八股-MySQL
Mysql 相关面试题
======= 基础 =======
如何避免重复插入数据
方式一:使用UNIQUE约束
在表的相关列上添加UNIQUE约束,确保每个值在该列中唯一。例如:
CREATE TABLE users (
id INT PRIMARY KEY AUTO_INCREMENT,
email VARCHAR(255) UNIQUE,
name VARCHAR(255)
);如果尝试插入重复的email,MySQL会返回错误
方式二:使用INSERT ... ON DUPLICATE KEY UPDATE
这种语句允许在插入记录时处理重复键的情况。如果插入的记录与现有记录冲突,可以选择更新现有记录:
INSERT INTO users (email, name)
VALUES ('[email protected]', 'John Doe')
ON DUPLICATE KEY UPDATE name = VALUES(name);方式三:使用INSERT IGNORE: 该语句会在插入记录时忽略那些因重复键而导致的插入错误。例如:
INSERT IGNORE INTO users (email, name)
VALUES ('[email protected]', 'John Doe');如果email已经存在,这条插入语句将被忽略而不会返回错误
CHAR 和 VARCHAR 的区别
-
CHAR 是固定长度的字符串类型,定义时需指定固定长度,存储时会在末尾补足空格CHAR 适合存储长度固定的数据,例如固定长度的代码、状态等,存储空间固定,对于短字符串效率较高 -
VARCHAR 是可变长度的字符串类型,定义时需指定最大长度,实际存储时根据实际长度占用存储空间VARCHAR 适合存储长度可变的数据,如用户输入的文本、备注等,能够节约存储空间
VARCHAR后面代表字节还是字符
字符
- 若字符集为ASCII字符集,则ASCII字符集的每个字符占用1个字节。因此,
VARCHAR(10)字段最多可存储10个ASCII字符,且占用的存储空间最多为10个字节(不考虑额外的长度记录开销) - 若字符集为UTF-8字符集,其每个字符可能占用1至4个字节。对于
VARCHAR(10)字段,最多可存储10个字符,但占用的字节数会因字符的不同而有所变化
int(1)、int(10) 在 mysql 中有什么不同
INT(1) 和 INT(10) 的区别主要在于 显示宽度,而不是存储范围或数据类型本身的大小。以下是核心区别的总结:
- 本质是显示宽度,不改变存储方式:
INT 的存储固定为 4 字节,所有INT(无论写成INT(1) 还是INT(10))占用的存储空间 均为 4 字节。括号内的数值(如1 或10)是显示宽度,用于在 特定场景下 控制数值的展示格式 - 唯一作用场景:
ZEROFILL 补零显示,当字段设置ZEROFILL 时:数字显示时会用前导零填充至指定宽度。比如,字段类型为INT(4) ZEROFILL,实际存入5 → 显示为0005,实际存入12345 → 显示仍为12345(宽度超限时不截断)
举个例子
-- 创建一个包含 INT(1) 和 INT(10) 字段的表,并设置 ZEROFILL 属性
CREATE TABLE test_int (
num1 INT(1) ZEROFILL,
num2 INT(10) ZEROFILL
);
-- 插入数据
INSERT INTO test_int (num1, num2) VALUES (1, 1);
-- 查询数据
SELECT * FROM test_int;结果分析:
-
num1 字段由于设置为INT(1) ZEROFILL,其显示宽度为 1,插入数据1 时会显示为1 -
num2 字段设置为INT(10) ZEROFILL,显示宽度为 10,插入数据1 时会在前面填充零,显示为0000000001
Text数据类型
MySQL 中三种 TEXT 类型的最大长度如下:
-
TEXT:65,535 字节 ≈ 64KB -
MEDIUMTEXT:16,777,215 字节 ≈ 16MB -
LONGTEXT:4,294,967,295 字节 ≈ 4GB
IP地址如何在数据库里存储?
以字符串形式存储(最常见)
| 类型 | 示例值 | 适用场景 |
|---|---|---|
| VARCHAR(15) | "192.168.1.1" | IPv4 |
| VARCHAR(39) | "2001:db8::1" | IPv6(最长39位) |
优点:
- 直观可读
- 方便日志记录和展示
缺点:
- 占用空间较大
- 不利于排序和范围比较(如:查询 IP 段)
存为整型(高性能方案,仅限 IPv4)
| 类型 | 示例值 | 说明 |
|---|---|---|
| INT或BIGINT | 3232235777(即 192.168.1.1) | 将 IP 转为整数 |
// Java中转换方式
String ip = "192.168.1.1";
long ipLong = InetAddress.getByName(ip).hashCode(); // 更精确方式见下面或使用自定义方法手动转换:
public static long ipToLong(String ip) {
String[] parts = ip.split("\\.");
long result = 0;
for (int i = 0; i < 4; i++) {
result |= Long.parseLong(parts[i]) << (24 - (8 * i));
}
return result;
}优点:
- 占用空间小
- 支持数值比较(IP段筛选)
- 查询效率高
缺点:
- 仅支持 IPv4
- 不直观,需要转换
二进制存储(支持 IPv6)
适合高性能、大规模 IPv6 场景:
| 类型 | 示例值 | 说明 |
|---|---|---|
| BINARY(16) | 原始二进制数据 | IPv6最多128位,即16字节 |
一些数据库(如 PostgreSQL)还提供专门的 inet 类型,原生支持 IP 存储与比较
实际推荐策略
| 场景 | 推荐存储类型 |
|---|---|
| 日志记录、展示为主 | VARCHAR(15/39) |
| IPv4 + 查询为主 | INT(整型) |
| 支持 IPv6 或未来拓展 | VARCHAR(39)或BINARY(16) |
| PostgreSQL 用户 | 使用INET类型最方便 |
关键字 in 和 exist
在MySQL中,IN 和 EXISTS 都是用来处理子查询的关键词,但它们在功能、性能和使用场景上有各自的特点和区别
IN关键字
IN 用于检查左边的表达式是否存在于右边的列表或子查询的结果集中。如果存在,则IN 返回TRUE,否则返回FALSE
语法结构:
SELECT column_name(s)
FROM table_name
WHERE column_name IN (value1, value2, ...);或
SELECT column_name(s)
FROM table_name
WHERE column_name IN (SELECT column_name FROM another_table WHERE condition);例子:
SELECT * FROM Customers
WHERE Country IN ('Germany', 'France');EXISTS关键字
EXISTS 用于判断子查询是否至少能返回一行数据。它不关心子查询返回什么数据,只关心是否有结果。如果子查询有结果,则EXISTS 返回TRUE,否则返回FALSE
语法结构:
SELECT column_name(s)
FROM table_name
WHERE EXISTS (SELECT column_name FROM another_table WHERE condition);例子:
SELECT * FROM Customers
WHERE EXISTS (SELECT 1 FROM Orders WHERE Orders.CustomerID = Customers.CustomerID);Customers 表:
| CustomerID | CustomerName | ContactName | Country |
|---|---|---|---|
| 1 | 张三 | 张三丰 | 中国 |
| 2 | 李四 | 李小四 | 美国 |
| 3 | 王五 | 王老五 | 中国 |
Orders 表:
| OrderID | CustomerID | OrderDate |
|---|---|---|
| 101 | 1 | 2025-01-05 |
| 102 | 1 | 2025-02-10 |
| 103 | 3 | 2025-03-15 |
那么,SQL 语句执行后的结果将会是:
| CustomerID | CustomerName | ContactName | Country |
|---|---|---|---|
| 1 | 张三 | 张三丰 | 中国 |
| 3 | 王五 | 王老五 | 中国 |
区别与选择:
- 性能差异:在很多情况下,
EXISTS 的性能优于IN,特别是当子查询的表很大时。这是因为EXISTS 一旦找到匹配项就会立即停止查询,而IN可能会扫描整个子查询结果集 - 使用场景:如果子查询结果集较小且不频繁变动,
IN 可能更直观易懂。而当子查询涉及外部查询的每一行判断,并且子查询的效率较高时,EXISTS 更为合适 - NULL值处理:
IN 能够正确处理子查询中包含NULL值的情况,而EXISTS 不受子查询结果中NULL值的影响,因为它关注的是行的存在性,而不是具体值
基本函数
字符串函数
CONCAT(str1, str2, ...) :连接多个字符串,返回一个合并后的字符串
SELECT CONCAT('Hello', ' ', 'World') AS Greeting;LENGTH(str) :返回字符串的长度(字符数)
SELECT LENGTH('Hello') AS StringLength;SUBSTRING(str, pos, len) :从指定位置开始,截取指定长度的子字符串
SELECT SUBSTRING('Hello World', 1, 5) AS SubStr;REPLACE(str, from_str, to_str) :将字符串中的某部分替换为另一个字符串
SELECT REPLACE('Hello World', 'World', 'MySQL') AS ReplacedStr;数值函数
ABS(num) :返回数字的绝对值
SELECT ABS(-10) AS AbsoluteValue;POWER(num, exponent) :返回指定数字的指定幂次方
SELECT POWER(2, 3) AS PowerValue;日期和时间函数
NOW() :返回当前日期和时间
SELECT NOW() AS CurrentDateTime;CURDATE() :返回当前日期
SELECT CURDATE() AS CurrentDate;聚合函数
COUNT(column) :计算指定列中的非NULL值的个数
SELECT COUNT(*) AS RowCount FROM my_table;SUM(column) :计算指定列的总和
SELECT SUM(price) AS TotalPrice FROM orders;AVG(column) :计算指定列的平均值
SELECT AVG(price) AS AveragePrice FROM orders;MAX(column) :返回指定列的最大值
SELECT MAX(price) AS MaxPrice FROM orders;MIN(column) :返回指定列的最小值
SELECT MIN(price) AS MinPrice FROM orders;
SQL 查询语句的执行顺序
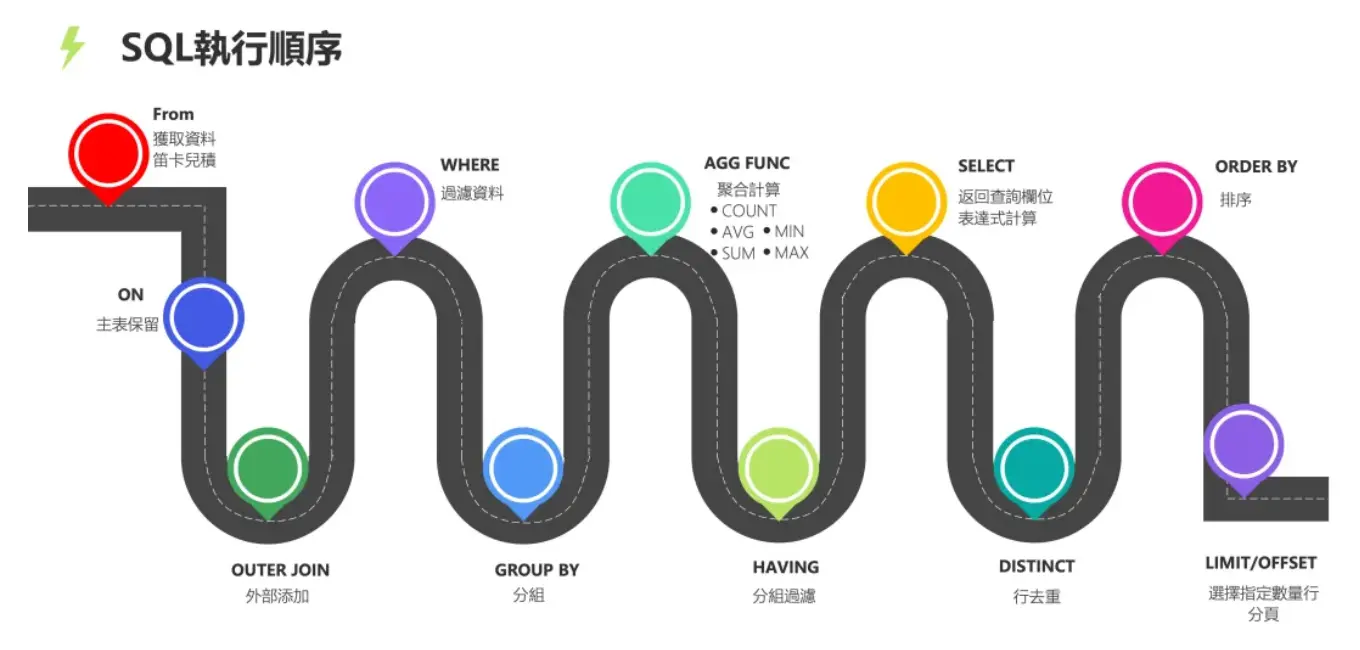
所有的查询语句都是从FROM开始执行,在执行过程中,每个步骤都会生成一个虚拟表,这个虚拟表将作为下一个执行步骤的输入,最后一个步骤产生的虚拟表即为输出结果
(9) SELECT
(10) DISTINCT <column>,
(6) AGG_FUNC <column> or <expression>, ...
(1) FROM <left_table>
(3) <join_type>JOIN<right_table>
(2) ON<join_condition>
(4) WHERE <where_condition>
(5) GROUP BY <group_by_list>
(7) WITH {CUBE|ROLLUP}
(8) HAVING <having_condtion>
(11) ORDER BY <order_by_list>
(12) LIMIT <limit_number>;
SQL 题目:
给学生表、课程成绩表,求不存在01课程但存在02课程的学生的成绩
给学生表、课程成绩表,求不存在01课程但存在02课程的学生的成绩
假设我们有以下两张表:
-
Student 表,其中包含学生的sid(学生编号)和其他相关信息 -
Score 表,其中包含sid(学生编号),cid(课程编号)和score(分数)
NOT IN + JOIN
SELECT st.sid, sc.score
FROM Student st
JOIN Score sc ON st.sid = sc.sid
WHERE sc.cid = '02'
AND st.sid NOT IN (
SELECT sid FROM Score WHERE cid = '01'
);NOT EXISTS(推荐,NULL 安全)
SELECT st.sid, sc.score
FROM Student st
JOIN Score sc ON st.sid = sc.sid
WHERE sc.cid = '02'
AND NOT EXISTS (
SELECT 1 FROM Score s2
WHERE s2.sid = st.sid AND s2.cid = '01'
);聚合 HAVING (适合复杂聚合场景)
SELECT s.sid
FROM Score s
GROUP BY s.sid
HAVING SUM(CASE WHEN cid = '01' THEN 1 ELSE 0 END) = 0
AND SUM(CASE WHEN cid = '02' THEN 1 ELSE 0 END) > 0;LEFT JOIN 排除(结构型思维)
SELECT s.sid, s.sname, sc2.cid, sc2.score
FROM Student s
LEFT JOIN Score AS sc1 ON s.sid = sc1.sid AND sc1.cid = '01'
LEFT JOIN Score AS sc2 ON s.sid = sc2.sid AND sc2.cid = '02'
WHERE sc1.cid IS NULL AND sc2.cid IS NOT NULL;| 写法 | 安全性 | 性能 | 适用场景 |
|---|---|---|---|
| NOT IN | 中 | 中 | 小表,数据无 NULL |
| NOT EXISTS | 高 | 高 | 推荐,大多数通用场景 |
| HAVING | 高 | 中 | 做统计分析时非常方便 |
| LEFT JOIN | 高 | 中 | 可读性好,有 JOIN 优化时优秀 |
给定一个学生表 student_score(stu_id,subject_id,score),查询总分排名在5-10名的学生id及对应的总分
SELECT stu_id AS id, SUM(score) AS sumScore
FROM student_score
GROUP BY stu_id
ORDER BY sumScore DESC
LIMIT 4,6;SELECT stu_id, total_score
FROM (
SELECT stu_id, SUM(score) AS total_score,
RANK() OVER (ORDER BY SUM(score) DESC) AS rk
FROM student_score
GROUP BY stu_id
) AS ranked
WHERE rk BETWEEN 5 AND 10;
查某个班级下所有学生的选课情况
有三张表:学生信息表、学生选课表、学生班级表
学生信息表(students)结构如下:
CREATE TABLE students (
student_id INT PRIMARY KEY, //学生的唯一标识,主键。
student_name VARCHAR(50), //学生姓名。
class_id INT //学生所属班级的标识,用于关联班级表。
);学生选课表(course_selections)结构如下:
CREATE TABLE course_selections (
selection_id INT PRIMARY KEY, //选课记录的唯一标识,主键。
student_id INT, //选课学生的标识,用于关联学生信息表。
course_name VARCHAR(50), //所选课程的名称。
);学生班级表(classes)结构如下:
CREATE TABLE classes (
class_id INT PRIMARY KEY, //班级的唯一标识,主键。
class_name VARCHAR(50) //班级名称。
);要查询某个班级(例如班级名称为 'Class A')下所有学生的选课情况
SELECT s.student_name, cs.course_name
FROM students s
JOIN classes c ON s.class_id = c.class_id
JOIN course_selections cs ON s.student_id = cs.student_id
WHERE c.class_name = 'Class A';JOIN classes:关联班级表,找到班级名为 'Class A' 的班级
LEFT JOIN course_selections:确保即使学生没有选课也能显示(若需要全部显示)
WHERE c.class_name = 'Class A':过滤班级
如何用 MySQL 实现一个可重入的锁
创建一个保存锁记录的表:
CREATE TABLE `lock_table` (
`id` INT AUTO_INCREMENT PRIMARY KEY,
//该字段用于存储锁的名称,作为锁的唯一标识符。
`lock_name` VARCHAR(255) NOT NULL,
// holder_thread该字段存储当前持有锁的线程的名称,用于标识哪个线程持有该锁。
`holder_thread` VARCHAR(255),
// reentry_count 该字段存储锁的重入次数,用于实现锁的可重入性
`reentry_count` INT DEFAULT 0
);加锁的实现逻辑
开启事务
执行
SQL SELECT holder_thread, reentry_count FROM lock_table WHERE lock_name =? FOR UPDATE,查询是否存在该记录:- 如果记录不存在,则直接加锁,执行
INSERT INTO lock_table (lock_name, holder_thread, reentry_count) VALUES (?,?, 1) - 如果记录存在,且持有者是同一个线程,则可冲入,增加重入次数,执行
UPDATE lock_table SET reentry_count = reentry_count + 1 WHERE lock_name =?
- 如果记录不存在,则直接加锁,执行
提交事务
解锁的逻辑:
开启事务
执行
SQL SELECT holder_thread, reentry_count FROM lock_table WHERE lock_name =? FOR UPDATE,查询是否存在该记录:- 如果记录存在,且持有者是同一个线程,且可重入数大于 1 ,则减少重入次数
UPDATE lock_table SET reentry_count = reentry_count - 1 WHERE lock_name =? - 如果记录存在,且持有者是同一个线程,且可重入数小于等于 0 ,则完全释放锁,
DELETE FROM lock_table WHERE lock_name =?
