index = VectorStoreIndex(nodes)存储向量索引
LlamaIndex 支持数十种矢量存储。可以通过传入 StorageContext 来指定要使用的参数,然后在该参数上指定 vector_store 参数
import pinecone
from llama_index.core import (
VectorStoreIndex,
SimpleDirectoryReader,
StorageContext,
)
from llama_index.vector_stores.pinecone import PineconeVectorStore
# init pinecone
pinecone.init(api_key="<api_key>", environment="<environment>")
pinecone.create_index(
"quickstart", dimension=1536, metric="euclidean", pod_type="p1"
)
# construct vector store and customize storage context
storage_context = StorageContext.from_defaults(
vector_store=PineconeVectorStore(pinecone.Index("quickstart"))
)
# Load documents and build index
documents = SimpleDirectoryReader(
"../../examples/data/paul_graham"
).load_data()
index = VectorStoreIndex.from_documents(
documents, storage_context=storage_context
)矢量存储索引使用示例:
Vector Store Index usage examples - LlamaIndex
可组合检索
VectorStoreIndex (以及任何其他索引/检索器)能够检索通用对象,包括
- references to nodes 对节点的引用
- query engines 查询引擎
- retrievers
- query pipelines 查询管道
如果检索到这些对象,它们将使用提供的查询自动运行
from llama_index.core.schema import IndexNode
query_engine = other_index.as_query_engine
obj = IndexNode(
text="A query engine describing X, Y, and Z.",
obj=query_engine,
index_id="my_query_engine",
)
index = VectorStoreIndex(nodes=nodes, objects=[obj])
retriever = index.as_retreiver(verbose=True)如果检索到包含查询引擎的索引节点,则将运行查询引擎并将结果响应作为节点返回
文件管理
大多数 LlamaIndex 索引结构允许插入、删除、更新和刷新操作
插入
from llama_index.core import SummaryIndex, Document
index = SummaryIndex([])
text_chunks = ["text_chunk_1", "text_chunk_2", "text_chunk_3"]
doc_chunks = []
for i, text in enumerate(text_chunks):
doc = Document(text=text, id_=f"doc_id_{i}")
doc_chunks.append(doc)
# insert
for doc_chunk in doc_chunks:
index.insert(doc_chunk)删除
可以通过指定 document_id 从大多数索引数据结构中“删除”文档。 (注:树索引目前不支持删除)。该文档对应的所有节点都将被删除。
index.delete_ref_doc("doc_id_0", delete_from_docstore=True)如果使用同一文档库在索引之间共享节点, delete_from_docstore 将默认为 False 。但是,当设置为 False 时,查询时不会使用这些节点,因为它们将从索引的 index_struct 中删除,索引会跟踪哪些节点可用于查询
更新
如果索引中已存在文档,可以使用相同的文档 id_ “更新”文档
# NOTE: the document has a `doc_id` specified
doc_chunks[0].text = "Brand new document text"
index.update_ref_doc(
doc_chunks[0],
update_kwargs={"delete_kwargs": {"delete_from_docstore": True}},
)刷新
如果在加载数据时设置每个文档的doc id_ ,还可以自动刷新索引
refresh() 函数只会更新具有相同 doc id_ 但文本内容不同的文档。索引中根本不存在的任何文档也将被插入。
refresh() 还返回一个布尔列表,指示输入中的哪些文档已在索引中刷新。
# modify first document, with the same doc_id
doc_chunks[0] = Document(text="Super new document text", id_="doc_id_0")
# add a new document
doc_chunks.append(
Document(
text="This isn't in the index yet, but it will be soon!",
id_="doc_id_3",
)
)
# refresh the index
refreshed_docs = index.refresh_ref_docs(
doc_chunks, update_kwargs={"delete_kwargs": {"delete_from_docstore": True}}
)
# refreshed_docs[0] and refreshed_docs[-1] should be true文件追踪
使用文档库的任何索引(即除大多数矢量存储集成之外的所有索引),可以查看已插入到文档库中的文档。
print(index.ref_doc_info)
"""
> {'doc_id_1': RefDocInfo(node_ids=['071a66a8-3c47-49ad-84fa-7010c6277479'], metadata={}),
'doc_id_2': RefDocInfo(node_ids=['9563e84b-f934-41c3-acfd-22e88492c869'], metadata={}),
'doc_id_0': RefDocInfo(node_ids=['b53e6c2f-16f7-4024-af4c-42890e945f36'], metadata={}),
'doc_id_3': RefDocInfo(node_ids=['6bedb29f-15db-4c7c-9885-7490e10aa33f'], metadata={})}
"""元数据提取
from llama_index.core.node_parser import SentenceSplitter
from llama_index.core.extractors import (
SummaryExtractor,
QuestionsAnsweredExtractor,
TitleExtractor,
KeywordExtractor,
)
from llama_index.extractors.entity import EntityExtractor
transformations = [
SentenceSplitter(),
TitleExtractor(nodes=5),
QuestionsAnsweredExtractor(questions=3),
