
Java语法
String
实例化
String s1 = "hello";
会在ST中创建一个字面量对象String s1 = new String("hello");
首先在堆中创建一个对象,再在ST中创建一个字面量对象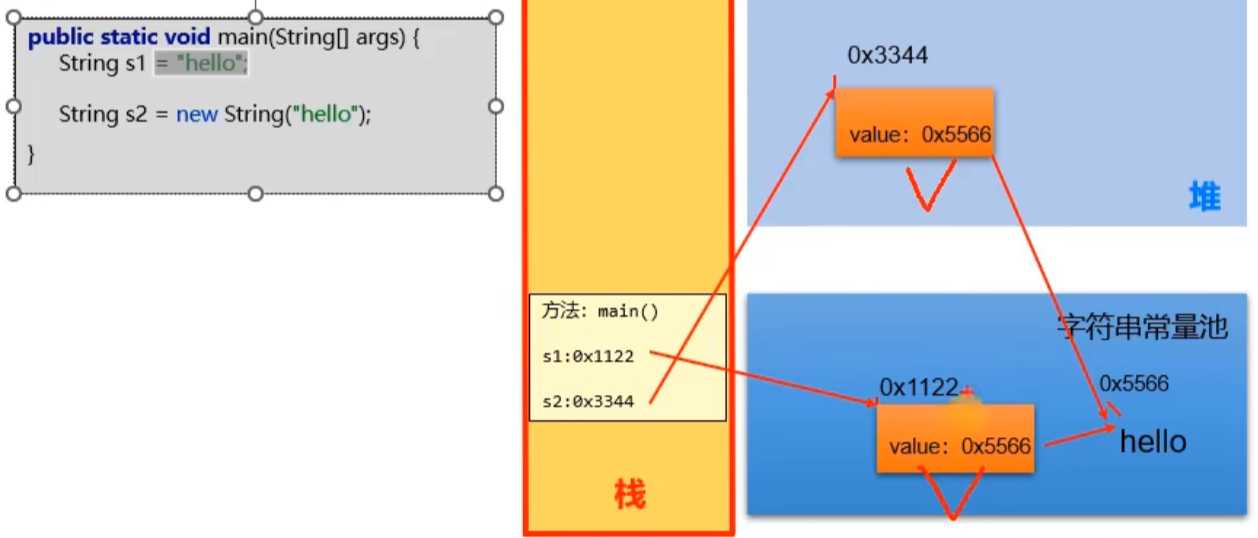
内存结构、不可变性
String s1 = "hello";
String s2 = "hello";
s2 = "hi";内部是 private final byte [] value
字符串放在字符串常量池中(StringTable),ST中不允许有相同的字面量
s1、s2指向相同地址,更改时创建新的字面量到ST,s1指向新地址
String s1 = "hello";
String s2 = "hello";
s2 += "hi";+=会将字符串创建在堆区,相当于new出来的
String s1 = "hello";
String s2 = "hello";
String s3 = s2.replace('l', 'w');s1:hello
s2:hello
s3:hewwo
s3也是new出来的
连接操作
常量+常量 = 常量(在ST中直接创建)
常量+变量 (在堆中先创,再ST中创建。new出来的)
变量+变量 (在堆中先创,再ST中创建。new出来的)
s = s1.intern(); intern()返回的是字符串常量池中字面量的地址
常量:字面量或final修饰的变量
变量加上final会变成常量
.concat() 也是new出来的
构造器与常用方法
常用类和基础API
日期、时间
System 类提供的 public static long currentTimeMillis():用来返回当前时间与 1970 年 1 月 1 日 0 时 0 分 0 秒之间以毫秒为单位的时间差
java.util.Date
构造器:
- Date():使用无参构造器创建的对象可以获取本地当前时间。
- Date(long 毫秒数):把该毫秒值换算成日期时间对象
常用方法:
getTime(): 返回自 1970 年 1 月 1 日 00:00:00 GMT 以来此 Date 对象表示的毫秒数。
toString(): 把此 Date 对象转换为以下形式的 String: dow mon dd hh:mm:ss zzz yyyy
其中: dow 是一周中的某一天 (Sun, Mon, Tue, Wed,Thu, Fri, Sat),zzz 是时间标准。
java.text.SimpleDateFormat
java.text.SimpleDateFormat 类是一个不与语言环境有关的方式来格式化和解析日期的具体类。
可以进行格式化:日期 --> 文本
可以进行解析:文本 --> 日期
构造器:
- SimpleDateFormat() :默认的模式和语言环境创建对象
- public SimpleDateFormat(String pattern):用参数 pattern指定的格式创建一个对象
格式化:
- public String format(Date date):方法格式化时间对象 date
解析:
- public Date parse(String source):从给定字符串的开始解析文本,以生成一个日期。
java.util.Calendar(日历)
比较器
自然排序:java.lang.Comparable
继承compare接口、重写compareTo方法
定制排序:java.util.Comparator
场景:
当元素的类型没有实现 java.lang.Comparable 接口而又不方便修改代码
一个类,实现了 Comparable 接口,也指定了比较规则,若不想按预定义的方法比较大小,又不能随意修改,因为会影响其他地方的使用
解决:
package java.util;
public interface Comparator{
int compare(Object o1,Object o2);
}强行对多个对象进行整体排序的比较
继承Comparator接口,重写 compare(Object o1,Object o2)方法,比较 o1 和 o2 的大小:
如果方法返回正整数,则表示 o1 大于 o2;如果返回 0,表示相等;返回负整数,表示 o1 小于 o2。
可以将 Comparator 传递给 sort 方法(如 Collections.sort 或Arrays.sort),从而允许在排序顺序上实现精确控制。
package com.atguigu.api;
import java.util.Comparator;
//定义定制比较器类
public class StudentScoreComparator implements Comparator {
@Override
public int compare(Object o1, Object o2) {
Student s1 = (Student) o1;
Student s2 = (Student) o2;
int result = s1.getScore() - s2.getScore();
return result != 0 ? result : s1.getId() - s2.getId();
}
}@Test
public void test01() {
Student[] students = new Student[5];
students[0] = new Student(3, "张三", 90, 23);
students[1] = new Student(1, "熊大", 100, 22);
students[2] = new Student(5, "王五", 75, 25);
students[3] = new Student(4, "李四", 85, 24);
students[4] = new Student(2, "熊二", 85, 18);
System.out.println(Arrays.toString(students));
//定制排序
StudentScoreComparator sc = new StudentScoreComparator();