- 如果记录存在,且持有者是同一个线程,且可重入数大于 1 ,则减少重入次数
提交事务
存储引擎
执行一条SQL请求的过程
连接器:建立连接,管理连接、校验用户身份
查询缓存:查询语句如果命中查询缓存则直接返回,否则继续往下执行MySQL 8.0 已删除该模块解析 SQL,通过解析器对 SQL 查询语句进行词法分析、语法分析,然后构建语法树,方便后续模块读取表名、字段、语句类型
执行 SQL:执行 SQL 共有三个阶段:
- 预处理阶段:检查表或字段是否存在;将
select * 中的* 符号扩展为表上的所有列 - 优化阶段:基于查询成本的考虑, 选择查询成本最小的执行计划
- 执行阶段:根据执行计划执行 SQL 查询语句,从存储引擎读取记录,返回给客户端
- 预处理阶段:检查表或字段是否存在;将
mysql 的引擎
- InnoDB:InnoDB是MySQL的默认存储引擎,具有ACID事务支持、行级锁、外键约束等特性。它适用于高并发的读写操作,支持较好的数据完整性和并发控制
- MyISAM:MyISAM是MySQL的另一种常见的存储引擎,具有较低的存储空间和内存消耗,适用于大量读操作的场景。然而,MyISAM不支持事务、行级锁和外键约束,因此在并发写入和数据完整性方面有一定的限制
- Memory:Memory引擎将数据存储在内存中,适用于对性能要求较高的读操作,但是在服务器重启或崩溃时数据会丢失。它不支持事务、行级锁和外键约束
为什么 InnoDB 是默认引擎
InnoDB引擎在事务支持、并发性能、崩溃恢复等方面展现出显著优势,因此被MySQL选为默认的存储引擎
- 事务支持:InnoDB引擎支持事务操作,实现了ACID(原子性、一致性、隔离性、持久性)属性。与之相对,MyISAM存储引擎不支持事务
- 并发性能:InnoDB引擎采用行级锁定机制,能够提供更优的并发性能。而MyISAM存储引擎仅支持表锁,锁的粒度较大
- 崩溃恢复:InnoDB引擎通过redolog日志实现崩溃恢复功能,在数据库遇到异常情况(如断电)时,可通过日志文件进行恢复,确保数据的持久性和一致性。MyISAM不支持崩溃恢复
InnoDB VS MyISAM
- 事务:InnoDB 支持事务,MyISAM 不支持事务,这是 MySQL 将默认存储引擎从 MyISAM 变成 InnoDB 的重要原因之一
- 索引结构:InnoDB 是聚簇索引,MyISAM 是非聚簇索引。聚簇索引的文件存放在主键索引的叶子节点上,因此 InnoDB 必须要有主键,通过主键索引效率很高。但是辅助索引需要两次查询,先查询到主键,然后再通过主键查询到数据。因此,主键不应该过大,因为主键太大,其他索引也都会很大。而 MyISAM 是非聚簇索引,数据文件是分离的,索引保存的是数据文件的指针。主键索引和辅助索引是独立的
- 锁粒度:InnoDB 最小的锁粒度是行锁,MyISAM 最小的锁粒度是表锁。一个更新语句会锁住整张表,导致其他查询和更新都会被阻塞,因此并发访问受限
- count 的效率:InnoDB 不保存表的具体行数,执行 select count(*) from table 时需要全表扫描。而MyISAM 用一个变量保存了整个表的行数,执行上述语句时只需要读出该变量即可,速度很快
======= 索引 =======
什么是索引
索引在项目中颇为常见,作为辅助MSQL高效获取数据的数据结构,其主要功能在于提升数据检索效率,减少数据库的I/O成本。同时,通过索引列对数据进行排序,进一步降低数据排序的成本,并有效减少CPU的消耗
索引的底层数据结构
MySQL默认的存储引擎InnoDB,采用B+树的数据结构来存储索引。选择B+树的主要原因如下:
- 第一,B+树的阶数更多,路径更短
- 第二,B+树的磁盘读写代价更低,非叶子节点仅存储指针,而叶子节点存储数据
- 第三,B+树便于进行全库扫描和区间查询,其叶子节点构成一个双向链表
索引创建的原则
先陈述自己在实际的工作中是怎么用的
主键索引
唯一索引
根据业务创建的索引(复合索引)
1). 针对数据量较大且查询频繁的表,建立索引。单表数据量超过10万条,有助于提升用户体验
2). 针对常用于查询条件(WHERE)、排序(ORDER BY)、分组(GROUP BY)的字段,建立索引
3). 尽量选择区分度高的列作为索引,并优先建立唯一索引。区分度越高,使用索引的效率也越高
4). 对于字符串类型的字段,若字段长度较长,可根据字段特性建立前缀索引
5). 尽量采用联合索引,减少单列索引的使用。在查询时,联合索引往往能覆盖索引,节省存储空间,避免回表操作,从而提高查询效率
mysql> show index from tb_seller;
| Table | Non_unique | Key_name | Seq_in_index | Column_name |
|---|---|---|---|---|
| tb_seller | 1 | tb_seller_index | 1 | name |
| tb_seller | 1 | tb_seller_index | 2 | status |
| tb_seller | 1 | tb_seller_index | 3 | address |
6). 控制索引数量,索引并非越多越好。索引越多,维护索引结构的成本也就越大,进而影响增删改的效率
7). 若索引列不能存储NULL值,请在创建表时使用NOT NULL约束。当优化器了解每列是否包含NULL值时,它能更有效地确定哪个索引最适用于查询
B树和B+树的区别
第一:在B树中,非叶子节点和叶子节点都会存放数据,而B+树的所有的数据都会出现在叶子节点,在查询的时候,B+树查找效率更加稳定
第二:在进行范围查询的时候,B+树效率更高,因为B+树都在叶子节点存储,并且叶子节点是一个双向链表
二叉树、红黑树
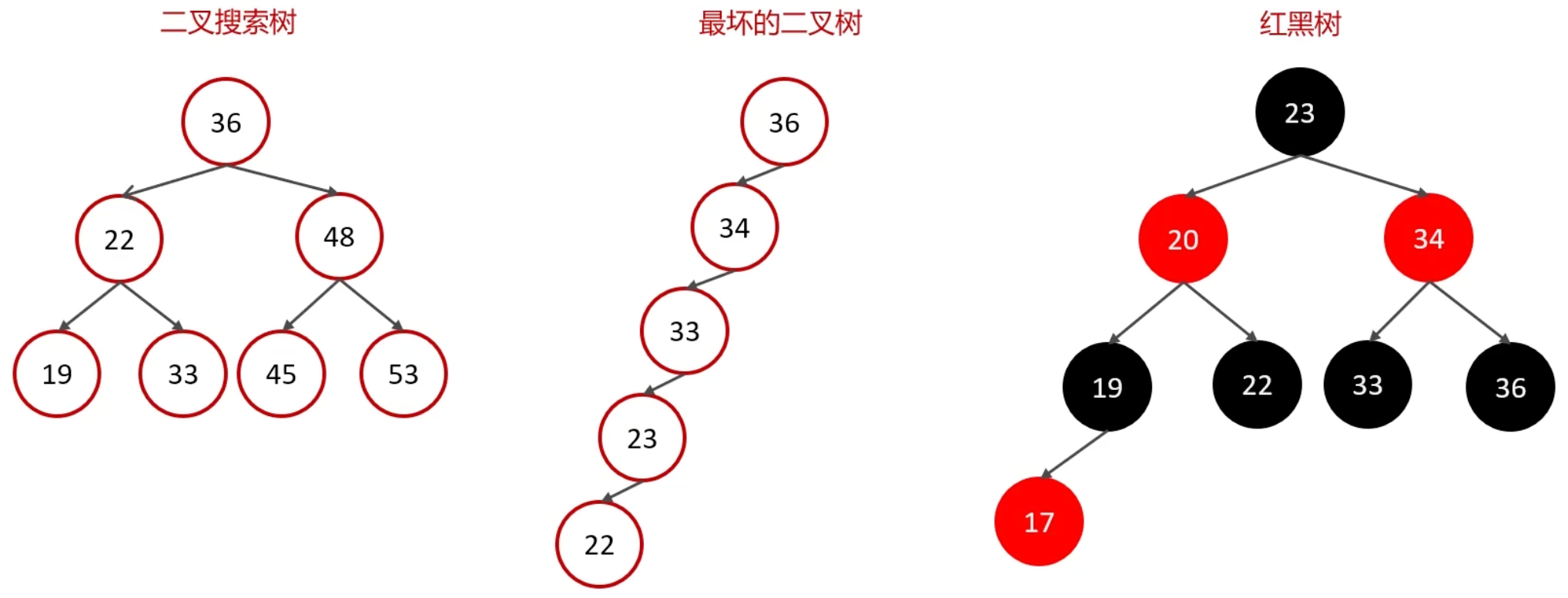
二叉树,不论哪种,在数据量很大的时候,树高很高(瘦高)
B 树
B-Tree,又称B树,是一种多路平衡查找树。与二叉树相比,B树每个节点可拥有多个分支,即多叉结构(矮胖)
以一颗最大度数(max-degree)为5(五阶)的B树为例,此类B树的每个节点最多存储4个key
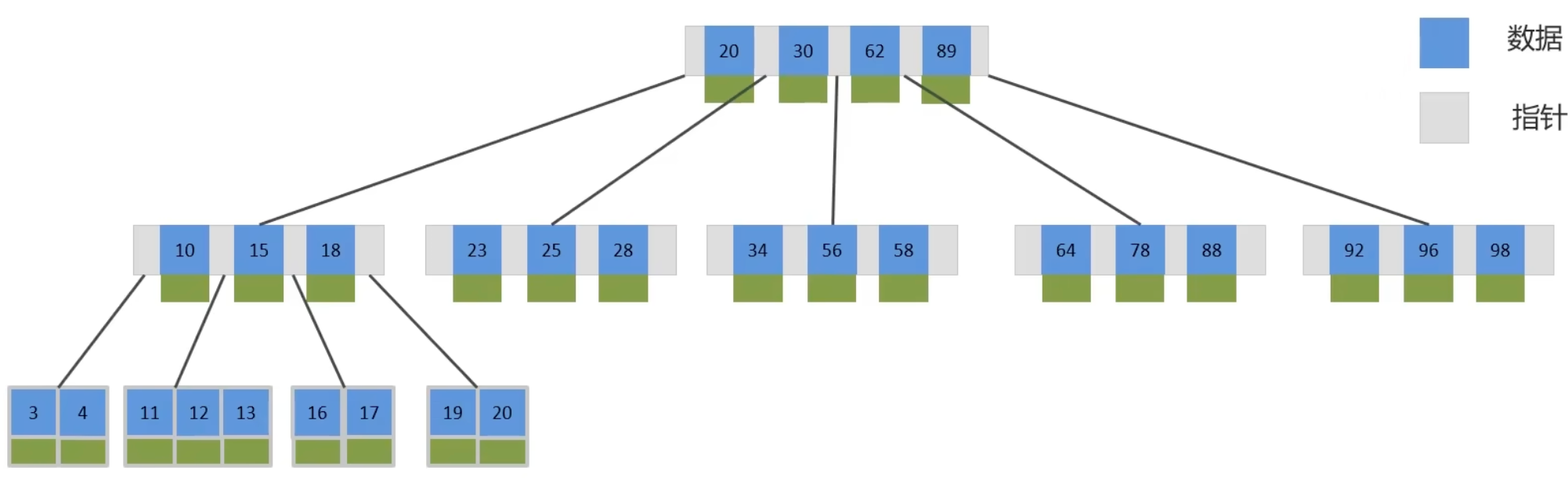
B+ Tree
B+Tree是在BTree基础上的一种优化,使其更适合实现外存储索引结构,InnoDB存储引擎就是用B+Tree实现其索引结构
叶子节点才会存储数据、非叶节点只存储指针
①:磁盘读写代价B+树更低(无需加载非叶节点的数据)
②:查询效率B+树更加稳定(数据都在叶节点)
③:B+树便于扫库和区间查询(节点之间有双向指针)
MySQL为什么用B+树结构?和其他结构比的优点?
- B+Tree 与 B Tree 对比:B+Tree 仅在叶子节点存储数据,而 B 树的非叶子节点同样存储数据,因此 B+Tree 的单个节点数据量更小。在相同的磁盘 I/O 次数下,B+Tree 可以查询更多节点。此外,B+Tree 的叶子节点采用双链表连接,适用于 MySQL 中常见的基于范围的顺序查找,而 B 树则无法实现这一点
- B+Tree 与二叉树对比:对于拥有 N 个叶子节点的 B+Tree,其搜索复杂度为 O(logdN),其中 d 代表节点允许的最大子节点数为 d 个。在实际应用中,d 值通常大于100,这确保了即使数据量达到千万级别,B+Tree 的高度也能维持在 3~4 层左右,意味着一次数据查询操作仅需进行 3~4 次磁盘 I/O 操作即可找到目标数据。而二叉树的每个父节点的子节点个数限制为 2 个,导致其搜索复杂度为 O(logN),这比 B+Tree 要高,因此二叉树检索目标数据所经历的磁盘 I/O 次数更多
- B+Tree 与 Hash 对比:Hash 在进行等值查询时效率极高,搜索复杂度为 O(1)。然而,Hash 表不适用于范围查询,它更适合进行等值查询。这也是为什么 B+Tree 索引相较于 Hash 表索引在应用场景上更为广泛的原因
MySQL 为什么不用跳表
B+树在数据量达到千万级时,树高只有 3~4 层,而跳表去维护同样的数据量会造成的跳表层数过高而导致的磁盘IO次数增多,也就是使用B+树在存储同样的数据下磁盘IO次数更少
聚簇(聚集)索引、非聚簇索引(二级索引/辅助索引)
什么是聚簇索引、非聚簇索引?
聚簇索引主要是指数据与索引放到一块,B+树的叶子节点保存了整行数据,有且只有一个,一般情况下主键在作为聚簇索引的
非聚簇索引指的是数据与索引分开存储,B+树的叶子节点保存对应的主键,可以有多个,一般我们自己定义的索引都是非聚簇索引
什么是回表查询?
回表的意思就是通过二级索引找到对应的主键值,然后再通过主键值找到聚集索引中所对应的整行数据,这个过程就是回表
备注:如果面试官直接问回表,则需要先介绍聚簇索引和非聚簇索引
| 分类 | 含义 | 特点 |
|---|---|---|
| 聚集索引 (Clustered Index) | 将数据存储与索引放到了一块,索引结构的叶子节点保存了整行数据 | 必须有,而且只有一个 |
| 二级索引 (Secondary Index) | 将数据与索引分开存储,索引结构的叶子节点关联的是对应的主键值 | 可以存在多个 |
聚集索引选取规则:
如果存在主键,主键索引就是聚集索引
如果不存在主键,将使用第一个唯一(UNIQUE)索引作为聚集索引
如果表没有主键,或没有合适的唯一索引,则InnoDB会自动生成一个rowid作为隐藏的聚集索引
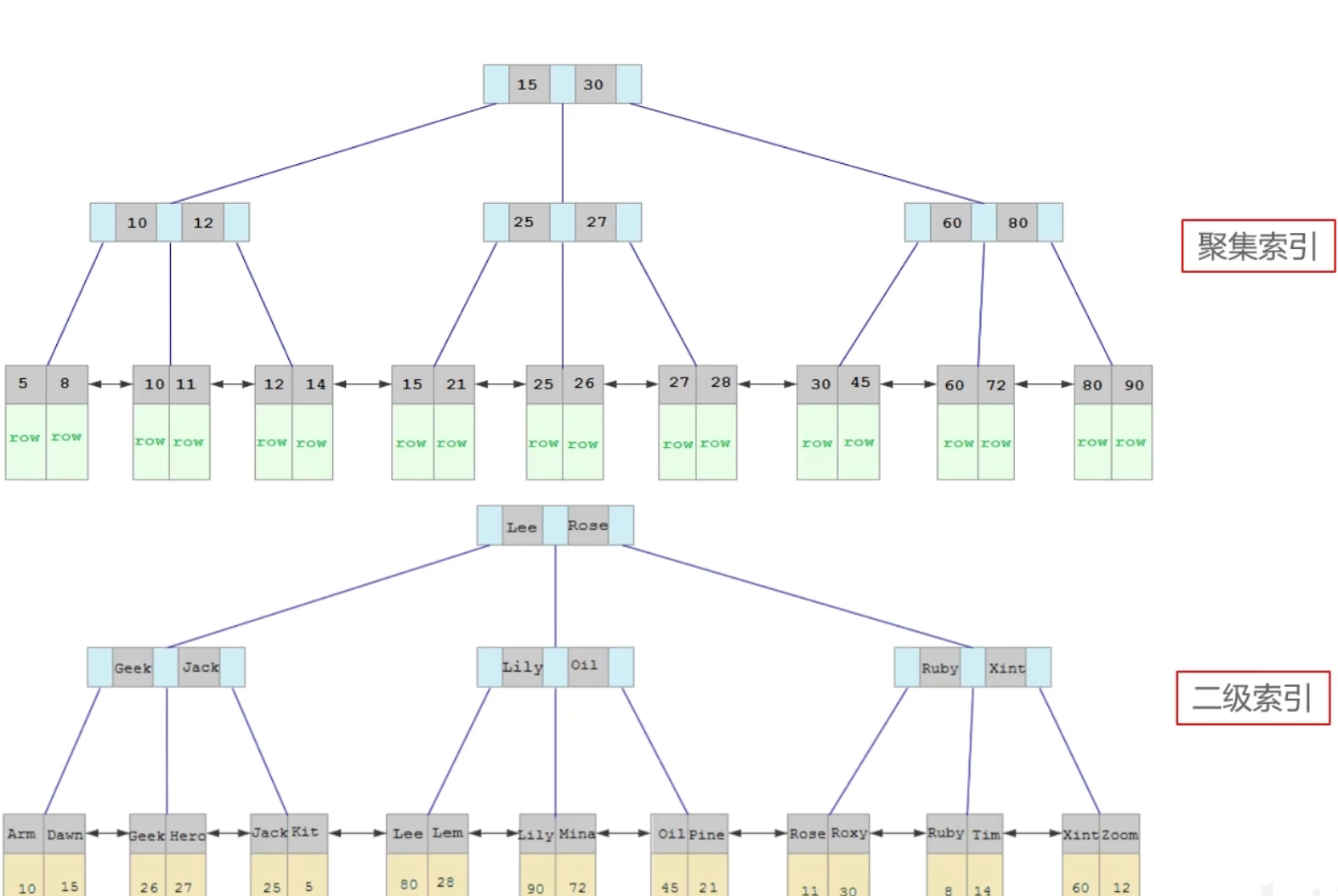
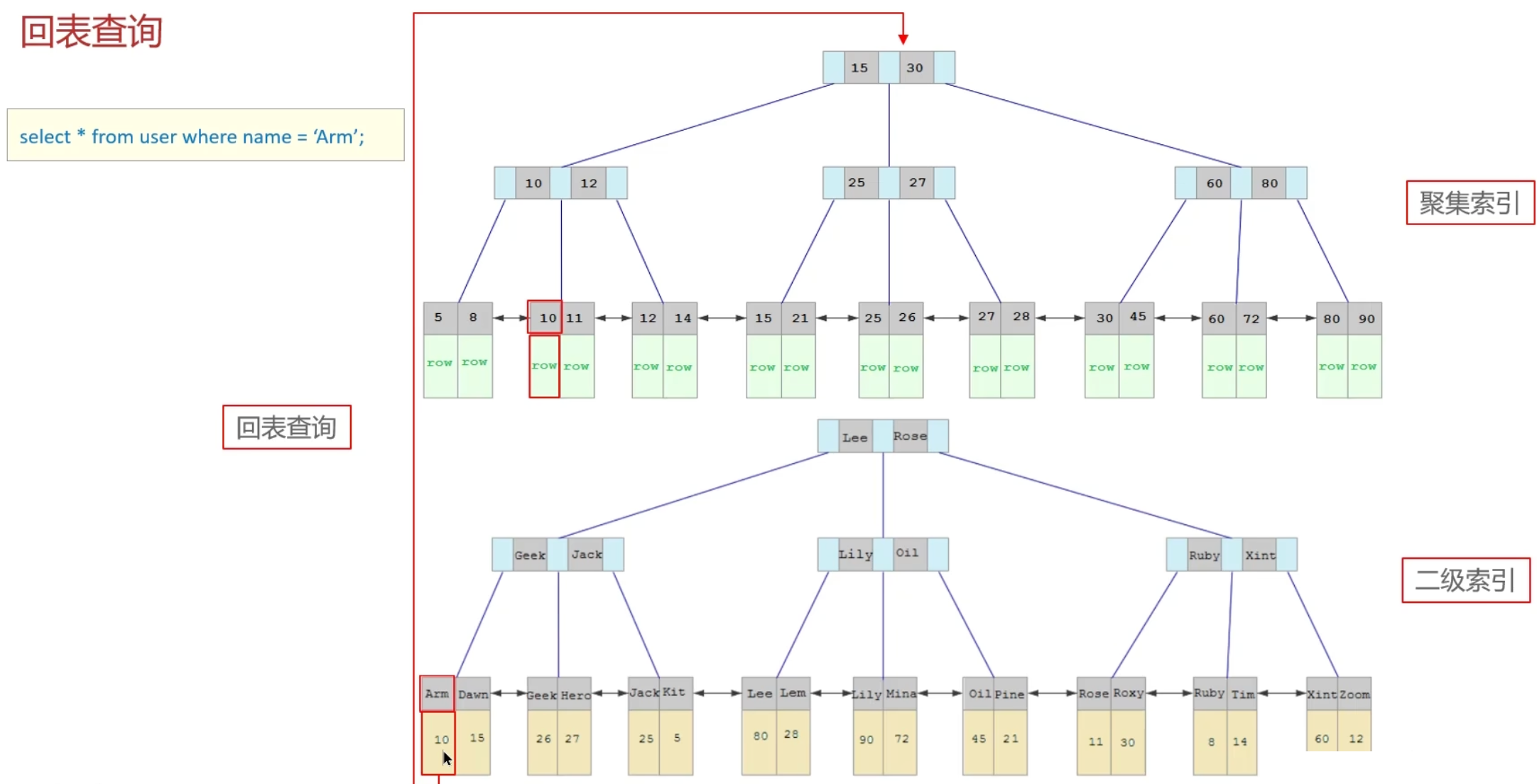
回表查询
先通过二级索引找到主键值,再到聚集索引根据主键找到整行数据
如果聚簇索引的数据更新,它的存储要不要变化?
- 如果更新的数据是非索引数据,也就是普通的用户记录,那么存储结构是不会发生变化
- 如果更新的数据是索引数据,那么存储结构是有变化的,因为要维护 b+树的有序性
什么字段适合当做主键?
