
面试题
面试题整理



用友
ArrayList和LinkedList的区别?
ArrayList底层基于数组;LinkedList 底层基于双向链表
ArrayList 支持按下标随机查询,查询时间复杂度 O(1);LinkedList查询时间复杂度 O(n)
ArrayList 尾插不扩容 O1,扩容 On,其他位置插入 On;LinkedList头插尾插 O1,中间插入 On
ArrayList 删除平均 On,LinkedList 删除平均On
ArrayList 内存空间连续,占用小;LinkedList需要存储额外的指针,因此占用空间更大
具体应用场景:能不能结合它们的特性,分别举例说明在什么情况下你会优先选择 ArrayList,什么情况下优先选择 LinkedList?
迭代器 (Iterator) 的行为:在使用迭代器遍历并同时修改集合时(例如删除元素),ArrayList 和 LinkedList 的迭代器有什么不同的表现或注意事项 (fail-fast机制)?
HashMap的原理是什么,扩容?和CurrentHashMap的区别
- HashMap 底层基于数组+链表(1.7 之前),数组默认大小 16,扩容因子 0.75,每次扩容容量翻倍,put 时根据 key 的 hash 值映射到数组下标的对应位置,如果发生冲突则使用头插法向链表中插入
- 1.8 之后,HashMap底层基于数组+链表+红黑树,链表采用尾插法,在扩容时链表元素相对顺序不变,防止并发情况下链表成环,当链表长度大于 8 且数组长度大于 64 时,会将链表转换为红黑树,红黑树节点个数小于 6 会退化回链表
- CurrentHashMap是线程安全的HashMap,1.7 之前使用分段锁,把数组分成多个段,每段一个ReentrantLock锁,并发性能较低,1.8之后每个哈希桶的头节点使用 synchronized , 并发量更高,同时使用 ACS+synchronized,如果没有冲突则 ACS 进行 put,有冲突则换成重量级锁synchronized
volatile和synchronized的区别
都是 java 关键字
volatile 可以用在变量上,使得对该变量的修改对其他线程可见,同时还通过插入内存屏障防止指令重排,保证了可见性和有序性,不保证复合操作的原子性。本质上是一种轻量级的同步机制,不会造成线程阻塞, 告诉编译器该变量易变,阻止编译器对其进行某些类型的重排序和优化(如缓存到寄存器而不写回主存)
synchronized是锁,保证复合操作的原子性,具有可重入性,其原理是在对象头中的 Mark Word 存储了锁的状态信息(如无锁、偏向锁、轻量级锁、重量级锁的标志位)以及持有锁的线程ID(偏向锁时)或指向锁记录的指针(轻量级锁时)等
synchronized在 1.8 之后有优化,会有偏向锁、轻量级锁、自旋锁等操作,只有竞争激烈时才会升级为重量级锁
synchronized和ReentrantLock的区别
都是锁,都支持可重入,但是实现原理不一样
synchronized 依赖 JVM 和对象头,其原理是在对象头中的 Mark Word 存储了锁的状态信息(如无锁、偏向锁、轻量级锁、重量级锁的标志位)以及持有锁的线程ID(偏向锁时)或指向锁记录的指针(轻量级锁时)等
ReentrantLock基于 Java 并发包(JUC)中的 AQS (AbstractQueuedSynchronizer) 和 CAS (Compare-And-Swap),是Java 并发包中的一个类。AQS 内部维护了一个 FIFO 的等待队列,并通过 CAS 操作来原子地修改同步状态 (一个 int 类型的 state 变量,表示锁的持有次数或状态)
锁的获取与释放:
-
synchronized:代码块执行完毕或抛出异常后,JVM 会自动释放锁。使用简单,不易出错 -
ReentrantLock:需要手动调用 lock() 方法获取锁,并且必须在 finally 块中调用 unlock() 方法释放锁。如果忘记释放锁,可能会导致死锁
公平性:
-
synchronized:是一种非公平锁。线程获取锁的顺序是不确定的,新来的线程可能抢占等待时间较长的线程的锁 -
ReentrantLock:默认是非公平锁,但可以构造为公平锁。公平锁会按照线程请求锁的时间顺序来分配锁,但通常会带来一定的性能开销
尝试获取锁 (Try Lock):
-
synchronized:没有提供尝试获取锁的机制,线程会一直阻塞直到获取到锁 -
ReentrantLock:提供了tryLock() 方法。该方法会尝试获取锁,如果锁未被其他线程持有,则获取成功并返回true;否则立即返回false,线程不会阻塞。还有一个带超时时间的tryLock(long timeout, TimeUnit unit) 方法,允许线程在指定时间内尝试获取锁
条件变量 (Condition):
-
synchronized:与Object 类的wait(),notify(),notifyAll() 方法配合使用,实现线程间的等待/通知机制。这种机制与锁对象本身绑定,只有一个条件队列 -
ReentrantLock:可以配合Condition 接口使用。一个ReentrantLock 对象可以创建多个Condition 实例 (lock.newCondition()),从而可以实现更细粒度的线程分组唤醒,即可以有多个独立的等待/通知队列。这在实现复杂的线程协作场景时非常有用
性能:
- 在 JDK 1.5 及之前,
ReentrantLock 在高并发场景下通常比synchronized 有更好的性能 - 从 JDK 1.6 开始,JVM 对
synchronized 进行了大量的优化(如偏向锁、轻量级锁、自适应自旋等),使得两者在性能上的差距已经很小。在某些情况下(例如锁竞争不激烈时),synchronized 的性能甚至可能由于 JVM 级别的优化而更好 -
ReentrantLock 由于是 API 层面实现,其灵活性也可能带来一些额外的开销
对象创建的过程了解吗?