Arrays.sort(students, sc);
System.out.println("排序之后:");
System.out.println(Arrays.toString(students));
}Goods[] all = new Goods[4];
all[0] = new Goods("War and Peace", 100);
all[1] = new Goods("Childhood", 80);
all[2] = new Goods("Scarlet and Black", 140);
all[3] = new Goods("Notre Dame de Paris", 120);
Arrays.sort(all, new Comparator() {
@Override
public int compare(Object o1, Object o2) {
Goods g1 = (Goods) o1;
Goods g2 = (Goods) o2;
return g1.getName().compareTo(g2.getName());
}
});
System.out.println(Arrays.toString(all));系统相关
java.lang.System
该类位于java.lang 包
由于该类的构造器是 private 的,所以无法创建该类的对象。其内部的成员变量和成员方法都是 static 的,所以也可以很方便的进行调用
成员变量
- Scanner scan = new Scanner(System.in);
System 类内部包含 in、out 和 err 三个成员变量,分别代表标准输入流(键盘输入),标准输出流(显示器)和标准错误输出流(显示器)
- Scanner scan = new Scanner(System.in);
成员方法
- native long currentTimeMillis():返回当前的计算机时间,与1970 年 1 月 1 号 0 时 0 分 0 秒所差的毫秒数
- void exit(int status) status = 0正常退出,非0代表异常退出
- void gc() 请求系统进行垃圾回收(不一定立刻回收)
- String getProperty(String key):获得系统中属性名为 key 的属性对应的值
- static void arraycopy(Object src, int srcPos, Object dest, intdestPos, int length):从指定源数组中复制一个数组,复制从指定的位置开始,到目标数组的指定位置结束。常用于数组的插入和删除
| 属性名 | 属性说明 |
|---|---|
| java.version | Java运行时环境版本 |
| java.home | Java安装目录 |
| os.name | 操作系统的名称 |
| os.version | 操作系统的版本 |
| user.name | 用户的账户名称 |
| user.home | 用户的主目录 |
| user.dir | 用户的当前工作目录 |
java.lang.Runtime
每个java程序都有一个Runtime实例,使应用程序能够与其运行的环境相连接
public static Runtime getRuntime(): 返回与当前 Java 应用程序相关的运行时对象。应用程序不能创建自己的 Runtime 类实例。
public long totalMemory():返回 Java 虚拟机中初始化时的内存总量。此方法返回的值可能随时间的推移而变化,这取决于主机环境。默认为电脑物理内存的 1/64。
public long maxMemory():返回 Java 虚拟机中最大程度能使用的内存总量。默认为电脑物理内存的 1/4。
public long freeMemory():回 Java 虚拟机中的空闲内存量。调用 gc 方法可能导致 freeMemory 返回值的增加
数学相关
java.lang.Math
public static long round(double a) :返回最接近参数的 long。(相当于四舍五入方法)
public static double random():返回[0,1)的随机值
public static final double PI:返回圆周率
BigInteger
不可变的任意精度的整数
String构造
abs、add、subtract、multiply、devide、remainder、pow
BigInteger[] divideAndRemainder(BigInteger val):返回包含 (this / val)后跟 (this % val) 的两个 BigInteger 的数组
BigDecimal
- 构造:
- double
- String
- add、subtract、multiply
- public BigDecimal divide(BigDecimal divisor, int scale, introundingMode):divisor 是除数,scale 指明保留几位小数,roundingMode指明舍入模式(ROUNDUP :向上加 1、ROUNDDOWN :直接舍去、ROUNDHALFUP:四舍五入)
java.util.Random
boolean nextBoolean():返回下一个伪随机数,它是取自此随机数生成器序列的均匀分布的 boolean 值。
void nextBytes(byte[] bytes):生成随机字节并将其置于用户提供的 byte 数组中。
double nextDouble():返回下一个伪随机数,它是取自此随机数生成器序列的、在0.0 和 1.0 之间均匀分布的 double 值。
float nextFloat():返回下一个伪随机数,它是取自此随机数生成器序列的、在0.0 和 1.0 之间均匀分布的 float 值。
double nextGaussian():返回下一个伪随机数,它是取自此随机数生成器序列的、呈高斯(“正态”)分布的 double 值,其平均值是 0.0,标准差是 1.0。