- 字段具有唯一性,且不能为空的特性
- 字段最好的是有递增的趋势的,如果字段的值是随机无序的,可能会引发页分裂的问题,造型性能影响
- 不建议用业务数据作为主键,比如会员卡号、订单号、学生号之类的,因为我们无法预测未来会不会因为业务需要,而出现业务字段重复或者重用的情况
- 通常情况下会用自增字段来做主键,对于单机系统来说是没问题的。但是,如果有多台服务器,各自都可以录入数据,那就不一定适用了。因为如果每台机器各自产生的数据需要合并,就可能会出现主键重复的问题,这时候就需要考虑分布式 id 的方案了
表中十个字段,你主键用自增ID还是UUID,为什么?
用的是自增 id
因为 uuid 相对顺序的自增 id 来说是毫无规律可言的,新行的值不一定要比之前的主键的值要大,所以 innodb 无法做到总是把新行插入到索引的最后,而是需要为新行寻找新的合适的位置从而来分配新的空间
这个过程需要做很多额外的操作,数据的毫无顺序会导致数据分布散乱,将会导致以下的问题:
- 写入的目标页很可能已经刷新到磁盘上并且从缓存上移除,或者还没有被加载到缓存中,innodb 在插入之前不得不先找到并从磁盘读取目标页到内存中,这将导致大量的随机 IO
- 因为写入是乱序的,innodb 不得不频繁的做页分裂操作,以便为新的行分配空间,页分裂导致移动大量的数据,影响性能
- 由于频繁的页分裂,页会变得稀疏并被不规则的填充,最终会导致数据会有碎片
结论:使用 InnoDB 应该尽可能的按主键的自增顺序插入,并且尽可能使用单调的增加的聚簇键的值来插入新行
🤔查询数据时,到了B+树的叶子节点,之后的查找数据是如何做?
数据页中的记录按照「主键」顺序组成单向链表,单向链表的特点就是插入、删除非常方便,但是检索效率不高,最差的情况下需要遍历链表上的所有节点才能完成检索
因此,数据页中有一个页目录,起到记录的索引作用,就像我们书那样,针对书中内容的每个章节设立了一个目录,想看某个章节的时候,可以查看目录,快速找到对应的章节的页数,而数据页中的页目录就是为了能快速找到记录。那 InnoDB 是如何给记录创建页目录的呢?
页目录与记录的关系如下图:
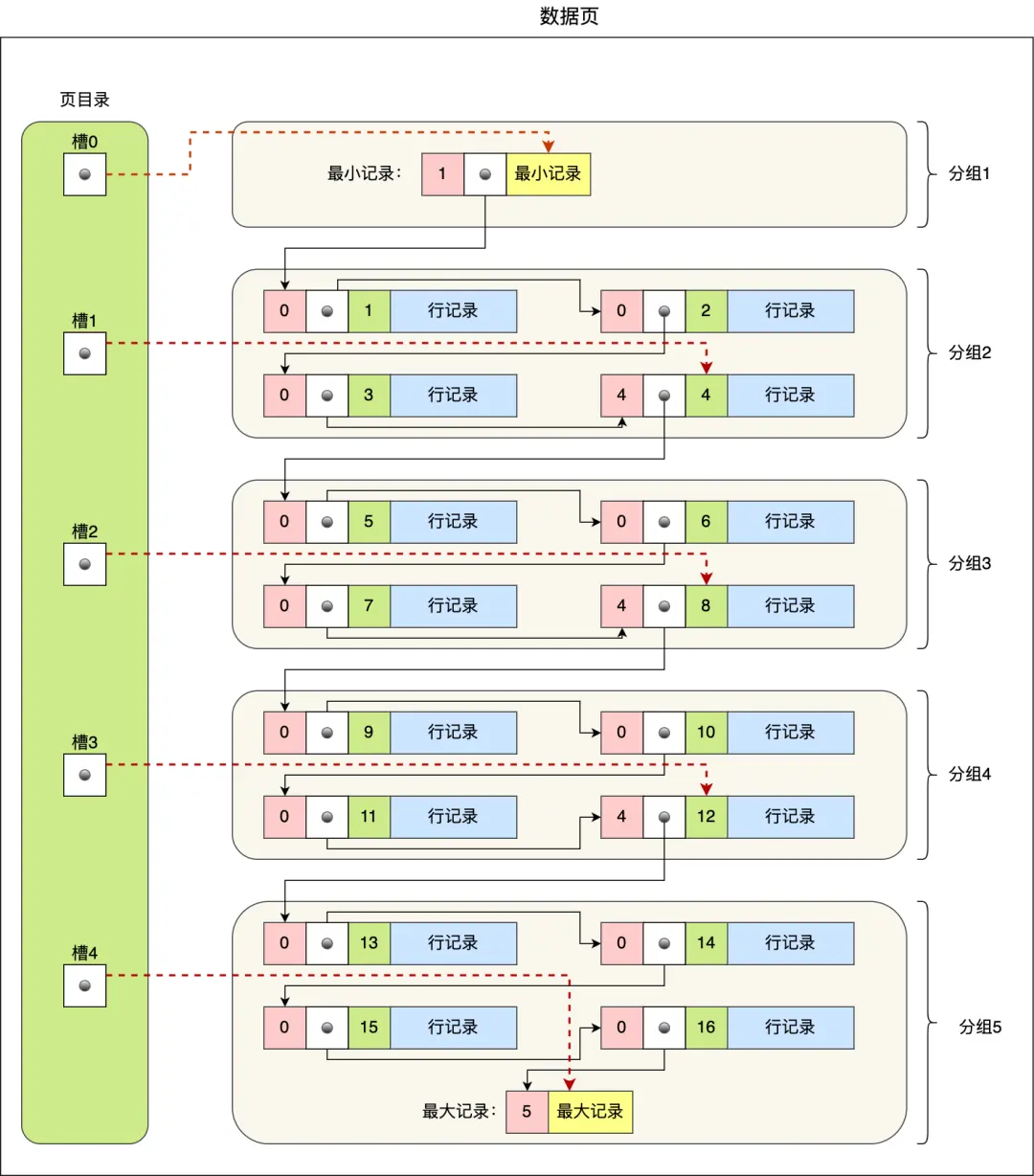
页目录创建过程如下:
- 将所有记录划分为数个组,其中包含最小记录和最大记录,但排除标记为“已删除”的记录
- 每个记录组的最后一条记录即为该组内最大的记录,且最后一条记录的头信息中会存储该组记录总数,作为
n_owned 字段(图中所示粉红色字段) - 页目录用于存储每组最后一条记录的地址偏移量,这些偏移量按顺序存储,每组的地址偏移量亦称为槽(slot)。每个槽相当于指向不同组最后一个记录的指针
从图中可见,页目录由多个槽构成,槽相当于分组记录的索引。由于记录是按“主键值”从小到大排序的,因此通过槽查找记录时,可以采用二分法快速定位目标记录所在的槽(即记录分组),定位到槽后,再遍历槽内的所有记录,找到对应记录,无需从最小记录开始遍历整个页中的记录链表。以下以图中的5个槽(编号为0、1、2、3、4)为例,查找主键为11的用户记录:
- 首先进行二分,槽中间位为
(0+4)/2 = 2,2号槽中最大记录为8。因为11 > 8,所以需在2号槽之后继续搜索 - 然后对2号和4号槽进行二分,中间位为
(2+4)/2 = 3,3号槽中最大记录为12。因为11 < 12,所以主键为11的记录位于3号槽 - 最后从3号槽指向的主键值为9的记录开始向下搜索2次,定位到主键为11的记录,提取该条记录的信息即为所需查找的内容
联合索引的原理
将商品表中的 product_no 和 name 字段组合成联合索引(product_no, name),创建联合索引的方式如下:
CREATE INDEX index_product_no_name ON product(product_no, name);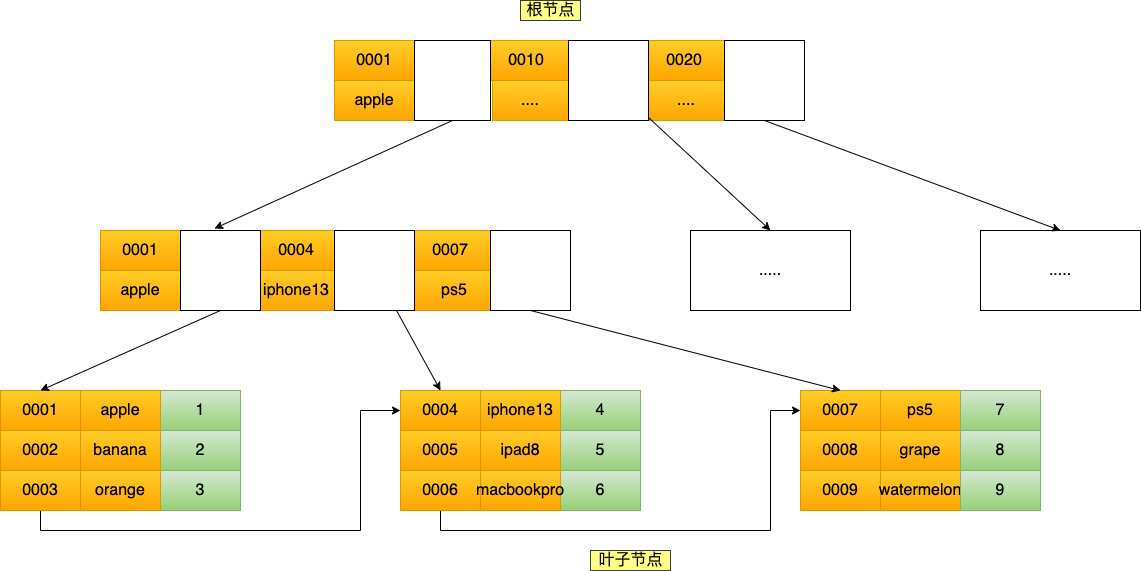
就是先按照product_no排序,然后按照name排序
product_no全局有序,name局部有序,所以不符合最左匹配原则,就无法匹配上联合索引
创建联合索引时需要注意什么
建立联合索引时的字段顺序,对索引效率也有很大影响。越靠前的字段被用于索引过滤的概率越高,实际开发工作中建立联合索引时,要把区分度大的字段排在前面,这样区分度大的字段越有可能被更多的 SQL 使用到
区分度就是某个字段 column 不同值的个数「除以」表的总行数,计算公式如下:
联合索引ABC,现在有个执行语句是A = XXX and C < XXX,索引怎么走
只能用到字段 A 的索引部分,即使用索引做了 A = xxx 的范围过滤
后面的 C < xxx 虽然是联合索引中的字段,但因为 B 没有参与过滤条件,无法继续使用索引扫描匹配 C
C < xxx 会在 A = xxx 过滤后的结果上再做回表或筛选
联合索引(a,b,c) ,查询条件 where b > xxx and a = x 会生效吗
会生效,优化器会重新排序 where
联合索引 (a, b,c),where条件是 a=2 and c = 1,能用到联合索引吗?
会用到联合索引,但是只有 a 才能走索引,c 无法走索引,因为不符合最左匹配原则。虽然 c 无法走索引, 但是 c 字段在 5.6 版本之后,会有索引下推的优化,能减少回表查询的次数
什么情况下索引会失效
回答:
违反最左前缀法则(联合索引/复合索引)
如果索引了多列,要遵守最左前缀法则。指的是查询从索引的最左前列开始,并且不跳过索引中的列
匹配最左前缀法则,走索引:
mysql> explain select * from tb_seller where name = '小米科技';id select_type table partitions type possible_keys key key_len ref rows filtered Extra 1 SIMPLE tb_seller NULL ref tb_seller_index tb_seller_index 303 const 1 100.00 NULL
mysql> explain select * from tb_seller where name = '小米科技' and status = '1';id select_type table partitions type possible_keys key key_len ref rows filtered Extra 1 SIMPLE tb_seller NULL ref tb_seller_index tb_seller_index 309 const,const 1 100.00 NULL
mysql> explain select * from tb_seller where name = '小米科技' and status = '1' and address = '北京市';id select_type table partitions type possible_keys key key_len ref rows filtered Extra 1 SIMPLE tb_seller NULL ref tb_seller_index tb_seller_index 612 const,const,const 1 100.00 NULL 违反最左前缀法则,索引失效: 查询条件:
status = '1' and address = '北京市'
mysql> explain select * from tb_seller where status = '1' and address = '北京市';id select_type table partitions type possible_keys key key_len ref rows filtered Extra 1 SIMPLE tb_seller NULL ALL NULL NULL NULL NULL 12 8.33 Using where
mysql> explain select * from tb_seller where status = '1';查询条件:status = '1'id select_type table partitions type possible_keys key key_len ref rows filtered Extra 1 SIMPLE tb_seller NULL ALL NULL NULL NULL NULL 12 10.00 Using where **符合最左法则,但跳跃某一列,只有最左列索引生效:**
name = '小米科技' and address = '北京市'
mysql> explain select * from tb_seller where name = '小米科技' and address = '北京市';id select_type table partitions type possible_keys key key_len ref rows filtered Extra 1 SIMPLE tb_seller NULL ref tb_seller_index tb_seller_index 303 const 1 10.00 Using index condition 范围查询右边的列,不能使用索引
mysql> explain select * from tb_seller where name = '小米科技' and status = '1' and address = '北京市';id select_type table partitions type possible_keys key key_len ref rows filtered Extra 1 SIMPLE tb_seller NULL ref tb_seller_index tb_seller_index 612 const,const,const 1 100.00 NULL
mysql> explain select * from tb_seller where name = '小米科技' and status > '1' and address = '北京市';id select_type table partitions type possible_keys key key_len ref rows filtered Extra 1 SIMPLE tb_seller NULL range tb_seller_index tb_seller_index 309 NULL 1 10.00 Using index condition 根据前面的两个字段 name、status 查询是走索引的,但是最后一个条件 address 没有用到索引
在索引列上进行运算操作,索引将失效
mysql> select * from tb_seller where substring(name, 3, 2) = '科技';sellerid name nickname password status address createtime baidu 百度科技有限公司 百度小店 e10adc3949ba59abbe56e057f20f883e 1 北京市 2088-01-01 12:00:00 huawei 华为科技有限公司 华为小店 e10adc3949ba59abbe56e057f20f883e 0 北京市 2088-01-01 12:00:00 luoji 罗技科技有限公司 罗技小店 e10adc3949ba59abbe56e057f20f883e 1 北京市 2088-01-01 12:00:00 ourpalm 掌趣科技股份有限公司 掌趣小店 e10adc3949ba59abbe56e057f20f883e 1 北京市 2088-01-01 12:00:00 qiandu 千度科技 千度小店 e10adc3949ba59abbe56e057f20f883e 2 北京市 2088-01-01 12:00:00 sina 新浪科技有限公司 新浪官方旗舰店 e10adc3949ba59abbe56e057f20f883e 1 北京市 2088-01-01 12:00:00 xiaomi 小米科技 小米官方旗舰店 e10adc3949ba59abbe56e057f20f883e 1 西安市 2088-01-01 12:00:00
mysql> explain select * from tb_seller where substring(name, 3, 2) = '科技';id select_type table partitions type possible_keys key key_len ref rows filtered Extra 1 SIMPLE tb_seller NULL ALL NULL NULL NULL NULL 12 100.00 Using where 在索引列上进行运算操作(如 substring(name, 3, 2)),会导致索引失效,查询时会进行全表扫描
字符串不加单引号,造成索引失效
mysql> explain select * from tb_seller where name = '科技' and status = '0';id select_type table partitions type possible_keys key key_len ref rows filtered Extra 1 SIMPLE tb_seller NULL ref tb_seller_index tb_seller_index 309 const,const 1 100.00 NULL
mysql> explain select * from tb_seller where name = '科技' and status = 0;id select_type table partitions type possible_keys key key_len ref rows filtered Extra 1 SIMPLE tb_seller NULL ref tb_seller_index tb_seller_index 303 const 1 10.00 Using index condition 由于在查询中没有对字符串加单引号,MySQL的查询优化器会自动进行类型转换,导致索引失效
以
% 开头的 Like 模糊查询,索引失效
mysql> explain select sellerid, name from tb_seller where name like '%黑马程序员%';id select_type table partitions type possible_keys key key_len ref rows filtered Extra 1 SIMPLE tb_seller NULL ALL NULL NULL NULL NULL 12 11.11 Using where
mysql> explain select sellerid, name from tb_seller where name like '%黑马程序员';id select_type table partitions type possible_keys key key_len ref rows filtered Extra 1 SIMPLE tb_seller NULL ALL NULL NULL NULL NULL 12 11.11 Using where 如果仅仅是尾部模糊匹配,索引不会失效:
mysql> explain select sellerid, name from tb_seller where name like '黑马程序员%';id select_type table partitions type possible_keys key key_len ref rows filtered Extra 1 SIMPLE tb_seller NULL range tb_seller_index tb_seller_index 303 NULL 1 100.00 Using index condition - 如果是头部模糊匹配(以
% 开头),索引会失效,导致全表扫描 - 如果仅仅是尾部模糊匹配(以
% 结尾),索引不会失效,可以正常使用索引进行查询
- 如果是头部模糊匹配(以
如果一个列既是单列索引,又是联合索引,单独查它的话先走哪个?