类加载 → 实例化 → 初始化 → 返回引用
Java 对象创建是一个多步骤过程,首先 JVM 会检查类是否已加载,如果未加载会通过类加载器加载类字节码。接着在堆中为对象分配内存,并将字段初始化为默认值。然后调用构造器方法,包括先调用父类构造器,再执行当前类构造器,初始化成员变量。最后将对象的引用返回并赋值给变量
类载入过程
加载 -> 链接 (验证、准备、解析) -> 初始化 (执行类的<clinit>()方法) -> 使用 -> 卸载
加载
通过类的全名,获取类的二进制数据流
解析类的二进制数据流为方法区内的数据结构(Java类模型)
创建java.lang.Class类的实例,表示该类型。作为方法区,此类的各种数据提供访问入口
验证
验证类是否符合JVM规范,安全性检查
- 文件格式验证
- 元数据验证
- 字节码验证
格式检查,如:文件格式是否错误、语法是否错误、字节码是否合规
- 符号引用验证 Class 文件在其常量池会通过字符串记录自己将要使用的其他类或者方法,检查它们是否存在
准备
为类变量分配内存并设置其初始值:
-
static 变量,其空间分配在准备阶段完成(设置默认值) ,赋值操作则在初始化阶段完成 - 当
static 变量是基本类型且为final,或为字符串常量时,其值已确定,赋值操作在准备阶段完成 - 若
static 变量是final 的引用类型,赋值操作同样会在初始化阶段完成
解析
将类中符号引用转换为直接引用
例如:方法内调用其他方法时,方法名可视为符号引用;而直接引用则是通过指针直接指向方法
初始化
对类的静态变量与静态代码块执行初始化操作
若在初始化一个类时,其父类尚未完成初始化,则系统将优先初始化其父类
若一个类中同时包含多个静态变量和静态代码块,这些代码将按照自上而下的顺序依次执行
谈谈自己对于Spring IoC的了解
控制反转,将对象的创建方式由 new 改为由 Spring 容器进行统一管理,起到了解耦的作用
好处
解耦 (Decoupling) :
- 对象不再直接依赖于具体的实现类,而是依赖于接口或抽象
- 当依赖的实现发生变化时,只需要修改容器的配置,而不需要修改使用该依赖的类的代码
- 这使得系统更加模块化,易于维护、测试和扩展
方便管理对象生命周期:Spring 容器可以管理 Bean 的整个生命周期,从创建到销毁,包括执行初始化方法和销毁方法
易于集成各种服务:例如,通过 IoC 可以方便地集成事务管理、AOP(面向切面编程)、数据访问等 Spring 提供的功能或第三方库
提高可测试性:由于依赖关系是通过注入的方式提供的,所以在单元测试时,可以方便地替换掉真实的依赖,使用 Mock 对象进行测试
代码更简洁:减少了创建和管理依赖对象的样板代码
如何实现/ 核心组件
IoC 容器 (IoC Container) :是 Spring 框架的核心。它负责创建对象,配置对象,装配对象之间的依赖关系,并管理它们的整个生命周期
BeanDefinition:容器内部使用
BeanDefinition 对象来描述需要创建和管理的 Bean(对象)的元数据,例如 Bean 的类名、作用域、构造函数参数、属性值、依赖关系、初始化方法、销毁方法等。这些元数据可以来自 XML 配置文件、Java注解或Java配置类BeanFactory 和 ApplicationContext:
BeanFactory:是 IoC 容器的基础接口,提供了最核心的 IoC 功能,采用延迟加载 (Lazy Loading) 的方式,即只有当getBean() 被调用时,对应的 Bean 才会被实例化
ApplicationContext:是BeanFactory 的子接口,提供了更多企业级的功能,例如国际化处理、事件发布、AOP集成、Web环境支持等。它通常采用预加载 (Eager Loading) 的方式,即容器启动时就会实例化所有单例 Bean。在绝大多数应用中,我们使用的是ApplicationContext- 常见的
ApplicationContext 实现类有:ClassPathXmlApplicationContext (从类路径加载XML配置),FileSystemXmlApplicationContext (从文件系统加载XML配置),AnnotationConfigApplicationContext (基于Java注解的配置)
- 常见的
依赖注入 (Dependency Injection - DI)
DI 是实现 IoC 的一种具体方式。容器负责将被依赖的对象(依赖项)注入到依赖该对象的 Bean 中
Spring 支持多种 DI 方式:
- 构造器注入 (Constructor Injection) :通过类的构造函数参数来注入依赖。这种方式可以保证 Bean 在实例化后其依赖就已经是可用的,并且可以清晰地表达强制依赖
- Setter 方法注入 (Setter Injection) :通过类中对应属性的 Setter 方法来注入依赖。这种方式更灵活,适用于可选依赖
- 字段注入 (Field Injection) :通过在字段上使用
@Autowired 等注解直接注入。代码简洁,但可能降低可测试性(因为难以在不使用反射的情况下手动设置依赖)和违反单一职责原则
Bean 的作用域 (Scope)
-
singleton (单例):默认作用域。在整个容器中,该 Bean 只会创建一个实例 -
prototype (原型):每次请求(例如通过getBean() 调用)时都会创建一个新的 Bean 实例 -
request (请求):在一个 HTTP 请求的生命周期内,该 Bean 只会创建一个实例。(仅适用于 Web 应用) -
session (会话):在一个 HTTP 会话的生命周期内,该 Bean 只会创建一个实例。(仅适用于 Web 应用) -
application (应用):在一个 ServletContext 的生命周期内,该 Bean 只会创建一个实例。(仅适用于 Web 应用) -
websocket (WebSocket):在一个 WebSocket 的生命周期内,该 Bean 只会创建一个实例。(仅适用于 Web 应用)
Spring AOP了解吗
面向切面编程,可以在不侵入现有代码的情况下,实现功能的增强
实现原理是通过动态代理,通过切面、切入点和通知配合,对功能进行增强,比如自动开启和关闭事务
核心概念(术语)
- 切面 (Aspect) :它是一个模块,封装了对特定横切关注点(cross-cutting concern,如日志、事务管理)的建议(通知)和切入点定义。通常由一个包含通知方法的普通 Java 类(用
@Aspect 注解标记)来实现 - 连接点 (Join Point) :程序执行过程中的特定点,例如方法的调用、异常的抛出等。在 Spring AOP 中,连接点总是表示方法的执行
- 通知 (Advice) :切面在特定的连接点上执行的动作。它是实际增强功能的代码
- 切入点 (Pointcut) :用于定义哪些连接点会被通知所应用。切入点表达式(如 AspectJ pointcut expression)用于匹配感兴趣的方法执行。它决定了通知将在何处执行
- 目标对象 (Target Object) :被一个或多个切面所通知的对象。也称为被代理对象
- AOP 代理 (AOP Proxy) :AOP 框架创建的对象,用于实现切面契约(包括通知方法的调用等)。在 Spring AOP 中,代理可以是 JDK 动态代理或 CGLIB 代理。这个代理对象包含了原始目标对象的功能,并增加了切面定义的增强逻辑
- 织入 (Weaving) :把切面连接到其它的应用程序类型或者对象上,并创建一个被通知的对象(代理对象)的过程。织入可以在编译时(例如使用 AspectJ 编译器)、类加载时或运行时完成。Spring AOP 是在运行时进行织入的
