xinference推理框架
大约 6 分钟
使用
安装
gcc、g++
apt-get install build-essentialpip install xinference
pip install "xinference[transformers]"
pip install "xinference[vllm]"
CMAKE_ARGS="-DLLAMA_CUBLAS=on" pip install llama-cpp-python环境(基于0.15.2版本)
chatchat==0.1.7
datasets==2.18.0
langchain_community==0.3.2
langchain_core==0.3.10
langchain_openai==0.2.2
loguru==0.7.2
milvus_model==0.2.7
numpy==2.1.2
openai==1.51.2
openpyxl==3.1.5
pandas==2.2.3
pdfplumber==0.11.4
pypdf==5.0.1
PyYAML==6.0.1
PyYAML==6.0.2
ragas==0.1.21
scikit_learn==1.5.2
setuptools==69.5.1
simplejson==3.19.2
streamlit==1.39.0
streamlit_antd_components==0.3.2
streamlit_extras==0.4.7
streamlit_feedback==0.1.3
streamlit_markdown==1.0.9
streamlit_raw_echarts==0.1.4
torch==2.4.0
tqdm==4.66.4
transformers==4.43.4
watchdog==5.0.3
xinference==0.15.2启动
需要设置目录变量
conda activate xinference
XINFERENCE_HOME=/data1/xinference xinference-local --host 0.0.0.0 --port 9997后台运行
conda activate xinference
nohup env XINFERENCE_HOME=/data1/xinference xinference-local --host 0.0.0.0 --port 9997 > /data1/xinference/output.log 2>&1 &启动脚本
#!/bin/bash
# 输出启动提示
echo "正在激活 conda 环境..."
source /data1/miniconda3/etc/profile.d/conda.sh
conda activate xinference
if [ $? -eq 0 ]; then
echo "conda 环境已激活。"
else
echo "Conda 环境激活失败。请确认 Conda 已安装并正确配置。"
exit 1
fi
# 输出设置环境变量提示
echo "正在设置环境变量并启动 Xinference..."
nohup env XINFERENCE_HOME=/data1/xinference xinference-local --host 0.0.0.0 --port 9997 > /data1/xinference/output.log 2>&1 &