mysql 优化器会分析每个索引的查询成本,然后选择成本最低的方案来执行 sql
如果单列索引是 a,联合索引是(a ,b),那么针对下面这个查询:
select a, b from table where a = ? and b =?优化器会选择联合索引,因为查询成本更低,查询也不需要回表,直接索引覆盖了
======= 事务 =======
事务的特性
事务代表一系列操作的集合,构成一个不可分割的工作单元。事务将所有操作视为一个整体,一并提交至系统或撤销操作请求,确保这些操作要么全部成功,要么全部失败
事务特性:ACID
- 原子性(Atomicity):事务作为不可分割的最小操作单元,须保证要么完全成功,要么完全失败
- 一致性(Consistency):事务执行完毕后,确保所有数据均保持一致状态
- 隔离性(Isolation):数据库系统通过隔离机制,确保事务在不受外部并发操作干扰的独立环境中运行
- 持久性(Durability):一旦事务提交或回滚,其对数据库数据的变更即成为永久性记录
结合转账等案例说明
- 持久性是通过 redo log (重做日志)来保证的
- 原子性是通过 undo log(回滚日志) 来保证的
- 隔离性是通过 MVCC(多版本并发控制) 或锁机制来保证的
- 一致性则是通过持久性+原子性+隔离性来保证
并发事务带来哪些问题
| 问题 | 描述 |
|---|---|
| 脏读 | 一个事务读到另一个事务还没有提交的数据 |
| 不可重复读 | 一个事务先后读取同一条记录,但两次读取的数据不同,称之为不可重复读 |
| 幻读(前提是可重复读) | 一个事务按照条件查询数据时,没有对应的数据行,但是在插入数据时,又发现这行数据已经存在,好像出现了“幻影” |
事务隔离
事务隔离级别越高,数据越安全,但是性能越低
| 隔离级别 | 脏读 | 不可重复读 | 幻读 |
|---|---|---|---|
| Read uncommitted 未提交读 | ✅ | ✅ | ✅ |
| Read committed 读已提交 | ❌ | ✅ | ✅ |
| Repeatable Read(默认) 可重复读 | ❌ | ❌ | ✅ |
| Serializable 串行读 | ❌ | ❌ | ❌ |
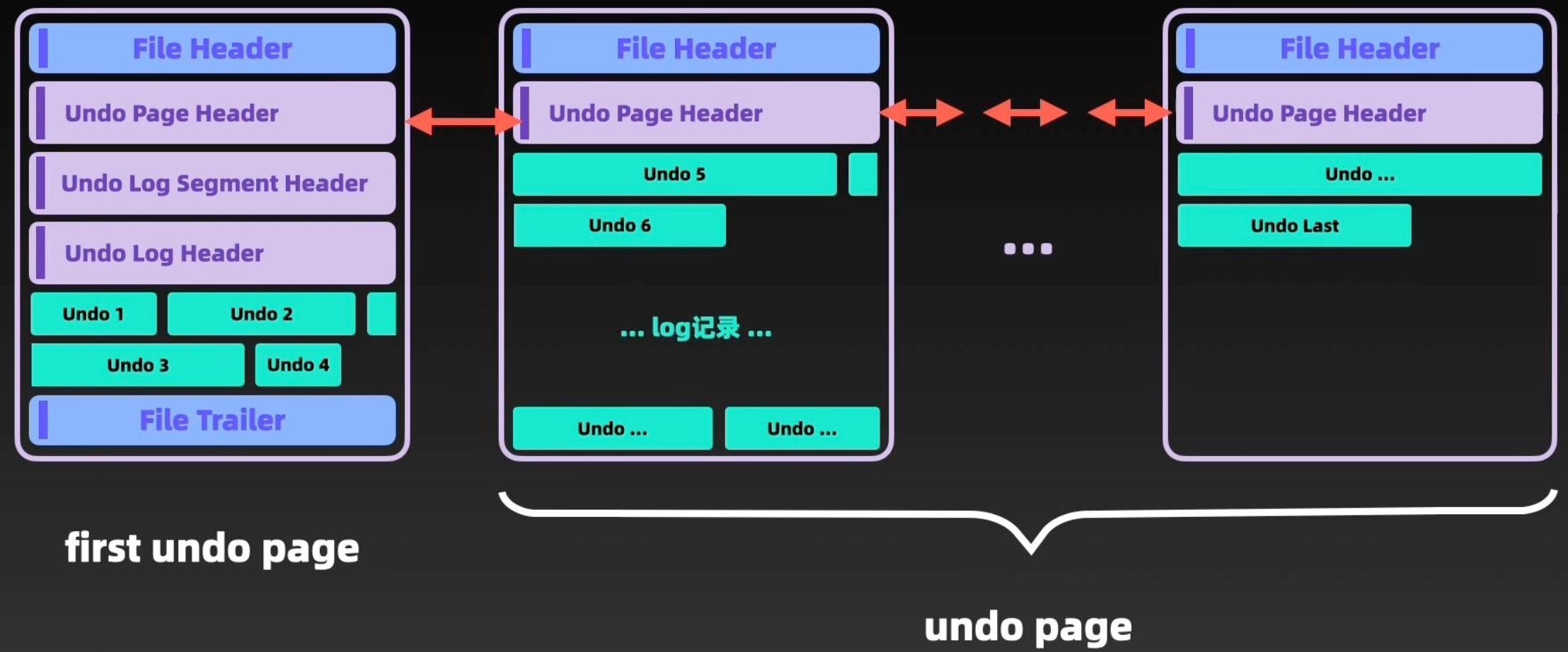
redo-log 和 undo-log 的区别
回答:
在数据库系统中,Redo Log 主要记录的是数据页的物理变化,其在服务宕机时,可用于数据同步。与之相对的,Undo Log 则主要记录逻辑日志。在事务回滚时,通过逆操作来恢复原始数据。例如,当我们删除一条数据时,Undo Log 日志文件中会新增一条DELETE语句;若发生回滚,则执行相应的逆操作
Redo Log 确保了事务的持久性,而Undo Log 则保障了事务的原子性和一致性



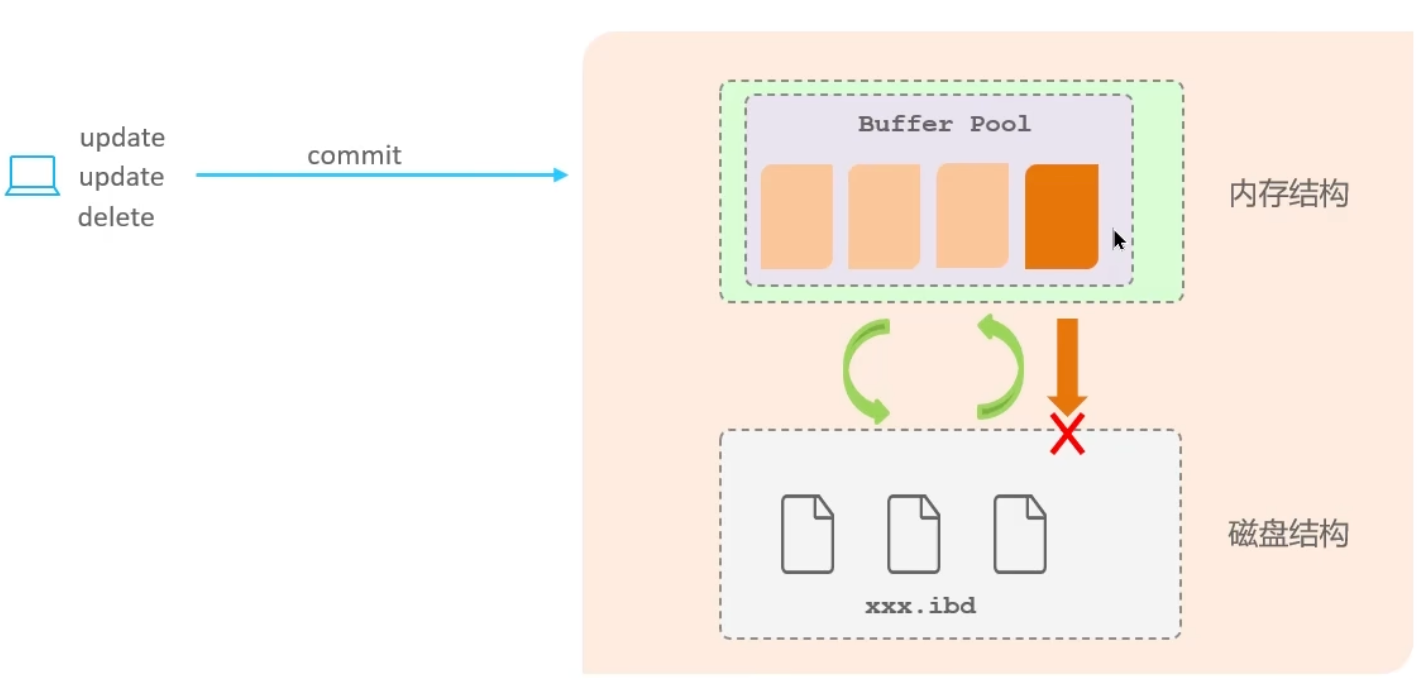
缓冲池(Buffer Pool): 主内存中的特定区域,用于缓存磁盘上频繁操作的真实数据。在执行增删改查操作时,首先对缓冲池中的数据进行操作(若缓冲池内无数据,则从磁盘加载并缓存)。以一定频率将缓冲池数据刷新回磁盘,以此减少磁盘I/O操作,提升处理速度
数据页(Page): InnoDB存储引擎在磁盘管理中的最小单元,每个页的默认大小为16KB。页中存储的是行数据
操作时会先看 buffer pool 里面有没有,没有就从磁盘加载进缓冲池,操作完成后,按照一定频率写回磁盘,减少了磁盘的 IO 次数
服务器宕机,会导致内存中的数据还没来得及写入磁盘就丢失,违背了持久化原则
redo log
重做日志记录的是事务提交时数据页的物理修改,其核心作用在于确保事务的持久性
此日志文件由两部分构成:重做日志缓冲(Redo Log Buffer)与重做日志文件(Redo Log File)。前者位于内存之中,后者则存储于磁盘。在事务提交后,所有修改信息将被存入该日志文件。这不仅用于在刷新脏页至磁盘的过程中提供支持,亦在发生错误时,为数据恢复提供依据
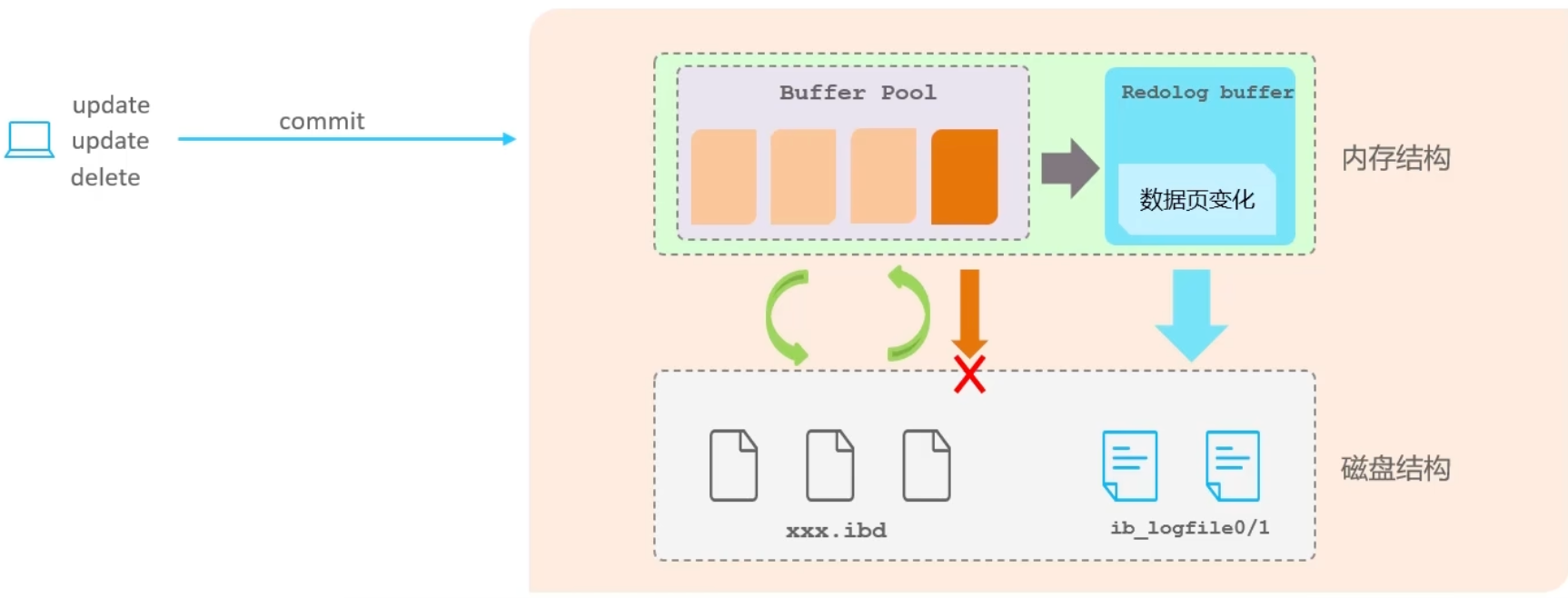
如果不用redo log,当数据页发生变化后直接进行同步,但操作可能包含多条,这时是随机的磁盘 IO,性能低,使用日志文件都是追加的,是顺序的磁盘 IO
undo log
回滚日志,用于记录数据被修改前的信息,其作用主要包括提供回滚和MVCC(多版本并发控制)。与undo log和redo log记录物理日志不同,它是逻辑日志
- 可以认为,当执行delete操作删除一条记录时,undo log中会记录一条对应的insert记录;反之亦然
- 当执行update操作修改一条记录时,它记录一条相反方向的update记录。当执行rollback操作时,就可以从undo log中的逻辑记录读取相应内容,并完成回滚
undo log可以实现事务的一致性和原子性
MVCC 多版本并发控制(Multi-Version Concurrency Control)
回答:
事务的隔离性是通过锁和MVCC(多版本并发控制)实现的。其中,MVCC指的是维护数据的多个版本,确保读写操作不会发生冲突。其底层实现主要分为三个部分:
- 隐藏字段:在MySQL中,每个表都设有隐藏字段,包括
trx_id(事务ID)和roll_pointer(回滚指针)trx_id记录每次操作的事务ID,且为自增roll_pointer指向上一个版本的事务版本记录地址 - Undo Log日志:主要记录回滚日志,存储老版本数据。在内部,它形成一个版本链,当多个事务并行操作某一行记录时,记录不同事务修改数据的版本。通过
roll_pointer指针形成一个链表 - ReadView:解决事务查询选择版本的问题。内部定义了匹配规则和当前事务ID,用以判断访问哪个版本的数据。不同隔离级别的快照读产生的结果不同。在 读已提交(Read Committed) 隔离级别下,每次执行快照读时都会重新生成ReadView;而在 可重复读(Repeatable Read) 隔离级别下,仅在事务中第一次执行快照读时生成ReadView,后续复用该ReadView
指维护一个数据的多个版本,使得读写操作没有冲突
MVCC的具体实现,主要依赖于数据库记录中的隐式字段、undo log日志、readView
实现原理
记录中的隐藏字段
| id | age | name |
|---|---|---|
| 1 | 1 | tom |
| 3 | 3 | cat |
| id | age | name | DB_TRX_ID | DB_ROLL_PTR | DB_ROW_ID |
|---|---|---|---|---|---|
| 1 | 1 | tom | |||
| 3 | 3 | cat |
隐藏字段及其含义
| 隐藏字段 | 含义 |
|---|---|
| DB_TRX_ID | 最近修改事务ID,记录插入这条记录或最后一次修改该记录的事务ID |
| DB_ROLL_PTR | 回滚指针,指向这条记录的上一个版本,用于配合 undo log,指向上一个版本 |
| DB_ROW_ID | 隐藏主键,如果表结构没有指定主键,将会生成该隐藏字段 |
undo log
回滚日志,于insert、update、delete操作时生成,旨在便于数据回滚
在insert操作时,生成的undo log日志仅在回滚时需要,事务提交后,可被立即删除
而update、delete操作时,产生的undo log日志不仅在回滚时需要,MVCC版本访问亦需,故不会立即被删除
undo log 版本链
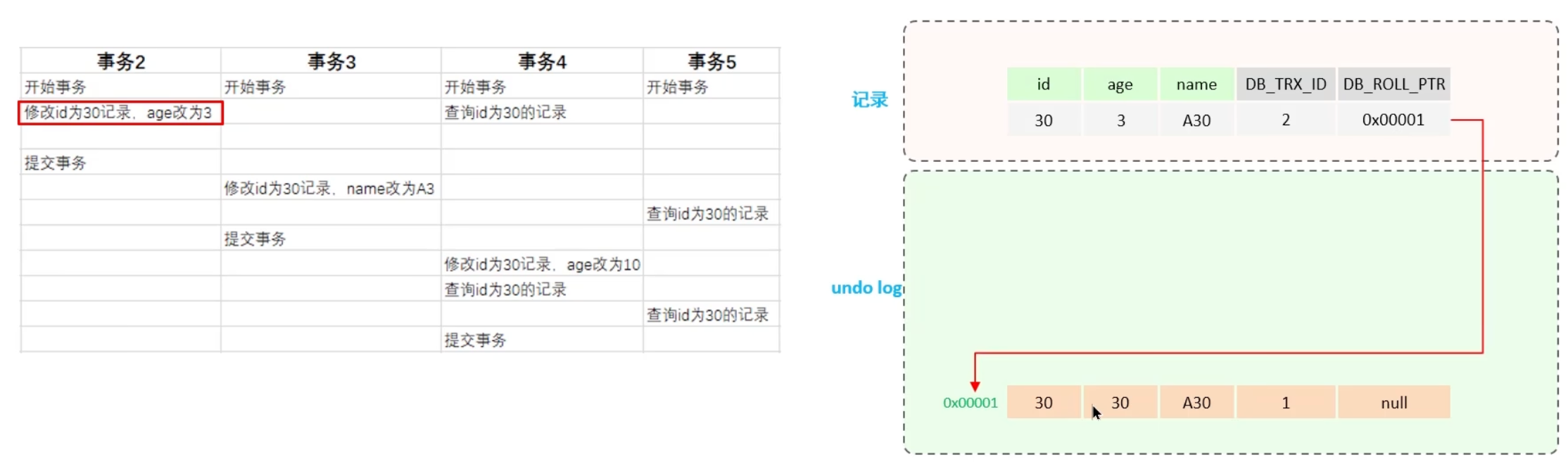
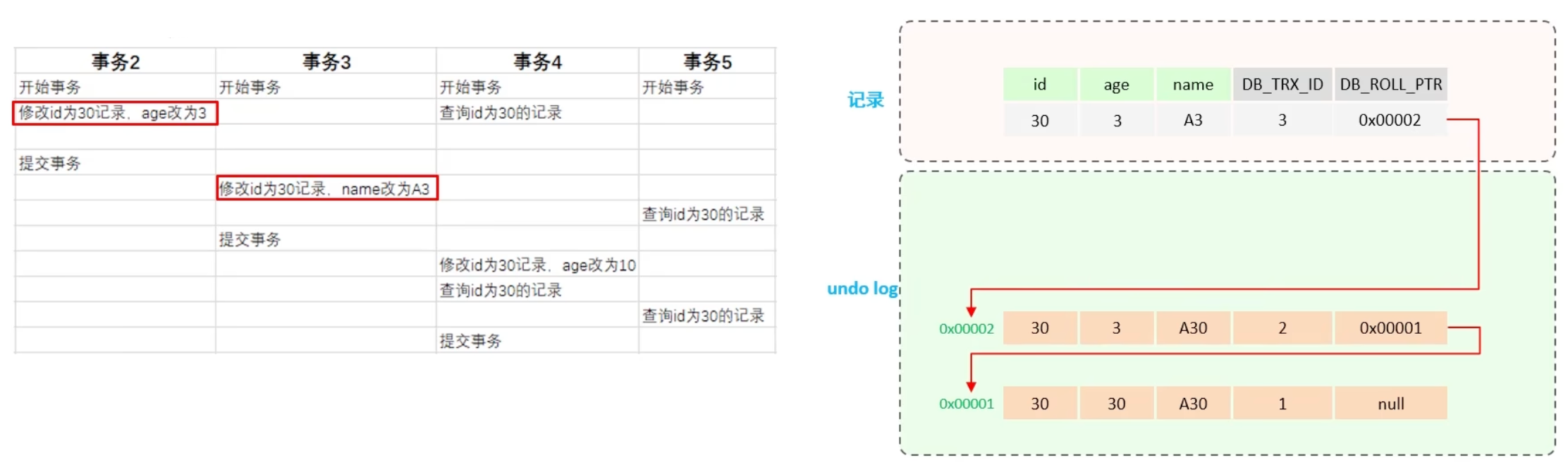
对于不同事务或相同事务对同一记录的修改,将生成一条记录的undo日志版本链表。链表的头部代表最新的旧记录,而尾部则是最早的旧记录
ReadView
ReadView(读视图)是快照读在SQL执行时MVCC提取数据的依据,记录并维护系统当前活跃的事务(未提交的)ID
当前读
读取的是记录的最新版本,读取时还需保证其他并发事务不能修改当前记录,会对读取的记录进行加锁。对于我们日常的操作,如:
SELECT ... LOCK IN SHARE MODE(共享锁)、SELECT ... FOR UPDATE、UPDATE、INSERT、DELETE(排他锁)都是一种当前读
快照读
简单的SELECT(不加锁)就是快照读。快照读读取的是记录数据的可见版本,有可能是历史数据,不加锁,是非阻塞读
- Read Committed:每次
SELECT都会生成一个快照读 - Repeatable Read:开启事务后第一个
SELECT语句才是快照读的发生点
readview 中包含的核心字段:
| 字段 | 含义 |
|---|---|
| m_ids | 当前活跃的事务ID集合 |
| min_trx_id | 最小活跃事务ID |
| max_trx_id | 预分配事务ID,当前最大事务ID+1(因为事务ID是自增的) |
| creator_trx_id | ReadView创建者的事务ID |
版本链数据访问规则
trx_id == creator_trx_id- 可以访问该版本
- 说明:数据是当前事务更改的
trx_id < min_trx_id- 可以访问该版本
- 说明:数据已经提交
trx_id > max_trx_id- 不可以访问该版本
- 说明:事务在 ReadView 生成后才开启
min_trx_id <= trx_id <= max_trx_id- 如果
trx_id 不在m_ids 中,可以访问该版本 - 说明:数据已经提交
- 如果
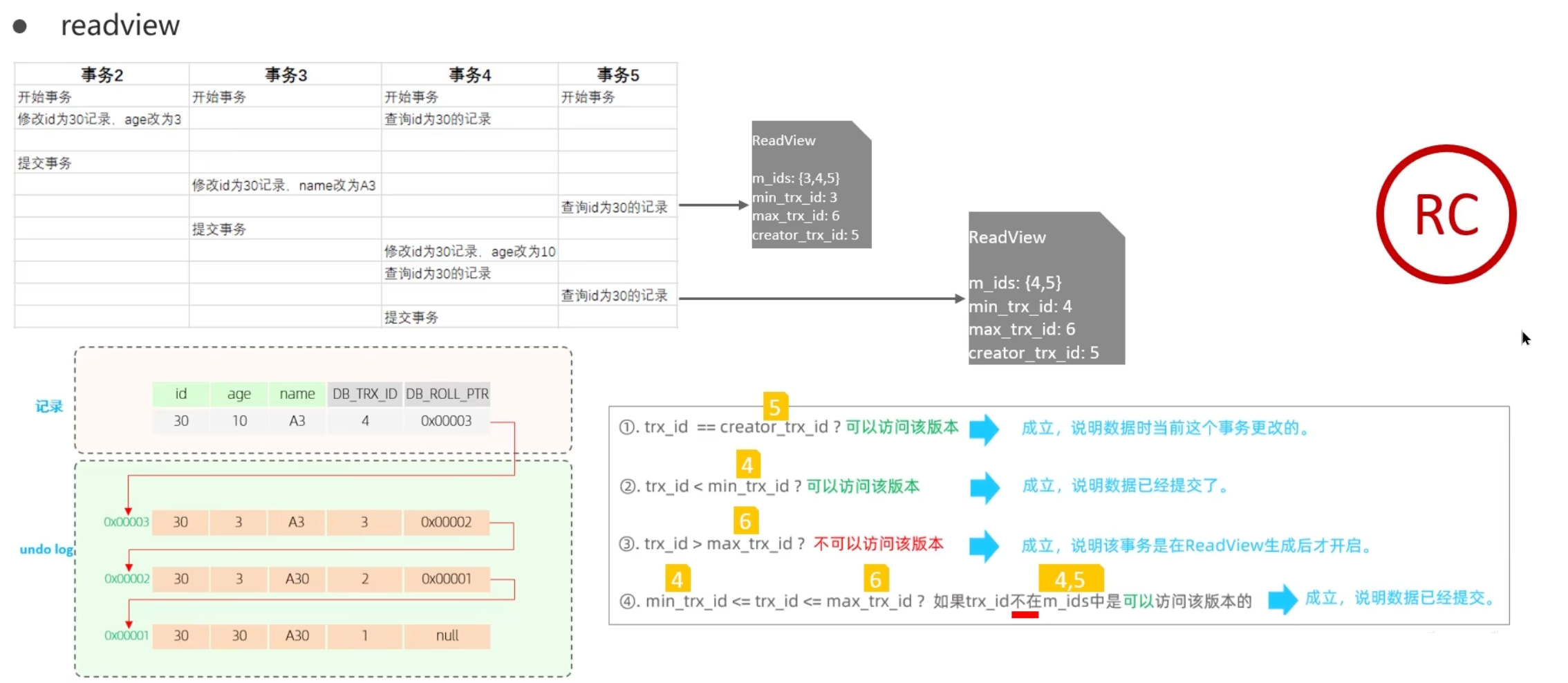
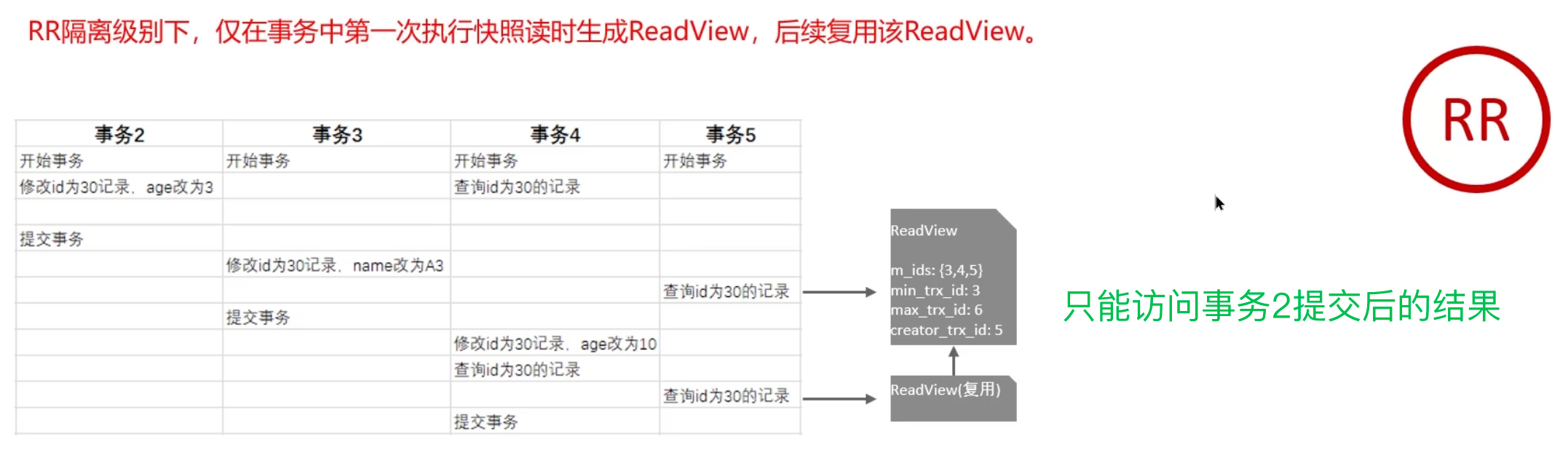
可重复读下的幻读问题
| id | name | score |
|---|---|---|
| 1 | 小林 | 50 |
| 2 | 小明 | 60 |
| 3 | 小红 | 70 |
| 4 | 小蓝 | 80 |
行为分析:
事务 A 首次查询 (
SELECT * FROM t_stu WHERE id = 5; )- 这是快照读 (Snapshot Read)
- 在事务 A 开始(或执行第一次读操作)时,InnoDB 会为事务 A 创建一个读视图 (Read View)
- 此时,
id = 5 的记录不存在,所以读视图中没有这条记录 - 结果:
Empty set。这是符合可重复读隔离级别下 MVCC 的预期的。事务 A 看到的是它启动时的数据快照
事务 B 插入并提交 (
INSERT INTO t_stu VALUES(5, '小美', 18); COMMIT; )- 事务 B 成功插入了一条
id = 5 的记录并提交。现在数据库的最新状态包含了这条记录
- 事务 B 成功插入了一条
事务 A 更新 (
UPDATE t_stu SET name = '小美更新' WHERE id = 5; )- 这是关键的一步!