实现原理
Spring AOP 的核心实现机制是动态代理 (Dynamic Proxy)
- 如果目标对象实现了至少一个接口,Spring AOP 默认使用 JDK 动态代理来创建代理对象。这个代理对象实现了与目标对象相同的接口
- 如果目标对象没有实现任何接口,Spring AOP 会使用 CGLIB 库来创建目标对象的子类作为代理对象
当客户端调用代理对象的方法时,代理对象会在调用目标对象的实际方法之前或之后(或环绕),执行切面中定义的通知逻辑
应用场景/优势
- 解耦:将横切关注点(如日志、事务、安全)从核心业务逻辑中分离出来,使业务代码更纯粹、更关注自身职责
- 代码复用:相同的横切逻辑可以被统一定义在切面中,并应用到多个模块,避免了代码重复
- 可维护性增强:修改或增加横切功能时,只需要修改对应的切面,而不需要改动大量的业务代码
- 典型的应用场景:事务管理|日志记录安全控制|性能监控|缓存|异常处理
SpringBoot 有哪些热部署方法
热部署就是当你修改了代码或配置文件后,不需要手动停止再重新启动整个应用程序,应用服务器能够自动加载这些更改,让你立即看到效果
Spring Boot DevTools (spring-boot-devtools)
这是 Spring Boot 官方推荐且最常用的热部署方案
原理:
spring-boot-devtools 模块在检测到 classpath 下的文件发生变化(例如.class 文件被重新编译,或配置文件被修改)时,会自动重新启动应用程序为了加快重启速度,DevTools 使用了两个类加载器 (ClassLoader):
- Base ClassLoader:加载那些不经常改变的第三方库 (JARs)
- Restart ClassLoader:加载你项目中的代码 (
src/main/java,src/main/resources 等) - 当重启时,Base ClassLoader 不会动,只有 Restart ClassLoader 会被丢弃并重新创建一个新的,加载修改后的代码。这样就避免了重新加载所有类库,从而大大缩短了重启时间
它还默认禁用了一些缓存(如 Thymeleaf、Freemarker、Groovy Templates 的模板缓存),以便修改后能立即生效
IDE 的热部署/热替换功能
- 一些现代的 Java IDE(如 IntelliJ IDEA Ultimate 版、Eclipse)本身也提供了一定的热替换 (HotSwap) 功能
- HotSwap 通常允许你在 Debug 模式下修改方法体内部的代码,并立即生效,但对于方法签名、类结构的修改支持有限
- 当配合
spring-boot-devtools 使用时,IDE 的自动编译功能会触发 DevTools 的重启机制
AOP 常见的通知类型
- 前置通知 (@Before) :在目标方法(连接点)执行之前执行的通知。不能阻止目标方法的执行,除非它抛出异常
- 后置返回通知 (@AfterReturning) :在目标方法正常执行完毕并返回结果之后执行的通知。可以访问到目标方法的返回值
- 异常通知 (@AfterThrowing) :在目标方法执行过程中抛出异常后执行的通知。可以访问到抛出的异常信息
- 最终通知 (@After 或称为后置通知) :无论目标方法是否成功执行(即无论是正常返回还是抛出异常),都会在其后执行的通知。类似于
try-catch-finally 中的finally 块 - 环绕通知 (@Around) :功能最强大的通知类型。它可以包围一个目标方法(连接点)的执行。可以在目标方法调用前后自定义行为,并且可以决定是否执行目标方法、修改返回值、或者抛出异常。环绕通知需要负责调用
ProceedingJoinPoint.proceed() 来执行目标方法
事务的隔离级别
读未提交 (Read Uncommitted)
描述:一个事务可以读取到其他事务尚未提交的数据(脏数据)
可能出现的问题:
- 脏读 (Dirty Read) :一个事务读取了另一个事务未提交的数据。如果那个事务最终回滚,那么第一个事务读取到的就是无效数据
读已提交 (Read Committed)
描述:一个事务只能读取到其他事务已经提交的数据。换句话说,它不会读取到“脏数据”
解决的问题:避免了脏读
可能出现的问题:
- 不可重复读 (Non-Repeatable Read) :在一个事务内,多次读取同一行数据,但由于其他并发事务的修改和提交,导致每次读取到的数据可能不一样
- 幻读 (Phantom Read) :在一个事务内,多次执行同样的范围查询,但由于其他并发事务的插入或删除操作并提交,导致后续查询返回了之前查询中未出现的“幻影”行
特点:这是大多数主流数据库(如 Oracle、SQL Server、PostgreSQL)的默认隔离级别
可重复读 (Repeatable Read)
描述:确保在一个事务内,多次读取同一行数据时,结果总是一致的。事务开始时会创建一个数据快照,后续的读取操作都基于这个快照
解决的问题:避免了脏读和不可重复读
可能出现的问题:
- 幻读 (Phantom Read) :虽然行级别的数据不会变,但在某些数据库实现中(非所有,例如 MySQL InnoDB 通过 Next-Key Locking 在一定程度上解决了幻读),范围查询仍然可能出现幻读,即其他事务插入了符合查询条件的新行并提交,导致后续查询结果集变大
特点:这是 MySQL InnoDB 存储引擎的默认隔离级别
可串行化 (Serializable)
- 描述:最高的隔离级别。强制事务串行执行,即一个事务完全执行完毕后,另一个事务才能开始。这通常通过对读取和写入的数据都加锁来实现
- 解决的问题:避免了脏读、不可重复读和幻读。保证了最高的数据一致性
| 隔离级别 | 脏读 (Dirty Read) | 不可重复读 (Non-Repeatable Read) | 幻读 (Phantom Read) |
|---|---|---|---|
| 读未提交 | ✔️ (可能) | ✔️ (可能) | ✔️ (可能) |
| 读已提交 | ❌ (避免) | ✔️ (可能) | ✔️ (可能) |
| 可重复读 | ❌ (避免) | ❌ (避免) | ✔️ (可能) |
| 可串行化 | ❌ (避免) | ❌ (避免) | ❌ (避免) |
慢查询优化
可以开启 mysql 的慢查询日志等方法获取到慢执行的 sql
使用 explain 对这条 sql 进行解释,看看是否使用了索引,索引是否失效,是否进行了回表查询
然后进行对应的优化
1. 问题发现与定位
- 开启慢查询日志:设置
slow_query_log=1 和long_query_time - 使用性能监控工具:如 pt-query-digest 分析日志,找出执行频率高、耗时长的SQL
- 实时监控:通过
SHOW PROCESSLIST 查看当前执行的慢查询
2. 问题分析
使用 EXPLAIN 分析执行计划,重点关注:
- type:连接类型,理想情况是 const > eq_ref > ref > range,避免 ALL(全表扫描)
- key:实际使用的索引
- rows:扫描的行数,越少越好
- Extra:额外信息,注意 "Using filesort"、"Using temporary" 等
3. 具体优化策略
索引优化
- 添加缺失的索引:根据 WHERE、ORDER BY、GROUP BY 条件创建合适索引
- 复合索引优化:遵循最左前缀原则,将区分度高的字段放前面
- 删除冗余索引:清理不必要的重复索引
SQL语句优化