int nextInt():返回下一个伪随机数,它是此随机数生成器的序列中均匀分布的int 值。
int nextInt(int n):返回一个伪随机数,它是取自此随机数生成器序列的、在 0(包括)和指定值(不包括)之间均匀分布的 int 值。
long nextLong():返回下一个伪随机数,它是取自此随机数生成器序列的均匀分布的 long 值。
集合框架
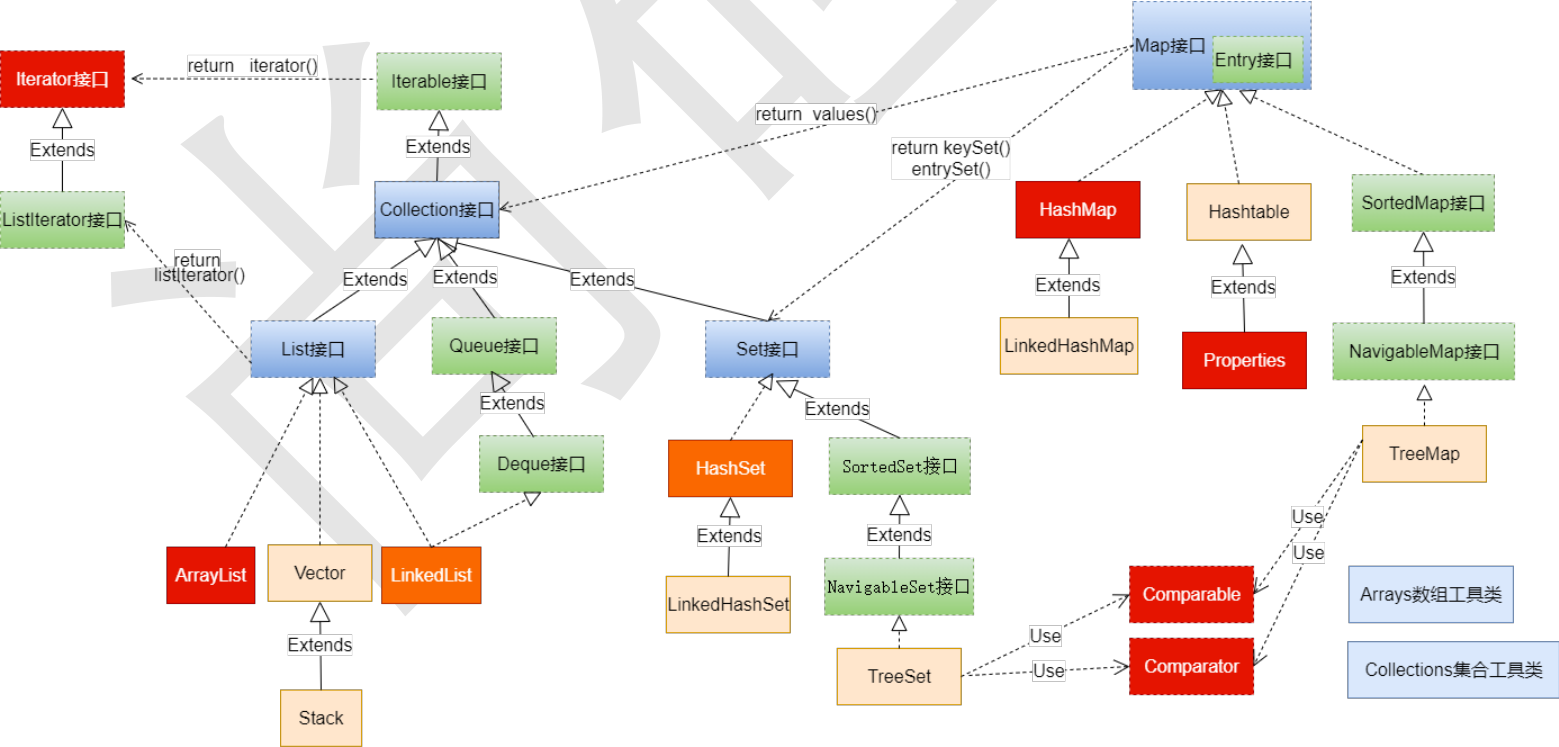
JDK 提供的集合 API 位于 java.util 包内
ArrayList(主要实现类)、LinkedList、Vector
HashSet(主要实现类)、LinkedHashSet、TreeSet
HashMap(主要实现类)、LinkedHashMap、TreeMap、Hashtable、Properties
Map 实现类之五:Properties
Collections 工具类
排序
reverse(List):反转 List 中元素的顺序
shuffle(List):对 List 集合元素进行随机排序
sort(List):根据元素的自然顺序对指定 List 集合元素按升序排序
sort(List,Comparator):根据指定的 Comparator 产生的顺序对 List 集合元素进行排序
swap(List,int, int):将指定 list 集合中的 i 处元素和 j 处元素进行交换
查找
Object max(Collection):根据元素的自然顺序,返回给定集合中的最大元素
Object max(Collection,Comparator):根据 Comparator 指定的顺序,返回给定集合中的最大元素
Object min(Collection):根据元素的自然顺序,返回给定集合中的最小元素
Object min(Collection,Comparator):根据 Comparator 指定的顺序,返回给定集合中的最小元素
int binarySearch(List list,T key)在 List 集合中查找某个元素的下标,但是 List 的元素必须是 T 或 T 的子类对象,而且必须是可比较大小的,即支持自然排序的。而且集合也事先必须是有序的,否则结果不确定。
int binarySearch(List list,T key,Comparator c)在 List 集合中查找某个元素的下标,但是List 的元素必须是 T 或 T 的子类对象,而且集合也事先必须是按照 c 比较器规则进行排序过的,否则结果不确定。
int frequency(Collection c,Object o):返回指定集合中指定元素的出现次数复制、替换
void copy(List dest,List src):将 src 中的内容复制到 dest 中
boolean replaceAll(List list,Object oldVal,Object newVal):使用新值替换 List 对象的所有旧值
提供了多个 unmodifiableXxx()方法,该方法返回指定 Xxx 的不可修改的视图。
添加
boolean addAll(Collection c,T... elements)将所有指定元素添加到指定 collection 中。
同步
Collections 类中提供了多个 synchronizedXxx() 方法,该方法可使将指定集合包装成
线程同步的集合,从而可以解决多线程并发访问集合时的线程安全问题:
数据结构
HashMap
底层实现使用 数组 单向链表 红黑树
大小为2的幂(计算索引的时候方便)
key -> hash1 -> hash2
File类、IO流
都在 java.io 包下
File 能新建、删除、重命名文件和目录,但 File 不能访问文件内容本身。如果需要访问文件内容本身,则需要使用输入/输出流。
File 对象可以作为参数传递给流的构造器。
构造:
- public File(String pathname) :以 pathname 为路径创建 File 对象,可以是绝对路径或者相对路径,如果 pathname 是相对路径,则默认的当前路径在系统属性user.dir 中存储。
- public File(String parent, String child) :以 parent 为父路径,child 为子路径创建 File 对象。
- public File(File parent, String child) :根据一个父 File 对象和子文件路径创建 File 对象
无论该路径下是否存在文件或者目录,都不影响 File 对象的创建
当构造路径是绝对路径时,那么 getPath 和 getAbsolutePath 结果一样
当构造路径是相对路径时,那么 getAbsolutePath 的路径 = user.dir的路径 + 构造路径
常用方法
public String getName() :获取名称
public String getPath() :获取路径
public String getAbsolutePath():获取绝对路径
public File getAbsoluteFile():获取绝对路径表示的文件
public String getParent():获取上层文件目录路径。若无,返回 null
public long length() :获取文件长度(即:字节数)。不能获取目录的长度。
public long lastModified() :获取最后一次的修改时间,毫秒值
public String[] list() :返回一个 String 数组,表示该 File 目录中的所有子文件或目录。
public File[] listFiles() :返回一个 File 数组,表示该 File 目录中的所有的子文件或目录。
public boolean renameTo(File dest):把文件重命名为指定的文件路径
public boolean exists() :此 File 表示的文件或目录是否实际存在。
public boolean isDirectory() :此 File 表示的是否为目录。