UPDATE 语句执行时,它需要找到并锁定目标行。这个过程是一个当前读 (Current Read) - 当前读会读取数据库中最新的已提交版本的数据,而不是事务开始时的快照
- 因此,事务 A 的
UPDATE 语句能够“看到”并找到事务 B 提交的id = 5 这条记录 -
UPDATE 成功执行,它修改了这条记录(这条记录现在被认为是事务 A 修改过的)
- 这是关键的一步!
事务 A 再次查询 (
SELECT * FROM t_stu WHERE id = 5; )- 这仍然是一个快照读
- 根据 MVCC 的规则,一个事务总是能看到它自己所做的修改
- 由于事务 A 在上一步通过
UPDATE 语句修改了id = 5 这条记录,这条记录(现在是(5, '小美更新', 18))对于事务 A 来说是可见的 - 结果:事务 A 看到了
(5, '小美更新', 18)
InnoDB 如何在一定程度上“解决”幻读:
对于快照读,MVCC 机制保证了在同一个事务中多次执行相同的
SELECT 语句时,如果查询条件不变,看到的结果集总是一致的,从而避免了这类幻读对于当前读(如
SELECT ... FOR UPDATE 或UPDATE 语句),InnoDB 使用 Next-Key Locks (间隙锁 + 记录锁) 来锁定一个范围,防止其他事务在这个范围内插入新的记录,从而避免当前读场景下的幻读- 在这个例子中,第一次
SELECT 是快照读,并没有对id=5 这个“空位”加间隙锁。所以事务 B 可以成功插入。当事务 A 执行UPDATE 时,它直接去锁定id=5 这条已存在的记录
- 在这个例子中,第一次
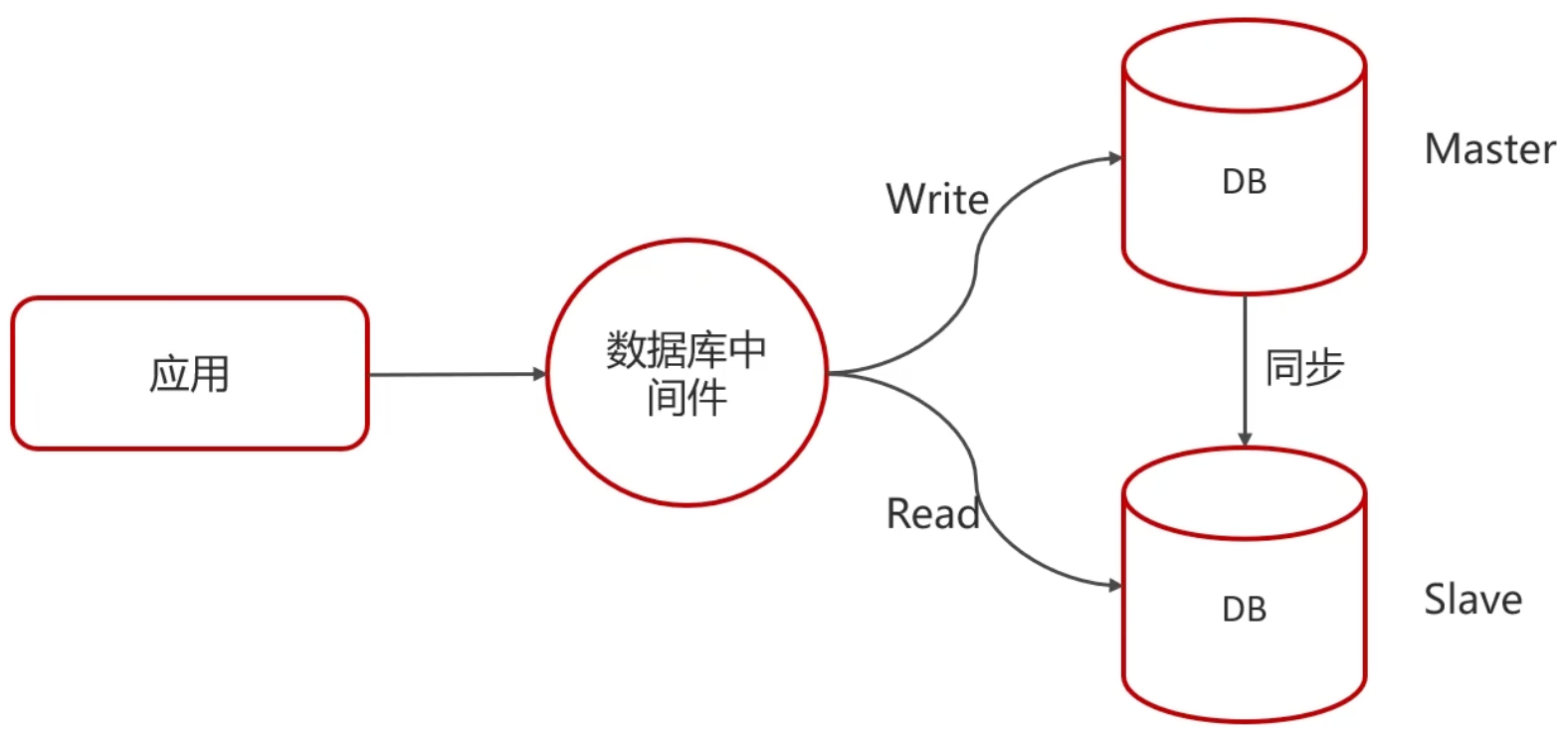
主从同步原理
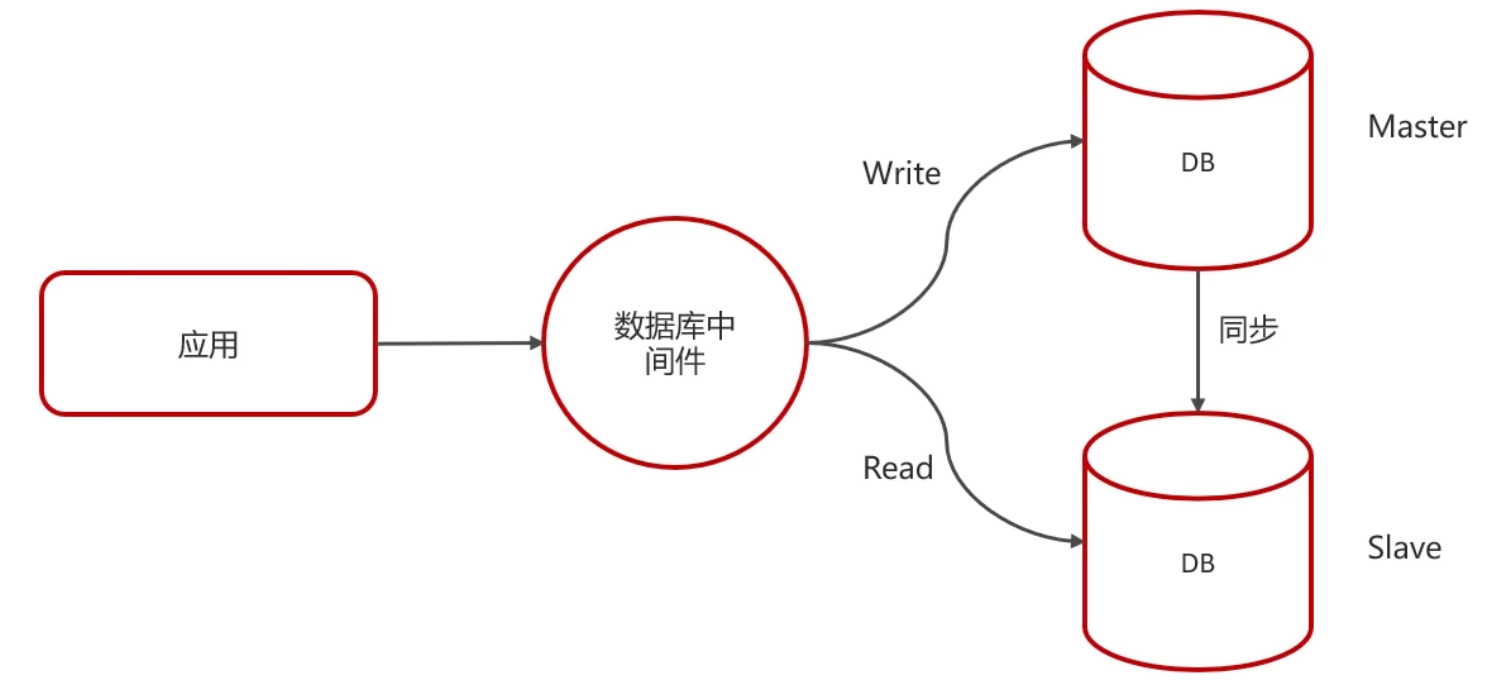
主从复制的核心在于二进制日志
二进制日志(BINLOG)详尽地记录了所有的DDL(数据定义语言)语句与DML(数据操纵语言)语句,然而,不包括数据查询(SELECT、SHOW)语句
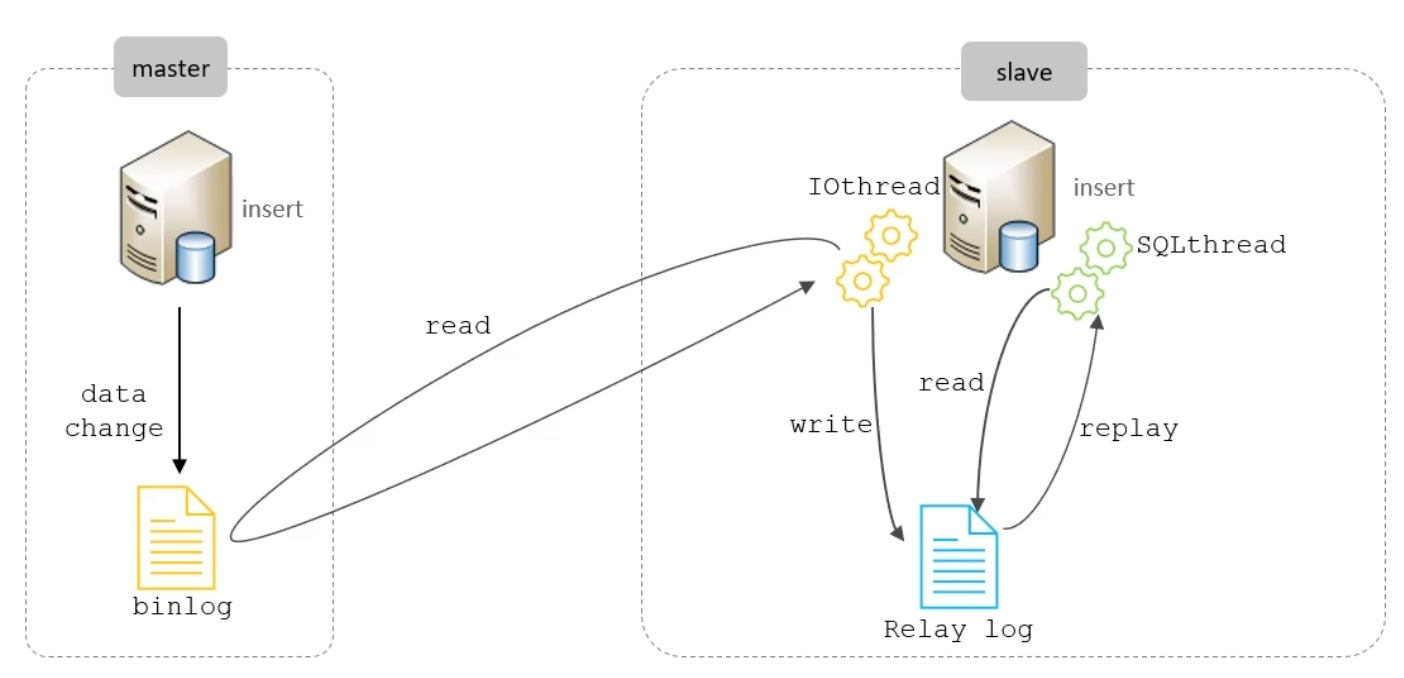
复制过程分为三步:
- Master主库在事务提交时,会将数据变更记录在二进制日志文件Binlog中
- 从库读取主库的二进制日志文件Binlog,并将之写入到从库的中继日志Relay Log
- Slave重做中继日志中的事件,从而将变更反映至自身的数据
一条update是不是原子性的?
是原子性,主要通过锁+undolog 日志保证原子性的
- 执行 update 的时候,会加行级别锁,保证了一个事务更新一条记录的时候,不会被其他事务干扰
- 事务执行过程中,会生成 undolog,如果事务执行失败,就可以通过 undolog 日志进行回滚
滥用事务,或者一个事务里有特别多sql的弊端?