- 避免 SELECT ***** :只查询需要的字段
- 优化 WHERE 条件:避免在索引列上使用函数、类型转换
- 分解复杂查询:将复杂的JOIN拆分为多个简单查询
- 使用 LIMIT:对大结果集进行分页
表结构优化
- 字段类型选择:使用合适的数据类型,避免过大的字段
- 表分区:对超大表进行水平分区
- 读写分离:将查询分散到从库
4. 系统层面优化
- 配置参数调优:调整
innodb_buffer_pool_size、query_cache_size 等 - 硬件升级:增加内存、使用SSD
- 应用层优化:增加缓存(Redis)、批量操作
5. 监控与预防
- 建立监控体系:定期检查慢查询日志
- 设置告警机制:超过阈值及时通知
- 代码审查:SQL上线前进行性能测试
三范式是什么,如何连接两个表
| student_id | student_name | student_info | course_id | course_name | teacher_name | teacher_phone | score |
|---|---|---|---|---|---|---|---|
| 1001 | 张三 | 计算机系,20岁 | 101 | 数据库 | 李老师 | 13800138000 | 85 |
| 1001 | 张三 | 计算机系,20岁 | 102 | 操作系统 | 王老师 | 13900139000 | 92 |
| 1002 | 李四 | 电子系,21岁 | 101 | 数据库 | 李老师 | 13800138000 | 78 |
1️⃣ 字段值必须是原子的,不可再分。student_info 字段包含多个信息,不是原子的
2️⃣ 非主键字段完全依赖于主键,不能存在部分依赖(针对复合主键)
- 复合主键:
(student_id, course_id) -
student_name, department, age 只依赖于student_id(部分依赖) -
course_name 只依赖于course_id(部分依赖) -
teacher_name, teacher_phone 只依赖于course_id(部分依赖)
分表
-- 学生表
CREATE TABLE students (
student_id INT PRIMARY KEY,
student_name VARCHAR(50),
department VARCHAR(50),
age INT
);
-- 课程表
CREATE TABLE courses (
course_id INT PRIMARY KEY,
course_name VARCHAR(50),
teacher_name VARCHAR(50),
teacher_phone VARCHAR(20)
);
-- 选课表
CREATE TABLE enrollments (
student_id INT,
course_id INT,
score INT,
PRIMARY KEY (student_id, course_id),
FOREIGN KEY (student_id) REFERENCES students(student_id),
FOREIGN KEY (course_id) REFERENCES courses(course_id)
);3️⃣ 非主键字段不能传递依赖于主键
在 courses 表中:
-
course_id →teacher_name →teacher_phone -
teacher_phone 传递依赖于course_id
连接两个表
-- 内连接
SELECT * FROM table1 INNER JOIN table2 ON table1.id = table2.table1_id;
-- 左连接
SELECT * FROM table1 LEFT JOIN table2 ON table1.id = table2.table1_id;
-- 右连接
SELECT * FROM table1 RIGHT JOIN table2 ON table1.id = table2.table1_id;
-- 全外连接
SELECT * FROM table1 FULL OUTER JOIN table2 ON table1.id = table2.table1_id;
单例设计模式有哪些
确保一个类只有一个实例,并提供全局访问点
饿汉式(推荐)
public class Singleton {
private static final Singleton INSTANCE = new Singleton();
private Singleton() {}
public static Singleton getInstance() {
return INSTANCE;
}
}优点:线程安全,简单 缺点:类加载时就创建,可能浪费内存
懒汉式(线程不安全)
public class Singleton {
private static Singleton instance;
private Singleton() {}
public static Singleton getInstance() {
if (instance == null) {
instance = new Singleton();
}
return instance;
}
}问题:多线程环境下不安全
懒汉式(同步方法)
public class Singleton {
private static Singleton instance;
private Singleton() {}
public static synchronized Singleton getInstance() {
if (instance == null) {
instance = new Singleton();
}
return instance;
}
}优点:线程安全 缺点:性能差,每次都要同步
双重检查锁(DCL)
public class Singleton {
private static volatile Singleton instance;
private Singleton() {}
public static Singleton getInstance() {
if (instance == null) {
synchronized (Singleton.class) {
if (instance == null) {
instance = new Singleton();
}
}
}
return instance;
}
}优点:线程安全,性能好 注意:必须使用 volatile 关键字
双重检查锁中volatile什么作用
使变量的修改对其他线程也可见,保证可见性
防止指令重排序,保证有序性
在双重检查锁中,volatile 防止了返回未完全初始化对象的致命问题
保证可见性
// 线程A执行
instance = new Singleton(); // 修改对线程B立即可见
// 线程B执行
if (instance == null) // 能看到线程A的修改防止指令重排序
// instance = new Singleton() 的执行步骤:
1. 分配内存空间
2. 初始化对象
3. 将instance指向内存地址问题场景演示
// 没有volatile的情况下:
Thread A: 执行到 instance = new Singleton()
1. 分配内存 ✓
2. instance指向内存 ✓ (重排序)
3. 初始化对象 ❌ (还没执行)
Thread B: if (instance == null) // false!
return instance; // 返回未初始化的对象!