if [ $? -eq 0 ]; then
echo "Xinference 已启动。"
else
echo "Xinference 启动失败。"
exit 1
fi#!/bin/bash
# 输出关闭提示
echo "正在查找并关闭 Xinference 进程..."
pkill -f 'xinference-local --host 0.0.0.0 --port 9997'
if [ $? -eq 0 ]; then
echo "Xinference 已关闭。"
else
echo "Xinference 关闭失败。可能没有运行中的 Xinference 进程。"
fi程序中调用
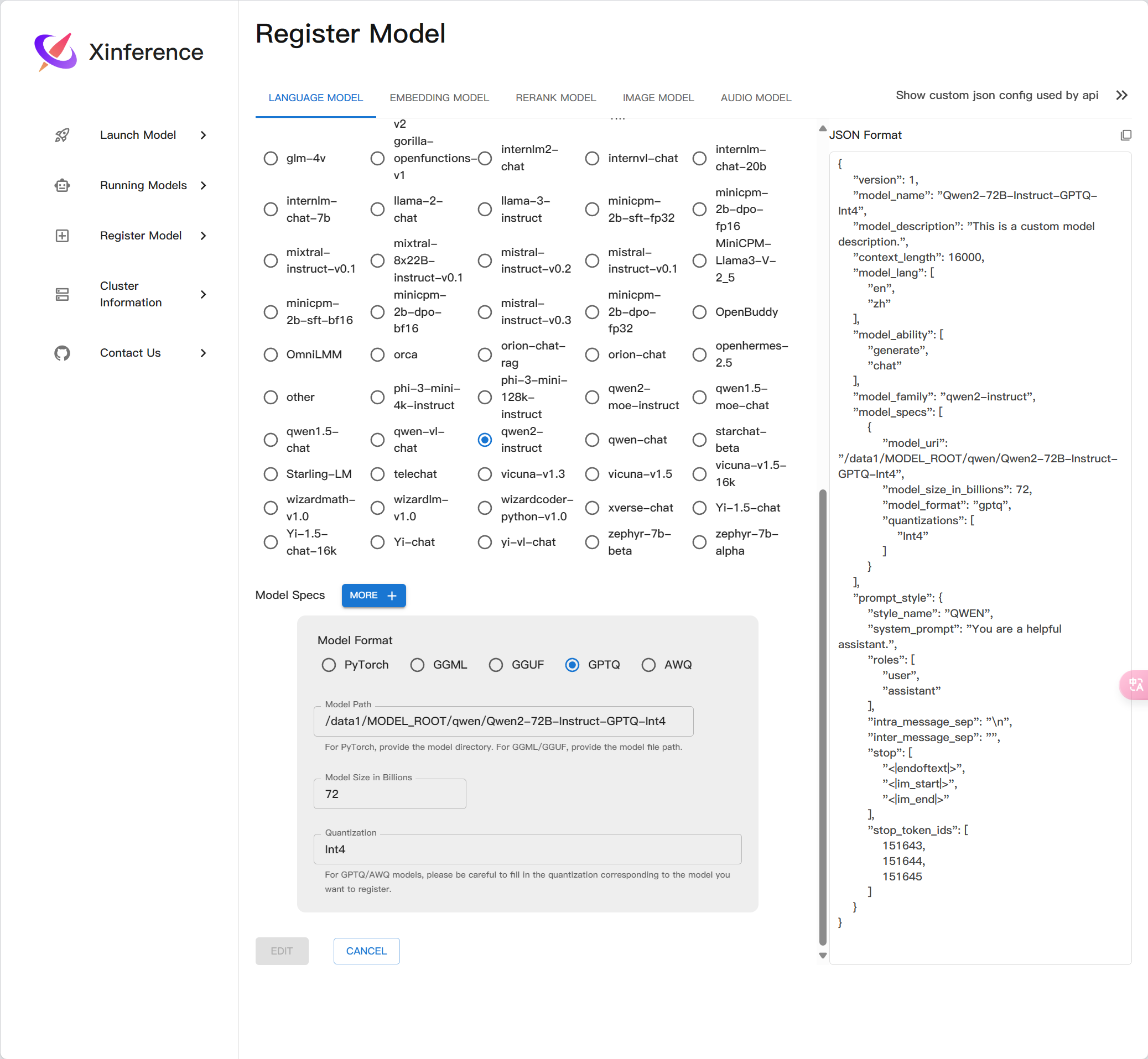
注册一个自定义模型
<model_type> 替换为 LLM 或者 embedding
LLM的Json示例[^1]
embedding的Json示例^2
import json
from xinference.client import Client
with open('model.json') as fd:
model = fd.read()
endpoint = 'http://localhost:9997'
client = Client(endpoint)
client.register_model(model_type="<model_type>", model=model, persist=False)启动自定义模型
uid = client.launch_model(model_name='my-glm-4-9b-chat', model_format='pytorch', model_engine='Transformers')使用自定义模型
model = client.get_model(model_uid=uid)
# 法一:
response = model.generate('What is the largest animal in the world?')
text = response["choices"][0]["text"].strip()
"""结果
{
"id":"cmpl-a4a9d9fc-7703-4a44-82af-fce9e3c0e52a",
"object":"text_completion",
"created":1692024624,
"model":"43e1f69a-3ab0-11ee-8f69-fa163e74fa2d",
"choices":[
{
"text":"\nWhat does an octopus look like?\nHow many human hours has an octopus been watching you for?",
"index":0,
"logprobs":"None",
"finish_reason":"stop"
}
],
"usage":{
"prompt_tokens":10,
"completion_tokens":23,
"total_tokens":33
}
}
"""
# 法二:
chat_history = []
prompt = "世界上最大的动物是什么?"