public boolean isFile() :此 File 表示的是否为文件。
public boolean canRead() :判断是否可读
public boolean canWrite() :判断是否可写
public boolean isHidden() :判断是否隐藏
public boolean createNewFile() :创建文件。若文件存在,则不创建,返回false。
public boolean mkdir() :创建文件目录。如果此文件目录存在,就不创建了。如果此文件目录的上层目录不存在,也不创建。
public boolean mkdirs() :创建文件目录。如果上层文件目录不存在,一并创建。
public boolean delete() :删除文件或者文件夹 删除注意事项:① Java 中的删除不走回收站。② 要删除一个文件目录,请注意该文件目录内不能包含文件或者文件目录。
IO流
字节流(8bit) 字符流(16bit)
字节流 :以字节为单位,读写数据的流。以 InputStream、OutputStream 结尾
字符流 :以字符为单位,读写数据的流。以 Reader、Writer 结尾
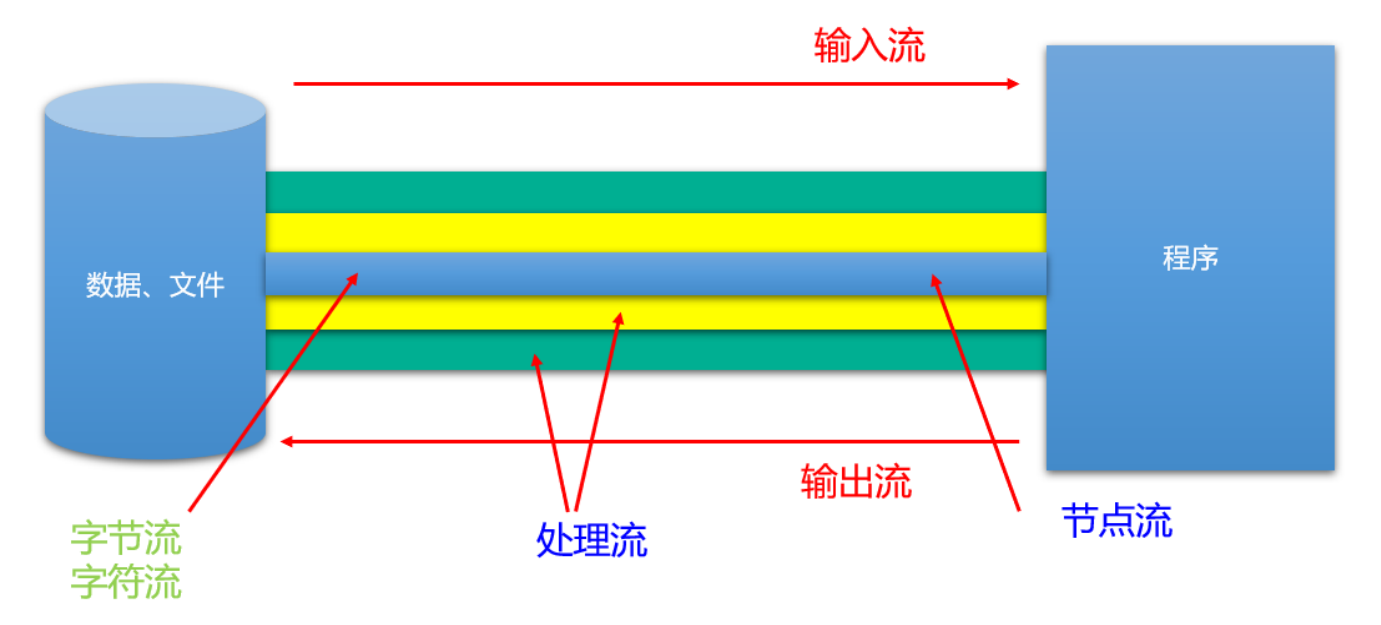
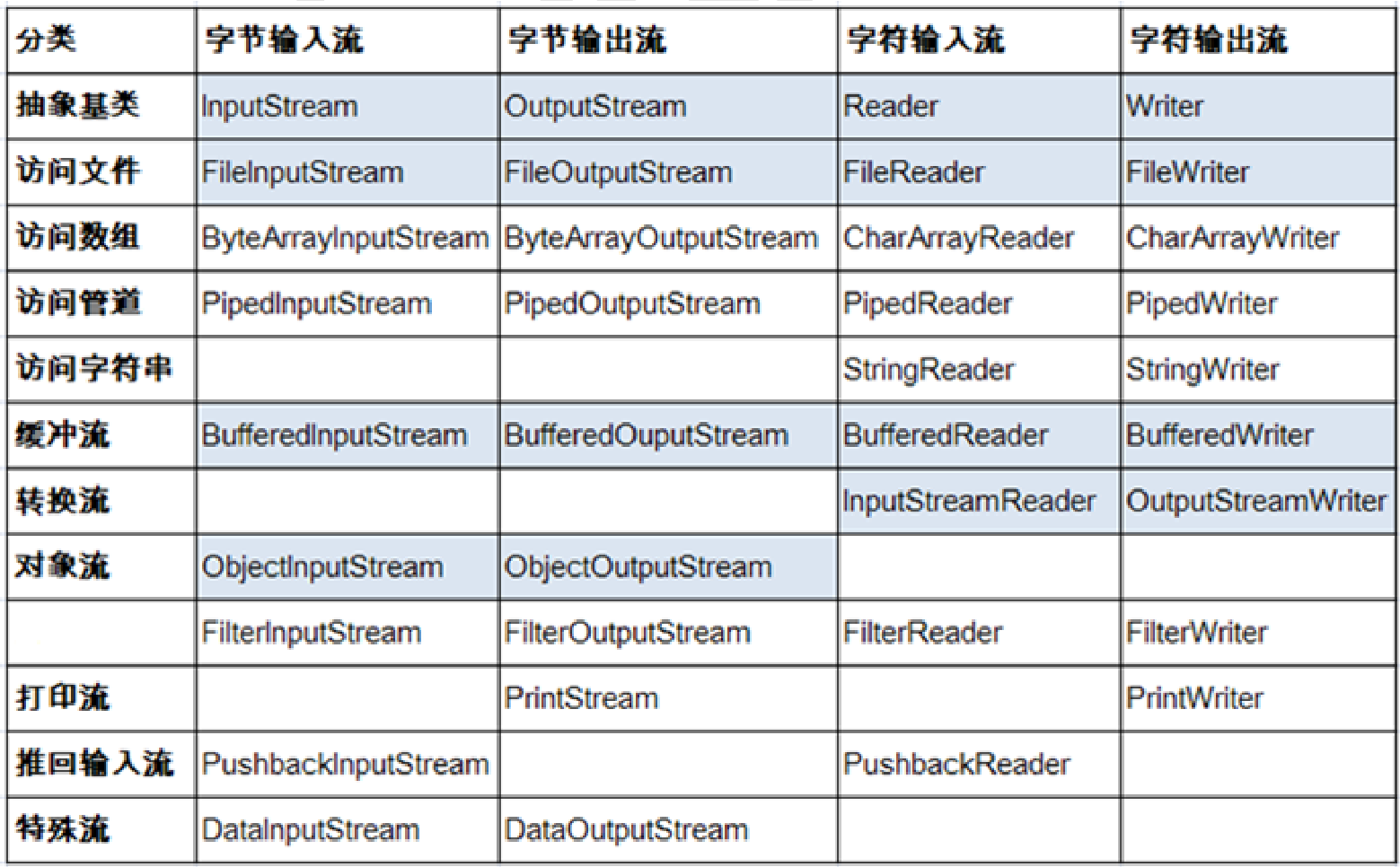
对数组进行处理的节点流(对应的不再是文件,而是内存中的一个数组)
节点流之一:FileReader\FileWriter
以字符为单位读写数据,专门用于处理文本文件。不能操作图片,视频等非文本文件。
常见的文本文件有如下的格式:.txt、.java、.c、.cpp、.py 等
注意:.doc、.xls、.ppt 这些都不是文本文件
Reader
抽象类是表示用于读取字符流的所有类的父类,可以读取字符信息到内存中
public int read(): 从输入流读取一个字符。 虽然读取了一个字符,但是会自动提升为 int 类型。返回该字符的 Unicode 编码值。如果已经到达流末尾了,则返回-1。
public int read(char[] cbuf): 从输入流中读取一些字符,并将它们存储到字符数组 cbuf 中 。每次最多读取 cbuf.length 个字符。返回实际读取的字符个数。如果已经到达流末尾,没有数据可读,则返回-1。
public int read(char[] cbuf,int off,int len):从输入流中读取一些字符,并将它们存储到字符数组 cbuf 中,从 cbuf[off]开始的位置存储。每次最多读取len 个字符。返回实际读取的字符个数。如果已经到达流末尾,没有数据可读,则返回-1。
public void close() :关闭此流并释放与此流相关联的任何系统资源。
注意:当完成流的操作时,必须调用 close()方法,释放系统资源,否
则会造成内存泄漏。
Writer
- java.io.Writer 抽象类是表示用于写出字符流的所有类的超类,将指定的字符信息写出到目的地。
- public void write(int c) :写出单个字符。
- public void write(char[] cbuf):写出字符数组。
- public void write(char[] cbuf, int off, int len):写出字符数组的某一部分。off:数组的开始索引;len:写出的字符个数。
- public void write(String str):写出字符串。
- public void write(String str, int off, int len) :写出字符串的某一部分。off:字符串的开始索引;len:写出的字符个数。
- public void flush():刷新该流的缓冲。
- public void close() :关闭此流。
- 注意:当完成流的操作时,必须调用 close()方法,释放系统资源,否则会造成内存泄漏。
FileReader
用于读取字符文件,构造时使用系统默认的字符编码和默认字节缓冲区
- FileReader(File file): 创建一个新的 FileReader ,给定要读取的 File 对象
- FileReader(String fileName): 创建一个新的 FileReader ,给定要读取的文件的名称
FileWriter
- FileWriter(File file): 创建一个新的 FileWriter,给定要读取的 File 对象
- FileWriter(String fileName): 创建一个新的 FileWriter,给定要读取的文件的名称
- FileWriter(File file,boolean append): 创建一个新的 FileWriter,指明是否在现有文件末尾追加内容
因为出现流资源的调用,为了避免内存泄漏,需要使用 try-catch-finally 处理异常
对于输入流来说,File 类的对象必须在物理磁盘上存在,否则执行就会报 FileNotFoundException。如果传入的是一个目录,则会报 IOException 异常。
对于输出流来说,File 类的对象是可以不存在的。
如果 File 类的对象不存在,则可以在输出的过程中,自动创建 File 类的对象
如果 File 类的对象存在,
如果调用 FileWriter(File file)或 FileWriter(File file,false),输出时会新建 File 文件覆盖已有的文件
如果调用 FileWriter(File file,true)构造器,则在现有的文件末尾追加写出内容。
节点流之二:FileInputStream\FileOutputStream
字节输入流:InputStream
表示字节输入流的所有类的超类,可以读取字节信息到内存中。它定义了字节输入流的基本共性功能方法。
- public int read(): 从输入流读取一个字节。返回读取的字节值。虽然读取了一个字节,但是会自动提升为 int 类型。如果已经到达流末尾,没有数据可读,则返回-1。
