
SpringCloud
Mybatis-Plus
MyBatis-Plus 🚀 为简化开发而生 (baomidou.com)
擅长单表操作
使用步骤
导入依赖
MybatisPlus提供了starter,实现了自动Mybatis以及MybatisPlus的自动装配功能
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.5.3.1</version>
</dependency>原来的Mapper继承BaseMapper
❗️需要指定泛型
public interface UserMapper 🚩 extends BaseMapper<User>{
}修改原来的方法
@SpringBootTest
class UserMapperTest {
@Autowired
private UserMapper userMapper;
@Test
void testInsert() {
User user = new User();
user.setId(5L);
user.setUsername("Lucy");
user.setPassword("123");
user.setPhone("18688990011");
user.setBalance(200);
user.setInfo("{\"age\": 24, \"intro\": \"英文老师\", \"gender\": \"female\"}");
user.setCreateTime(LocalDateTime.now());
user.setUpdateTime(LocalDateTime.now());
-userMapper.saveUser(user);
+userMapper.insert(user);
}
@Test
void testSelectById() {
-User user = userMapper.queryUserById(5L);
+User user = userMapper.selectById(5L);
System.out.println("user = " + user);
}
@Test
void testQueryByIds() {
-List<User> users = userMapper.queryUserByIds(List.of(1L, 2L, 3L, 4L));
+List<User> users = userMapper.selectBatchIds(List.of(1L, 2L, 3L, 4L));
users.forEach(System.out::println);
}
@Test
void testUpdateById() {
User user = new User();
user.setId(5L);
user.setBalance(20000);
-userMapper.updateUser(user);
+userMapper.updateById(user)
}
@Test
void testDeleteUser() {
-userMapper.deleteUser(5L);
+userMapper.deleteById(5L);
}
}常见注解
MybatisPlus如何知道要查询的是哪张表?表中有哪些字段呢?
MyBatisPlus通过扫描实体类,并基于反射获取实体类信息作为数据库表信息。
大家回忆一下,UserMapper在继承BaseMapper的时候指定了一个泛型:
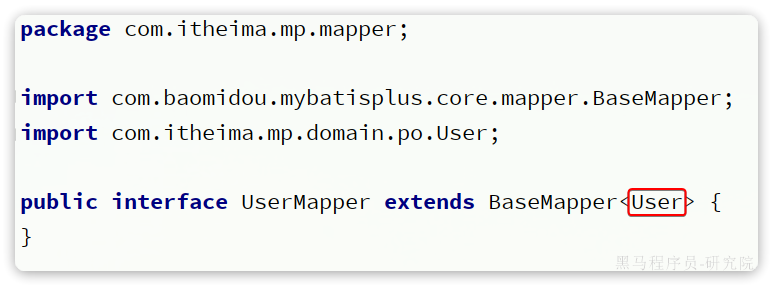
泛型中的User就是与数据库对应的PO.
MybatisPlus就是根据PO实体的信息来推断出表的信息,从而生成SQL的。默认情况下:
- MybatisPlus会把PO实体的类名驼峰转下划线作为表名
- MybatisPlus会把PO实体的所有变量名驼峰转下划线作为表的字段名,并根据变量类型推断字段类型
- MybatisPlus会把名为id的字段作为主键
但很多情况下,默认的实现与实际场景不符,因此MybatisPlus提供了一些注解便于声明表信息。
@TableName
- 描述:表名注解,标识实体类对应的表
- 使用位置:实体类
@TableName("user")
public class User {
private Long id;
private String name;
}| 属性 | 类型 | 必须指定 | 默认值 | 描述 |
|---|---|---|---|---|
| value | String | 否 | "" | 表名 |
| schema | String | 否 | "" | schema |
| keepGlobalPrefix | boolean | 否 | false | 是否保持使用全局的 tablePrefix 的值(当全局 tablePrefix 生效时) |
| resultMap | String | 否 | "" | xml 中 resultMap 的 id(用于满足特定类型的实体类对象绑定) |
| autoResultMap | boolean | 否 | false | 是否自动构建 resultMap 并使用(如果设置 resultMap 则不会进行 resultMap 的自动构建与注入) |
| excludeProperty | String[] | 否 | {} | 需要排除的属性名 @since 3.3.1 |
@TableId
- 描述:主键注解,标识实体类中的主键字段
- 使用位置:实体类的主键字段
@TableName("user")
public class User {
@TableId(type = IdType.AUTO)
private Long id;
private String name;
}TableId注解支持两个属性:
| 属性 | 类型 | 必须指定 | 默认值 | 描述 |
|---|---|---|---|---|
| value | String | 否 | "" | 表名 |
| type | Enum | 否 | IdType.NONE | 指定主键类型 |
IdType支持的类型有:
| 值 | 描述 |
|---|---|
| AUTO | 数据库 ID 自增 |
| NONE | 无状态,该类型为未设置主键类型(注解里等于跟随全局,全局里约等于 INPUT) |
| INPUT | insert 前自行 set 主键值 |
| ASSIGN_ID | 分配 ID(主键类型为 Number(Long 和 Integer)或 String)(since 3.3.0),使用接口IdentifierGenerator的方法nextId(默认实现类为DefaultIdentifierGenerator雪花算法) |
| ASSIGN_UUID | 分配 UUID,主键类型为 String(since 3.3.0),使用接口IdentifierGenerator的方法nextUUID(默认 default 方法) |
| ID_WORKER | 分布式全局唯一 ID 长整型类型(please use ASSIGN_ID) |
| UUID | 32 位 UUID 字符串(please use ASSIGN_UUID) |
| ID_WORKER_STR | 分布式全局唯一 ID 字符串类型(please use ASSIGN_ID) |
这里比较常见的有三种:
AUTO:利用数据库的id自增长INPUT:手动生成idASSIGN_ID:雪花算法生成Long类型的全局唯一id,这是默认的ID策略- 不指定,默认❄️算法
@TableField
描述:普通字段注解
@TableName("user")
public class User {
@TableId
private Long id;
private String name;
private Integer age;
@TableField("isMarried")
private Boolean isMarried;
@TableField("concat")
private String concat;
}一般情况下并不需要给字段添加@TableField注解,一些特殊情况除外:
- 成员变量名与数据库字段名不一致
- 成员变量是以
isXXX命名,按照JavaBean的规范,MybatisPlus识别字段时会把is去除,这就导致与数据库不符。 - 成员变量名与数据库一致,但是与数据库的关键字冲突。使用
@TableField注解给字段名添加转义字符:``
支持的其它属性如下:
| 属性 | 类型 | 必填 | 默认值 | 描述 |
|---|---|---|---|---|
| value | String | 否 | "" | 数据库字段名 |
| exist | boolean | 否 | true | 是否为数据库表字段 |
| condition | String | 否 | "" | 字段 where 实体查询比较条件,有值设置则按设置的值为准,没有则为默认全局的 %s=#{%s},参考(opens new window) |
| update | String | 否 | "" | 字段 update set 部分注入,例如:当在version字段上注解update="%s+1" 表示更新时会 set version=version+1 (该属性优先级高于 el 属性) |
| insertStrategy | Enum | 否 | FieldStrategy.DEFAULT | 举例:NOT_NULL insert into table_a() values () |
| updateStrategy | Enum | 否 | FieldStrategy.DEFAULT | 举例:IGNORED update table_a set column=# |
| whereStrategy | Enum | 否 | FieldStrategy.DEFAULT | 举例:NOT_EMPTY where |
| fill | Enum | 否 | FieldFill.DEFAULT | 字段自动填充策略 |
| select | boolean | 否 | true | 是否进行 select 查询 |
| keepGlobalFormat | boolean | 否 | false | 是否保持使用全局的 format 进行处理 |
| jdbcType | JdbcType | 否 | JdbcType.UNDEFINED | JDBC 类型 (该默认值不代表会按照该值生效) |
| typeHandler | TypeHander | 否 | 类型处理器 (该默认值不代表会按照该值生效) | |
| numericScale | String | 否 | "" | 指定小数点后保留的位数 |
常见配置
配置 | MyBatis-Plus (baomidou.com)
大多数的配置都有默认值,因此都无需配置。但还有一些是没有默认值的,例如:
- 实体类的别名扫描包
- 全局id类型
mybatis-plus:
type-aliases-package: com.itheima.mp.domain.po
global-config:
db-config:
id-type: auto # 全局id类型为自增长需要注意的是,MyBatisPlus也支持手写SQL的,而mapper文件的读取地址可以自己配置:
mybatis-plus:
mapper-locations: "classpath*:/mapper/**/*.xml" # Mapper.xml文件地址,当前这个是默认值。可以看到默认值是classpath*:/mapper/**/*.xml,也就是说只要把mapper.xml文件放置这个目录下就一定会被加载。
例如,新建一个UserMapper.xml文件:
然后在其中定义一个方法:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.itheima.mp.mapper.UserMapper">
<select id="queryById" resultType="User">
SELECT * FROM user WHERE id = #{id}
</select>
</mapper>然后在测试类UserMapperTest中测试该方法:
@Test
void testQuery() {
User user = userMapper.queryById(1L);
System.out.println("user = " + user);
}条件构造器
Wrapper
参数中的Wrapper就是条件构造的抽象类,其下有很多默认实现,继承关系如图:
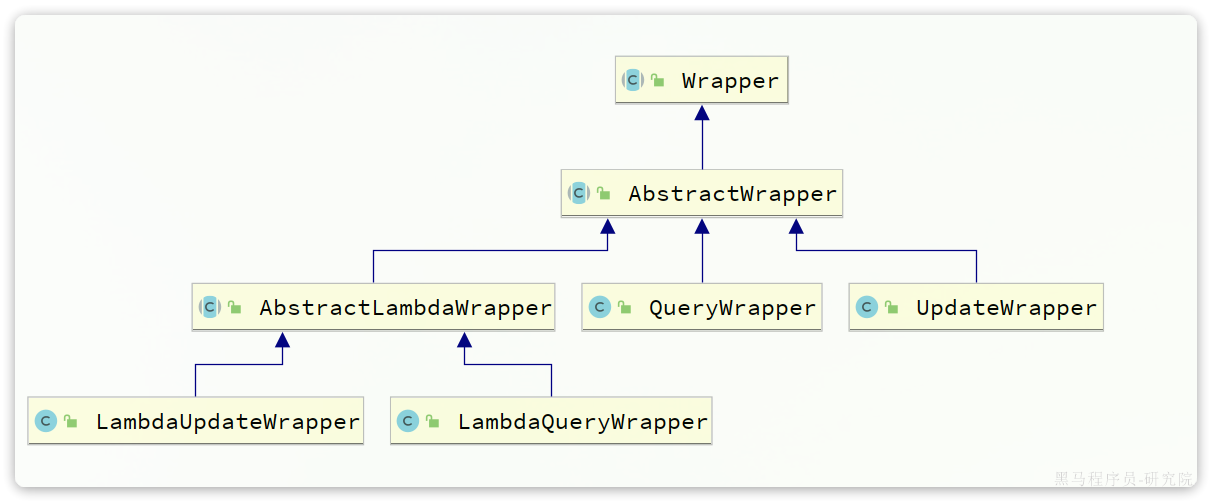
Wrapper的子类AbstractWrapper提供了where中包含的所有条件构造方法:
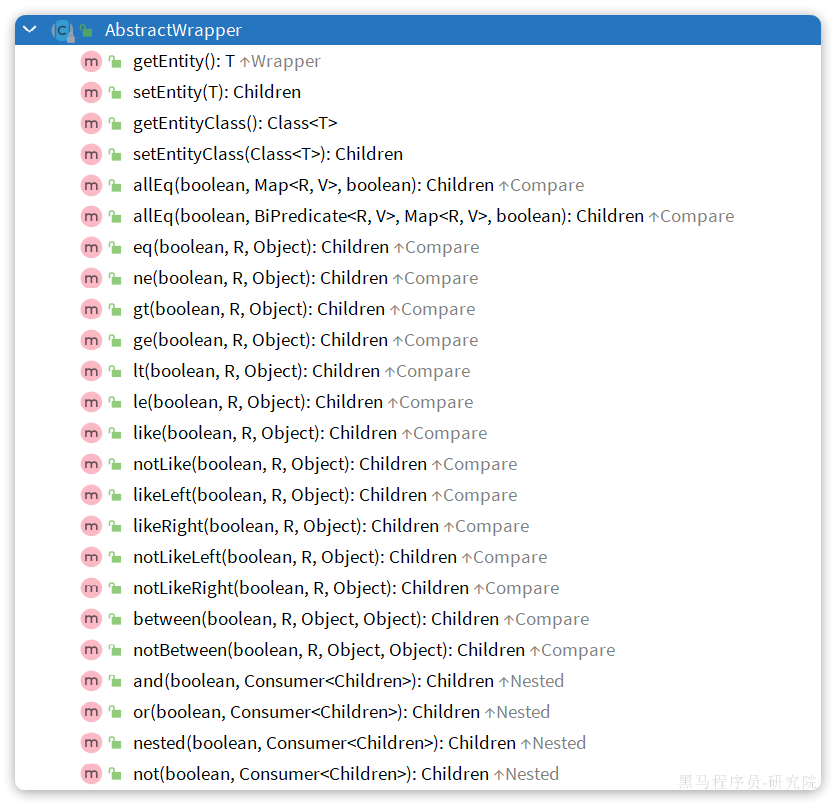
而QueryWrapper在AbstractWrapper的基础上拓展了一个select方法,允许指定查询字段:

而UpdateWrapper在AbstractWrapper的基础上拓展了一个set方法,允许指定SQL中的SET部分:

@Test
void testQueryWrapper() {
QueryWrapper<User> wrapper = new QueryWrapper<User>()
.select("id", "username", "info", "balance")
.like("username", "o")
.gt("balance", 1000);
List<User> users = userMapper.selectList(wrapper);
users.forEach(System.out::println);
} @Test
void testUpdateByQueryWrapper(){
User user = new User();
user.setBalance(2000);
QueryWrapper<User> wrapper = new QueryWrapper<User>()
.eq("username", "jack");
int update = userMapper.update(user, wrapper);
System.out.println(update);
}
@Test
void testUpdateWrapper1(){
UpdateWrapper<User> wrapper = new UpdateWrapper<User>()
.set("balance", 2000)
.eq("username", "jack");
int update = userMapper.update(null, wrapper);
System.out.println(update);
} @Test
void testUpdateWrapper2(){
List<Long> ids = List.of(1L, 2L, 4L);
UpdateWrapper<User> wrapper = new UpdateWrapper<User>()
.setSql("balance = balance - 200")
.in("id", 1, 2, 4);
// .in("id", ids);
int update = userMapper.update(null, wrapper);
System.out.println(update);
}LambdaWrapper减少硬编码,推荐使用
@Test
void testLambdaQueryWrapper(){
LambdaQueryWrapper<User> wrapper = new LambdaQueryWrapper<User>()
.select(User::getId, User::getUsername, User::getInfo, User::getBalance)
.like(User::getUsername, "o")
.ge(User::getBalance, 800);
List<User> users = userMapper.selectList(wrapper);
users.forEach(System.out::println);
}WARNING: An illegal reflective access operation has occurred
WARNING: Illegal reflective access by com.baomidou.mybatisplus.core.toolkit.SetAccessibleAction (file:/E:/MySoftware/apache-maven-3.9.6/local%20repository/com/baomidou/mybatis-plus-core/3.5.3.1/mybatis-plus-core-3.5.3.1.jar) to field java.lang.invoke.SerializedLambda.capturingClass
WARNING: Please consider reporting this to the maintainers of com.baomidou.mybatisplus.core.toolkit.SetAccessibleAction
WARNING: Use --illegal-access=warn to enable warnings of further illegal reflective access operations
WARNING: All illegal access operations will be denied in a future release
13:54:06 INFO 35160 --- [ main] com.zaxxer.hikari.HikariDataSource : HikariPool-1 - Starting...
13:54:07 INFO 35160 --- [ main] com.zaxxer.hikari.HikariDataSource : HikariPool-1 - Start completed.
13:54:07 DEBUG 35160 --- [ main] c.i.mp.mapper.UserMapper.selectList : ==> Preparing: SELECT id,username,info,balance FROM user WHERE (username LIKE ? AND balance >= ?)
13:54:07 DEBUG 35160 --- [ main] c.i.mp.mapper.UserMapper.selectList : ==> Parameters: %o%(String), 800(Integer)
13:54:07 DEBUG 35160 --- [ main] c.i.mp.mapper.UserMapper.selectList : <== Total: 1
User(id=3, username=Hope, password=null, phone=null, info={"age": 25, "intro": "上进青年", "gender": "male"}, status=null, balance=100000, createTime=null, updateTime=null)自定义SQL
在某些企业也是不允许在业务层写SQL,因为SQL语句最好都维护在持久层,而不是业务层。
可以利用MyBatisPlus的Wrapper来构建复杂的Where条件,然后自己定义SQL语句中剩下的部分。
基于Wrapper构建where条件
List<Long> ids = List.of(1L, 2L, 4L);
int amount = 200;
LambdaQueryWrapper<User> wrapper = new LambdaQueryWrapper<User>()
.in(User::getId, ids);在mapper方法参数中用Param注解声明wrapper变量名称,❗️必须是ew
userMapper.updateBalanceByIds(wrapper, amount);自定义SQL,并使用Wrapper条件
public interface UserMapper extends BaseMapper<User> {
void updateBalanceByIds(@Param("ew") LambdaQueryWrapper<User> wrapper, @Param("amount") int amount);
}<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.itheima.mp.mapper.UserMapper">
<update id="updateBalanceByIds">
update user set balance = balance - #{amount} ${ew.customSqlSegment}
</update>
</mapper> @Test
void testCustomSqlUpdate(){
List<Long> ids = List.of(1L, 2L, 4L);
int amount = 200;
LambdaQueryWrapper<User> wrapper = new LambdaQueryWrapper<User>()
.in(User::getId, ids);
userMapper.updateBalanceByIds(wrapper, amount);
}IService接口
MybatisPlus不仅提供了BaseMapper,还提供了通用的Service接口及默认实现,封装了一些常用的service模板方法。 通用接口为IService,默认实现为ServiceImpl,其中封装的方法可以分为以下几类:
save:新增remove:删除update:更新get:查询单个结果list:查询集合结果count:计数page:分页查询
使用步骤
分别继承接口和实现类
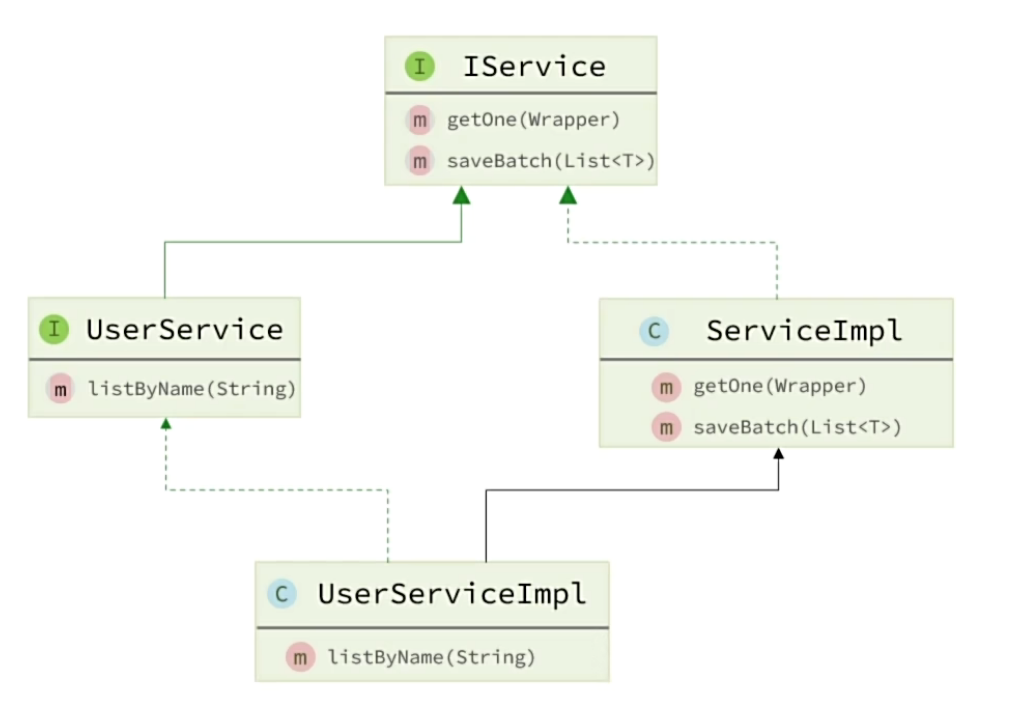
接口
public interface IUserService extends IService<User> {
}实现类
@Service
public class IUserServiceImpl extends ServiceImpl<UserMapper, User> implements IUserService {
}测试
@SpringBootTest
class IUserServiceTest {
@Resource
private IUserService userService;
@Test
void testSaveUser(){
User user = new User();
user.setUsername("test");
user.setPassword("123456");
user.setPhone("11111111111");
user.setBalance(200);
user.setInfo("{\"age\": 24, \"intro\": \"英文老师\", \"gender\": \"female\"}");
userService.save(user);
}
}
开发基础业务接口
| 编号 | 接口 | 请求方式 | 请求路径 | 请求参数 | 返回值 |
|---|---|---|---|---|---|
| 1 | 新增用户 | POST | /users | 用户表单实体 | 无 |
| 2 | 删除用户 | DELETE | /users/ | 用户id | 无 |
| 3 | 根据id查询用户 | GET | /users/ | 用户id | 用户VO |
| 4 | 根据id批量查询 | GET | /users | 用户id集合 | 用户VO集合 |
引入Swagger和web依赖
<!--swagger-->
<dependency>
<groupId>com.github.xiaoymin</groupId>
<artifactId>knife4j-openapi2-spring-boot-starter</artifactId>
<version>4.1.0</version>
</dependency>
<!--web-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>修改配置文件
spring:
datasource:
url: jdbc:mysql://127.0.0.1:3306/mp?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true&serverTimezone=Asia/Shanghai
driver-class-name: com.mysql.cj.jdbc.Driver
username: cdd
password: 1
logging:
level:
com.itheima: debug
pattern:
dateformat: HH:mm:ss
mybatis-plus:
type-aliases-package: com.itheima.mp.domain.po
global-config:
db-config:
id-type: auto # 全局id类型为自增长
mapper-locations: "classpath*:/mapper/**/*.xml" # Mapper.xml文件地址,当前这个是默认值。
knife4j:
enable: true
openapi:
title: 用户管理接口文档
description: "用户管理接口文档"
email: [email protected]
concat: CharmingDaiDai
version: v1.0.0
group:
default:
group-name: default
api-rule: package
api-rule-resources:
- com.itheima.mp.controller创建VO和DTO实体类
创建UserController
package com.itheima.mp.controller;
import cn.hutool.core.bean.BeanUtil;
import com.itheima.mp.domain.dto.UserFormDTO;
import com.itheima.mp.domain.po.User;
import com.itheima.mp.domain.vo.UserVO;
import com.itheima.mp.service.IUserService;
import io.swagger.annotations.Api;
import io.swagger.annotations.ApiOperation;
import io.swagger.annotations.ApiParam;
import lombok.extern.slf4j.Slf4j;
import org.apache.ibatis.annotations.Param;
import org.springframework.web.bind.annotation.*;
import javax.annotation.Resource;
import java.util.ArrayList;
import java.util.List;
/**
* @Author:CharmingDaiDai
* @Project:mp-demo
* @Date:2024/5/17 下午3:51
*/
@RestController
@Api(tags = "用户管理")
@RequestMapping("/users")
@Slf4j
public class UserController {
@Resource
private IUserService iUserService;
@ApiOperation(value = "新增用户")
@PostMapping
public void saveUser(@RequestBody UserFormDTO userDTO){
User user = BeanUtil.copyProperties(userDTO, User.class);
iUserService.save(user);
}
@ApiOperation(value = "删除用户")
@DeleteMapping("/{id}")
public void deleteUser(@ApiParam("用户id") @PathVariable Long id){
iUserService.removeById(id);
}
@ApiOperation(value = "根据id查询用户")
@GetMapping("/{id}")
public UserVO getById(@PathVariable Long id){
User user = iUserService.getById(id);
return BeanUtil.copyProperties(user, UserVO.class);
}
@ApiOperation(value = "根据id批量查询")
@GetMapping("/users")
public List<UserVO> getByIds(@RequestParam("ids") List<Long> ids){
List<User> users = iUserService.listByIds(ids);
return BeanUtil.copyToList(users, UserVO.class);
}
}开发复杂业务接口
一些带有业务逻辑的接口则需要在service中自定义实现了。例如下面的需求:
- 根据id扣减用户余额
这看起来是个简单修改功能,只要修改用户余额即可。但这个业务包含一些业务逻辑处理:
- 判断用户状态是否正常
- 判断用户余额是否充足
这些业务逻辑都要在service层来做,另外更新余额需要自定义SQL,要在mapper中来实现。因此,除了要编写controller以外,具体的业务还要在service和mapper中编写。
UserController
@PutMapping("{id}/deduction/{money}")
@ApiOperation("扣减用户余额")
public String deductBalance(@PathVariable("id") Long id, @PathVariable("money")Integer money){
return iUserService.deductBalance(id, money);
}IUserServiceImpl
package com.itheima.mp.service.impl;
/**
* @Author:CharmingDaiDai
* @Project:mp-demo
* @Date:2024/5/17 下午3:36
*/
@Service
public class IUserServiceImpl extends ServiceImpl<UserMapper, User> implements IUserService {
@Resource
// userMapper可以不用注入
// 因为已经继承了baseMapper,直接使用baseMapper
private UserMapper userMapper;
@Override
public String deductBalance(Long id, Integer money) {
// 直接调用实现的service接口
// User user = getById(id);
User user = userMapper.selectById(id);
if(user==null || user.getStatus() == 2){
return "用户状态异常!";
}
if (user.getBalance() <money ){
return "余额不足!";
}
user.setBalance(user.getBalance() - money);
// updateById(user);
userMapper.updateById(user);
return "扣减余额成功!";
}
} // 4.扣减余额
baseMapper.deductMoneyById(id, money);
@Update("UPDATE user SET balance = balance - #{money} WHERE id = #{id}")
void deductMoneyById(@Param("id") Long id, @Param("money") Integer money);Lambda
案例一:实现一个根据复杂条件查询用户的接口,查询条件如下:
- name:用户名关键字,可以为空
- status:用户状态,可以为空
- minBalance:最小余额,可以为空
- maxBalance:最大余额,可以为空
可以理解成一个用户的后台管理界面,管理员可以自己选择条件来筛选用户,因此上述条件不一定存在,需要做判断。
controller
@ApiOperation(value = "根据条件查询")
@GetMapping("/list")
public List<UserVO> getUsers(UserQuery userQuery){
List<User> users = iUserService.list(userQuery);
return BeanUtil.copyToList(users, UserVO.class);
}实现类
@Override
public List<User> list(UserQuery userQuery) {
String name = userQuery.getName();
Integer status = userQuery.getStatus();
Integer maxBalance = userQuery.getMaxBalance();
Integer minBalance = userQuery.getMinBalance();
List<User> users = lambdaQuery()
.like(name != null, User::getUsername, name)
.eq(status != null, User::getStatus, status)
.lt(maxBalance != null, User::getBalance, maxBalance)
.gt(minBalance != null, User::getBalance, minBalance)
.list();
return users;
}❗️记得➕.list()
需求:改造根据id修改用户余额的接口,要求如下
- 如果扣减后余额为0,则将用户status修改为冻结状态(2)
也就是说在扣减用户余额时,需要对用户剩余余额做出判断,如果发现剩余余额为0,则应该将status修改为2,这就是说update语句的set部分是动态的。
@Override
@Transactional(propagation = Propagation.REQUIRED, rollbackFor = Exception.class)
public String deductBalance(Long id, Integer money) {
// 直接调用实现的service接口
// User user = getById(id);
User user = userMapper.selectById(id);
if(user==null || user.getStatus() == 2){
return "用户状态异常!";
}
Integer balance = user.getBalance();
if (balance <money ){
return "余额不足!";
}
int remainBalance = balance - money;
// 使用乐观锁确保并发安全
boolean updateSuccess = lambdaUpdate()
.set(User::getBalance, remainBalance)
.set(remainBalance == 0, User::getStatus, 2)
.eq(User::getId, id)
.eq(User::getBalance, balance)
.update();
return "扣减余额成功!";
}❗️记得➕.update() 前面只是构建语句,不加不会执行
ℹ️@Transactional
在Spring框架中,@Transactional注解用于管理方法或类的事务行为。它提供了多个属性来配置事务的具体行为,其中 propagation 和 rollbackFor 是两个常用的属性。
Propagation(传播行为)
传播行为(Propagation)定义了事务的边界,决定了当前方法是否应该在一个现有事务中运行,或者是否应该启动一个新的事务。Spring提供了七种传播行为:
REQUIRED(默认值):
- 如果当前已经存在一个事务,则当前方法将在该事务中运行。
- 如果当前没有事务,则会启动一个新的事务。
- 这是最常用的传播行为,确保方法始终在事务中运行。
REQUIRES_NEW:
- 无论是否存在当前事务,总是会启动一个新的事务。
- 如果当前已经有一个事务,则该事务会被挂起,直到新的事务完成。
SUPPORTS:
- 如果当前存在一个事务,则当前方法在该事务中运行。
- 如果当前没有事务,则该方法不在事务中运行。
NOT_SUPPORTED:
- 如果当前存在一个事务,则该事务会被挂起,当前方法在没有事务的情况下运行。
MANDATORY:
- 必须在一个现有事务中运行,如果当前没有事务,则抛出异常。
NEVER:
- 当前方法必须在没有事务的情况下运行,如果当前存在事务,则抛出异常。
NESTED:
- 如果当前存在一个事务,则在该事务的嵌套事务中运行。
- 如果当前没有事务,则启动一个新的事务。
- 嵌套事务是通过保存点(savepoint)实现的,可以部分回滚到保存点,而不影响外部事务。
rollbackFor(回滚规则)
rollbackFor属性定义了哪些异常会导致事务回滚。默认情况下,Spring只会在未检查异常(unchecked exceptions,继承自RuntimeException的异常)和错误(Error)上回滚事务,但可以通过rollbackFor指定其他类型的异常。
rollbackFor:指定一个或多个异常类,当这些异常被抛出时,事务将回滚。例如:@Transactional(rollbackFor = Exception.class)这意味着当方法中抛出
Exception或其子类异常时,事务将回滚。Exception是所有受检查异常(checked exceptions)和未检查异常的基类,所以这种配置会捕获几乎所有类型的异常。
详细示例
下面是一个使用 @Transactional 的详细示例,结合了 propagation 和 rollbackFor:
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import org.springframework.transaction.annotation.Propagation;
import org.springframework.transaction.annotation.Transactional;
@Service
public class UserService {
@Autowired
private UserMapper userMapper;
@Transactional(propagation = Propagation.REQUIRED, rollbackFor = Exception.class)
public String deductBalance(Long id, Integer money) {
// 获取用户信息
User user = userMapper.selectById(id);
if (user == null || user.getStatus() == 2) {
return "用户状态异常!";
}
Integer balance = user.getBalance();
if (balance < money) {
return "余额不足!";
}
int remainBalance = balance - money;
// 使用乐观锁确保并发安全
boolean updateSuccess = userMapper.updateUserBalance(id, remainBalance, balance);
if (!updateSuccess) {
return "余额扣减失败,请重试!";
}
return "扣减余额成功!";
}
}解释
propagation = Propagation.REQUIRED:
- 确保
deductBalance方法始终在一个事务中运行。如果调用该方法时已经有一个事务在进行,则在该事务中运行;否则,会启动一个新的事务。
- 确保
rollbackFor = Exception.class:
- 指定了方法在捕获任何
Exception或其子类异常时回滚事务。这样可以确保即使是受检查异常也会触发事务回滚。
- 指定了方法在捕获任何
使用场景
- REQUIRED:适用于大多数情况,确保方法在事务中运行。是最常用的传播行为。
- REQUIRES_NEW:适用于需要独立的事务处理逻辑,不影响当前事务的场景。
- rollbackFor = Exception.class:适用于希望捕获所有异常(包括受检查异常和未检查异常)并回滚事务的情况。
通过合理配置 @Transactional 注解,可以灵活地控制事务的行为,确保数据的一致性和完整性。
批量新增
逐条
IService中的批量新增功能使用起来非常方便,但有一点注意事项,先来测试一下。 首先测试逐条插入数据:
@Test
void testSaveOneByOne() {
long b = System.currentTimeMillis();
for (int i = 1; i <= 100000; i++) {
userService.save(buildUser(i));
}
long e = System.currentTimeMillis();
System.out.println("耗时:" + (e - b));
}
private User buildUser(int i) {
User user = new User();
user.setUsername("user_" + i);
user.setPassword("123");
user.setPhone("" + (18688190000L + i));
user.setBalance(2000);
user.setInfo("{\"age\": 24, \"intro\": \"英文老师\", \"gender\": \"female\"}");
user.setCreateTime(LocalDateTime.now());
user.setUpdateTime(user.getCreateTime());
return user;
}执行结果如下:
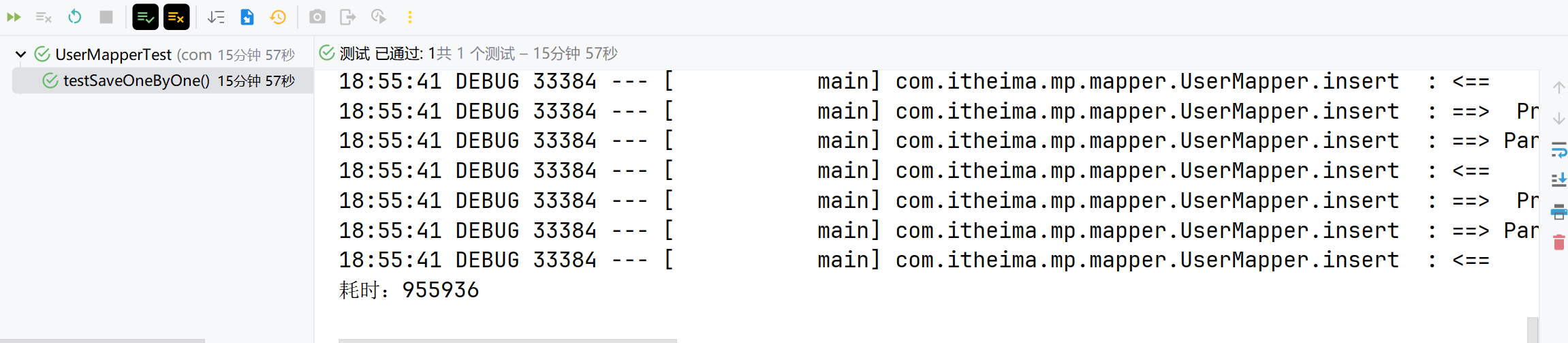
可以看到速度非常慢。
批处理
然后再试试MybatisPlus的批处理:
@Test
void testSaveBatch() {
// 准备10万条数据
List<User> list = new ArrayList<>(1000);
long b = System.currentTimeMillis();
for (int i = 1; i <= 100000; i++) {
list.add(buildUser(i));
// 每1000条批量插入一次
if (i % 1000 == 0) {
userService.saveBatch(list);
list.clear();
}
}
long e = System.currentTimeMillis();
System.out.println("耗时:" + (e - b));
}执行最终耗时如下:
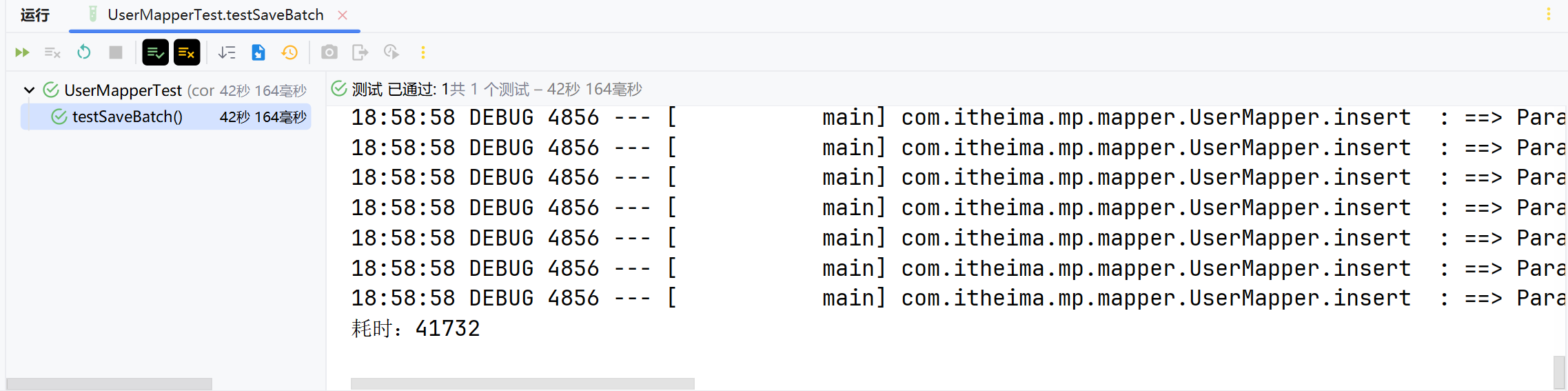
可以看到使用了批处理以后,比逐条新增效率提高了10倍左右,性能还是不错的。
不过,简单查看一下MybatisPlus源码:
@Transactional(rollbackFor = Exception.class)
@Override
public boolean saveBatch(Collection<T> entityList, int batchSize) {
String sqlStatement = getSqlStatement(SqlMethod.INSERT_ONE);
return executeBatch(entityList, batchSize, (sqlSession, entity) -> sqlSession.insert(sqlStatement, entity));
}
// ...SqlHelper
public static <E> boolean executeBatch(Class<?> entityClass, Log log, Collection<E> list, int batchSize, BiConsumer<SqlSession, E> consumer) {
Assert.isFalse(batchSize < 1, "batchSize must not be less than one");
return !CollectionUtils.isEmpty(list) && executeBatch(entityClass, log, sqlSession -> {
int size = list.size();
int idxLimit = Math.min(batchSize, size);
int i = 1;
for (E element : list) {
consumer.accept(sqlSession, element);
if (i == idxLimit) {
sqlSession.flushStatements();
idxLimit = Math.min(idxLimit + batchSize, size);
}
i++;
}
});
}可以发现其实MybatisPlus的批处理是基于PrepareStatement的预编译模式,然后批量提交,最终在数据库执行时还是会有多条insert语句,逐条插入数据。SQL类似这样:
Preparing: INSERT INTO user ( username, password, phone, info, balance, create_time, update_time ) VALUES ( ?, ?, ?, ?, ?, ?, ? )
Parameters: user_1, 123, 18688190001, "", 2000, 2023-07-01, 2023-07-01
Parameters: user_2, 123, 18688190002, "", 2000, 2023-07-01, 2023-07-01
Parameters: user_3, 123, 18688190003, "", 2000, 2023-07-01, 2023-07-01而如果想要得到最佳性能,最好是将多条SQL合并为一条,像这样:
INSERT INTO user ( username, password, phone, info, balance, create_time, update_time )
VALUES
(user_1, 123, 18688190001, "", 2000, 2023-07-01, 2023-07-01),
(user_2, 123, 18688190002, "", 2000, 2023-07-01, 2023-07-01),
(user_3, 123, 18688190003, "", 2000, 2023-07-01, 2023-07-01),
(user_4, 123, 18688190004, "", 2000, 2023-07-01, 2023-07-01);该怎么做呢?
rewriteBatchedStatements
MySQL的客户端连接参数中有这样的一个参数:rewriteBatchedStatements。顾名思义,就是重写批处理的statement语句.
这个参数的默认值是false,需要修改连接参数,将其配置为true
修改项目中的application.yml文件,在jdbc的url后面添加参数&rewriteBatchedStatements=true:
spring:
datasource:
url: jdbc:mysql://127.0.0.1:3306/mp?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true&serverTimezone=Asia/Shanghai&rewriteBatchedStatements=true
driver-class-name: com.mysql.cj.jdbc.Driver
username: cdd
password: 1再次测试插入10万条数据,可以发现速度有非常明显的提升:
在ClientPreparedStatement的executeBatchInternal中,有判断rewriteBatchedStatements值是否为true并重写SQL的功能:
最终,SQL被重写了:

代码生成器

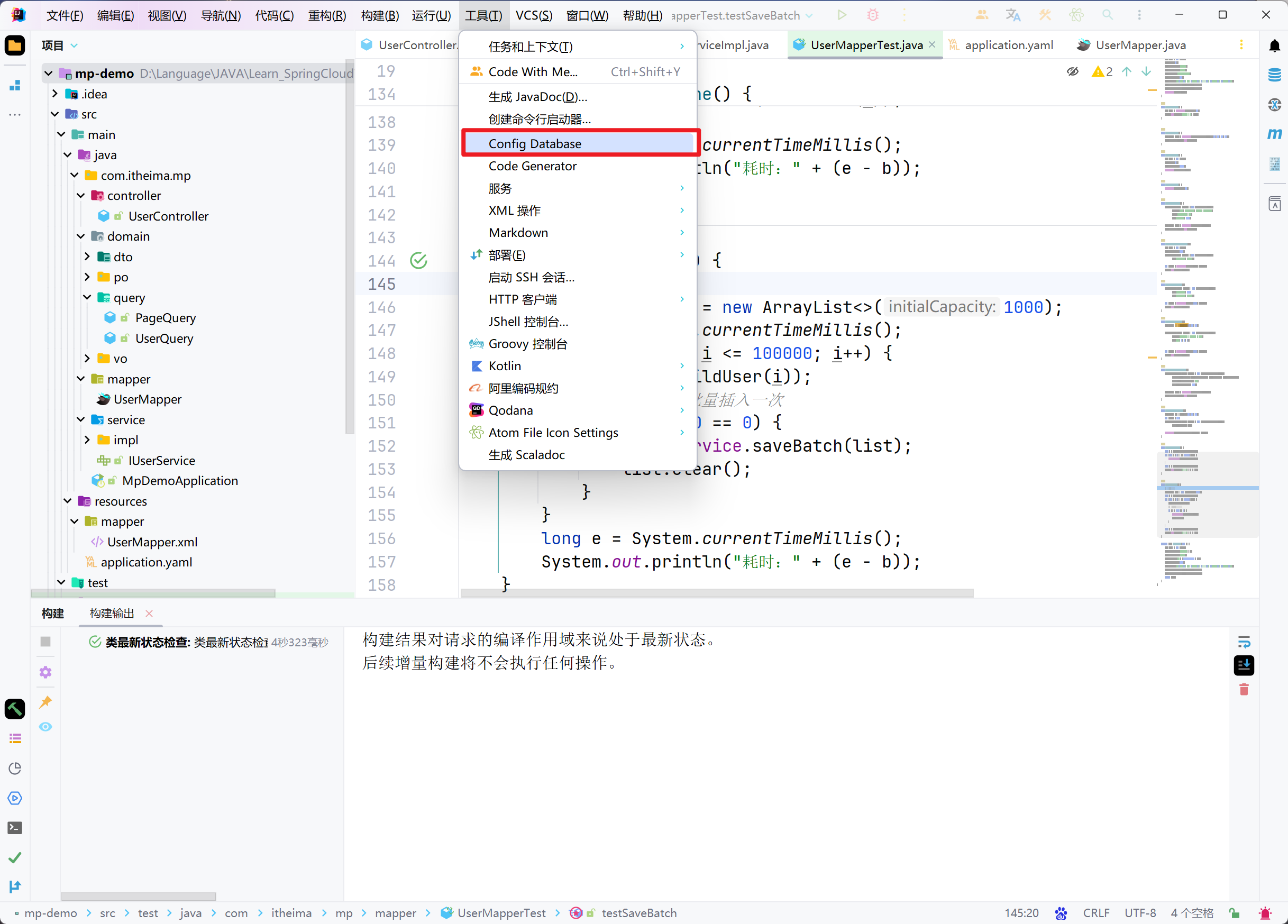
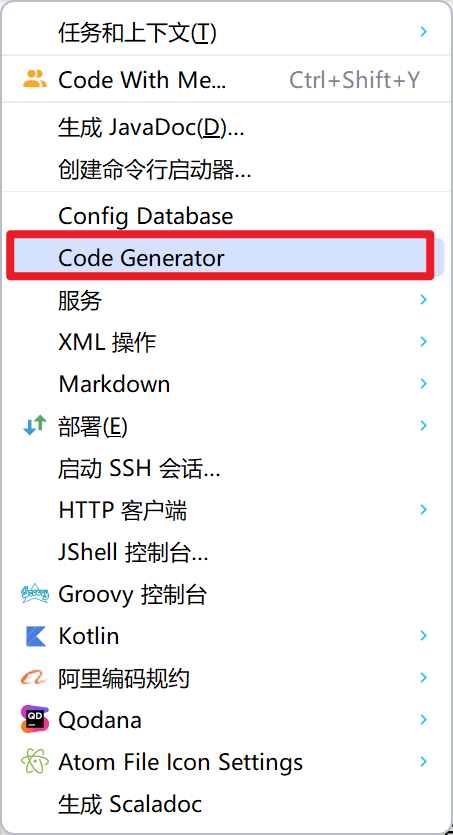
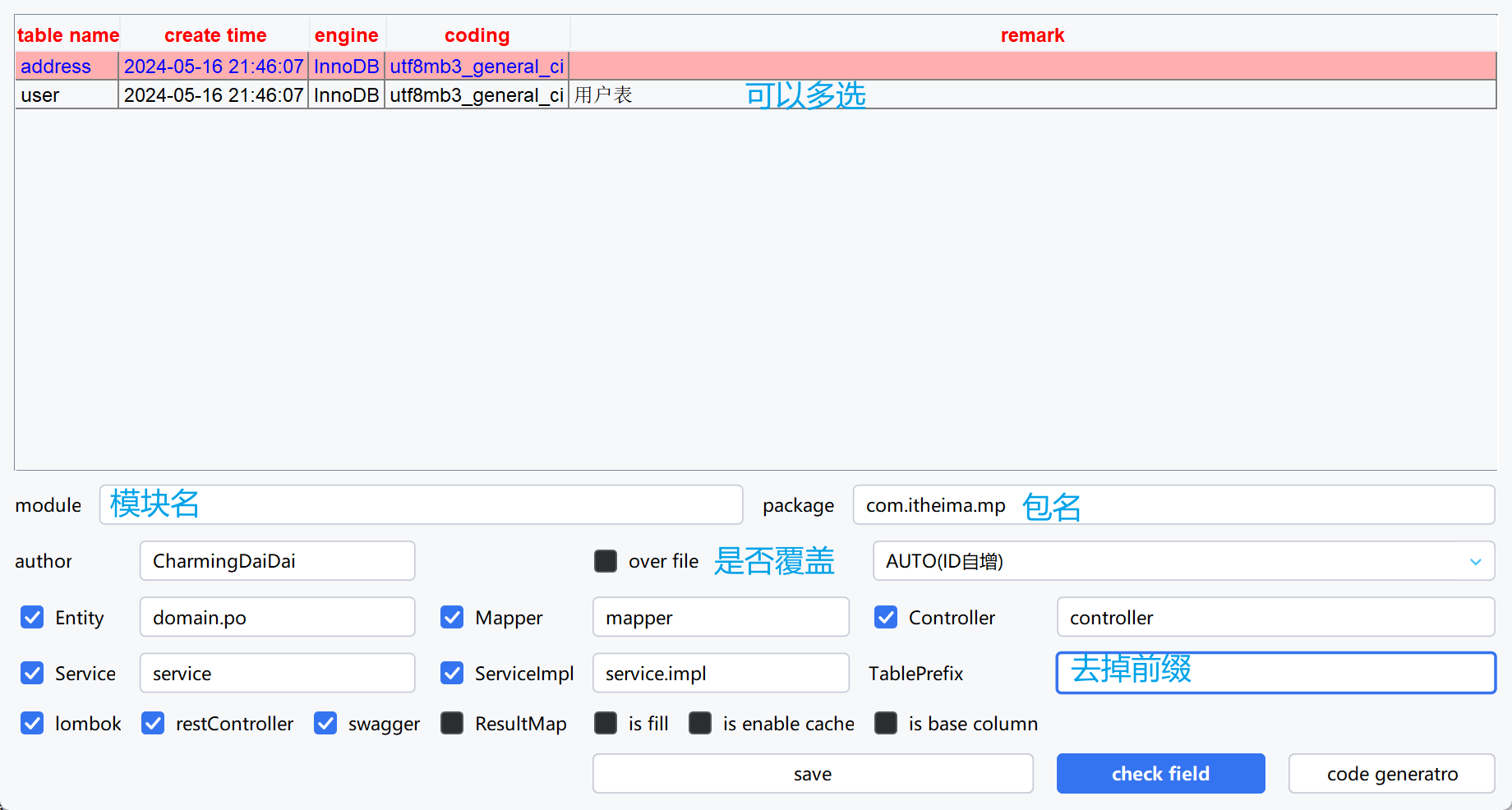
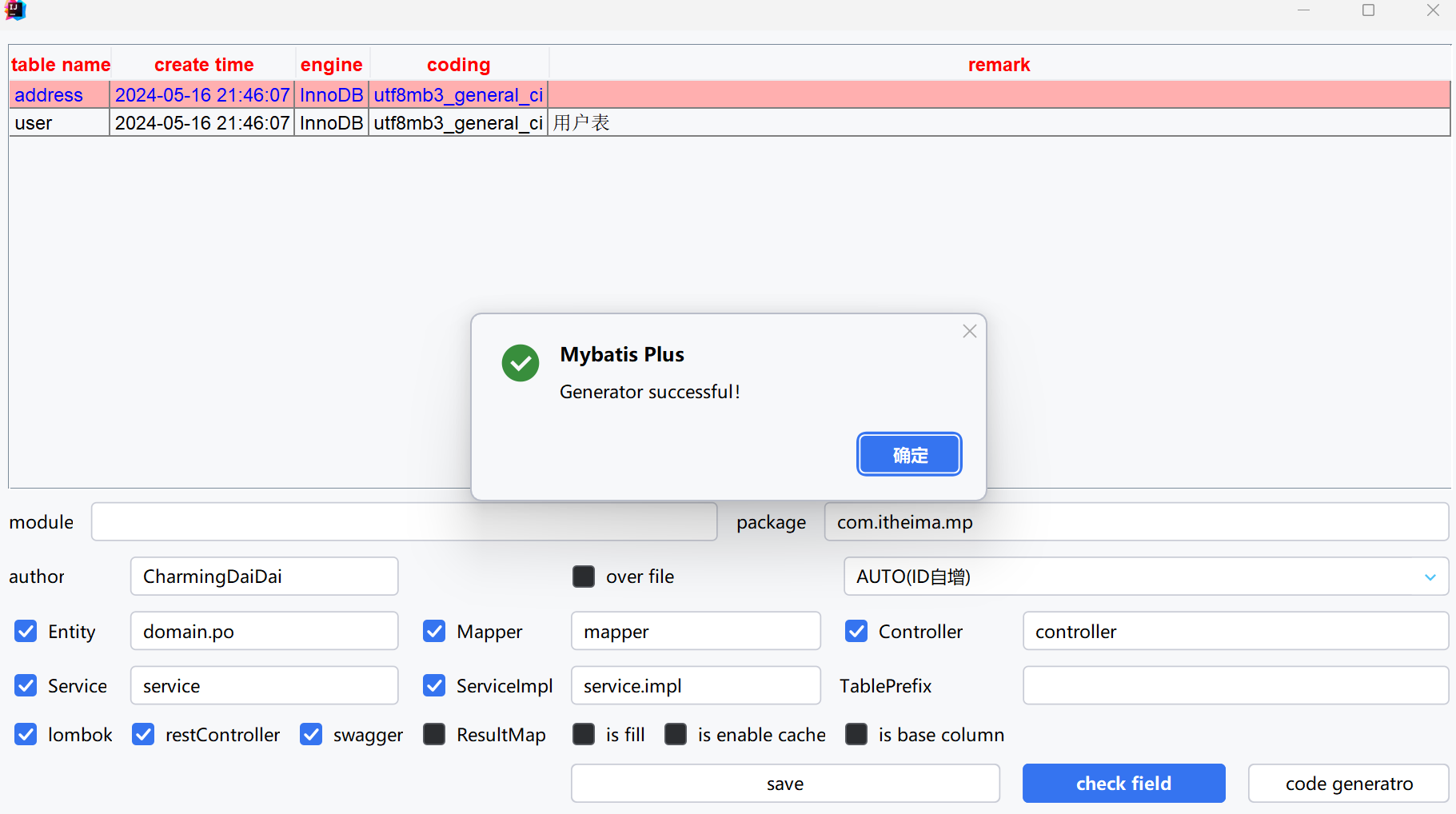
DB静态工具
有的时候Service之间也会相互调用,为了避免出现循环依赖问题,MybatisPlus提供一个静态工具类:Db,其中的一些静态方法与IService中方法签名基本一致,也可以帮助实现CRUD功能
需求:改造根据id用户查询的接口,查询用户的同时返回用户收货地址列表
添加收货地址VO对象
package com.itheima.mp.domain.vo;
import io.swagger.annotations.ApiModel;
import io.swagger.annotations.ApiModelProperty;
import lombok.Data;
@Data
@ApiModel(description = "收货地址VO")
public class AddressVO{
@ApiModelProperty("id")
private Long id;
@ApiModelProperty("用户ID")
private Long userId;
@ApiModelProperty("省")
private String province;
@ApiModelProperty("市")
private String city;
@ApiModelProperty("县/区")
private String town;
@ApiModelProperty("手机")
private String mobile;
@ApiModelProperty("详细地址")
private String street;
@ApiModelProperty("联系人")
private String contact;
@ApiModelProperty("是否是默认 1默认 0否")
private Boolean isDefault;
@ApiModelProperty("备注")
private String notes;
}controller
@ApiOperation(value = "根据id查询用户")
@GetMapping("/{id}")
public UserVO getById(@PathVariable Long id){
return iUserService.queryUserAndAddressById(id);
}实现类
@Override
public UserVO queryUserAndAddressById(Long id) {
User user = getById(id);
if (user == null || user.getStatus() == 2) {
throw new RuntimeException("用户状态异常");
}
List<Address> addressList = Db.lambdaQuery(Address.class).eq(Address::getUserId, id).list();
UserVO userVO = new UserVO();
BeanUtil.copyProperties(user, userVO);
userVO.setAddresses(BeanUtil.copyToList(addressList, AddressVO.class));
return userVO;
}批量改造:
controller
@ApiOperation(value = "根据id查询用户")
@GetMapping("/{id}")
public UserVO getById(@PathVariable Long id){
return iUserService.queryUserAndAddressById(id);
}实现类
@Override
public List<UserVO> queryUserAndAddressByIds(List<Long> ids) {
List<User> users = listByIds(ids);
if (users == null) {
return Collections.emptyList();
}
List<Long> userIds = users.stream().map(User::getId).collect(Collectors.toList());
List<Address> addressList = Db.lambdaQuery(Address.class).in(Address::getUserId, userIds).list();
List<AddressVO> addressVOS = BeanUtil.copyToList(addressList, AddressVO.class);
Map<Long, List<AddressVO>> addressMap = new HashMap<>();
if (addressList != null){
addressMap = addressVOS.stream().collect(Collectors.groupingBy(AddressVO::getUserId));
}
List<UserVO> userVOS = new ArrayList<>();
for (User user : users) {
UserVO userVO = BeanUtil.copyProperties(user, UserVO.class);
userVO.setAddresses(addressMap.get(user.getId()));
userVOS.add(userVO);
}
return userVOS;
}逻辑删除
对于一些比较重要的数据,往往会采用逻辑删除的方案,即:
- 在表中添加一个字段标记数据是否被删除
- 当删除数据时把标记置为true
- 查询时过滤掉标记为true的数据
一旦采用了逻辑删除,所有的查询和删除逻辑都要跟着变化,非常麻烦。
为了解决这个问题,MybatisPlus就添加了对逻辑删除的支持。
注意,只有MybatisPlus生成的SQL语句才支持自动的逻辑删除,自定义SQL需要自己手动处理逻辑删除。
给address表添加一个逻辑删除字段:
alter table address add deleted bit default b'0' null comment '逻辑删除';给Address实体添加一个逻辑删除字段
@Data
@EqualsAndHashCode(callSuper = false)
@Accessors(chain = true)
@TableName("address")
@ApiModel(value="Address对象", description="")
public class Address implements Serializable {
private static final long serialVersionUID = 1L;
@TableId(value = "id", type = IdType.AUTO)
private Long id;
@ApiModelProperty(value = "用户ID")
private Long userId;
@ApiModelProperty(value = "省")
private String province;
@ApiModelProperty(value = "市")
private String city;
@ApiModelProperty(value = "县/区")
private String town;
@ApiModelProperty(value = "手机")
private String mobile;
@ApiModelProperty(value = "详细地址")
private String street;
@ApiModelProperty(value = "联系人")
private String contact;
@ApiModelProperty(value = "是否是默认 1默认 0否")
private Boolean isDefault;
@ApiModelProperty(value = "备注")
private String notes;
@ApiModelProperty(value = "逻辑删除")
private Boolean deleted;
}在application.yml中配置逻辑删除字段
mybatis-plus:
type-aliases-package: com.itheima.mp.domain.po
global-config:
db-config:
id-type: auto # 全局id类型为自增长
logic-delete-field: deleted # 全局逻辑删除的实体字段名(since 3.3.0,配置后可以忽略不配置步骤2)
logic-delete-value: 1 # 逻辑已删除值(默认为 1)
logic-not-delete-value: 0 # 逻辑未删除值(默认为 0)测试
@Test
void testDeleteByLogic() {
// 删除方法与以前没有区别
addressService.removeById(59L);
}@Test
void testQuery() {
List<Address> list = addressService.list();
list.forEach(System.out::println);
}注意: 逻辑删除本身也有自己的问题,比如:
- 会导致数据库表垃圾数据越来越多,从而影响查询效率
- SQL中全都需要对逻辑删除字段做判断,影响查询效率
因此,我不太推荐采用逻辑删除功能,如果数据不能删除,可以采用把数据迁移到其它表的办法。
通用枚举
User类中有一个用户状态字段:
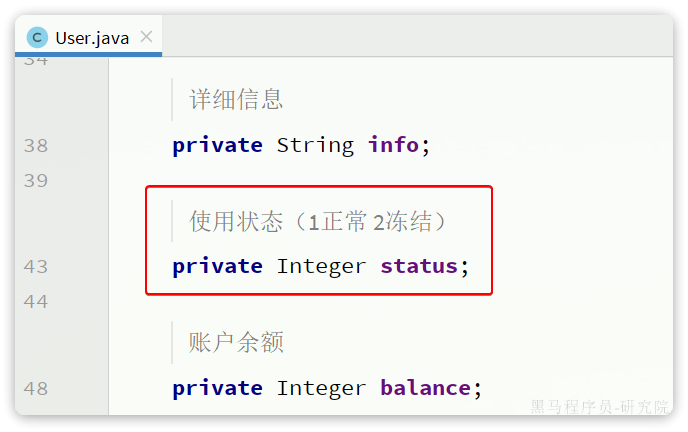
像这种字段一般会定义一个枚举,做业务判断的时候就可以直接基于枚举做比较。但是数据库采用的是int类型,对应的PO也是Integer。因此业务操作时必须手动把枚举与Integer转换,非常麻烦。
因此,MybatisPlus提供了一个处理枚举的类型转换器,可以帮把枚举类型与数据库类型自动转换。
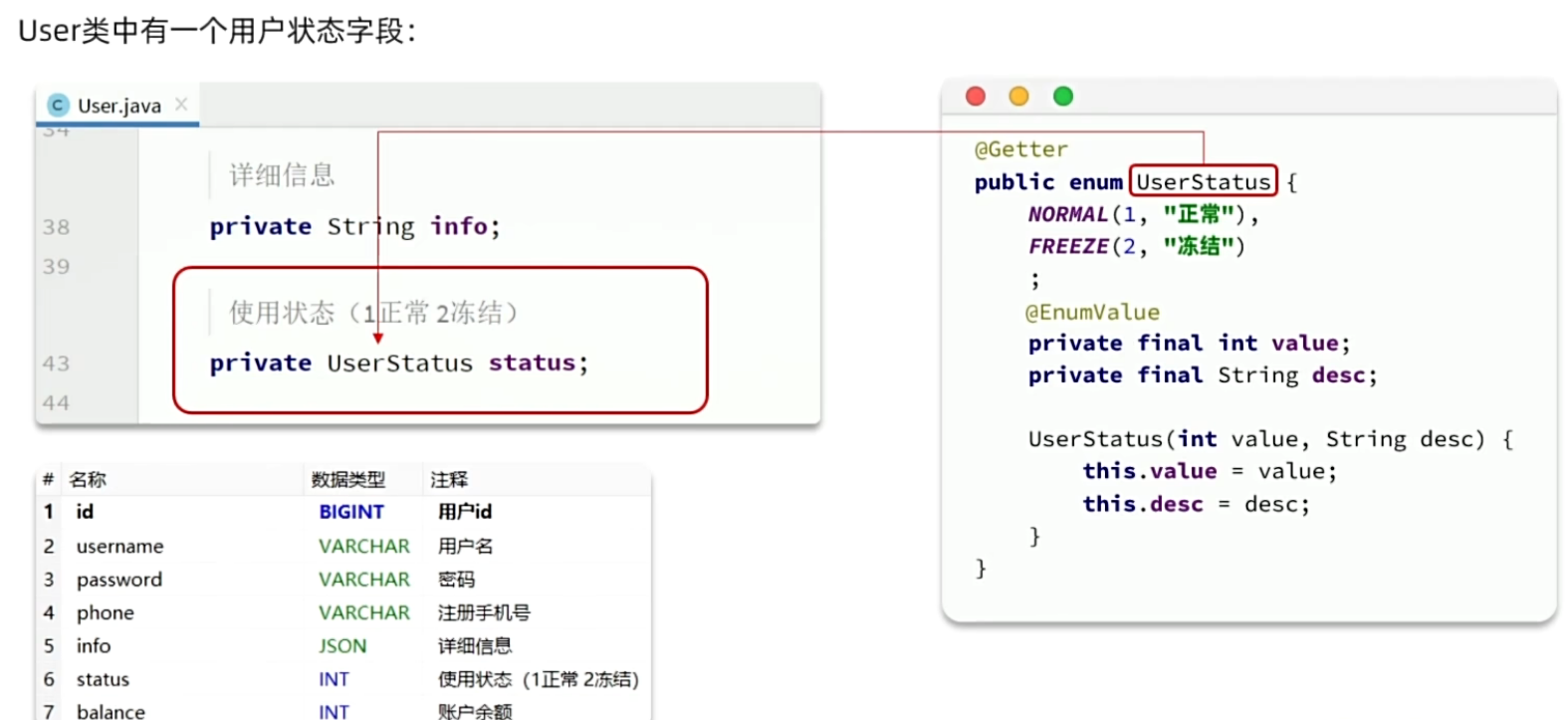
定义枚举
package com.itheima.mp.enums;
import com.baomidou.mybatisplus.annotation.EnumValue;
import com.fasterxml.jackson.annotation.JsonValue;
import lombok.Getter;
/**
* @author:CharmingDaiDai
* @project:mp-demo
* @since:2024/5/17 下午8:52
*/
@Getter
public enum UserStatus {
NORMAL(1, "正常"),
FREEZE(2, "冻结"),
;
private final int value;
private final String desc;
UserStatus(int value, String desc) {
this.value = value;
this.desc = desc;
}
}把User类中的status字段改为UserStatus 类型
/**
* 使用状态(1正常 2冻结)
*/
private UserStatus status;MybatisPlus提供了@EnumValue注解来标记枚举属性
配置枚举处理器
❗️3.5.2开始无需配置
mybatis-plus:
configuration:
default-enum-type-handler: com.baomidou.mybatisplus.core.handlers.MybatisEnumTypeHandler测试
@Test
void testService() {
List<User> list = userService.list();
list.forEach(System.out::println);
}21:03:08 INFO 31976 --- [ main] com.zaxxer.hikari.HikariDataSource : HikariPool-1 - Starting...
21:03:09 INFO 31976 --- [ main] com.zaxxer.hikari.HikariDataSource : HikariPool-1 - Start completed.
21:03:09 DEBUG 31976 --- [ main] c.i.mp.mapper.UserMapper.selectList : ==> Preparing: SELECT id,username,password,phone,info,status,balance,create_time,update_time FROM user
21:03:09 DEBUG 31976 --- [ main] c.i.mp.mapper.UserMapper.selectList : ==> Parameters:
21:03:09 DEBUG 31976 --- [ main] c.i.mp.mapper.UserMapper.selectList : <== Total: 6
User(id=1, username=Jack, password=123, phone=13900112224, info={"age": 20, "intro": "佛系青年", "gender": "male"}, status=NORMAL, balance=1600, createTime=2023-05-19T20:50:21, updateTime=2024-05-17T15:28:46)
User(id=2, username=Rose, password=123, phone=13900112223, info={"age": 19, "intro": "青涩少女", "gender": "female"}, status=NORMAL, balance=200, createTime=2023-05-19T21:00:23, updateTime=2024-05-17T15:28:46)
User(id=3, username=Hope, password=123, phone=13900112222, info={"age": 25, "intro": "上进青年", "gender": "male"}, status=NORMAL, balance=100000, createTime=2023-06-19T22:37:44, updateTime=2023-06-19T22:37:44)
User(id=4, username=Thomas, password=123, phone=17701265258, info={"age": 29, "intro": "伏地魔", "gender": "male"}, status=NORMAL, balance=400, createTime=2023-06-19T23:44:45, updateTime=2024-05-17T15:28:46)
User(id=5, username=Lucy, password=123, phone=18688990011, info={"age": 24, "intro": "英文老师", "gender": "female"}, status=NORMAL, balance=200, createTime=2024-05-17T10:55:38, updateTime=2024-05-17T10:55:38)
User(id=6, username=test, password=123456, phone=11111111111, info={"age": 24, "intro": "英文老师", "gender": "female"}, status=NORMAL, balance=193, createTime=2024-05-17T15:43:49, updateTime=2024-05-17T15:43:49)为了使页面查询结果也是枚举格式,需要修改UserVO中的status属性
@ApiModelProperty("使用状态(1正常 2冻结)")
private UserStatus status;在UserStatus枚举中通过@JsonValue注解标记JSON序列化时展示的字段
package com.itheima.mp.enums;
import com.baomidou.mybatisplus.annotation.EnumValue;
import com.fasterxml.jackson.annotation.JsonValue;
import lombok.Getter;
/**
* @author:CharmingDaiDai
* @project:mp-demo
* @since:2024/5/17 下午8:52
*/
@Getter
public enum UserStatus {
NORMAL(1, "正常"),
FREEZE(2, "冻结");
@EnumValue
private final int value;
@JsonValue
private final String desc;
UserStatus(int value, String desc) {
this.value = value;
this.desc = desc;
}
}Json类处理器
数据库的user表中有一个info字段,是JSON类型:
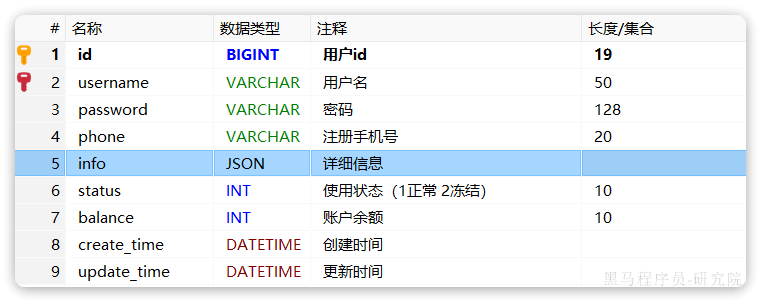
格式像这样:
{"age": 20, "intro": "佛系青年", "gender": "male"}而目前User实体类中却是String类型:
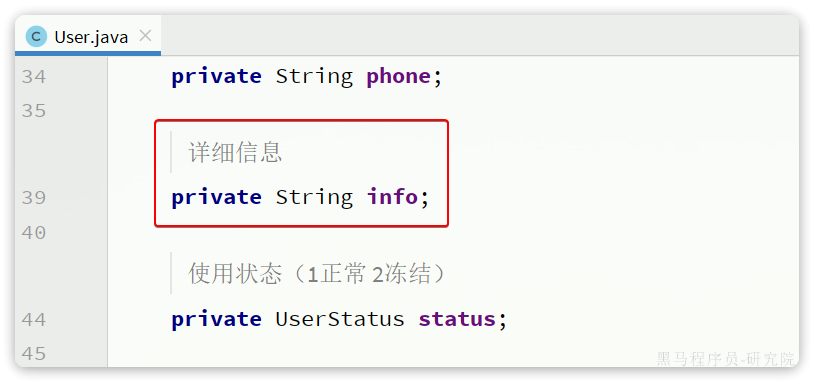
这样一来,要读取info中的属性时就非常不方便。如果要方便获取,info的类型最好是一个Map或者实体类。
而一旦把info改为对象类型,就需要在写入数据库时手动转为String,再读取数据库时,手动转换为对象,这会非常麻烦。
因此MybatisPlus提供了很多特殊类型字段的类型处理器,解决特殊字段类型与数据库类型转换的问题。例如处理JSON就可以使用JacksonTypeHandler处理器。
定义实体
package com.itheima.mp.domain.po;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
@Data
@AllArgsConstructor(staticName = "of")
@NoArgsConstructor
public class UserInfo {
private Integer age;
private String intro;
private String gender;
}使用类型处理器
将User类的info字段修改为UserInfo类型,并声明类型处理器,并开启注解映射:
@Data
🚩开启注解映射
@TableName(autoResultMap = true)
public class User {
/**
* 用户id
*/
@TableId(type = IdType.AUTO)
private Long id;
/**
* 用户名
*/
private String username;
/**
* 密码
*/
private String password;
/**
* 注册手机号
*/
private String phone;
/**
* 详细信息
*/
🚩声明类处理器
@TableField(typeHandler = JacksonTypeHandler.class)
private UserInfo info;
/**
* 使用状态(1正常 2冻结)
*/
private UserStatus status;
/**
* 账户余额
*/
private Integer balance;
/**
* 创建时间
*/
private LocalDateTime createTime;
/**
* 更新时间
*/
private LocalDateTime updateTime;
}修改UserVO中的info字段:
@ApiModelProperty("详细信息")
private UserInfo info;{
"id": 1,
"username": "Jack",
*-------------------------------------------------------------------*
"info": "{\"age\": 20, \"intro\": \"佛系青年\", \"gender\": \"male\"}",
*-------------------------------------------------------------------*
"info": {
"age": 20,
"intro": "佛系青年",
"gender": "male"
},
*-------------------------------------------------------------------*
"status": "正常",
"balance": 1600,
"addresses": [
{
"id": 60,
"userId": 1,
"province": "北京",
"city": "北京",
"town": "朝阳区",
"mobile": "13700221122",
"street": "修正大厦",
"contact": "Jack",
"isDefault": false,
"notes": null
},
{
"id": 61,
"userId": 1,
"province": "上海",
"city": "上海",
"town": "浦东新区",
"mobile": "13301212233",
"street": "航头镇航头路",
"contact": "Jack",
"isDefault": true,
"notes": null
}
]
}分页插件
在3.4.0及之后的版本中,分页插件已经默认集成。无需额外配置
在未引入分页插件的情况下,MybatisPlus是不支持分页功能的,IService和BaseMapper中的分页方法都无法正常起效。 所以必须配置分页插件。
分页插件配置类
package com.itheima.mp.config;
import com.baomidou.mybatisplus.annotation.DbType;
import com.baomidou.mybatisplus.extension.plugins.MybatisPlusInterceptor;
import com.baomidou.mybatisplus.extension.plugins.inner.PaginationInnerInterceptor;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
/**
* @author:CharmingDaiDai
* @project:mp-demo
* @since:2024/5/20 上午9:10
*/
@Configuration
public class MybatisConfig {
@Bean
public MybatisPlusInterceptor mybatisPlusInterceptor() {
// 初始化核心插件
MybatisPlusInterceptor interceptor = new MybatisPlusInterceptor();
// 添加分页插件
interceptor.addInnerInterceptor(new PaginationInnerInterceptor(DbType.MYSQL));
return interceptor;
}
}测试类
@Test
void testPageQuery() {
// 1.分页查询,new Page()的两个参数分别是:页码、每页大小
Page<User> p = userService.page(new Page<>(2, 2));
// 2.总条数
System.out.println("total = " + p.getTotal());
// 3.总页数
System.out.println("pages = " + p.getPages());
// 4.数据
List<User> records = p.getRecords();
records.forEach(System.out::println);
}total = 6
pages = 3
User(id=3, username=Hope, password=123, phone=13900112222, info=UserInfo(age=25, intro=上进青年, gender=male), status=NORMAL, balance=100000, createTime=2023-06-19T22:37:44, updateTime=2023-06-19T22:37:44)
User(id=4, username=Thomas, password=123, phone=17701265258, info=UserInfo(age=29, intro=伏地魔, gender=male), status=NORMAL, balance=400, createTime=2023-06-19T23:44:45, updateTime=2024-05-17T15:28:46)可以添加排序的字段
int pageNo = 1, pageSize = 5;
// 分页参数
Page<User> page = Page.of(pageNo, pageSize);
// 排序参数, 通过OrderItem来指定
page.addOrder(new OrderItem("balance", false));
userService.page(page);分页工具类
package com.itheima.mp.domain.query;
import com.baomidou.mybatisplus.core.metadata.OrderItem;
import com.baomidou.mybatisplus.extension.plugins.pagination.Page;
import lombok.Data;
@Data
public class PageQuery {
private Integer pageNo;
private Integer pageSize;
private String sortBy;
private Boolean isAsc;
public <T> Page<T> toMpPage(OrderItem ... orders){
// 1.分页条件
Page<T> p = Page.of(pageNo, pageSize);
// 2.排序条件
// 2.1.先看前端有没有传排序字段
if (sortBy != null) {
p.addOrder(new OrderItem(sortBy, isAsc));
return p;
}
// 2.2.再看有没有手动指定排序字段
if(orders != null){
p.addOrder(orders);
}
return p;
}
public <T> Page<T> toMpPage(String defaultSortBy, boolean isAsc){
return this.toMpPage(new OrderItem(defaultSortBy, isAsc));
}
public <T> Page<T> toMpPageDefaultSortByCreateTimeDesc() {
return toMpPage("create_time", false);
}
public <T> Page<T> toMpPageDefaultSortByUpdateTimeDesc() {
return toMpPage("update_time", false);
}
}改造PageDTO
package com.itheima.mp.domain.dto;
import cn.hutool.core.bean.BeanUtil;
import com.baomidou.mybatisplus.extension.plugins.pagination.Page;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import java.util.Collections;
import java.util.List;
import java.util.function.Function;
import java.util.stream.Collectors;
@Data
@NoArgsConstructor
@AllArgsConstructor
public class PageDTO<V> {
private Long total;
private Long pages;
private List<V> list;
/**
* 返回空分页结果
* @param p MybatisPlus的分页结果
* @param <V> 目标VO类型
* @param <P> 原始PO类型
* @return VO的分页对象
*/
public static <V, P> PageDTO<V> empty(Page<P> p){
return new PageDTO<>(p.getTotal(), p.getPages(), Collections.emptyList());
}
/**
* 将MybatisPlus分页结果转为 VO分页结果
* @param p MybatisPlus的分页结果
* @param voClass 目标VO类型的字节码
* @param <V> 目标VO类型
* @param <P> 原始PO类型
* @return VO的分页对象
*/
public static <V, P> PageDTO<V> of(Page<P> p, Class<V> voClass) {
// 1.非空校验
List<P> records = p.getRecords();
if (records == null || records.size() <= 0) {
// 无数据,返回空结果
return empty(p);
}
// 2.数据转换
List<V> vos = BeanUtil.copyToList(records, voClass);
// 3.封装返回
return new PageDTO<>(p.getTotal(), p.getPages(), vos);
}
/**
* 将MybatisPlus分页结果转为 VO分页结果,允许用户自定义PO到VO的转换方式
* @param p MybatisPlus的分页结果
* @param convertor PO到VO的转换函数
* @param <V> 目标VO类型
* @param <P> 原始PO类型
* @return VO的分页对象
*/
public static <V, P> PageDTO<V> of(Page<P> p, Function<P, V> convertor) {
// 1.非空校验
List<P> records = p.getRecords();
if (records == null || records.size() <= 0) {
// 无数据,返回空结果
return empty(p);
}
// 2.数据转换
List<V> vos = records.stream().map(convertor).collect(Collectors.toList());
// 3.封装返回
return new PageDTO<>(p.getTotal(), p.getPages(), vos);
}
}controller
@ApiOperation(value = "根据分页查询")
@GetMapping("/page")
public PageDTO<UserVO> getByPage(PageQuery pageQuery){
return iUserService.queryUserByPage(pageQuery);
}实现类
@Override
public PageDTO<UserVO> queryUserByPage(PageQuery query) {
// 1.构建条件
Page<User> page = query.toMpPageDefaultSortByCreateTimeDesc();
// 2.查询
page(page);
// 3.封装返回
return PageDTO.of(page, UserVO.class);
}docker
Docker: Accelerated Container Application Development
Docker Hub Container Image Library | App Containerization
安装-ubuntu
Install Docker Engine on Ubuntu | Docker Docs
卸载旧的
Set up Docker's apt repository.
# Add Docker's official GPG key:
sudo apt-get update
sudo apt-get install ca-certificates curl
sudo install -m 0755 -d /etc/apt/keyrings
sudo curl -fsSL https://download.docker.com/linux/ubuntu/gpg -o /etc/apt/keyrings/docker.asc
sudo chmod a+r /etc/apt/keyrings/docker.asc
# Add the repository to Apt sources:
echo \
"deb [arch=$(dpkg --print-architecture) signed-by=/etc/apt/keyrings/docker.asc] https://download.docker.com/linux/ubuntu \
$(. /etc/os-release && echo "$VERSION_CODENAME") stable" | \
sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
sudo apt-get updateTo install the latest version, run:
sudo apt-get install docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin阿里云镜像加速
针对Docker客户端版本大于 1.10.0 的用户
您可以通过修改daemon配置文件/etc/docker/daemon.json来使用加速器
sudo mkdir -p /etc/docker
sudo tee /etc/docker/daemon.json <<-'EOF'
{
"registry-mirrors": ["加速器地址"]
}
EOF
sudo systemctl daemon-reload
sudo systemctl restart docker# Docker开机自启
systemctl enable docker
# Docker容器开机自启
docker update --restart=always [容器名/容器id]命令
| 命令 | 说明 | 文档地址 |
|---|---|---|
| docker pull | 拉取镜像 | docker pull |
| docker push | 推送镜像到DockerRegistry | docker push |
| docker images | 查看本地镜像 | docker images |
| docker rmi | 删除本地镜像 | docker rmi |
| docker run | 创建并运行容器(不能重复创建) | docker run |
| docker stop | 停止指定容器 | docker stop |
| docker start | 启动指定容器 | docker start |
| docker restart | 重新启动容器 | docker restart |
| docker rm | 删除指定容器 | docs.docker.com |
| docker ps | 查看容器 | docker ps |
| docker logs | 查看容器运行日志 | docker logs |
| docker exec | 进入容器 | docker exec |
| docker save | 保存镜像到本地压缩文件 | docker save |
| docker load | 加载本地压缩文件到镜像 | docker load |
| docker inspect | 查看容器详细信息 | docker inspect |
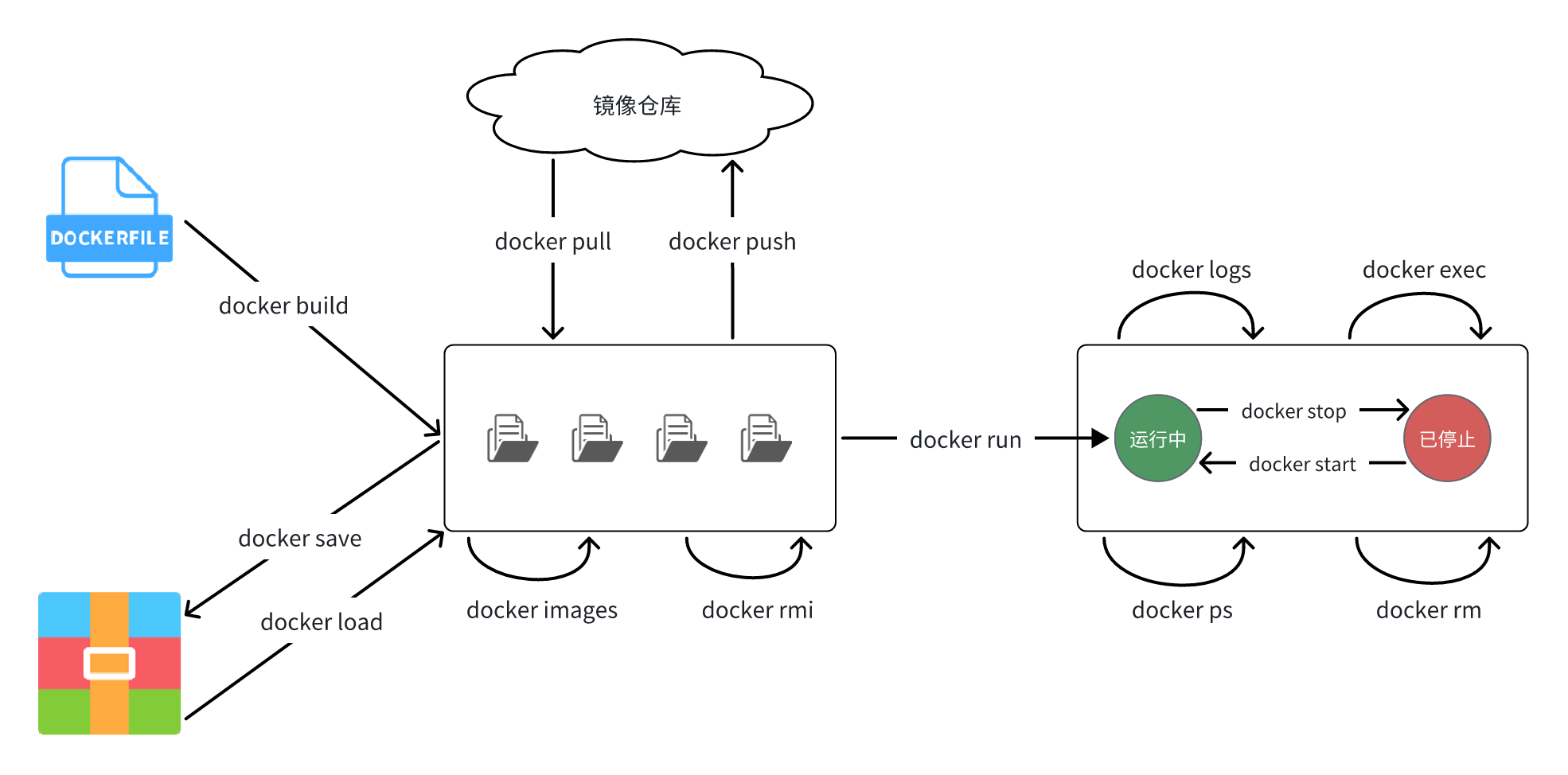
命令别名
# 修改/root/.bashrc文件
vim /root/.bashrc内容如下:
# .bashrc
# User specific aliases and functions
alias rm='rm -i'
alias cp='cp -i'
alias mv='mv -i'
alias dps='docker ps --format "table {{.ID}}\t{{.Image}}\t{{.Ports}}\t{{.Status}}\t{{.Names}}"'
alias dis='docker images'
# Source global definitions
if [ -f /etc/bashrc ]; then
. /etc/bashrc
fisource /root/.bashrc数据卷
数据卷(volume)是一个虚拟目录,是容器内目录与宿主机目录之间映射的桥梁。
以Nginx为例,知道Nginx中有两个关键的目录:
html:放置一些静态资源conf:放置配置文件
如果要让Nginx代理的静态资源,最好是放到html目录;如果要修改Nginx的配置,最好是找到conf下的nginx.conf文件。
但遗憾的是,容器运行的Nginx所有的文件都在容器内部。所以必须利用数据卷将两个目录与宿主机目录关联,方便操作。如图:
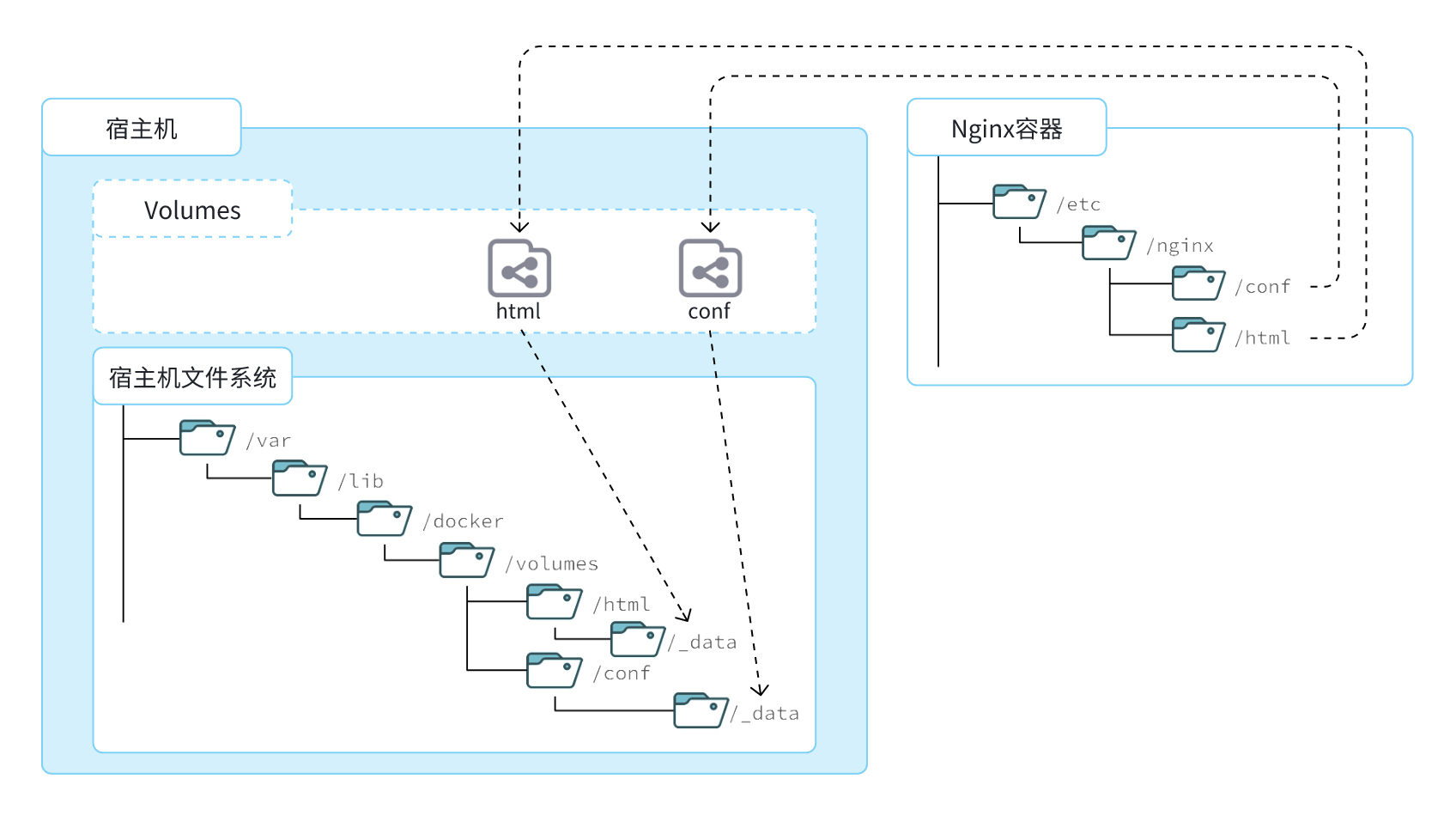
在上图中:
- 创建了两个数据卷:
conf、html - Nginx容器内部的
conf目录和html目录分别与两个数据卷关联。 - 而数据卷conf和html分别指向了宿主机的
/var/lib/docker/volumes/conf/_data目录和/var/lib/docker/volumes/html/_data目录
这样以来,容器内的conf和html目录就 与宿主机的conf和html目录关联起来,称为挂载。此时,操作宿主机的/var/lib/docker/volumes/html/_data就是在操作容器内的/usr/share/nginx/html/_data目录。只要将静态资源放入宿主机对应目录,就可以被Nginx代理了。
小提示:
/var/lib/docker/volumes这个目录就是默认的存放所有容器数据卷的目录,其下再根据数据卷名称创建新目录,格式为/数据卷名/_data。
为什么不让容器目录直接指向宿主机目录呢?
- 因为直接指向宿主机目录就与宿主机强耦合了,如果切换了环境,宿主机目录就可能发生改变了。由于容器一旦创建,目录挂载就无法修改,这样容器就无法正常工作了。
- 但是容器指向数据卷,一个逻辑名称,而数据卷再指向宿主机目录,就不存在强耦合。如果宿主机目录发生改变,只要改变数据卷与宿主机目录之间的映射关系即可。
不过,通过由于数据卷目录比较深,不好寻找,通常也允许让容器直接与宿主机目录挂载而不使用数据卷
| 命令 | 说明 | 文档地址 |
|---|---|---|
| docker volume create | 创建数据卷 | docker volume create |
| docker volume ls | 查看所有数据卷 | docs.docker.com |
| docker volume rm | 删除指定数据卷 | docs.docker.com |
| docker volume inspect | 查看某个数据卷的详情 | docs.docker.com |
| docker volume prune | 清除数据卷 | docker volume prune |
❗️容器与数据卷的挂载要在创建容器时配置,对于创建好的容器,是不能设置数据卷的。而且创建容器的过程中,数据卷会自动创建。
nginx的html目录挂载
# 1.首先创建容器并指定数据卷,注意通过 -v 参数来指定数据卷
docker run -d --name nginx -p 80:80 -v html:/usr/share/nginx/html nginx
# 2.然后查看数据卷
docker volume ls
# 结果
DRIVER VOLUME NAME
local 29524ff09715d3688eae3f99803a2796558dbd00ca584a25a4bbc193ca82459f
local html
# 3.查看数据卷详情
docker volume inspect html
# 结果
[
{
"CreatedAt": "2024-05-17T19:57:08+08:00",
"Driver": "local",
"Labels": null,
"Mountpoint": "/var/lib/docker/volumes/html/_data",
"Name": "html",
"Options": null,
"Scope": "local"
}
]
# 4.查看/var/lib/docker/volumes/html/_data目录
ll /var/lib/docker/volumes/html/_data
# 可以看到与nginx的html目录内容一样,结果如下:
总用量 8
-rw-r--r--. 1 root root 497 12月 28 2021 50x.html
-rw-r--r--. 1 root root 615 12月 28 2021 index.html
# 5.进入该目录,并随意修改index.html内容
cd /var/lib/docker/volumes/html/_data
vi index.html
# 6.打开页面,查看效果
# 7.进入容器内部,查看/usr/share/nginx/html目录内的文件是否变化
docker exec -it nginx bash演示一下MySQL的匿名数据卷
# 1.查看MySQL容器详细信息
docker inspect mysql
# 关注其中.Config.Volumes部分和.Mounts部分{
"Config": {
// ... 略
"Volumes": {
"/var/lib/mysql": {}
}
// ... 略
}
}可以发现这个容器声明了一个本地目录,需要挂载数据卷,但是数据卷未定义。这就是匿名卷。
{
"Mounts": [
{
"Type": "volume",
"Name": "29524ff09715d3688eae3f99803a2796558dbd00ca584a25a4bbc193ca82459f",
"Source": "/var/lib/docker/volumes/29524ff09715d3688eae3f99803a2796558dbd00ca584a25a4bbc193ca82459f/_data",
"Destination": "/var/lib/mysql",
"Driver": "local",
}
]
}可以发现,其中有几个关键属性:
- Name:数据卷名称。由于定义容器未设置容器名,这里的就是匿名卷自动生成的名字,一串hash值。
- Source:宿主机目录
- Destination : 容器内的目录
上述配置是将容器内的/var/lib/mysql这个目录,与数据卷29524ff09715d3688eae3f99803a2796558dbd00ca584a25a4bbc193ca82459f挂载。于是在宿主机中就有了/var/lib/docker/volumes/29524ff09715d3688eae3f99803a2796558dbd00ca584a25a4bbc193ca82459f/_data这个目录。这就是匿名数据卷对应的目录,其使用方式与普通数据卷没有差别。
接下来,可以查看该目录下的MySQL的data文件:
ls -l /var/lib/docker/volumes/29524ff09715d3688eae3f99803a2796558dbd00ca584a25a4bbc193ca82459f/_data注意:每一个不同的镜像,将来创建容器后内部有哪些目录可以挂载,可以参考DockerHub对应的页面
挂载本地目录或文件
# 挂载本地目录
-v 本地目录:容器内目录
# 挂载本地文件
-v 本地文件:容器内文件❗️注意:本地目录或文件必须以 / 或 ./开头,如果直接以名字开头,会被识别为数据卷名而非本地目录名。
-v mysql:/var/lib/mysql # 会被识别为一个数据卷叫mysql,运行时会自动创建这个数据卷
-v ./mysql:/var/lib/mysql # 会被识别为当前目录下的mysql目录,运行时如果不存在会创建目录演示
- 挂载
/root/mysql/data到容器内的/var/lib/mysql目录 - 挂载
/root/mysql/init到容器内的/docker-entrypoint-initdb.d目录(初始化的SQL脚本目录) - 挂载
/root/mysql/conf到容器内的/etc/mysql/conf.d目录(这个是MySQL配置文件目录)
# 1.删除原来的MySQL容器
docker rm -f mysql
# 2.进入root目录
cd ~
# 3.创建并运行新mysql容器,挂载本地目录
docker run -d \
--name mysql \
-p 3306:3306 \
-e TZ=Asia/Shanghai \
-e MYSQL_ROOT_PASSWORD=123 \
-v ./mysql/data:/var/lib/mysql \
-v ./mysql/conf:/etc/mysql/conf.d \
-v ./mysql/init:/docker-entrypoint-initdb.d \
mysql
# 4.查看root目录,可以发现~/mysql/data目录已经自动创建好了
ls -l mysql
# 结果:
总用量 4
drwxr-xr-x. 2 root root 20 5月 19 15:11 conf
drwxr-xr-x. 7 polkitd root 4096 5月 19 15:11 data
drwxr-xr-x. 2 root root 23 5月 19 15:11 init
# 查看data目录,会发现里面有大量数据库数据,说明数据库完成了初始化
ls -l data
# 5.查看MySQL容器内数据
# 5.1.进入MySQL
docker exec -it mysql mysql -uroot -p123
# 5.2.查看编码表
show variables like "%char%";
# 5.3.结果,发现编码是utf8mb4没有问题
+--------------------------+--------------------------------+
| Variable_name | Value |
+--------------------------+--------------------------------+
| character_set_client | utf8mb4 |
| character_set_connection | utf8mb4 |
| character_set_database | utf8mb4 |
| character_set_filesystem | binary |
| character_set_results | utf8mb4 |
| character_set_server | utf8mb4 |
| character_set_system | utf8mb3 |
| character_sets_dir | /usr/share/mysql-8.0/charsets/ |
+--------------------------+--------------------------------+
# 6.查看数据
# 6.1.查看数据库
show databases;
# 结果,hmall是黑马商城数据库
+--------------------+
| Database |
+--------------------+
| hmall |
| information_schema |
| mysql |
| performance_schema |
| sys |
+--------------------+
5 rows in set (0.00 sec)
# 6.2.切换到hmall数据库
use hmall;
# 6.3.查看表
show tables;
# 结果:
+-----------------+
| Tables_in_hmall |
+-----------------+
| address |
| cart |
| item |
| order |
| order_detail |
| order_logistics |
| pay_order |
| user |
+-----------------+
# 6.4.查看address表数据
+----+---------+----------+--------+----------+-------------+---------------+-----------+------------+-------+
| id | user_id | province | city | town | mobile | street | contact | is_default | notes |
+----+---------+----------+--------+----------+-------------+---------------+-----------+------------+-------+
| 59 | 1 | 北京 | 北京 | 朝阳区 | 13900112222 | 金燕龙办公楼 | 李佳诚 | 0 | NULL |
| 60 | 1 | 北京 | 北京 | 朝阳区 | 13700221122 | 修正大厦 | 李佳红 | 0 | NULL |
| 61 | 1 | 上海 | 上海 | 浦东新区 | 13301212233 | 航头镇航头路 | 李佳星 | 1 | NULL |
| 63 | 1 | 广东 | 佛山 | 永春 | 13301212233 | 永春武馆 | 李晓龙 | 0 | NULL |
+----+---------+----------+--------+----------+-------------+---------------+-----------+------------+-------+
4 rows in set (0.00 sec)docker run -d
--name mysql
-p 3309:3306
-e TZ=Asia/Shanghai
-e MYSQL_ROOT_PASSWORD=1
-v ./mysql/data:/var/lib/mysql
-v ./mysql/conf:/etc/mysql/conf.d
mysql
镜像
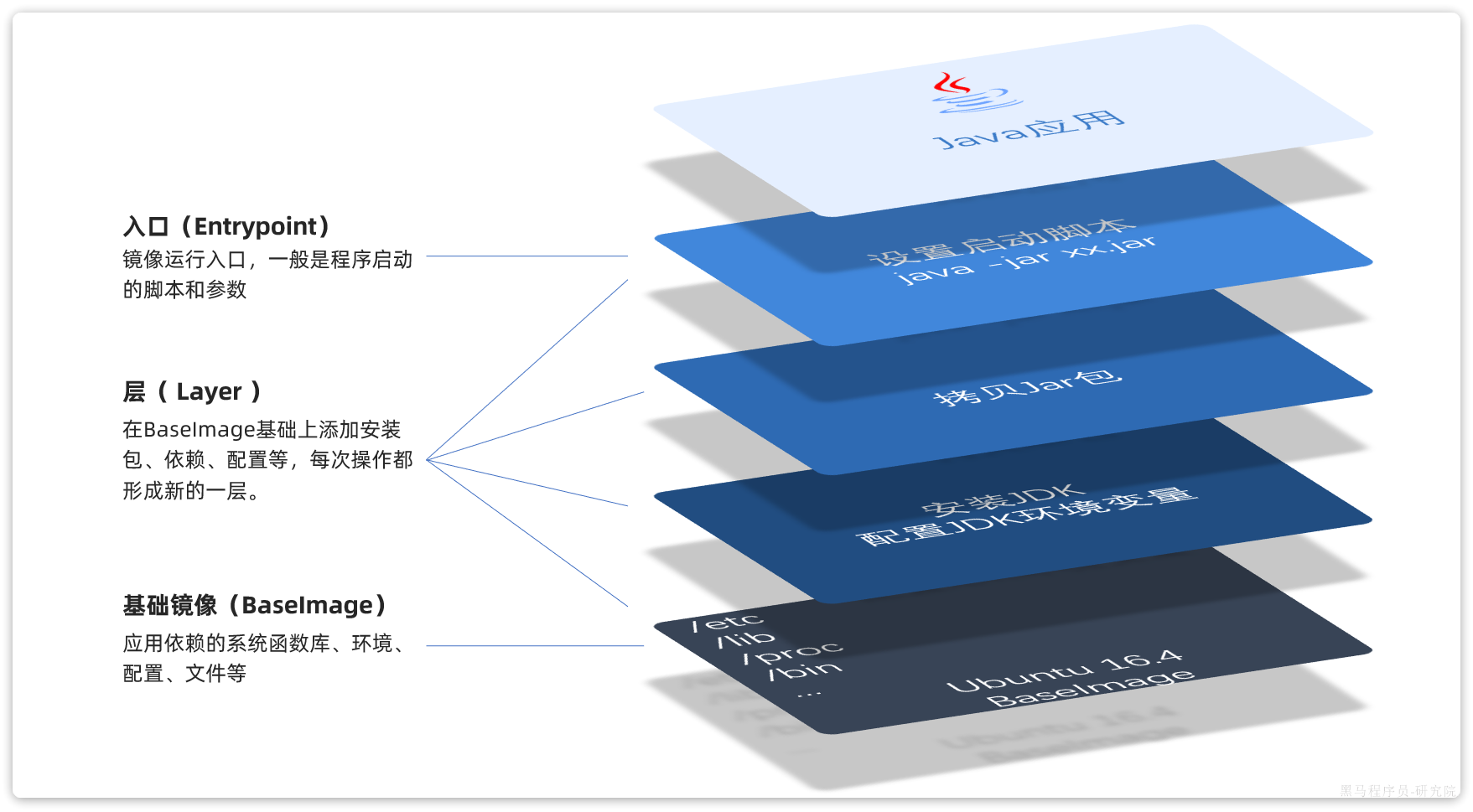
举个例子,要从0部署一个Java应用,大概流程是这样:
- 准备一个linux服务(CentOS或者Ubuntu均可)
- 安装并配置JDK
- 上传Jar包
- 运行jar包
那因此,打包镜像也是分成这么几步:
- 准备Linux运行环境(java项目并不需要完整的操作系统,仅仅是基础运行环境即可)
- 安装并配置JDK
- 拷贝jar包
- 配置启动脚本
上述步骤中的每一次操作其实都是在生产一些文件(系统运行环境、函数库、配置最终都是磁盘文件),所以镜像就是一堆文件的集合。
但需要注意的是,镜像文件不是随意堆放的,而是按照操作的步骤分层叠加而成,每一层形成的文件都会单独打包并标记一个唯一id,称为Layer(层)。这样,如果构建时用到的某些层其他人已经制作过,就可以直接拷贝使用这些层,而不用重复制作。
例如,第一步中需要的Linux运行环境,通用性就很强,所以Docker官方就制作了这样的只包含Linux运行环境的镜像。在制作java镜像时,就无需重复制作,直接使用Docker官方提供的CentOS或Ubuntu镜像作为基础镜像。然后再搭建其它层即可,这样逐层搭建,最终整个Java项目的镜像结构如图所示:
Dockerfile
由于制作镜像的过程中,需要逐层处理和打包,比较复杂,所以Docker就提供了自动打包镜像的功能。只需要将打包的过程,每一层要做的事情用固定的语法写下来,交给Docker去执行即可。
而这种记录镜像结构的文件就称为Dockerfile
Dockerfile reference | Docker Docs
| 指令 | 说明 | 示例 |
|---|---|---|
| FROM | 指定基础镜像 | FROM centos:6 |
| ENV | 设置环境变量,可在后面指令使用 | ENV key value |
| COPY | 拷贝本地文件到镜像的指定目录 | COPY ./xx.jar /tmp/app.jar |
| RUN | 执行Linux的shell命令,一般是安装过程的命令 | RUN yum install gcc |
| EXPOSE | 指定容器运行时监听的端口,是给镜像使用者看的 | EXPOSE 8080 |
| ENTRYPOINT | 镜像中应用的启动命令,容器运行时调用 | ENTRYPOINT java -jar xx.jar |
例如,要基于Ubuntu镜像来构建一个Java应用,其Dockerfile内容如下:
# 指定基础镜像
FROM ubuntu:16.04
# 配置环境变量,JDK的安装目录、容器内时区
ENV JAVA_DIR=/usr/local
ENV TZ=Asia/Shanghai
# 拷贝jdk和java项目的包
COPY ./jdk8.tar.gz $JAVA_DIR/
COPY ./docker-demo.jar /tmp/app.jar
# 设定时区
RUN ln -snf /usr/share/zoneinfo/$TZ /etc/localtime && echo $TZ > /etc/timezone
# 安装JDK
RUN cd $JAVA_DIR \
&& tar -xf ./jdk8.tar.gz \
&& mv ./jdk1.8.0_144 ./java8
# 配置环境变量
ENV JAVA_HOME=$JAVA_DIR/java8
ENV PATH=$PATH:$JAVA_HOME/bin
# 指定项目监听的端口
EXPOSE 8080
# 入口,java项目的启动命令
ENTRYPOINT ["java", "-jar", "/app.jar"]# 基础镜像
FROM openjdk:11.0-jre-buster
# 设定时区
ENV TZ=Asia/Shanghai
RUN ln -snf /usr/share/zoneinfo/$TZ /etc/localtime && echo $TZ > /etc/timezone
# 拷贝jar包
COPY docker-demo.jar /app.jar
# 入口
ENTRYPOINT ["java", "-jar", "/app.jar"]构建镜像
# 进入镜像目录
cd /root/demo
# 开始构建
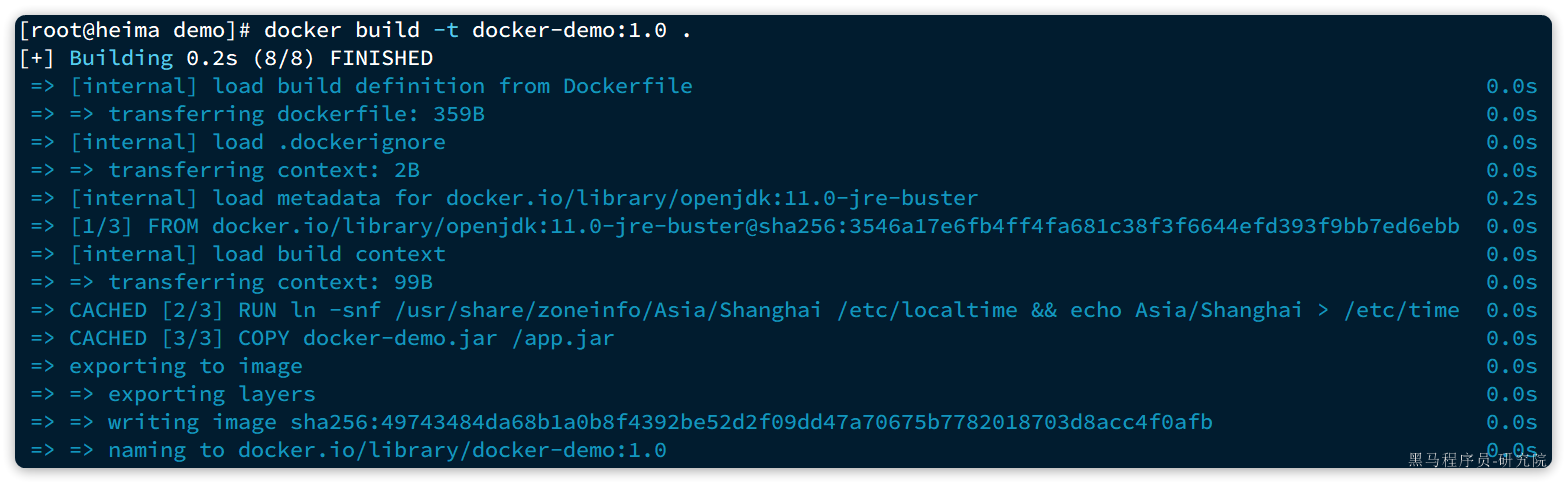
docker build -t docker-demo:1.0 .命令说明:
docker build: 就是构建一个docker镜像-t docker-demo:1.0:-t参数是指定镜像的名称(repository和tag).: 最后的点是指构建时Dockerfile所在路径,由于进入了demo目录,所以指定的是.代表当前目录,也可以直接指定Dockerfile目录:# 直接指定Dockerfile目录 docker build -t docker-demo:1.0 /root/demo
结果:
查看镜像列表:
# 查看镜像列表:
docker images
# 结果
REPOSITORY TAG IMAGE ID CREATED SIZE
docker-demo 1.0 d6ab0b9e64b9 27 minutes ago 327MB
nginx latest 605c77e624dd 16 months ago 141MB
mysql latest 3218b38490ce 17 months ago 516MB网络
容器的网络IP其实是一个虚拟的IP,其值并不固定与某一个容器绑定,如果在开发时写死某个IP,而在部署时很可能MySQL容器的IP会发生变化,连接会失败。
| 命令 | 说明 | 文档地址 |
|---|---|---|
| docker network create | 创建一个网络 | docker network create |
| docker network ls | 查看所有网络 | docs.docker.com |
| docker network rm | 删除指定网络 | docs.docker.com |
| docker network prune | 清除未使用的网络 | docs.docker.com |
| docker network connect | 使指定容器连接加入某网络 | docs.docker.com |
| docker network disconnect | 使指定容器连接离开某网络 | docker network disconnect |
| docker network inspect | 查看网络详细信息 | docker network inspect |
自定义网络
# 1.首先通过命令创建一个网络
docker network create hmall
# 2.然后查看网络
docker network ls
# 结果:
NETWORK ID NAME DRIVER SCOPE
639bc44d0a87 bridge bridge local
403f16ec62a2 hmall bridge local
0dc0f72a0fbb host host local
cd8d3e8df47b none null local
# 其中,除了hmall以外,其它都是默认的网络
# 3.让dd和mysql都加入该网络,注意,在加入网络时可以通过--alias给容器起别名
# 这样该网络内的其它容器可以用别名互相访问!
# 3.1.mysql容器,指定别名为db,另外每一个容器都有一个别名是容器名
docker network connect hmall mysql --alias db
# 3.2.db容器,也就是的java项目
docker network connect hmall dd
# 4.进入dd容器,尝试利用别名访问db
# 4.1.进入容器
docker exec -it dd bash
# 4.2.用db别名访问
ping db
# 结果
PING db (172.18.0.2) 56(84) bytes of data.
64 bytes from mysql.hmall (172.18.0.2): icmp_seq=1 ttl=64 time=0.070 ms
64 bytes from mysql.hmall (172.18.0.2): icmp_seq=2 ttl=64 time=0.056 ms
# 4.3.用容器名访问
ping mysql
# 结果:
PING mysql (172.18.0.2) 56(84) bytes of data.
64 bytes from mysql.hmall (172.18.0.2): icmp_seq=1 ttl=64 time=0.044 ms
64 bytes from mysql.hmall (172.18.0.2): icmp_seq=2 ttl=64 time=0.054 ms总结:
- 在自定义网络中,可以给容器起多个别名,默认的别名是容器名本身
- 在同一个自定义网络中的容器,可以通过别名互相访问
项目部署
项目说明:
- hmall:商城的后端代码
- hmall-portal:商城用户端的前端代码
- hmall-admin:商城管理端的前端代码
部署的容器及端口说明:
| 项目 | 容器名 | 端口 | 备注 |
|---|---|---|---|
| hmall | hmall | 8080 | 黑马商城后端API入口 |
| hmall-portal | nginx | 18080 | 黑马商城用户端入口 |
| hmall-admin | 18081 | 黑马商城管理端入口 | |
| mysql | mysql | 3306 | 数据库 |
hmall项目是一个maven聚合项目,使用IDEA打开hmall项目,查看项目结构如图:

要部署的就是其中的hm-service,其中的配置文件采用了多环境的方式:
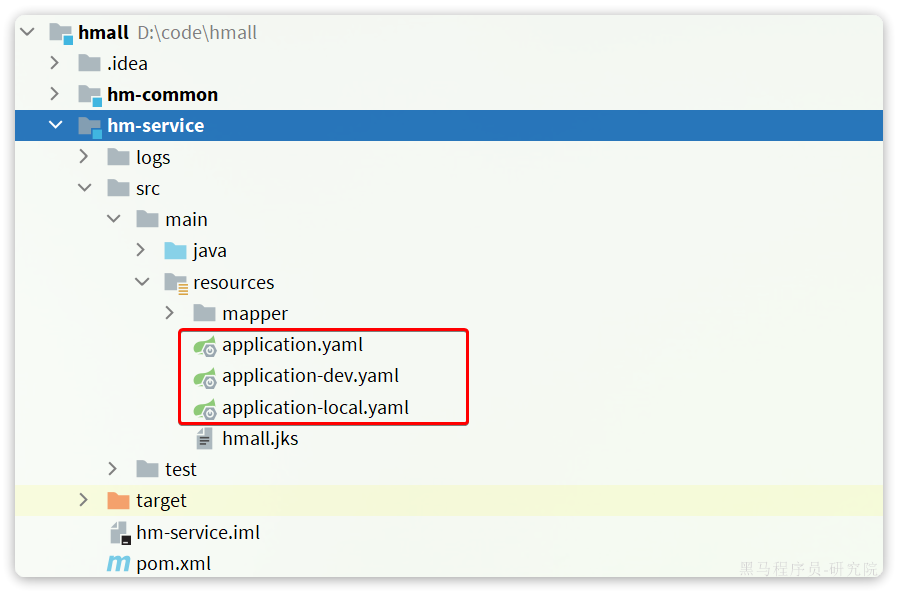
其中的application-dev.yaml是部署到开发环境的配置,application-local.yaml是本地运行时的配置。
查看application.yaml,你会发现其中的JDBC地址并未写死,而是读取变量:
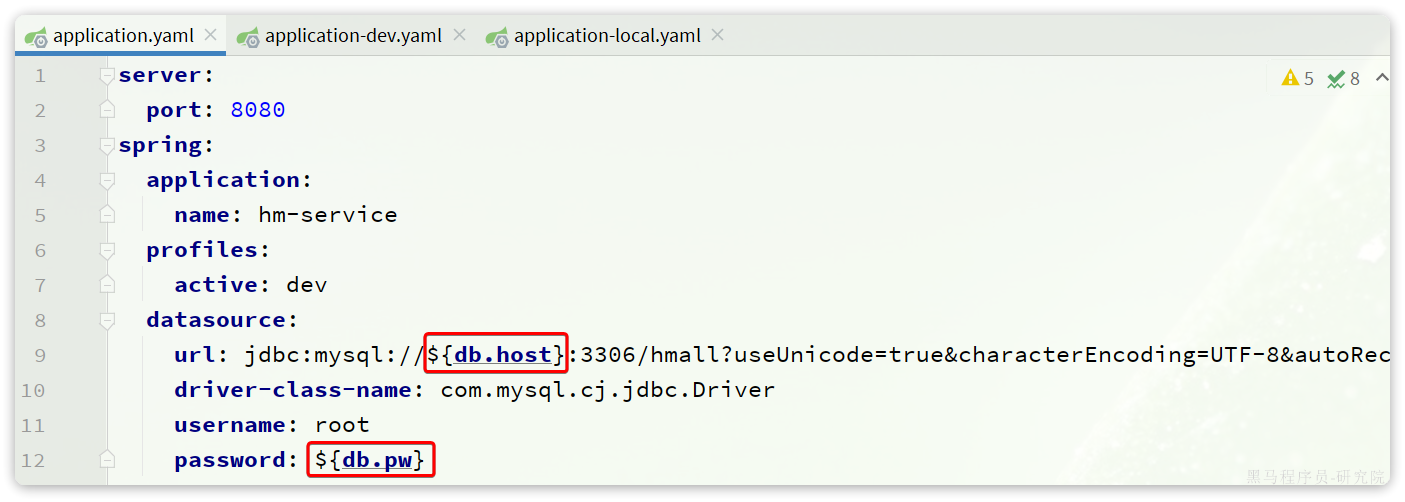
这两个变量在application-dev.yaml和application-local.yaml中并不相同:
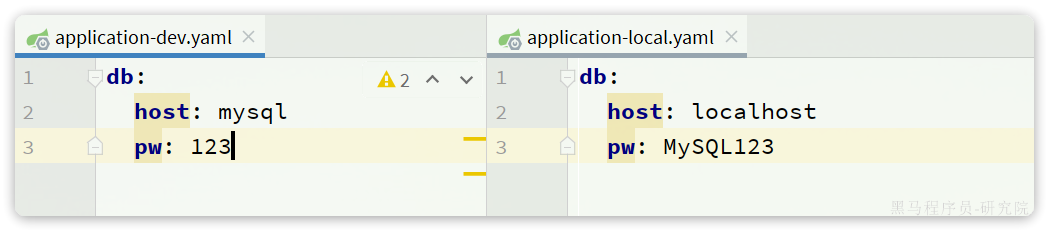
在dev开发环境(也就是Docker部署时)采用了mysql作为地址,刚好是的mysql容器名,只要两者在一个网络,就一定能互相访问。
将项目打包:
结果:
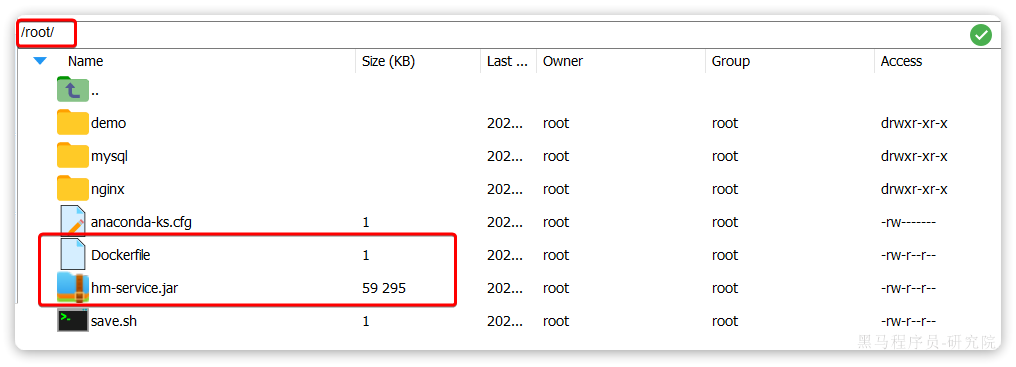
将hm-service目录下的Dockerfile和hm-service/target目录下的hm-service.jar一起上传到虚拟机的root目录:
部署项目:
# 1.构建项目镜像,不指定tag,则默认为latest
docker build -t hmall .
# 2.查看镜像
docker images
# 结果
REPOSITORY TAG IMAGE ID CREATED SIZE
hmall latest 0bb07b2c34b9 43 seconds ago 362MB
docker-demo 1.0 49743484da68 24 hours ago 327MB
nginx latest 605c77e624dd 16 months ago 141MB
mysql latest 3218b38490ce 17 months ago 516MB
# 3.创建并运行容器,并通过--network将其加入hmall网络,这样才能通过容器名访问mysql
docker run -d --name hmall --network hmall -p 8080:8080 hmall测试,通过浏览器访问:http://你的虚拟机地址:8080/search/list
hmall-portal和hmall-admin是前端代码,需要基于nginx部署。在课前资料中已经给大家提供了nginx的部署目录:
其中:
html是静态资源目录,需要把hmall-portal以及hmall-admin都复制进去nginx.conf是nginx的配置文件,主要是完成对html下的两个静态资源目录做代理
现在要做的就是把整个nginx目录上传到虚拟机的/root目录下:
然后创建nginx容器并完成两个挂载:
- 把
/root/nginx/nginx.conf挂载到/etc/nginx/nginx.conf - 把
/root/nginx/html挂载到/usr/share/nginx/html
由于需要让nginx同时代理hmall-portal和hmall-admin两套前端资源,因此需要暴露两个端口:
- 18080:对应hmall-portal
- 18081:对应hmall-admin
命令如下:
docker run -d \
--name nginx \
-p 18080:18080 \
-p 18081:18081 \
-v /root/nginx/html:/usr/share/nginx/html \
-v /root/nginx/nginx.conf:/etc/nginx/nginx.conf \
--network hmall \
nginx测试,通过浏览器访问:http://你的虚拟机ip:18080
DockerCompose
docker-compose文件中可以定义多个相互关联的应用容器,每一个应用容器被称为一个服务(service)。由于service就是在定义某个应用的运行时参数,因此与docker run参数非常相似。
docker run -d \
--name mysql \
-p 3309:3306 \
-e TZ=Asia/Shanghai \
-e MYSQL_ROOT_PASSWORD=1 \
-v ./mysql/data:/var/lib/mysql \
-v ./mysql/conf:/etc/mysql/conf.d \
-v ./mysql/init:/docker-entrypoint-initdb.d \
--network hm-net \
mysqlversion: "3.8"
services:
mysql:
image: mysql
container_name: mysql
ports:
- "3306:3306"
environment:
TZ: Asia/Shanghai
MYSQL_ROOT_PASSWORD: 123
volumes:
- "./mysql/conf:/etc/mysql/conf.d"
- "./mysql/data:/var/lib/mysql"
networks:
- new
networks:
new:
name: hmall| docker run 参数 | docker compose 指令 | 说明 |
|---|---|---|
| --name | container_name | 容器名称 |
| -p | ports | 端口映射 |
| -e | environment | 环境变量 |
| -v | volumes | 数据卷配置 |
| --network | networks | 网络 |
version: "3.8"
services:
mysql:
image: mysql
container_name: mysql
ports:
- "3306:3306"
environment:
TZ: Asia/Shanghai
MYSQL_ROOT_PASSWORD: 123
volumes:
- "./mysql/conf:/etc/mysql/conf.d"
- "./mysql/data:/var/lib/mysql"
- "./mysql/init:/docker-entrypoint-initdb.d"
networks:
- hm-net
hmall:
build:
context: .
dockerfile: Dockerfile
container_name: hmall
ports:
- "8080:8080"
networks:
- hm-net
depends_on:
- mysql
nginx:
image: nginx
container_name: nginx
ports:
- "18080:18080"
- "18081:18081"
volumes:
- "./nginx/nginx.conf:/etc/nginx/nginx.conf"
- "./nginx/html:/usr/share/nginx/html"
depends_on:
- hmall
networks:
- hm-net
networks:
hm-net:
name: hmallOverview of docker compose CLI | Docker Docs
docker compose [OPTIONS] [COMMAND]| 类型 | 参数或指令 | 说明 |
|---|---|---|
| Options | -f | 指定compose文件的路径和名称 |
| -p | 指定project名称。project就是当前compose文件中设置的多个service的集合,是逻辑概念 | |
| Commands | up | 创建并启动所有service容器 |
| down | 停止并移除所有容器、网络 | |
| ps | 列出所有启动的容器 | |
| logs | 查看指定容器的日志 | |
| stop | 停止容器 | |
| start | 启动容器 | |
| restart | 重启容器 | |
| top | 查看运行的进程 | |
| exec | 在指定的运行中容器中执行命令 |
认识微服务
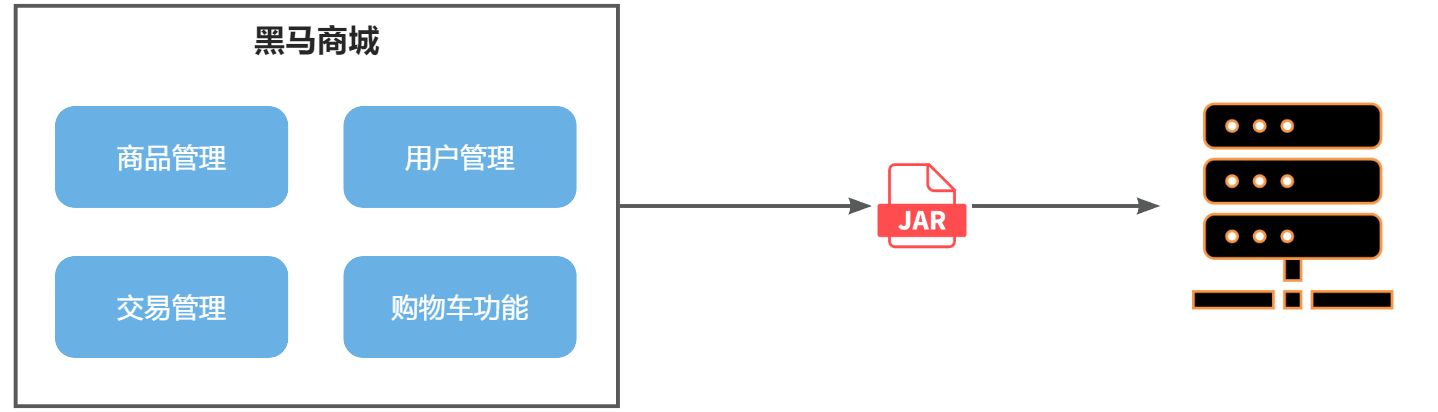
单体架构
单体架构(monolithic structure):顾名思义,整个项目中所有功能模块都在一个工程中开发;项目部署时需要对所有模块一起编译、打包;项目的架构设计、开发模式都非常简单。
当项目规模较小时,这种模式上手快,部署、运维也都很方便,因此早期很多小型项目都采用这种模式。
但随着项目的业务规模越来越大,团队开发人员也不断增加,单体架构就呈现出越来越多的问题:
- 团队协作成本高:试想一下,你们团队数十个人同时协作开发同一个项目,由于所有模块都在一个项目中,不同模块的代码之间物理边界越来越模糊。最终要把功能合并到一个分支,你绝对会陷入到解决冲突的泥潭之中。
- 系统发布效率低:任何模块变更都需要发布整个系统,而系统发布过程中需要多个模块之间制约较多,需要对比各种文件,任何一处出现问题都会导致发布失败,往往一次发布需要数十分钟甚至数小时。
- 系统可用性差:单体架构各个功能模块是作为一个服务部署,相互之间会互相影响,一些热点功能会耗尽系统资源,导致其它服务低可用。
微服务
微服务架构,首先是服务化,就是将单体架构中的功能模块从单体应用中拆分出来,独立部署为多个服务。同时要满足下面的一些特点:
- 单一职责:一个微服务负责一部分业务功能,并且其核心数据不依赖于其它模块。
- 团队自治:每个微服务都有自己独立的开发、测试、发布、运维人员,团队人员规模不超过10人(2张披萨能喂饱)
- 服务自治:每个微服务都独立打包部署,访问自己独立的数据库。并且要做好服务隔离,避免对其它服务产生影响
例如,黑马商城项目,就可以把商品、用户、购物车、交易等模块拆分,交给不同的团队去开发,并独立部署:
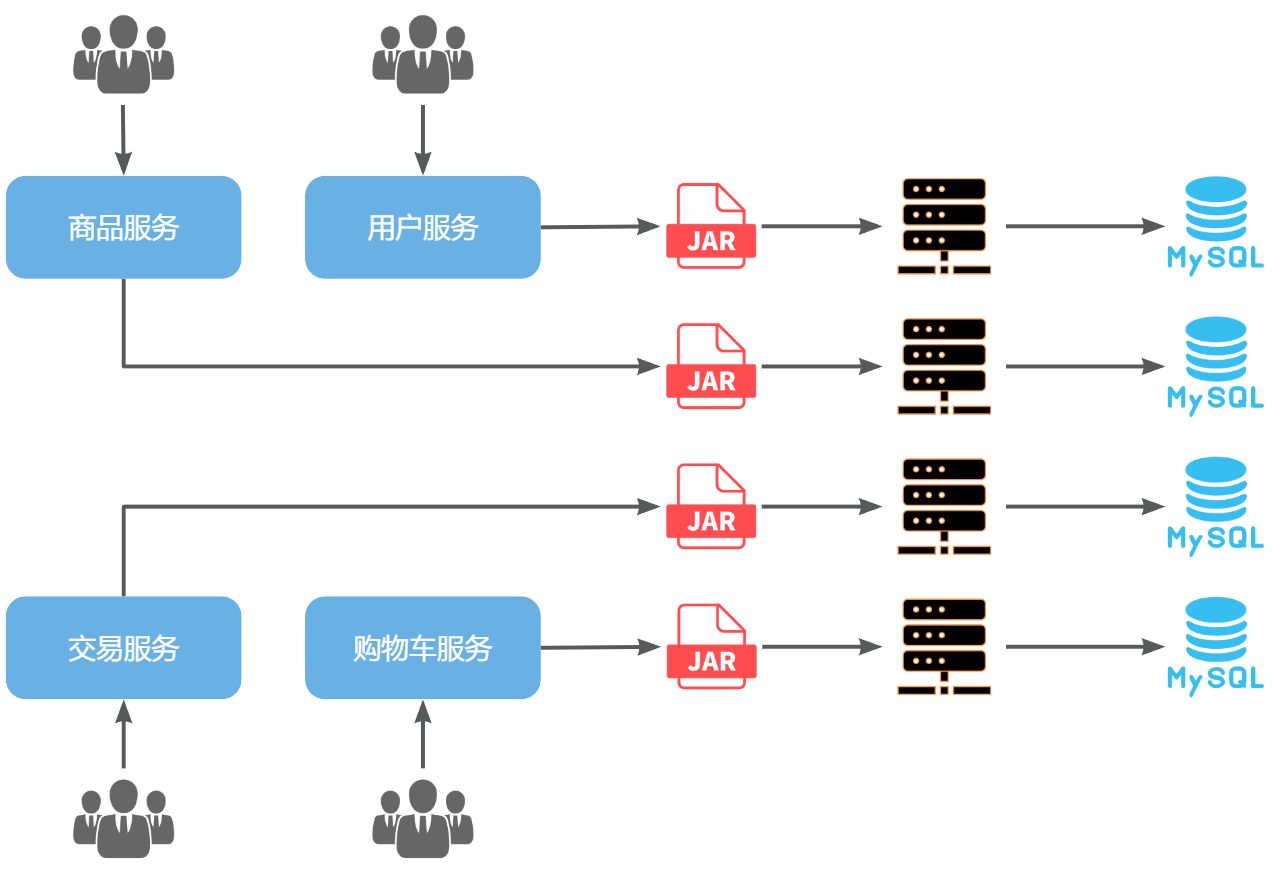
那么,单体架构存在的问题有没有解决呢?
- 团队协作成本高?
- 由于服务拆分,每个服务代码量大大减少,参与开发的后台人员在1~3名,协作成本大大降低
- 系统发布效率低?
- 每个服务都是独立部署,当有某个服务有代码变更时,只需要打包部署该服务即可
- 系统可用性差?
- 每个服务独立部署,并且做好服务隔离,使用自己的服务器资源,不会影响到其它服务。
综上所述,微服务架构解决了单体架构存在的问题,特别适合大型互联网项目的开发,因此被各大互联网公司普遍采用。大家以前可能听说过分布式架构,分布式就是服务拆分的过程,其实微服务架构正式分布式架构的一种最佳实践的方案。
当然,微服务架构虽然能解决单体架构的各种问题,但在拆分的过程中,还会面临很多其它问题。比如:
- 如果出现跨服务的业务该如何处理?
- 页面请求到底该访问哪个服务?
- 如何实现各个服务之间的服务隔离?
SpringCloud
而且SpringCloud依托于SpringBoot的自动装配能力,大大降低了其项目搭建、组件使用的成本。对于没有自研微服务组件能力的中小型企业,使用SpringCloud全家桶来实现微服务开发可以说是最合适的选择了!
目前SpringCloud最新版本为2022.0.x版本,对应的SpringBoot版本为3.x版本,但它们全部依赖于JDK17,目前在企业中使用相对较少。
| SpringCloud版本 | SpringBoot版本 |
|---|---|
| 2022.0.x aka Kilburn | 3.0.x |
| 2021.0.x aka Jubilee | 2.6.x, 2.7.x (Starting with 2021.0.3) |
| 2020.0.x aka Ilford | 2.4.x, 2.5.x (Starting with 2020.0.3) |
| Hoxton | 2.2.x, 2.3.x (Starting with SR5) |
| Greenwich | 2.1.x |
| Finchley | 2.0.x |
| Edgware | 1.5.x |
| Dalston | 1.5.x |
因此,推荐使用次新版本:Spring Cloud 2021.0.x以及Spring Boot 2.7.x版本。
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.heima</groupId>
<artifactId>hmall</artifactId>
<packaging>pom</packaging>
<version>1.0.0</version>
<modules>
<module>hm-common</module>
<module>hm-service</module>
</modules>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.7.12</version>
<relativePath/>
</parent>
<properties>
<maven.compiler.source>11</maven.compiler.source>
<maven.compiler.target>11</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
<org.projectlombok.version>1.18.20</org.projectlombok.version>
<spring-cloud.version>2021.0.3</spring-cloud.version>
<spring-cloud-alibaba.version>2021.0.4.0</spring-cloud-alibaba.version>
<mybatis-plus.version>3.4.3</mybatis-plus.version>
<hutool.version>5.8.11</hutool.version>
<mysql.version>8.0.23</mysql.version>
</properties>
<!-- 对依赖包进行管理 -->
<dependencyManagement>
<dependencies>
<!--spring cloud-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>${spring-cloud.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
<!--spring cloud alibaba-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-alibaba-dependencies</artifactId>
<version>${spring-cloud-alibaba.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
<!-- 数据库驱动包管理 -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>${mysql.version}</version>
</dependency>
<!-- mybatis plus 管理 -->
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>${mybatis-plus.version}</version>
</dependency>
<!--hutool工具包-->
<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-all</artifactId>
<version>${hutool.version}</version>
</dependency>
</dependencies>
</dependencyManagement>
<dependencies>
<!-- lombok 管理 -->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>${org.projectlombok.version}</version>
</dependency>
<!--单元测试-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<pluginManagement>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.8.1</version>
<configuration>
<source>11</source> <!-- depending on your project -->
<target>11</target> <!-- depending on your project -->
</configuration>
</plugin>
</plugins>
</pluginManagement>
</build>
</project>微服务拆分
什么时候拆
一般情况下,对于一个初创的项目,首先要做的是验证项目的可行性。因此这一阶段的首要任
务是敏捷开发,快速产出生产可用的产品,投入市场做验证。为了达成这一目的,该阶段项目
架构往往会比较简单,很多情况下会直接采用单体架构,这样开发成本比较低,可以快速产出
结果,一旦发现项目不符合市场,损失较小。
如果这一阶段采用复杂的微服务架构,投入大量的人力和时间成本用于架构设计,最终发现产
品不符合市场需求,等于全部做了无用功。
所以,对于大多数小型项目来说,一般是先采用单体架构,随着用户规模扩大、业务复杂后再
逐渐拆分为微服务架构。这样初期成本会比较低,可以快速试错。但是,这么做的问题就在于
后期做服务拆分时,可能会遇到很多代码耦合带来的问题,拆分比较困难(前易后难)。
而对于一些大型项目,在立项之初目的就很明确,为了长远考虑,在架构设计时就直接选择微
服务架构。虽然前期投入较多,但后期就少了拆分服务的烦恼(前难后易)。
之前说过,微服务拆分时粒度要小,这其实是拆分的目标。具体可以从两个角度来分析:
- 高内聚:每个微服务的职责要尽量单一,包含的业务相互关联度高、完整度高。
- 低耦合:每个微服务的功能要相对独立,尽量减少对其它微服务的依赖,或者依赖接口的稳定性要强。
明确了拆分目标,接下来就是拆分方式了。在做服务拆分时一般有两种方式:
- 纵向拆分
- 横向拆分
所谓纵向拆分,就是按照项目的功能模块来拆分。例如黑马商城中,就有用户管理功能、订单管理功能、购物车功能、商品管理功能、支付功能等。那么按照功能模块将他们拆分为一个个服务,就属于纵向拆分。这种拆分模式可以尽可能提高服务的内聚性。
而横向拆分,是看各个功能模块之间有没有公共的业务部分,如果有将其抽取出来作为通用服务。例如用户登录是需要发送消息通知,记录风控数据,下单时也要发送短信,记录风控数据。因此消息发送、风控数据记录就是通用的业务功能,因此可以将他们分别抽取为公共服务:消息中心服务、风控管理服务。这样可以提高业务的复用性,避免重复开发。同时通用业务一般接口稳定性较强,也不会使服务之间过分耦合。
远程调用
Spring提供了一个RestTemplate的API,可以方便的实现Http请求的发送。
先将RestTemplate注册为一个Bean:
package com.hmall.cart.config;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.web.client.RestTemplate;
@Configuration
public class RemoteCallConfig {
@Bean
public RestTemplate restTemplate() {
return new RestTemplate();
}
}CartServiceImpl
private void handleCartItems(List<CartVO> vos) {
// 1.获取商品id
Set<Long> itemIds = vos.stream().map(CartVO::getItemId).collect(Collectors.toSet());
// 2.查询商品
// List<ItemDTO> items = itemService.queryItemByIds(itemIds);
// 通过调用http请求获取
ResponseEntity<List<ItemDTO>> response = restTemplate.exchange(
"http://localhost:8081/items={ids}",
HttpMethod.GET,
null,
new ParameterizedTypeReference<List<ItemDTO>>() {
},
Map.of("ids", CollectionUtil.join(itemIds, ","))
);
// 解析数据
if (!response.getStatusCode().is2xxSuccessful()) {
return;
}
List<ItemDTO> items = response.getBody();
if (CollUtils.isEmpty(items)) {
return;
}
// 3.转为 id 到 item的map
Map<Long, ItemDTO> itemMap = items.stream().collect(Collectors.toMap(ItemDTO::getId, Function.identity()));
// 4.写入vo
for (CartVO v : vos) {
ItemDTO item = itemMap.get(v.getItemId());
if (item == null) {
continue;
}
v.setNewPrice(item.getPrice());
v.setStatus(item.getStatus());
v.setStock(item.getStock());
}
}服务治理
注册中心
试想一下,假如商品微服务被调用较多,为了应对更高的并发,进行了多实例部署,如图:

此时,每个item-service的实例其IP或端口不同,问题来了:
- item-service这么多实例,cart-service如何知道每一个实例的地址?
- http请求要写url地址,
cart-service服务到底该调用哪个实例呢? - 如果在运行过程中,某一个
item-service实例宕机,cart-service依然在调用该怎么办? - 如果并发太高,
item-service临时多部署了N台实例,cart-service如何知道新实例的地址?
为了解决上述问题,就必须引入注册中心的概念了
注册中心原理
在微服务远程调用的过程中,包括两个角色:
- 服务提供者:提供接口供其它微服务访问,比如
item-service - 服务消费者:调用其它微服务提供的接口,比如
cart-service
在大型微服务项目中,服务提供者的数量会非常多,为了管理这些服务就引入了注册中心的概念。注册中心、服务提供者、服务消费者三者间关系如下:
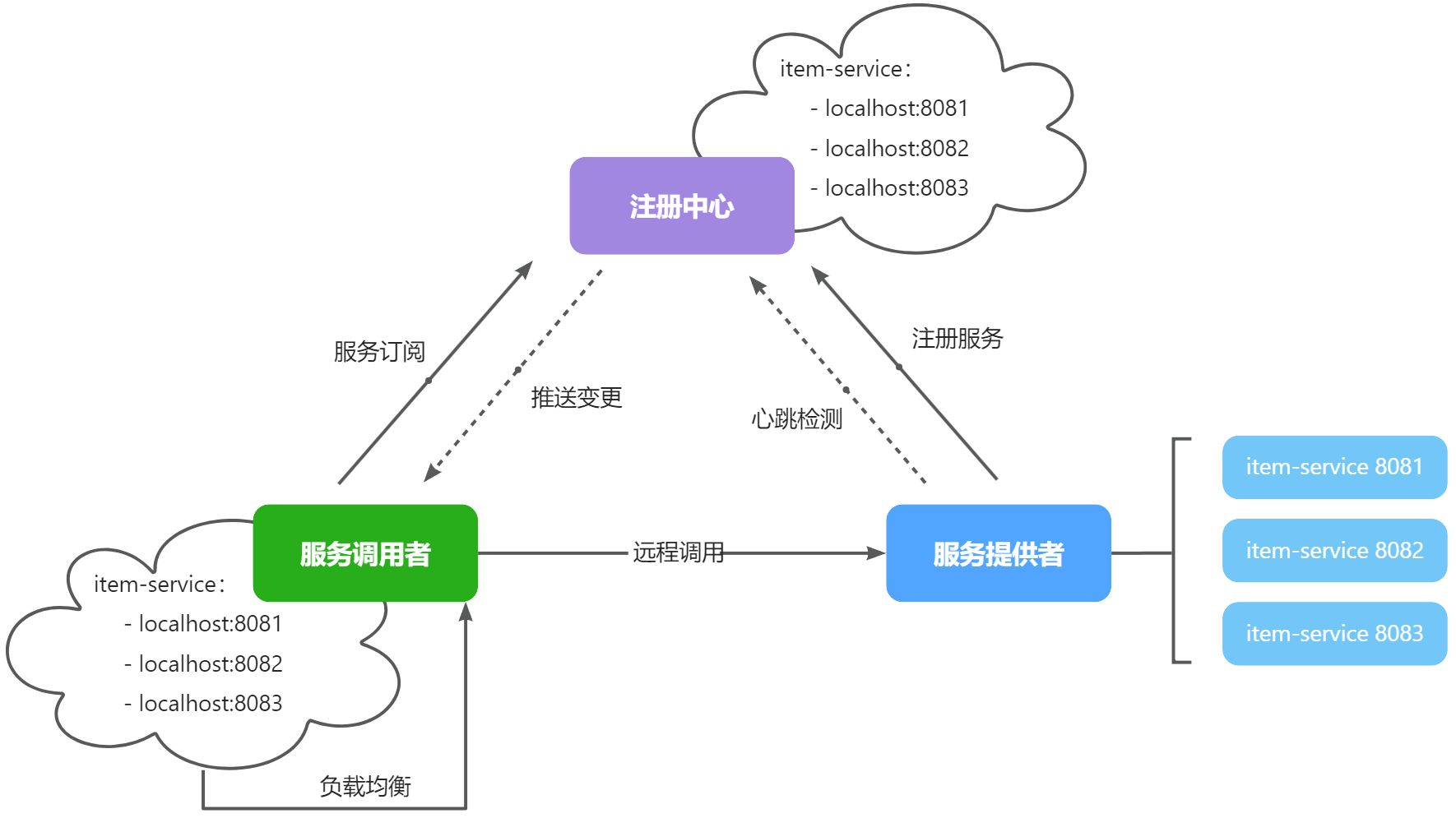
流程如下:
- 服务启动时就会注册自己的服务信息(服务名、IP、端口)到注册中心
- 调用者可以从注册中心订阅想要的服务,获取服务对应的实例列表(1个服务可能多实例部署)
- 调用者自己对实例列表负载均衡,挑选一个实例
- 调用者向该实例发起远程调用
当服务提供者的实例宕机或者启动新实例时,调用者如何得知呢?
- 服务提供者会定期向注册中心发送请求,报告自己的健康状态(心跳请求)
- 当注册中心长时间收不到提供者的心跳时,会认为该实例宕机,将其从服务的实例列表中剔除
- 当服务有新实例启动时,会发送注册服务请求,其信息会被记录在注册中心的服务实例列表
- 当注册中心服务列表变更时,会主动通知微服务,更新本地服务列表
Nacos注册中心
目前开源的注册中心框架有很多,国内比较常见的有:
- Eureka:Netflix公司出品,目前被集成在SpringCloud当中,一般用于Java应用
- Nacos:Alibaba公司出品,目前被集成在SpringCloudAlibaba中,一般用于Java应用
- Consul:HashiCorp公司出品,目前集成在SpringCloud中,不限制微服务语言
Nacos官网 | Nacos 官方社区 | Nacos 下载 | Nacos
基于Docker来部署Nacos的注册中心,首先要准备MySQL数据库表,用来存储Nacos的数据。
部署nacos
配置文件 custom.env
PREFER_HOST_MODE=hostname
MODE=standalone
SPRING_DATASOURCE_PLATFORM=mysql
MYSQL_SERVICE_HOST=mysql 🚩写ip不对
MYSQL_SERVICE_DB_NAME=nacos
MYSQL_SERVICE_PORT=3306
MYSQL_SERVICE_USER=root
MYSQL_SERVICE_PASSWORD=123
MYSQL_SERVICE_DB_PARAM=characterEncoding=utf8&connectTimeout=1000&socketTimeout=3000&autoReconnect=true&useSSL=false&allowPublicKeyRetrieval=true&serverTimezone=Asia/Shanghai
docker run -d \
--name nacos \
--env-file ./nacos/custom.env \
-p 8848:8848 \
-p 9848:9848 \
-p 9849:9849 \
--restart=always \
--network hm-net \
nacos/nacos-server:v2.1.0-slim这里不用和mysql要同一个网络下,因为nacos.env文件中会使用虚拟机地址访问
root@LAPTOP-L6QS5167:~# docker run -d \
--name n> --name nacos \
> --env-file ./nacos/custom.env \
> -p 8848:8848 \
> -p 9848:9848 \
> -p 9849:9849 \
> --restart=always \
> nacos/nacos-server:v2.1.0-slim
Unable to find image 'nacos/nacos-server:v2.1.0-slim' locally
v2.1.0-slim: Pulling from nacos/nacos-server
1fe172e4850f: Pull complete
44d3aa8d0766: Pull complete
81bea02f1eea: Pull complete
072e5a76c05b: Pull complete
b11ea097ecb2: Pull complete
0b1ee541a876: Pull complete
9e6c0537392c: Pull complete
c43200de8246: Pull complete
2c34f234a65f: Pull complete
4f4fb700ef54: Pull complete
Digest: sha256:e689b1c79ca4a391fc478b6b28eac74916bfe569f37abaa8145c156cefe45067
Status: Downloaded newer image for nacos/nacos-server:v2.1.0-slim
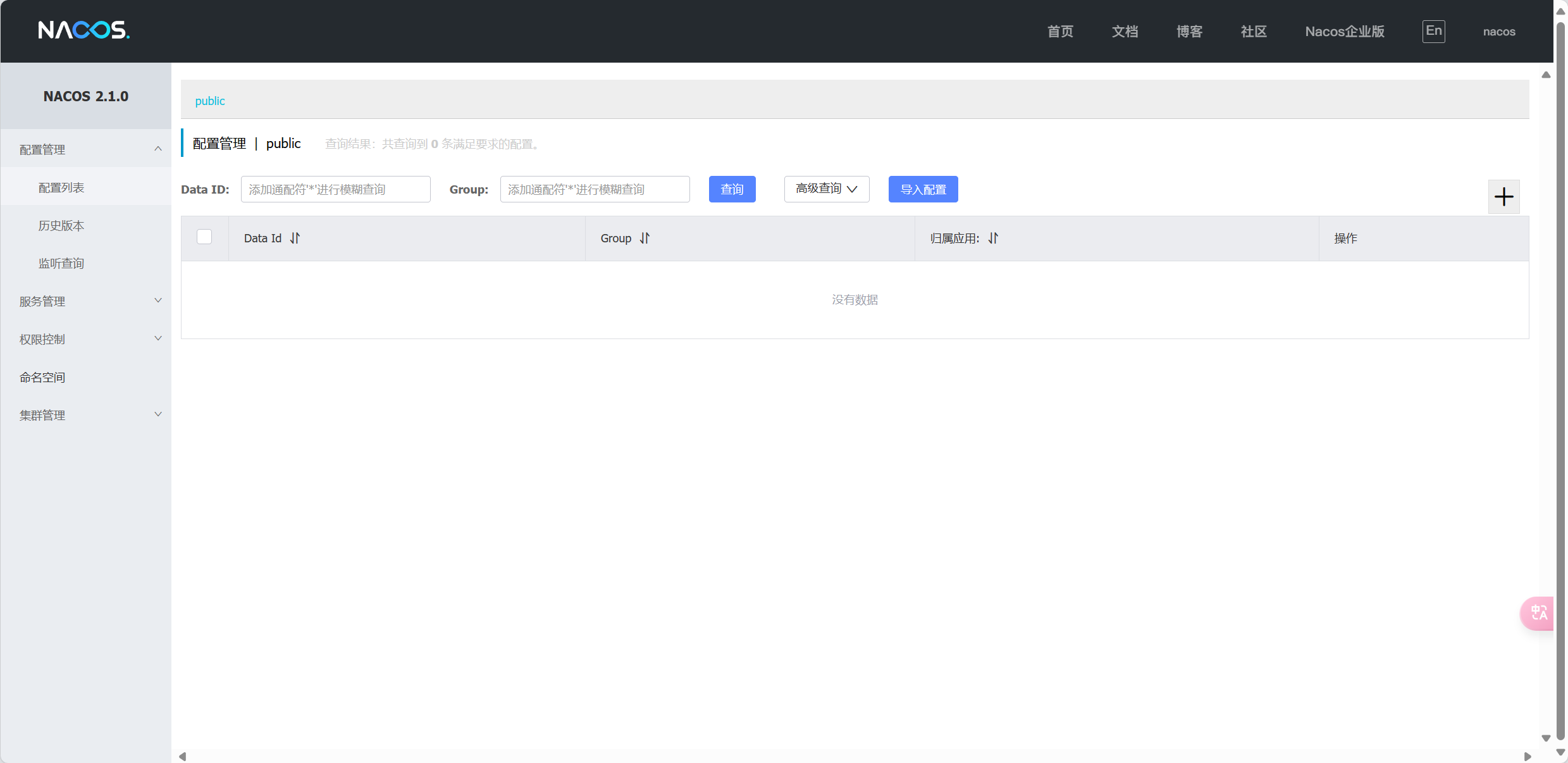
64dacd745237562c7253c9c0c6805cc8ceaf16676264d11b0adbc0353d45269e启动完成后,访问下面地址:http://127.0.0.1:8848/nacos/
账号密码都是nacos
服务注册
引入nacos discovery依赖
在item-service的pom.xml中添加依赖
<!--nacos 服务注册发现-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
</dependency>配置nacos地址
在item-service的application.yml中添加nacos地址配置
spring:
application:
name: item-service # 微服务名称
cloud:
nacos:
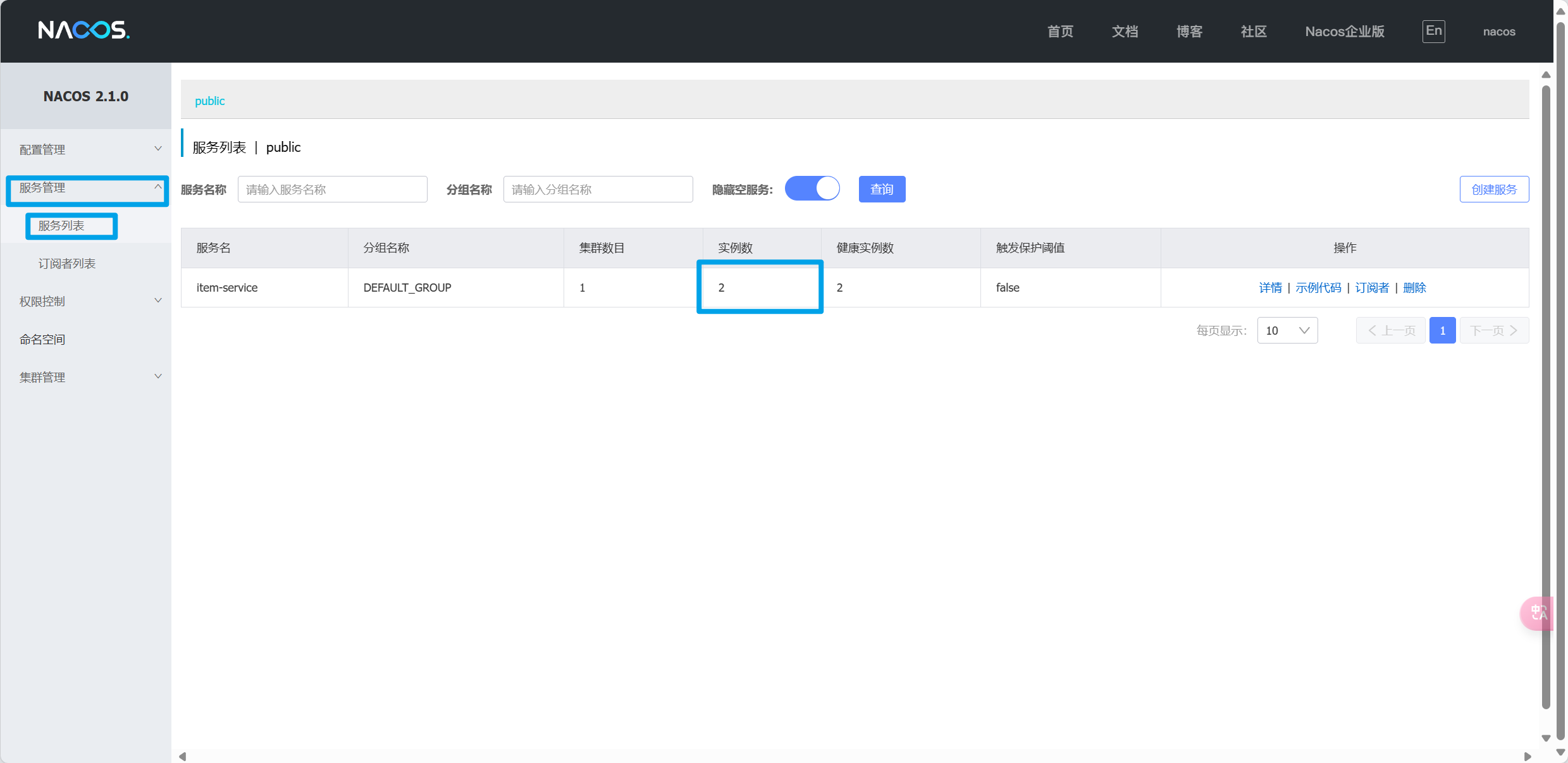
server-addr: 127.0.0.1:8848 # nacos地址为了测试一个服务多个实例的情况,再配置一个item-service的部署实例
ctrl+D复制实例
服务发现
服务的消费者要去nacos订阅服务,这个过程就是服务发现,步骤如下:
- 引入依赖
- 配置Nacos地址
- 发现并调用服务
引入依赖
服务发现除了要引入nacos依赖以外,由于还需要负载均衡,因此要引入SpringCloud提供的LoadBalancer依赖。
在cart-service中的pom.xml中添加下面的依赖
<!--nacos 服务注册发现-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
</dependency>配置Nacos地址
在cart-service的application.yml中添加nacos地址配置
spring:
application:
name: cart-service # 微服务名称
cloud:
nacos:
server-addr: 127.0.0.1:8848 # nacos地址发现并调用服务
服务调用者cart-service订阅item-service服务
常见的负载均衡算法有:
- 随机
- 轮询
- IP的hash
- 最近最少访问
- ...
服务发现需要用到一个工具,DiscoveryClient,SpringCloud已经帮自动装配,可以直接注入使用