SummaryExtractor(summaries=["prev", "self"]),
KeywordExtractor(keywords=10),
EntityExtractor(prediction_threshold=0.5),
]
from llama_index.core.ingestion import IngestionPipeline
pipeline = IngestionPipeline(transformations=transformations)
nodes = pipeline.run(documents=documents){'page_label': '2',
'file_name': '10k-132.pdf',
'document_title': 'Uber Technologies, Inc. 2019 Annual Report: Revolutionizing Mobility and Logistics Across 69 Countries and 111 Million MAPCs with $65 Billion in Gross Bookings',
'questions_this_excerpt_can_answer': '\n\n1. How many countries does Uber Technologies, Inc. operate in?\n2. What is the total number of MAPCs served by Uber Technologies, Inc.?\n3. How much gross bookings did Uber Technologies, Inc. generate in 2019?',
'prev_section_summary': "\n\nThe 2019 Annual Report provides an overview of the key topics and entities that have been important to the organization over the past year. These include financial performance, operational highlights, customer satisfaction, employee engagement, and sustainability initiatives. It also provides an overview of the organization's strategic objectives and goals for the upcoming year.",
'section_summary': '\nThis section discusses a global tech platform that serves multiple multi-trillion dollar markets with products leveraging core technology and infrastructure. It enables consumers and drivers to tap a button and get a ride or work. The platform has revolutionized personal mobility with ridesharing and is now leveraging its platform to redefine the massive meal delivery and logistics industries. The foundation of the platform is its massive network, leading technology, operational excellence, and product expertise.',
'excerpt_keywords': '\nRidesharing, Mobility, Meal Delivery, Logistics, Network, Technology, Operational Excellence, Product Expertise, Point A, Point B'}自定义提取器
from llama_index.core.extractors import BaseExtractor
class CustomExtractor(BaseExtractor):
async def aextract(self, nodes) -> List[Dict]:
metadata_list = [
{
"custom": node.metadata["document_title"]
+ "\n"
+ node.metadata["excerpt_keywords"]
}
for node in nodes
]
return metadata_list存储
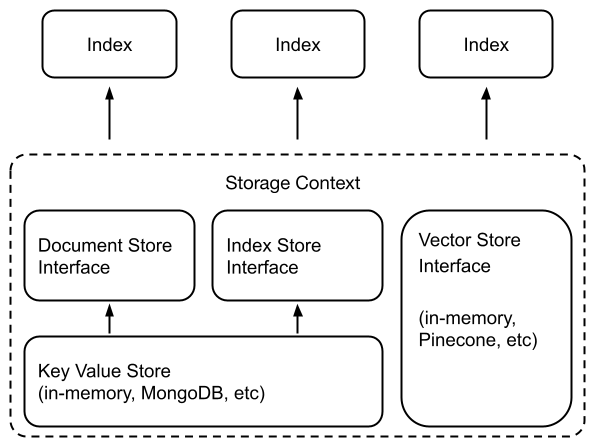
在底层,LlamaIndex 支持可交换存储组件,允许自定义:
- Document stores: 文档存储:存储摄取的文档(即
Node对象)的位置, - Index stores: 索引存储:存储索引元数据的位置,
- Vector stores: 向量存储:存储嵌入向量的位置。
- Graph stores: 图存储:存储知识图的位置(即
KnowledgeGraphIndex)。 - Chat Stores: 聊天存储:存储和组织聊天消息的地方。
文档/索引存储依赖于通用的键值存储抽象
LlamaIndex 支持将数据持久保存到 fsspec 支持的任何存储后端。我们已确认支持以下存储后端:
- Local filesystem 本地文件系统
- AWS S3
- Cloudflare R2
许多向量存储(FAISS 除外)将存储数据和索引(嵌入)。这意味着不需要使用单独的文档存储或索引存储。这也意味着不需要显式地保留这些数据——这会自动发生。用法如下所示来构建新索引/重新加载现有索引。
## build a new index
from llama_index.core import VectorStoreIndex, StorageContext
from llama_index.vector_stores.deeplake import DeepLakeVectorStore
# construct vector store and customize storage context
vector_store = DeepLakeVectorStore(dataset_path="<dataset_path>")
storage_context = StorageContext.from_defaults(vector_store=vector_store)
# Load documents and build index
index = VectorStoreIndex.from_documents(
documents, storage_context=storage_context
)
## reload an existing one
index = VectorStoreIndex.from_vector_store(vector_store=vector_store)通常要使用存储抽象,需要定义一个 StorageContext 对象:
from llama_index.core.storage.docstore import SimpleDocumentStore
from llama_index.core.storage.index_store import SimpleIndexStore
from llama_index.core.vector_stores import SimpleVectorStore
from llama_index.core import StorageContext
# create storage context using default stores
storage_context = StorageContext.from_defaults(