事务的资源在事务提交之后才会释放的,比如存储资源、锁
如果一个事务特别多 sql,那么会带来这些问题:
- 如果一个事务特别多 sql,锁定的数据太多,容易造成大量的死锁和锁超时
- 回滚记录会占用大量存储空间,事务回滚时间长。在MySQL中,实际上每条记录在更新的时候都会同时记录一条回滚操作。记录上的最新值,通过回滚操作,都可以得到前一个状态的值,sql 越多,所需要保存的回滚数据就越多
- 执行时间长,容易造成主从延迟,主库上必须等事务执行完成才会写入binlog,再传给备库。所以,如果一个主库上的语句执行10分钟,那这个事务很可能就会导致从库延迟10分钟
MySQL 分库分表
回答:
业务介绍
- 根据简历上的项目经验,构思一个数据量较大的业务(如请求数量众多或业务累积数据量巨大)
- 确定业务达到的量级(例如,单表数据量达到1000万条或超过20GB)
具体拆分策略
- 水平分库:将一个数据库中的数据分散至多个数据库中,以此解决海量数据存储和高并发的问题
- 水平分表:通过此方法解决单表存储容量和性能的瓶颈
水平拆分中间件
- 使用中间件解决拆分后可能出现的问题,如
sharding-sphere、mycat等
- 垂直分库:根据业务需求进行数据库拆分,在高并发情况下提升磁盘I/O和网络连接数。(常用)
- 垂直分表:实现冷热数据分离,确保多表之间互不影响。(常用)
分库分表的时机
- 前提:项目业务数据量逐渐增长,或业务发展迅速,单表数据量达到1000万条或20GB以上
- 优化措施已无法解决性能问题(如主从读写分离、查询索引等)
- 遇到瓶颈(包括磁盘IO、网络带宽等)、CPU瓶颈(如聚合查询、连接数过多等)
拆分策略
垂直分库
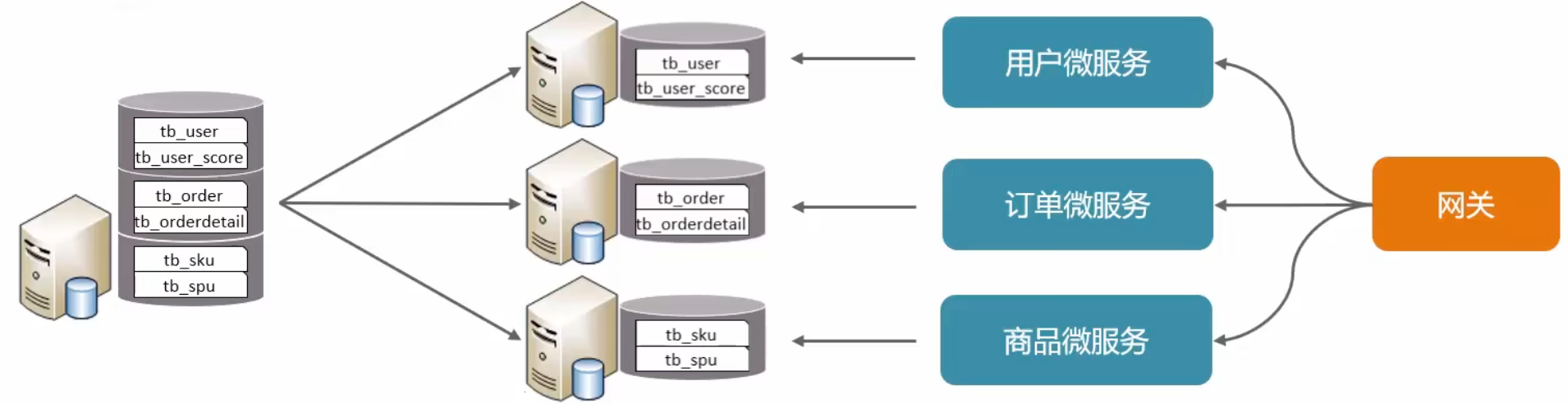
垂直分库:以表为依据,根据业务需求,将不同的表拆分至独立的数据库中
特点:
- 按业务对数据进行分级管理、维护、监控及扩展
- 在高并发环境下,提升磁盘I/O性能和数据连接数
垂直分表
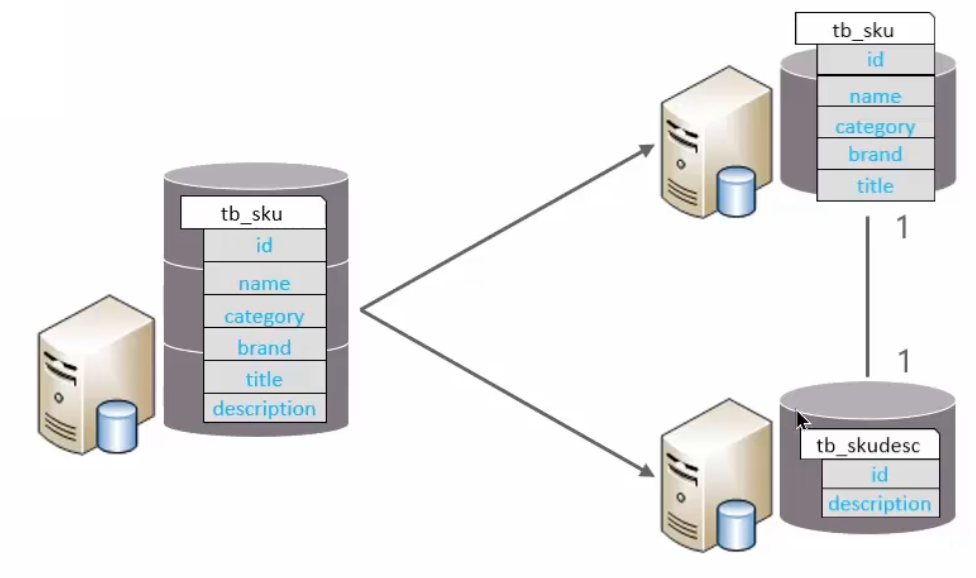
垂直分表:依据字段属性,将不同字段分配至不同的表中
特点:
- 冷热数据分离
- 降低 IO 过渡争抢,两表互不干扰
拆分规则:
将不常用字段独立放置于一张表中
将text、blob等大字段拆分并置于附属表中
水平分库
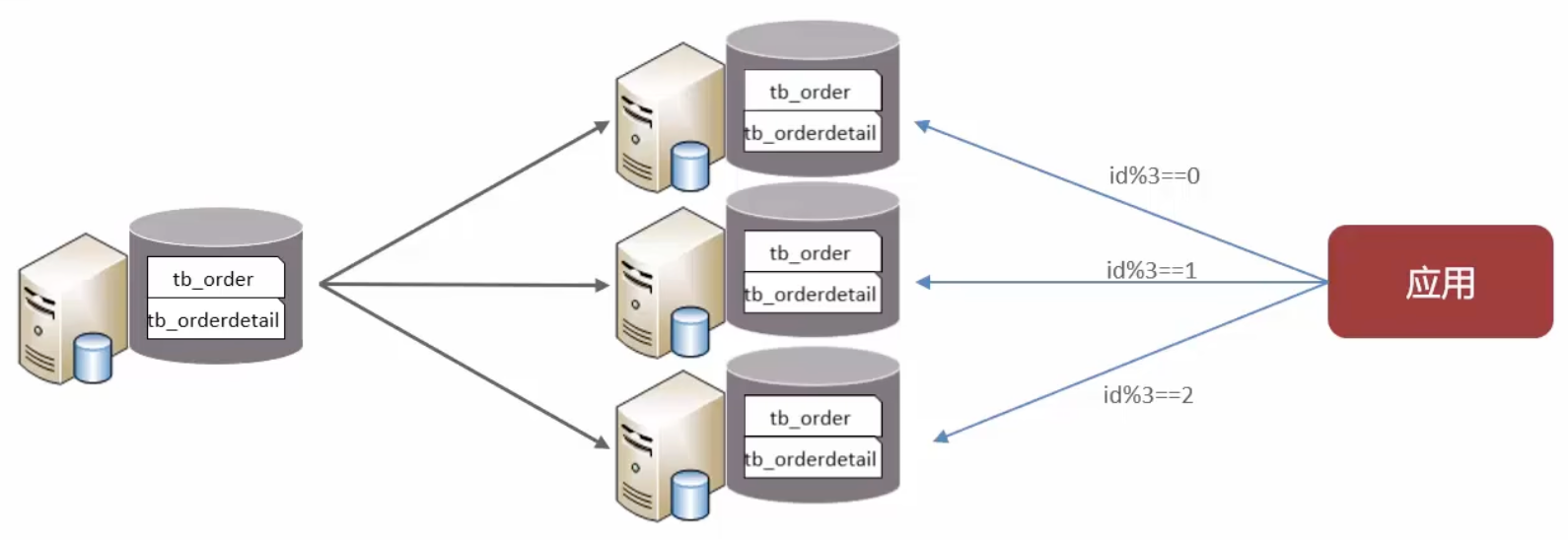
水平分库:将库中数据拆分至多个库中
特点:
- 解决了单库大数量、高并发下的性能瓶颈问题
- 提升了系统的稳定性和可用性
路由规则
- 根据ID节点进行取模操作
- 按ID进行范围路由,节点1:ID范围(1-100万)
- 节点2:ID范围(100万-200万)
水平分表
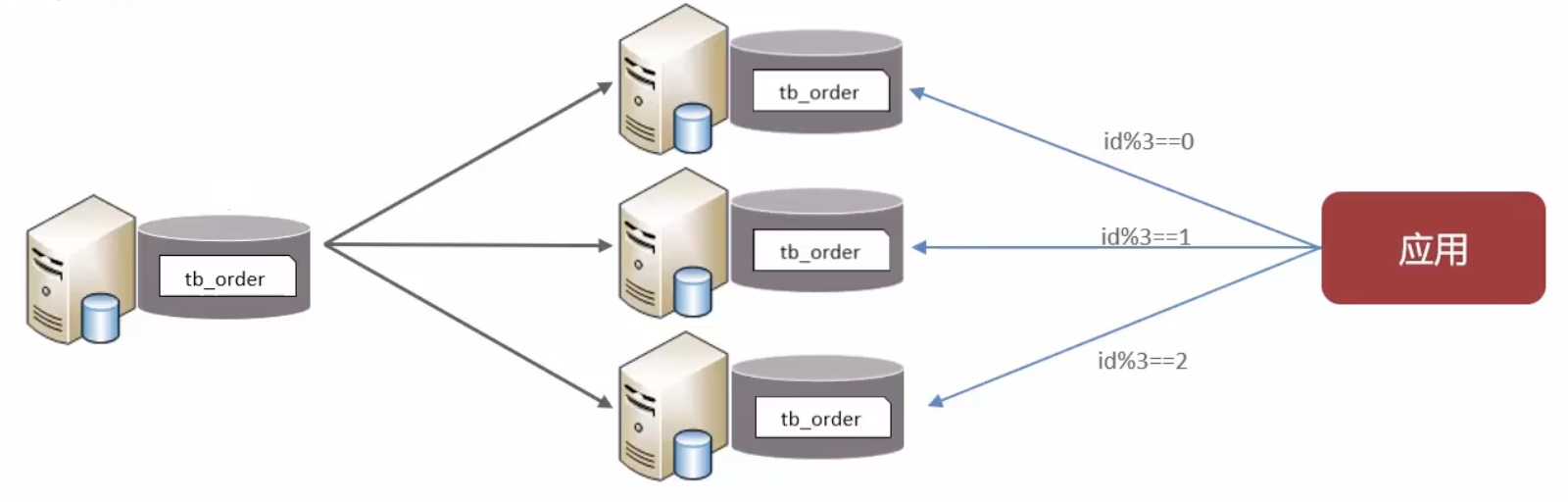
水平分表:将一个表的数据拆分至多个表中(可在同一数据库内)
特点:
- 优化因单一表数据量过大而产生的性能问题
- 避免I/O争抢并减少锁表的几率
拆分后的问题
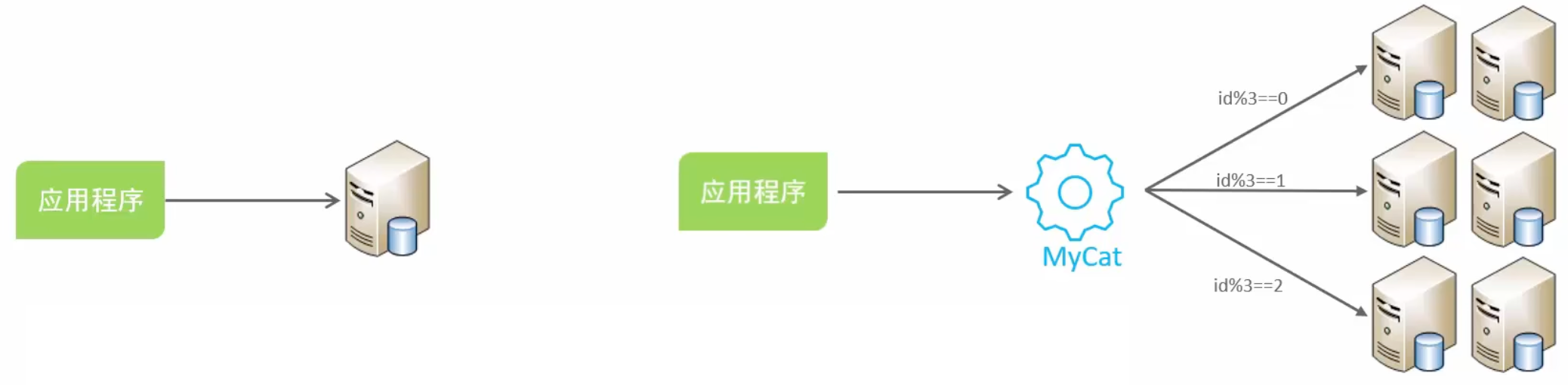
分库之后面临的问题:
- 分布式事务一致性
- 跨节点关联查询
- 跨节点分页、排序函数
- 主键防重复
分库分表中间件:
- ShardingSphere
- Mycat
======= 锁 =======
MySQL 有哪些锁
MySQL 锁概述
锁主要用于管理对共享资源的并发访问。MySQL 的锁可以从不同维度进行划分:
- 按锁的粒度划分:全局锁、表级锁、行级锁(InnoDB 特定)、页级锁(BDB、NDB引擎,不常用)
- 按锁的共享模式(或操作类型)划分:共享锁(读锁)、排他锁(写锁)
- 按加锁方式划分:隐式锁(由存储引擎自动添加)、显式锁(用户手动指定)
- 其他特定锁:意向锁、自增锁(AUTO-INC Lock)、元数据锁(MDL)等
MySQL 主要锁类型
| 锁类别 | 锁名称 (中文/英文) | 锁粒度 | 主要引擎 | 主要特点和用途 |
|---|---|---|---|---|
| 全局锁 | 全局锁 (Global Lock) | 全局 | MySQL Server | FLUSH TABLES WITH READ LOCK (FTWRL)。锁定整个数据库实例,使整个库处于只读状态。通常用于全库逻辑备份。对线上业务影响大 |
| 表级锁 | 表锁 (Table Lock) | 表 | MyISAM, InnoDB | MyISAM 默认。InnoDB 中通常指通过 LOCK TABLES ... READ/WRITE 显式加的表锁,或者在没有合适索引导致行锁升级为表锁的情况。开销小,加锁快;不会出现死锁;锁定粒度大,发生锁冲突的概率最高,并发度最低 |
| 元数据锁 (Metadata Lock, MDL) | 表 | MySQL Server | MySQL 5.5 引入。保护表结构(元数据)的一致性。DML 操作需要共享MDL,DDL 操作需要独占MDL。DML和DDL之间会互斥 | |
| 意向共享锁 (Intention Shared, IS) | 表 | InnoDB | 事务想要获取一张表中某些行的共享锁 | |
| 意向排他锁 (Intention Exclusive, IX) | 表 | InnoDB | 事务想要获取一张表中某些行的排他锁 | |
| 自增锁 (AUTO-INC Lock) | 表 | InnoDB | 特殊的表级锁,用于处理自增列 (AUTO_INCREMENT)。并发插入时,需要获取此锁来分配自增值。可通过 innodb_autoinc_lock_mode 配置模式 | |
| 行级锁 | 记录锁 (Record Lock) | 行 | InnoDB | 锁定单个索引记录。如果表没有索引,InnoDB会创建隐藏的聚簇索引并使用记录锁 |
| (InnoDB) | 间隙锁 (Gap Lock) | 行之间 | InnoDB | 锁定索引记录之间的间隙,或者第一个索引记录之前的间隙,或最后一个索引记录之后的间隙。不锁定记录本身。防止其他事务在这个间隙中插入数据,解决部分幻读问题 |
| 临键锁 (Next-Key Lock) | 行及间隙 | InnoDB | 记录锁 + 间隙锁的组合。锁定一个索引记录以及该记录之前的间隙。InnoDB 在可重复读隔离级别下,范围查询默认使用临键锁,主要用于防止幻读 | |
| 插入意向锁 (Insert Intention Lock) | 行之间 | InnoDB | 一种特殊的间隙锁,在 INSERT 操作之前设置。如果多个事务向同一个索引间隙中插入不同位置的数据,它们之间不会阻塞 | |
| 共享/排他 | 共享锁 (Shared Lock, S锁) | 行/表 | InnoDB, MyISAM | 也称读锁。多个事务可以同时持有同一资源的S锁。事务持有S锁可以读取数据,但不能修改SELECT ... LOCK IN SHARE MODE |
| 排他锁 (Exclusive Lock, X锁) | 行/表 | InnoDB, MyISAM | 也称写锁。一个事务持有X锁时,其他事务不能获取该资源的任何锁(S或X)。事务持有X锁可以读取和修改数据SELECT ... FOR UPDATE, INSERT, UPDATE, DELETE 会自动加X锁 |
详细说明
1. 全局锁 (Global Lock)
- 命令:
FLUSH TABLES WITH READ LOCK (FTWRL) - 作用:让整个数据库实例处于只读状态。后续的 DML(数据操作语言)、DDL(数据定义语言)语句,以及更新事务的提交语句都会被阻塞
- 场景:主要用于做全库逻辑备份(如使用
mysqldump) - 风险:如果在主库上执行,会导致所有更新无法进行;如果在从库上执行,会导致从库无法执行主库同步过来的 binlog,造成主从延迟
- 替代方案:对于支持事务的引擎如 InnoDB,推荐使用
mysqldump --single-transaction 参数进行备份,它利用 MVCC 获取一致性快照,不会阻塞 DML
2. 表级锁 (Table Lock)
MyISAM 引擎:默认使用表级锁,分为表共享读锁(Table Read Lock)和表独占写锁(Table Write Lock)
InnoDB 引擎:
显式表锁:可以通过
LOCK TABLES t1 READ, t2 WRITE; 和UNLOCK TABLES; 来显式使用元数据锁 (MDL) :不需要显式使用,访问表时自动加上。MDL 锁是为了保证在对表结构进行变更(DDL)时,不会与正在进行的查询和DML操作冲突
- 对一张表做 CRUD 操作时,加 MDL 读锁(共享)
- 对一张表做表结构变更操作时,加 MDL 写锁(独占)
- MDL 读锁之间不互斥,MDL 写锁之间、MDL 读写锁之间互斥
意向锁 (Intention Lock) :
- 意向锁是表级别的锁,但它表明事务意图在表中的某些行上加锁(共享或排他)
- IS 锁:事务准备在某些行上加 S 锁
- IX 锁:事务准备在某些行上加 X 锁
- 作用:如果一个事务想获取整个表的 X 锁,它需要检查表上是否有其他事务持有的 IX/IS/S/X 锁。如果想获取表的 S 锁,需要检查是否有其他事务持有的 IX/X 锁。意向锁的存在使得 InnoDB 在判断表级锁兼容性时,无需逐行检查行锁,提高了效率。例如,当一个事务请求表级 X 锁时,如果发现表上已经存在 IX 锁,则说明有其他事务正在锁定某些行,表级 X 锁请求就会被阻塞
- 兼容性:意向锁之间是互相兼容的。IS 可以和 IS/IX 并存,IX 也可以和 IS/IX 并存。但意向锁会与表级 S 锁和表级 X 锁冲突(见下表)
X IX S IS X 冲突 冲突 冲突 冲突 IX 冲突 兼容 冲突 兼容 S 冲突 冲突 兼容 兼容 IS 冲突 兼容 兼容 兼容 自增锁 (AUTO-INC Lock) :
- 当表有
AUTO_INCREMENT 列时,插入操作需要获取这种特殊的表级锁来安全地生成自增值 -
innodb_autoinc_lock_mode 参数可以控制其行为模式(传统模式、连续模式、交错模式),影响并发插入性能
- 当表有
3. 行级锁 (Row Lock - InnoDB 核心)
InnoDB 实现了多种行级锁算法,它们都是针对索引记录加锁的
记录锁 (Record Lock) :
- 总是锁定索引记录。例如
SELECT * FROM t WHERE id = 1 FOR UPDATE;,会在id=1 的索引记录上加 X 型记录锁
- 总是锁定索引记录。例如
间隙锁 (Gap Lock) :
- 锁定一个开区间,比如
(3, 5)。它封禁了这个间隙,防止其他事务在这个间隙中插入新的满足条件的记录 - 间隙锁之间是兼容的,一个事务持有的间隙锁不会阻止其他事务在同一个间隙上加间隙锁
- 主要目的是为了防止幻读
- 锁定一个开区间,比如
临键锁 (Next-Key Lock) :
- 记录锁和间隙锁的组合,锁定一个左开右闭的区间。例如,一个临键锁可能覆盖
(3, 5],即锁定id=5 这条记录以及(3, 5) 这个间隙 - InnoDB 在可重复读 (Repeatable Read) 隔离级别下,对于范围查询和更新操作,默认会使用临键锁来避免幻读
- 例如
UPDATE t SET name = 'new' WHERE id > 3 AND id <= 5; 可能会在id=5 的记录上加临键锁,覆盖(previous_key_of_3, 5]
- 记录锁和间隙锁的组合,锁定一个左开右闭的区间。例如,一个临键锁可能覆盖
插入意向锁 (Insert Intention Lock) :
- 在
INSERT 操作执行前,会检查待插入位置的间隙是否被其他事务的间隙锁或临键锁覆盖。如果没有,会尝试获取插入意向锁 - 它是一种特殊的间隙锁,多个事务在同一个间隙中插入不同位置时,如果它们之间没有冲突,就不需要互相等待
- 在
共享锁 (S) 与排他锁 (X)
这是最基本的锁模式,可以应用于表级和行级
共享锁 (S锁, 读锁) :
-
SELECT ... LOCK IN SHARE MODE; - 允许多个事务同时读取同一资源
- 一个事务获取了 S 锁后,其他事务也可以获取该资源的 S 锁,但不能获取 X 锁
-
排他锁 (X锁, 写锁) :
-
SELECT ... FOR UPDATE; -
INSERT,UPDATE,DELETE 会自动隐式加 X 锁 - 只允许一个事务写入数据
- 一个事务获取了 X 锁后,其他事务不能获取该资源的任何锁(S 或 X)
-
行锁的兼容性:
| X (行) | S (行) | |
|---|---|---|
| X (行) | 冲突 | 冲突 |
| S (行) | 冲突 | 兼容 |
如何查看锁信息
-
SHOW OPEN TABLES WHERE In_use > 0; (查看表锁情况) -