改造实现类,不把地址写死
package com.hmall.cart.service.impl;
/**
* <p>
* 订单详情表 服务实现类
* </p>
*/
@Service
@RequiredArgsConstructor
public class CartServiceImpl extends ServiceImpl<CartMapper, Cart> implements ICartService {
// private final IItemService itemService;
@Resource
private RestTemplate restTemplate;
@Resource
private DiscoveryClient discoveryClient;
@Override
public void addItem2Cart(CartFormDTO cartFormDTO) {
// 1.获取登录用户
Long userId = UserContext.getUser();
// 2.判断是否已经存在
if (checkItemExists(cartFormDTO.getItemId(), userId)) {
// 2.1.存在,则更新数量
baseMapper.updateNum(cartFormDTO.getItemId(), userId);
return;
}
// 2.2.不存在,判断是否超过购物车数量
checkCartsFull(userId);
// 3.新增购物车条目
// 3.1.转换PO
Cart cart = BeanUtils.copyBean(cartFormDTO, Cart.class);
// 3.2.保存当前用户
cart.setUserId(userId);
// 3.3.保存到数据库
save(cart);
}
@Override
public List<CartVO> queryMyCarts() {
// 1.查询我的购物车列表
List<Cart> carts = lambdaQuery().eq(Cart::getUserId, 1L /* TODO UserContext.getUser()*/).list();
if (CollUtils.isEmpty(carts)) {
return CollUtils.emptyList();
}
// 2.转换VO
List<CartVO> vos = BeanUtils.copyList(carts, CartVO.class);
// 3.处理VO中的商品信息
handleCartItems(vos);
// 4.返回
return vos;
}
private void handleCartItems(List<CartVO> vos) {
// 1.获取商品id
Set<Long> itemIds = vos.stream().map(CartVO::getItemId).collect(Collectors.toSet());
// 2.查询商品
// List<ItemDTO> items = itemService.queryItemByIds(itemIds);
List<ServiceInstance> instances = discoveryClient.getInstances("item-service");
if(CollUtil.isEmpty(instances)) {
return;
}
ServiceInstance instance = instances.get(RandomUtil.randomInt(instances.size()));
// 通过调用http请求获取
ResponseEntity<List<ItemDTO>> response =
restTemplate.exchange(instance.getUri() + "/items?ids={ids}", HttpMethod.GET, null,
new ParameterizedTypeReference<List<ItemDTO>>() {}, Map.of("ids", CollectionUtil.join(itemIds, ",")));
// 解析数据
if (!response.getStatusCode().is2xxSuccessful()) {
return;
}
List<ItemDTO> items = response.getBody();
if (CollUtils.isEmpty(items)) {
return;
}
// 3.转为 id 到 item的map
Map<Long, ItemDTO> itemMap = items.stream().collect(Collectors.toMap(ItemDTO::getId, Function.identity()));
// 4.写入vo
for (CartVO v : vos) {
ItemDTO item = itemMap.get(v.getItemId());
if (item == null) {
continue;
}
v.setNewPrice(item.getPrice());
v.setStatus(item.getStatus());
v.setStock(item.getStock());
}
}
@Override
public void removeByItemIds(Collection<Long> itemIds) {
// 1.构建删除条件,userId和itemId
QueryWrapper<Cart> queryWrapper = new QueryWrapper<Cart>();
queryWrapper.lambda().eq(Cart::getUserId, UserContext.getUser()).in(Cart::getItemId, itemIds);
// 2.删除
remove(queryWrapper);
}
private void checkCartsFull(Long userId) {
int count = lambdaQuery().eq(Cart::getUserId, userId).count();
if (count >= 10) {
throw new BizIllegalException(StrUtil.format("用户购物车课程不能超过{}", 10));
}
}
private boolean checkItemExists(Long itemId, Long userId) {
int count = lambdaQuery().eq(Cart::getUserId, userId).eq(Cart::getItemId, itemId).count();
return count > 0;
}
}OpenFeign
入门
解决调用太麻烦的问题
远程调用的关键点就在于四个:
- 请求方式
- 请求路径
- 请求参数
- 返回值类型
所以,OpenFeign就利用SpringMVC的相关注解来声明上述4个参数,然后基于动态代理帮生成远程调用的代码,而无需手动再编写
引入依赖
在cart-service服务的pom.xml中引入OpenFeign的依赖和loadBalancer依赖
<!--openFeign-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-openfeign</artifactId>
</dependency>
<!--负载均衡器-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-loadbalancer</artifactId>
</dependency>启用OpenFeign
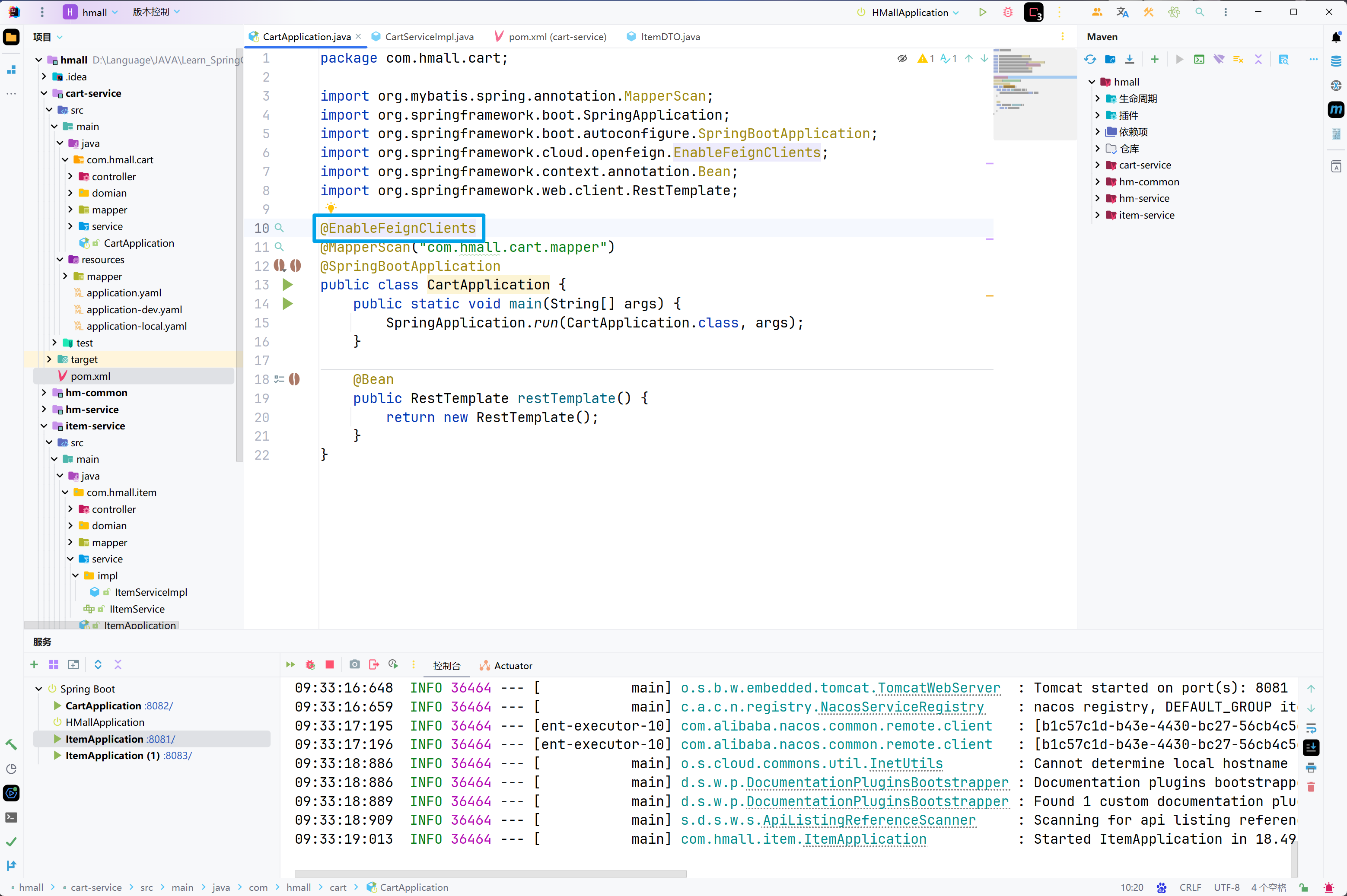
在cart-service的CartApplication启动类上添加EnableFeignClients注解,启动OpenFeign功能
编写OpenFeign客户端
在cart-service中,定义一个新的接口,编写Feign客户端
package com.hmall.cart.client;
import com.hmall.cart.domain.dto.ItemDTO;
import org.springframework.cloud.openfeign.FeignClient;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestParam;
import java.util.List;
@FeignClient("item-service")
public interface ItemClient {
@GetMapping("/items")
List<ItemDTO> queryItemByIds(@RequestParam("ids") Collection<Long> ids);
}这里只需要声明接口,无需实现方法。接口中的几个关键信息:
@FeignClient("item-service"):声明服务名称@GetMapping:声明请求方式@GetMapping("/items"):声明请求路径@RequestParam("ids") Collection<Long> ids:声明请求参数List<ItemDTO>:返回值类型
有了上述信息,OpenFeign就可以利用动态代理帮实现这个方法,并且向http://item-service/items发送一个GET请求,携带ids为请求参数,并自动将返回值处理为List<ItemDTO>。
只需要直接调用这个方法,即可实现远程调用了。
使用FeignClient
在cart-service的com.hmall.cart.service.impl.CartServiceImpl中改造代码,直接调用ItemClient的方法
package com.hmall.cart.service.impl;
/**
* <p>
* 订单详情表 服务实现类
* </p>
*/
@Service
@RequiredArgsConstructor
public class CartServiceImpl extends ServiceImpl<CartMapper, Cart> implements ICartService {
// private final IItemService itemService;
// @Resource
// private RestTemplate restTemplate;
// @Resource
// private DiscoveryClient discoveryClient;
🚩🚩🚩
@Resource
private ItemClient itemClient;
@Override
public void addItem2Cart(CartFormDTO cartFormDTO) {
// 1.获取登录用户
Long userId = UserContext.getUser();
// 2.判断是否已经存在
if (checkItemExists(cartFormDTO.getItemId(), userId)) {
// 2.1.存在,则更新数量
baseMapper.updateNum(cartFormDTO.getItemId(), userId);
return;
}
// 2.2.不存在,判断是否超过购物车数量
checkCartsFull(userId);
// 3.新增购物车条目
// 3.1.转换PO
Cart cart = BeanUtils.copyBean(cartFormDTO, Cart.class);
// 3.2.保存当前用户
cart.setUserId(userId);
// 3.3.保存到数据库
save(cart);
}
@Override
public List<CartVO> queryMyCarts() {
// 1.查询我的购物车列表
List<Cart> carts = lambdaQuery().eq(Cart::getUserId, 1L /* TODO UserContext.getUser()*/).list();
if (CollUtils.isEmpty(carts)) {
return CollUtils.emptyList();
}
// 2.转换VO
List<CartVO> vos = BeanUtils.copyList(carts, CartVO.class);
// 3.处理VO中的商品信息
handleCartItems(vos);
// 4.返回
return vos;
}
private void handleCartItems(List<CartVO> vos) {
// 1.获取商品id
Set<Long> itemIds = vos.stream().map(CartVO::getItemId).collect(Collectors.toSet());
// 2.查询商品
// List<ItemDTO> items = itemService.queryItemByIds(itemIds);
🚩🚩🚩
List<ItemDTO> items = itemClient.queryItemByIds(itemIds);
// List<ServiceInstance> instances = discoveryClient.getInstances("item-service");
// if(CollUtil.isEmpty(instances)) {
// return;
// }
//
// ServiceInstance instance = instances.get(RandomUtil.randomInt(instances.size()));
//
// // 通过调用http请求获取
// ResponseEntity<List<ItemDTO>> response =
// restTemplate.exchange(instance.getUri() + "/items?ids={ids}", HttpMethod.GET, null,
// new ParameterizedTypeReference<List<ItemDTO>>() {}, Map.of("ids", CollectionUtil.join(itemIds, ",")));
//
// // 解析数据
// if (!response.getStatusCode().is2xxSuccessful()) {
// return;
// }
//
// List<ItemDTO> items = response.getBody();
if (CollUtils.isEmpty(items)) {
return;
}
// 3.转为 id 到 item的map
Map<Long, ItemDTO> itemMap = items.stream().collect(Collectors.toMap(ItemDTO::getId, Function.identity()));
// 4.写入vo
for (CartVO v : vos) {
ItemDTO item = itemMap.get(v.getItemId());
if (item == null) {
continue;
}
v.setNewPrice(item.getPrice());
v.setStatus(item.getStatus());
v.setStock(item.getStock());
}
}
@Override
public void removeByItemIds(Collection<Long> itemIds) {
// 1.构建删除条件,userId和itemId
QueryWrapper<Cart> queryWrapper = new QueryWrapper<Cart>();
queryWrapper.lambda().eq(Cart::getUserId, UserContext.getUser()).in(Cart::getItemId, itemIds);
// 2.删除
remove(queryWrapper);
}
private void checkCartsFull(Long userId) {
int count = lambdaQuery().eq(Cart::getUserId, userId).count();
if (count >= 10) {
throw new BizIllegalException(StrUtil.format("用户购物车课程不能超过{}", 10));
}
}
private boolean checkItemExists(Long itemId, Long userId) {
int count = lambdaQuery().eq(Cart::getUserId, userId).eq(Cart::getItemId, itemId).count();
return count > 0;
}
}连接池
Feign底层发起http请求,依赖于其它的框架。其底层支持的http客户端实现包括:
- HttpURLConnection:默认实现,不支持连接池(慢)
- Apache HttpClient :支持连接池
- OKHttp:支持连接池
因此通常会使用带有连接池的客户端来代替默认的HttpURLConnection。比如,使用OK Http.
引入依赖
在cart-service的pom.xml中引入依赖
<!--OK http 的依赖 -->
<dependency>
<groupId>io.github.openfeign</groupId>
<artifactId>feign-okhttp</artifactId>
</dependency>开启连接池
在cart-service的application.yml配置文件中开启Feign的连接池功能
feign:
okhttp:
enabled: true # 开启OKHttp功能最佳实践
避免重复编码的办法就是抽取。不过这里有两种抽取思路:
- 思路1:抽取到微服务之外的公共module
- 思路2:每个微服务自己抽取一个module
方案1抽取更加简单,工程结构也比较清晰,但缺点是整个项目耦合度偏高。
方案2抽取相对麻烦,工程结构相对更复杂,但服务之间耦合度降低。
由于item-service已经创建好,无法继续拆分,因此这里采用方案1
抽取Feign客户端
在hmall下定义一个新的module,命名为hm-api
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>com.heima</groupId>
<artifactId>hmall</artifactId>
<version>1.0.0</version>
</parent>
<artifactId>hm-api</artifactId>
<properties>
<maven.compiler.source>11</maven.compiler.source>
<maven.compiler.target>11</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<!--openFeign-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-openfeign</artifactId>
</dependency>
<!--负载均衡器-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-loadbalancer</artifactId>
</dependency>
<!--OK http 的依赖 -->
<dependency>
<groupId>io.github.openfeign</groupId>
<artifactId>feign-okhttp</artifactId>
</dependency>
<dependency>
<groupId>io.swagger</groupId>
<artifactId>swagger-annotations</artifactId>
<version>1.6.6</version>
<scope>compile</scope>
</dependency>
<dependency>
<groupId>io.swagger</groupId>
<artifactId>swagger-annotations</artifactId>
<version>1.6.6</version>
<scope>compile</scope>
</dependency>
</dependencies>
</project>现在,任何微服务要调用item-service中的接口,只需要引入hm-api模块依赖即可,无需自己编写Feign客户端了。
扫描包
在cart-service的pom.xml中引入hm-api模块
<!--feign模块-->
<dependency>
<groupId>com.heima</groupId>
<artifactId>hm-api</artifactId>
<version>1.0.0</version>
</dependency>删除cart-service中原来的ItemDTO和ItemClient,重启项目,发现报错
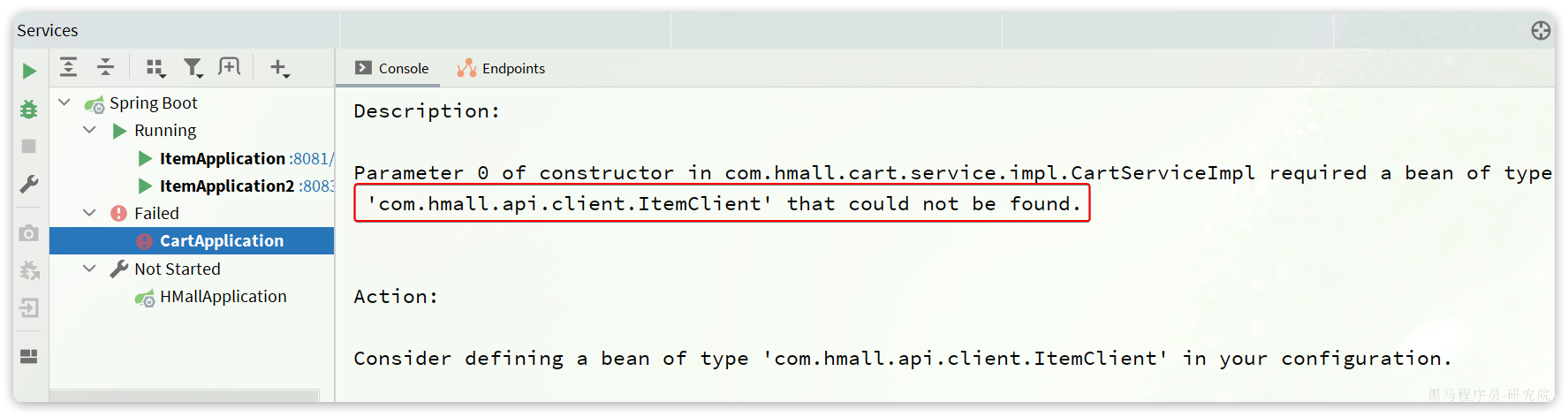
因为ItemClient现在定义到了com.hmall.api.client包下,而cart-service的启动类定义在com.hmall.cart包下,扫描不到ItemClient,所以报错了
解决办法
- 方式1:声明扫描包
@EnableFeignClients(basePackages = "com.hmall.api.client")
@MapperScan("com.hmall.cart.mapper")
@SpringBootApplication
public class CartApplication {
public static void main(String[] args) {
SpringApplication.run(CartApplication.class, args);
}
@Bean
public RestTemplate restTemplate() {
return new RestTemplate();
}
}- 方式2:声明要用的FeignClient
@EnableFeignClients(clients = {ItemClient.class})
@MapperScan("com.hmall.cart.mapper")
@SpringBootApplication
public class CartApplication {
public static void main(String[] args) {
SpringApplication.run(CartApplication.class, args);
}
@Bean
public RestTemplate restTemplate() {
return new RestTemplate();
}
}日志配置
OpenFeign只会在FeignClient所在包的日志级别为DEBUG时,才会输出日志。而且其日志级别有4级:
- NONE:不记录任何日志信息,这是默认值。
- BASIC:仅记录请求的方法,URL以及响应状态码和执行时间
- HEADERS:在BASIC的基础上,额外记录了请求和响应的头信息
- FULL:记录所有请求和响应的明细,包括头信息、请求体、元数据。
Feign默认的日志级别就是NONE,所以默认看不到请求日志。
定义日志级别
在hm-api模块下新建一个配置类,定义Feign的日志级别
package com.hmall.api.config;
/**
* @author:CharmingDaiDai
* @project:hmall
* @since:2024/5/21 下午12:49
*/
import feign.Logger;
import org.springframework.context.annotation.Bean;
public class DefaultFeignConfig {
@Bean
public Logger.Level feignLogLevel(){
return Logger.Level.FULL;
}
}配置
接下来,要让日志级别生效,还需要配置这个类。有两种方式:
- 局部生效:在某个
FeignClient中配置,只对当前FeignClient生效
@FeignClient(value = "item-service", configuration = DefaultFeignConfig.class)- 全局生效:在
@EnableFeignClients中配置,针对所有FeignClient生效。
@EnableFeignClients(defaultConfiguration = DefaultFeignConfig.class)日志格式:
12:50:55:171 INFO 35972 --- [nio-8082-exec-1] o.a.c.c.C.[Tomcat].[localhost].[/] : Initializing Spring DispatcherServlet 'dispatcherServlet'
12:50:55:173 INFO 35972 --- [nio-8082-exec-1] o.s.web.servlet.DispatcherServlet : Initializing Servlet 'dispatcherServlet'
12:50:55:174 INFO 35972 --- [nio-8082-exec-1] o.s.web.servlet.DispatcherServlet : Completed initialization in 1 ms
WARNING: An illegal reflective access operation has occurred
WARNING: Illegal reflective access by com.baomidou.mybatisplus.core.toolkit.SetAccessibleAction (file:/E:/MySoftware/apache-maven-3.9.6/local%20repository/com/baomidou/mybatis-plus-core/3.4.3/mybatis-plus-core-3.4.3.jar) to field java.lang.invoke.SerializedLambda.capturingClass
WARNING: Please consider reporting this to the maintainers of com.baomidou.mybatisplus.core.toolkit.SetAccessibleAction
WARNING: Use --illegal-access=warn to enable warnings of further illegal reflective access operations
WARNING: All illegal access operations will be denied in a future release
12:50:55:252 INFO 35972 --- [nio-8082-exec-1] com.zaxxer.hikari.HikariDataSource : HikariPool-1 - Starting...
12:50:55:487 INFO 35972 --- [nio-8082-exec-1] com.zaxxer.hikari.HikariDataSource : HikariPool-1 - Start completed.
12:50:55:492 DEBUG 35972 --- [nio-8082-exec-1] c.h.cart.mapper.CartMapper.selectList : ==> Preparing: SELECT id,user_id,item_id,num,name,spec,price,image,create_time,update_time FROM cart WHERE (user_id = ?)
12:50:55:510 DEBUG 35972 --- [nio-8082-exec-1] c.h.cart.mapper.CartMapper.selectList : ==> Parameters: 1(Long)
12:50:55:532 DEBUG 35972 --- [nio-8082-exec-1] c.h.cart.mapper.CartMapper.selectList : <== Total: 1
12:50:55:578 DEBUG 35972 --- [nio-8082-exec-1] com.hmall.api.client.ItemClient : [ItemClient#queryItemByIds] ---> GET http://item-service/items?ids=100000006163 HTTP/1.1
12:50:55:578 DEBUG 35972 --- [nio-8082-exec-1] com.hmall.api.client.ItemClient : [ItemClient#queryItemByIds] ---> END HTTP (0-byte body)
12:50:55:745 DEBUG 35972 --- [nio-8082-exec-1] com.hmall.api.client.ItemClient : [ItemClient#queryItemByIds] <--- HTTP/1.1 200 (167ms)
12:50:55:746 DEBUG 35972 --- [nio-8082-exec-1] com.hmall.api.client.ItemClient : [ItemClient#queryItemByIds] connection: keep-alive
12:50:55:746 DEBUG 35972 --- [nio-8082-exec-1] com.hmall.api.client.ItemClient : [ItemClient#queryItemByIds] content-type: application/json
12:50:55:746 DEBUG 35972 --- [nio-8082-exec-1] com.hmall.api.client.ItemClient : [ItemClient#queryItemByIds] date: Tue, 21 May 2024 04:50:55 GMT
12:50:55:746 DEBUG 35972 --- [nio-8082-exec-1] com.hmall.api.client.ItemClient : [ItemClient#queryItemByIds] keep-alive: timeout=60
12:50:55:746 DEBUG 35972 --- [nio-8082-exec-1] com.hmall.api.client.ItemClient : [ItemClient#queryItemByIds] transfer-encoding: chunked
12:50:55:746 DEBUG 35972 --- [nio-8082-exec-1] com.hmall.api.client.ItemClient : [ItemClient#queryItemByIds]
12:50:55:747 DEBUG 35972 --- [nio-8082-exec-1] com.hmall.api.client.ItemClient : [ItemClient#queryItemByIds] [{"id":"100000006163","name":"巴布豆(BOBDOG)柔薄悦动婴儿拉拉裤XXL码80片(15kg以上)","price":67100,"stock":10000,"image":"https://m.360buyimg.com/mobilecms/s720x720_jfs/t23998/350/2363990466/222391/a6e9581d/5b7cba5bN0c18fb4f.jpg!q70.jpg.webp","category":"拉拉裤","brand":"巴布豆","spec":"{}","sold":11,"commentCount":33343434,"isAD":false,"status":2}]
12:50:55:747 DEBUG 35972 --- [nio-8082-exec-1] com.hmall.api.client.ItemClient : [ItemClient#queryItemByIds] <--- END HTTP (371-byte body)
12:50:56:213 INFO 35972 --- [ent-executor-13] com.alibaba.nacos.common.remote.client : [d5b35aa5-4584-4496-acc5-f13a43d0aea4] Receive server push request, request = NotifySubscriberRequest, requestId = 20
12:50:56:213 INFO 35972 --- [ent-executor-13] com.alibaba.nacos.common.remote.client : [d5b35aa5-4584-4496-acc5-f13a43d0aea4] Ack server push request, request = NotifySubscriberRequest, requestId = 20网关
由于每个微服务都有不同的地址或端口,入口不同,一些问题:
- 请求不同数据时要访问不同的入口,需要维护多个入口地址,麻烦
- 前端无法调用nacos,无法实时更新服务列表
单体架构时只需要完成一次用户登录、身份校验,就可以在所有业务中获取到用户信息。而微服务拆分后,每个微服务都独立部署,这就存在一些问题:
- 每个微服务都需要编写登录校验、用户信息获取的功能吗?
- 当微服务之间调用时,该如何传递用户信息?
认识网关
网关就是网络的关口。数据在网络间传输,从一个网络传输到另一网络时就需要经过网关来做数据的路由和转发以及数据安全的校验。
- 网关可以做安全控制,也就是登录身份校验,校验通过才放行
- 通过认证后,网关再根据请求判断应该访问哪个微服务,将请求转发过去
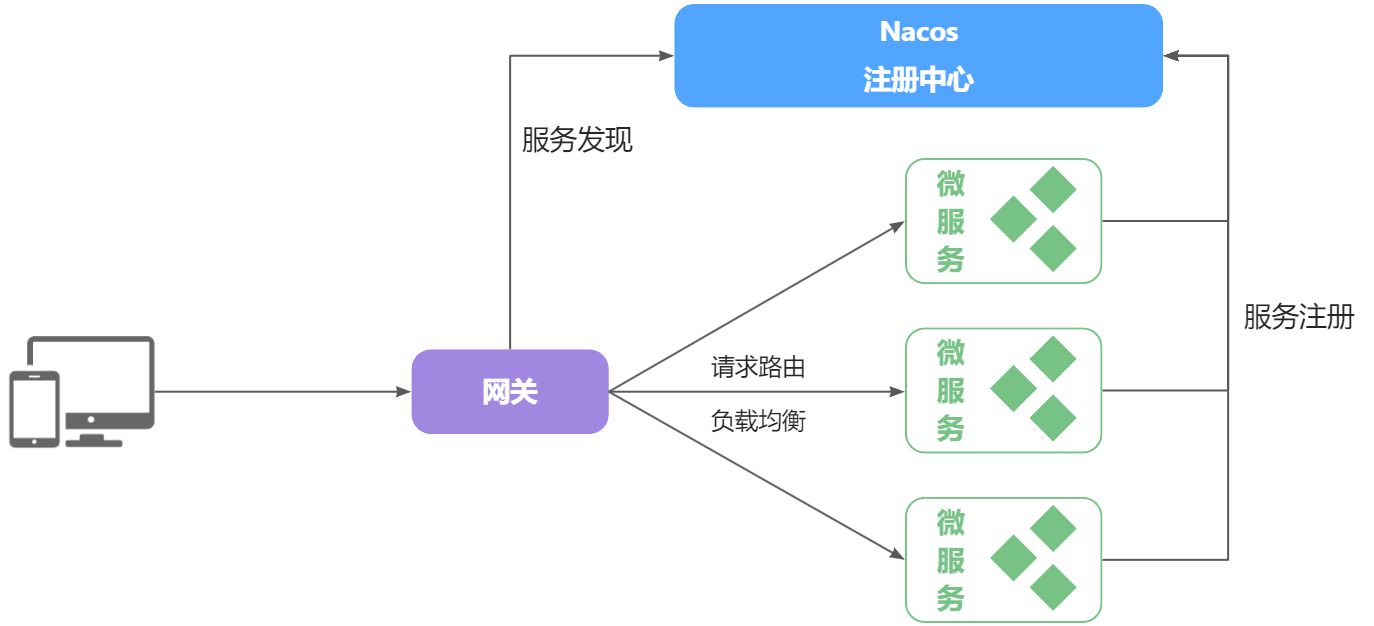
在SpringCloud当中,提供了两种网关实现方案:
- Netflix Zuul:早期实现,目前已经淘汰
- SpringCloudGateway:基于Spring的WebFlux技术,完全支持响应式编程,吞吐能力更强
入门
大概步骤如下:
- 创建网关微服务
- 引入SpringCloudGateway、NacosDiscovery依赖
- 编写启动类
- 配置网关路由
创建新模块hm-gateway
引入依赖
在hm-gateway模块的pom.xml文件中引入依赖
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<parent>
<artifactId>hmall</artifactId>
<groupId>com.heima</groupId>
<version>1.0.0</version>
</parent>
<modelVersion>4.0.0</modelVersion>
<artifactId>hm-gateway</artifactId>
<properties>
<maven.compiler.source>11</maven.compiler.source>
<maven.compiler.target>11</maven.compiler.target>
</properties>
<dependencies>
<!--common-->
<dependency>
<groupId>com.heima</groupId>
<artifactId>hm-common</artifactId>
<version>1.0.0</version>
</dependency>
<!--网关-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-gateway</artifactId>
</dependency>
<!--nacos discovery-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
</dependency>
<!--负载均衡-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-loadbalancer</artifactId>
</dependency>
</dependencies>
<build>
<finalName>${project.artifactId}</finalName>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>启动类
在hm-gateway模块的com.hmall.gateway包下新建一个启动类
package com.hmall.gateway;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
/**
* @author:CharmingDaiDai
* @project:hmall
* @since:2024/5/21 下午8:43
*/
@SpringBootApplication
public class GatewayApplication {
public static void main(String[] args) {
SpringApplication.run(GatewayApplication.class, args);
}
}配置路由
在hm-gateway模块的resources目录新建一个application.yaml文件
server:
port: 8080
spring:
application:
name: gateway
cloud:
nacos:
server-addr: 127.0.0.1:8848
gateway:
routes:
- id: item # 路由规则id,自定义,唯一
uri: lb://item-service # 路由的目标服务,lb代表负载均衡,会从注册中心拉取服务列表
predicates: # 路由断言,判断当前请求是否符合当前规则,符合则路由到目标服务
- Path=/items/**,/search/** # 这里是以请求路径作为判断规则
- id: cart
uri: lb://cart-service
predicates:
- Path=/carts/**
- id: user
uri: lb://user-service
predicates:
- Path=/users/**,/addresses/**
- id: trade
uri: lb://trade-service
predicates:
- Path=/orders/**
- id: pay
uri: lb://pay-service
predicates:
- Path=/pay-orders/**测试
启动GatewayApplication,以 http://localhost:8080 拼接微服务接口路径来测试。例如:
http://localhost:8080/items/page?pageNo=1&pageSize=1
{
"total": "88476",
"pages": "88476",
"list": [
{
"id": "2120808",
"name": "姬龙雪 guy laroche女包 GL经典手提包女牛皮大容量单肩包女欧美时尚包包女包GS1210001-06杏色",
"price": 71800,
"stock": 1,
"image": "https://m.360buyimg.com/mobilecms/s720x720_jfs/t30694/267/398774087/90954/6fc143cf/5bf25358N14dadbf7.jpg!q70.jpg.webp",
"category": "真皮包",
"brand": "姬龙雪",
"spec": "{}",
"sold": 0,
"commentCount": 0,
"isAD": false,
"status": 1
}
]
}
路由规则的定义语法如下:
spring:
cloud:
gateway:
routes:
- id: item
uri: lb://item-service
predicates:
- Path=/items/**,/search/**其中routes对应的类型如下:
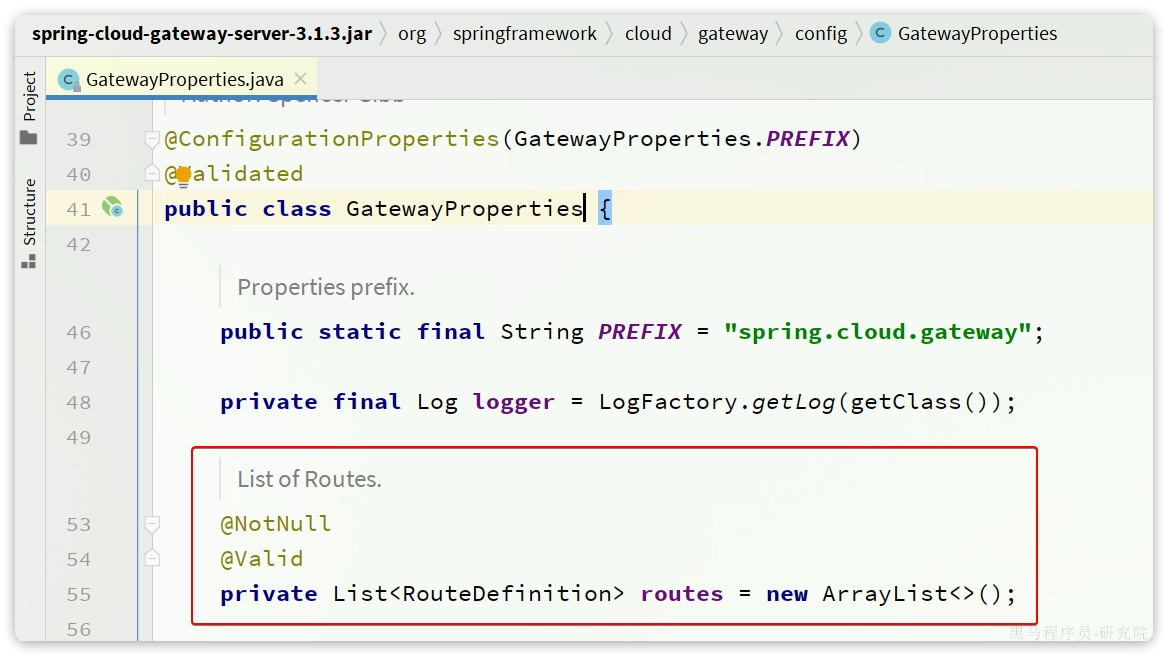
是一个集合,也就是说可以定义很多路由规则。集合中的RouteDefinition就是具体的路由规则定义,其中常见的属性如下:
四个属性含义如下:
id:路由的唯一标示predicates:路由断言,其实就是匹配条件filters:路由过滤条件,后面讲uri:路由目标地址,lb://代表负载均衡,从注册中心获取目标微服务的实例列表,并且负载均衡选择一个访问。
predicates,也就是路由断言。SpringCloudGateway中支持的断言类型有很多:
| 名称 | 说明 | 示例 |
|---|---|---|
| After | 是某个时间点后的请求 | - After=2037-01-20T17:42:47.789-07:00[America/Denver] |
| Before | 是某个时间点之前的请求 | - Before=2031-04-13T15:14:47.433+08:00[Asia/Shanghai] |
| Between | 是某两个时间点之前的请求 | - Between=2037-01-20T17:42:47.789-07:00[America/Denver], 2037-01-21T17:42:47.789-07:00[America/Denver] |
| Cookie | 请求必须包含某些cookie | - Cookie=chocolate, ch.p |
| Header | 请求必须包含某些header | - Header=X-Request-Id, \d+ |
| Host | 请求必须是访问某个host(域名) | - Host=**.somehost.org,**.anotherhost.org |
| Method | 请求方式必须是指定方式 | - Method=GET,POST |
| Path | 请求路径必须符合指定规则 | - Path=/red/{segment},/blue/** |
| Query | 请求参数必须包含指定参数 | - Query=name, Jack或者- Query=name |
| RemoteAddr | 请求者的ip必须是指定范围 | - RemoteAddr=192.168.1.1/24 |
| weight | 权重处理 |
过滤器
GatewayFilter Factories :: Spring Cloud Gateway
网关登录校验
在网关转发之前做JWT校验
网关过滤器
登录校验必须在请求转发到微服务之前做,否则就失去了意义。而网关的请求转发是Gateway内部代码实现的,要想在请求转发之前做登录校验,就必须了解Gateway内部工作的基本原理。
如图所示:
- 客户端请求进入网关后由
HandlerMapping对请求做判断,找到与当前请求匹配的路由规则(Route),然后将请求交给WebHandler去处理。 WebHandler则会加载当前路由下需要执行的过滤器链(Filter chain),然后按照顺序逐一执行过滤器(后面称为**Filter**)。- 图中
Filter被虚线分为左右两部分,是因为Filter内部的逻辑分为pre和post两部分,分别会在请求路由到微服务之前和之后被执行。 - 只有所有
Filter的pre逻辑都依次顺序执行通过后,请求才会被路由到微服务。 - 微服务返回结果后,再倒序执行
Filter的post逻辑。 - 最终把响应结果返回。
如图中所示,最终请求转发是有一个名为NettyRoutingFilter的过滤器来执行的,而且这个过滤器是整个过滤器链中顺序最靠后的一个。如果能够定义一个过滤器,在其中实现登录校验逻辑,并且将过滤器执行顺序定义到NettyRoutingFilter之前,这就符合需求了!
需要解决的问题
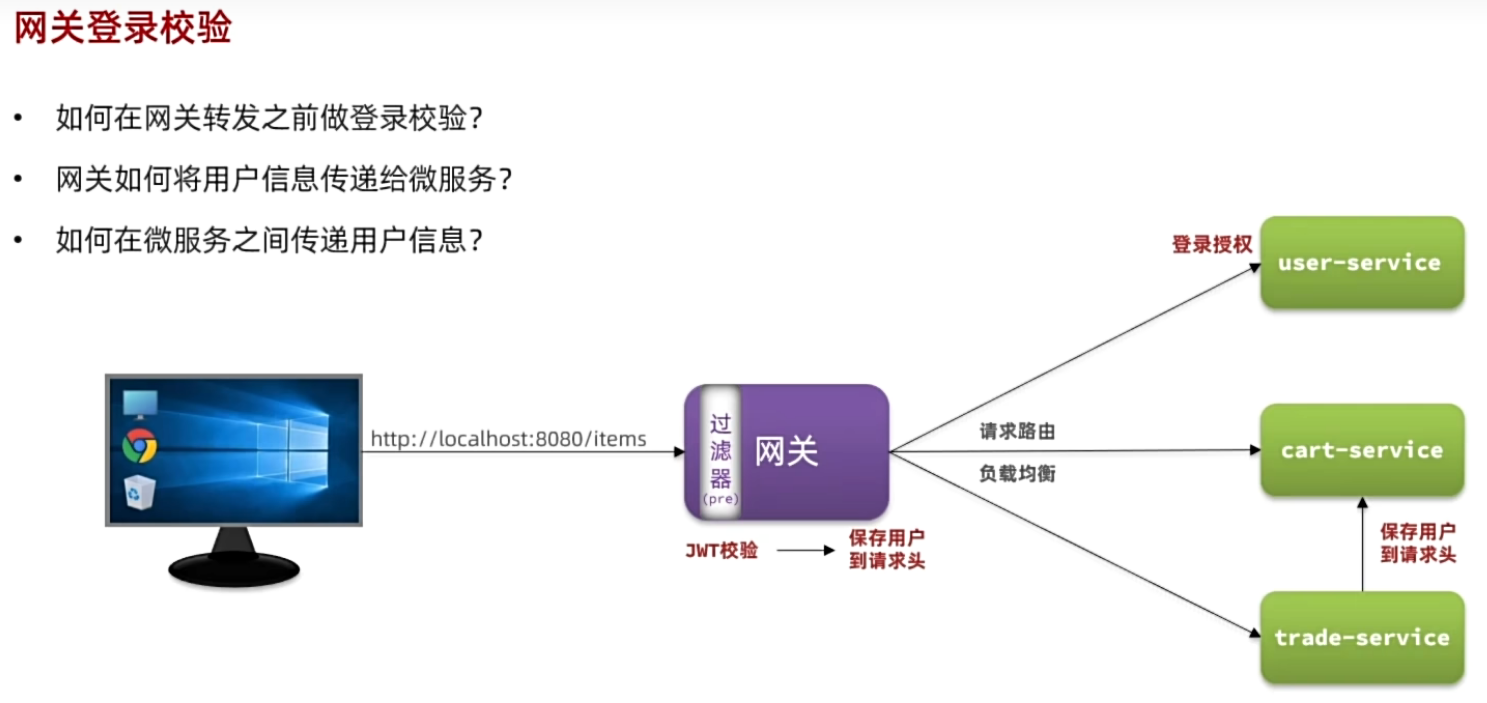
那么,该如何实现一个网关过滤器呢?
网关过滤器链中的过滤器有两种:
GatewayFilter:路由过滤器,作用范围比较灵活,可以是任意指定的路由Route.GlobalFilter:全局过滤器,作用范围是所有路由,不可配置。
注意:过滤器链之外还有一种过滤器,HttpHeadersFilter,用来处理传递到下游微服务的请求头。例如org.springframework.cloud.gateway.filter.headers.XForwardedHeadersFilter可以传递代理请求原本的host头到下游微服务。
其实GatewayFilter和GlobalFilter这两种过滤器的方法签名完全一致:
/**
* 处理请求并将其传递给下一个过滤器
* @param exchange 当前请求的上下文,其中包含request、response等各种数据
* @param chain 过滤器链,基于它向下传递请求
* @return 根据返回值标记当前请求是否被完成或拦截,chain.filter(exchange)就放行了。
*/
Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain);FilteringWebHandler在处理请求时,会将GlobalFilter装饰为GatewayFilter,然后放到同一个过滤器链中,排序以后依次执行。
Gateway中内置了很多的GatewayFilter,详情可以参考官方文档:
Gateway内置的GatewayFilter过滤器使用起来非常简单,无需编码,只要在yaml文件中简单配置即可。而且其作用范围也很灵活,配置在哪个Route下,就作用于哪个Route.
例如,有一个过滤器叫做AddRequestHeaderGatewayFilterFacotry,顾明思议,就是添加请求头的过滤器,可以给请求添加一个请求头并传递到下游微服务。
使用的使用只需要在application.yaml中这样配置:
spring:
cloud:
gateway:
routes:
- id: test_route
uri: lb://test-service
predicates:
-Path=/test/**
filters:
- AddRequestHeader=key, value # 逗号之前是请求头的key,逗号之后是value如果想要让过滤器作用于所有的路由,则可以这样配置:
spring:
cloud:
gateway:
default-filters: # default-filters下的过滤器可以作用于所有路由
- AddRequestHeader=key, value
routes:
- id: test_route
uri: lb://test-service
predicates:
-Path=/test/**自定义过滤器
package com.hmall.gateway.filters;
import org.springframework.cloud.gateway.filter.GatewayFilterChain;
import org.springframework.cloud.gateway.filter.GlobalFilter;
import org.springframework.core.Ordered;
import org.springframework.http.HttpHeaders;
import org.springframework.http.server.reactive.ServerHttpRequest;
import org.springframework.stereotype.Component;
import org.springframework.web.server.ServerWebExchange;
import reactor.core.publisher.Mono;
/**
* @author:CharmingDaiDai
* @project:hmall
* @since:2024/5/21 下午10:11
*/
@Component
public class MyGlobalFilter implements GlobalFilter, Ordered {
@Override
public Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) {
// TODO 模拟登录校验逻辑
ServerHttpRequest request = exchange.getRequest();
HttpHeaders headers = request.getHeaders();
System.out.println("headers = " + headers);
// 放行
return chain.filter(exchange);
}
@Override
public int getOrder() {
// 定义过滤器优先级,数字越小优先级越高,可以为负数
return 0;
}
}自定义GatewayFilter
自定义GatewayFilter不是直接实现GatewayFilter,而是实现AbstractGatewayFilterFactory。最简单的方式是这样的:
@Component
public class PrintAnyGatewayFilterFactory extends AbstractGatewayFilterFactory<Object> {
@Override
public GatewayFilter apply(Object config) {
return new GatewayFilter() {
@Override
public Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) {
// 获取请求
ServerHttpRequest request = exchange.getRequest();
// 编写过滤器逻辑
System.out.println("过滤器执行了");
// 放行
return chain.filter(exchange);
}
};
}
}注意:该类的名称一定要以GatewayFilterFactory为后缀!
然后在yaml配置中这样使用:
spring:
cloud:
gateway:
default-filters:
- PrintAny # 此处直接以自定义的GatewayFilterFactory类名称前缀类声明过滤器带ordered顺序的
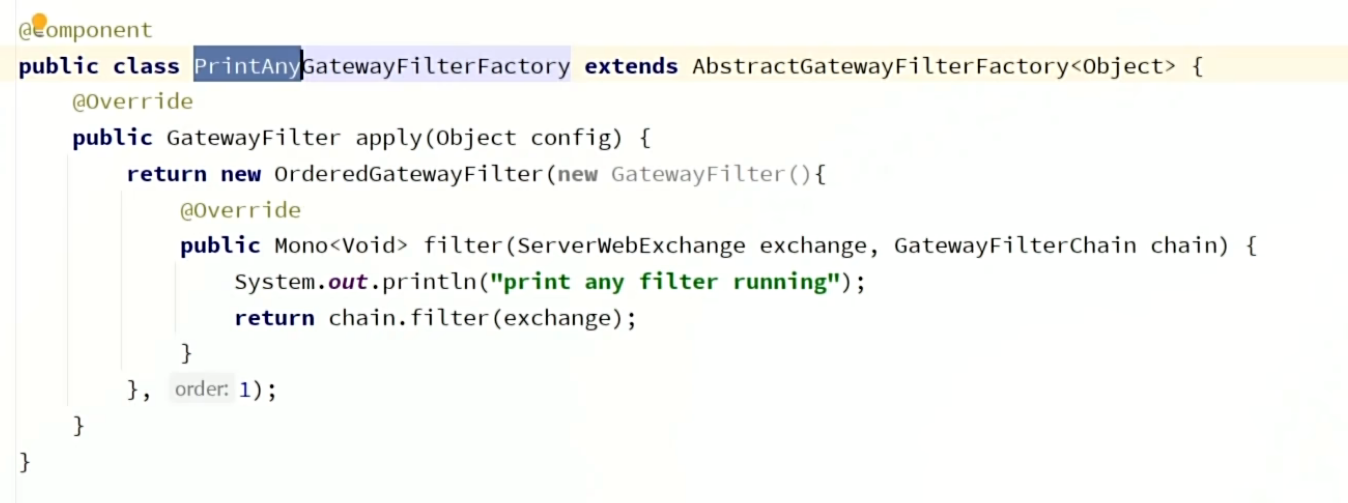
这种过滤器还可以支持动态配置参数,不过实现起来比较复杂,示例:
@Component
public class PrintAnyGatewayFilterFactory // 父类泛型是内部类的Config类型
extends AbstractGatewayFilterFactory<PrintAnyGatewayFilterFactory.Config> {
@Override
public GatewayFilter apply(Config config) {
// OrderedGatewayFilter是GatewayFilter的子类,包含两个参数:
// - GatewayFilter:过滤器
// - int order值:值越小,过滤器执行优先级越高
return new OrderedGatewayFilter(new GatewayFilter() {
@Override
public Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) {
// 获取config值
String a = config.getA();
String b = config.getB();
String c = config.getC();
// 编写过滤器逻辑
System.out.println("a = " + a);
System.out.println("b = " + b);
System.out.println("c = " + c);
// 放行
return chain.filter(exchange);
}
}, 100);
}
// 自定义配置属性,成员变量名称很重要,下面会用到
@Data
static class Config{
private String a;
private String b;
private String c;
}
// 将变量名称依次返回,顺序很重要,将来读取参数时需要按顺序获取
@Override
public List<String> shortcutFieldOrder() {
return List.of("a", "b", "c");
}
// 返回当前配置类的类型,也就是内部的Config
@Override
public Class<Config> getConfigClass() {
return Config.class;
}
}然后在yaml文件中使用:
spring:
cloud:
gateway:
default-filters:
- PrintAny=1,2,3 # 注意,这里多个参数以","隔开,将来会按照shortcutFieldOrder()方法返回的参数顺序依次复制上面这种配置方式参数必须严格按照shortcutFieldOrder()方法的返回参数名顺序来赋值。
还有一种用法,无需按照这个顺序,就是手动指定参数名:
spring:
cloud:
gateway:
default-filters:
- name: PrintAny
args: # 手动指定参数名,无需按照参数顺序
a: 1
b: 2
c: 3实现登录校验
复制所需内容
创建登录过滤器
package com.hmall.gateway.filters;
import java.util.List;
import javax.annotation.Resource;
import com.hmall.common.exception.UnauthorizedException;
import org.springframework.boot.context.properties.EnableConfigurationProperties;
import org.springframework.cloud.gateway.filter.GatewayFilterChain;
import org.springframework.cloud.gateway.filter.GlobalFilter;
import org.springframework.core.Ordered;
import org.springframework.http.HttpStatus;
import org.springframework.http.server.reactive.ServerHttpRequest;
import org.springframework.http.server.reactive.ServerHttpResponse;
import org.springframework.stereotype.Component;
import org.springframework.util.AntPathMatcher;
import org.springframework.web.server.ServerWebExchange;
import com.hmall.gateway.config.AuthProperties;
import com.hmall.gateway.utils.JwtTool;
import reactor.core.publisher.Mono;
/**
* @author:CharmingDaiDai
* @project:hmall @since:2024/5/22 下午3:08
*/
@Component
@EnableConfigurationProperties(AuthProperties.class)
public class AuthGlobalFilter implements GlobalFilter, Ordered {
@Resource
private AuthProperties authProperties;
@Resource
private JwtTool jwtTool;
private AntPathMatcher antPathMatcher = new AntPathMatcher();
@Override
public Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) {
// 获取request
ServerHttpRequest request = exchange.getRequest();
// System.out.println("request.getPath().toString() = " + request.getPath().toString());
// 判断是否需要拦截
if (isExclude(request.getPath().toString())) {
// 放行
return chain.filter(exchange);
}
// 获取token
String token = null;
List<String> headers = request.getHeaders().get("Authorization");
if (headers != null && !headers.isEmpty()) {
token = headers.get(0);
}
Long userId = null;
// 校验并解析token
try {
userId = jwtTool.parseToken(token);
} catch (UnauthorizedException e) {
ServerHttpResponse response = exchange.getResponse();
response.setStatusCode(HttpStatus.UNAUTHORIZED);
return response.setComplete();
}
// TODO 传递用户信息
System.out.println("userId = " + userId);
// 放行
return chain.filter(exchange);
}
private boolean isExclude(String path) {
for (String pathPattern : authProperties.getExcludePaths()) {
if (antPathMatcher.match(pathPattern, path)){
return true;
}
}
return false;
}
@Override
public int getOrder() {
return 0;
}
}配置
server:
port: 8080
spring:
application:
name: gateway
cloud:
nacos:
server-addr: 127.0.0.1:8848
gateway:
routes:
- id: item # 路由规则id,自定义,唯一
uri: lb://item-service # 路由的目标服务,lb代表负载均衡,会从注册中心拉取服务列表
predicates: # 路由断言,判断当前请求是否符合当前规则,符合则路由到目标服务
- Path=/items/**,/search/** # 这里是以请求路径作为判断规则
- id: cart
uri: lb://cart-service
predicates:
- Path=/carts/**
- id: user
uri: lb://user-service
predicates:
- Path=/users/**,/addresses/**
- id: trade
uri: lb://trade-service
predicates:
- Path=/orders/**
- id: pay
uri: lb://pay-service
predicates:
- Path=/pay-orders/**
hm:
jwt:
location: classpath:hmall.jks
alias: hmall
password: hmall123
tokenTTL: 30m
auth:
excludePaths:
- /search/**
- /users/login
- /items/**
- /hi
# keytool -genkeypair -alias hmall -keyalg RSA -keypass hmall123 -keystore hmall.jks -storepass hmall123微服务获取用户
现在,网关已经可以完成登录校验并获取登录用户身份信息。但是当网关将请求转发到微服务时,微服务又该如何获取用户身份呢?
由于网关发送请求到微服务依然采用的是Http请求,因此可以将用户信息以请求头的方式传递到下游微服务。然后微服务可以从请求头中获取登录用户信息。考虑到微服务内部可能很多地方都需要用到登录用户信息,因此可以利用SpringMVC的拦截器来实现登录用户信息获取,并存入ThreadLocal,方便后续使用。
据图流程图如下:
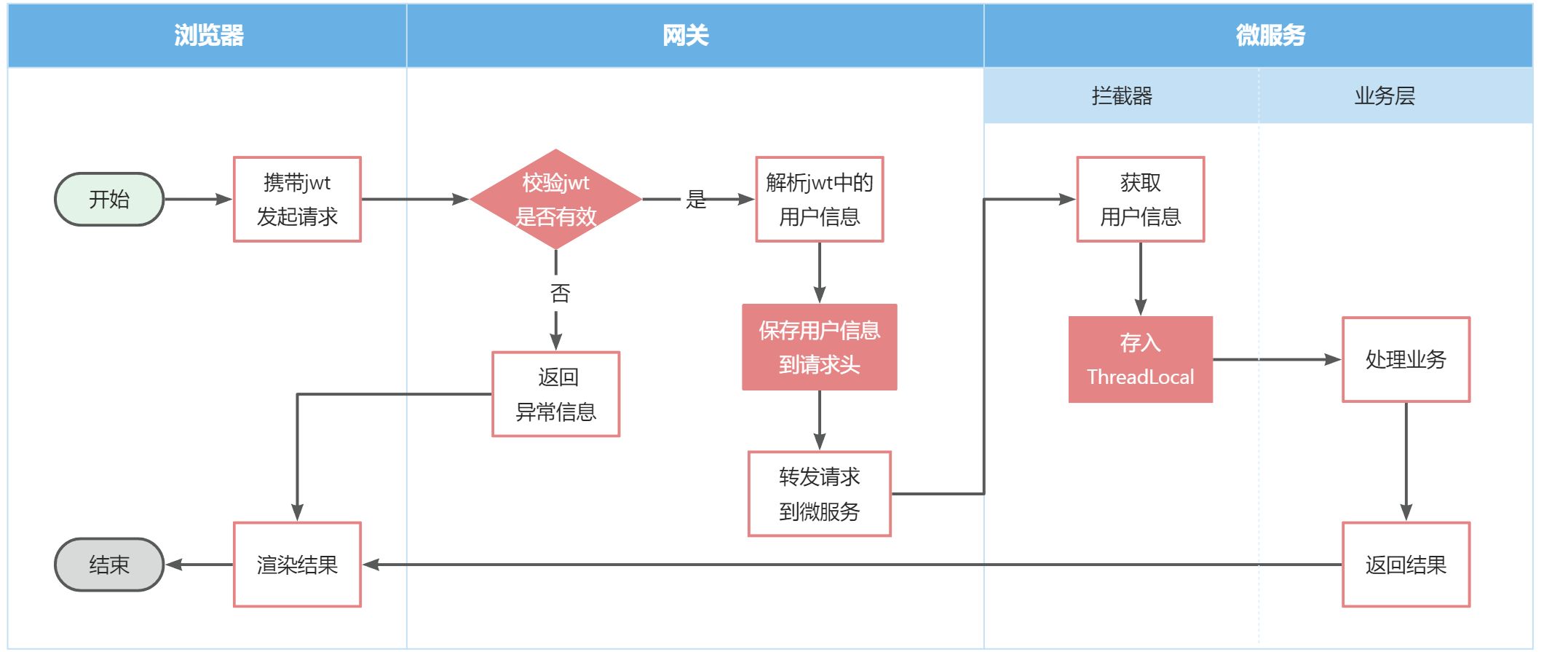
因此,接下来要做的事情有:
- 改造网关过滤器,在获取用户信息后保存到请求头,转发到下游微服务
- 编写微服务拦截器,拦截请求获取用户信息,保存到ThreadLocal后放行
保存用户到请求头
修改登录校验拦截器的处理逻辑,保存用户信息到请求头中:
// 传递用户信息
String userInfo = userId.toString();
exchange.mutate()
.request(builder -> builder.header("user-info", userInfo))
.build();拦截器获取用户
在hm-common中已经有一个用于保存登录用户的ThreadLocal工具:
其中已经提供了保存和获取用户的方法:
package com.hmall.common.utils;
public class UserContext {
private static final ThreadLocal<Long> tl = new ThreadLocal<>();
/**
* 保存当前登录用户信息到ThreadLocal
* @param userId 用户id
*/
public static void setUser(Long userId) {
tl.set(userId);
}
/**
* 获取当前登录用户信息
* @return 用户id
*/
public static Long getUser() {
return tl.get();
}
/**
* 移除当前登录用户信息
*/
public static void removeUser(){
tl.remove();
}
}只需要编写拦截器,获取用户信息并保存到UserContext,然后放行即可。
由于每个微服务都有获取登录用户的需求,因此拦截器直接写在hm-common中,并写好自动装配。这样微服务只需要引入hm-common就可以直接具备拦截器功能,无需重复编写。
在hm-common模块下定义一个拦截器:
package com.hmall.common.interceptor;
import cn.hutool.core.util.StrUtil;
import com.hmall.common.utils.UserContext;
import org.springframework.web.servlet.HandlerInterceptor;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
/**
* @author:CharmingDaiDai
* @project:hmall
* @since:2024/5/22 下午3:52
*/
public class UserInfoInterceptor implements HandlerInterceptor {
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
// 1.获取请求头中的用户信息
String userInfo = request.getHeader("user-info");
// 2.判断是否为空
if (StrUtil.isNotBlank(userInfo)) {
// 不为空,保存到ThreadLocal
UserContext.setUser(Long.valueOf(userInfo));
}
// 3.放行
return true;
}
@Override
public void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, Exception ex) throws Exception {
// 移除用户
UserContext.removeUser();
}
}在hm-common模块下编写SpringMVC的配置类,配置登录拦截器:
package com.hmall.common.config;
import com.hmall.common.interceptor.UserInfoInterceptor;
import org.springframework.boot.autoconfigure.condition.ConditionalOnClass;
import org.springframework.context.annotation.Configuration;
import org.springframework.web.servlet.DispatcherServlet;
import org.springframework.web.servlet.config.annotation.InterceptorRegistry;
import org.springframework.web.servlet.config.annotation.WebMvcConfigurer;
/**
* @author:CharmingDaiDai
* @project:hmall
* @since:2024/5/22 下午3:53
*/
@Configuration
@ConditionalOnClass(DispatcherServlet.class)
// WebMvcConfigurer属于SpringMVC包下的
// 网关底层不是SpringMVC,希望配置在网关不要生效
// DispatcherServlet.class是SpringMVC核心API
// 网关没有SpringMVC,所以不生效
public class MvcConfig implements WebMvcConfigurer {
@Override
public void addInterceptors(InterceptorRegistry registry) {
registry.addInterceptor(new UserInfoInterceptor());
}
}不过,需要注意的是,这个配置类默认是不会生效的,因为它所在的包是com.hmall.common.config,与其它微服务的扫描包不一致,无法被扫描到,因此无法生效。
基于SpringBoot的自动装配原理,要将其添加到resources目录下的META-INF/spring.factories文件中:
org.springframework.boot.autoconfigure.EnableAutoConfiguration=\
com.hmall.common.config.MyBatisConfig,\
com.hmall.common.config.MvcConfig,\
com.hmall.common.config.JsonConfigOpenFeign传递用户信息
微服务之间的用户传递
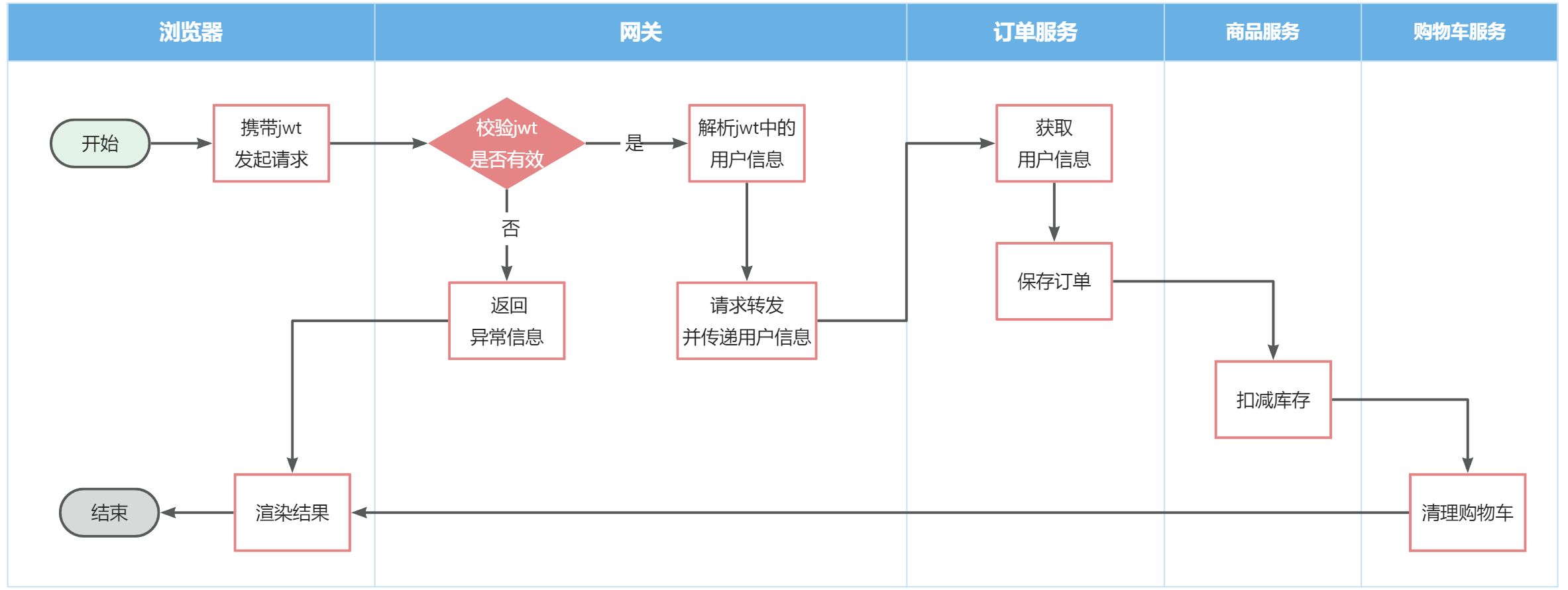
微服务之间调用是基于OpenFeign来实现的,并不是自己发送的请求。如何才能让每一个由OpenFeign发起的请求自动携带登录用户信息呢?
这里要借助Feign中提供的一个拦截器接口:feign.RequestInterceptor
public interface RequestInterceptor {
/**
* Called for every request.
* Add data using methods on the supplied {@link RequestTemplate}.
*/
void apply(RequestTemplate template);
}只需要实现这个接口,然后实现apply方法,利用RequestTemplate类来添加请求头,将用户信息保存到请求头中。这样以来,每次OpenFeign发起请求的时候都会调用该方法,传递用户信息。
由于FeignClient全部都是在hm-api模块,因此在hm-api模块的com.hmall.api.config.DefaultFeignConfig中编写这个拦截器:
在com.hmall.api.config.DefaultFeignConfig中添加一个Bean:
package com.hmall.api.config;
/**
* @author:CharmingDaiDai
* @project:hmall
* @since:2024/5/21 下午12:49
*/
import com.hmall.common.utils.UserContext;
import feign.Logger;
import feign.RequestInterceptor;
import feign.RequestTemplate;
import org.springframework.context.annotation.Bean;
public class DefaultFeignConfig {
@Bean
public Logger.Level feignLogLevel(){
return Logger.Level.BASIC;
}
@Bean
public RequestInterceptor userInfoRequestInterceptor(){
return new RequestInterceptor() {
@Override
public void apply(RequestTemplate requestTemplate) {
Long userId = UserContext.getUser();
if(userId != null){
requestTemplate.header("userId", String.valueOf(userId));
}
}
};
}
}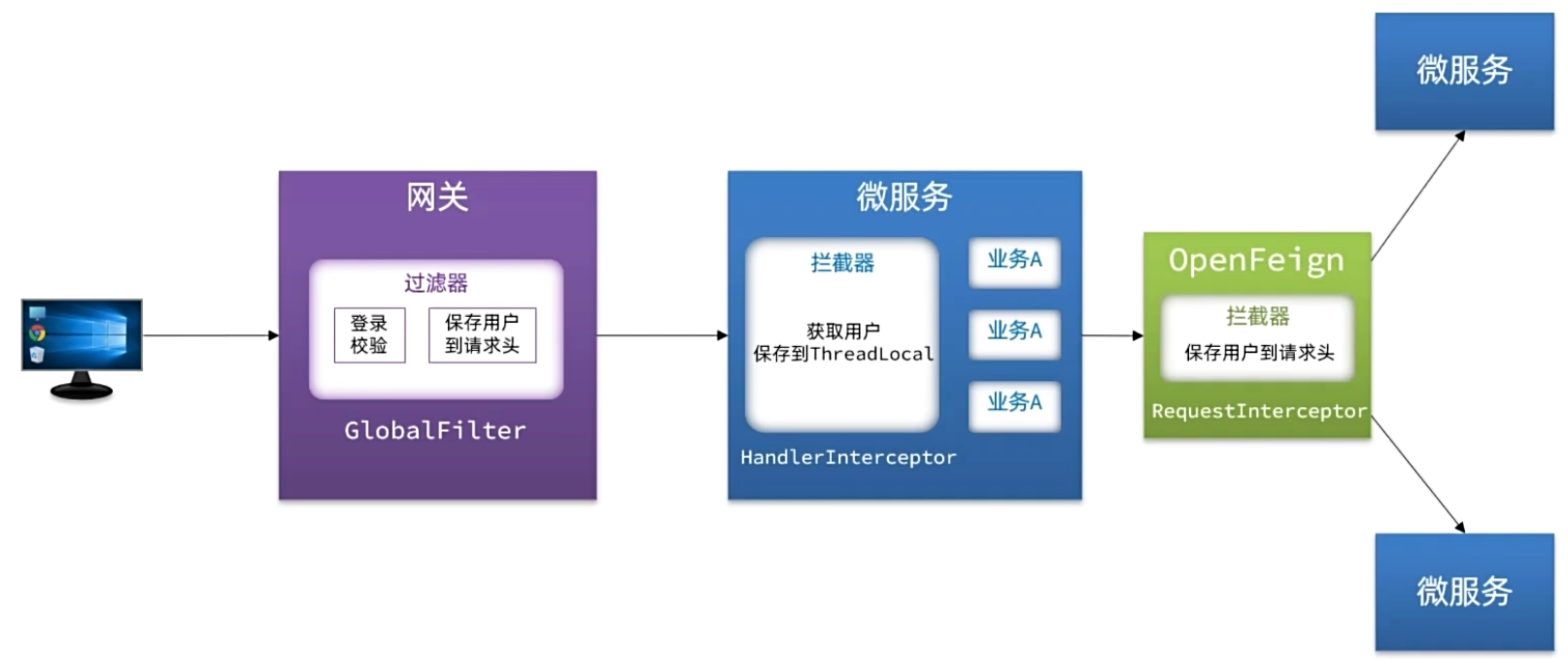
获取id
获取请求头@RequestHeader(value = "userId") Long userId
@PutMapping("/money/deduct")
public void deductMoney(@RequestParam("pw") String pw,@RequestParam("amount") Integer amount, @RequestHeader(value = "userId") Long userId){
userService.deductMoney(pw, amount, userId);
}
配置管理
几个问题需要解决:
- 网关路由在配置文件中写死了,如果变更必须重启微服务
- 某些业务配置在配置文件中写死了,每次修改都要重启服务
- 每个微服务都有很多重复的配置,维护成本高
Nacos不仅仅具备注册中心功能,也具备配置管理的功能:
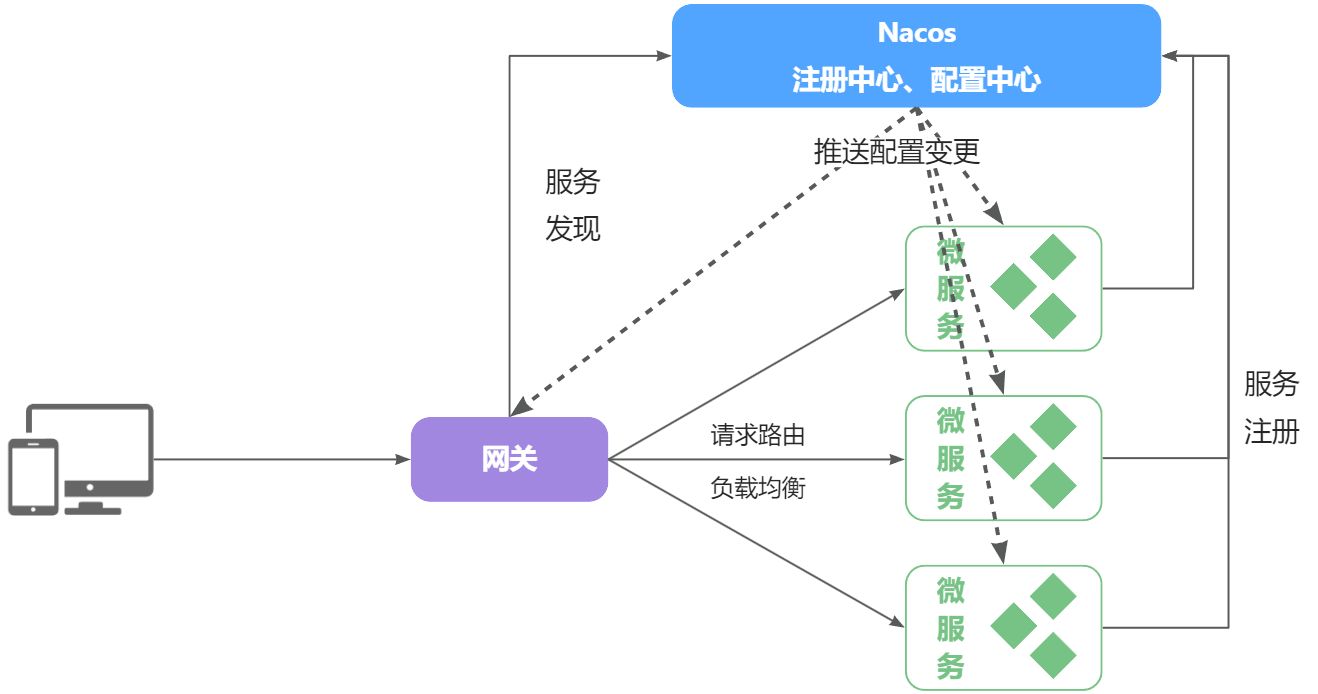
微服务共享的配置可以统一交给Nacos保存和管理,在Nacos控制台修改配置后,Nacos会将配置变更推送给相关的微服务,并且无需重启即可生效,实现配置热更新。
网关的路由同样是配置,因此同样可以基于这个功能实现动态路由功能,无需重启网关即可修改路由配置。
配置共享
添加共享配置
以cart-service为例,抽取重复的配置:
首先是jdbc相关配置:
日志配置:
swagger:
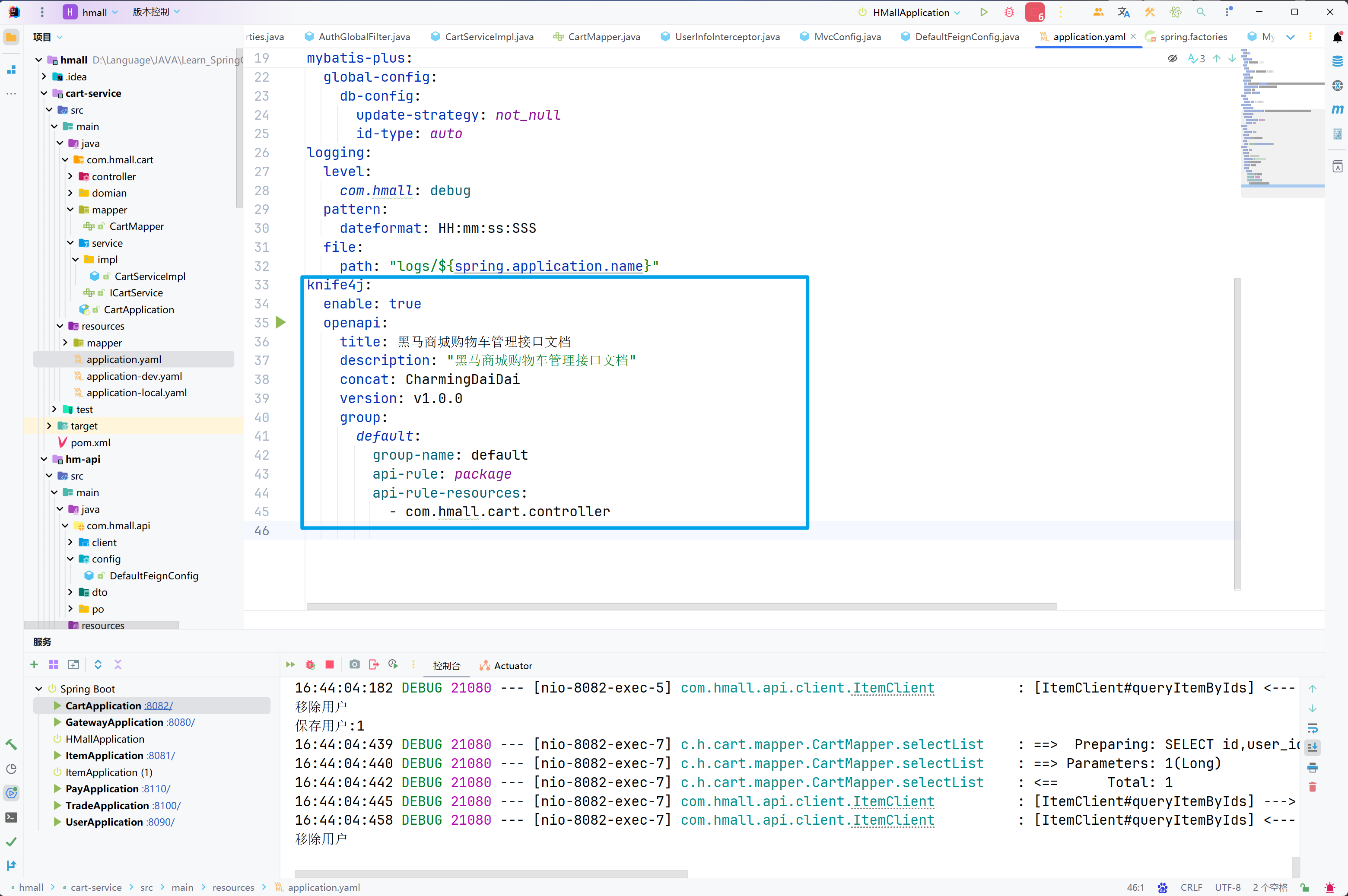
OpenFeign的配置:
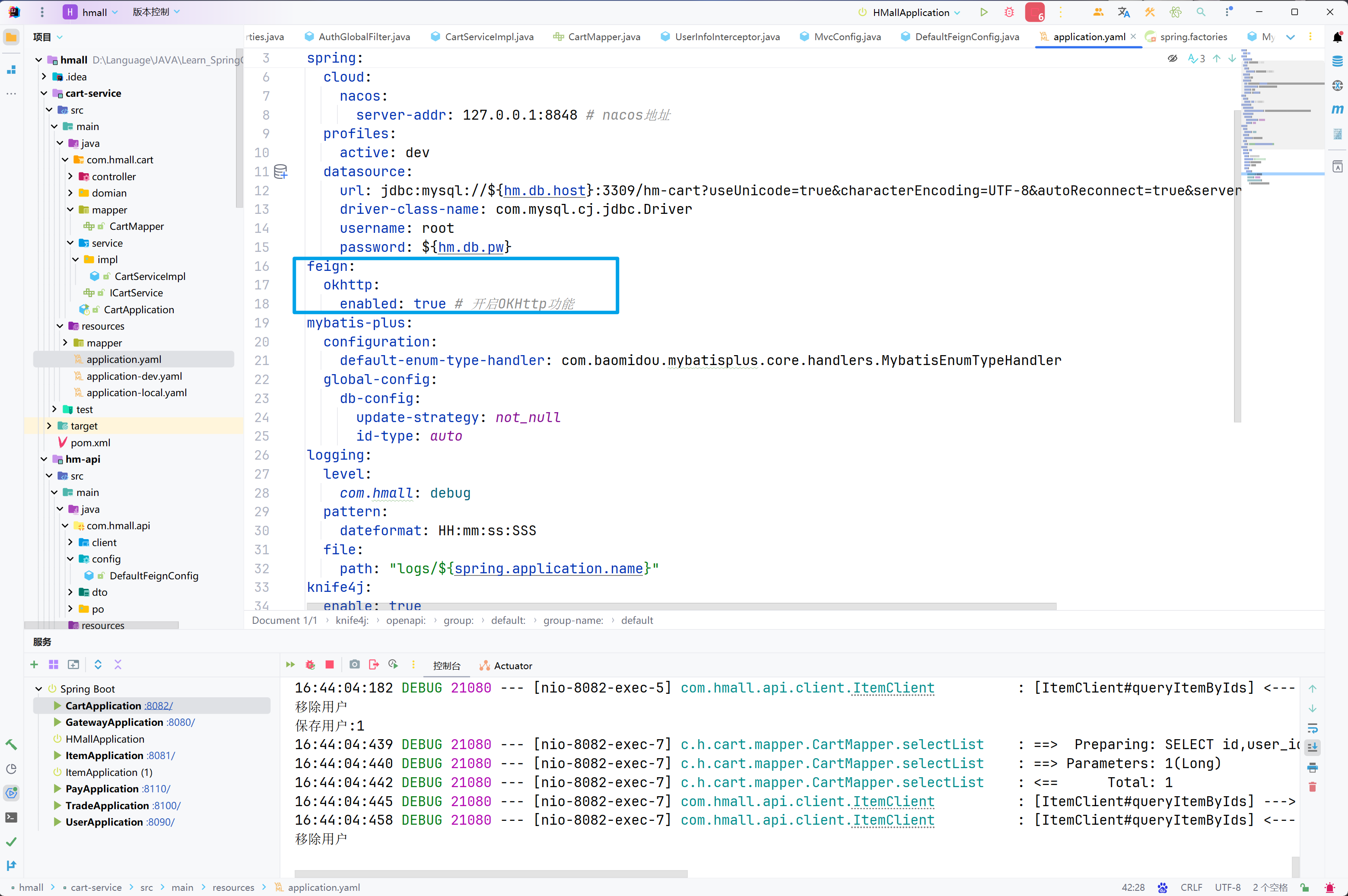
在OpenFeign中添加配置
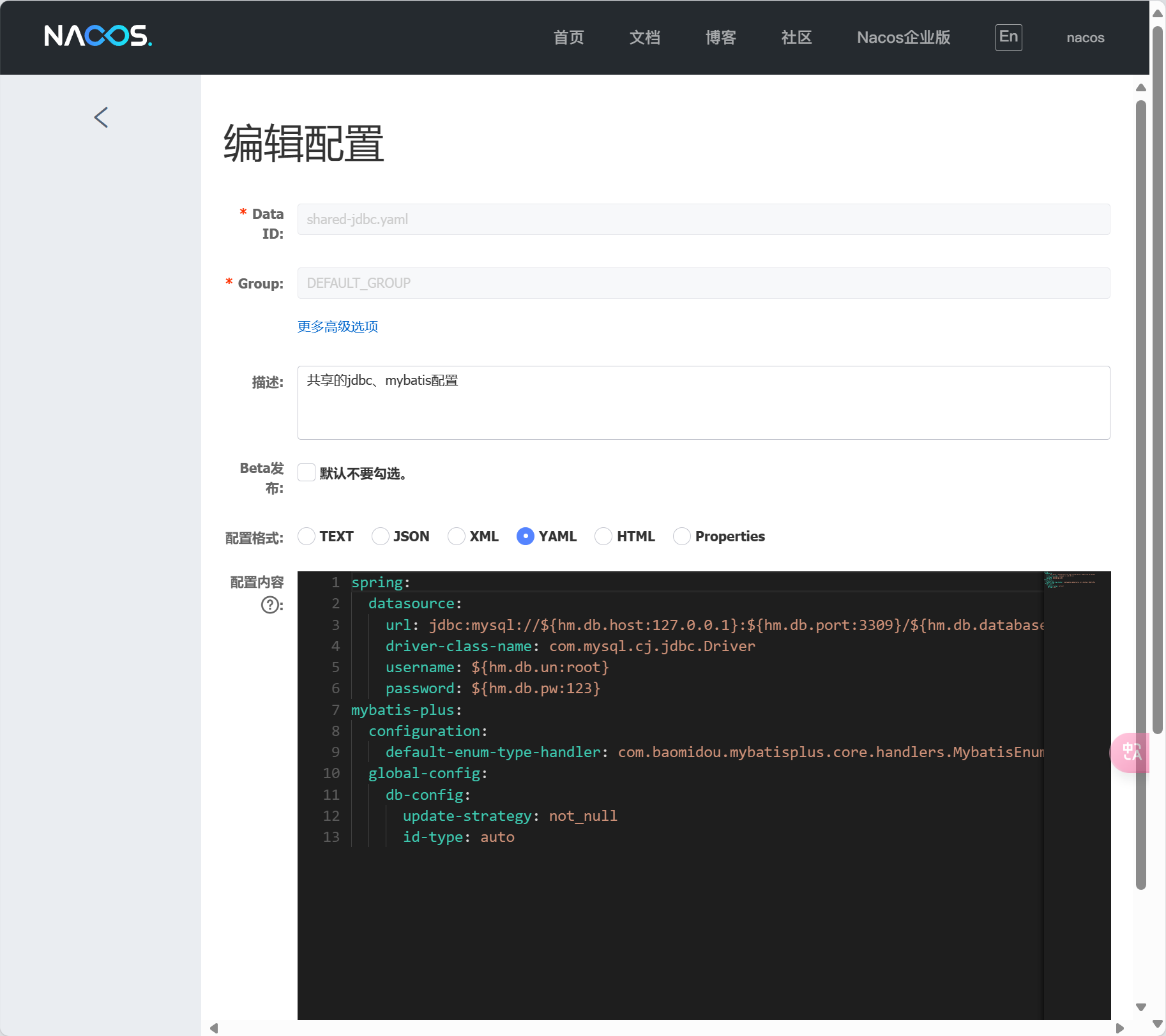
spring:
datasource:
url: jdbc:mysql://${hm.db.host:127.0.0.1}:${hm.db.port:3309}/${hm.db.database}?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true&serverTimezone=Asia/Shanghai
driver-class-name: com.mysql.cj.jdbc.Driver
username: ${hm.db.un:root}
password: ${hm.db.pw:123}
mybatis-plus:
configuration:
default-enum-type-handler: com.baomidou.mybatisplus.core.handlers.MybatisEnumTypeHandler
global-config:
db-config:
update-strategy: not_null
id-type: auto这里的jdbc的相关参数并没有写死,例如:
数据库ip:通过${hm.db.host:127.0.0.1}配置了默认值为127.0.0.1,同时允许通过${hm.db.host}来覆盖默认值数据库端口:通过${hm.db.port:3309}配置了默认值为3309,同时允许通过${hm.db.port}来覆盖默认值数据库database:可以通过${hm.db.database}来设定,无默认值
统一的日志配置,命名为shared-log.yaml,配置内容如下:
logging:
level:
com.hmall: debug
pattern:
dateformat: HH:mm:ss:SSS
file:
path: "logs/${spring.application.name}"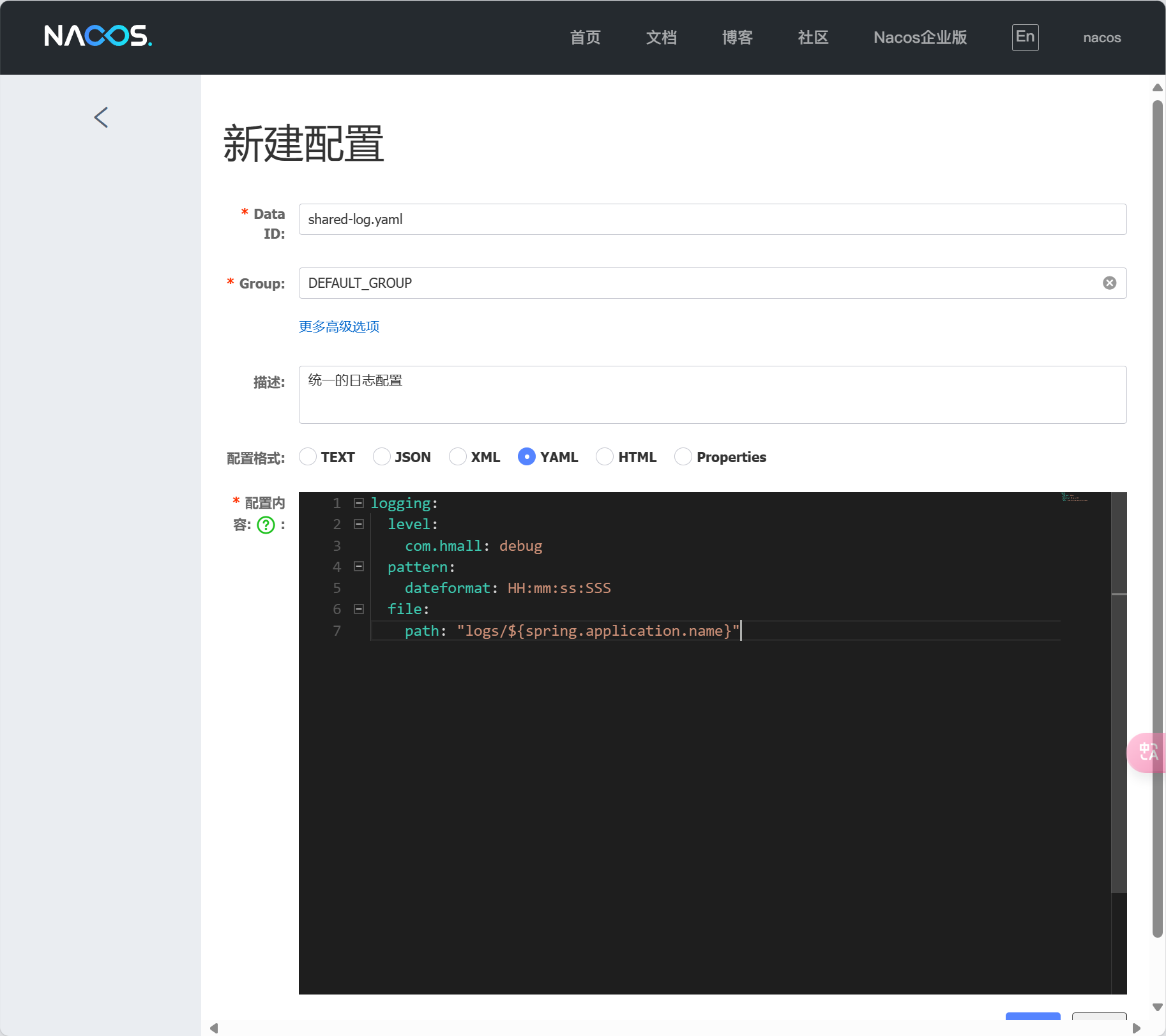
统一的swagger配置,命名为shared-swagger.yaml,配置内容如下:
knife4j:
enable: true
openapi:
title: ${hm.swagger.title:黑马商城接口文档}
description: ${hm.swagger.description:黑马商城接口文档}
email: ${hm.swagger.email:[email protected]}
concat: ${hm.swagger.concat:cdd}
url: https://www.itcast.cn
version: v1.0.0
group:
default:
group-name: default
api-rule: package
api-rule-resources:
- ${hm.swagger.package}注意,这里的swagger相关配置没有写死,例如:
title:接口文档标题,用了${hm.swagger.title}来代替,将来可以有用户手动指定email:联系人邮箱,用了${hm.swagger.email:``[email protected]``},默认值是[email protected],同时允许用户利用${hm.swagger.email}来覆盖。
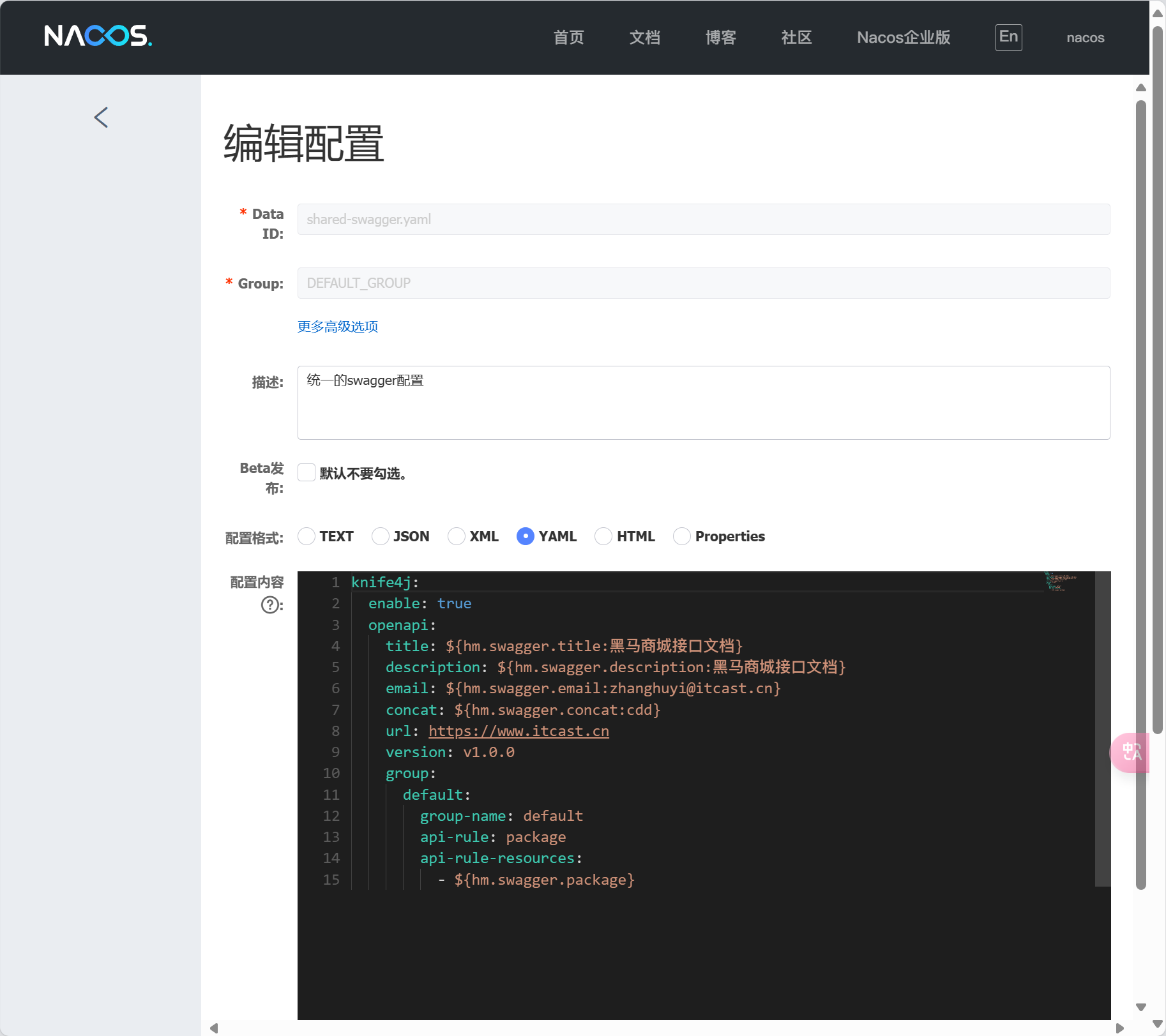
拉取共享配置
将拉取到的共享配置与本地的application.yaml配置合并,完成项目上下文的初始化。
不过,需要注意的是,读取Nacos配置是SpringCloud上下文(ApplicationContext)初始化时处理的,发生在项目的引导阶段。然后才会初始化SpringBoot上下文,去读取application.yaml。
也就是说引导阶段,application.yaml文件尚未读取,根本不知道nacos 地址,该如何去加载nacos中的配置文件呢?
SpringCloud在初始化上下文的时候会先读取一个名为bootstrap.yaml(或者bootstrap.properties)的文件,如果将nacos地址配置到bootstrap.yaml中,那么在项目引导阶段就可以读取nacos中的配置了。
因此,微服务整合Nacos配置管理的步骤如下:
引入依赖:
在cart-service模块引入依赖:
<!--nacos配置管理-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-config</artifactId>
</dependency>
<!--读取bootstrap文件-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-bootstrap</artifactId>
</dependency>新建bootstrap.yaml
在cart-service中的resources目录新建一个bootstrap.yaml文件:
spring:
application:
name: cart-service # 服务名称
profiles:
active: dev
cloud:
nacos:
server-addr: 127.0.0.1:8848 # nacos地址
config:
file-extension: yaml # 文件后缀名
shared-configs: # 共享配置
- dataId: shared-jdbc.yaml # 共享mybatis配置
- dataId: shared-log.yaml # 共享日志配置
- dataId: shared-swagger.yaml # 共享日志配置修改application.yaml
由于一些配置挪到了bootstrap.yaml,因此application.yaml需要修改为:
server:
port: 8082
feign:
okhttp:
enabled: true # 开启OKHttp连接池支持
hm:
swagger:
title: 购物车服务接口文档
package: com.hmall.cart.controller
db:
database: hm-cart配置热更新
有很多的业务相关参数,将来可能会根据实际情况临时调整。例如购物车业务,购物车数量有一个上限,默认是10,对应代码如下:
private void checkCartsFull(Long userId) {
int count = lambdaQuery().eq(Cart::getUserId, userId).count();
if (count >= 10) {
throw new BizIllegalException(StrUtil.format("用户购物车课程不能超过{}", 10));
}
}Nacos的配置热更新能力了,分为两步:
- 在Nacos中添加配置
- 在微服务读取配置
添加配置到Nacos
文件名称由三部分组成:
服务名:是购物车服务,所以是cart-servicespring.active.profile:就是spring boot中的spring.active.profile,可以省略,则所有profile共享该配置后缀名:例如yaml
hm:
cart:
maxAmount: 1 # 购物车商品数量上限注意文件的dataId格式:
[服务名]-[spring.active.profile].[后缀名]微服务会自动拉取这类配置,因此无需在bootstrap中配置
配置热更新
在cart-service中新建一个属性读取类:
在业务中使用该属性加载类:
private final CartProperties cartProperties;
private void checkCartsFull(Long userId) {
int count = lambdaQuery().eq(Cart::getUserId, userId).count();
if (count >= cartProperties.getMaxAmount()) {
throw new BizIllegalException(StrUtil.format("用户购物车课程不能超过{}", cartProperties.getMaxAmount()));
}
}重启服务,添加购物车
修改配置
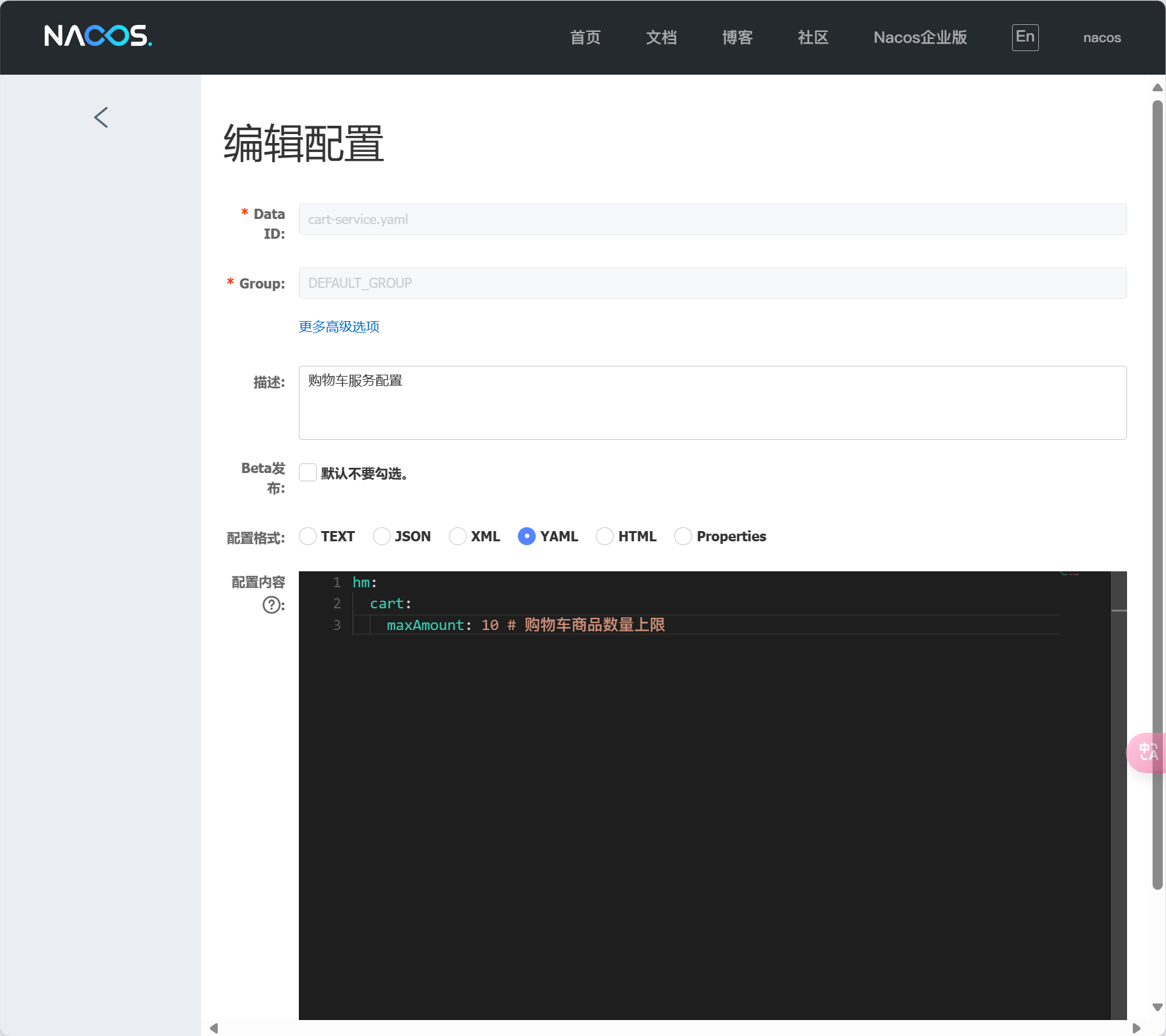
再次添加购物车可以成功
动态路由
监听Nacos配置变更
网关的路由配置全部是在项目启动时由org.springframework.cloud.gateway.route.CompositeRouteDefinitionLocator在项目启动的时候加载,并且一经加载就会缓存到内存中的路由表内(一个Map),不会改变。也不会监听路由变更,所以,无法利用上节课学习的配置热更新来实现路由更新。
必须监听Nacos的配置变更,然后手动把最新的路由更新到路由表中。这里有两个难点:
- 如何监听Nacos配置变更?
- 如何把路由信息更新到路由表?
如果希望 Nacos 推送配置变更,可以使用 Nacos 动态监听配置接口来实现。
public void addListener(String dataId, String group, Listener listener)请求参数说明:
| 参数名 | 参数类型 | 描述 |
|---|---|---|
| dataId | string | 配置 ID,保证全局唯一性,只允许英文字符和 4 种特殊字符("."、":"、"-"、"_")。不超过 256 字节。 |
| group | string | 配置分组,一般是默认的DEFAULT_GROUP。 |
| listener | Listener | 监听器,配置变更进入监听器的回调函数。 |
示例代码:
String serverAddr = "{serverAddr}";
String dataId = "{dataId}";
String group = "{group}";
// 1.创建ConfigService,连接Nacos
Properties properties = new Properties();
properties.put("serverAddr", serverAddr);
ConfigService configService = NacosFactory.createConfigService(properties);
// 2.读取配置
String content = configService.getConfig(dataId, group, 5000);
// 3.添加配置监听器
configService.addListener(dataId, group, new Listener() {
@Override
public void receiveConfigInfo(String configInfo) {
// 配置变更的通知处理
System.out.println("recieve1:" + configInfo);
}
@Override
public Executor getExecutor() {
return null;
}
});这里核心的步骤有2步:
- 创建ConfigService,目的是连接到Nacos
- 添加配置监听器,编写配置变更的通知处理逻辑
由于采用了spring-cloud-starter-alibaba-nacos-config自动装配,因此ConfigService已经在com.alibaba.cloud.nacos.NacosConfigAutoConfiguration中自动创建好了:
NacosConfigManager中是负责管理Nacos的ConfigService的,具体代码如下:
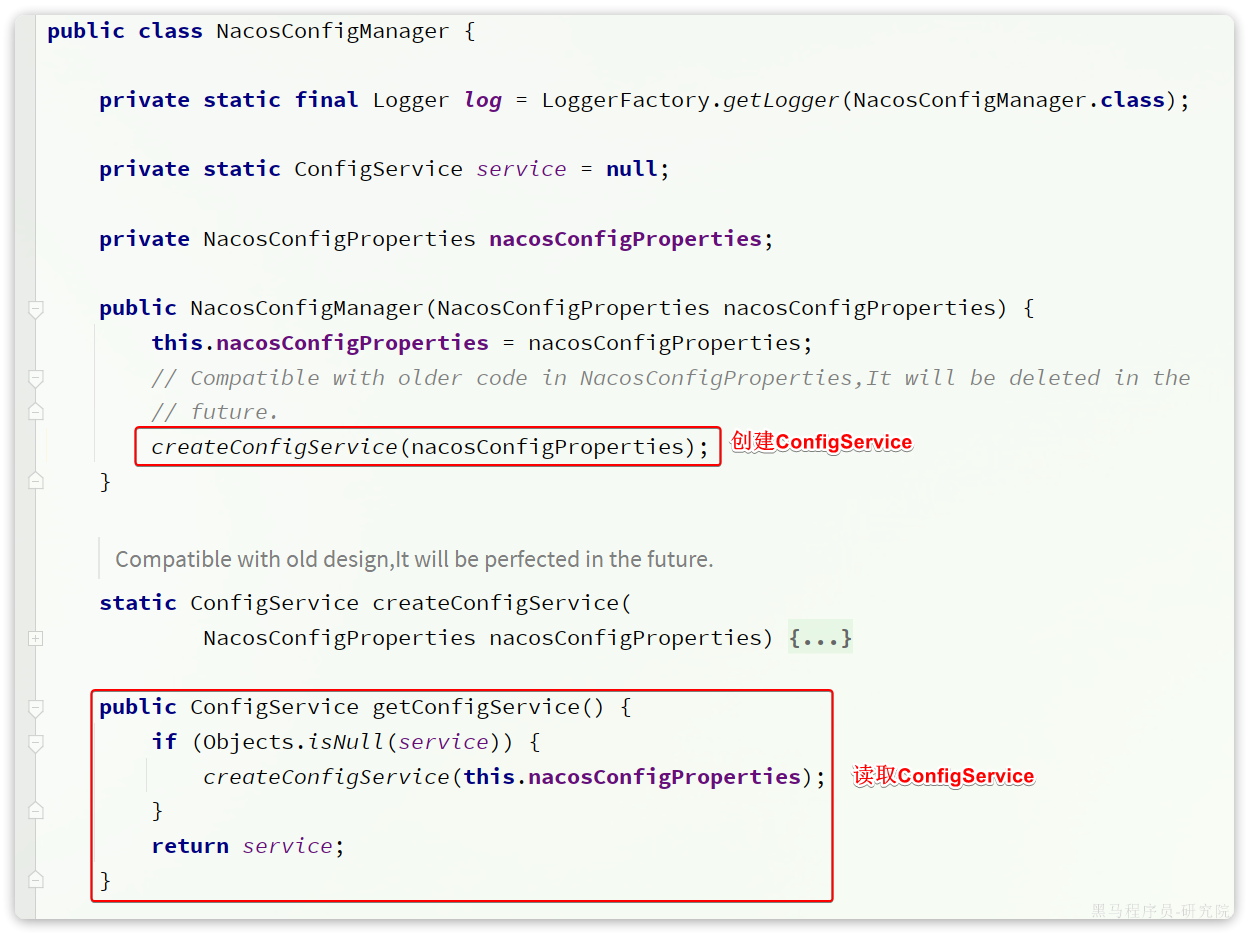
因此,只要拿到NacosConfigManager就等于拿到了ConfigService,第一步就实现了。
第二步,编写监听器。虽然官方提供的SDK是ConfigService中的addListener,不过项目第一次启动时不仅仅需要添加监听器,也需要读取配置,因此建议使用的API是这个:
String getConfigAndSignListener(
String dataId, // 配置文件id
String group, // 配置组,走默认
long timeoutMs, // 读取配置的超时时间
Listener listener // 监听器
) throws NacosException;既可以配置监听器,并且会根据dataId和group读取配置并返回。就可以在项目启动时先更新一次路由,后续随着配置变更通知到监听器,完成路由更新。
更新路由
更新路由要用到org.springframework.cloud.gateway.route.RouteDefinitionWriter这个接口:
package org.springframework.cloud.gateway.route;
import reactor.core.publisher.Mono;
/**
* @author Spencer Gibb
*/
public interface RouteDefinitionWriter {
/**
* 更新路由到路由表,如果路由id重复,则会覆盖旧的路由
*/
Mono<Void> save(Mono<RouteDefinition> route);
/**
* 根据路由id删除某个路由
*/
Mono<Void> delete(Mono<String> routeId);
}这里更新的路由,也就是RouteDefinition,包含下列常见字段:
- id:路由id
- predicates:路由匹配规则
- filters:路由过滤器
- uri:路由目的地
将来保存到Nacos的配置也要符合这个对象结构,将来以JSON来保存,格式如下:
{
"id": "item",
"predicates": [{
"name": "Path",
"args": {"_genkey_0":"/items/**", "_genkey_1":"/search/**"}
}],
"filters": [],
"uri": "lb://item-service"
}以上JSON配置就等同于:
spring:
cloud:
gateway:
routes:
- id: item
uri: lb://item-service
predicates:
- Path=/items/**,/search/**实现动态路由
在网关gateway引入依赖:
<!--统一配置管理-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-config</artifactId>
</dependency>
<!--加载bootstrap-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-bootstrap</artifactId>
</dependency>在网关gateway的resources目录创建bootstrap.yaml文件
spring:
application:
name: gateway # 服务名称
profiles:
active: dev
cloud:
nacos:
server-addr: 127.0.0.1:8848 # nacos地址
config:
file-extension: yaml # 文件后缀名
shared-configs: # 共享配置
- dataId: shared-log.yaml # 共享日志配置修改gateway的resources目录下的application.yml,把之前的路由移除
server:
port: 8080
hm:
jwt:
location: classpath:hmall.jks
alias: hmall
password: hmall123
tokenTTL: 30m
auth:
excludePaths:
- /search/**
- /users/login
- /items/**
- /hi
# keytool -genkeypair -alias hmall -keyalg RSA -keypass hmall123 -keystore hmall.jks -storepass hmall123在gateway中定义配置监听器
package com.hmall.gateway.routers;
import cn.hutool.json.JSONUtil;
import com.alibaba.cloud.nacos.NacosConfigManager;
import com.alibaba.nacos.api.config.listener.Listener;
import com.alibaba.nacos.api.exception.NacosException;
import com.hmall.common.utils.CollUtils;
import lombok.RequiredArgsConstructor;
import lombok.extern.slf4j.Slf4j;
import org.springframework.cloud.gateway.route.RouteDefinition;
import org.springframework.cloud.gateway.route.RouteDefinitionWriter;
import org.springframework.stereotype.Component;
import reactor.core.publisher.Mono;
import javax.annotation.PostConstruct;
import java.util.HashSet;
import java.util.List;
import java.util.Set;
import java.util.concurrent.Executor;
/**
* @author:CharmingDaiDai
* @project:hmall
* @since:2024/5/23 上午11:09
*/
@Slf4j
@Component
@RequiredArgsConstructor
public class DynamicRouteLoader {
private final RouteDefinitionWriter writer;
private final NacosConfigManager nacosConfigManager;
// 路由配置文件的id和分组
private final String dataId = "gateway-routes.json";
private final String group = "DEFAULT_GROUP";
// 保存更新过的路由id
private final Set<String> routeIds = new HashSet<>();
@PostConstruct
public void initRouteConfigListener() throws NacosException {
// 1.注册监听器并首次拉取配置
String configInfo = nacosConfigManager.getConfigService()
.getConfigAndSignListener(dataId, group, 5000, new Listener() {
@Override
public Executor getExecutor() {
return null;
}
@Override
public void receiveConfigInfo(String configInfo) {
updateConfigInfo(configInfo);
}
});
// 2.首次启动时,更新一次配置
updateConfigInfo(configInfo);
}
private void updateConfigInfo(String configInfo) {
log.debug("监听到路由配置变更,{}", configInfo);
// 1.反序列化
List<RouteDefinition> routeDefinitions = JSONUtil.toList(configInfo, RouteDefinition.class);
// 2.更新前先清空旧路由
// 2.1.清除旧路由
for (String routeId : routeIds) {
writer.delete(Mono.just(routeId)).subscribe();
}
routeIds.clear();
// 2.2.判断是否有新的路由要更新
if (CollUtils.isEmpty(routeDefinitions)) {
// 无新路由配置,直接结束
return;
}
// 3.更新路由
routeDefinitions.forEach(routeDefinition -> {
// 3.1.更新路由
writer.save(Mono.just(routeDefinition)).subscribe();
// 3.2.记录路由id,方便将来删除
routeIds.add(routeDefinition.getId());
});
}
}这段代码是一个Java类,用于动态加载和更新Spring Cloud Gateway的路由配置。下面是对代码中每一部分的详细解释:
包声明:
package com.hmall.gateway.routers;这行代码声明了这个类属于
com.hmall.gateway.routers包。导入必要的类:
import ... // 省略了其他导入这些导入语句引入了代码中使用到的类和接口。
类注释:
/** * @author:CharmingDaiDai * @project:hmall * @since:2024/5/23 上午11:09 */这是一个简单的注释,提供了作者、项目名称和创建时间。
类定义:
@Slf4j @Component @RequiredArgsConstructor public class DynamicRouteLoader { ... }@Slf4j:这是Lombok库提供的注解,用于自动为类生成日志对象。@Component:这是Spring框架的注解,表示这个类是一个Spring组件,会被Spring容器管理。@RequiredArgsConstructor:Lombok提供的注解,用于自动生成一个构造函数,包含所有final字段。
成员变量:
private final RouteDefinitionWriter writer; private final NacosConfigManager nacosConfigManager; private final String dataId = "gateway-routes.json"; private final String group = "DEFAULT_GROUP"; private final Set<String> routeIds = new HashSet<>();RouteDefinitionWriter:用于操作路由定义的Spring接口。NacosConfigManager:用于管理Nacos配置的类。dataId和group:标识Nacos中配置文件的ID和分组。routeIds:用于存储路由定义的ID集合。
初始化路由配置监听器:
@PostConstruct public void initRouteConfigListener() throws NacosException { ... }@PostConstruct:Spring注解,表示这个方法会在依赖注入完成后执行。
注册监听器并首次拉取配置:
String configInfo = nacosConfigManager.getConfigService() .getConfigAndSignListener(dataId, group, 5000, new Listener() {...}); ...- 注册一个监听器到Nacos配置服务,并设置超时时间为5000毫秒。
new Listener() {...}:创建一个新的监听器实例,重写receiveConfigInfo方法以处理配置信息变更。
首次启动时更新配置:
updateConfigInfo(configInfo);- 调用
updateConfigInfo方法来处理首次拉取的配置信息。
- 调用
更新配置信息:
private void updateConfigInfo(String configInfo) { ... }- 这个方法用于处理配置信息的变更。
反序列化配置信息:
List<RouteDefinition> routeDefinitions = JSONUtil.toList(configInfo, RouteDefinition.class);- 使用Hutool库的
JSONUtil类将JSON格式的配置信息反序列化为RouteDefinition列表。
- 使用Hutool库的
更新前清空旧路由:
for (String routeId : routeIds) { writer.delete(Mono.just(routeId)).subscribe(); } routeIds.clear();- 删除所有旧的路由定义,并清空
routeIds集合。
- 删除所有旧的路由定义,并清空
判断是否有新的路由要更新:
if (CollUtils.isEmpty(routeDefinitions)) { return; }- 如果没有新的路由定义,则直接返回。
更新路由:
routeDefinitions.forEach(routeDefinition -> { writer.save(Mono.just(routeDefinition)).subscribe(); routeIds.add(routeDefinition.getId()); });- 对于每个新的路由定义,使用
RouteDefinitionWriter保存它,并将其ID添加到routeIds集合中。
- 对于每个新的路由定义,使用
这个类的主要作用是监听Nacos配置中心中的路由配置文件的变更,并动态地更新Spring Cloud Gateway的路由配置。通过这种方式,可以在不重启服务的情况下,动态地调整路由规则。
重启网关,任意访问一个接口,比如 localhost:8080/items/page
接下来,直接在Nacos控制台添加路由,路由文件名为gateway-routes.json,类型为json
[
{
"id": "item",
"predicates": [{
"name": "Path",
"args": {"_genkey_0":"/items/**", "_genkey_1":"/search/**"}
}],
"filters": [],
"uri": "lb://item-service"
},
{
"id": "cart",
"predicates": [{
"name": "Path",
"args": {"_genkey_0":"/carts/**"}
}],
"filters": [],
"uri": "lb://cart-service"
},
{
"id": "user",
"predicates": [{
"name": "Path",
"args": {"_genkey_0":"/users/**", "_genkey_1":"/addresses/**"}
}],
"filters": [],
"uri": "lb://user-service"
},
{
"id": "trade",
"predicates": [{
"name": "Path",
"args": {"_genkey_0":"/orders/**"}
}],
"filters": [],
"uri": "lb://trade-service"
},
{
"id": "pay",
"predicates": [{
"name": "Path",
"args": {"_genkey_0":"/pay-orders/**"}
}],
"filters": [],
"uri": "lb://pay-service"
}
]发布后无需重启网关