- public int read(byte[] b): 从输入流中读取一些字节数,并将它们存储到字节数组 b 中 。每次最多读取 b.length 个字节。返回实际读取的字节个数。如果已经到达流末尾,没有数据可读,则返回-1。
- public int read(byte[] b,int off,int len):从输入流中读取一些字节数,并将它们存储到字节数组 b 中,从 b[off]开始存储,每次最多读取 len 个字节 。返回实际读取的字节个数。如果已经到达流末尾,没有数据可读,则返回-1。
- public void close() :关闭此输入流并释放与此流相关联的任何系统资源。
字节输出流:OutputStream
表示字节输出流的所有类的超类,将指定的字节信息写出到目的地
- public void write(int b) :将指定的字节输出流。虽然参数为 int 类型四个字节,但是只会保留一个字节的信息写出。
- public void write(byte[] b):将 b.length 字节从指定的字节数组写入此输出流。
- public void write(byte[] b, int off, int len) :从指定的字节数组写入 len 字节,从偏移量 off 开始输出到此输出流。
- public void flush() :刷新此输出流并强制任何缓冲的输出字节被写出。
- public void close() :关闭此输出流并释放与此流相关联的任何系统资源。
FileInputStream
文件输入流,从文件中读取字节。
- FileInputStream(File file): 通过打开与实际文件的连接来创建一个FileInputStream ,该文件由文件系统中的 File 对象 file 命名。
- FileInputStream(String name): 通过打开与实际文件的连接来创建一个FileInputStream ,该文件由文件系统中的路径名 name 命名。
FileOutputStream
- public FileOutputStream(File file):创建文件输出流,写出由指定的 File对象表示的文件。
- public FileOutputStream(String name): 创建文件输出流,指定的名称为写出文件。
- public FileOutputStream(File file, boolean append): 创建文件输出流,指明是否在现有文件末尾追加内容。
处理流之一:缓冲流
为了提高数据读写的速度,Java API 提供了带缓冲功能的流类:缓冲流。
缓冲流要“套接”在相应的节点流之上,根据数据操作单位可以把缓冲流分为:
字节缓冲流:BufferedInputStream,BufferedOutputStream
字符缓冲流:BufferedReader,BufferedWriter缓冲流的基本原理:在创建流对象时,内部会创建一个缓冲区数组(缺省使用 8192个字节(8Kb)的缓冲区),通过缓冲区读写,减少系统 IO 次数,从而提高读写的效率。
public BufferedInputStream(InputStream in) :创建一个新的字节型的缓冲输入流。
public BufferedOutputStream(OutputStream out): 创建一个新的字节型的缓冲输出流。
public BufferedReader(Reader in) :创建一个 新的字符型的缓冲输入流。
public BufferedWriter(Writer out): 创建一个新的字符型的缓冲输出流。
//方法 2:使用 BufferedInputStream\BufferedOuputStream 实现非文本文件的复制
public void copyFileWithBufferedStream(String srcPath,String destPat
h){
FileInputStream fis = null;
FileOutputStream fos = null;
BufferedInputStream bis = null;
BufferedOutputStream bos = null;
try {
//1. 造文件
File srcFile = new File(srcPath);
File destFile = new File(destPath);
//2. 造流
fis = new FileInputStream(srcFile);
fos = new FileOutputStream(destFile);
bis = new BufferedInputStream(fis);
bos = new BufferedOutputStream(fos);
//3. 读写操作
int len;
byte[] buffer = new byte[100];
while ((len = bis.read(buffer)) != -1) {
bos.write(buffer, 0, len);
}
System.out.println("复制成功");
} catch (IOException e) {
e.printStackTrace();
} finally {
//4. 关闭资源(如果有多个流,我们需要先关闭外面的流,再关闭内部的
流)
try {
if (bos != null)
bos.close();
} catch (IOException e) {
throw new RuntimeException(e);
}
try {
if (bis != null)
bis.close();
} catch (IOException e) {
throw new RuntimeException(e);
}
}
}
@Test
public void test2(){
String srcPath = "C:\\Users\\shkstart\\Desktop\\01-复习.mp4";
String destPath = "C:\\Users\\shkstart\\Desktop\\01-复习 2.mp4";
long start = System.currentTimeMillis();
copyFileWithBufferedStream(srcPath,destPath);