docstore=SimpleDocumentStore(),
vector_store=SimpleVectorStore(),
index_store=SimpleIndexStore(),
)简单向量存储
默认情况下,LlamaIndex 使用简单的内存向量存储
可以通过调用 vector_store.persist() (分别调用 SimpleVectorStore.from_persist_path(...) )将它们保存到磁盘(并从磁盘加载)
Example Notebooks
Chroma - LlamaIndex
Chroma Vector Store - LlamaIndex
Elasticsearch Vector Store - LlamaIndex
Faiss Vector Store - LlamaIndex
Milvus Vector Store - LlamaIndex
Milvus Vector Store With Hybrid Retrieval - LlamaIndex
MilvusOperatorFunctionDemo - LlamaIndex
Neo4j vector store - LlamaIndex
pgvecto.rs - LlamaIndex
Qdrant Vector Store - LlamaIndex
Qdrant Hybrid Search - LlamaIndex
文档存储
简单文档存储
默认情况下, SimpleDocumentStore 在内存中存储 Node 对象。可以通过调用 docstore.persist() (分别调用 SimpleDocumentStore.from_persist_path(...) )将它们保存到磁盘(并从磁盘加载)
MongoDB 文档存储
支持 MongoDB 作为替代文档存储后端,在摄取 Node 对象时保留数据
from llama_index.storage.docstore.mongodb import MongoDocumentStore
from llama_index.core.node_parser import SentenceSplitter
# create parser and parse document into nodes
parser = SentenceSplitter()
nodes = parser.get_nodes_from_documents(documents)
# create (or load) docstore and add nodes
docstore = MongoDocumentStore.from_uri(uri="<mongodb+srv://...>")
docstore.add_documents(nodes)
# create storage context
storage_context = StorageContext.from_defaults(docstore=docstore)
# build index
index = VectorStoreIndex(nodes, storage_context=storage_context)在底层, MongoDocumentStore 连接到固定的 MongoDB 数据库并为节点初始化新集合(或加载现有集合)。
使用 MongoDocumentStore 时无需调用 storage_context.persist() (或 docstore.persist() ),因为默认情况下数据会保留。
可以通过使用现有的 db_name 和 collection_name 重新初始化 MongoDocumentStore 轻松地重新连接到 MongoDB 集合并重新加载索引。
Redis 文档存储
支持 Redis 作为替代文档存储后端,在摄取 Node 对象时保留数据
from llama_index.storage.docstore.redis import RedisDocumentStore
from llama_index.core.node_parser import SentenceSplitter
# create parser and parse document into nodes
parser = SentenceSplitter()
nodes = parser.get_nodes_from_documents(documents)
# create (or load) docstore and add nodes
docstore = RedisDocumentStore.from_host_and_port(
host="127.0.0.1", port="6379", namespace="llama_index"
)
docstore.add_documents(nodes)
# create storage context
storage_context = StorageContext.from_defaults(docstore=docstore)
# build index
index = VectorStoreIndex(nodes, storage_context=storage_context)在底层, RedisDocumentStore 连接到 redis 数据库,并将您的节点添加到存储在 {namespace}/docs 下的命名空间。
可以在实例化 RedisDocumentStore 时配置 namespace ,否则默认 namespace="docstore"
Firestore 文档存储
支持 Firestore 作为替代文档存储后端,在摄取 Node 对象时保留数据
from llama_index.storage.docstore.firestore import FirestoreDocumentStore
from llama_index.core.node_parser import SentenceSplitter
# create parser and parse document into nodes
parser = SentenceSplitter()
nodes = parser.get_nodes_from_documents(documents)
# create (or load) docstore and add nodes
docstore = FirestoreDocumentStore.from_database(
project="project-id",
database="(default)",
)
docstore.add_documents(nodes)
# create storage context
storage_context = StorageContext.from_defaults(docstore=docstore)
# build index
index = VectorStoreIndex(nodes, storage_context=storage_context)在底层, FirestoreDocumentStore 连接到 Google Cloud 中的 firestore 数据库,并将您的节点添加到存储在 {namespace}/docs 下的命名空间。
TODO 索引存储
简单索引存储
默认情况下,LlamaIndex 使用由内存中键值存储支持的简单索引存储。可以通过调用 index_store.persist() (分别调用 SimpleIndexStore.from_persist_path(...) )将它们保存到磁盘(并从磁盘加载)
🚩自用加载索引
def get_vector_store(overwrite : bool = False) -> MilvusVectorStore:
vector_store = MilvusVectorStore(
uri=config.MILVUS,
collection_name='aiops',
dim=config.VECTOR_DIM,
overwrite=overwrite,
similarity_metric='COSINE',
index_params = {
"index_type": "IVF_FLAT",
"metric_type": "COSINE",