# If the model has "generate" capability, then you can call the
# model.generate API.
response = model.chat(
prompt,
chat_history=chat_history,
generate_config={"max_tokens": 16000}
)
# 获取 content 字段的值
content = data['choices'][0]['message']['content']
"""结果
{'id': 'chatf5f9d956-35e6-11ef-a7ad-7c7a3ced17c9', 'object': 'chat.completion', 'created': 1719645155, 'model': 'glm-1', 'choices': [{'index': 0, 'message': {'role': 'assistant', 'content': '你好👋!有什么可以帮助你的吗?'}, 'finish_reason': 'stop'}], 'usage': {'prompt_tokens': -1, 'completion_tokens': -1, 'total_tokens': -1}}
"""关闭模型
client.terminate_model(model_uid=uid)注销自定义模型(❗️是注销,不是关闭)
model = client.unregister_model(model_type="<model_type>", model_name='my-glm-4-9b-chat')[^1]:LLM glm-4-9b-chat
{
"version": 1,
"context_length": 32000,
"model_name": "my-glm-4-9b-chat",
"model_lang": [
"en",
"zh"
],
"model_ability": [
"generate",
"chat"
],
"model_description": "glm-4-9b-chat",
"model_family": "glm4-chat",
"model_specs": [
{
"model_format": "pytorch",
"model_size_in_billions": 9,
"quantizations": [
"none"
],
"model_id": null,
"model_hub": "huggingface",
"model_uri": "/data1/MODEL_ROOT/ZhipuAI/glm-4-9b-chat/",
"model_revision": null
}
],
"prompt_style": {
"style_name": "CHATGLM3",
"system_prompt": "",
"roles": [
"user",
"assistant"
],
"intra_message_sep": "",
"inter_message_sep": "",
"stop": [
"<|endoftext|>",
"<|user|>",
"<|observation|>"
],
"stop_token_ids": [
151329,
151336,
151338
]
},
"is_builtin": false
}Llama3-Chinese-8B-Instruct
{
"version": 1,
"context_length": 16000,
"model_name": "Llama3-Chinese-8B-Instruct",
"model_lang": [
"en",
"zh"
],
"model_ability": [
"generate",
"chat"
],
"model_description": "This is a custom model description.",
"model_family": "llama-3-instruct",
"model_specs": [
{
"model_format": "pytorch",
"model_size_in_billions": 8,
"quantizations": [
"none"
],
"model_id": null,
"model_hub": "huggingface",
"model_uri": "/data1/MODEL_ROOT/Llama/Llama3-Chinese-8B-Instruct",
"model_revision": null
}
],
"prompt_style": {
"style_name": "LLAMA3",
"system_prompt": "You are a helpful assistant.",
"roles": [
"user",
"assistant"
],
"intra_message_sep": "\n\n",
"inter_message_sep": "<|eot_id|>",
"stop": [
"<|end_of_text|>",
"<|eot_id|>"
],
"stop_token_ids": [
128001,
128009
]
},
"is_builtin": false
}Qwen2-72B-Instruct-GPTQ-Int4
{
"version": 1,
"context_length": 16000,
"model_name": "Qwen2-72B-Instruct-GPTQ-Int4",
"model_lang": [
"en",
"zh"
],
"model_ability": [
"generate",
"chat"
],
"model_description": "💩,生成速度慢,效果差",
"model_family": "qwen2-instruct",
"model_specs": [
{
"model_format": "gptq",
"model_size_in_billions": 72,
"quantizations": [
"Int4"
],
"model_id": null,
"model_hub": "huggingface",
"model_uri": "/data1/MODEL_ROOT/qwen/Qwen2-72B-Instruct-GPTQ-Int4",
"model_revision": null
}
],
"prompt_style": {
"style_name": "QWEN",
"system_prompt": "You are a helpful assistant.",
"roles": [
"user",
"assistant"
],
"intra_message_sep": "\n",
"inter_message_sep": "",
"stop": [
"<|endoftext|>",
"<|im_start|>",
"<|im_end|>"
],
"stop_token_ids": [
151643,
151644,
151645
]
},
"is_builtin": false
}{
"model_name": "my-bge-large-zh-v1.5",
"model_id": null,
"model_revision": null,
"model_hub": "huggingface",
"dimensions": 1024,
"max_tokens": 512,
"language": [
"zh"
],
"model_uri": "/data1/MODEL_ROOT/embedding/bge-large-zh-v1.5/",
"is_builtin": false
}自用代码示例
暂时不支持一张卡上同时运行多个LLM 同一张卡上运行多个模型需要设置 gpu_idx
import json
import time
from xinference.client import Client
from config import config
from logger import logger
def register_and_start_model(config_path: str, client: Client, type: str, inference_engine='Transformers', **args):
try:
logger.info(f"注册自定义模型, 配置文件路径: {config_path}")
with open(config_path) as fd:
model = fd.read()
info = json.loads(model)
except FileNotFoundError:
logger.error(f"配置文件未找到: {config_path}")
return False
except json.JSONDecodeError as e:
logger.error(f"解析 JSON 失败, 错误信息: {e}")
return False
except Exception as e:
logger.error(f"读取配置文件时出错, 错误信息: {e}")
return False
try:
client.register_model(model_type=type, model=json.dumps(info, indent=4), persist=False)
model_name = info["model_name"]
model_format = info["model_specs"][0]["model_format"]
model_uid = info["model_specs"][0]["model_id"]
logger.info(f"注册自定义模型 {model_name} 完成")
except Exception as e:
logger.error(f"注册模型失败, 错误信息: {e}")
return False
try:
logger.info(f"自定义模型 {model_name} 启动中......")