long end = System.currentTimeMillis();
System.out.println("花费的时间为:" + (end - start));//415 毫秒
}字符缓冲流特有方法
BufferedReader:public String readLine(): 读一行文字。
BufferedWriter:public void newLine(): 写一行。行分隔符由系统属性定义符号。
涉及到嵌套的多个流时,如果都显式关闭的话,需要先关闭外层的流,再关闭内层的流
其实在开发中,只需要关闭最外层的流即可,因为在关闭外层流时,内层的流也会被关闭。
处理流之二:转换流
解决乱码问题
是字节与字符间的桥梁
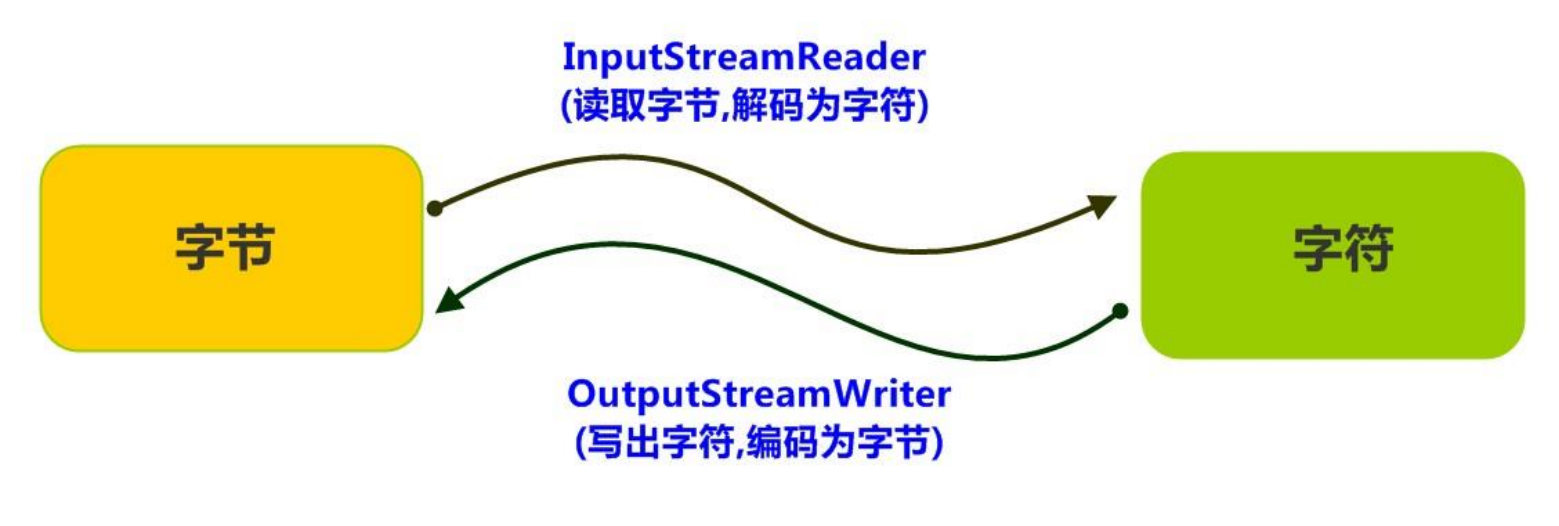
InputStreamReader
- 从字节流到字符流。它读取字节,并使用指定的字符集将其解码为字符。它的字符集可以由名称指定,也可以接受平台的默认字符集
构造
- InputStreamReader(InputStream in): 创建一个使用默认字符集的字符流。
- InputStreamReader(InputStream in, StringcharsetName): 创建一个指定字符集的字符流。
OutputStreamWriter
- 从字符流到字节流。使用指定的字符集将字符编码为字节
构造
- OutputStreamWriter(OutputStream in): 创建一个使用默认字符集的字符流。
- OutputStreamWriter(OutputStream in,StringcharsetName): 创建一个指定字符集的字符流。
处理流之三/四:数据流、对象流
- DataOutputStream:允许应用程序将基本数据类型、String 类型的变量写入输出流中
- DataInputStream:允许应用程序以与机器无关的方式从底层输入流中读取基本数据类型、String 类型的变量。
对象流 DataInputStream 中的方法:
byte readByte() short readShort()
int readInt() long readLong()
float readFloat() double readDouble()
char readChar() boolean readBoolean()
String readUTF() void readFully(byte[] b)
DataOutputStream 把read改成write
数据流的弊端:只支持 Java 基本数据类型和字符串的读写,而不支持其它 Java 对象的类型。
而 ObjectOutputStream 和 ObjectInputStream 既支持 Java 基本数据类型的数据读写,又支持 Java 对象的读写
ObjectOutputStream
public ObjectOutputStream(OutputStream out): 创建一个指定的ObjectOutputStream
public void writeBoolean(boolean val):写出一个 boolean 值。
public void writeByte(int val):写出一个 8 位字节
public void writeShort(int val):写出一个 16 位的 short 值
public void writeChar(int val):写出一个 16 位的 char 值
public void writeInt(int val):写出一个 32 位的 int 值
public void writeLong(long val):写出一个 64 位的 long 值
public void writeFloat(float val):写出一个 32 位的 float 值。
public void writeDouble(double val):写出一个 64 位的 double 值
public void writeUTF(String str):将表示长度信息的两个字节写入输出流,后跟字符串s 中每个字符的 UTF-8 修改版表示形式。根据字符的值,将字符串 s 中每个字符转换成一个字节、两个字节或三个字节的字节组。注意,将 String 作为基本数据写入流中与将它作为 Object 写入流中明显不同。 如果 s 为 null,则抛出NullPointerException。
public void writeObject(Object obj):写出一个 obj 对象
public void close() :关闭此输出流并释放与此流相关联的任何系统资源
ObjectInputStream
- public boolean readBoolean():读取一个 boolean 值
- public byte readByte():读取一个 8 位的字节
- public short readShort():读取一个 16 位的 short 值
- public char readChar():读取一个 16 位的 char 值
- public int readInt():读取一个 32 位的 int 值
- public long readLong():读取一个 64 位的 long 值
- public float readFloat():读取一个 32 位的 float 值
- public double readDouble():读取一个 64 位的 double 值
- public String readUTF():读取 UTF-8 修改版格式的 String
- public void readObject(Object obj):读入一个 obj 对象
- public void close() :关闭此输入流并释放与此流相关联的任何系统资源
对象序列化机制
序列化过程:用一个字节序列可以表示一个对象,该字节序列包含该对象的类型和对象中存储的属性等信息。字节序列写出到文件之后,相当于文件中持久保存了一个对象的信息。
反序列化过程:该字节序列还可以从文件中读取回来,重构对象,对它进行反序列化。对象的数据、对象的类型和对象中存储的数据信息,都可以用来在内存中创建对象。