JVM的内存模型
程序计数器(PC Register) 记录当前线程执行的字节码指令地址,线程私有,唯一不会OOM的区域
堆内存(Heap)
├── 年轻代(Young Generation)
│ ├── Eden区
│ ├── Survivor0区(From)
│ └── Survivor1区(To)
└── 老年代(Old Generation)
虚拟机栈(VM Stack)
- 作用:存储方法调用的栈帧(局部变量、操作数栈、方法出口等)
- 特点:线程私有,LIFO结构
- 异常:StackOverflowError、OutOfMemoryError
本地方法栈(Native Method Stack) 为Native方法(C/C++)服务
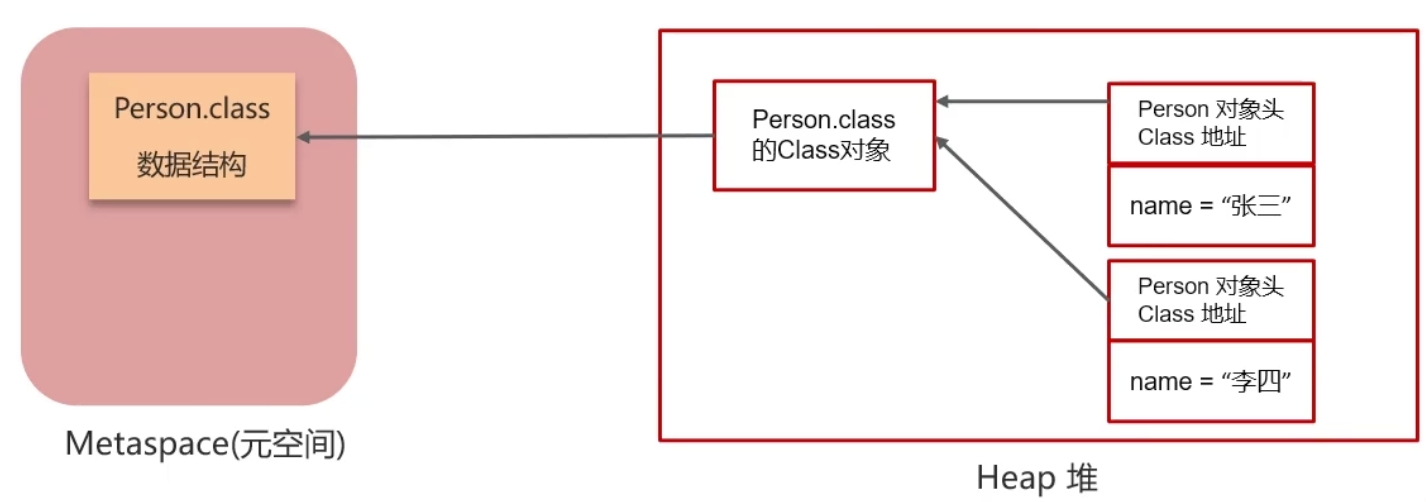
方法区/元空间(Method Area/Metaspace)
作用:存储类信息、常量池、静态变量
JDK8前:永久代(PermGen)
JDK8后:元空间(Metaspace,使用本地内存)
直接内存(Direct Memory)
- 作用:NIO操作、堆外缓存
- 特点:不属于JVM管理,但受总内存限制
JDK 1.8后,在内存模型方面的变化
JVM堆内存
├── 年轻代
├── 老年代
└── 永久代(PermGen)
├── 类元数据
├── 常量池
└── 静态变量JVM堆内存
├── 年轻代
└── 老年代
本地内存
└── 元空间(Metaspace)
└── 类元数据
堆内存
└── 常量池、静态变量(移到堆中)方法区从永久代移动到了元空间,使用本地内存,可存储的类信息等更多
永久代的问题:
- 固定大小限制:容易出现
OutOfMemoryError: PermGen space - GC效率低:永久代回收困难
- 内存碎片:长期运行后碎片严重
元空间的优势:
- 动态扩展:受本地内存限制,不再有固定上限
- 减少OOM:不再频繁出现永久代溢出
- GC优化:简化垃圾回收逻辑
JVM的线程都有哪些状态?
新建(new)线程刚创建还未 start
可运行(runnable:{ready、running})调用 start,可能正在运行,也可能在等待CPU时间片
阻塞(blocked)线程等待获取synchronized锁
等待(waiting)Object.wait(); Thread.join(); LockSupport.park();
限时等待(timed waiting)Thread.sleep(1000); Object.wait(1000); Thread.join(1000); LockSupport.parkNanos();
终止(terminated)
Java中的线程的sleep和wait的区别是什么?在占用CPU时间和锁方面都有哪些操作?
sleep 是线程类的静态方法,可以随时调用;wait是Object类的实例方法,只有对象才能调用,而且必须在synchronized块中才能调用
sleep 调用后不会释放锁;wait 会释放锁
sleep 调用后会释放当前 cpu 的执行权,wait 也会,但是 sleep 时间结束后就会自动获取时间片继续运行,但是 wait 需要等待其他线程调用同一个对象的 notify/notifyall 才能被唤醒去争抢锁
给你一个JDK的线程快照,请给出方法分析出来可能有问题的线程?比如某个线程在阻塞
分析方法及工具
手动
# 1. 统计各状态线程数量
grep "java.lang.Thread.State:" threaddump.txt | sort | uniq -c
# 2. 查找BLOCKED线程
grep -A 10 "BLOCKED" threaddump.txt
# 3. 查找等待同一锁的线程
grep -B 2 -A 5 "waiting to lock" threaddump.txt工具
- Eclipse MAT:内存和线程分析
- VisualVM:图形化分析
- FastThread.io:在线线程分析
- IBM Thread and Monitor Dump Analyzer
🔍 需要重点关注的状态:
| 状态 | 说明 | 潜在问题 |
|---|---|---|
| BLOCKED | 等待获取synchronized锁 | 🚨 可能有锁竞争 |
| WAITING | 无限期等待 | ⚠️ 可能等待通知 |
| TIMED_WAITING | 限时等待 | ℹ️ 通常是sleep或定时等待 |
| RUNNABLE | 运行或等待CPU | ✅ 正常状态 |
🚨 高风险信号:
1. 大量BLOCKED线程:
"Thread-1" #10 prio=5 os_prio=0 tid=0x... nid=0x... waiting for monitor entry
java.lang.Thread.State: BLOCKED (on object monitor)
at com.example.Service.syncMethod(Service.java:25)
- waiting to lock <0x000000076ab62208> (a java.lang.Object)🔍 分析: 多个线程在等待同一个锁,可能有死锁或锁竞争激烈
2. 长时间WAITING的线程:
"pool-1-thread-1" #15 prio=5 os_prio=0 tid=0x... nid=0x... waiting on condition
java.lang.Thread.State: WAITING (parking)
at sun.misc.Unsafe.park(Native Method)
at java.util.concurrent.locks.LockSupport.park(LockSupport.java:175)🔍 分析: 线程可能在等待某个条件,需要查看业务逻辑
3. 死锁检测:
Found Java-level deadlock:
=============================
"Thread-1":
waiting to lock monitor 0x... (object 0x..., a java.lang.Object),
which is held by "Thread-2"
"Thread-2":
waiting to lock monitor 0x... (object 0x..., a java.lang.Object),
which is held by "Thread-1"
mysql的存储引擎都有哪些?
InnoDB、Myisam、Memory
InnoDB 底层使用 B+ 树作为数据结构(聚簇索引),支持 ACID 事务,支持行级锁 + 表级锁,并发读写性能优秀,支持外键约束,自动崩溃恢复
Myisam 底层也使用B+ 树(非聚簇索引),只支持表级锁,不支持事务,读性能优秀,崩溃需要手动修复
Memory 底层Hash索引(默认)或B-Tree索引,使用内存存储,表级锁,性能优秀,但是不支持持久化
mysql的innodb的底层数据结构是怎样的?