SHOW ENGINE INNODB STATUS; (查看详细的 InnoDB 状态,包括最后一个死锁信息,锁等待等) -
SELECT * FROM information_schema.INNODB_TRX; (当前运行的所有事务) -
SELECT * FROM information_schema.INNODB_LOCKS; (当前出现的锁) -
SELECT * FROM information_schema.INNODB_LOCK_WAITS; (锁等待的对应关系)
(注意:INNODB_LOCKS 和INNODB_LOCK_WAITS 在 MySQL 8.0 中被performance_schema 下的表替代,如performance_schema.data_locks 和performance_schema.data_lock_waits)
======= 日志 =======
日志文件的种类
- redo log 重做日志,是 Innodb 存储引擎层生成的日志,实现了事务中的持久性,主要用于掉电等故障恢复
- undo log 回滚日志,是 Innodb 存储引擎层生成的日志,实现了事务中的原子性,主要用于事务回滚和 MVCC
- bin log 二进制日志,是 Server 层生成的日志,主要用于数据备份和主从复制
- relay log 中继日志,用于主从复制场景下,slave通过io线程拷贝master的bin log后本地生成的日志
- 慢查询日志,用于记录执行时间过长的sql,需要设置阈值后手动开启binlog 是追加写,写满一个文件,就创建一个新的文件继续写,不会覆盖以前的日志,保存的是全量的日志,用于备份恢复、主从复制
bin log
MySQL 在完成一条更新操作后,Server 层还会生成一条 binlog,等之后事务提交的时候,会将该事物执行过程中产生的所有 binlog 统一写 入 binlog 文件,binlog 是 MySQL 的 Server 层实现的日志,所有存储引擎都可以使用
binlog 是追加写,写满一个文件,就创建一个新的文件继续写,不会覆盖以前的日志,保存的是全量的日志,用于备份恢复、主从复制
binlog 文件是记录了所有数据库表结构变更和表数据修改的日志,不会记录查询类的操作,比如 SELECT 和 SHOW 操作
binlog 有 3 种格式类型,分别是 STATEMENT(默认格式)、ROW、 MIXED,区别如下:
- STATEMENT:每一条修改数据的 SQL 都会被记录到 binlog 中(相当于记录了逻辑操作,所以针对这种格式, binlog 可以称为逻辑日志),主从复制中 slave 端再根据 SQL 语句重现。但 STATEMENT 有动态函数的问题,比如你用了 uuid 或者 now 这些函数,你在主库上执行的结果并不是你在从库执行的结果,这种随时在变的函数会导致复制的数据不一致
- ROW:记录行数据最终被修改成什么(这种格式的日志,就不能称为逻辑日志了),不会出现 STATEMENT 下动态函数的问题。但 ROW 的缺点是每行数据的变化结果都会被记录,比如执行批量 update 语句,更新多少行数据就会产生多少条记录,使 binlog 文件过大,而在 STATEMENT 格式下只会记录一个 update 语句而已
- MIXED:包含了 STATEMENT 和 ROW 模式,它会根据不同的情况自动使用 ROW 模式和 STATEMENT 模式
有了 undo log 为什么还需要 redo log
Buffer Pool 虽然提高了读写效率,但是 Buffer Pool 是基于内存的,而内存总是不可靠,万一断电重启,还没来得及落盘的脏页数据就会丢失
为了防止断电导致数据丢失的问题,当有一条记录需要更新的时候,InnoDB 引擎就会先更新内存(同时标记为脏页),然后将本次对这个页的修改以 redo log 的形式记录下来,这个时候更新就算完成了
后续,InnoDB 引擎会在适当的时候,由后台线程将缓存在 Buffer Pool 的脏页刷新到磁盘里,这就是 WAL (Write-Ahead Logging)技术
WAL 技术指的是, MySQL 的写操作并不是立刻写到磁盘上,而是先写日志,然后在合适的时间再写到磁盘上
过程如下图:
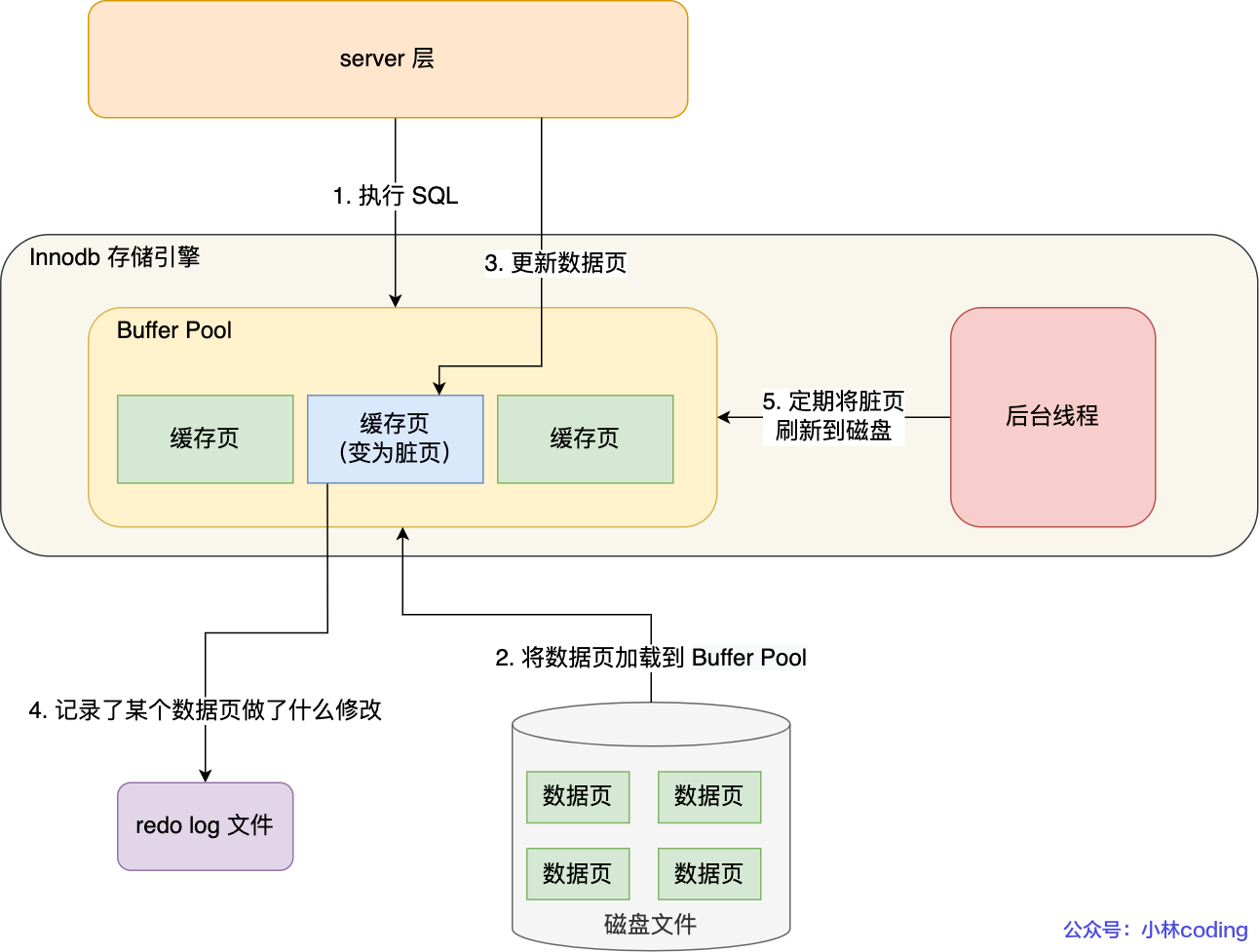
redo log 是物理日志,记录了某个数据页做了什么修改,比如对 XXX 表空间中的 YYY 数据页 ZZZ 偏移量的地方做了AAA 更新,每当执行一个事务就会产生这样的一条或者多条物理日志
在事务提交时,只要先将 redo log 持久化到磁盘即可,可以不需要等到将缓存在 Buffer Pool 里的脏页数据持久化到磁盘
当系统崩溃时,虽然脏页数据没有持久化,但是 redo log 已经持久化,接着 MySQL 重启后,可以根据 redo log 的内容,将所有数据恢复到最新的状态
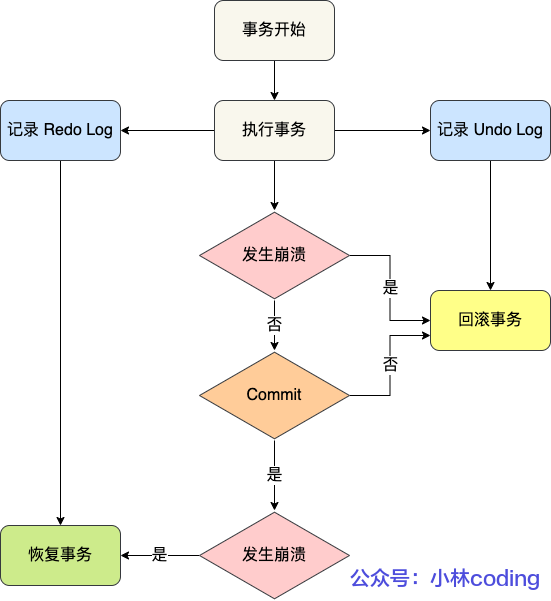
redo log 和 undo log 这两种日志是属于 InnoDB 存储引擎的日志,它们的区别在于:
- redo log 记录了此次事务「完成后」的数据状态,记录的是更新之后的值
- undo log 记录了此次事务「开始前」的数据状态,记录的是更新之前的值
事务提交之前发生了崩溃,重启后会通过 undo log 回滚事务,事务提交之后发生了崩溃,重启后会通过 redo log 恢复事务,如下图:
所以有了 redo log,再通过 WAL 技术,InnoDB 就可以保证即使数据库发生异常重启,之前已提交的记录都不会丢失,这个能力称为 crash-safe(崩溃恢复)。可以看出来, redo log 保证了事务四大特性中的持久性
写入 redo log 的方式使用了追加操作, 所以磁盘操作是顺序写,而写入数据需要先找到写入位置,然后才写到磁盘,所以磁盘操作是随机写
磁盘的「顺序写」比「随机写」 高效的多,因此 redo log 写入磁盘的开销更小
针对「顺序写」为什么比「随机写」更快这个问题,可以比喻为你有一个本子,按照顺序一页一页写肯定比写一个字都要找到对应页写快得多
可以说这是 WAL 技术的另外一个优点:MySQL 的写操作从磁盘的「随机写」变成了「顺序写」 ,提升语句的执行性能。这是因为 MySQL 的写操作并不是立刻更新到磁盘上,而是先记录在日志上,然后在合适的时间再更新到磁盘上
至此, 针对为什么需要 redo log 这个问题我们有两个答案:
- 实现事务的持久性,让 MySQL 有 crash-safe 的能力,能够保证 MySQL 在任何时间段突然崩溃,重启后之前已提交的记录都不会丢失
- 将写操作从「随机写」变成了「顺序写」 ,提升 MySQL 写入磁盘的性能
能不能只用bin log不用relo log?
不行,bin log 是 server 层的日志,没办法记录哪些脏页还没有刷盘,redo log 是存储引擎层的日志,可以记录哪些脏页还没有刷盘,这样崩溃恢复的时候,就能恢复那些还没有被刷盘的脏页数据
🚩binlog 两阶段提交过程
事务提交后,redo log 和 binlog 都要持久化到磁盘,但是这两个是独立的逻辑,可能出现半成功的状态,这样就造成两份日志之间的逻辑不一致
在 MySQL 的 InnoDB 存储引擎中,开启 binlog 的情况下,MySQL 会同时维护 binlog 日志与 InnoDB 的 redo log,为了保证这两个日志的一致性,MySQL 使用了内部 XA 事务,内部 XA 事务由 binlog 作为协调者,存储引擎是参与者
当客户端执行 commit 语句或者在自动提交的情况下,MySQL 内部开启一个 XA 事务,分两阶段来完成 XA 事务的提交,如下图:
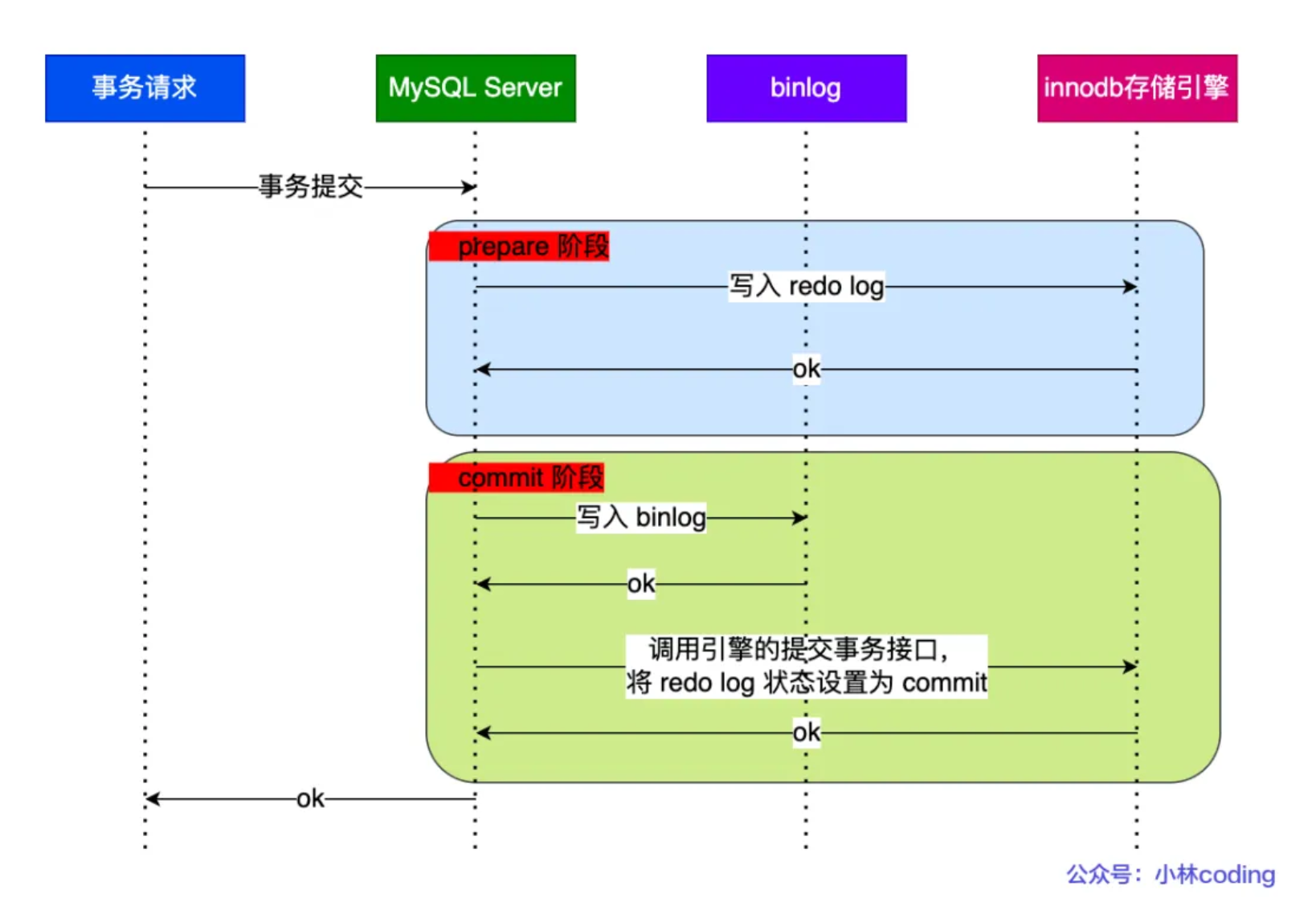
从图中可看出,事务的提交过程有两个阶段,就是将 redo log 的写入拆成了两个步骤:prepare 和 commit,中间再穿插写入binlog,具体如下:
- prepare 阶段:将 XID(内部 XA 事务的 ID) 写入到 redo log,同时将 redo log 对应的事务状态设置为 prepare,然后将 redo log 持久化到磁盘(innodb_flush_log_at_trx_commit = 1 的作用)
- commit 阶段:把 XID 写入到 binlog,然后将 binlog 持久化到磁盘(sync_binlog = 1 的作用),接着调用引擎的提交事务接口,将 redo log 状态设置为 commit,此时该状态并不需要持久化到磁盘,只需要 write 到文件系统的 page cache 中就够了,因为只要 binlog 写磁盘成功,就算 redo log 的状态还是 prepare 也没有关系,一样会被认为事务已经执行成功
在两阶段提交的不同时刻,MySQL 异常重启会出现什么现象?下图中有时刻 A 和时刻 B 都有可能发生崩溃:
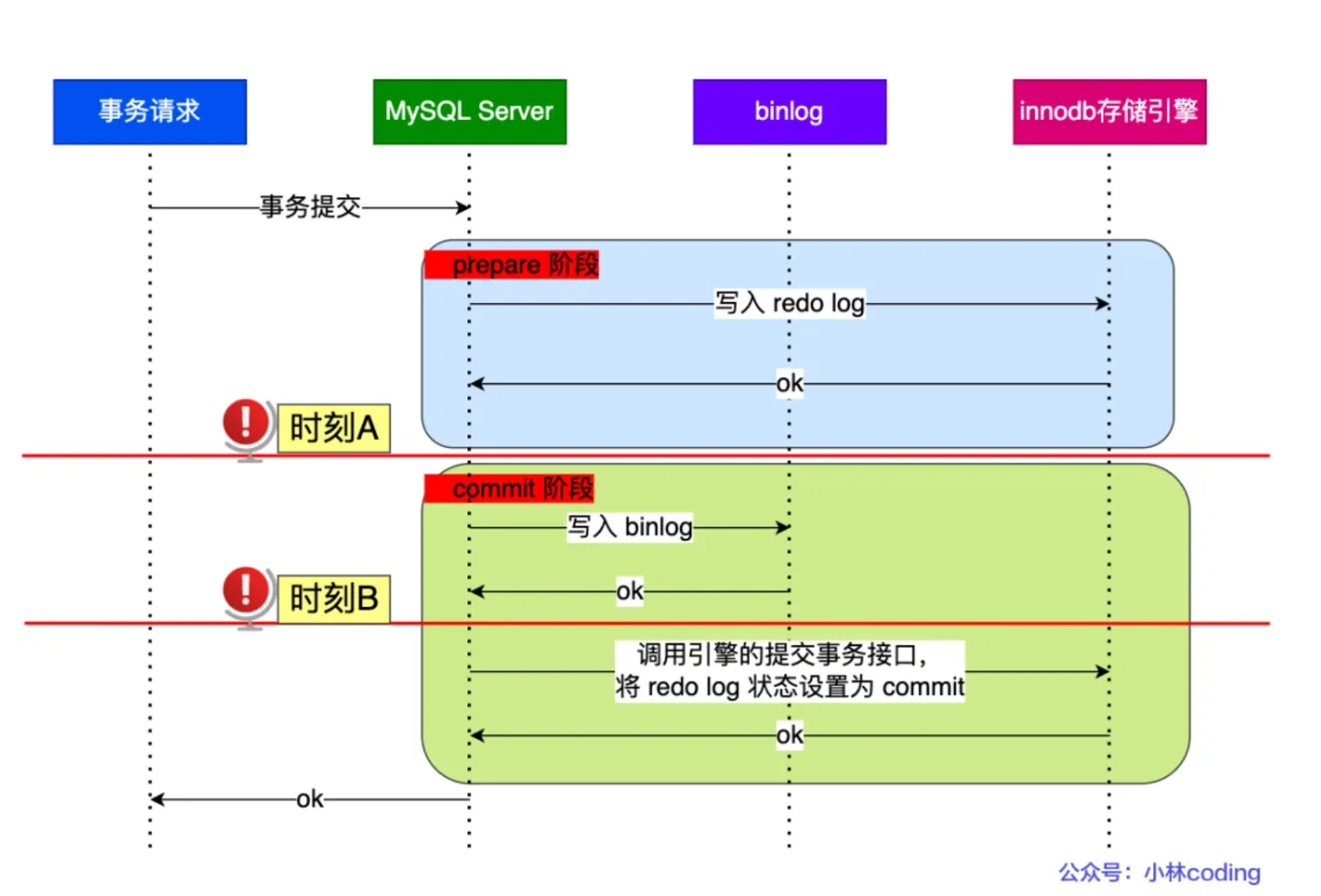
不管是时刻 A(redo log 已经写入磁盘, binlog 还没写入磁盘),还是时刻 B (redo log 和 binlog 都已经写入磁盘,还没写入 commit 标识)崩溃,此时的 redo log 都处于 prepare 状态
在 MySQL 重启后会按顺序扫描 redo log 文件,碰到处于 prepare 状态的 redo log,就拿着 redo log 中的 XID 去 binlog 查看是否存在此 XID:
- 如果 binlog 中没有当前内部 XA 事务的 XID,说明 redolog 完成刷盘,但是 binlog 还没有刷盘,则回滚事务。对应时刻 A 崩溃恢复的情况
- 如果 binlog 中有当前内部 XA 事务的 XID,说明 redolog 和 binlog 都已经完成了刷盘,则提交事务。对应时刻 B 崩溃恢复的情况
可以看到,对于处于 prepare 阶段的 redo log,即可以提交事务,也可以回滚事务,这取决于是否能在 binlog 中查找到与 redo log 相同的 XID,如果有就提交事务,如果没有就回滚事务。这样就可以保证 redo log 和 binlog 这两份日志的一致性了
所以说,两阶段提交是以 binlog 写成功为事务提交成功的标识,因为 binlog 写成功了,就意味着能在 binlog 中查找到与 redo log 相同的 XID
UPDATE语句的具体执行过程
具体更新一条记录 UPDATE t_user SET name = 'mtmn' WHERE id = 1; 的流程如下:
执行器负责具体执行,会调用存储引擎的接口,通过主键索引树搜索获取
id = 1 这一行记录:- 如果
id=1 这一行所在的数据页本来就在 buffer pool 中,就直接返回给执行器更新 - 如果记录不在 buffer pool,将数据页从磁盘读入到 buffer pool,返回记录给执行器
- 如果
执行器得到聚簇索引记录后,会看一下更新前的记录和更新后的记录是否一样:
- 如果一样的话就不进行后续更新流程
- 如果不一样的话就把更新前的记录和更新后的记录都当作参数传给 InnoDB 层,让 InnoDB 真正执行更新记录的操作
开启事务,InnoDB 层更新记录前,首先要记录相应的 undo log,因为这是更新操作,需要把被更新的列的旧值记下来,也就是要生成一条 undo log,undo log 会写入 Buffer Pool 中的 Undo 页面,不过在内存修改该 Undo 页面后,需要记录对应的 redo log
InnoDB 层开始更新记录,会先更新内存(同时标记为脏页),然后将记录写到 redo log 里面,这个时候更新就算完成了。为了减少磁盘I/O,不会立即将脏页写入磁盘,后续由后台线程选择一个合适的时机将脏页写入到磁盘。这就是 WAL 技术,MySQL 的写操作并不是立刻写到磁盘上,而是先写 redo 日志,然后在合适的时间再将修改的行数据写到磁盘上
至此,一条记录更新完成
在一条更新语句执行完成后,然后开始记录该语句对应的 binlog,此时记录的 binlog 会被保存到 binlog cache,并没有刷新到硬盘上的 binlog 文件,在事务提交时才会统一将该事务运行过程中的所有 binlog 刷新到硬盘
事务提交(为了方便说明,这里不说组提交的过程,只说两阶段提交):
- prepare 阶段:将 redo log 对应的事务状态设置为 prepare,然后将 redo log 刷新到硬盘
- commit 阶段:将 binlog 刷新到磁盘,接着调用引擎的提交事务接口,将 redo log 状态设置为 commit(将事务设置为 commit 状态后,刷入到磁盘 redo log 文件)
至此,一条更新语句执行完成
redo log 是在内存中吗?