微服务保护和分布式事务
home | Sentinel (sentinelguard.io)
雪崩问题
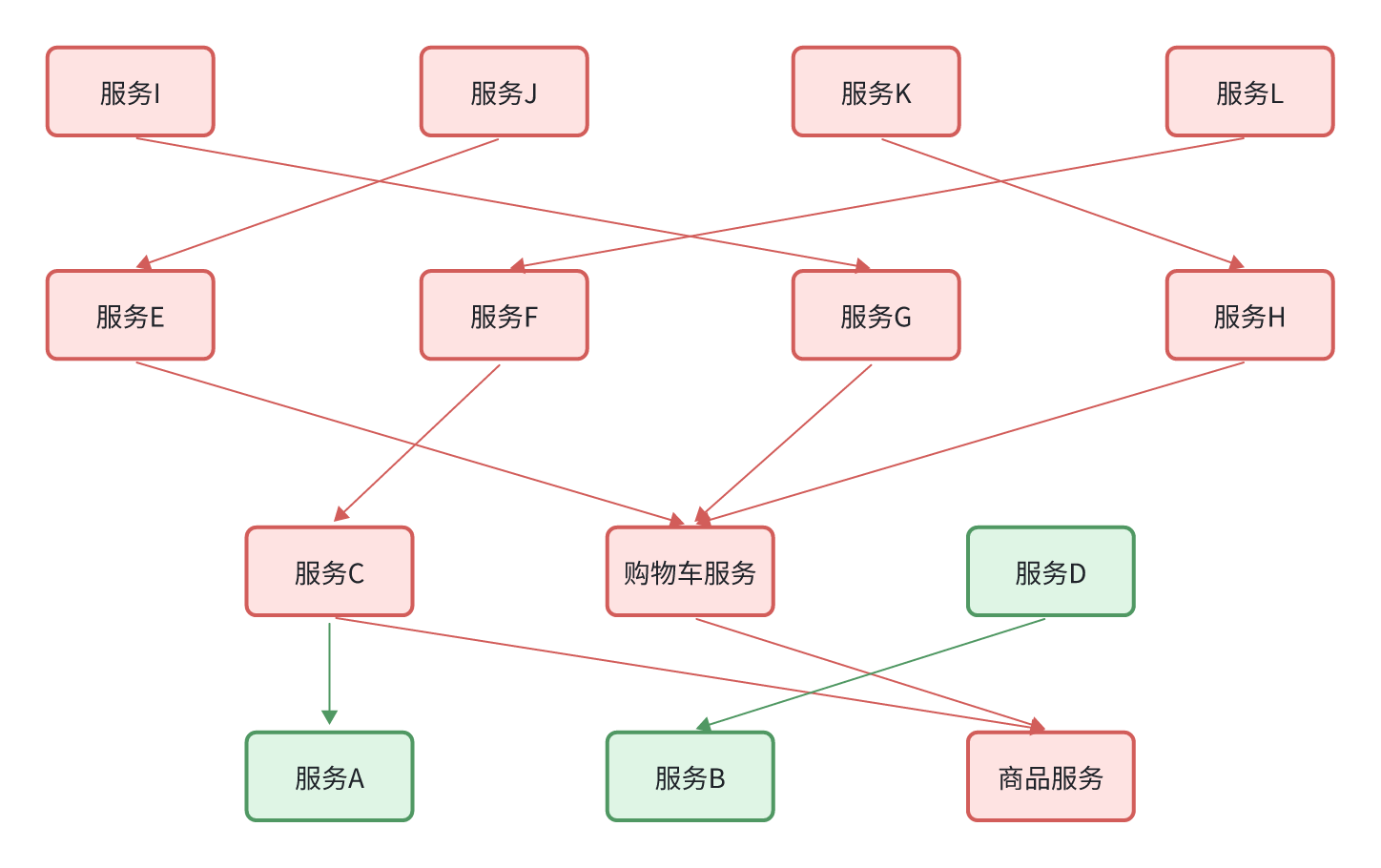
级联失败问题,或者叫雪崩问题:
商品服务业务并发较高,占用过多Tomcat连接。可能会导致商品服务的所有接口响应时间增加,延迟变高,甚至是长时间阻塞直至查询失败。
此时查询购物车业务需要查询并等待商品查询结果,从而导致查询购物车列表业务的响应时间也变长,甚至也阻塞直至无法访问。而此时如果查询购物车的请求较多,可能导致购物车服务的Tomcat连接占用较多,所有接口的响应时间都会增加,整个服务性能很差, 甚至不可用。
依次类推,整个微服务群中与购物车服务、商品服务等有调用关系的服务可能都会出现问题,最终导致整个集群不可用。
还有跨服务的事务问题:
比如下单业务,下单的过程中需要调用多个微服务:
- 商品服务:扣减库存
- 订单服务:保存订单
- 购物车服务:清理购物车
这些业务全部都是数据库的写操作,必须确保所有操作的同时成功或失败。但是这些操作在不同微服务,也就是不同的Tomcat,这样的情况如何确保事务特性呢?
微服务保护
微服务保护的方案有很多,比如:
- 请求限流
- 线程隔离
- 服务熔断
这些方案或多或少都会导致服务的体验上略有下降,比如请求限流,降低了并发上限;线程隔离,降低了可用资源数量;服务熔断,降低了服务的完整度,部分服务变的不可用或弱可用。因此这些方案都属于服务降级的方案。但通过这些方案,服务的健壮性得到了提升,
请求限流
服务故障最重要原因,就是并发太高!解决了这个问题,就能避免大部分故障。当然,接口的并发不是一直很高,而是突发的。因此请求限流,就是限制或控制接口访问的并发流量,避免服务因流量激增而出现故障。
请求限流往往会有一个限流器,数量高低起伏的并发请求曲线,经过限流器就变的非常平稳。这就像是水电站的大坝,起到蓄水的作用,可以通过开关控制水流出的大小,让下游水流始终维持在一个平稳的量。
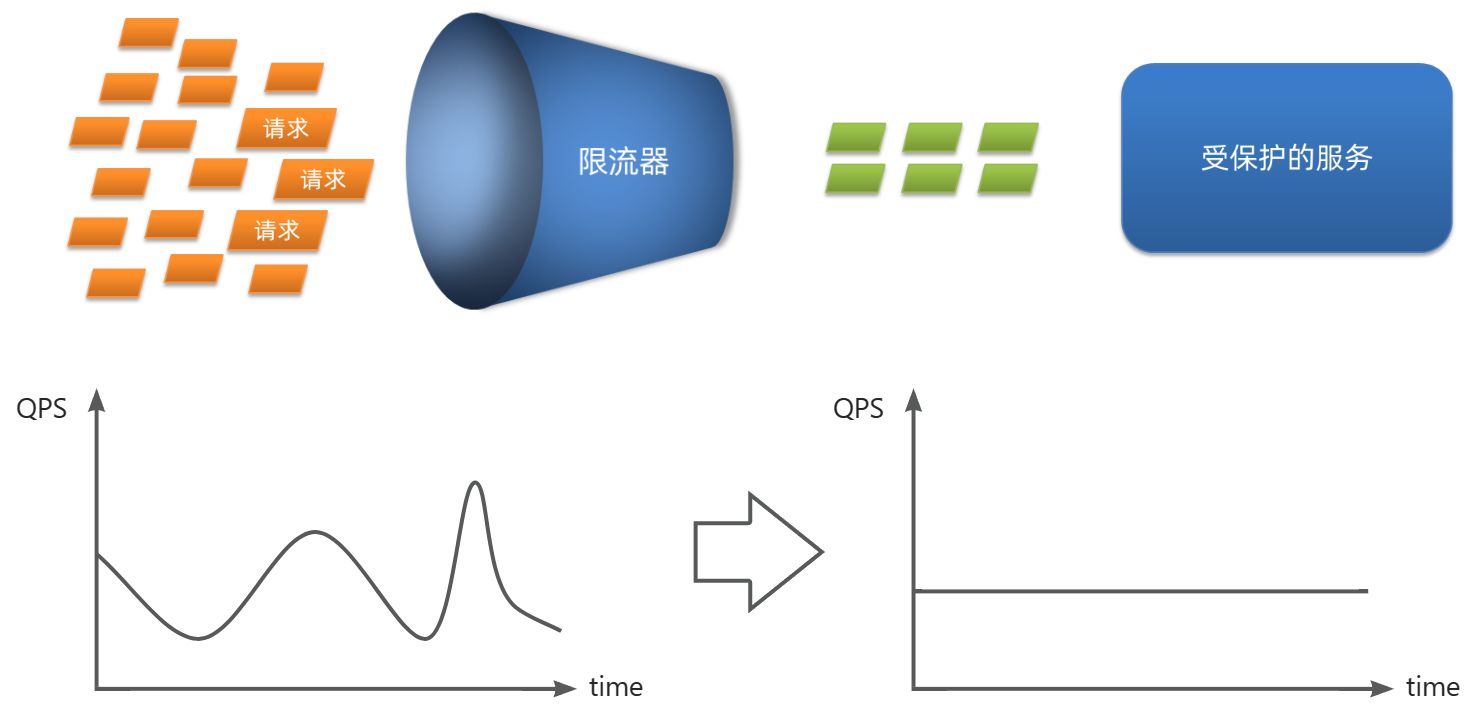
线程隔离
当一个业务接口响应时间长,而且并发高时,就可能耗尽服务器的线程资源,导致服务内的其它接口受到影响。所以必须把这种影响降低,或者缩减影响的范围。线程隔离正是解决这个问题的好办法。
线程隔离的思想来自轮船的舱壁模式:
轮船的船舱会被隔板分割为N个相互隔离的密闭舱,假如轮船触礁进水,只有损坏的部分密闭舱会进水,而其他舱由于相互隔离,并不会进水。这样就把进水控制在部分船体,避免了整个船舱进水而沉没。
为了避免某个接口故障或压力过大导致整个服务不可用,可以限定每个接口可以使用的资源范围,也就是将其“隔离”起来。
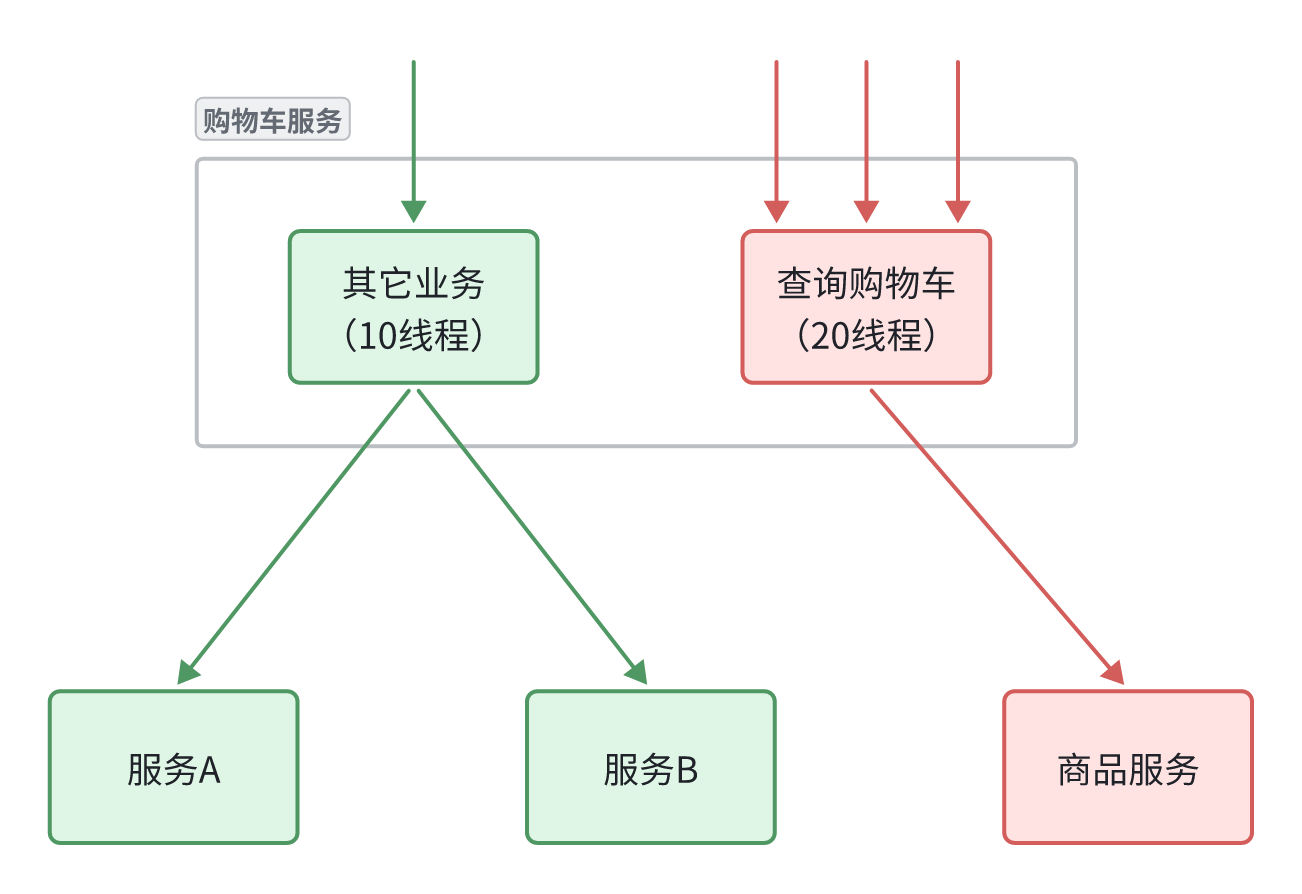
如图所示,给查询购物车业务限定可用线程数量上限为20,这样即便查询购物车的请求因为查询商品服务而出现故障,也不会导致服务器的线程资源被耗尽,不会影响到其它接口。
服务熔断
线程隔离虽然避免了雪崩问题,但故障服务(商品服务)依然会拖慢购物车服务(服务调用方)的接口响应速度。而且商品查询的故障依然会导致查询购物车功能出现故障,购物车业务也变的不可用了。
所以,要做两件事情:
- 编写服务降级逻辑:就是服务调用失败后的处理逻辑,根据业务场景,可以抛出异常,也可以返回友好提示或默认数据。
- 异常统计和熔断:统计服务提供方的异常比例,当比例过高表明该接口会影响到其它服务,应该拒绝调用该接口,而是直接走降级逻辑。
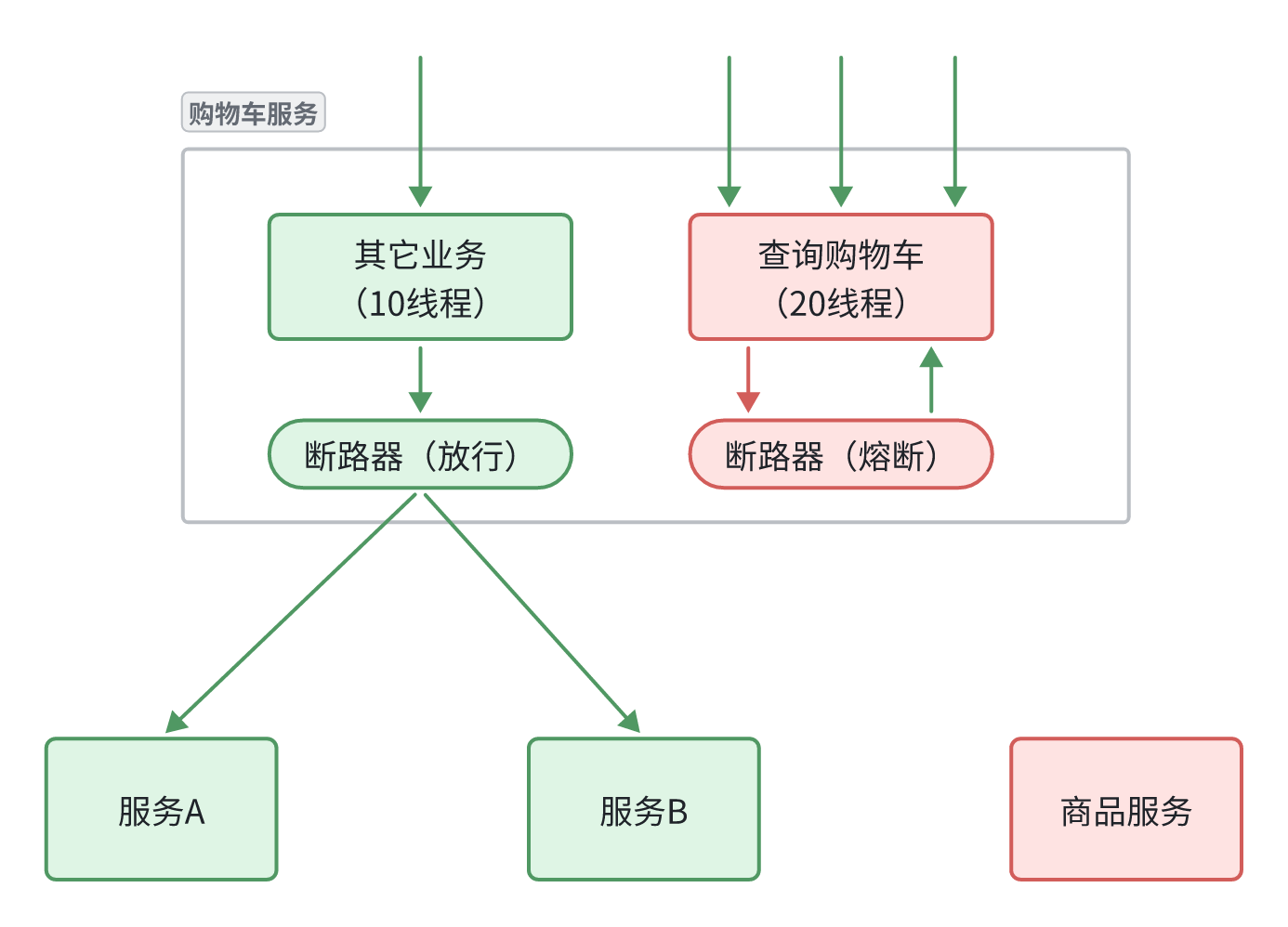
Sentinel
Sentinel是阿里巴巴开源的一款服务保护框架,目前已经加入SpringCloudAlibaba中
https://sentinelguard.io/zh-cn/
使用可以分为两个部分:
核心库(jar包)
不依赖任何框架/库,能够运行于 Java 8 及以上的版本的运行时环境,同时对 Dubbo / Spring Cloud 等框架也有较好的支持。在项目中引入依赖即可实现服务限流、隔离、熔断等功能。
控制台(Dashboard)
Dashboard 主要负责管理推送规则、监控、管理机器信息等。
下载jar包
Releases · alibaba/Sentinel (github.com)
将jar包放在任意非中文、不包含特殊字符的目录下,重命名为sentinel-dashboard.jar
运行命令启动控制台
java '-Dserver.port=8090' '-Dcsp.sentinel.dashboard.server=localhost:8090' '-Dproject.name=sentinel-dashboard' -jar sentinel-dashboard.jar
访问http://localhost:8090页面,就可以看到sentinel的控制台了:

账号密码都是sentinel

微服务整合
在cart-service模块中整合sentinel,连接sentinel-dashboard控制台
引入sentinel依赖
<!--sentinel-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-sentinel</artifactId>
</dependency>配置控制台
修改application.yaml文件,添加下面内容:
server:
port: 8082
feign:
okhttp:
enabled: true # 开启OKHttp连接池支持
hm:
swagger:
title: 购物车服务接口文档
desc: 购物车服务接口文档
package: com.hmall.cart.controller
db:
database: hm-cart
+🚩
spring:
cloud:
sentinel:
transport:
dashboard: localhost:8090访问cart-service的任意端点
重启cart-service,然后访问查询购物车接口,sentinel的客户端就会将服务访问的信息提交到sentinel-dashboard控制台。并展示出统计信息
所谓簇点链路,就是单机调用链路,是一次请求进入服务后经过的每一个被Sentinel监控的资源。默认情况下,Sentinel会监控SpringMVC的每一个Endpoint(接口)。
因此,看到/carts这个接口路径就是其中一个簇点,可以对其进行限流、熔断、隔离等保护措施。
不过,需要注意的是,的SpringMVC接口是按照Restful风格设计,因此购物车的查询、删除、修改等接口全部都是/carts路径
默认情况下Sentinel会把路径作为簇点资源的名称,无法区分路径相同但请求方式不同的接口,查询、删除、修改等都被识别为一个簇点资源,这显然是不合适的。
所以可以选择打开Sentinel的请求方式前缀,把请求方式 + 请求路径作为簇点资源名:
首先,在cart-service的application.yml中添加下面的配置:
server:
port: 8082
feign:
okhttp:
enabled: true # 开启OKHttp连接池支持
hm:
swagger:
title: 购物车服务接口文档
desc: 购物车服务接口文档
package: com.hmall.cart.controller
db:
database: hm-cart
spring:
cloud:
sentinel:
transport:
dashboard: localhost:8090
http-method-specify: true # 开启请求方式前缀重启服务,通过页面访问购物车的相关接口,可以看到sentinel控制台的簇点链路发生了变化
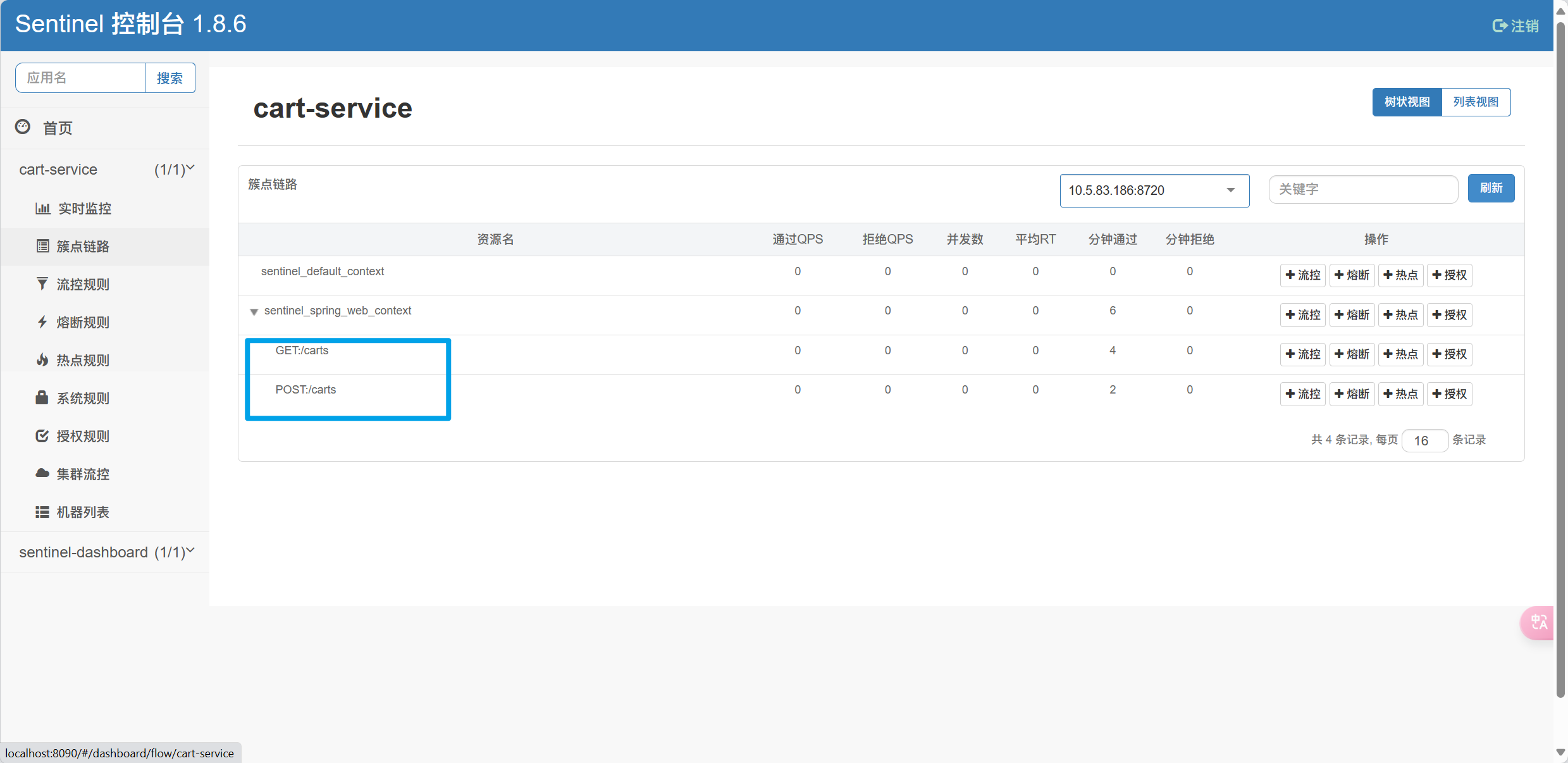
Sentinel 请求限流
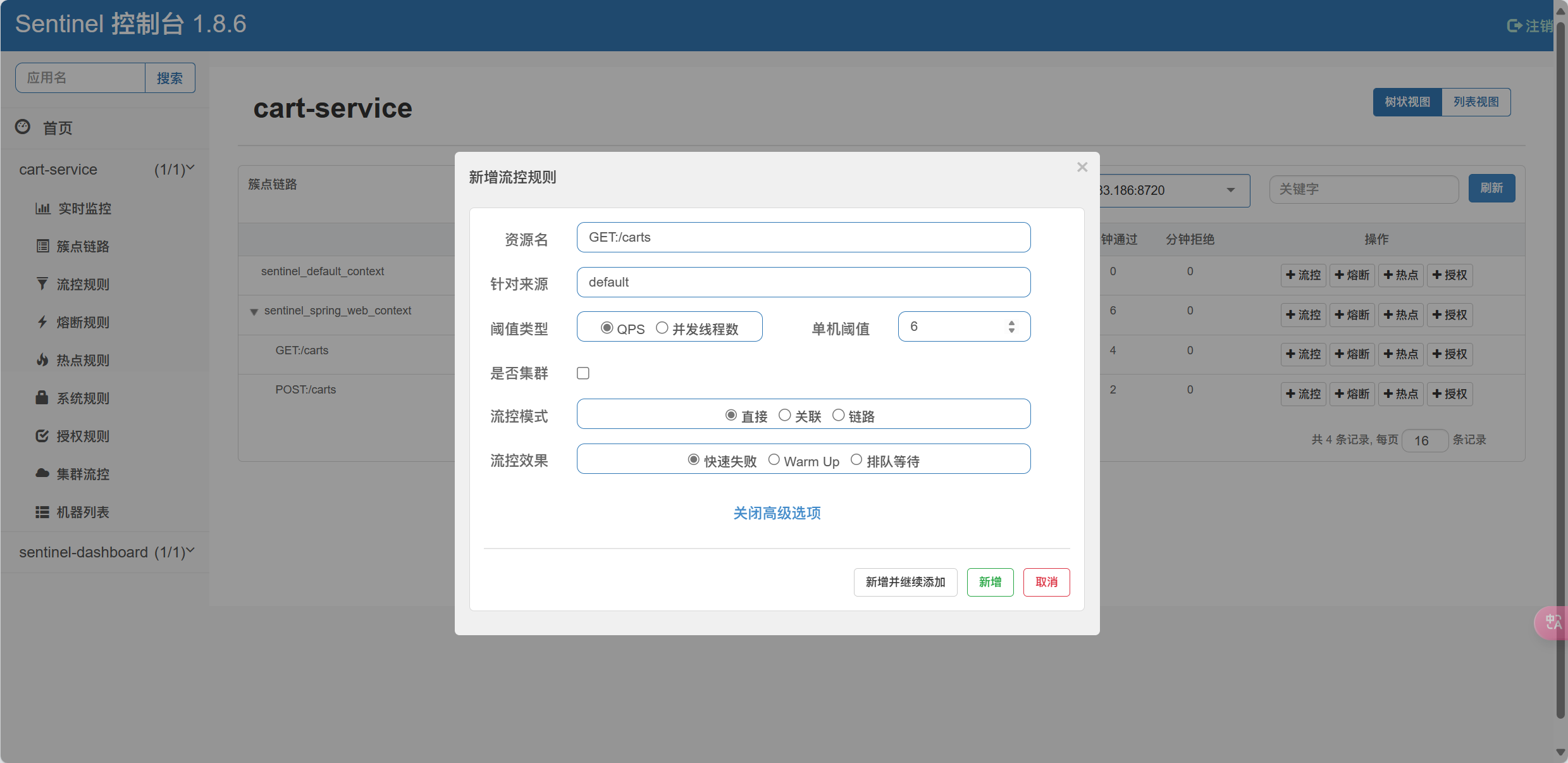
测试
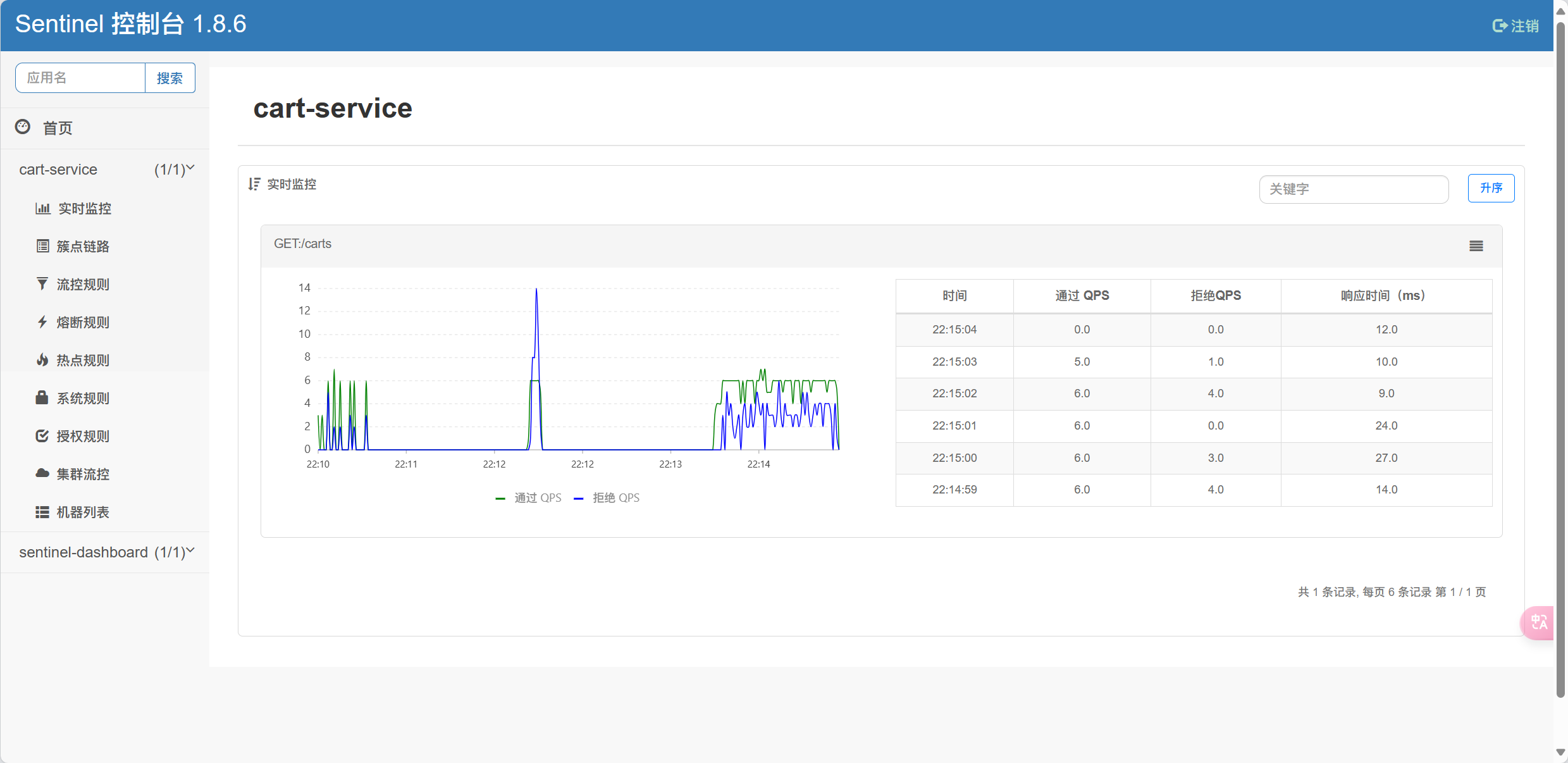
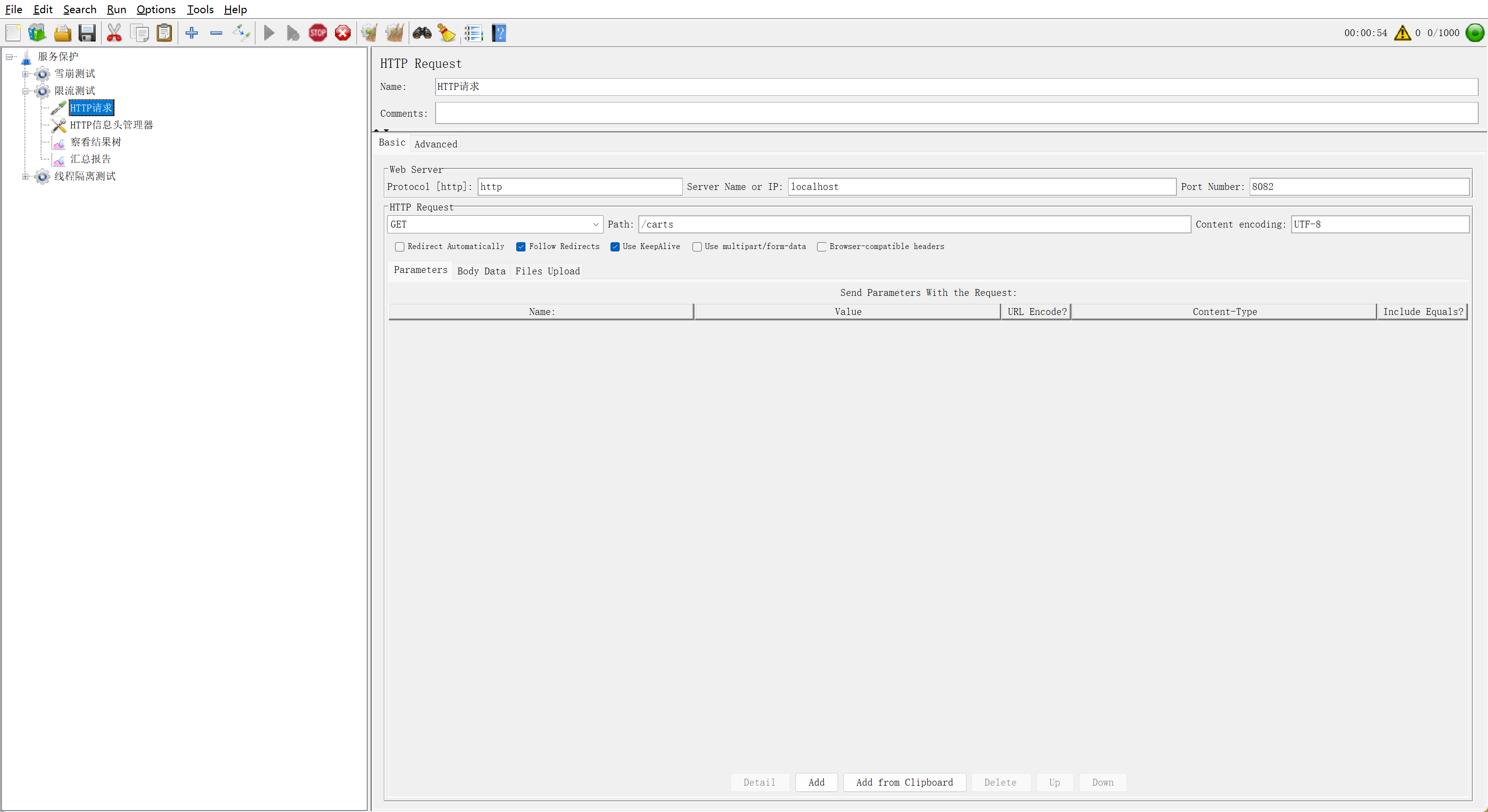
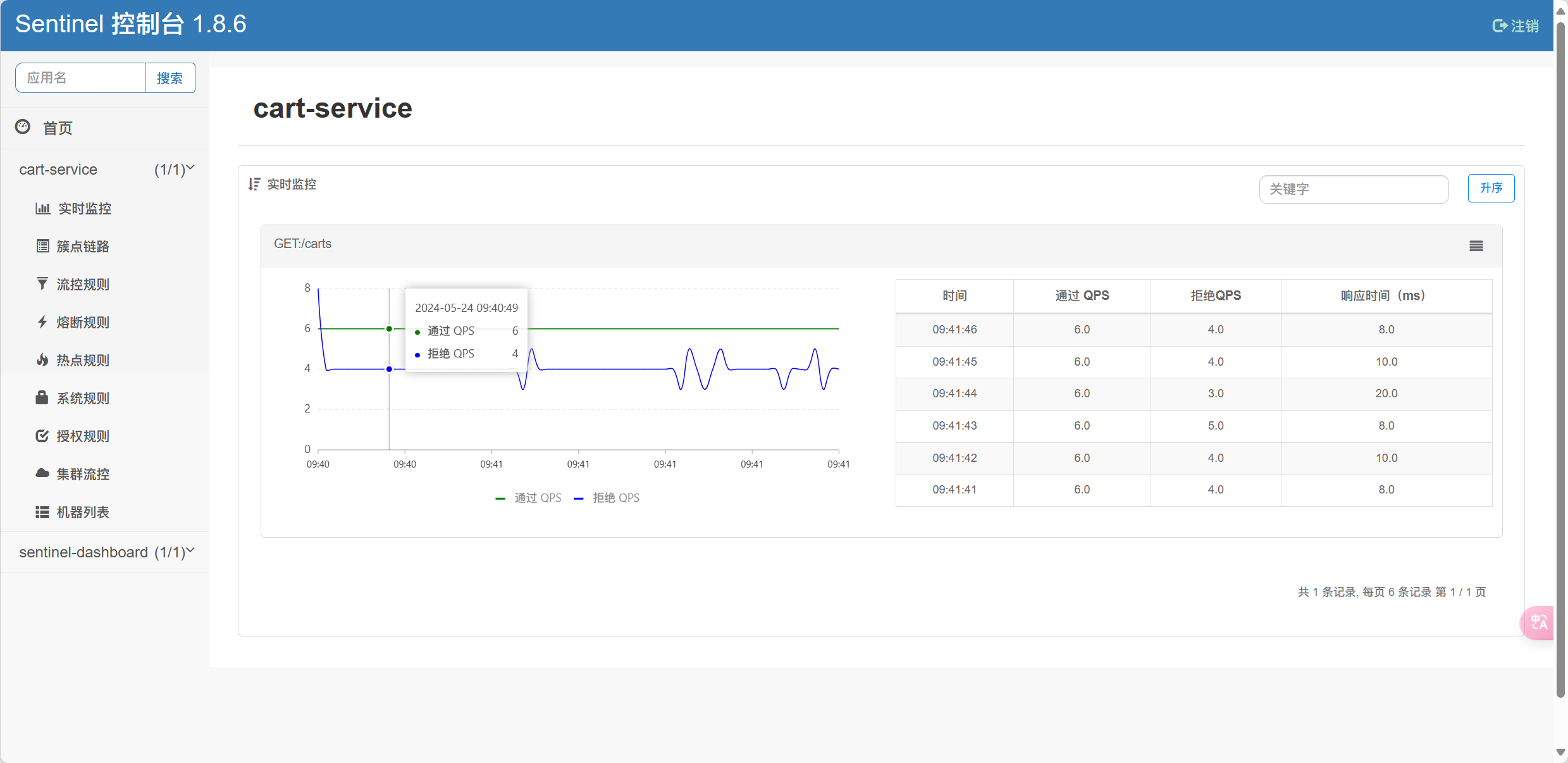
通过的QPS稳定在6附近
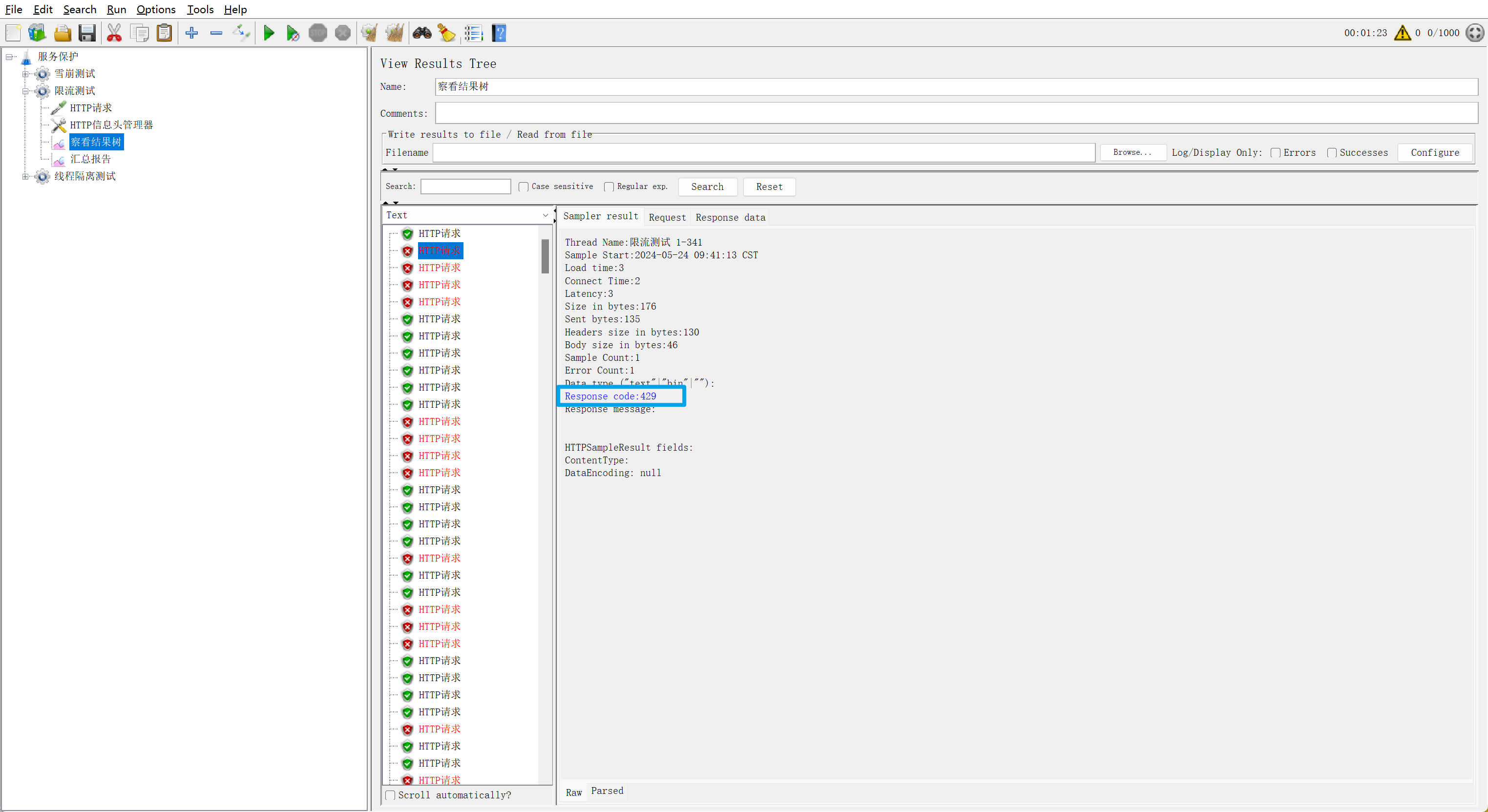
429是被限流
线程隔离
限制访问的线程数
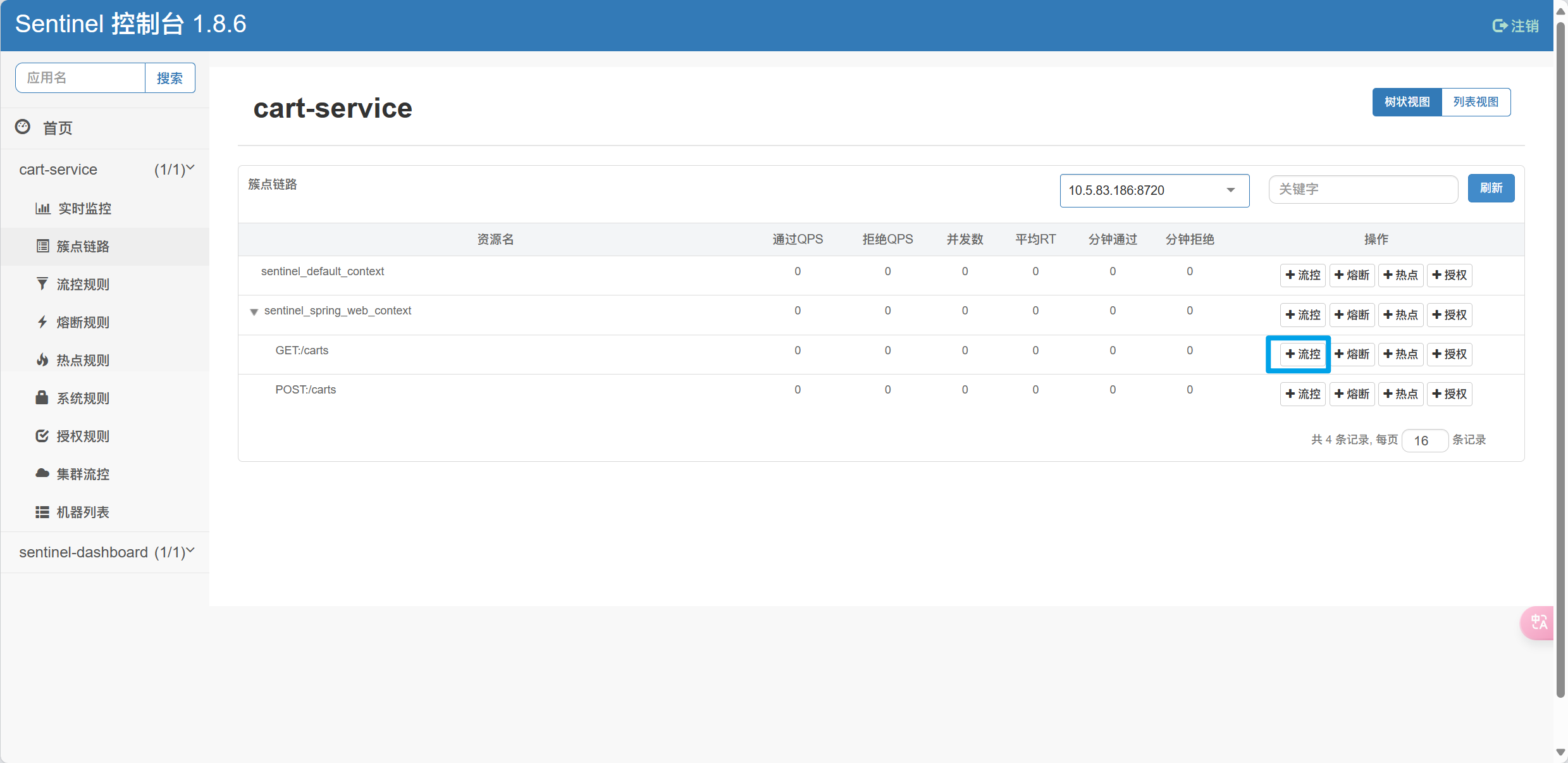
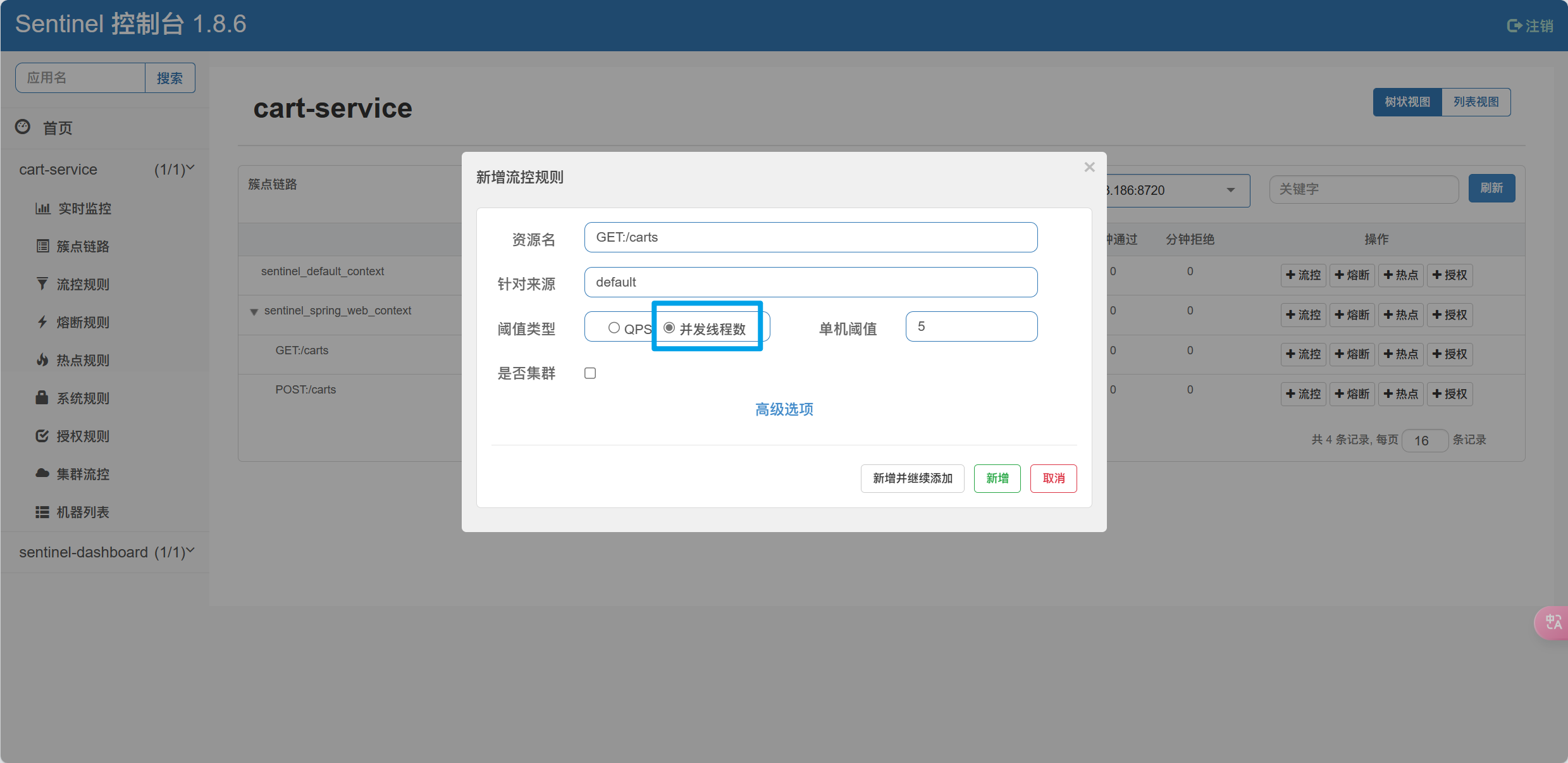
FallBack
OpenFeign整合Sentinel
不再对整个业务进行控制,而是控制远程调用
为了开启远程调用feignclient作为簇点,可以被流量监控
修改cart-service模块的application.yml文件,开启Feign的sentinel功能
feign:
okhttp:
enabled: true # 开启OKHttp连接池支持
sentinel:
enabled: true❗️需要注意的是,默认情况下SpringBoot项目的tomcat最大线程数是200,允许的最大连接是8492,单机测试很难打满。
配置一下cart-service模块的application.yml文件,修改tomcat连接
server:
port: 8082
tomcat:
threads:
max: 50 # 允许的最大线程数
accept-count: 50 # 最大排队等待数量
max-connections: 100 # 允许的最大连接重启cart-service服务,可以看到查询商品的FeignClient自动变成了一个簇点资源
服务降级
触发限流或熔断后的请求不一定要直接报错,也可以返回一些默认数据或者友好提示,用户体验会更好。
给FeignClient编写失败后的降级逻辑有两种方式:
- 方式一:FallbackClass,无法对远程调用的异常做处理
- 方式二:FallbackFactory,可以对远程调用的异常做处理,一般选择这种方式。
在hm-api模块中给ItemClient定义降级处理类,实现FallbackFactory
package com.hmall.api.client.fallback;
/**
* @author:CharmingDaiDai
* @project:hmall
* @since:2024/5/24 上午10:31
*/
@Slf4j
public class ItemClientFallback implements FallbackFactory<ItemClient> {
@Override
public ItemClient create(Throwable cause) {
return new ItemClient() {
@Override
public List<ItemDTO> queryItemByIds(Collection<Long> ids) {
log.error("远程调用ItemClient#queryItemByIds方法出现异常,参数:{}", ids, cause);
// 查询购物车允许失败,查询失败,返回空集合
return CollUtils.emptyList();
}
@Override
public void deductStock(List<OrderDetailDTO> items) {
// 库存扣减业务需要触发事务回滚,查询失败,抛出异常
throw new BizIllegalException(cause);
}
};
}
}在hm-api模块中的com.hmall.api.config.DefaultFeignConfig类中将ItemClientFallback注册为一个Bean
package com.hmall.api.config;
/**
* @author:CharmingDaiDai
* @project:hmall
* @since:2024/5/21 下午12:49
*/
public class DefaultFeignConfig {
@Bean
public Logger.Level feignLogLevel(){
return Logger.Level.BASIC;
}
@Bean
public RequestInterceptor userInfoRequestInterceptor(){
return new RequestInterceptor() {
@Override
public void apply(RequestTemplate requestTemplate) {
Long userId = UserContext.getUser();
if(userId != null){
requestTemplate.header("userId", String.valueOf(userId));
}
}
};
}
@Bean
public ItemClientFallback itemClientFallback(){
return new ItemClientFallback();
}
}在hm-api模块中的ItemClient接口中使用ItemClientFallbackFactory
package com.hmall.api.client;
/**
* @author:CharmingDaiDai
* @project:hmall
* @since:2024/5/21 上午9:43
*/
import com.hmall.api.client.fallback.ItemClientFallback;
import com.hmall.api.dto.ItemDTO;
import com.hmall.api.dto.OrderDetailDTO;
import org.springframework.cloud.openfeign.FeignClient;
import org.springframework.web.bind.annotation.*;
import java.util.Collection;
import java.util.List;
@FeignClient(value = "item-service", fallbackFactory = ItemClientFallback.class)
public interface ItemClient {
@GetMapping("/items")
List<ItemDTO> queryItemByIds(@RequestParam("ids") Collection<Long> ids);
@PutMapping("items/stock/deduct")
void deductStock(@RequestBody List<OrderDetailDTO> items);
}再次测试,发现被限流的请求不再报错,走了降级逻辑
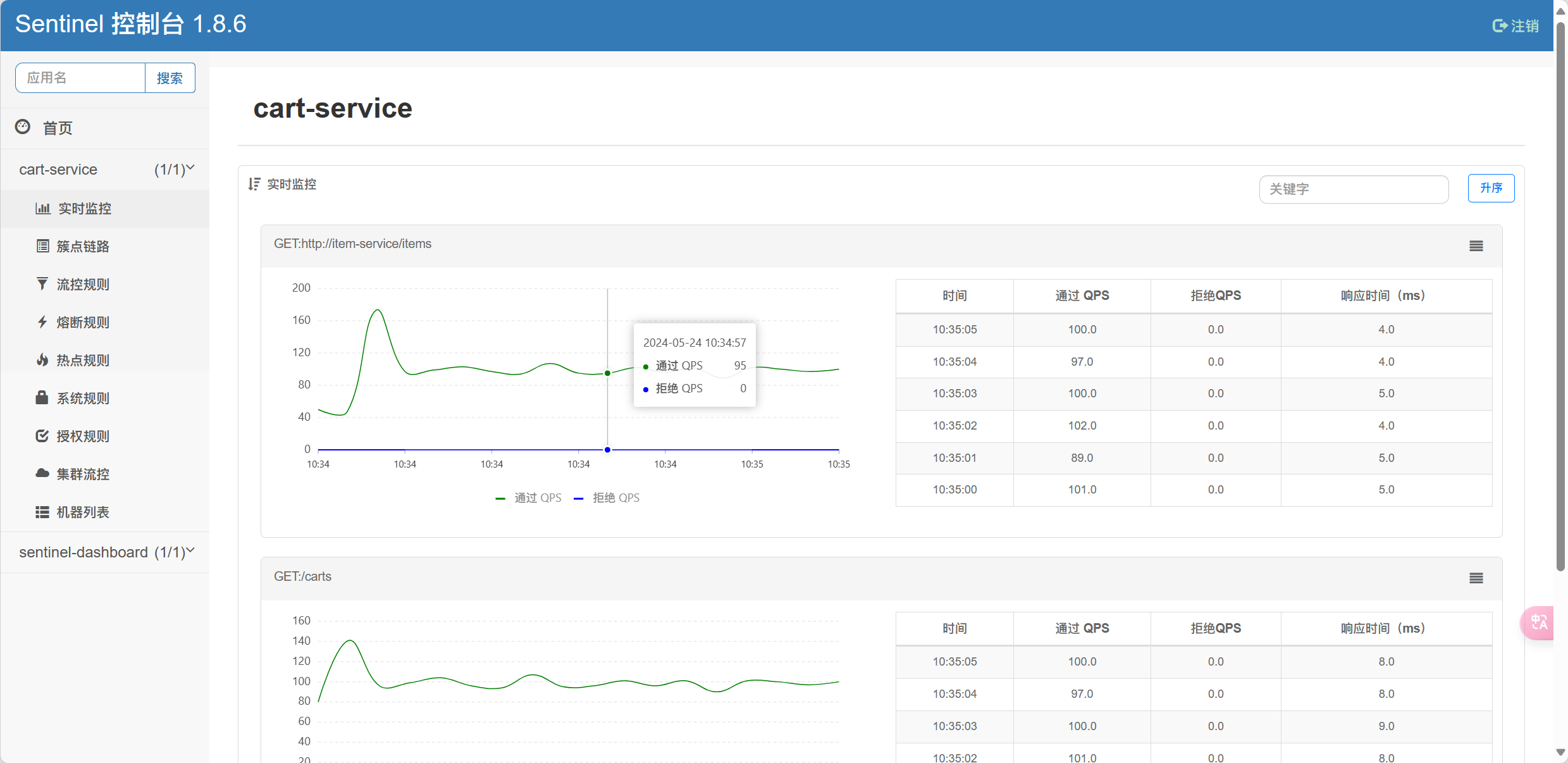
服务熔断
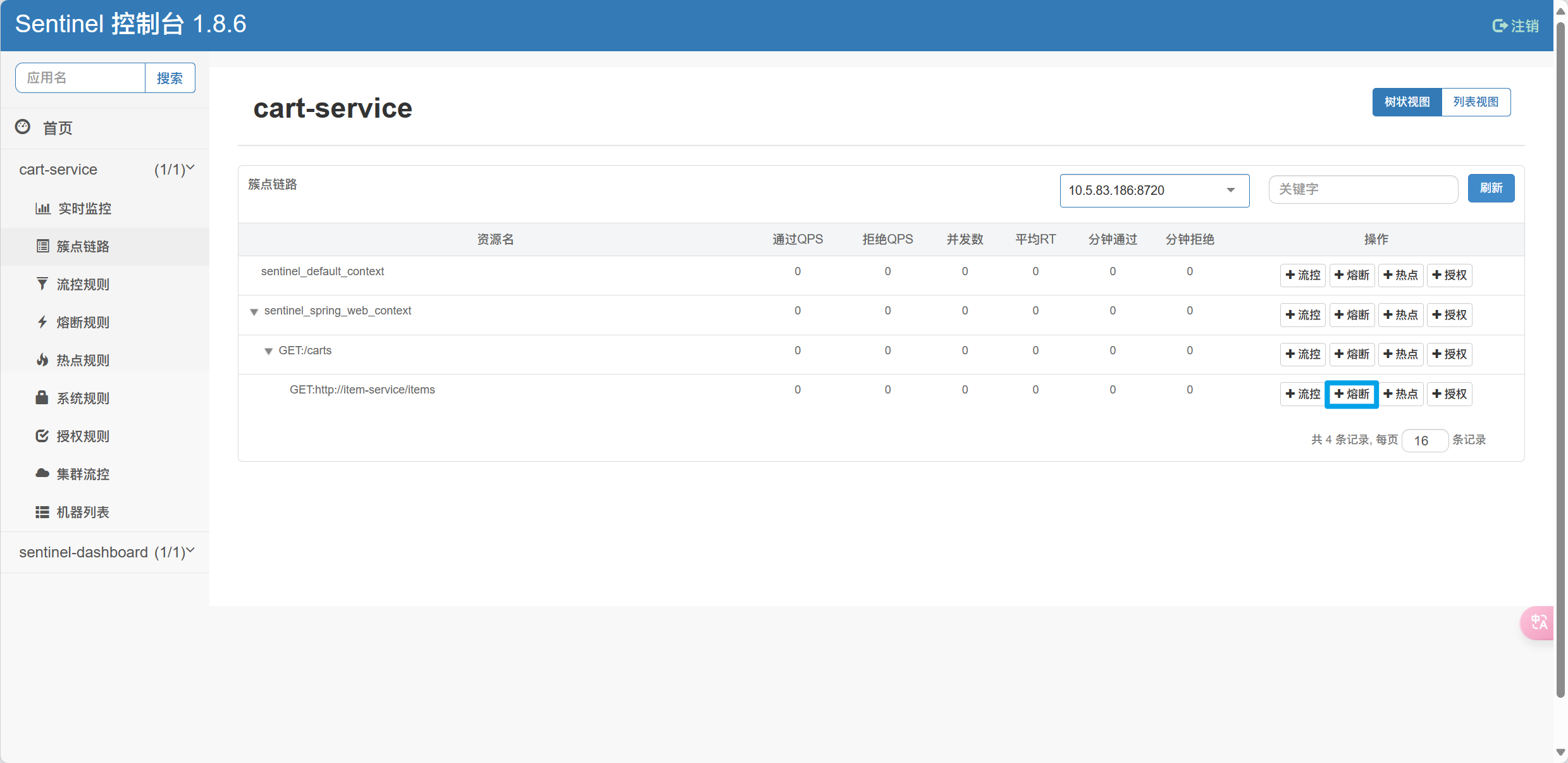
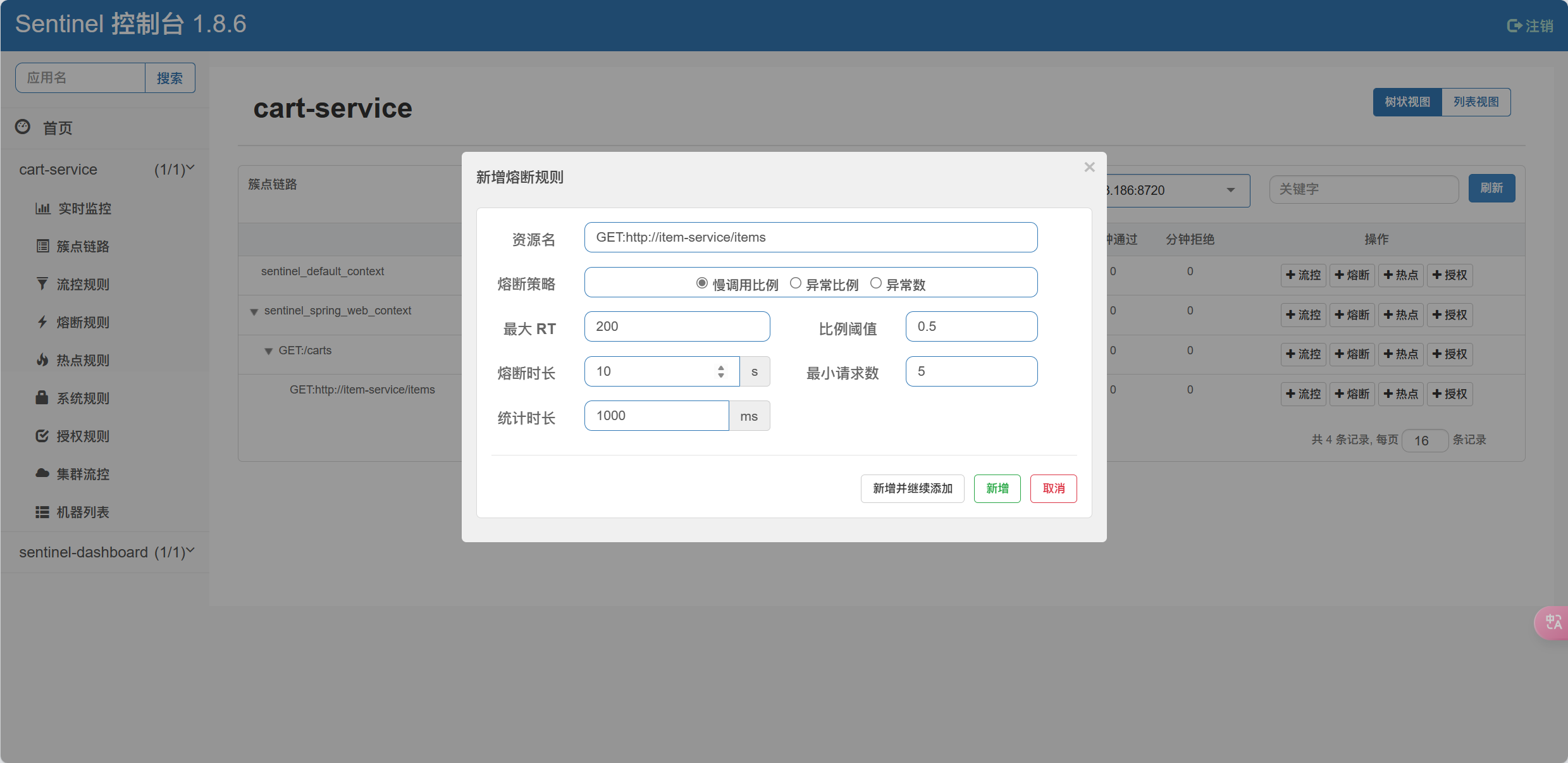
分布式事务
在分布式系统中,如果一个业务需要多个服务合作完成,而且每一个服务都有事务,多个事务必须同时成功或失败,这样的事务就是分布式事务。其中的每个服务的事务就是一个分支事务。整个业务称为全局事务。
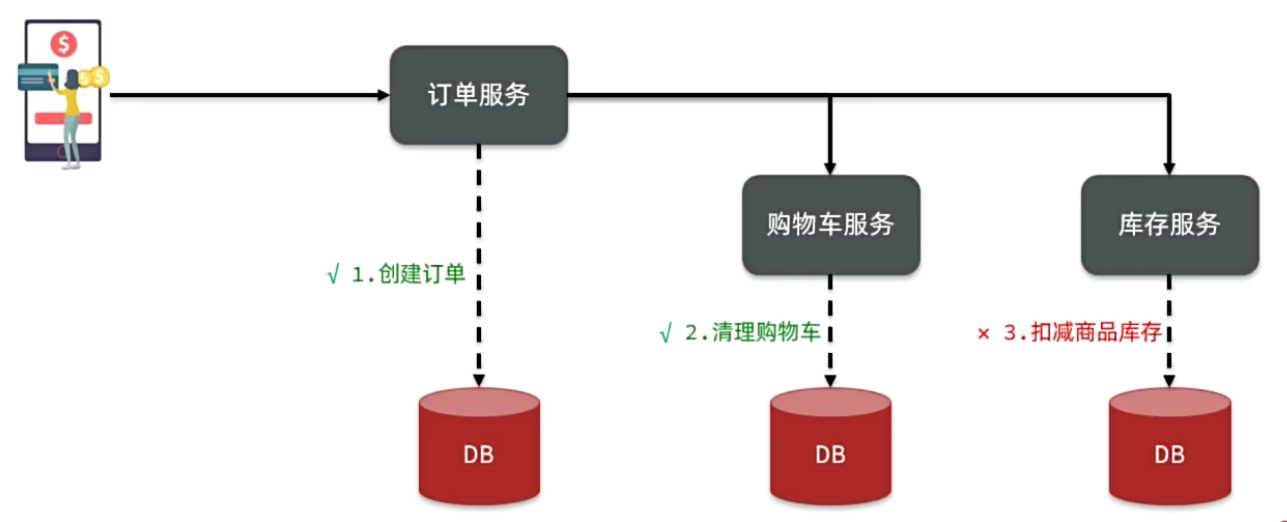
可能产生分布式事务问题:
- 业务跨多个服务实现
- 业务跨多个数据源实现
Seata
Seata 是一款开源的分布式事务解决方案,致力于提供高性能和简单易用的分布式事务服务。Seata 将为用户提供了 AT、TCC、SAGA 和 XA 事务模式,为用户打造一站式的分布式解决方案。
在Seata的事务管理中有三个重要的角色:
- **TC (Transaction Coordinator) - 事务协调者:**维护全局和分支事务的状态,协调全局事务提交或回滚。
- TM (Transaction Manager) - **事务管理器:**定义全局事务的范围、开始全局事务、提交或回滚全局事务。
- RM (Resource Manager) - **资源管理器:**管理分支事务,与TC交谈以注册分支事务和报告分支事务的状态,并驱动分支事务提交或回滚。
工作架构如图
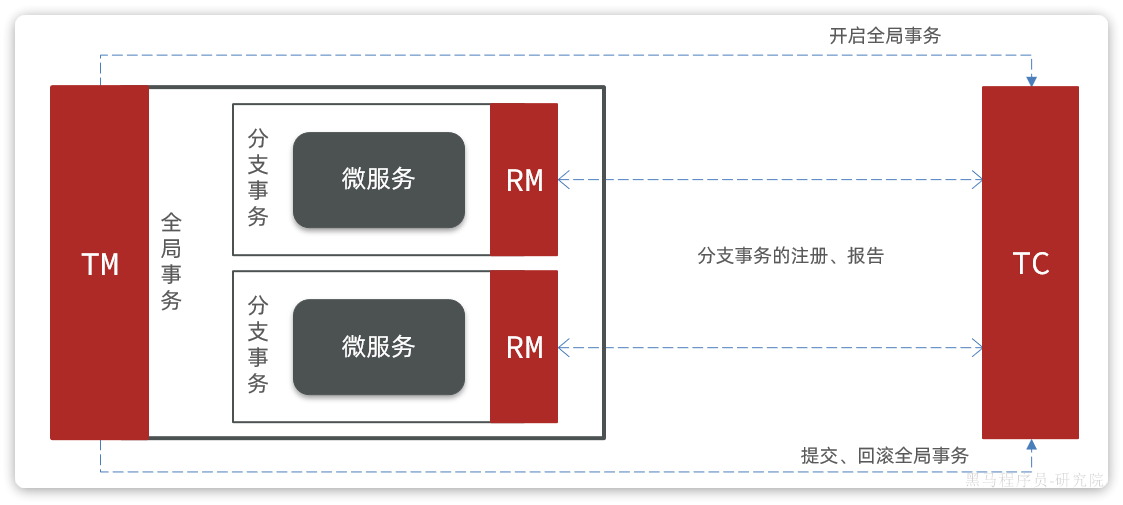
其中,TM和RM可以理解为Seata的客户端部分,引入到参与事务的微服务依赖中即可。将来TM和RM就会协助微服务,实现本地分支事务与TC之间交互,实现事务的提交或回滚。
而TC服务则是事务协调中心,是一个独立的微服务,需要单独部署。
部署TC服务
Seata支持多种存储模式,但考虑到持久化的需要,一般选择基于数据库存储。执行资料提供的seata-tc.sql,导入数据库表:
准备配置文件
资料中的seata目录,其中包含了seata运行时所需要的配置文件
server:
port: 7099
spring:
application:
name: seata-server
logging:
config: classpath:logback-spring.xml
file:
path: ${user.home}/logs/seata
# extend:
# logstash-appender:
# destination: 127.0.0.1:4560
# kafka-appender:
# bootstrap-servers: 127.0.0.1:9092
# topic: logback_to_logstash
console:
user:
username: admin
password: admin
seata:
config:
# support: nacos, consul, apollo, zk, etcd3
type: file
# nacos:
# server-addr: nacos:8848
# group : "DEFAULT_GROUP"
# namespace: ""
# dataId: "seataServer.properties"
# username: "nacos"
# password: "nacos"
registry:
# support: nacos, eureka, redis, zk, consul, etcd3, sofa
type: nacos
nacos:
application: seata-server
server-addr: nacos:8848
group : "DEFAULT_GROUP"
namespace: ""
username: "nacos"
password: "nacos"
# server:
# service-port: 8091 #If not configured, the default is '${server.port} + 1000'
security:
secretKey: SeataSecretKey0c382ef121d778043159209298fd40bf3850a017
tokenValidityInMilliseconds: 1800000
ignore:
urls: /,/**/*.css,/**/*.js,/**/*.html,/**/*.map,/**/*.svg,/**/*.png,/**/*.ico,/console-fe/public/**,/api/v1/auth/login
server:
# service-port: 8091 #If not configured, the default is '${server.port} + 1000'
max-commit-retry-timeout: -1
max-rollback-retry-timeout: -1
rollback-retry-timeout-unlock-enable: false
enable-check-auth: true
enable-parallel-request-handle: true
retry-dead-threshold: 130000
xaer-nota-retry-timeout: 60000
enableParallelRequestHandle: true
recovery:
committing-retry-period: 1000
async-committing-retry-period: 1000
rollbacking-retry-period: 1000
timeout-retry-period: 1000
undo:
log-save-days: 7
log-delete-period: 86400000
session:
branch-async-queue-size: 5000 #branch async remove queue size
enable-branch-async-remove: false #enable to asynchronous remove branchSession
store:
# support: file 、 db 、 redis
mode: db
session:
mode: db
lock:
mode: db
db:
datasource: druid
db-type: mysql
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://mysql:3306/seata?rewriteBatchedStatements=true&serverTimezone=UTC
user: root
password: 123
min-conn: 10
max-conn: 100
global-table: global_table
branch-table: branch_table
lock-table: lock_table
distributed-lock-table: distributed_lock
query-limit: 1000
max-wait: 5000
# redis:
# mode: single
# database: 0
# min-conn: 10
# max-conn: 100
# password:
# max-total: 100
# query-limit: 1000
# single:
# host: 192.168.150.101
# port: 6379
metrics:
enabled: false
registry-type: compact
exporter-list: prometheus
exporter-prometheus-port: 9898
transport:
rpc-tc-request-timeout: 15000
enable-tc-server-batch-send-response: false
shutdown:
wait: 3
thread-factory:
boss-thread-prefix: NettyBoss
worker-thread-prefix: NettyServerNIOWorker
boss-thread-size: 1将整个seata文件夹拷贝到虚拟机的/root目录
Docker部署
要确保nacos、mysql都在hm-net网络中
docker run --name seata \
-p 8099:8099 \
-p 7099:7099 \
-e SEATA_IP=172.26.134.204 \
-v ./seata:/seata-server/resources \
--privileged=true \
--network hm-net \
-d \
seataio/seata-server:1.5.28099:微服务和seata TC服务进行连接的端口
7099:seata控制台端口
SEATA_IP:注册到nacos的地址
账号密码:admin
微服务整合seata
在nacos上添加一个共享的seata配置,命名为shared-seata.yaml
seata:
registry: # TC服务注册中心的配置,微服务根据这些信息去注册中心获取tc服务地址
type: nacos # 注册中心类型 nacos
nacos:
server-addr: 127.0.0.1:8848 # nacos地址
namespace: "" # namespace,默认为空
group: DEFAULT_GROUP # 分组,默认是DEFAULT_GROUP
application: seata-server # seata服务名称
username: nacos
password: nacos
tx-service-group: hmall # 事务组名称
service:
vgroup-mapping: # 事务组与tc集群的映射关系
hmall: "default"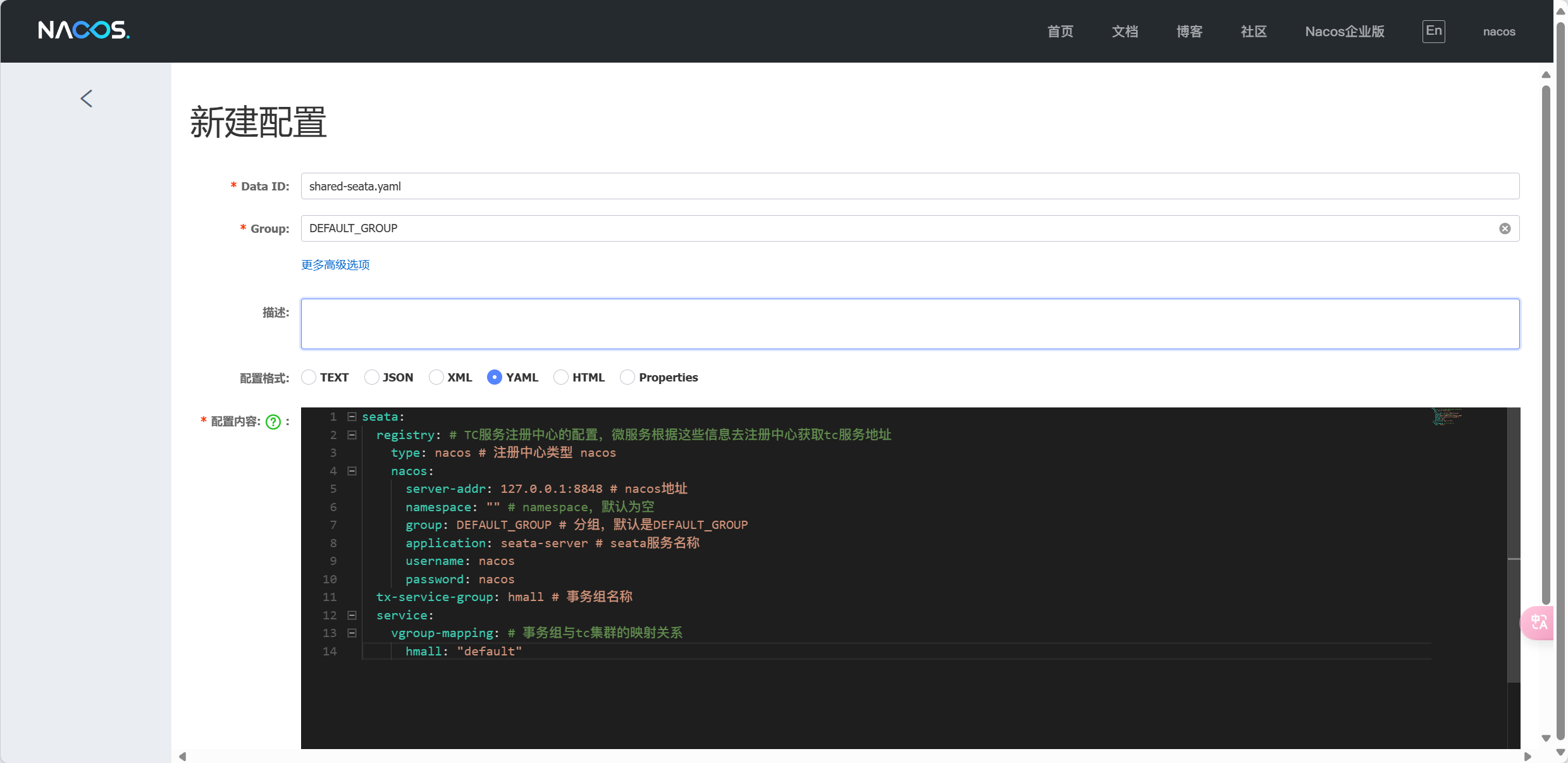
引入依赖
trade-service
为了方便各个微服务集成seata,需要把seata配置共享到nacos,因此trade-service模块不仅仅要引入seata依赖,还要引入nacos依赖
<!--统一配置管理-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-config</artifactId>
</dependency>
<!--读取bootstrap文件-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-bootstrap</artifactId>
</dependency>
<!--seata-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-seata</artifactId>
</dependency>添加bootstrap.yaml
spring:
application:
name: trade-service # 服务名称
profiles:
active: dev
cloud:
nacos:
server-addr: 127.0.0.1:8848 # nacos地址
config:
file-extension: yaml # 文件后缀名
shared-configs: # 共享配置
- dataId: shared-jdbc.yaml # 共享mybatis配置
- dataId: shared-log.yaml # 共享日志配置
- dataId: shared-swagger.yaml # 共享日志配置
- data-id: shared-seata.yaml # 共享seata配置修改application.yaml
server:
port: 8100
hm:
swagger:
title: 交易服务接口文档
desc: 交易服务接口文档
package: com.trade.item.controller
db:
database: hm-tradecart-service
cart-service添加seata依赖
<!--seata-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-seata</artifactId>
</dependency>bootstrap.yaml 添加共享配置
spring:
application:
name: cart-service # 服务名称
profiles:
active: dev
cloud:
nacos:
server-addr: 127.0.0.1:8848 # nacos地址
config:
file-extension: yaml # 文件后缀名
shared-configs: # 共享配置
- dataId: shared-jdbc.yaml # 共享mybatis配置
- dataId: shared-log.yaml # 共享日志配置
- dataId: shared-swagger.yaml # 共享日志配置
- data-id: shared-seata.yaml # 共享seata配置item-service
引入依赖
<!--nacos配置管理-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-config</artifactId>
</dependency>
<!--读取bootstrap文件-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-bootstrap</artifactId>
</dependency>
<!--sentinel-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-sentinel</artifactId>
</dependency>
<!--seata-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-seata</artifactId>
</dependency>添加bootstrap.yaml
spring:
application:
name: item-service # 服务名称
profiles:
active: dev
cloud:
nacos:
server-addr: 127.0.0.1:8848 # nacos地址
config:
file-extension: yaml # 文件后缀名
shared-configs: # 共享配置
- dataId: shared-jdbc.yaml # 共享mybatis配置
- dataId: shared-log.yaml # 共享日志配置
- dataId: shared-swagger.yaml # 共享日志配置
- data-id: shared-seata.yaml # 共享seata配置修改application.yaml
server:
port: 8081
hm:
swagger:
title: 商品服务接口文档
desc: 商品服务接口文档
package: com.hmall.item.controller
db:
database: hm-item
wsl hostname -I标识通过 WSL 2 安装的 Linux 分发版 IP 地址(WSL 2 VM 地址)cat /etc/resolv.conf表示从 WSL 2 看到的 WINDOWS 计算机的 IP 地址 (WSL 2 VM)
XA模式
Seata支持四种不同的分布式事务解决方案:
- XA
- TCC
- AT
- SAGA
XA 规范 是 X/Open 组织定义的分布式事务处理(DTP,Distributed Transaction Processing)标准,XA 规范 描述了全局的TM与局部的RM之间的接口,几乎所有主流的数据库都对 XA 规范 提供了支持。
两阶段提交
A是规范,目前主流数据库都实现了这种规范,实现的原理都是基于两阶段提交。
正常情况:
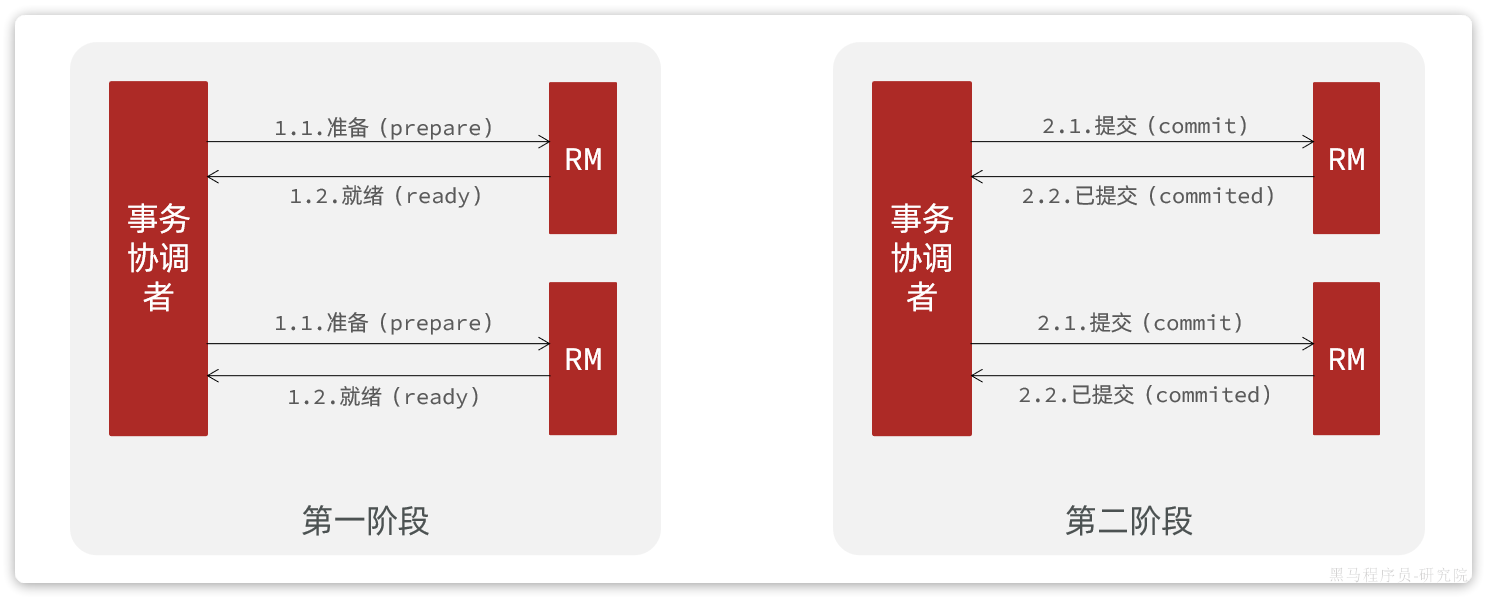
异常情况:
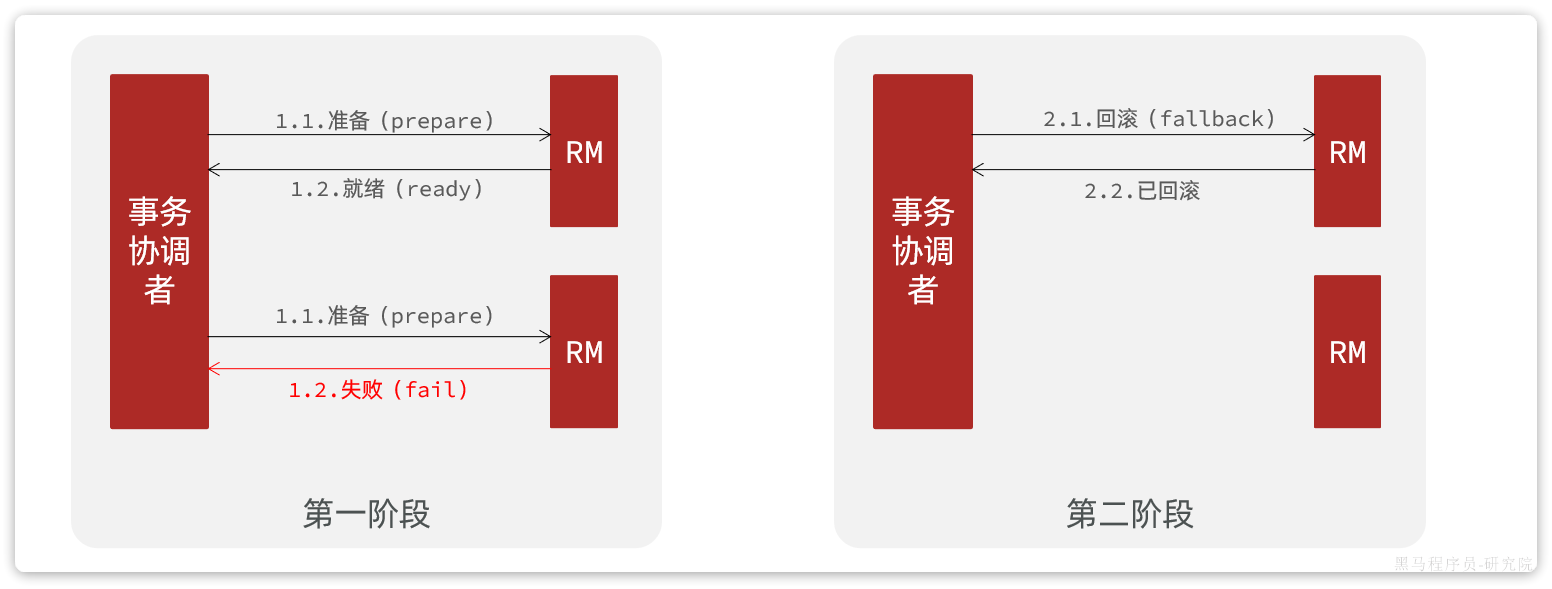
一阶段:
- 事务协调者通知每个事务参与者执行本地事务
- 本地事务执行完成后报告事务执行状态给事务协调者,此时事务不提交,继续持有数据库锁
二阶段:
- 事务协调者基于一阶段的报告来判断下一步操作
- 如果一阶段都成功,则通知所有事务参与者,提交事务
- 如果一阶段任意一个参与者失败,则通知所有事务参与者回滚事务
Seata的XA模型
Seata对原始的XA模式做了简单的封装和改造,以适应自己的事务模型,基本架构如图:
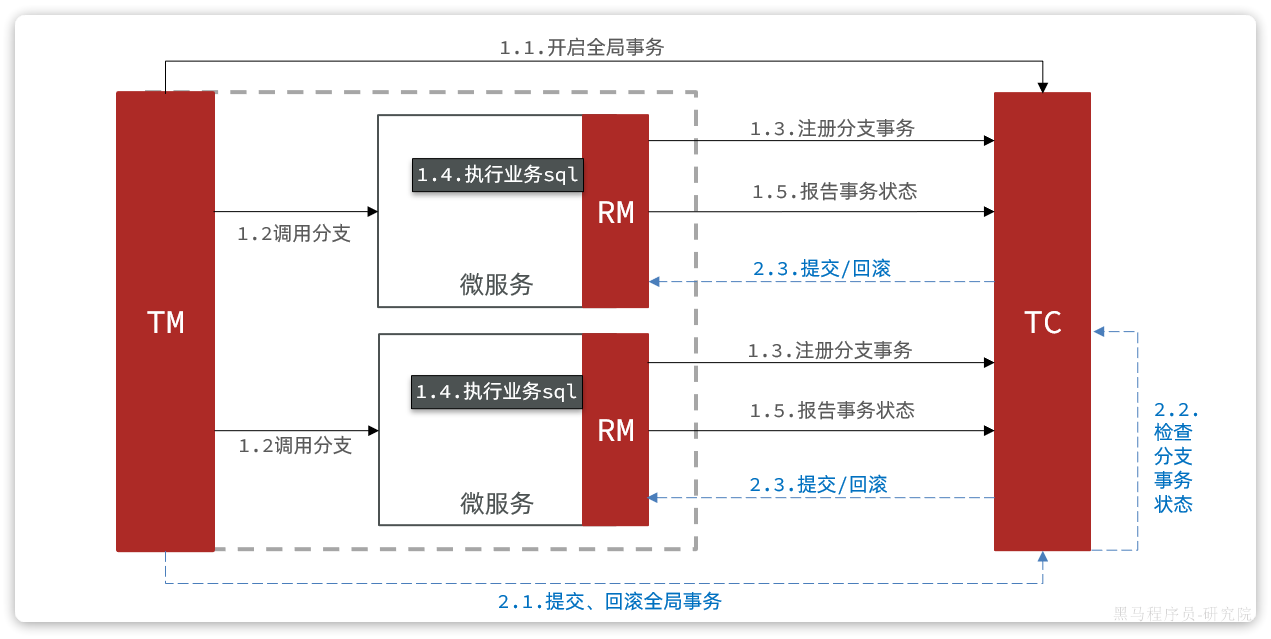
RM一阶段的工作:
- 注册分支事务到
TC - 执行分支业务sql但不提交
- 报告执行状态到
TC
TC二阶段的工作:
TC检测各分支事务执行状态- 如果都成功,通知所有RM提交事务
- 如果有失败,通知所有RM回滚事务
RM二阶段的工作:
- 接收
TC指令,提交或回滚事务
优缺点
XA模式的优点是什么?
- 事务的强一致性,满足ACID原则
- 常用数据库都支持,实现简单,并且没有代码侵入
XA模式的缺点是什么?
- 因为一阶段需要锁定数据库资源,等待二阶段结束才释放,性能较差
- 依赖关系型数据库实现事务
实现步骤
在配置文件中指定要采用的分布式事务模式。可以在Nacos中的共享shared-seata.yaml配置文件中设置:
seata:
data-source-proxy-mode: XA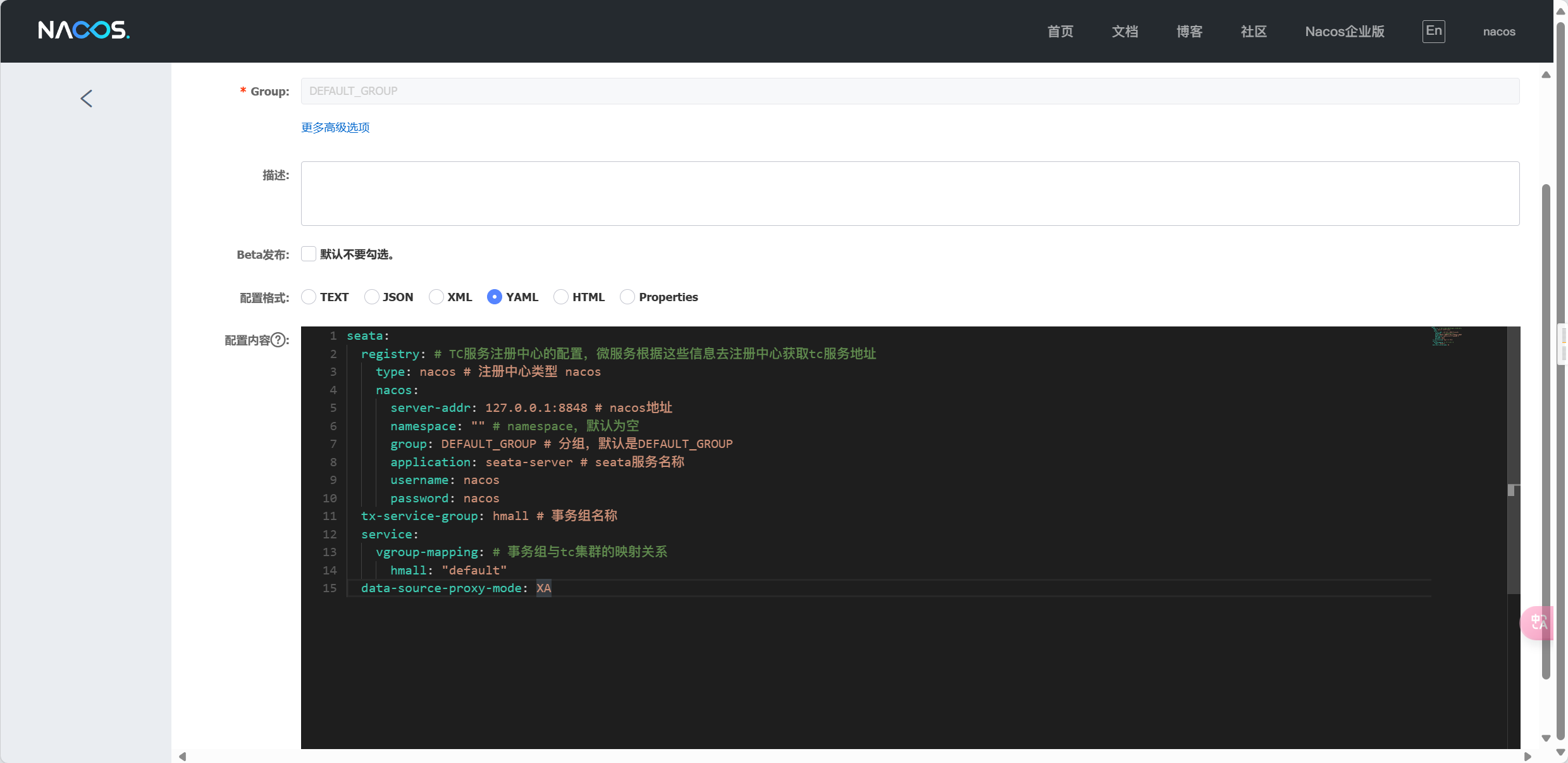
利用@GlobalTransactional标记分布式事务的入口方法:
@Override
// @Transactional
@GlobalTransactional
public Long createOrder(OrderFormDTO orderFormDTO) {
// 1.订单数据
Order order = new Order();
// 1.1.查询商品
List<OrderDetailDTO> detailDTOS = orderFormDTO.getDetails();
// 1.2.获取商品id和数量的Map
Map<Long, Integer> itemNumMap = detailDTOS.stream()
.collect(Collectors.toMap(OrderDetailDTO::getItemId, OrderDetailDTO::getNum));
Set<Long> itemIds = itemNumMap.keySet();
// 1.3.查询商品
List<ItemDTO> items = itemClient.queryItemByIds(itemIds);
// List<ItemDTO> items = itemService.queryItemByIds(itemIds);
if (items == null || items.size() < itemIds.size()) {
throw new BadRequestException("商品不存在");
}
// 1.4.基于商品价格、购买数量计算商品总价:totalFee
int total = 0;
for (ItemDTO item : items) {
total += item.getPrice() * itemNumMap.get(item.getId());
}
order.setTotalFee(total);
// 1.5.其它属性
order.setPaymentType(orderFormDTO.getPaymentType());
order.setUserId(UserContext.getUser());
order.setStatus(1);
// 1.6.将Order写入数据库order表中
save(order);
// 2.保存订单详情
List<OrderDetail> details = buildDetails(order.getId(), items, itemNumMap);
detailService.saveBatch(details);
// 3.清理购物车商品
// cartService.removeByItemIds(itemIds);
cartClient.removeByItemIds(itemIds);
// 4.扣减库存
try {
// itemService.deductStock(detailDTOS);
itemClient.deductStock(detailDTOS);
} catch (Exception e) {
throw new RuntimeException("库存不足!");
}
return order.getId();
}订单加上事务注解