"params": {
"nlist": 256
}
},
search_config={"metric_type": "COSINE", "params": {"nprobe": 20}}
)
return vector_store
index = VectorStoreIndex.from_vector_store(vector_store=get_vector_store())MongoDB 索引存储
Redis 索引存储
聊天存储
保存和加载数据
默认情况下,LlamaIndex 将数据存储在内存中,如果需要,可以显式保留该数据:
storage_context.persist(persist_dir="<persist_dir>")这会将数据保存到磁盘上指定的 persist_dir (默认情况下为 ./storage )
假设跟踪要加载的索引 ID,则可以保留多个索引并从同一目录加载多个索引
用户还可以配置默认保存数据的替代存储后端(例如 MongoDB )。在这种情况下,调用 storage_context.persist() 将不会执行任何操作。
加载数据
要加载数据,只需使用相同的配置重新创建存储上下文(例如传入相同的 persist_dir 或向量存储客户端)
storage_context = StorageContext.from_defaults(
docstore=SimpleDocumentStore.from_persist_dir(persist_dir="<persist_dir>"),
vector_store=SimpleVectorStore.from_persist_dir(
persist_dir="<persist_dir>"
),
index_store=SimpleIndexStore.from_persist_dir(persist_dir="<persist_dir>"),
)可以通过下面的一些便利函数从 StorageContext 加载特定索引
from llama_index.core import (
load_index_from_storage,
load_indices_from_storage,
load_graph_from_storage,
)
# load a single index
# need to specify index_id if multiple indexes are persisted to the same directory
index = load_index_from_storage(storage_context, index_id="<index_id>")
# don't need to specify index_id if there's only one index in storage context
index = load_index_from_storage(storage_context)
# load multiple indices
indices = load_indices_from_storage(storage_context) # loads all indices
indices = load_indices_from_storage(
storage_context, index_ids=[index_id1, ...]
) # loads specific indices
# load composable graph
graph = load_graph_from_storage(
storage_context, root_id="<root_id>"
) # loads graph with the specified root_id自定义存储
默认情况下,LlamaIndex 隐藏了复杂性,可以用不到 5 行代码查询数据:
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
documents = SimpleDirectoryReader("data").load_data()
index = VectorStoreIndex.from_documents(documents)
query_engine = index.as_query_engine()
response = query_engine.query("Summarize the documents.")在底层,LlamaIndex 还支持可交换存储层,允许自定义摄取文档(即 Node 对象)、嵌入向量和索引元数据的存储位置。
低级 API
使用较低级别的 API 来提供更精细的控制:
from llama_index.core.storage.docstore import SimpleDocumentStore
from llama_index.core.storage.index_store import SimpleIndexStore
from llama_index.core.vector_stores import SimpleVectorStore
from llama_index.core.node_parser import SentenceSplitter
# create parser and parse document into nodes
parser = SentenceSplitter()
nodes = parser.get_nodes_from_documents(documents)
# create storage context using default stores
storage_context = StorageContext.from_defaults(
docstore=SimpleDocumentStore(),
vector_store=SimpleVectorStore(),
index_store=SimpleIndexStore(),
)
# create (or load) docstore and add nodes
storage_context.docstore.add_documents(nodes)
# build index
index = VectorStoreIndex(nodes, storage_context=storage_context)
# save index
index.storage_context.persist(persist_dir="<persist_dir>")
# can also set index_id to save multiple indexes to the same folder
index.set_index_id("<index_id>")
index.storage_context.persist(persist_dir="<persist_dir>")
# to load index later, make sure you setup the storage context
# this will loaded the persisted stores from persist_dir
storage_context = StorageContext.from_defaults(persist_dir="<persist_dir>")
# then load the index object
from llama_index.core import load_index_from_storage
loaded_index = load_index_from_storage(storage_context)
# if loading an index from a persist_dir containing multiple indexes
loaded_index = load_index_from_storage(storage_context, index_id="<index_id>")
# if loading multiple indexes from a persist dir
loaded_indicies = load_index_from_storage(
storage_context, index_ids=["<index_id>", ...]
)查询