client.launch_model(model_name=model_name, model_uid=model_uid, model_format=model_format, model_engine=inference_engine, gpu_idx=0, **args)
logger.info(f"自定义模型 {model_name} 已启动")
except Exception as e:
logger.error(f"启动模型失败, model_name={model_name}, 错误信息: {e}")
return False
return True
def close_model(client: Client, uid: str):
try:
logger.info(f"关闭模型, model_id={uid}")
client.terminate_model(model_uid=uid)
except Exception as e:
logger.error(f"关闭模型失败, model_id={uid}, 错误信息: {e}")
def unregister_model(client, name: str, type: str):
try:
logger.info(f"注销模型, model_name={name}")
client.unregister_model(model_type=type, model_name=name)
except Exception as e:
logger.error(f"注销模型失败, model_name={name}, 错误信息: {e}")
def get_model_with_retry(client, model_uid, max_attempts=5, retry_interval=10):
attempts = 0
while attempts < max_attempts:
try:
llm = client.get_model(model_uid=model_uid)
return llm # 如果成功获取模型,则直接返回
except Exception as e:
logger.error(f"第 {attempts + 1} 次获取模型 {model_uid} 出错: {e}")
attempts += 1
time.sleep(retry_interval) # 等待一段时间后重试
logger.error(f"尝试 {max_attempts} 次仍然无法获取模型 {model_uid}")
return None # 如果达到最大重试次数仍然失败,则返回 None 或者采取其他适当的处理
if __name__ == "__main__":