购物车加上事务注解
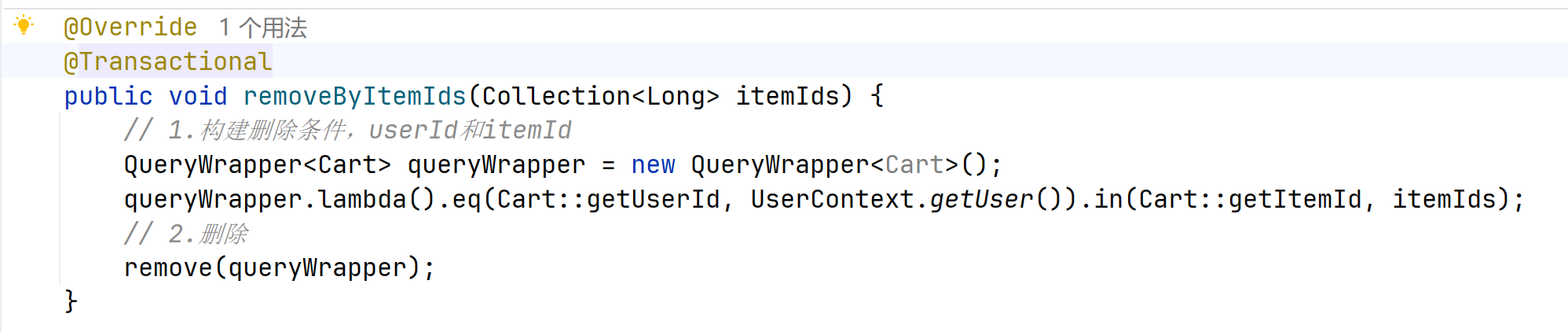
结算

改数量
购物车服务可以看到回滚

trade报错

购物车没被清除
AT模式
AT模式同样是分阶段提交的事务模型,不过缺弥补了XA模型中资源锁定周期过长的缺陷
Seata的AT模型
基本流程图:
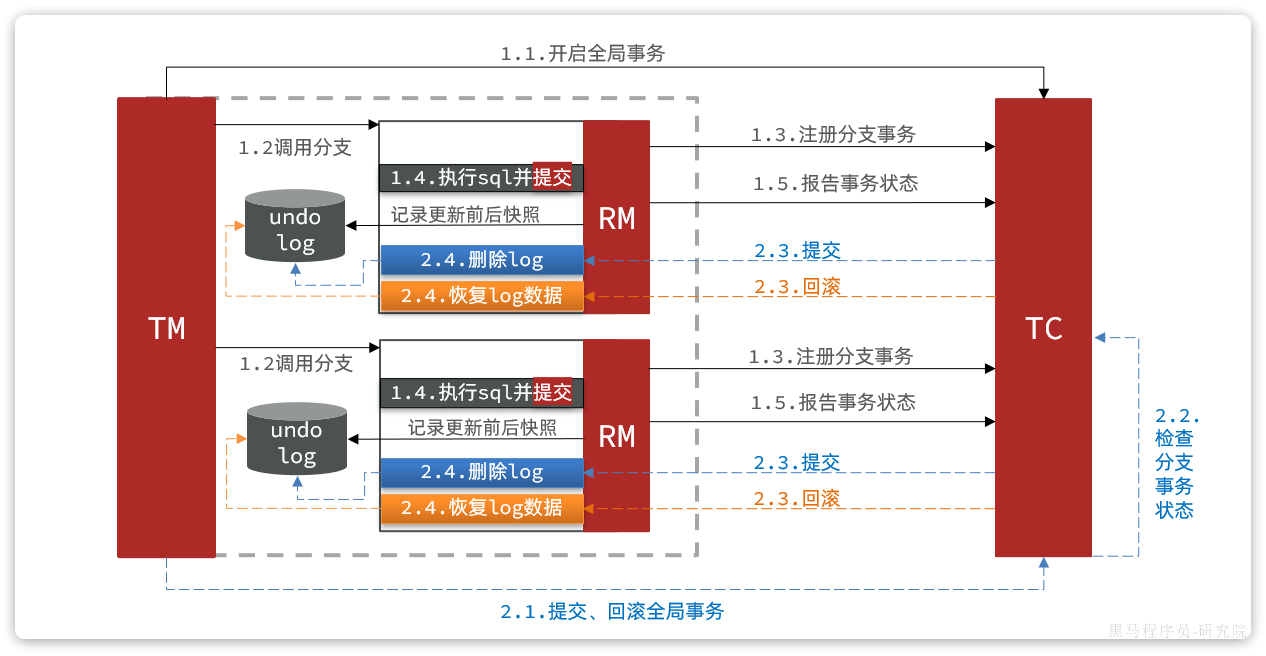
阶段一RM的工作:
- 注册分支事务
- 记录undo-log(数据快照)
- 执行业务sql并提交
- 报告事务状态
阶段二提交时RM的工作:
- 删除undo-log即可
阶段二回滚时RM的工作:
- 根据undo-log恢复数据到更新前
流程梳理
用一个真实的业务来梳理下AT模式的原理。
比如,现在有一个数据库表,记录用户余额:
| id | money |
|---|---|
| 1 | 100 |
其中一个分支业务要执行的SQL为:
update tb_account set money = money - 10 where id = 1AT模式下,当前分支事务执行流程如下:
一阶段:
TM发起并注册全局事务到TCTM调用分支事务- 分支事务准备执行业务SQL
RM拦截业务SQL,根据where条件查询原始数据,形成快照。
{
"id": 1, "money": 100
}RM执行业务SQL,提交本地事务,释放数据库锁。此时 money = 90RM报告本地事务状态给TC
二阶段:
TM通知TC事务结束TC检查分支事务状态- 如果都成功,则立即删除快照
- 如果有分支事务失败,需要回滚。读取快照数据({"id": 1, "money": 100}),将快照恢复到数据库。此时数据库再次恢复为100
流程图:
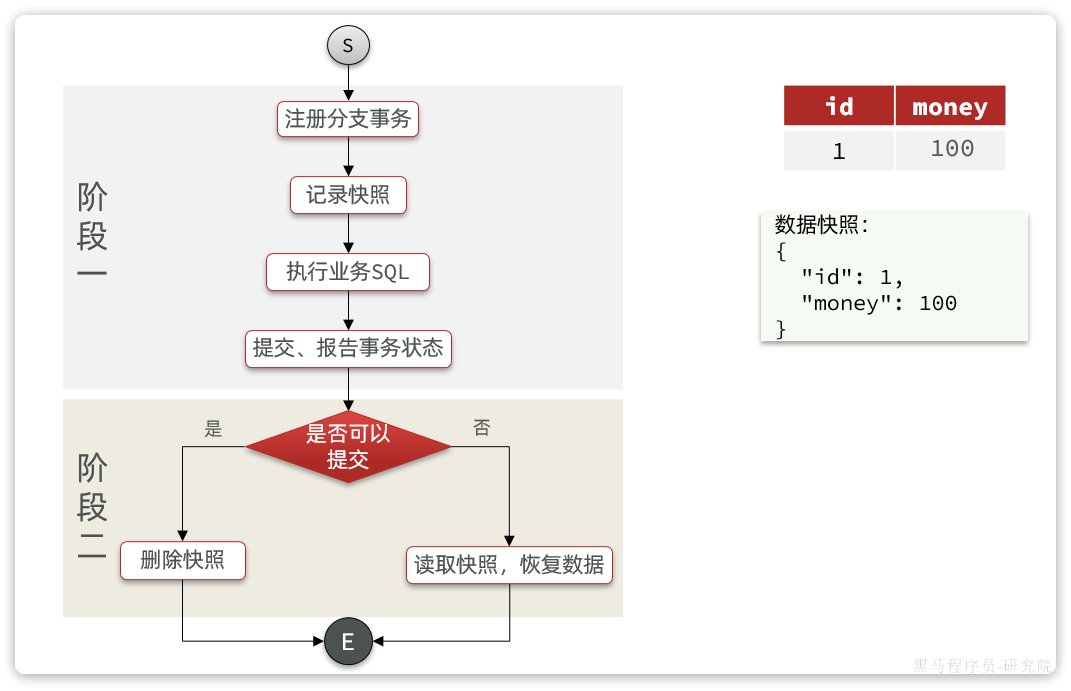
AT与XA的区别
简述AT模式与XA模式最大的区别是什么?
XA模式一阶段不提交事务,锁定资源;AT模式一阶段直接提交,不锁定资源。XA模式依赖数据库机制实现回滚;AT模式利用数据快照实现数据回滚。XA模式强一致;AT模式最终一致
可见,AT模式使用起来更加简单,无业务侵入,性能更好。因此企业90%的分布式事务都可以用AT模式来解决。
实现步骤
添加undo_log表
seata的客户端在解决分布式事务的时候需要记录一些中间数据,保存在数据库中。因此要先准备一个这样的表。
把XA模式改成AT
删除也行,默认AT
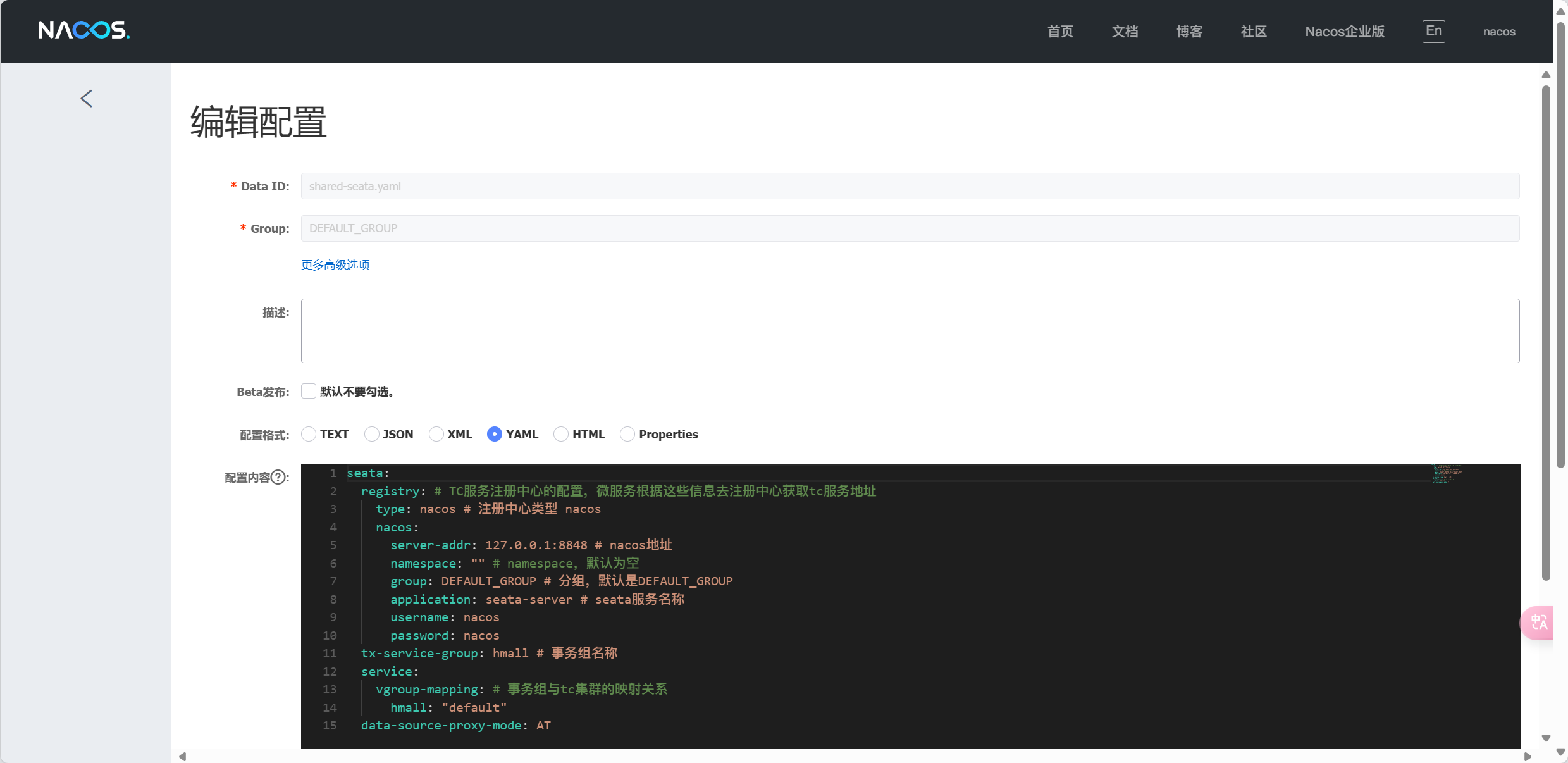
改为全局事务注解
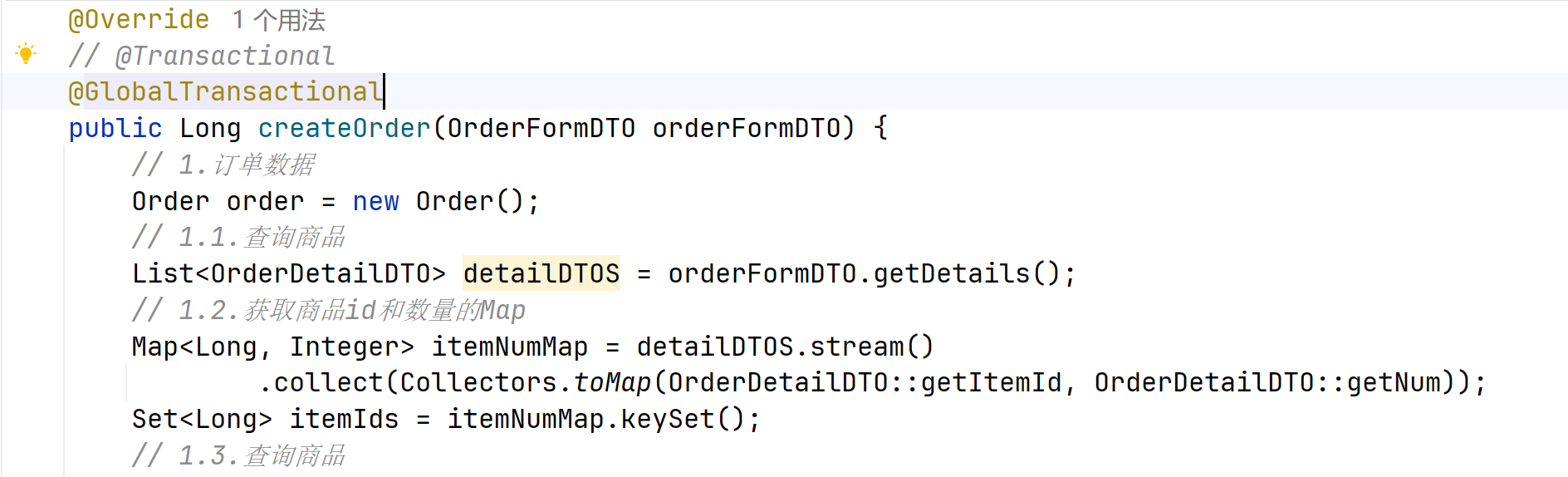
改造剩下的微服务
item-service接入sentinel
<!--sentinel-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-sentinel</artifactId>
</dependency>
spring:
cloud:
sentinel:
transport:
dashboard: localhost:8090
http-method-specify: true # 开启请求方式前缀pay-service接入sentinel
<!--sentinel-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-sentinel</artifactId>
</dependency>
trade-service接入sentinel
<!--sentinel-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-sentinel</artifactId>
</dependency>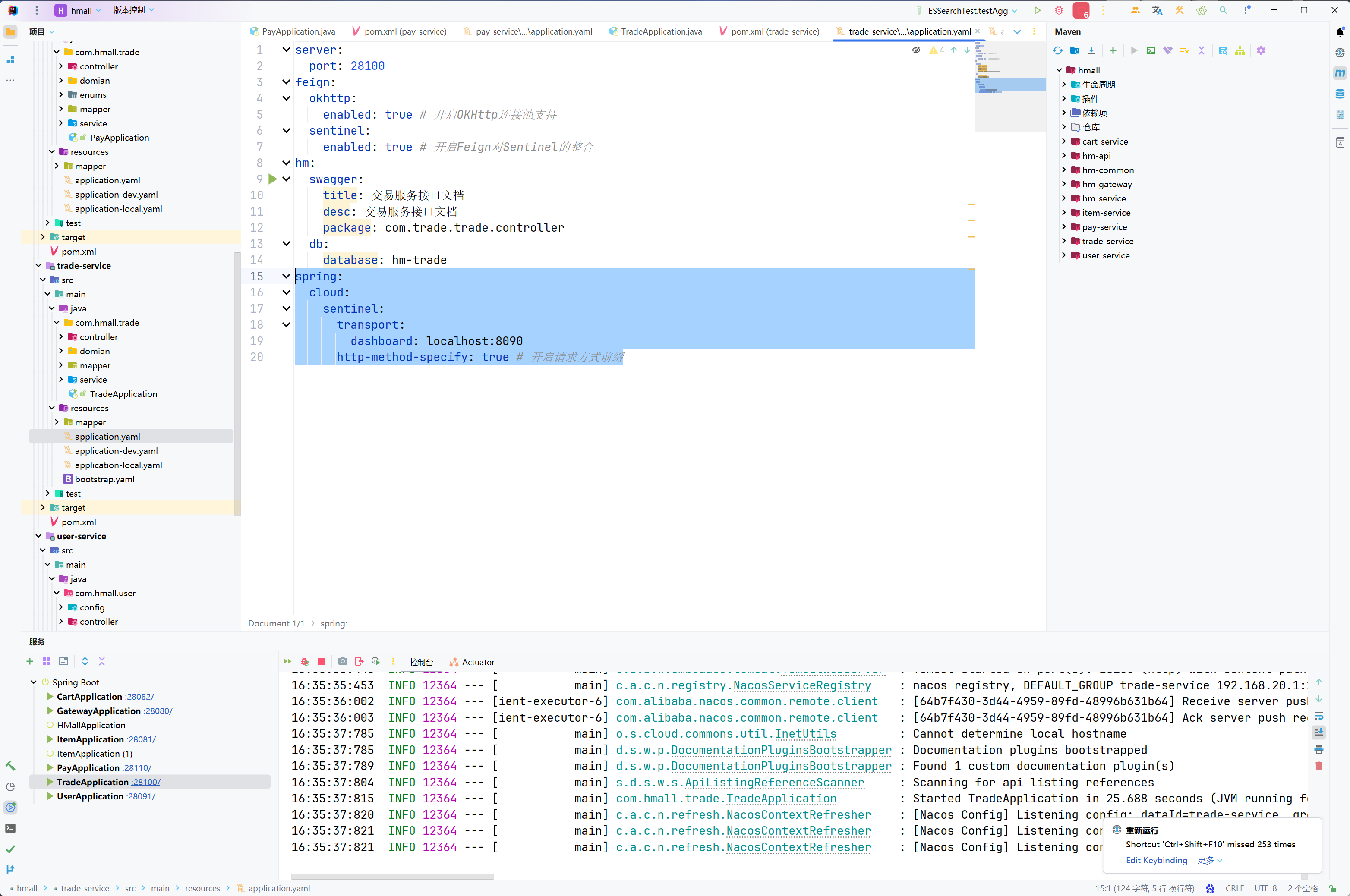
user-service接入sentinel
<!--sentinel-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-sentinel</artifactId>
</dependency>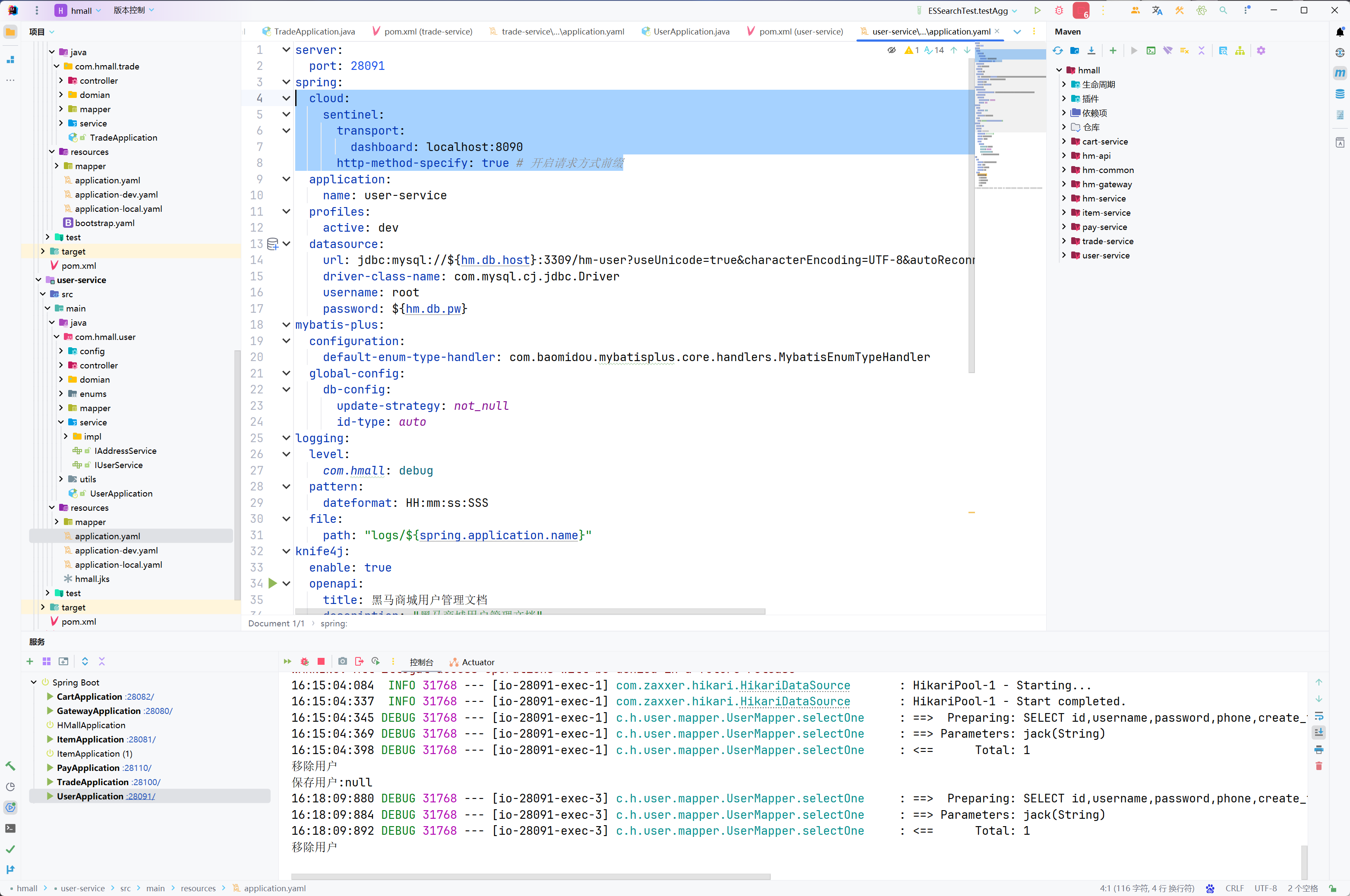
pay-service配置管理
引入依赖
<!--nacos配置管理-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-config</artifactId>
</dependency>
<!--读取bootstrap文件-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-bootstrap</artifactId>
</dependency>新建bootstrap.yaml
spring:
application:
name: pay-service # 服务名称
profiles:
active: dev
cloud:
nacos:
server-addr: 127.0.0.1:8848 # nacos地址
config:
file-extension: yaml # 文件后缀名
shared-configs: # 共享配置
- dataId: shared-jdbc.yaml # 共享mybatis配置
- dataId: shared-log.yaml # 共享日志配置
- dataId: shared-swagger.yaml # 共享日志配置
- dataId: shared-seata.yaml # 共享seata配置修改application.yaml
server:
port: 28110
feign:
okhttp:
enabled: true # 开启OKHttp连接池支持
sentinel:
enabled: true # 开启Feign对Sentinel的整合
spring:
cloud:
sentinel:
transport:
dashboard: localhost:8090
http-method-specify: true # 开启请求方式前缀
hm:
swagger:
title: 支付服务接口文档
desc: 支付服务接口文档
package: com.hmall.pay.controller
db:
database: hm-payuser-service配置管理
引入依赖
<!--nacos配置管理-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-config</artifactId>
</dependency>
<!--读取bootstrap文件-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-bootstrap</artifactId>
</dependency>新建bootstrap.yaml
spring:
application:
name: user-service # 服务名称
profiles:
active: dev
cloud:
nacos:
server-addr: 127.0.0.1:8848 # nacos地址
config:
file-extension: yaml # 文件后缀名
shared-configs: # 共享配置
- dataId: shared-jdbc.yaml # 共享mybatis配置
- dataId: shared-log.yaml # 共享日志配置
- dataId: shared-swagger.yaml # 共享日志配置
- dataId: shared-seata.yaml # 共享seata配置修改application.yaml
server:
port: 28091
feign:
okhttp:
enabled: true # 开启OKHttp连接池支持
sentinel:
enabled: true # 开启Feign对Sentinel的整合
spring:
cloud:
sentinel:
transport:
dashboard: localhost:8090
http-method-specify: true # 开启请求方式前缀
hm:
swagger:
title: 用户服务接口文档
desc: 用户服务接口文档
package: com.hmall.user.controller
db:
database: hm-user
jwt:
location: classpath:hmall.jks
alias: hmall
password: hmall123
tokenTTL: 30m
auth:
excludePaths:
- /search/**
- /users/login
- /items/**
- /hi
# keytool -genkeypair -alias hmall -keyalg RSA -keypass hmall123 -keystore hmall.jks -storepass hmall123MQ
ElasticsSearch
Elasticsearch是由elastic公司开发的一套搜索引擎技术,它是elastic技术栈中的一部分。完整的技术栈包括:
- Elasticsearch:用于数据存储、计算和搜索
- Logstash/Beats:用于数据收集
- Kibana:用于数据可视化
Elasticsearch是提供核心的数据存储、搜索、分析功能的。
然后是Kibana,Elasticsearch对外提供的是Restful风格的API,任何操作都可以通过发送http请求来完成。不过http请求的方式、路径、还有请求参数的格式都有严格的规范。这些规范肯定记不住,因此要借助于Kibana这个服务。
Kibana是elastic公司提供的用于操作Elasticsearch的可视化控制台。它的功能非常强大,包括:
- 对Elasticsearch数据的搜索、展示
- 对Elasticsearch数据的统计、聚合,并形成图形化报表、图形
- 对Elasticsearch的集群状态监控
- 它还提供了一个开发控制台(DevTools),在其中对Elasticsearch的Restful的API接口提供了语法提示
安装
- elasticsearch:存储、搜索和运算
docker run -d \
--name es \
-e "ES_JAVA_OPTS=-Xms512m -Xmx512m" \
-e "discovery.type=single-node" \
-v es-data:/usr/share/elasticsearch/data \
-v es-plugins:/usr/share/elasticsearch/plugins \
--privileged \
--network hm-net \
-p 9200:9200 \
-p 9300:9300 \
elasticsearch:7.12.18以上版本的JavaAPI变化很大,在企业中应用并不广泛,企业中应用较多的还是8以下的版本
安装完成后,访问9200端口,即可看到响应的Elasticsearch服务的基本信息
- kibana:图形化展示
docker run -d \
--name kibana \
-e ELASTICSEARCH_HOSTS=http://es:9200 \
--network=hm-net \
-p 5601:5601 \
kibana:7.12.1
倒排索引
elasticsearch之所以有如此高性能的搜索表现,正是得益于底层的倒排索引技术
倒排索引的概念是基于MySQL这样的正向索引而言的
正向索引
例如有一张名为tb_goods的表:
| id | title | price |
|---|---|---|
| 1 | 小米手机 | 3499 |
| 2 | 华为手机 | 4999 |
| 3 | 华为小米充电器 | 49 |
| 4 | 小米手环 | 49 |
| ... | ... | ... |
其中的id字段已经创建了索引,由于索引底层采用了B+树结构,因此根据id搜索的速度会非常快。但是其他字段例如title,只在叶子节点上存在。
因此要根据title搜索的时候只能遍历树中的每一个叶子节点,判断title数据是否符合要求。
比如用户的SQL语句为:
select * from tb_goods where title like '%手机%';那搜索的大概流程如图:
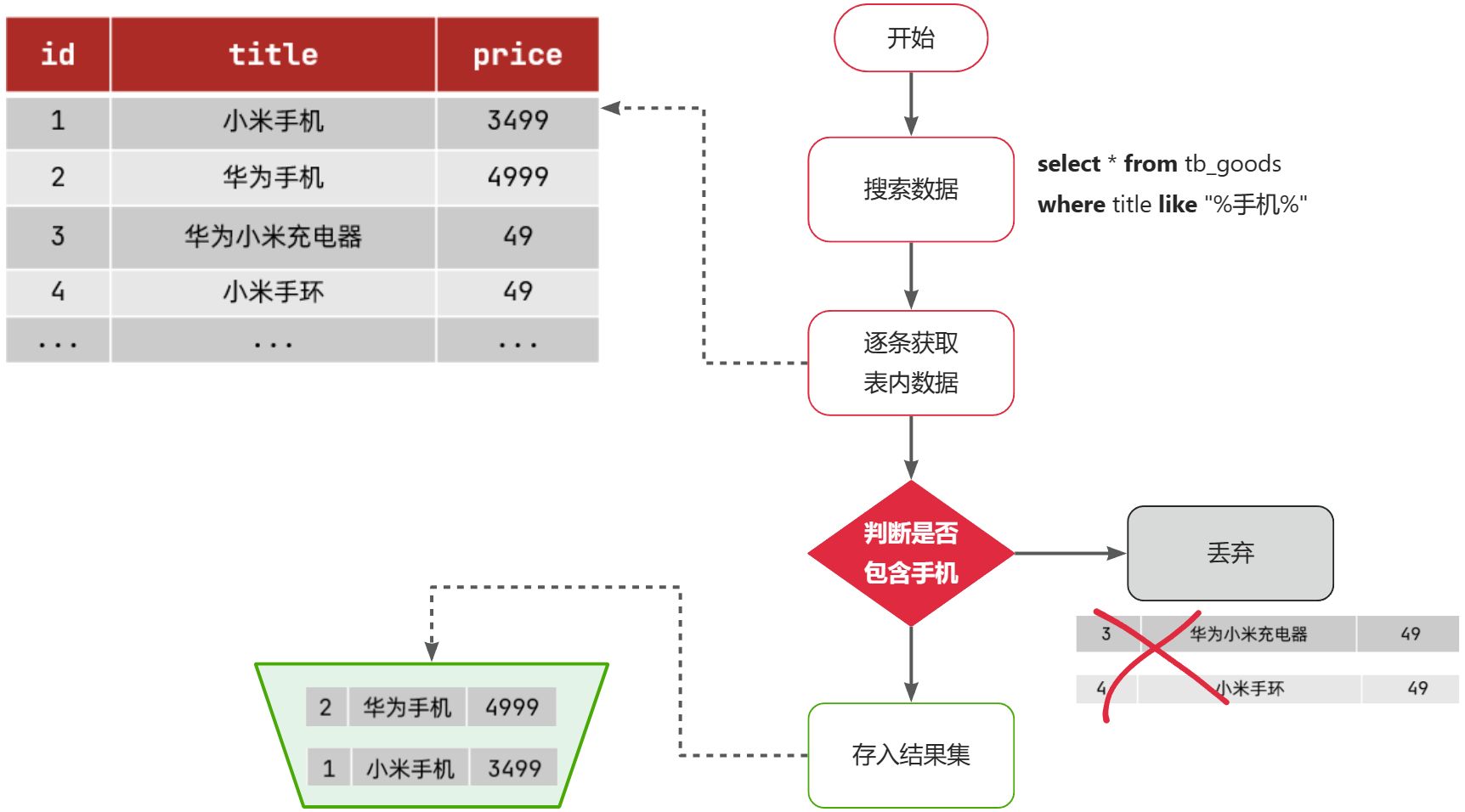
说明:
- 1)检查到搜索条件为
like '%手机%',需要找到title中包含手机的数据 - 2)逐条遍历每行数据(每个叶子节点),比如第1次拿到
id为1的数据 - 3)判断数据中的
title字段值是否符合条件 - 4)如果符合则放入结果集,不符合则丢弃
- 5)回到步骤1
综上,根据id精确匹配时,可以走索引,查询效率较高。而当搜索条件为模糊匹配时,由于索引无法生效,导致从索引查询退化为全表扫描,效率很差。
因此,正向索引适合于根据索引字段的精确搜索,不适合基于部分词条的模糊匹配。
而倒排索引恰好解决的就是根据部分词条模糊匹配的问题。
倒排索引
倒排索引中有两个非常重要的概念:
- 文档(
Document):用来搜索的数据,其中的每一条数据就是一个文档。例如一个网页、一个商品信息 - 词条(
Term):对文档数据或用户搜索数据,利用某种算法分词,得到的具备含义的词语就是词条。例如:我是中国人,就可以分为:我、是、中国人、中国、国人这样的几个词条
创建倒排索引是对正向索引的一种特殊处理和应用,流程如下:
- 将每一个文档的数据利用分词算法根据语义拆分,得到一个个词条
- 创建表,每行数据包括词条、词条所在文档id、位置等信息
- 因为词条唯一性,可以给词条创建正向索引
此时形成的这张以词条为索引的表,就是倒排索引表,两者对比如下:
正向索引
| id(索引) | title | price |
|---|---|---|
| 1 | 小米手机 | 3499 |
| 2 | 华为手机 | 4999 |
| 3 | 华为小米充电器 | 49 |
| 4 | 小米手环 | 49 |
| ... | ... | ... |
倒排索引
| 词条(索引) | 文档id |
|---|---|
| 小米 | 1,3,4 |
| 手机 | 1,2 |
| 华为 | 2,3 |
| 充电器 | 3 |
| 手环 | 4 |
倒排索引的搜索流程如下(以搜索"华为手机"为例),如图:
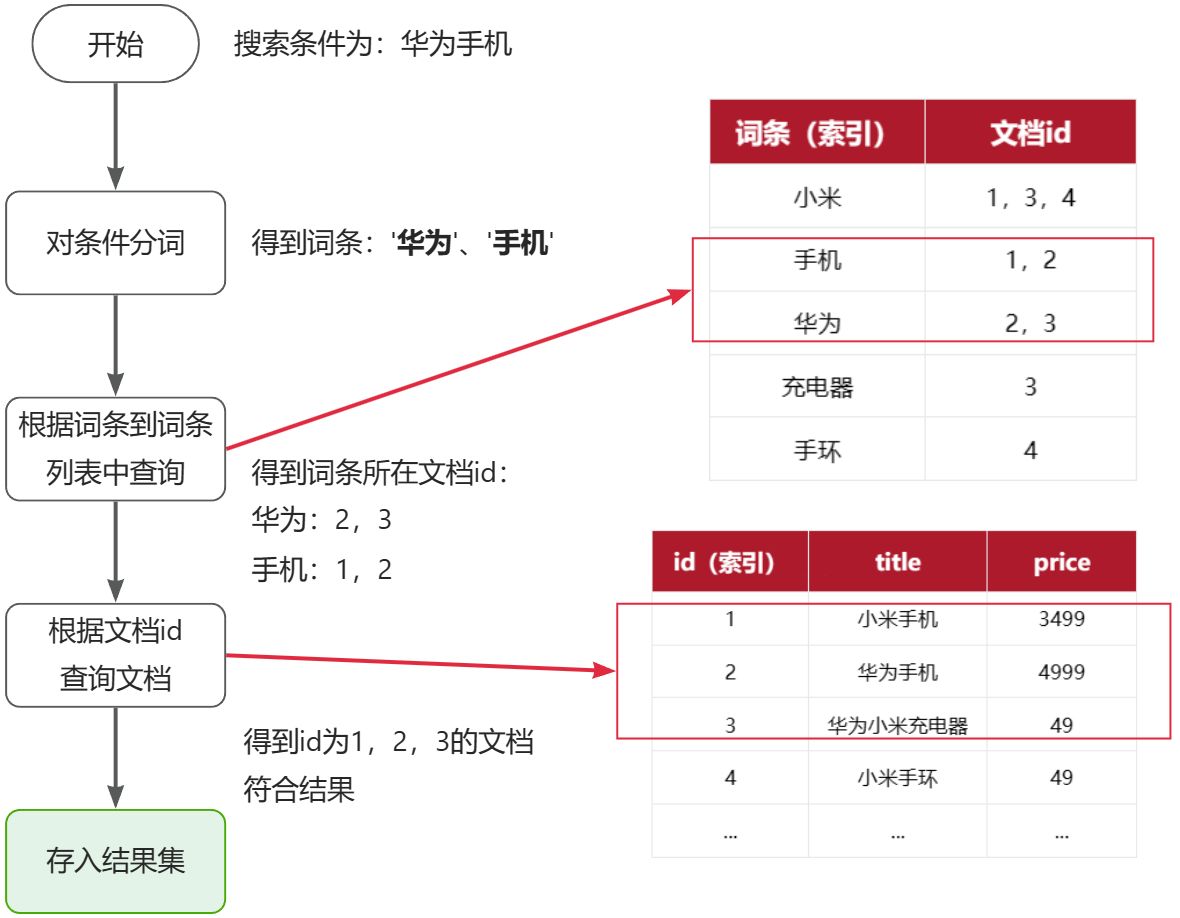
流程描述:
1)用户输入条件"华为手机"进行搜索。
2)对用户输入条件分词,得到词条:华为、手机。
3)拿着词条在倒排索引中查找(由于词条有索引,查询效率很高),即可得到包含词条的文档id:1、2、3。
4)拿着文档id到正向索引中查找具体文档即可(由于id也有索引,查询效率也很高)。
虽然要先查询倒排索引,再查询倒排索引,但是无论是词条、还是文档id都建立了索引,查询速度非常快!无需全表扫描。
- 正向索引是最传统的,根据id索引的方式。但根据词条查询时,必须先逐条获取每个文档,然后判断文档中是否包含所需要的词条,是根据文档找词条的过程。
- 而倒排索引则相反,是先找到用户要搜索的词条,根据词条得到保护词条的文档的id,然后根据id获取文档。是根据词条找文档的过程。
正向索引:
- 优点:
- 可以给多个字段创建索引
- 根据索引字段搜索、排序速度非常快
- 缺点:
- 根据非索引字段,或者索引字段中的部分词条查找时,只能全表扫描。
倒排索引:
- 优点:
- 根据词条搜索、模糊搜索时,速度非常快
- 缺点:
- 只能给词条创建索引,而不是字段
- 无法根据字段做排序
mysql与elasticsearch
把mysql与elasticsearch的概念做一下对比:
| MySQL | Elasticsearch | 说明 |
|---|---|---|
| Table | Index | 索引(index),就是文档的集合,类似数据库的表(table) |
| Row | Document | 文档(Document),就是一条条的数据,类似数据库中的行(Row),文档都是JSON格式 |
| Column | Field | 字段(Field),就是JSON文档中的字段,类似数据库中的列(Column) |
| Schema | Mapping | Mapping(映射)是索引中文档的约束,例如字段类型约束。类似数据库的表结构(Schema) |
| SQL | DSL | DSL是elasticsearch提供的JSON风格的请求语句,用来操作elasticsearch,实现CRUD |
如图:
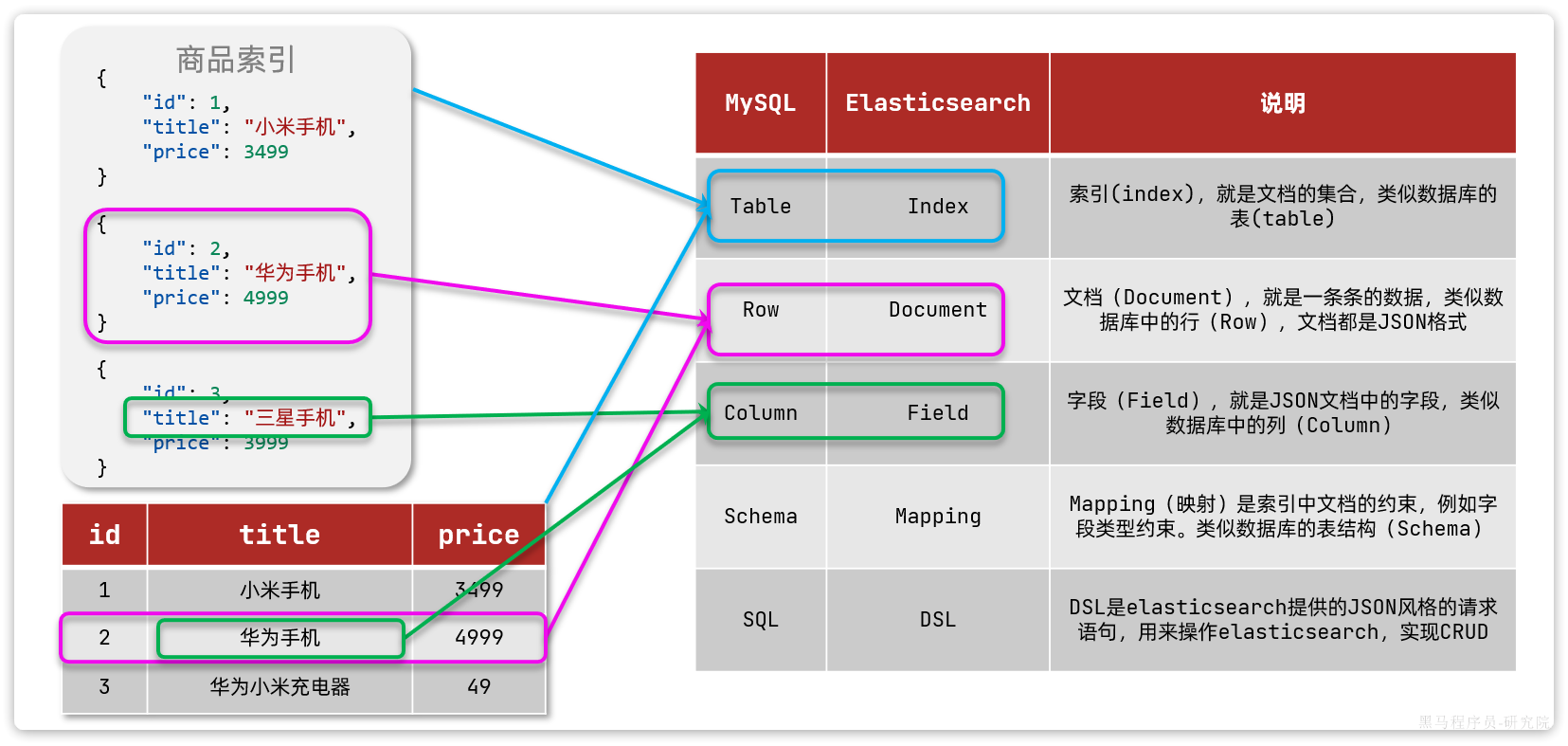
两者各自有自己的擅长之处:
- Mysql:擅长事务类型操作,可以确保数据的安全和一致性
- Elasticsearch:擅长海量数据的搜索、分析、计算
因此在企业中,往往是两者结合使用:
- 对安全性要求较高的写操作,使用mysql实现
- 对查询性能要求较高的搜索需求,使用elasticsearch实现
- 两者再基于某种方式,实现数据的同步,保证一致性
IK分词器
安装ik分词器插件
法一:
查看挂载路径
(base) root@LAPTOP-L6QS5167:~# docker volume ls
DRIVER VOLUME NAME
local es-data
local es-plugins
(base) root@LAPTOP-L6QS5167:~# docker inspect es-plugins
[
{
"CreatedAt": "2024-05-27T14:14:10+08:00",
"Driver": "local",
"Labels": null,
"Mountpoint": "/var/lib/docker/volumes/es-plugins/_data",
"Name": "es-plugins",
"Options": null,
"Scope": "local"
}
]把插件放在该路径下
docker restart es方法二:
docker exec -it es ./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.12.1/elasticsearch-analysis-ik-7.12.1.zipdocker restart es使用ik分词器
默认模式是standard,对英文效果不错,中文全是单个字
IK分词器包含两种模式:
ik_smart:智能语义切分ik_max_word:最细粒度切分
ik_smart
ik_max_word
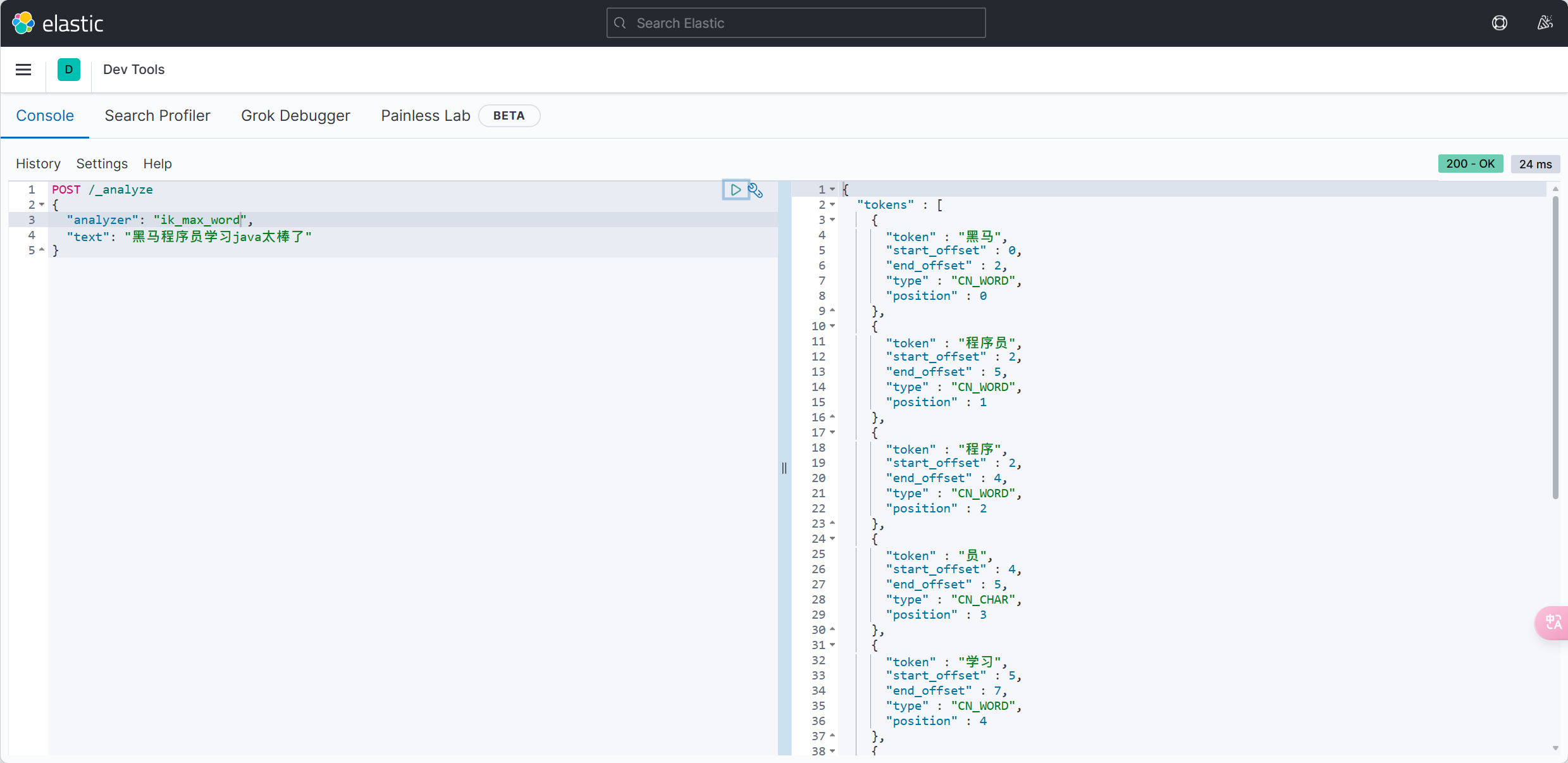
添加自定义词库
默认词典只到2012年
所以要想正确分词,IK分词器的词库也需要不断的更新,IK分词器提供了扩展词汇的功能。
1)打开IK分词器config目录:
注意,如果采用在线安装的通过,默认是没有config目录的,需要把课前资料提供的ik下的config上传至对应目录。
2)在IKAnalyzer.cfg.xml配置文件内容添加:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict">ext.dic</entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords"></entry>
<!--用户可以在这里配置远程扩展字典 -->
<!-- <entry key="remote_ext_dict">words_location</entry> -->
<!--用户可以在这里配置远程扩展停止词字典-->
<!-- <entry key="remote_ext_stopwords">words_location</entry> -->
</properties>3)在IK分词器的config目录新建一个 ext.dic,可以参考config目录下复制一个配置文件进行修改