B+树,只有叶节点存储数据,叶节点之间还通过双向链表连接,可以方便的访问周围的节点,对于范围查询、分页查询等帮助很大
B+树输入矮胖类型的树形结构,千万数据只有 3~4 层,对于 MySQL 来说,可以减少磁盘 IO 的次数,提升性能
具体说下聚簇索引和辅助索引的区别?Innodb的一个联合索引和一个单字段的索引,他们分别是聚簇索引或者辅助索引中的哪一种?为什么?
聚簇索引在叶节点保存了一条完整的包含所有字段的数据,而辅助索引在叶节点只保存了主键和索引列,需要回表查询才能获得其他字段的信息
聚簇索引每个表只能有一个,数据必须唯一且非空,辅助索引可以有多个
联合索引是辅助索引,因为只有主键的索引才是聚簇索引;单字段的索引如果是主键字段是聚簇索引,其他单字段索引还是辅助索引
搜狐畅游
创建对象有几种方式?
Java的集合类有哪些?用过哪些?
string,stringbuffer,stringbuilder区别
Java 的乐观锁和悲观锁
说一下 Java 反射
HashMap 和 TreeMap 有哪些区别?
你有部署过你这些项目吗?那部署的时候有没有关注过 JVM 一些参数上的调优?
SpringBoot 常用注解有哪些?
UNION 和 UNION ALL 的区别?
从前端到后端再到数据库,有一张表,表存在上百万条数据,从这三个层面,去做一个查询方面的优化
说一下 Linux 系统查询进程的命令
北京博纳讯动科技

一、云原生及容器化技术 (Docker/Kubernetes)
请您谈谈对云原生的理解,以及它为什么对AI平台的构建如此重要?
- 回答示例: “我理解的云原生是一套思想理念和技术方法的集合,它的核心目标是让应用在云环境中能够更好地构建、部署和管理。它强调微服务、容器化、DevOps、持续交付这些实践。对于AI平台来说,云原生至关重要。首先,AI模型通常计算密集,需要弹性伸缩能力,Kubernetes这样的容器编排工具能很好地满足这一点。其次,AI平台的组件多,比如数据预处理、模型训练、模型推理服务、监控等,微服务化能让各组件独立开发和迭代。再者,AI模型的迭代速度快,云原生的CI/CD流程能加速模型的上线和更新。总的来说,云原生能为AI平台带来弹性、敏捷性和高可用性。”
您是如何利用容器化技术优化AI模型训练和推理流程的?
- 回答示例: “容器化技术对AI模型训练和推理流程的优化体现在多个方面。对于训练,Docker可以打包训练环境所需的所有依赖库和框架(如TensorFlow, PyTorch特定版本),确保环境的一致性和可复现性,避免了在不同机器上配置环境的麻烦。结合Kubernetes,我们可以方便地调度分布式训练任务,动态分配GPU等资源。对于推理,将模型打包成Docker镜像后,可以快速部署为API服务。通过Kubernetes进行管理,可以轻松实现模型的版本控制、灰度发布、弹性伸缩,确保推理服务的高可用和高性能。”
请谈谈您对云原生AI平台开发与优化的经验和思路。
- 回答示例: “在开发云原生AI平台时,我的思路是首先进行合理的微服务拆分,比如数据接入、特征工程、模型训练、模型管理、推理服务、监控告警等模块。每个模块都容器化,并通过Kubernetes进行编排。在优化方面,我会关注:1. 资源利用率:通过合理的request/limit设置,以及HPA和Cluster Autoscaler来提高GPU等昂贵资源的利用率。2. 训练/推理效率:针对模型特点选择合适的分布式训练策略(数据并行/模型并行),优化数据加载,使用更高效的推理引擎(如TensorRT, ONNX Runtime)。3. 运维效率:建立完善的CI/CD流水线,实现模型的快速迭代和部署;构建全面的监控体系,覆盖基础设施、Kubernetes集群和AI应用本身,例如使用Prometheus、Grafana、ELK等。4. 成本优化:例如使用Spot实例进行离线训练任务,选择合适的存储方案等。”
二、AI大模型 (LLM) 及相关技术栈 (PyTorch, Transformers, LangChain)
请介绍一下您对大语言模型(LLM)的理解。您认为LLM在当前的AI领域有哪些重要的应用场景?
- 回答示例: “我理解的LLM是基于海量文本数据训练的、参数量巨大的深度学习模型,它们通常采用Transformer架构。LLM的核心能力在于理解和生成自然语言。在AI领域,LLM的应用场景非常广泛,比如智能客服、内容创作(写文章、代码)、机器翻译、情感分析、问答系统、以及作为更复杂应用的AI Agent的核心大脑等。它们极大地提升了机器与人自然交互的能力。”
您在哪些项目中接触或使用过PyTorch、Transformers或LangChain?请具体描述一下您在项目中的角色和贡献。
- 回答示例: “在我之前的一个项目中,我们开发了一个基于LLM的智能问答系统。我主要负责后端服务的开发和模型集成。在这个项目中,我们使用了预训练的Transformer模型(比如BERT的某个变种)作为基础,并使用PyTorch框架对其进行微调以适应我们的特定领域数据。我的贡献包括:数据预处理、模型微调脚本的编写和调试、将微调后的模型封装成API服务。我们也初步探索了LangChain来构建更复杂的问答逻辑链,比如结合外部知识库进行检索增强生成(RAG)。”
在进行大模型训练或推理时,您遇到过哪些挑战?是如何解决的?
- 回答示例: “在LLM方面,我主要接触的是模型微调和推理部署。挑战主要有:1. 资源消耗大:微调时,即使是中等规模的模型也需要较多的显存和计算时间。推理时,为了保证低延迟和高吞吐,也需要优化。我们的解决方式是,微调时采用梯度累积、混合精度训练等技术,并选择合适的GPU实例。推理时,进行模型量化(比如INT8)、算子融合,并使用像TensorRT这样的推理优化库。2. “幻觉”问题:LLM有时会生成看似合理但不符合事实的答案。我们通过引入RAG(检索增强生成)机制,让模型在回答前先从可信的知识库中检索相关信息,来缓解这个问题。”
请谈谈大模型(LLM)与云原生技术结合的可能场景和优势。
- 回答示例: “LLM与云原生技术的结合非常有前景。场景上,比如构建可弹性伸缩的LLM推理服务API,通过Kubernetes管理LLM应用的生命周期,包括模型的版本管理、A/B测试、自动扩缩容。优势在于:云原生提供了LLM应用所需的弹性、可靠性和运维效率。例如,LLM推理对资源需求波动大,Kubernetes的HPA可以动态调整实例数。模型的迭代和部署可以通过CI/CD流程自动化。同时,云原生的监控和日志系统也能帮助我们更好地管理和维护LLM应用。”
您在模型部署、监控和自动化运维方面有哪些经验?