client = Client(config.XINFERENCE_URI)
close_model(client, 'glm-1')
unregister_model(client, 'glm-1', type='LLM')
register_and_start_model('json/glm-1.json', client, type='LLM')
llm = client.get_model(model_uid='glm-1')
response = llm.chat(
"你好",
generate_config={"max_tokens": 16000}
)
logger.debug(f'response:\n{response}')
# 获取 text
content = response['choices'][0]['message']['content']
logger.debug(content)OpenAI格式调用
client = openai.Client(api_key="not empty", base_url="http://localhost:9997/v1")
res = client.embeddings.create(model="my-bge-large-zh-v1.5", input=[input1, input2])
ebds = []
for e in res.data:
ebds.append(e.embedding)VLLM推理
在 vLLM 中,LLM 服务的性能受到内存的瓶颈。在自回归解码过程中,LLM 的所有输入标记都会生成其注意键和值张量,并且这些张量保存在 GPU 内存中以生成下一个标记。这些缓存的键和值张量通常称为 KV 缓存。这些缓存特别大,LLaMA-13B 中的单个序列最多占用 1.7GB。而且其大小取决于序列长度,序列长度变化很大且不可预测,vllm引入PagedAttention来有效管理KV缓存,这是一种受操作系统中虚拟内存和分页的经典思想启发的注意力算法。与传统的注意力算法不同,PagedAttention 允许在不连续的内存空间中存储连续的键和值。具体来说,PagedAttention 将每个序列的 KV 缓存划分为块,每个块包含固定数量令牌的键和值。
使用vllm推理最要设置参数,不然默认占用90%显存
"gpu_memory_utilization": 0.9,
"temperature": 0.2,
"top_p":0.95,
"max_tokens":16000,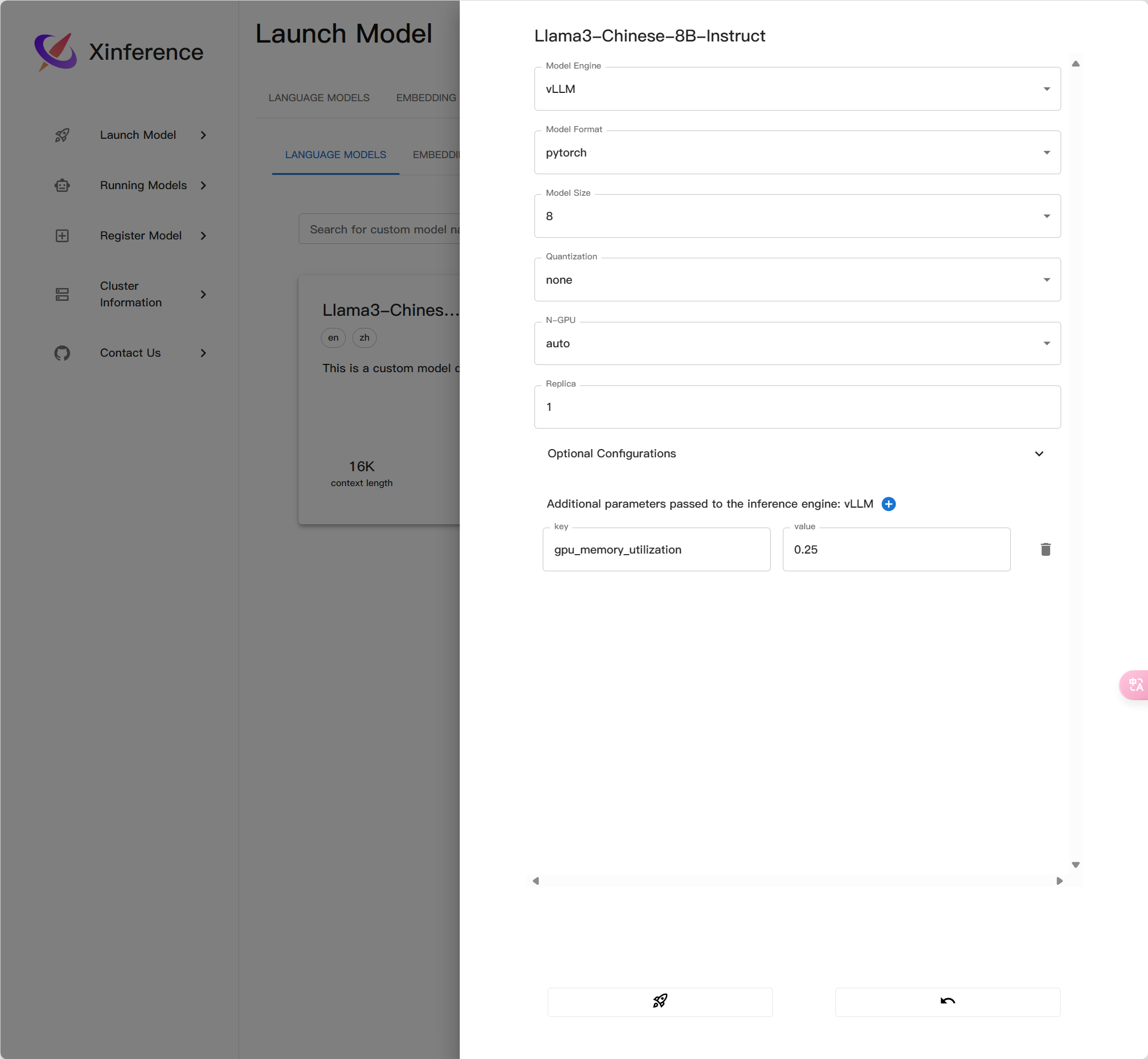
⚠️
- 需要gcc、g++
- llama 需要安装 flash-attn,可能会遇到build失败的情况,需要设置cuda的环境变量
- 加载量化模型需要安装 auto-gptq