事务执行过程中,生成的 redolog 会在 redolog buffer 中,也就是在内存中,等事务提交的时候,会把 redolog 写入磁盘
为什么要写 Redo Log,而不是直接写到B+树?
由于Redo Log的写入磁盘是顺序操作,而B+树中的数据页写入磁盘则是随机操作,顺序写入的性能通常优于随机写入,从而可以提升事务提交的效率
最为关键的是,Redo Log具备了故障恢复的功能。Redo Log记录的是物理层面的修改,包括页面的修改,如插入、更新、删除等操作在磁盘上的物理位置及修改内容。例如,在执行一个更新操作时,Redo Log会记录被修改的数据页的地址以及更新后的数据,而非SQL语句本身
在实际数据页更新之前,先将修改操作记录到Redo Log中。当数据库重启时,将启动恢复流程。首先,根据Redo Log确定哪些事务已经提交但数据页尚未完全写入磁盘。接着,利用Redo Log中的记录对这些事务执行重做(Redo)操作,完成未完成的数据页修改,确保事务的修改得以生效
🚩mysql 两次写(double write buffer)
我们常见的服务器一般都是Linux操作系统,Linux文件系统页(OS Page)的大小默认是4KB。而MySQL的页(Page)大小默认是16KB
MySQL程序是跑在Linux操作系统上的,需要跟操作系统交互,所以MySQL中一页数据刷到磁盘,要写4个文件系统里的页
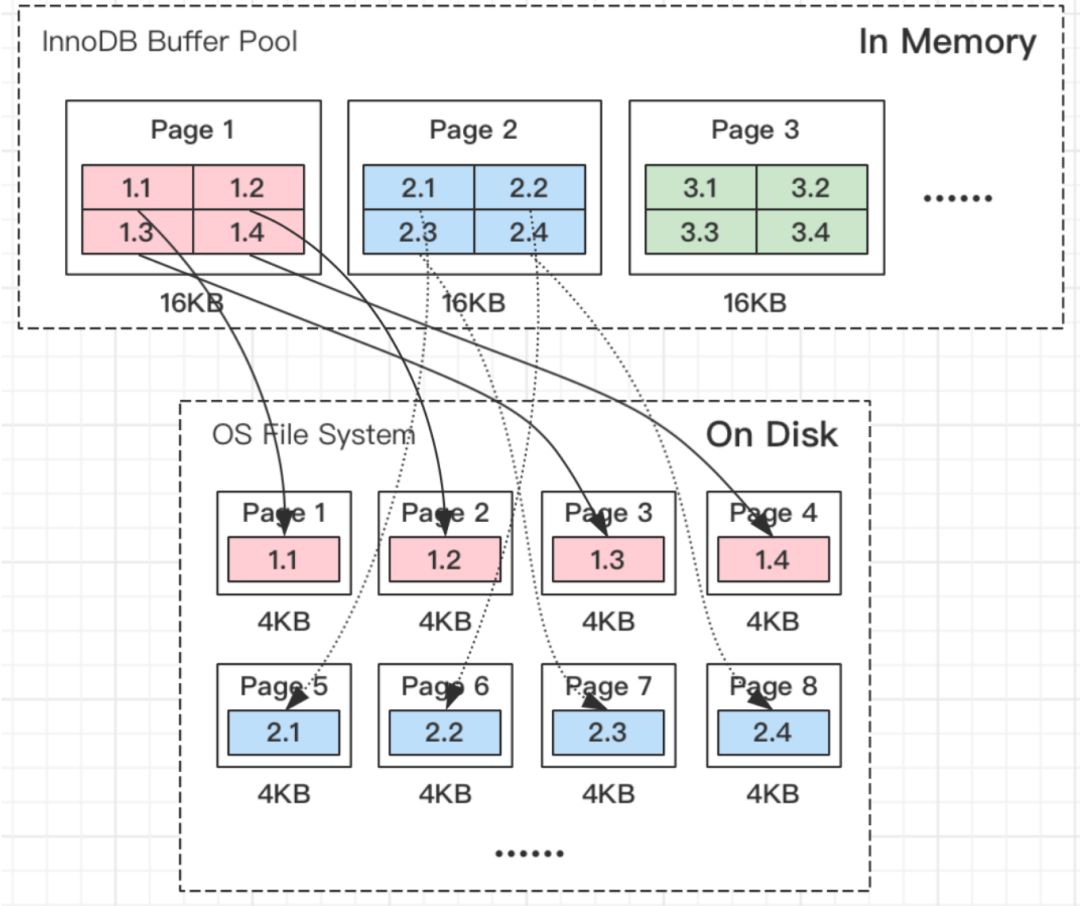
需要注意的是,这个操作并非原子操作,比如我操作系统写到第二个页的时候,Linux机器断电了,这时候就会出现问题了。造成”页数据损坏“。并且这种”页数据损坏“靠 redo日志是无法修复的
Doublewrite Buffer的出现就是为了解决上面的这种情况,虽然名字带了Buffer,但实际上Doublewrite Buffer是内存+磁盘的结构
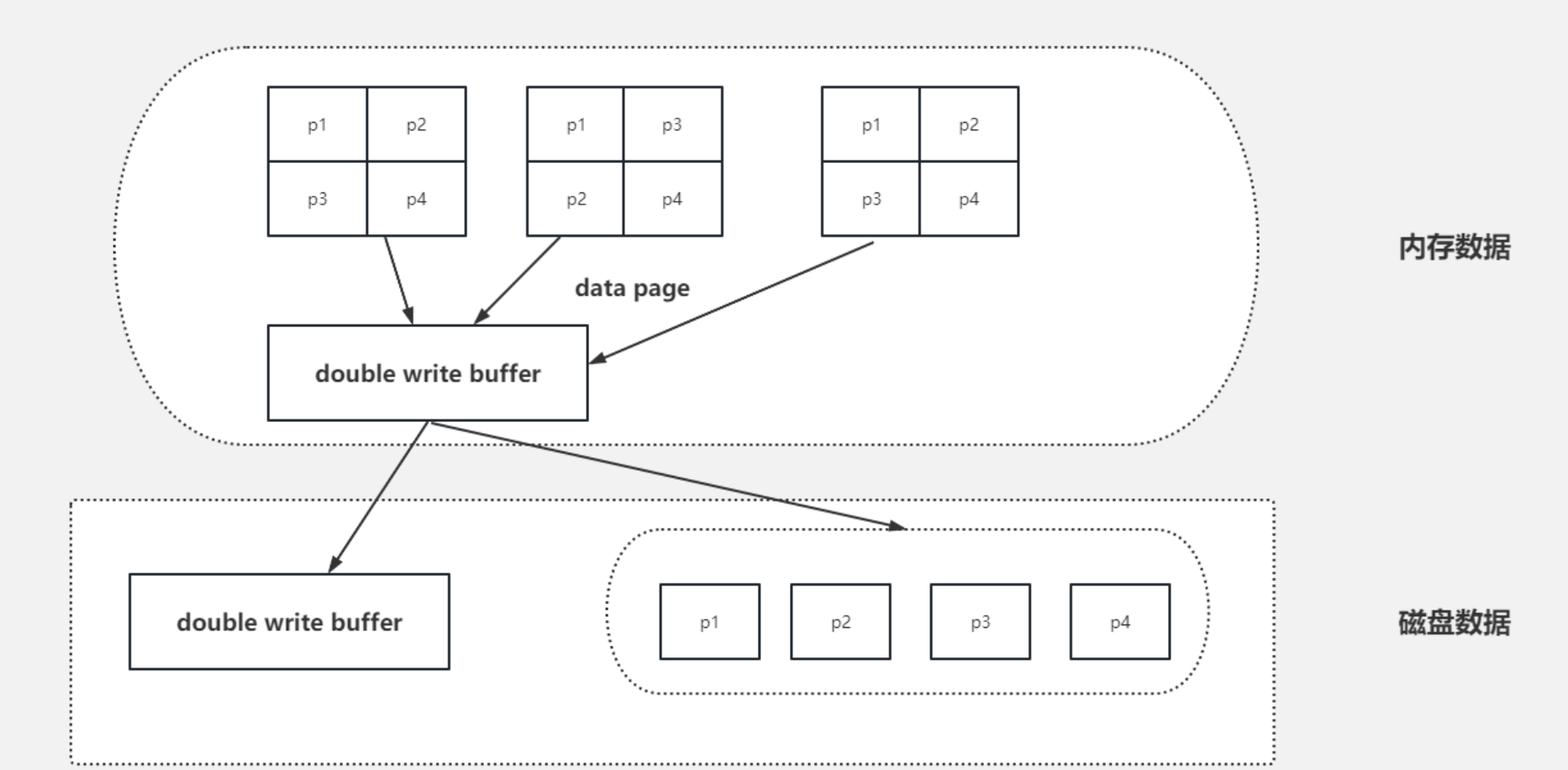
Doublewrite Buffer 作用是,在把页写到数据文件之前,InnoDB先把它们写到一个叫doublewrite buffer(双写缓冲区)的共享表空间内,在写doublewrite buffer完成后,InnoDB才会把页写到数据文件的适当的位置。如果在写页的过程中发生意外崩溃,InnoDB在稍后的恢复过程中在doublewrite buffer中找到完好的page副本用于恢复,所以本质上是一个最近写回的页面的备份拷贝
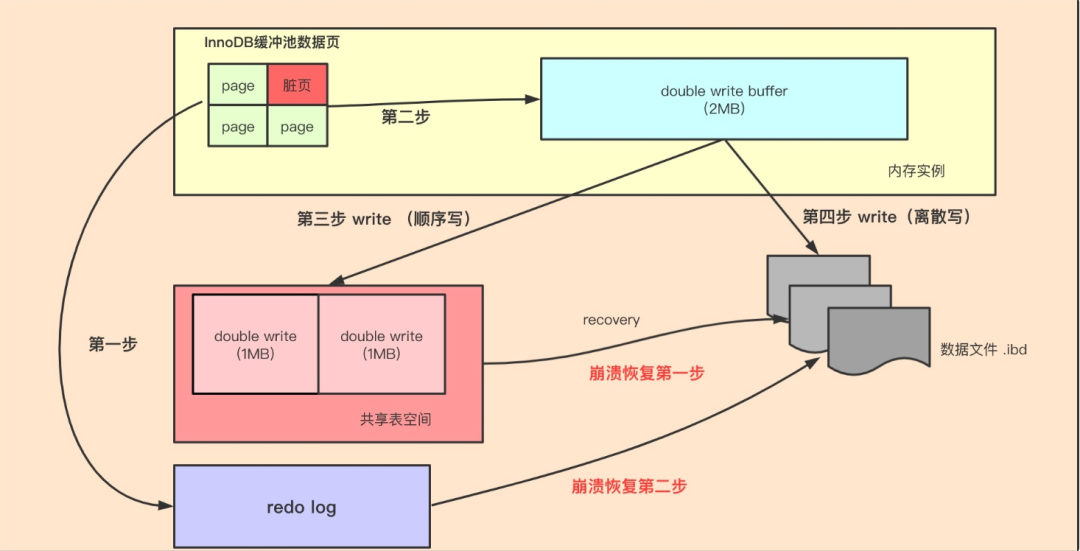
如上图所示,当有页数据要刷盘时:
- 页数据先通过memcpy函数拷贝至内存中的Doublewrite Buffer(大小为约 2MB)中,Doublewrite Buffer 分为两个区域,每次写入一个区域(最多 1MB 的数据)
- Doublewrite Buffer的内存里的数据页,会fsync刷到Doublewrite Buffer的磁盘上,写两次到到共享表空间中(连续存储,顺序写,性能很高),每次写1MB
- 写入完成后,再将脏页刷到数据磁盘存储.ibd文件上(随机写)
当MySQL出现异常崩溃时,有如下几种情况发生:
- 情况一:步骤1前宕机,刷盘未开始,数据在redo log,后期可以恢复
- 情况二:步骤1后,步骤2前宕机,因为是在内存中,宕机清空内存,和情况1一样
- 情况三:步骤2后,步骤3前宕机,因为DWB的磁盘有完整的数据,可以修复损坏的页数据
由此我们可以得出结论,double write buffer是针对实际的buffer数据页的原子性保证,就是避免MySQL异常崩溃时,写的那几个data page不会出错,要么都写了,要么什么都没有做
为什么redolog无法代替double write buffer?
redolog的设计之初,是“账本的作用”,是一种操作日志,用于MySQL异常崩溃恢复使用,是InnoDB引擎特有的日志,本质上是物理日志,记录的是 “ 在某个数据页上做了什么修改 ” ,但如果数据页本身已经发生了损坏,redolog来恢复已经损坏的数据块是无效的,数据块的本身已经损坏,再次重做依然是一个坏块。 所以此时需要一个数据块的副本来还原该损坏的数据块,再利用重做日志进行其他数据块的重做操作,这就是double write buffer的原因作用
======= 优化 =======
如何定位慢查询
回答:
- 介绍当时产生问题的场景:在接口测试过程中,我们发现速度极为缓慢,压测结果显示大约需要5秒钟
- 系统中,我们采用了运维工具——Skywalking,该工具能够监测到具体的接口。最终,问题源于SQL语句
- 在MySQL数据库中,我们启用了慢日志查询功能,并将阈值设置为2秒。一旦SQL语句的执行时间超过2秒,系统便会将其记录到日志中(适用于调试阶段)
慢查询:
- 聚合查询
- 多表查询
- 表数据量过大查询
- 深度分页查询
表象:页面加载缓慢、接口压力测试响应时间过长(超过1秒)
方案:
开源工具
- 调试工具:Arthas
- 运维工具:Prometheus、Skywalking
MySQL 自带慢日志
- 慢查询日志记录了所有执行时间超过指定参数(
long_query_time, 单位: 秒, 默认10秒)的所有SQL语句
要开启慢查询日志, 需要在MySQL的配置文件(/etc/my.cnf)中配置如下信息: #开启MySQL慢日志查询开关 slow query log=1 #设置慢日志的时间为2秒,SQL语句执行时间超过2秒,就会视为慢查询,记录慢查询日志 long_query_time=2- 配置完毕之后,重新启动MySQL服务器进行测试,查看慢日志文件中记录的信息
/var/lib/mysql/localhost-slow.log
- 慢查询日志记录了所有执行时间超过指定参数(
SQL 语句执行很慢,如何分析
回答:
可以采用MySQL自带的分析工具EXPLAIN
通过key和key_len检查是否命中了索引(索引本身存在是否有失效的情况)
通过type字段查看sql是否有进一步的优化空间,是否存在全索引扫描或全盘扫描
通过extra建议判断,是否出现了回表的情况,如果出现了,可以尝试添加索引或修改返回字段来修复
- 聚合查询
- 多表查询
- 表数据量过大查询
这些可以通过 SQL 执行计划找到慢的原因
采用EXPLAIN或者DESC命令获取MySQL如何执行SELECT语句的信息
explain select * from documents where id = 1;

possible key 当前sql可能会使用到的索引
key 当前sql实际命中的索引
通过它们两个查看是否可能会命中索引
key_len 索引占用的大小
Extra 额外的优化建议
| Extra | 含义 |
|---|---|
| Using filesort | 当查询语句中包含 group by 操作,而且无法利用索引完成排序操作的时候, 这时不得不选择相应的排序算法进行,甚至可能会通过文件排序,效率是很低的,所以要避免这种问题的出现 |
| Using temporary | 使了用临时表保存中间结果,MySQL 在对查询结果排序时使用临时表,常见于排序 order by 和分组查询 group by。效率低,要避免这种问题的出现 |
| Using index | 所需数据只需在索引即可全部获得,不须要再到表中取数据,也就是使用了覆盖索引,避免了回表操作,效率不错 |
TYPE 这条 SQL 的连接类型,性能由高至低排序为:NULL、SYSTEM、CONST、EQ_REF、REF、RANGE、INDEX、ALL- SYSTEM:查询系统中的表
- CONST:根据主键查询
- EQ_REF:主键索引查询或唯一索引查询
- REF:索引查询
- RANGE:范围查询
- INDEX:索引树扫描(需要优化)
- ALL:全盘扫描(需要优化)
覆盖索引、超大分页优化
覆盖索引是指查询使用了索引,并且需要返回的列,在该索引中已经全部能够找到

❓什么是覆盖索引
覆盖索引,即查询利用索引进行,返回的列,必须在索引中全部可寻
以id进行查询,可径直走聚集索引路径,实现一次索引扫描,即刻返回数据,性能优越
若查询返回的列未在索引中创建,则可能引发回表查询,宜尽力避免使用SELECT *
❓超大分页处理
问题:在数据量比较大时,limit分页查询,需要对数据进行排序,效率低
解决方案:覆盖索引+子查询
mysql> select * from tb_sku limit 0,10;
10 rows in set (0.00 sec)
mysql> select * from tb_sku limit 9000000,10;
10 rows in set (11.05 sec)优化思路:一般分页查询时,通过创建覆盖索引能够比较好地提高性能,可以通过覆盖索引加子查询形式进行优化
select *
from tb_sku t,
(select id from tb_sku order by id limit 9000000,10) a
where t.id = a.id;
谈一谈对 SQL 优化的经验
- 表的设计优化
- 索引优化
- SQL 语句优化
- 主从复制、读写分离
- 分库分表
表设计优化
① 例如,设置适当的数值类型(如 tinyint, int, bigint)时,应依据实际情况进行选择
② 例如,在设置字符串类型时(如 char 和 varchar),char 类型定长效率较高,而 varchar 类型可变长度,效率相对较低
SQL 语句优化
SELECT语句务必指明字段名称
- 避免直接使用
select *
- 避免直接使用
避免造成索引失效的SQL写法
尽量用
union all 代替 union-
union 会多一次过滤操作,效率较低 -
select * from t_user where id > 2 union all / union select * from t_user where id < 5
-
避免在
where 子句中对字段进行表达式操作- 这会导致索引失效
Join 语句优化
- 能用
inner join 就不用left join 或right join - 如果必须使用
left join 或right join,一定要以小表为驱动 - 内连接会对两个表进行优化,优先把小表放到外边,把大表放到里边
-
left join 或right join 不会重新调整顺序 - 小表决定了数据库连接次数,大表决定了每次连接的操作次数
- 能用
主从复制、读写分离
如果数据库的使用场景读的操作比较多的时候,为了避免写的操作所造成的性能影响可以采用读写分离架构
读写分离解决的是,数据库的写入,影响了查询的效率