序列化的好处,在于可将任何实现了 Serializable 接口的对象转化为字节数据,使其在保存和传输时可被还原
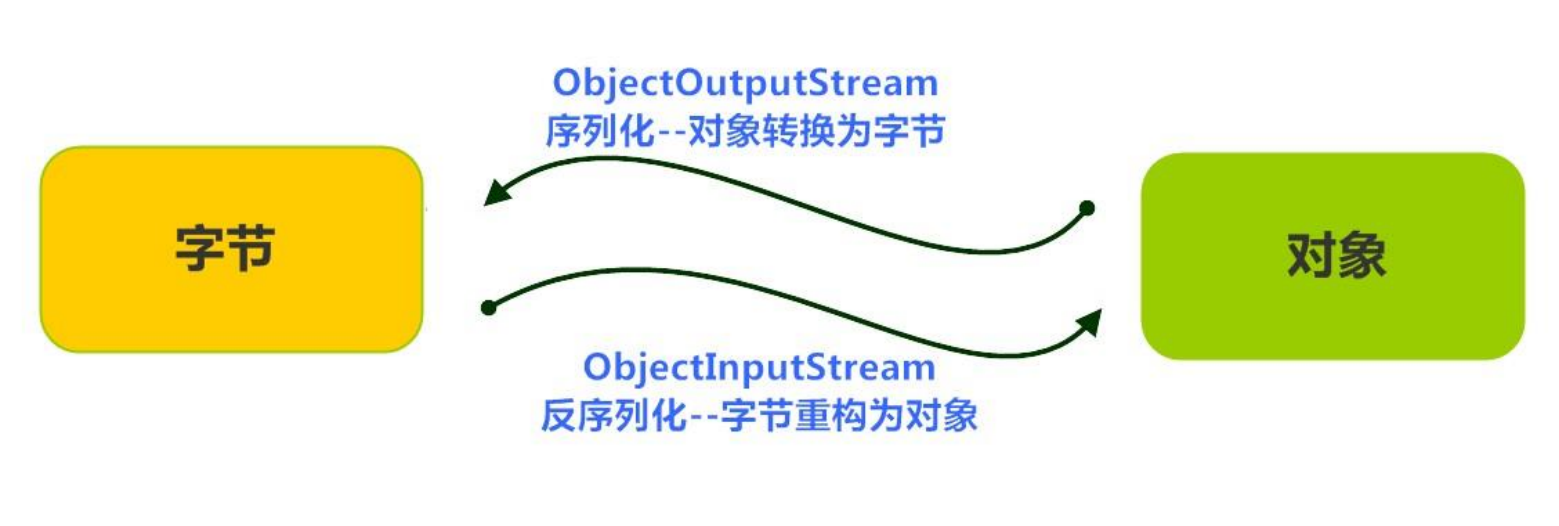
- 如果需要让某个对象支持序列化机制,则必须让对象所属的类及其属性是可序列化的,为了让某个类是可序列化的,该类必须实现 java.io.Serializable接口。Serializable 是一个标记接口,不实现此接口的类将不会使任何状态序列化或反序列化,会抛出 NotSerializableException 。
import java.io.*;
public class ReadWriteDataOfAnyType {
@Test
public void save() throws IOException {
String name = "巫师";
int age = 300;
char gender = '男';
int energy = 5000;
double price = 75.5;
boolean relive = true;
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("game.dat"));
oos.writeUTF(name);
oos.writeInt(age);
oos.writeChar(gender);
oos.writeInt(energy);
oos.writeDouble(price);
oos.writeBoolean(relive);
oos.close();
}
@Test
public void reload()throws IOException{
ObjectInputStream ois = new ObjectInputStream(new FileInputStream("game.dat"));
String name = ois.readUTF();
int age = ois.readInt();
char gender = ois.readChar();
int energy = ois.readInt();
double price = ois.readDouble();
boolean relive = ois.readBoolean();
System.out.println(name+"," + age + "," + gender + "," + energy + "," + price + "," + relive);
ois.close();
}
}import java.io.*;
import java.util.ArrayList;
public class ReadWriteCollection {
@Test
public void save() throws IOException {
ArrayList<Employee> list = new ArrayList<>();
list.add(new Employee("张三", "宏福苑", 23));
list.add(new Employee("李四", "白庙", 24));
list.add(new Employee("王五", "平西府", 25));
// 创建序列化流对象
ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream("employees.dat"));
// 写出对象
oos.writeObject(list);
// 释放资源
oos.close();
}
@Test
public void reload() throws IOException, ClassNotFoundException {
// 创建反序列化流
FileInputStream fis = new FileInputStream("employees.dat");
ObjectInputStream ois = new ObjectInputStream(fis);
// 读取一个对象
ArrayList<Employee> list = (ArrayList<Employee>) ois.readObject();
// 释放资源
ois.close();
fis.close();
System.out.println(list);
}
}对于 JVM 可以反序列化对象,它必须是能够找到 class 文件的类。如果找不到该类的 class 文件,则抛出一个 ClassNotFoundException 异常。
当 JVM 反序列化对象时,能找到 class 文件,但是 class 文件在序列化对象之后发生了修改,那么反序列化操作也会失败,抛出一个 InvalidClassException异常。发生这个异常的原因如下:
- 该类的序列版本号与从流中读取的类描述符的版本号不匹配
- 该类包含未知数据类型
标准输入、输出流
System.in 和 System.out 分别代表了系统标准的输入和输出设备
默认输入设备是:键盘,输出设备是:显示器
System.in 的类型是 InputStream
System.out 的类型是 PrintStream,其是 OutputStream 的子类 FilterOutputStream 的子类
重定向:通过 System 类的 setIn,setOut 方法对默认设备进行改变。
public static void setIn(InputStream in)
public static void setOut(PrintStream out)
打印流
PrintStream 和 PrintWriter
- PrintStream 和 PrintWriter 的输出不会抛出 IOException 异常
- PrintStream 和 PrintWriter 有自动 flush 功能
- PrintStream 打印的所有字符都使用平台的默认字符编码转换为字节。在需要写入字符而不是写入字节的情况下,应该使用 PrintWriter 类
- System.out 返回的是 PrintStream 的实例