- 回答示例: “在模型部署方面,我主要经验是将PyTorch或TensorFlow训练好的模型转换为ONNX格式,然后使用如TensorRT或ONNX Runtime进行优化和部署为API服务,通常会用Flask/FastAPI(Python)或Spring Boot(Java)包装。服务会容器化并通过Kubernetes管理。监控方面,我们会采集模型的QPS、延迟、错误率等指标,以及GPU利用率、显存占用等资源指标,通常使用Prometheus收集,Grafana展示。自动化运维主要是通过CI/CD流水线(如Jenkins, GitLab CI)实现代码提交后自动构建镜像、测试、部署到预发和生产环境。”
您是否有过大模型训练或部署经验?如果有,请分享一下。
- 回答示例: “我主要经验在于大模型的微调和部署。例如,在一个项目中,我们基于一个开源的预训练LLM(比如LLaMA系列的某个模型),使用我们自己业务场景的数据进行微调,以提升它在特定任务上的表现。微调过程是在多GPU服务器上使用PyTorch的分布式训练完成的。部署时,我们会将微调后的模型进行量化和优化,然后封装成Docker镜像,通过Kubernetes部署为在线推理服务,并配置了监控和告警。”
三、编程语言 (Go/Java/Python)
(针对Go/Java)请描述一个您使用Go或Java设计、开发和优化业务系统的项目经验,重点说明您是如何确保系统稳定性和高性能的。
- 回答示例 (Java): “我曾参与一个电商系统的订单处理模块开发,使用的是Java和Spring Boot。为保证稳定性,我们采用了分布式事务方案(如Seata或基于消息队列的最终一致性方案),对数据库操作和外部服务调用都做了容错处理和限流。为保证高性能,我们对热点商品的库存查询做了多级缓存(本地缓存Caffeine + 分布式缓存Redis),数据库层面做了分库分表和SQL优化,并使用了线程池来异步处理非核心逻辑,例如发送通知短信。”
(针对Python)Python在AI领域的优势是什么?您在项目中主要使用Python来完成哪些任务?
- 回答示例: “Python在AI领域的优势非常明显:首先,它有非常庞大和成熟的生态系统,像NumPy, Pandas, Scikit-learn, TensorFlow, PyTorch这些核心库都提供了Python接口,极大方便了开发。其次,Python语法简洁易学,开发效率高,非常适合快速原型验证和算法实现。在项目中,我主要使用Python进行数据清洗和预处理、模型训练和评估、以及使用Flask/FastAPI快速搭建模型API服务。”
请谈谈您对至少一门编程语言(Go/Java/Python)的深入理解,例如内存管理、并发处理、性能优化等方面。
- 回答示例 (Go): “以Go为例,我对它的内存管理有一些理解。Go有自己的垃圾回收器(GC),从1.5版本开始引入了并发GC,不断优化以降低STW(Stop-The-World)的时间。我知道Go的内存分配器是基于TCMalloc的思想,有mspan, mcache, mcentral等组件来高效管理内存。在并发处理方面,Goroutine和Channel是其核心,CSP并发模型使得编写并发程序相对简单和安全。性能优化方面,Go提供了pprof工具,可以方便地进行CPU和内存的性能分析,定位瓶颈,例如通过火焰图分析函数调用栈和耗时。”
您在实际项目中是如何进行代码优化和性能调优的?
- 回答示例: “代码优化和性能调优通常遵循一个流程:首先,明确性能瓶颈,不能凭感觉优化,我会使用性能分析工具(如Java的JProfiler/VisualVM,Go的pprof,Python的cProfile)来定位热点代码。其次,针对瓶颈进行优化,常见的手段有:算法优化(选择更高效的算法或数据结构),减少不必要的计算或IO操作,利用缓存(本地缓存或分布式缓存),并发处理(多线程或异步),以及针对语言特性的优化(比如Java的JIT编译,Go的逃逸分析)。优化后,会再次进行性能测试,确保达到预期目标,并注意避免过度优化。”
四、分布式系统、微服务及消息队列
请解释一下您对分布式系统基本概念的理解,例如CAP理论、BASE理论。
- 回答示例: “CAP理论指出,一个分布式系统不可能同时满足一致性(Consistency)、可用性(Availability)和分区容错性(Partition tolerance)这三个基本需求,最多只能同时满足其中的两项。在网络分区发生时,我们必须在一致性和可用性之间做权衡。BASE理论是CAP理论中AP策略的延伸,它强调基本可用(Basically Available)、软状态(Soft state)和最终一致性(Eventually consistent)。它主张牺牲强一致性来换取可用性,允许系统在一段时间内数据不一致,但最终会达到一致状态。”
您在项目中是如何应用微服务架构的?它带来了哪些好处和挑战?
- 回答示例: “在项目中,我们会根据业务领域将一个大的单体应用拆分成多个独立的微服务,比如用户服务、商品服务、订单服务等。每个服务都有自己的数据库,独立开发、部署和伸缩。好处是:技术选型灵活,不同服务可以用最适合的技术栈;团队可以并行开发,提高效率;故障隔离,一个服务出问题不影响其他服务;易于扩展,可以针对性地扩展热点服务。挑战也很多:服务间通信成本增加,需要考虑RPC框架选型和网络延迟;分布式事务处理复杂;运维复杂度提高,需要服务发现、配置管理、熔断、监控等配套设施;数据一致性保证更难。”
请谈谈消息队列在分布式系统中的作用,以及您使用过哪些消息队列中间件(如Redis也常用于此场景)?
- 回答示例: “消息队列在分布式系统中主要有三个作用:1. 异步处理:将非核心流程异步化,比如用户注册后的发送欢迎邮件,可以先响应用户注册成功,再将邮件发送任务放入队列。2. 应用解耦:生产者和消费者之间通过消息队列交互,互相不直接依赖,降低耦合度。3. 流量削峰:在秒杀等高并发场景,可以将请求先写入消息队列,后端服务按自己的处理能力消费,避免系统被冲垮。我使用过Kafka和RabbitMQ。Kafka吞吐量高,适合大数据量日志处理和流式计算场景。RabbitMQ功能丰富,支持多种消息模式,适合业务逻辑复杂的场景。Redis的List结构或Stream结构有时也会被用作轻量级的消息队列。”
如何保证分布式系统中数据的一致性?
- 回答示例: “保证分布式系统数据一致性是一个复杂的问题,通常根据业务场景选择不同的方案。对于要求强一致性的场景,可以考虑使用分布式事务方案,比如两阶段提交(2PC)或三阶段提交(3PC),但它们性能和可用性较差。更常见的是追求最终一致性,比如通过TCC(Try-Confirm-Cancel)模式、Saga模式,或者基于可靠消息最终一致性的方案(比如利用消息队列,发送事务消息,消费者确认消费后,再更新状态)。在某些读多写少的场景,也会采用读写分离加主从复制,但要注意主从延迟导致的不一致问题。”
五、数据库及其他技术 (MySQL, Redis, Django, 云计算经验)
您在项目中是如何使用MySQL的?请谈谈数据库设计、SQL优化方面的经验。
- 回答示例: “MySQL是我们项目中常用的关系型数据库。数据库设计时,我会遵循三范式,但有时为了性能也会做适当的反范式设计。会仔细考虑字段类型、索引策略(比如B+Tree索引,联合索引,覆盖索引)。SQL优化方面,我会使用
EXPLAIN分析SQL执行计划,避免全表扫描,确保索引有效利用。常见的优化手段包括:优化WHERE子句,避免在索引列上使用函数或运算,减少JOIN的表数量,使用LIMIT分页,以及在业务允许的情况下将复杂查询拆分成多个简单查询。”
- 回答示例: “MySQL是我们项目中常用的关系型数据库。数据库设计时,我会遵循三范式,但有时为了性能也会做适当的反范式设计。会仔细考虑字段类型、索引策略(比如B+Tree索引,联合索引,覆盖索引)。SQL优化方面,我会使用
Redis在您的项目中主要扮演什么角色?(例如缓存、消息队列等)
- 回答示例: “Redis在我们的项目中扮演了多个角色。最主要的是作为缓存,缓存热点数据,减轻数据库压力,提升系统响应速度。比如缓存用户信息、商品详情等。其次,我们也会用Redis的List或Stream结构实现轻量级的消息队列,用于一些简单的异步任务。还会用Redis的Set或Sorted Set实现排行榜、去重等功能。它的原子操作也常用于实现分布式锁。”
(如果提到Django/Python)您有用Django或其他Python Web框架开发过AI相关的后台服务吗?
- 回答示例: “是的,我使用过Flask和FastAPI来开发AI相关的后台服务。比如,将训练好的机器学习模型或LLM模型封装成API接口,供前端或其他服务调用。FastAPI因其高性能和基于类型提示的自动数据校验和文档生成,在构建API服务时特别方便。”
大模型方面的智能体 Agent、工具调用和 MCP 的原理是什么,并举例
1. 大模型智能体(Agent)的原理
定义与构成
智能体(Agent)是构建于大型语言模型(LLM)之上的自主系统,具备“感知–思考–决策–执行”闭环能力。其核心可简化为:
Agent = LLM + 记忆(Memory)+ 感知&反思(Perception & Reflection)+ 规划(Planning)+ 工具使用(Tool Use) (woshipm.com, cnblogs.com)
工作流程
- 感知:接收用户输入或环境信息;
- 思考:LLM 对信息进行解析与推理,结合内置或外部“记忆”(如会话历史、知识库);
- 规划:基于目标拆解任务步骤(Task Decomposition);
- 工具调用:在需要时触发外部工具(见下节);
- 执行与反馈:整合工具返回结果,输出最终响应,并更新记忆。 (agent.csdn.net)
示例:Auto-GPT
Auto-GPT 是首个“出圈”的开源 Agent,用户只需给定一个高层目标(如“为某产品写一篇市场分析报告”),它即可:
- 拆解子任务(检索资料→撰写大纲→扩充内容→校对);
- 自动调用 Web 搜索、文档编辑、API 等工具;
- 迭代执行直到目标完成。
缺点:成本高、响应慢,易陷入循环 (cnblogs.com)
2. 工具调用(Function Calling)的原理
基本概念
- 当 LLM 本身能力不足以完成特定操作(如数学运算、数据库查询、获取实时天气等)时,可通过“函数调用”(Function Calling)接口,将任务委托给外部程序或 API。
- 大模型在推理过程中识别出“需要调用工具”,并按照预定义的函数签名输出调用指令,框架执行后将结果返还给模型,最后由模型整合生成最终答案。 (blog.csdn.net)
调用流程
- 注册函数:在模型 SDK 中定义工具名称、参数格式、返回值结构;
- 模型输出:当遇到调用需求,模型按照 JSON 形式输出
{"name":"queryWeather","arguments":{"city":"上海"}}; - 执行函数:SDK 捕获该调用,执行业务代码,获取结果;
- 返回给模型:将函数返回的数据注入后续对话上下文,模型据此生成最终回复。 (blog.csdn.net)
示例
// 注册一个查询消息状态的函数 const functions = [ { name: "messageStatusFunction", description: "根据消息ID查询当前状态", parameters: { type: "object", properties: { messageId: { type: "string", description: "消息唯一ID" } }, required: ["messageId"] } } ]; // 当模型输出调用指令后,后台执行: async function messageStatusFunction({messageId}) { // 从数据库或缓存查询状态 return { status: await db.queryStatus(messageId) }; }- 用户问:“ID 为 abc123 的消息现在是什么状态?”
- 模型输出调用
messageStatusFunction → 工具执行 → 返回{status:"已送达"} → 模型整合回复。 (blog.csdn.net)
3. MCP(Model Context Protocol,模型上下文协议)的原理
背景与动机
- LLM 通常只能访问其训练语料,对“水面下”私有数据(如企业知识库、用户笔记)无能为力。MCP 提供了一个开放标准协议,使 LLM 应用能够统一接入各种数据源和工具,从而扩展模型上下文。 (zh.wikipedia.org, theverge.com)
架构与通信流程
- MCP 客户端(Client) :集成在 LLM 应用端,负责按协议构建请求;
- MCP 服务器(Server) :部署在外部系统端,接收请求并与实际数据源/工具交互(数据库、GitHub、CRM 等);
- JSON-RPC 2.0:作为通信载体,规定请求字段(资源类型、操作,参数)与响应字段(数据、状态码、错误信息);
- 上下文注入:MCP 服务器将获取的数据格式化后返回,MCP 客户端将其注入到 LLM 的上下文中,供后续生成或决策使用。 (zh.wikipedia.org, cnblogs.com)
|优势对比|||
特性 Function Calling MCP(Model Context Protocol) 接口类型 专有(如 OpenAI 函数调用) 开放标准(JSON-RPC 2.0) 模型依赖 需针对每个大模型平台单独定义 跨模型兼容(GPT、Claude、Llama 等) 工具复用性 绑定模型,需重复实现 一次实现,多处复用 适用场景 轻量级快速任务 复杂企业级多工具、多数据源集成 示例:Anthropic MCP 与 GitHub 集成
通过 MCP,Anthropic Claude 在数分钟内实现直接与 GitHub 交互:
- 创建新仓库;
- 新建分支并提交 Pull Request;
开发者只需遵循 MCP 规范一次性接入,后续无需要为每种工具单独编码。 (theverge.com)