Scanner
apache-common
网络编程
lambda
- 语法格式一:无参,无返回值
@Test
public void test1(){
//未使用 Lambda 表达式
Runnable r1 = new Runnable() {
@Override
public void run() {
System.out.println("我爱北京天安门");
}
};
r1.run();
System.out.println("***********************");
//使用 Lambda 表达式
Runnable r2 = () -> {
System.out.println("我爱北京故宫");
};
r2.run();
}- 语法格式二:Lambda 需要一个参数,但是没有返回值。
@Test
public void test2(){
//未使用 Lambda 表达式
Consumer<String> con = new Consumer<String>() {
@Override
public void accept(String s) {
System.out.println(s);
}
};
con.accept("谎言和誓言的区别是什么?");
System.out.println("*******************");
//使用 Lambda 表达式
Consumer<String> con1 = (String s) -> {
System.out.println(s);
};
con1.accept("一个是听得人当真了,一个是说的人当真了");
}- 语法格式三:数据类型可以省略,因为可由编译器推断得出,称为“类型推断”
@Test
public void test3(){
//语法格式三使用前
Consumer<String> con1 = (String s) -> {
System.out.println(s);
};
con1.accept("一个是听得人当真了,一个是说的人当真了");
System.out.println("*******************");
//语法格式三使用后
Consumer<String> con2 = (s) -> {
System.out.println(s);
};
con2.accept("一个是听得人当真了,一个是说的人当真了");
}- 语法格式四:Lambda 若只需要一个参数时,参数的小括号可以省略
@Test
public void test4(){
//语法格式四使用前
Consumer<String> con1 = (s) -> {
System.out.println(s);
};
con1.accept("一个是听得人当真了,一个是说的人当真了");
System.out.println("*******************");
//语法格式四使用后
Consumer<String> con2 = s -> {
System.out.println(s);
};
con2.accept("一个是听得人当真了,一个是说的人当真了");
}- 语法格式五:Lambda 需要两个或以上的参数,多条执行语句,并且可以有返回值
@Test
public void test5(){
//语法格式五使用前
Comparator<Integer> com1 = new Comparator<Integer>() {
@Override
public int compare(Integer o1, Integer o2) {
System.out.println(o1);
System.out.println(o2);
return o1.compareTo(o2);
}
};
System.out.println(com1.compare(12,21));
System.out.println("*****************************");
//语法格式五使用后
Comparator<Integer> com2 = (o1,o2) -> {
System.out.println(o1);
System.out.println(o2);
return o1.compareTo(o2);
};
System.out.println(com2.compare(12,6));
}- 语法格式六:当 Lambda 体只有一条语句时,return 与大括号若有,都可以省略
@Test
public void test6(){
//语法格式六使用前
Comparator<Integer> com1 = (o1,o2) -> {
return o1.compareTo(o2);
};
System.out.println(com1.compare(12,6));
System.out.println("*****************************");
//语法格式六使用后
Comparator<Integer> com2 = (o1,o2) -> o1.compareTo(o2);
System.out.println(com2.compare(12,21));
}
@Test
public void test7(){
//语法格式六使用前
Consumer<String> con1 = s -> {
System.out.println(s);
};
con1.accept("一个是听得人当真了,一个是说的人当真了");
System.out.println("*****************************");
//语法格式六使用后
Consumer<String> con2 = s -> System.out.println(s);
con2.accept("一个是听得人当真了,一个是说的人当真了");
}- 函数式接口才能用lambda
方法引用
Stream API
像视图
不改变原来,本身也不保存数据
操作需要终止才会执行
新特性
var 类似于c++ auto
switch case 的 -> 。用 -> 代替 :,不用写break。且可以用变量接收switch的结果。yield,返回值