传智播客
泰裤辣4)重启elasticsearch
docker restart es
# 查看 日志
docker logs -f es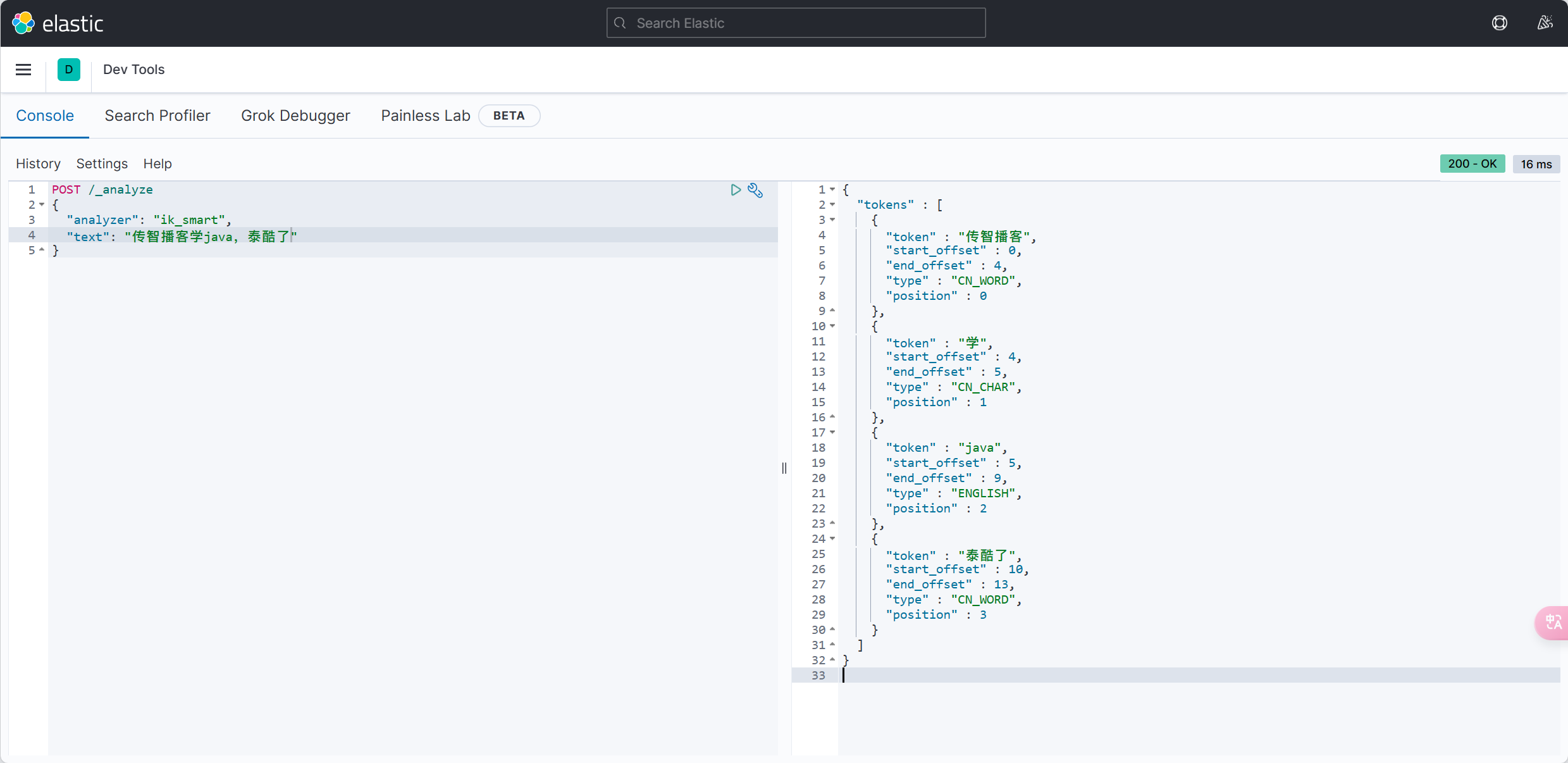
基础概念
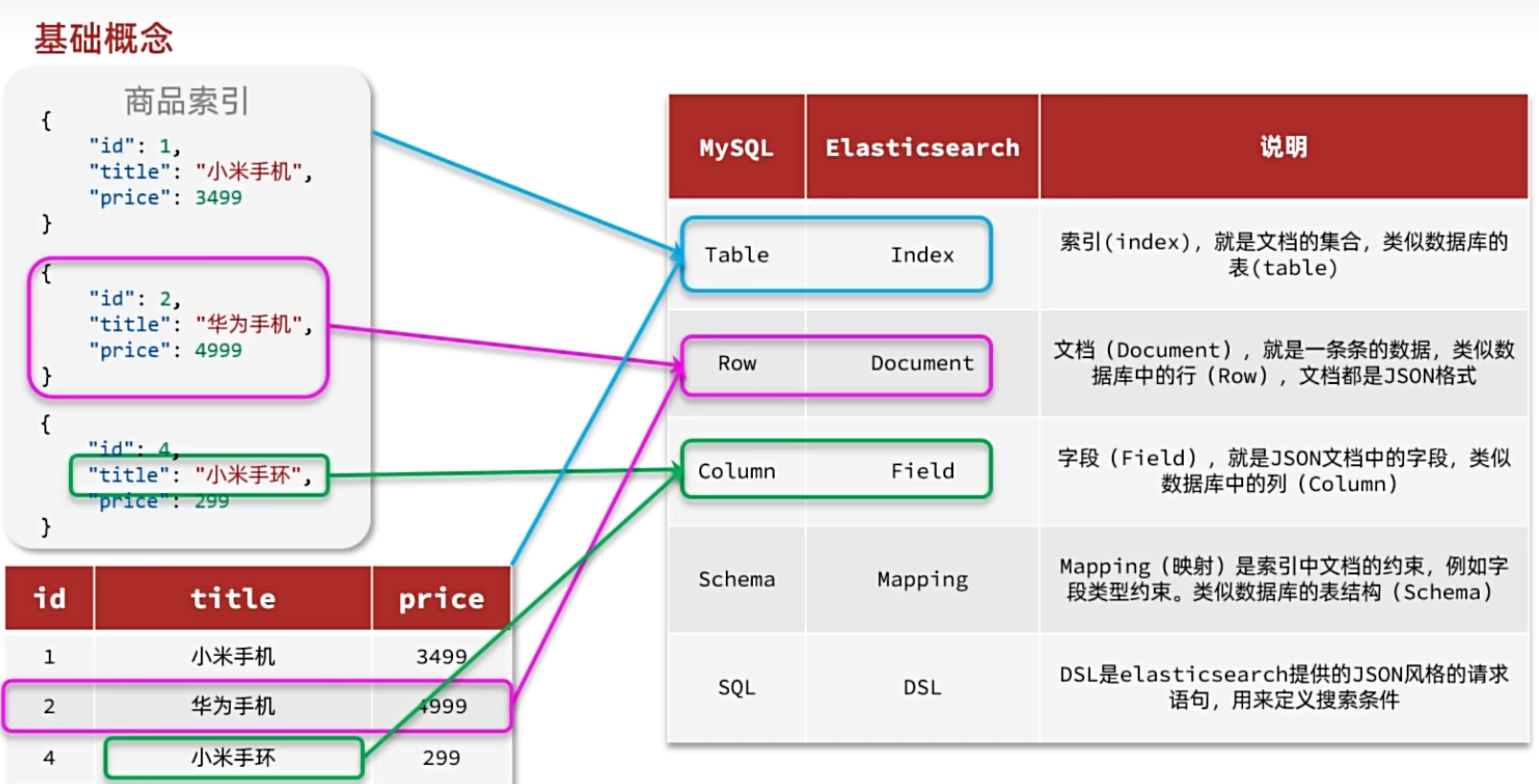
索引库操作
Index就类似数据库表,Mapping映射就类似表的结构。要向es中存储数据,必须先创建Index和Mapping
Mapping映射属性
Mapping是对索引库中文档的约束,常见的Mapping属性包括:
type:字段数据类型,常见的简单类型有:- 字符串:
text(可分词的文本)、keyword(精确值,例如:品牌、国家、ip地址) - 数值:
long、integer、short、byte、double、float、 - 布尔:
boolean - 日期:
date - 对象:
object
- 字符串:
index:是否创建索引,默认为trueanalyzer:使用哪种分词器properties:该字段的子字段
{
"age": 21,
"weight": 52.1,
"isMarried": false,
"info": "黑马程序员Java讲师",
"email": "[email protected]",
"score": [99.1, 99.5, 98.9],
"name": {
"firstName": "云",
"lastName": "赵"
}
}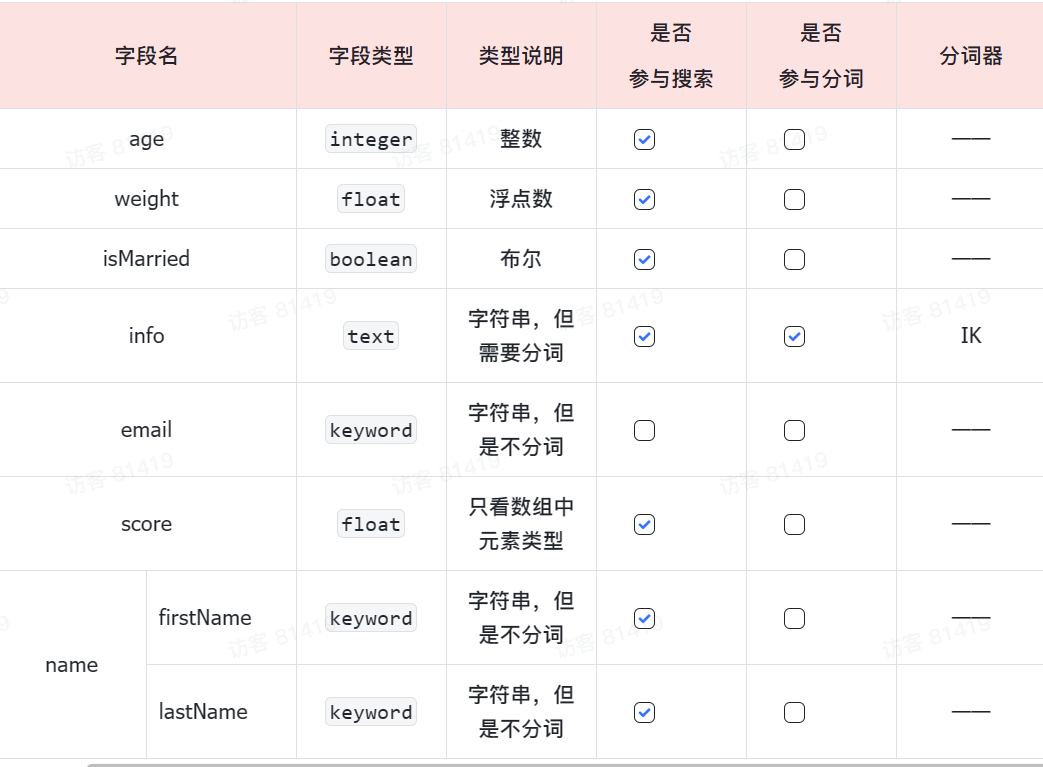
索引库的CRUD
Elasticsearch采用的是Restful风格的API,因此其请求方式和路径相对都比较规范,而且请求参数也都采用JSON风格。
创建索引库和映射
基本语法:
- 请求方式:
PUT - 请求路径:
/索引库名,可以自定义 - 请求参数:
mapping映射
index默认为treu
PUT /索引库名称
{
"mappings": {
"properties": {
"字段名":{
"type": "text",
"analyzer": "ik_smart"
},
"字段名2":{
"type": "keyword",
"index": "false"
},
"字段名3":{
"properties": {
"子字段": {
"type": "keyword"
}
}
},
// ...略
}
}
}PUT /heima
{
"mappings": {
"properties": {
"info":{
"type": "text",
"analyzer": "ik_smart"
},
"email":{
"type": "keyword",
"index": "false"
},
"name":{
"properties": {
"firstName": {
"type": "keyword"
}
}
}
}
}
}
查询索引库
基本语法:
- 请求方式:GET
- 请求路径:/索引库名
- 请求参数:无
GET /索引库名GET /heima
修改索引库
倒排索引结构虽然不复杂,但是一旦数据结构改变(比如改变了分词器),就需要重新创建倒排索引,这简直是灾难。因此索引库一旦创建,无法修改mapping。
虽然无法修改mapping中已有的字段,但是却允许添加新的字段到mapping中,因为不会对倒排索引产生影响。因此修改索引库能做的就是向索引库中添加新字段,或者更新索引库的基础属性。
PUT /索引库名/_mapping
{
"properties": {
"新字段名":{
"type": "integer"
}
}
}PUT /heima/_mapping
{
"properties": {
"age":{
"type": "integer"
}
}
}
删除索引库
语法:
- 请求方式:DELETE
- 请求路径:/索引库名
- 请求参数:无
DELETE /索引库名DELETE /heima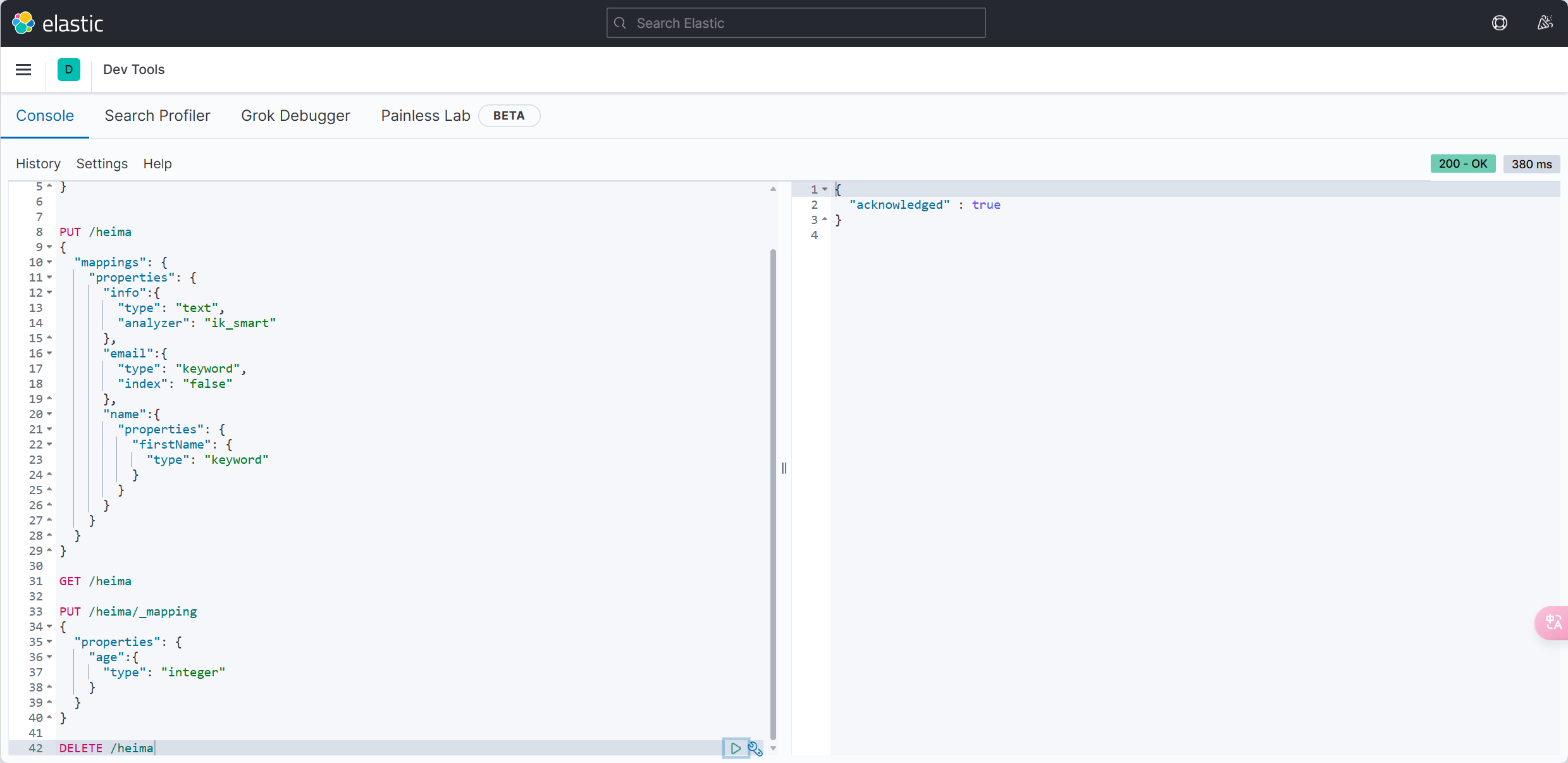
文档操作(对应数据库的一条数据)
CRUD
新增文档
POST /索引库名/_doc/文档id
{
"字段1": "值1",
"字段2": "值2",
"字段3": {
"子属性1": "值3",
"子属性2": "值4"
},
}POST /heima/_doc/1
{
"info": "黑马程序员Java讲师",
"email": "[email protected]",
"name": {
"firstName": "云",
"lastName": "赵"
}
}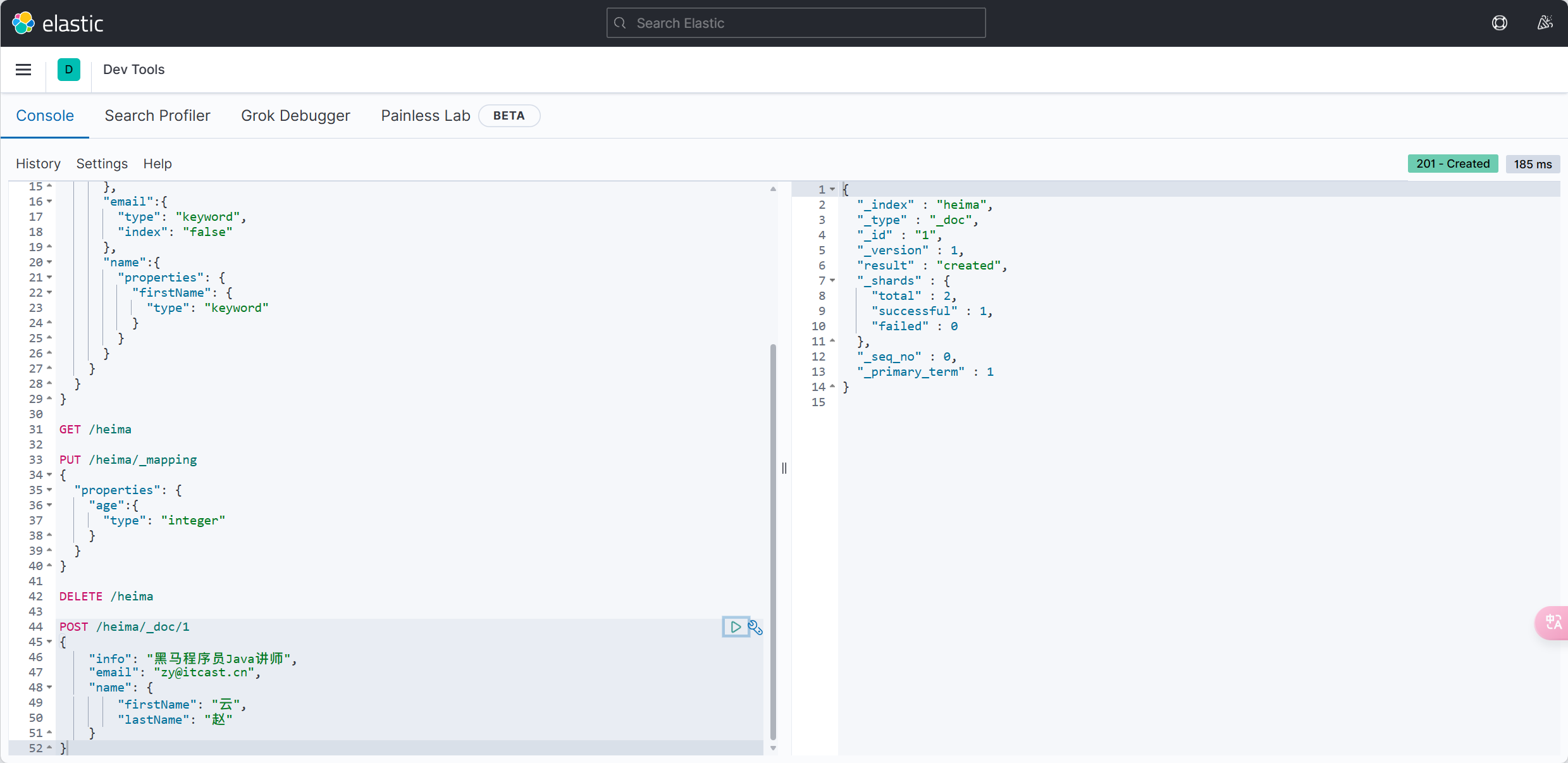
查询文档
GET /{索引库名称}/_doc/{id}GET /heima/_doc/1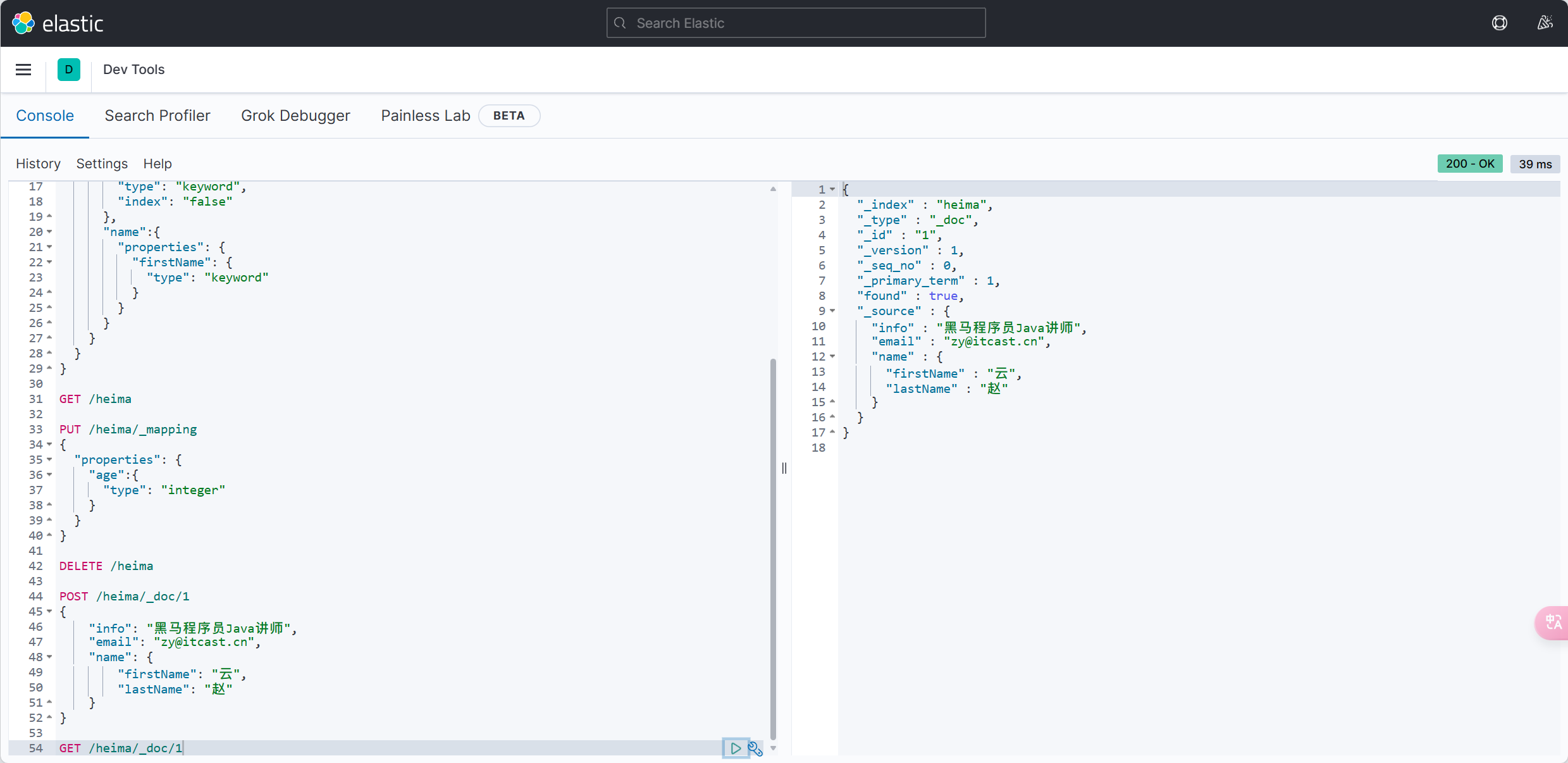
删除文档
DELETE /{索引库名}/_doc/id值DELETE /heima/_doc/1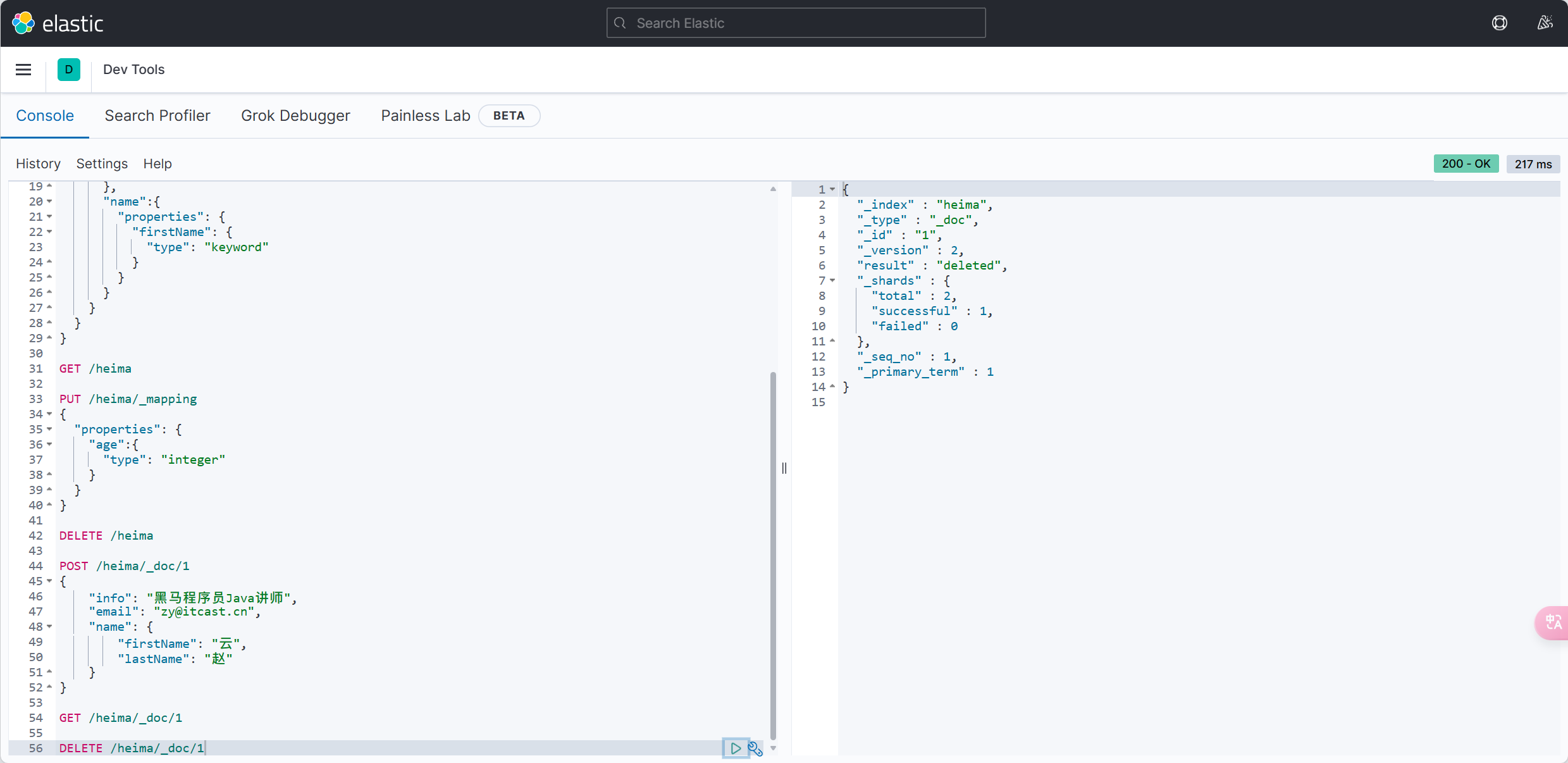
修改文档
全量修改
全量修改是覆盖原来的文档,其本质是两步操作:
- 根据指定的id删除文档
- 新增一个相同id的文档
注意:如果根据id删除时,id不存在,第二步的新增也会执行,也就从修改变成了新增操作了。
PUT /{索引库名}/_doc/文档id
{
"字段1": "值1",
"字段2": "值2",
// ... 略
}PUT /heima/_doc/1
{
"info": "黑马程序员高级Java讲师",
"email": "[email protected]",
"name": {
"firstName": "云",
"lastName": "赵"
}
}局部修改
局部修改是只修改指定id匹配的文档中的部分字段。
POST /{索引库名}/_update/文档id
{
"doc": {
"字段名": "新的值",
}
}POST /heima/_update/1
{
"doc": {
"email": "[email protected]"
}
}批处理
批处理采用POST请求
新增、更新两行为原来的一个
不能换行,要写在一行里
POST _bulk
{ "index" : { "_index" : "test", "_id" : "1" } }
{ "field1" : "value1" }
{ "delete" : { "_index" : "test", "_id" : "2" } }
{ "create" : { "_index" : "test", "_id" : "3" } }
{ "field1" : "value3" }
{ "update" : {"_id" : "1", "_index" : "test"} }
{ "doc" : {"field2" : "value2"} }其中:
index代表新增操作_index:指定索引库名_id指定要操作的文档id{ "field1" : "value1" }:则是要新增的文档内容
delete代表删除操作_index:指定索引库名_id指定要操作的文档id
update代表更新操作_index:指定索引库名_id指定要操作的文档id{ "doc" : {"field2" : "value2"} }:要更新的文档字段
批量新增:
POST /_bulk
{"index": {"_index":"heima", "_id": "3"}}
{"info": "黑马程序员C++讲师", "email": "[email protected]", "name":{"firstName": "五", "lastName":"王"}}
{"index": {"_index":"heima", "_id": "4"}}
{"info": "黑马程序员前端讲师", "email": "[email protected]", "name":{"firstName": "三", "lastName":"张"}}批量删除:
POST /_bulk
{"delete":{"_index":"heima", "_id": "3"}}
{"delete":{"_index":"heima", "_id": "4"}}总结
- 创建文档:
POST /{索引库名}/_doc/文档id { json文档 } - 查询文档:
GET /{索引库名}/_doc/文档id - 删除文档:
DELETE /{索引库名}/_doc/文档id - 修改文档:
- 全量修改:
PUT /{索引库名}/_doc/文档id { json文档 } - 局部修改:
POST /{索引库名}/_update/文档id { "doc": {字段}}
- 全量修改:
JavaRestClient
采用的是7.12版本
[Quick start | Elasticsearch Guide 8.13] | Elastic
初始化RestClient
在item-service模块中引入es的RestHighLevelClient依赖
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
</dependency>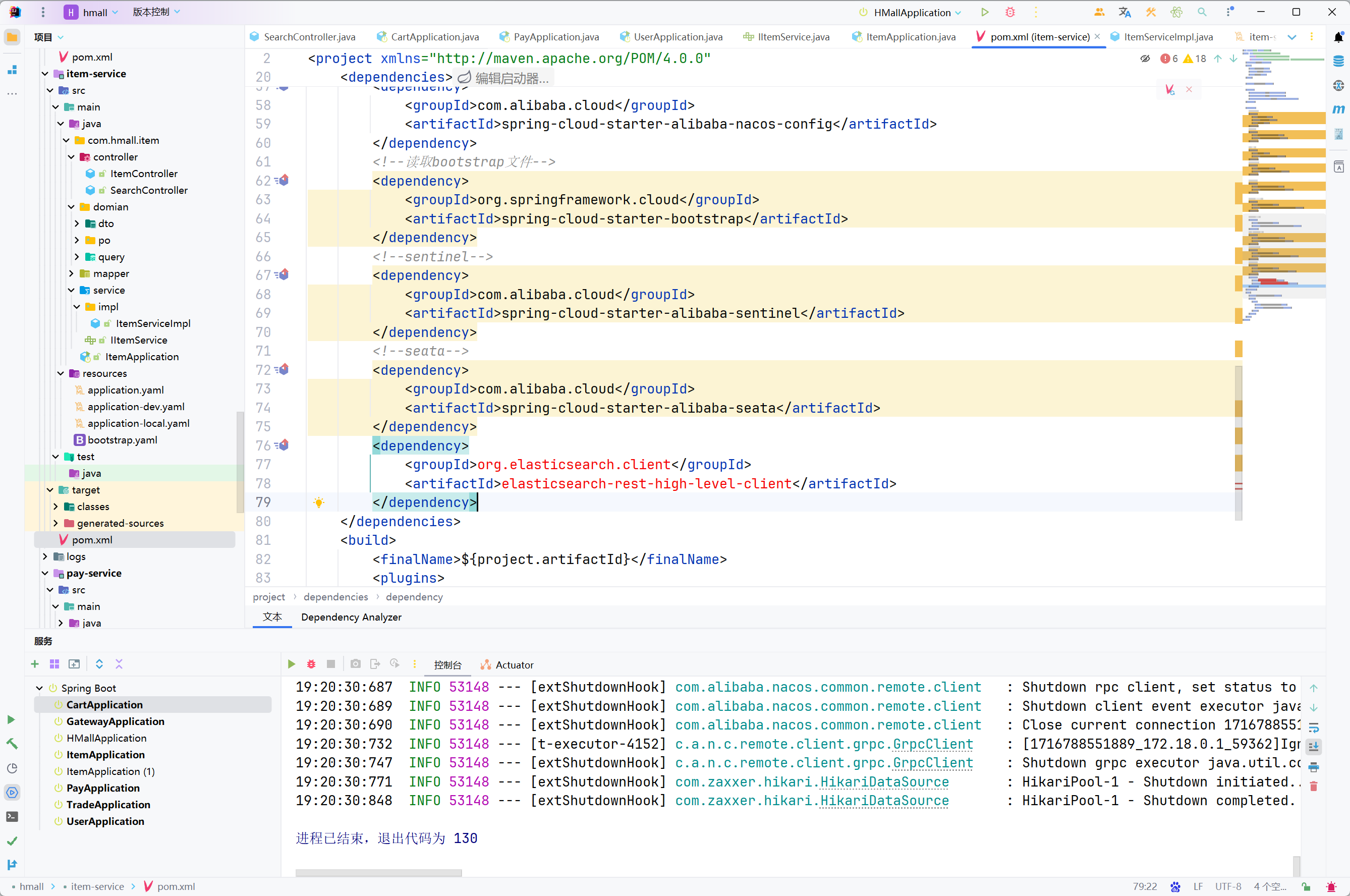
因为SpringBoot默认的ES版本是7.17.10,所以需要覆盖默认的ES版本
父工程的pom.xml
<properties>
<maven.compiler.source>11</maven.compiler.source>
<maven.compiler.target>11</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
<org.projectlombok.version>1.18.20</org.projectlombok.version>
<spring-cloud.version>2021.0.3</spring-cloud.version>
<spring-cloud-alibaba.version>2021.0.4.0</spring-cloud-alibaba.version>
<mybatis-plus.version>3.4.3</mybatis-plus.version>
<hutool.version>5.8.11</hutool.version>
<mysql.version>8.0.23</mysql.version>
<elasticsearch.version>7.12.1</elasticsearch.version>
</properties>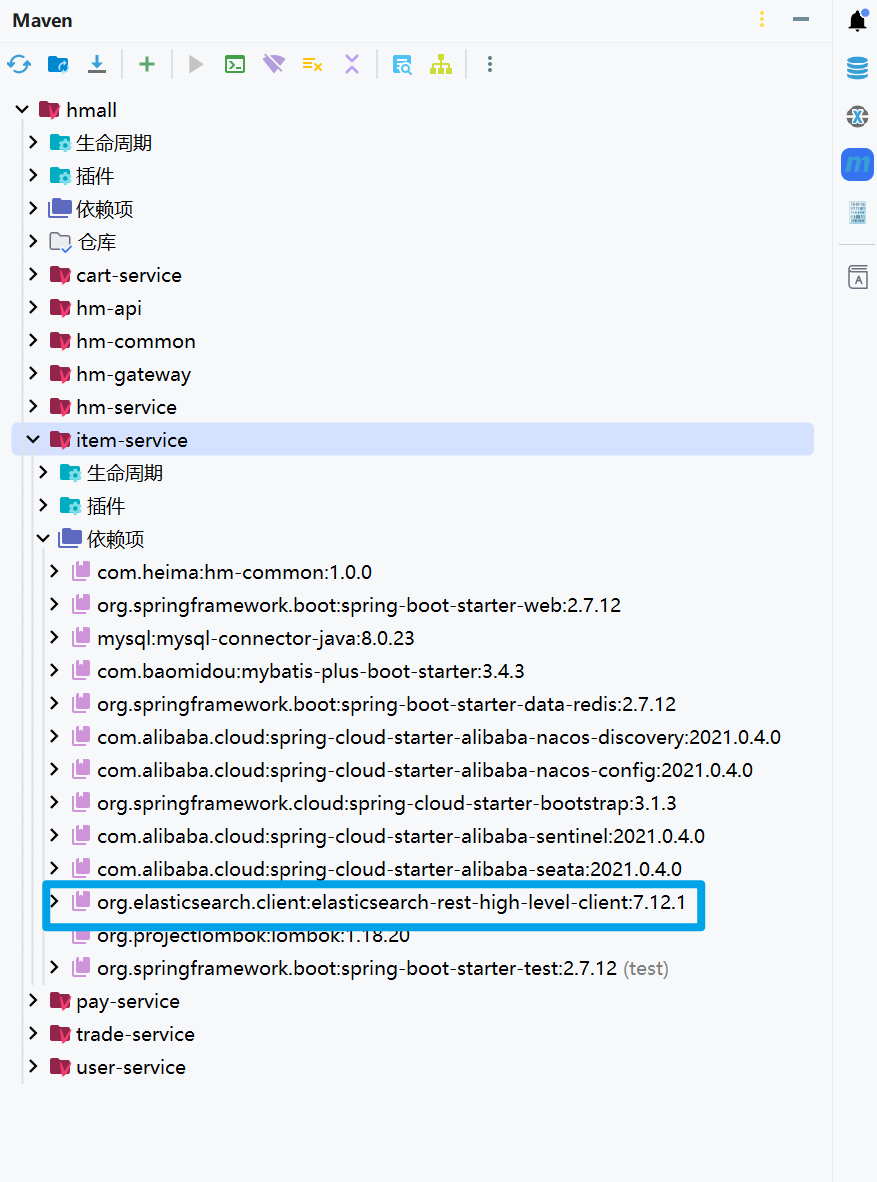
初始化RestHighLevelClient
RestHighLevelClient client = new RestHighLevelClient(RestClient.builder(
HttpHost.create("http://192.168.150.101:9200")
));单元测试
要放到相同包或者子包中,不然找不到
package com.hmall.item.es;
import org.apache.http.HttpHost;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.junit.jupiter.api.AfterEach;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
/**
* @author:CharmingDaiDai
* @project:hmall @since:2024/5/27 下午9:22
*/
public class ESTest {
private RestHighLevelClient client;
@Test
void testConnection() {
System.out.println("client = " + client);
}
@BeforeEach
void setUp() throws Exception {
client = new RestHighLevelClient(RestClient.builder(HttpHost.create("http://127.0.0.1:9200")));
}
@AfterEach
void tearDown() throws Exception {
if (client != null){
client.close();
}
}
}
商品Mapping映射
搜索页面的效果如图所示:
实现搜索功能需要的字段包括三大部分:
- 搜索过滤字段
- 分类
- 品牌
- 价格
- 排序字段
- 默认:按照更新时间降序排序
- 销量
- 价格
- 展示字段
- 商品id:用于点击后跳转
- 图片地址
- 是否是广告推广商品
- 名称
- 价格
- 评价数量
- 销量
对应的商品表结构如下,索引库无关字段已经划掉:
结合数据库表结构,以上字段对应的mapping映射属性如下:
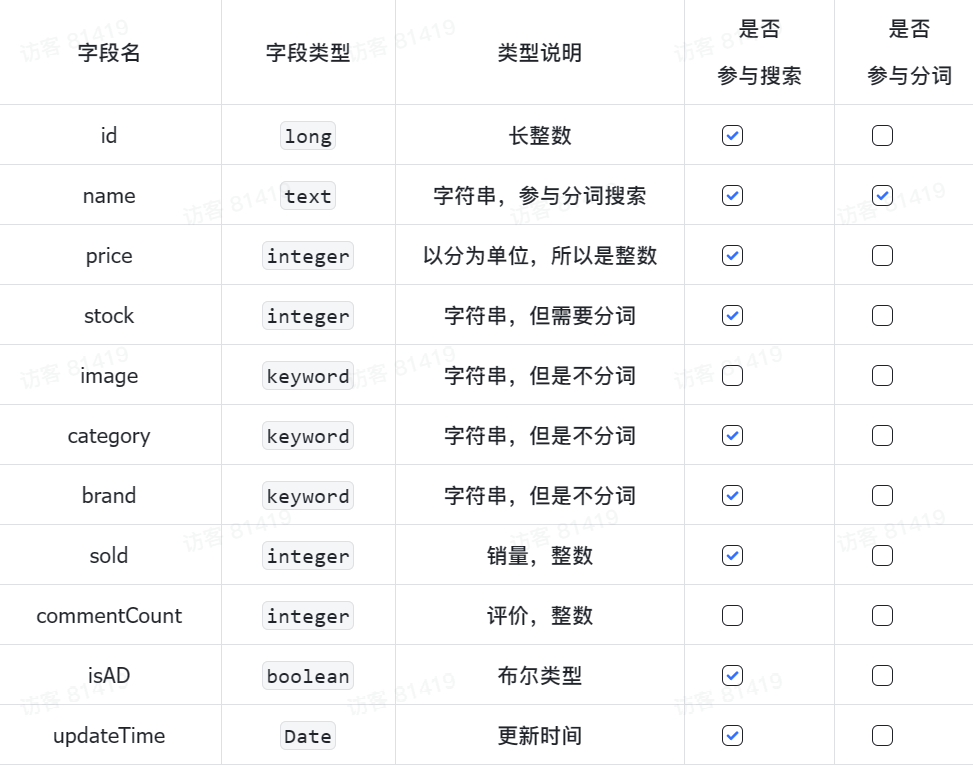
最终的索引库文档结构
PUT /items
{
"mappings": {
"properties": {
"id": {
"type": "keyword"
},
"name":{
"type": "text",
"analyzer": "ik_max_word"
},
"price":{
"type": "integer"
},
"stock":{
"type": "integer"
},
"image":{
"type": "keyword",
"index": false
},
"category":{
"type": "keyword"
},
"brand":{
"type": "keyword"
},
"sold":{
"type": "integer"
},
"commentCount":{
"type": "integer",
"index": false
},
"isAD":{
"type": "boolean"
},
"updateTime":{
"type": "date"
}
}
}
}创建索引
创建索引库的API:
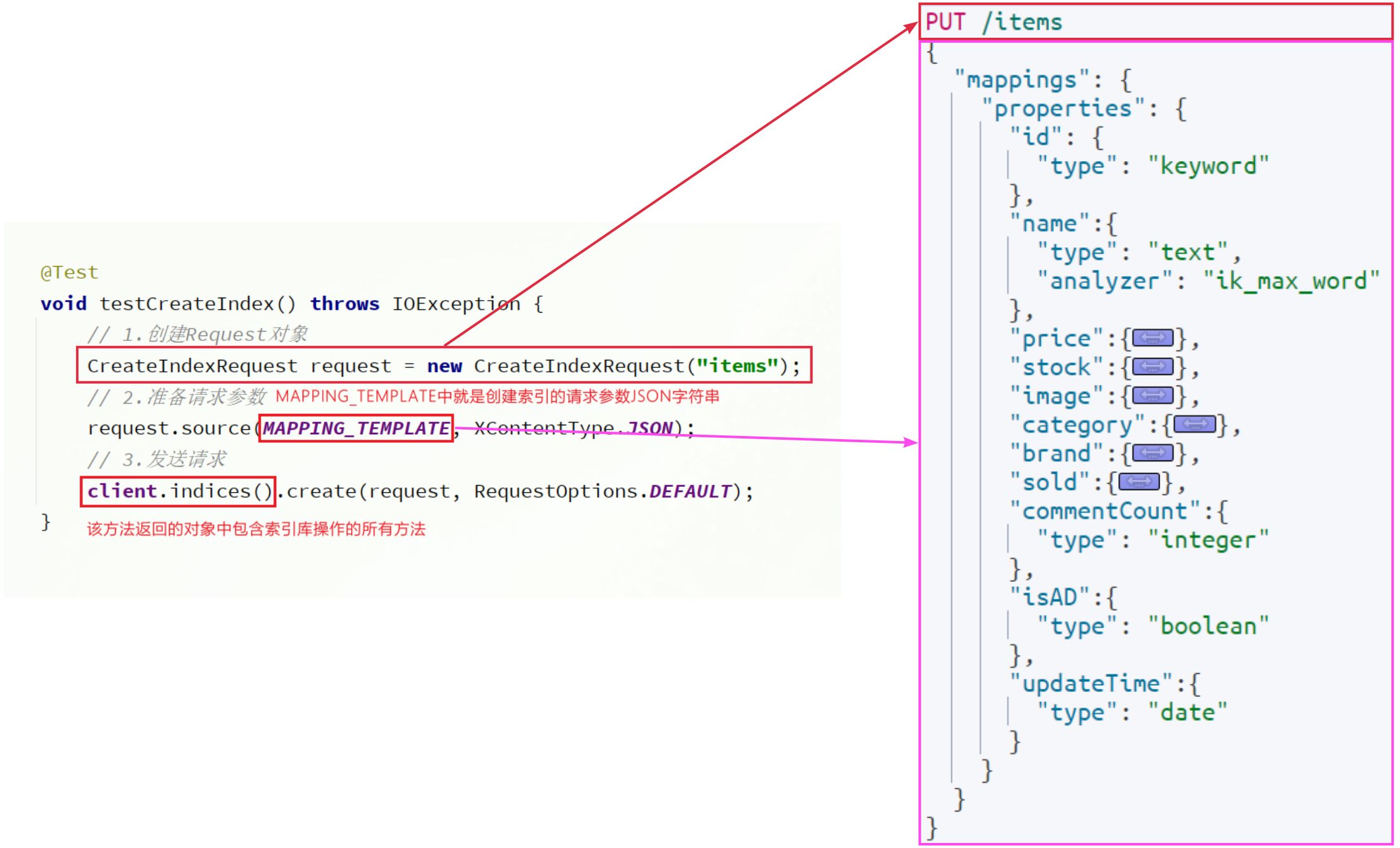
- 1)创建Request对象。
- 因为是创建索引库的操作,因此Request是
CreateIndexRequest。
- 因为是创建索引库的操作,因此Request是
- 2)添加请求参数
- Json格式的Mapping映射参数。因为json字符串很长,这里是定义了静态字符串常量
MAPPING_TEMPLATE,让代码看起来更加优雅。
- Json格式的Mapping映射参数。因为json字符串很长,这里是定义了静态字符串常量
- 3)发送请求
client.indices()方法的返回值是IndicesClient类型,封装了所有与索引库操作有关的方法。例如创建索引、删除索引、判断索引是否存在等
测试
package com.hmall.item.es;
import org.apache.http.HttpHost;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.client.indices.CreateIndexRequest;
import org.elasticsearch.common.xcontent.XContentType;
import org.junit.jupiter.api.AfterEach;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
import java.io.IOException;
/**
* @author:CharmingDaiDai
* @project:hmall @since:2024/5/27 下午9:22
*/
public class ESTest {
private RestHighLevelClient client;
@Test
void testConnection() {
System.out.println("client = " + client);
}
@Test
void testCreateIndex() throws IOException {
CreateIndexRequest request = new CreateIndexRequest("items");
request.source(MAPPING_TEMPLATE, XContentType.JSON);
client.indices().create(request, RequestOptions.DEFAULT);
}
@BeforeEach
void setUp() throws Exception {
client = new RestHighLevelClient(RestClient.builder(HttpHost.create("http://127.0.0.1:9200")));
}
@AfterEach
void tearDown() throws Exception {
if (client != null){
client.close();
}
}
static final String MAPPING_TEMPLATE = "{\n" +
" \"mappings\": {\n" +
" \"properties\": {\n" +
" \"id\": {\n" +
" \"type\": \"keyword\"\n" +
" },\n" +
" \"name\":{\n" +
" \"type\": \"text\",\n" +
" \"analyzer\": \"ik_max_word\"\n" +
" },\n" +
" \"price\":{\n" +
" \"type\": \"integer\"\n" +
" },\n" +
" \"stock\":{\n" +
" \"type\": \"integer\"\n" +
" },\n" +
" \"image\":{\n" +
" \"type\": \"keyword\",\n" +
" \"index\": false\n" +
" },\n" +
" \"category\":{\n" +
" \"type\": \"keyword\"\n" +
" },\n" +
" \"brand\":{\n" +
" \"type\": \"keyword\"\n" +
" },\n" +
" \"sold\":{\n" +
" \"type\": \"integer\"\n" +
" },\n" +
" \"commentCount\":{\n" +
" \"type\": \"integer\"\n" +
" },\n" +
" \"isAD\":{\n" +
" \"type\": \"boolean\"\n" +
" },\n" +
" \"updateTime\":{\n" +
" \"type\": \"date\"\n" +
" }\n" +
" }\n" +
" }\n" +
"}";
}
删除索引
- 请求方式从PUT变为DELTE
- 请求路径不变
- 无请求参数
@Test
void testDeleteIndex() throws IOException {
// 1.创建Request对象
DeleteIndexRequest request = new DeleteIndexRequest("items");
// 2.发送请求
client.indices().delete(request, RequestOptions.DEFAULT);
}

判断索引库是否存在
- 1)创建Request对象。这次是GetIndexRequest对象
- 2)准备参数。这里是无参,直接省略
- 3)发送请求。改用exists方法
@Test
void testExistsIndex() throws IOException {
// 1.创建Request对象
GetIndexRequest request = new GetIndexRequest("items");
// 2.发送请求
boolean exists = client.indices().exists(request, RequestOptions.DEFAULT);
// 3.输出
System.err.println(exists ? "索引库已经存在!" : "索引库不存在!");
}JavaRestClient操作elasticsearch的流程基本类似。核心是client.indices()方法来获取索引库的操作对象。
索引库操作的基本步骤:
- 初始化
RestHighLevelClient - 创建XxxIndexRequest。XXX是
Create、Get、Delete - 准备请求参数(
Create时需要,其它是无参,可以省略) - 发送请求。调用
RestHighLevelClient#indices().xxx()方法,xxx是create、exists、delete

新增文档
新增ItemDoc po类
package com.hmall.item.domian.po;
import io.swagger.annotations.ApiModel;
import io.swagger.annotations.ApiModelProperty;
import lombok.Data;
import java.time.LocalDateTime;
/**
* @author:CharmingDaiDai
* @project:hmall
* @since:2024/5/28 下午12:55
*/
@Data
@ApiModel(description = "索引库实体")
public class ItemDoc{
@ApiModelProperty("商品id")
private String id;
@ApiModelProperty("商品名称")
private String name;
@ApiModelProperty("价格(分)")
private Integer price;
@ApiModelProperty("商品图片")
private String image;
@ApiModelProperty("类目名称")
private String category;
@ApiModelProperty("品牌名称")
private String brand;
@ApiModelProperty("销量")
private Integer sold;
@ApiModelProperty("评论数")
private Integer commentCount;
@ApiModelProperty("是否是推广广告,true/false")
private Boolean isAD;
@ApiModelProperty("更新时间")
private LocalDateTime updateTime;
}读取一条数据库数据,转换对象格式,转为json字符串,发送请求
package com.hmall.item.es;
import java.io.IOException;
import cn.hutool.core.bean.BeanUtil;
import cn.hutool.json.JSONUtil;
import com.hmall.item.domian.po.Item;
import com.hmall.item.domian.po.ItemDoc;
import com.hmall.item.service.IItemService;
import org.apache.http.HttpHost;
import org.elasticsearch.action.admin.indices.delete.DeleteIndexRequest;
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.client.indices.CreateIndexRequest;
import org.elasticsearch.client.indices.GetIndexRequest;
import org.elasticsearch.common.xcontent.XContentType;
import org.junit.jupiter.api.AfterEach;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
import org.springframework.boot.test.context.SpringBootTest;
import javax.annotation.Resource;
/**
* ESDocTest 类用于测试 Elasticsearch 文档的插入操作
*
* @author:CharmingDaiDai
* @project:hmall
* @since:2024/5/27 下午9:22
*/
@SpringBootTest(properties = "spring.profiles.active=local")
public class ESDocTest {
private RestHighLevelClient client;
@Resource
private IItemService itemService;
/**
* 测试方法,用于插入文档到 Elasticsearch
*/
@Test
void testInsertDoc() throws IOException {
// 根据 ID 获取 Item 对象
Item item = itemService.getById(100000011127L);
// 将 Item 对象转换为 ItemDoc 对象
ItemDoc itemDoc = BeanUtil.copyProperties(item, ItemDoc.class);
// 将 ItemDoc 对象转换为 JSON 字符串
String jsonStr = JSONUtil.toJsonStr(itemDoc);
// 创建索引请求,指定索引名称为 "item" 并设置文档 ID
IndexRequest request = new IndexRequest("item").id(itemDoc.getId());
// 设置请求源为 JSON 字符串
request.source(jsonStr, XContentType.JSON);
// 执行索引请求,将文档插入到 Elasticsearch 中
client.index(request, RequestOptions.DEFAULT);
}
/**
* 在每个测试方法执行前初始化 RestHighLevelClient
*/
@BeforeEach
void setUp() throws Exception {
// 创建连接到 Elasticsearch 的客户端
client = new RestHighLevelClient(RestClient.builder(HttpHost.create("http://127.0.0.1:9200")));
}
/**
* 在每个测试方法执行后关闭 RestHighLevelClient
*/
@AfterEach
void tearDown() throws Exception {
// 关闭客户端连接
if (client != null){
client.close();
}
}
}文档CRUD
删除
@Test
void testDeleteDocument() throws IOException {
// 1.准备Request,两个参数,第一个是索引库名,第二个是文档id
DeleteRequest request = new DeleteRequest("item", "100002644680");
// 2.发送请求
client.delete(request, RequestOptions.DEFAULT);
}查询
@Test
void testGetDoc() throws IOException {
GetRequest request = new GetRequest("item", "1");
GetResponse response = client.get(request, RequestOptions.DEFAULT);
System.out.println("response.getSource() = " + response.getSourceAsString());
System.out.println("response = " + response);
}13:12:13:659 INFO 40640 --- [ient-executor-6] com.alibaba.nacos.common.remote.client : [898c8f72-9a39-4d91-930b-18ff482f085e] Receive server push request, request = NotifySubscriberRequest, requestId = 39
13:12:13:660 INFO 40640 --- [ient-executor-6] com.alibaba.nacos.common.remote.client : [898c8f72-9a39-4d91-930b-18ff482f085e] Ack server push request, request = NotifySubscriberRequest, requestId = 39
response.getSource() = {"id":"100000011127","name":"莎米特SUMMIT拉杆箱22英寸PC材质万向轮旅行箱行李箱PC154T4A可扩容 米白","price":26600,"image":"https://m.360buyimg.com/mobilecms/s720x720_jfs/t1/25363/12/2929/274060/5c21df3aE1789bda7/030af31afd116ae0.jpg!q70.jpg.webp","category":"拉杆箱","brand":"莎米特","sold":45454,"commentCount":233324,"isAD":false,"updateTime":1556640000000}
response = {"_index":"item","_type":"_doc","_id":"1","_version":1,"_seq_no":0,"_primary_term":1,"found":true,"_source":{"id":"100000011127","name":"莎米特SUMMIT拉杆箱22英寸PC材质万向轮旅行箱行李箱PC154T4A可扩容 米白","price":26600,"image":"https://m.360buyimg.com/mobilecms/s720x720_jfs/t1/25363/12/2929/274060/5c21df3aE1789bda7/030af31afd116ae0.jpg!q70.jpg.webp","category":"拉杆箱","brand":"莎米特","sold":45454,"commentCount":233324,"isAD":false,"updateTime":1556640000000}}修改
全量更新
和新增相同
/**
* 测试方法,用于插入文档到 Elasticsearch
*/
@Test
void testInsertDoc() throws IOException {
// 根据 ID 获取 Item 对象
Item item = itemService.getById(100000011127L);
// 将 Item 对象转换为 ItemDoc 对象
ItemDoc itemDoc = BeanUtil.copyProperties(item, ItemDoc.class);
// 将 ItemDoc 对象转换为 JSON 字符串
String jsonStr = JSONUtil.toJsonStr(itemDoc);
// 创建索引请求,指定索引名称为 "item" 并设置文档 ID
IndexRequest request = new IndexRequest("item").id(itemDoc.getId());
// 设置请求源为 JSON 字符串
request.source(jsonStr, XContentType.JSON);
// 执行索引请求,将文档插入到 Elasticsearch 中
client.index(request, RequestOptions.DEFAULT);
}局部更新
@Test
void testUpdateDocument() throws IOException {
// 1.准备Request
UpdateRequest request = new UpdateRequest("items", "100002644680");
// 2.准备请求参数
request.doc(
"price", 58800,
"commentCount", 1
);
// 3.发送请求
client.update(request, RequestOptions.DEFAULT);
}文档批处理
- 利用Logstash批量导入
- 需要安装Logstash
- 对数据的再加工能力较弱
- 无需编码,但要学习编写Logstash导入配置
- 利用JavaAPI批量导入
- 需要编码,但基于JavaAPI,学习成本低
- 更加灵活,可以任意对数据做再加工处理后写入索引库
批处理与前面讲的文档的CRUD步骤基本一致:
- 创建Request,但这次用的是
BulkRequest - 准备请求参数
- 发送请求,这次要用到
client.bulk()方法
BulkRequest本身其实并没有请求参数,其本质就是将多个普通的CRUD请求组合在一起发送。例如:
- 批量新增文档,就是给每个文档创建一个
IndexRequest请求,然后封装到BulkRequest中,一起发出。 - 批量删除,就是创建N个
DeleteRequest请求,然后封装到BulkRequest,一起发出
因此BulkRequest中提供了add方法,用以添加其它CRUD的请求:
可以看到,能添加的请求有:
IndexRequest,也就是新增UpdateRequest,也就是修改DeleteRequest,也就是删除
因此Bulk中添加了多个IndexRequest,就是批量新增功能了。
批量新增
@Test
void testBulk() throws IOException {
// 1.创建Request
BulkRequest request = new BulkRequest();
// 2.准备请求参数
request.add(new IndexRequest("items").id("1").source("json doc1", XContentType.JSON));
request.add(new IndexRequest("items").id("2").source("json doc2", XContentType.JSON));
// 3.发送请求
client.bulk(request, RequestOptions.DEFAULT);
}批量删除
@Test
void testBulk() throws IOException {
// 1.创建Request
BulkRequest request = new BulkRequest();
// 2.准备请求参数
request.add(new DeleteRequest("items").id("1"));
request.add(new DeleteRequest("items").id("2"));
// 3.发送请求
client.bulk(request, RequestOptions.DEFAULT);
}完整示例
@Test
void testLoadItemDocs() throws IOException {
// 分页查询商品数据
int pageNo = 1;
int size = 1000;
while (true) {
Page<Item> page = itemService.lambdaQuery().eq(Item::getStatus, 1).page(new Page<Item>(pageNo, size));
// 非空校验
List<Item> items = page.getRecords();
if (CollUtils.isEmpty(items)) {
return;
}
log.info("加载第{}页数据,共{}条", pageNo, items.size());
// 1.创建Request
BulkRequest request = new BulkRequest("items");
// 2.准备参数,添加多个新增的Request
for (Item item : items) {
// 2.1.转换为文档类型ItemDTO
ItemDoc itemDoc = BeanUtil.copyProperties(item, ItemDoc.class);
// 2.2.创建新增文档的Request对象
request.add(new IndexRequest()
.id(itemDoc.getId())
.source(JSONUtil.toJsonStr(itemDoc), XContentType.JSON));
}
// 3.发送请求
client.bulk(request, RequestOptions.DEFAULT);
// 翻页
pageNo++;
}
}
DSL查询
Elasticsearch提供了基于JSON的DSL(Domain Specific Language)语句来定义查询条件,其JavaAPI就是在组织DSL条件。
Elasticsearch的查询可以分为两大类:
- 叶子查询(Leaf query clauses):一般是在特定的字段里查询特定值,属于简单查询,很少单独使用。
- 复合查询(Compound query clauses):以逻辑方式组合多个叶子查询或者更改叶子查询的行为方式。
查询的语法结构
GET /{索引库名}/_search
{
"query": {
"查询类型": {
// .. 查询条件
}
}
}说明:
GET /{索引库名}/_search:其中的_search是固定路径,不能修改
最简单的无条件查询为例,无条件查询的类型是:match_all,因此其查询语句如下:
GET /items/_search
{
"query": {
"match_all": {
}
}
}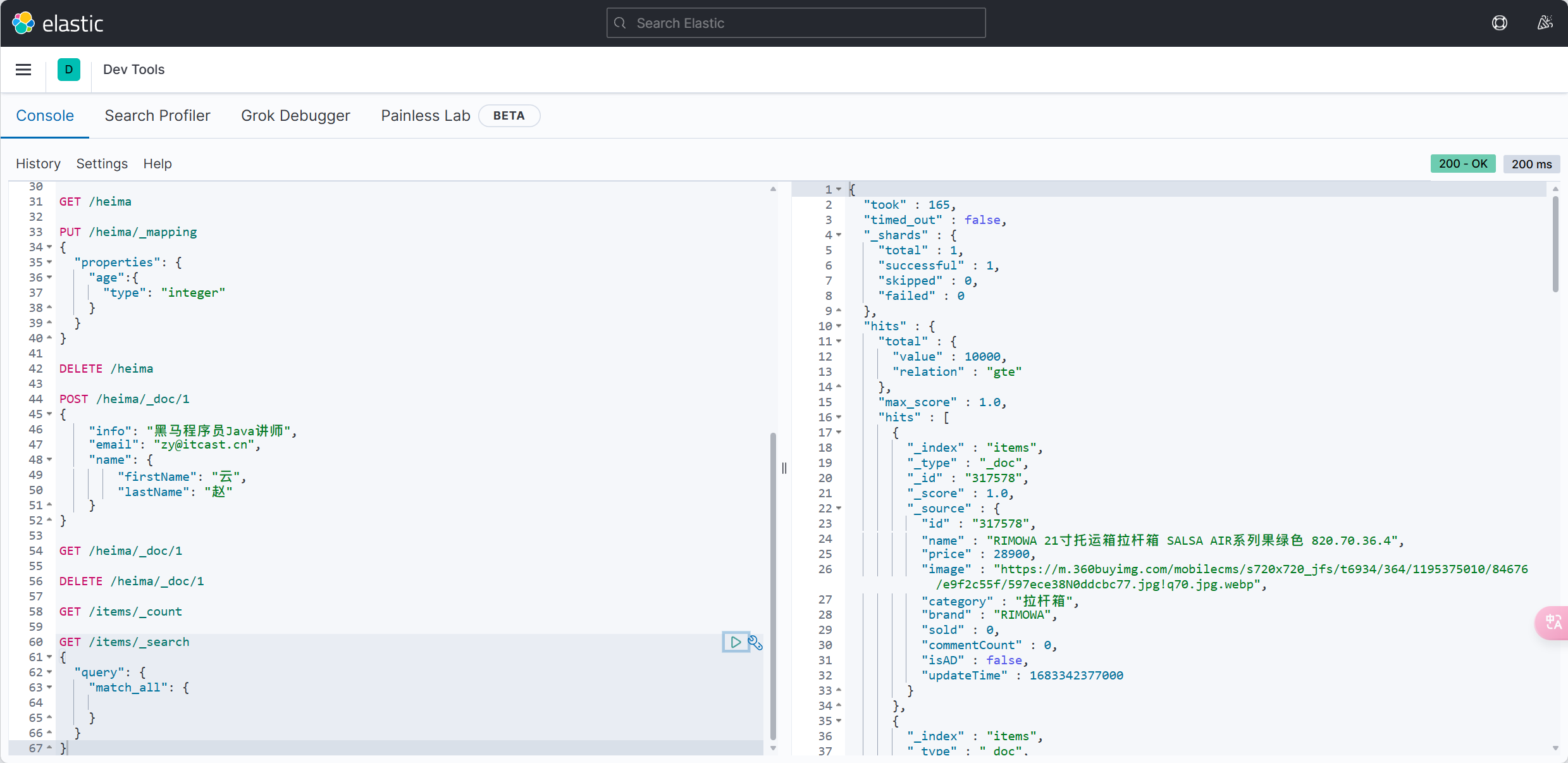
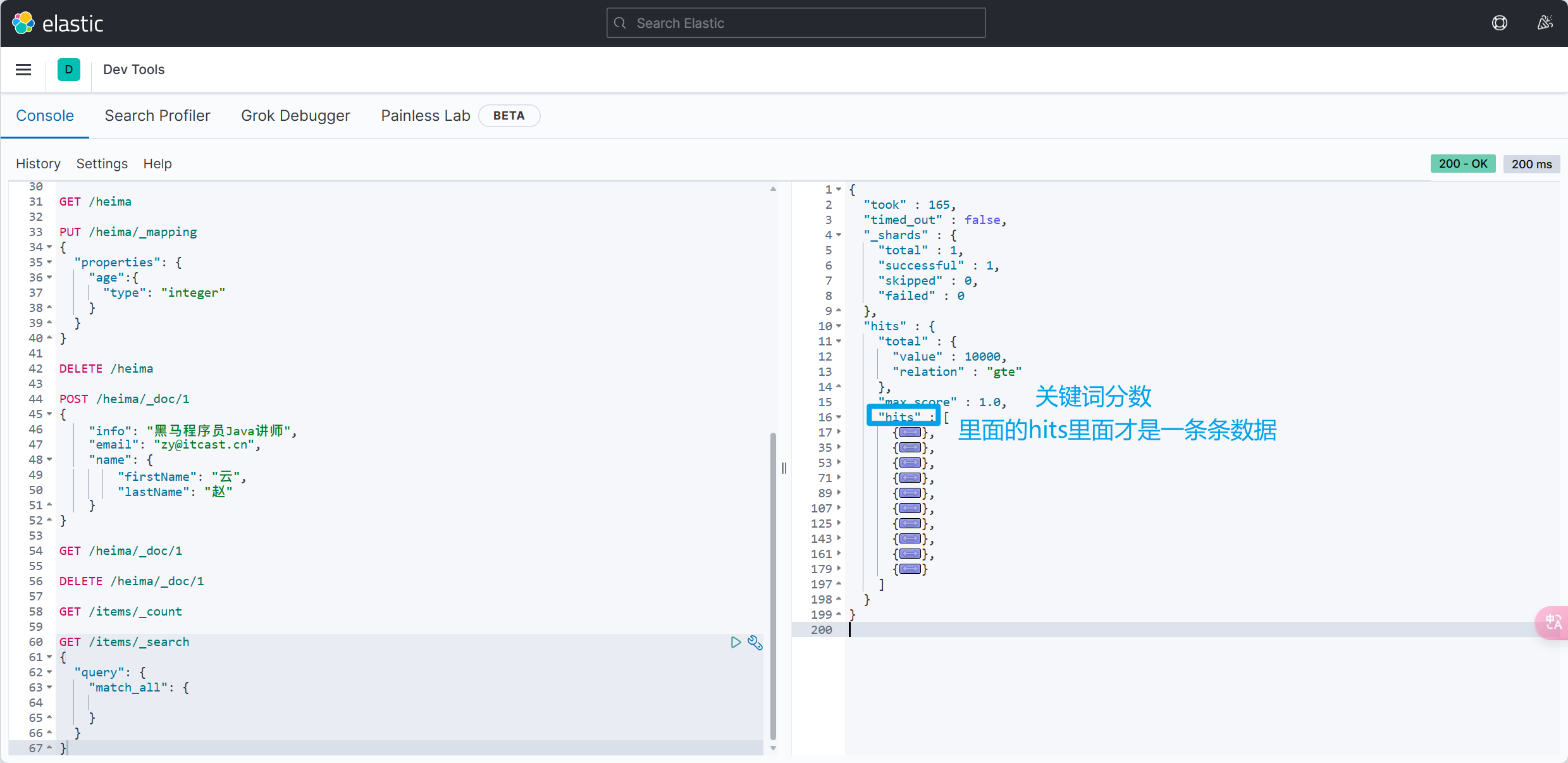

虽然是match_all,但是响应结果中并不会包含索引库中的所有文档,而是仅有10条。这是因为处于安全考虑,elasticsearch设置了默认的查询页数。
叶子查询
[Query DSL | Elasticsearch Guide 7.12] | Elastic
- 全文检索查询(Full Text Queries):利用分词器对用户输入搜索条件先分词,得到词条,然后再利用倒排索引搜索词条。例如:
match:multi_match
- 精确查询(Term-level queries):不对用户输入搜索条件分词,根据字段内容精确值匹配。但只能查找keyword、数值、日期、boolean类型的字段。例如:
idstermrange
- **地理坐标查询:**用于搜索地理位置,搜索方式很多,例如:
geo_bounding_box:按矩形搜索geo_distance:按点和半径搜索
全文检索查询
[Full text queries | Elasticsearch Guide 7.12] | Elastic
- match
GET /{索引库名}/_search
{
"query": {
"match": {
"字段名": "搜索条件"
}
}
}
- multi_match
GET /{索引库名}/_search
{
"query": {
"multi_match": {
"query": "搜索条件",
"fields": ["字段1", "字段2"]
}
}
}
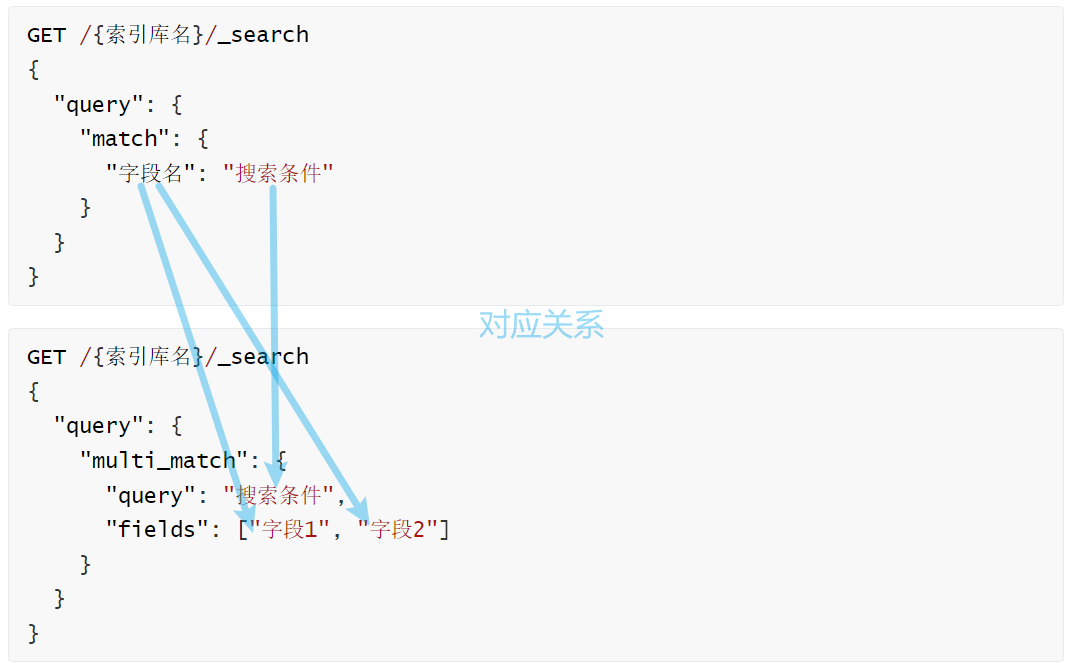
精确查询
[Term-level queries | Elasticsearch Guide 7.12] | Elastic
精确查询,英文是Term-level query,顾名思义,词条级别的查询。也就是说不会对用户输入的搜索条件再分词,而是作为一个词条,与搜索的字段内容精确值匹配。因此推荐查找keyword、数值、日期、boolean类型的字段。例如:
- id
- price
- 城市
- 地名
- 人名
等等,作为一个整体才有含义的字段。
- term
GET /{索引库名}/_search
{
"query": {
"term": {
"字段名": {
"value": "搜索条件"
}
}
}
}
- range
GET /{索引库名}/_search
{
"query": {
"range": {
"字段名": {
"gte": {最小值},
"lte": {最大值}
}
}
}
}range是范围查询,对于范围筛选的关键字有:
gte:大于等于gt:大于lte:小于等于lt:小于
- ids
GET /items/_search
{
"query": {
"ids": {
"values": ["id1", "id2"]
}
}
}
复合查询
[Compound queries | Elasticsearch Guide 7.12] | Elastic
复合查询大致可以分为两类:
- 第一类:叶子查询,实现组合条件,例如
- bool
- 第二类:基于某种算法修改查询时的文档相关性算分,从而改变文档排名。例如:
- function_score
- dis_max
基于逻辑运算组合
bool查询,即布尔查询。就是利用逻辑运算来组合一个或多个查询子句的组合。bool查询支持的逻辑运算有:
- must:必须匹配每个子查询,类似“与”
- should:选择性匹配子查询,类似“或”
- must_not:必须不匹配,不参与算分,类似“非”
- filter:必须匹配,不参与算分
GET /items/_search
{
"query": {
"bool": {
"must": [
{"match": {"name": "手机"}}
],
"should": [
{"term": {"brand": { "value": "vivo" }}},
{"term": {"brand": { "value": "小米" }}}
],
"must_not": [
{"range": {"price": {"gte": 2500}}}
],
"filter": [
{"range": {"price": {"lte": 1000}}}
]
}
}
}出于性能考虑,与搜索关键字无关的查询尽量采用must_not或filter逻辑运算,避免参与相关性算分。
例如黑马商城的搜索页面:
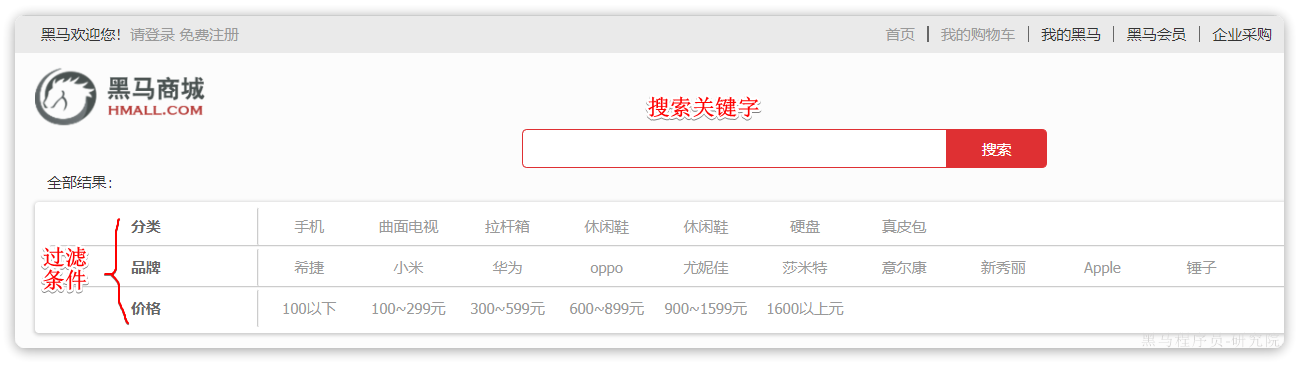
其中输入框的搜索条件肯定要参与相关性算分,可以采用match。但是价格范围过滤、品牌过滤、分类过滤等尽量采用filter,不要参与相关性算分。
搜索手机,但品牌必须是华为,价格必须是900~1599:
GET /items/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"name": "手机"
}
}
],
"filter": [
{
"term": {
"brand": {
"value": "华为"
}
}
},
{
"range": {
"price": {
"gte": 90000,
"lte": 159900
}
}
}
]
}
}
}
算分函数查询
当我们利用match查询时,文档结果会根据与搜索词条的关联度打分(_score),返回结果时按照分值降序排列。
从elasticsearch5.1开始,采用的相关性打分算法是BM25算法,公式如下:

基于这套公式,就可以判断出某个文档与用户搜索的关键字之间的关联度,还是比较准确的。但是,在实际业务需求中,常常会有竞价排名的功能。不是相关度越高排名越靠前,而是掏的钱多的排名靠前。
例如在百度中搜索Java培训,排名靠前的就是广告推广:
要想认为控制相关性算分,就需要利用elasticsearch中的function score 查询了。
基本语法:
function score 查询中包含四部分内容:
- 原始查询条件:query部分,基于这个条件搜索文档,并且基于BM25算法给文档打分,原始算分(query score)
- 过滤条件:filter部分,符合该条件的文档才会重新算分
- 算分函数:符合filter条件的文档要根据这个函数做运算,得到的函数算分(function score),有四种函数
- weight:函数结果是常量
- field_value_factor:以文档中的某个字段值作为函数结果
- random_score:以随机数作为函数结果
- script_score:自定义算分函数算法
- 运算模式:算分函数的结果、原始查询的相关性算分,两者之间的运算方式,包括:
- multiply:相乘
- replace:用function score替换query score
- 其它,例如:sum、avg、max、min
function score的运行流程如下:
- 1)根据原始条件查询搜索文档,并且计算相关性算分,称为原始算分(query score)
- 2)根据过滤条件,过滤文档
- 3)符合过滤条件的文档,基于算分函数运算,得到函数算分(function score)
- 4)将原始算分(query score)和函数算分(function score)基于运算模式做运算,得到最终结果,作为相关性算分。
因此,其中的关键点是:
- 过滤条件:决定哪些文档的算分被修改
- 算分函数:决定函数算分的算法
- 运算模式:决定最终算分结果
示例:给IPhone这个品牌的手机算分提高十倍,分析如下:
- 过滤条件:品牌必须为IPhone
- 算分函数:常量weight,值为10
- 算分模式:相乘multiply
对应代码如下:
GET /hotel/_search
{
"query": {
"function_score": {
"query": { .... }, // 原始查询,可以是任意条件
"functions": [ // 算分函数
{
"filter": { // 满足的条件,品牌必须是Iphone
"term": {
"brand": "Iphone"
}
},
"weight": 10 // 算分权重为2
}
],
"boost_mode": "multipy" // 加权模式,求乘积
}
}
}排序
GET /items/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"sold": "desc"
},
{
"price": "asc"
}
]
}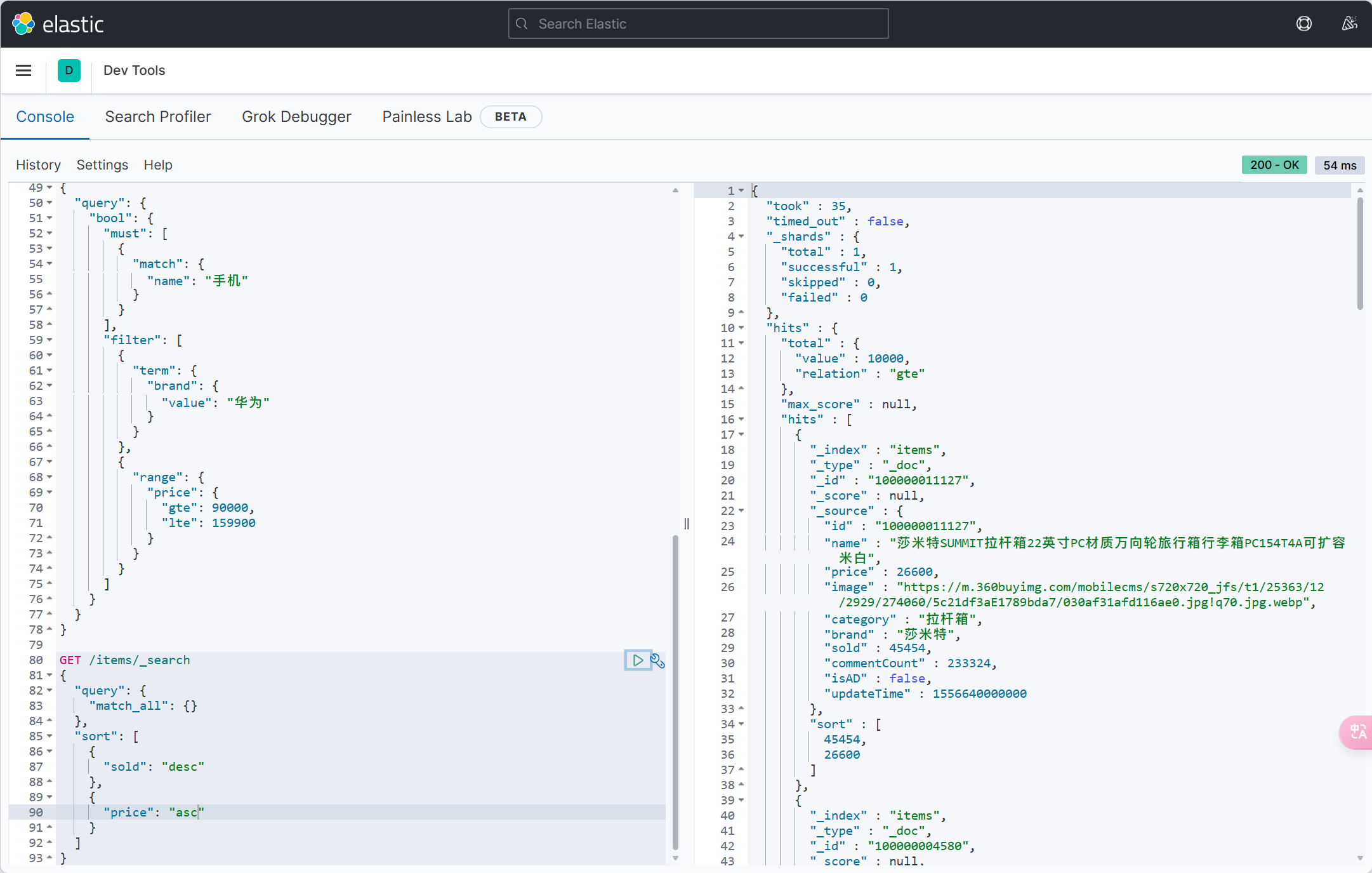
分页
[Paginate search results | Elasticsearch Guide 7.12] | Elastic
elasticsearch 默认情况下只返回top10的数据。而如果要查询更多数据就需要修改分页参数了。
elasticsearch中通过修改from、size参数来控制要返回的分页结果:
from:从第几个文档开始size:总共查询几个文档
类似于mysql中的limit ?, ?
基础分页
GET /items/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"sold": "desc"
},
{
"price": "asc"
}
],
"from": 0, // 分页开始的位置,默认为0
"size": 1 // 每页文档数量,默认10
}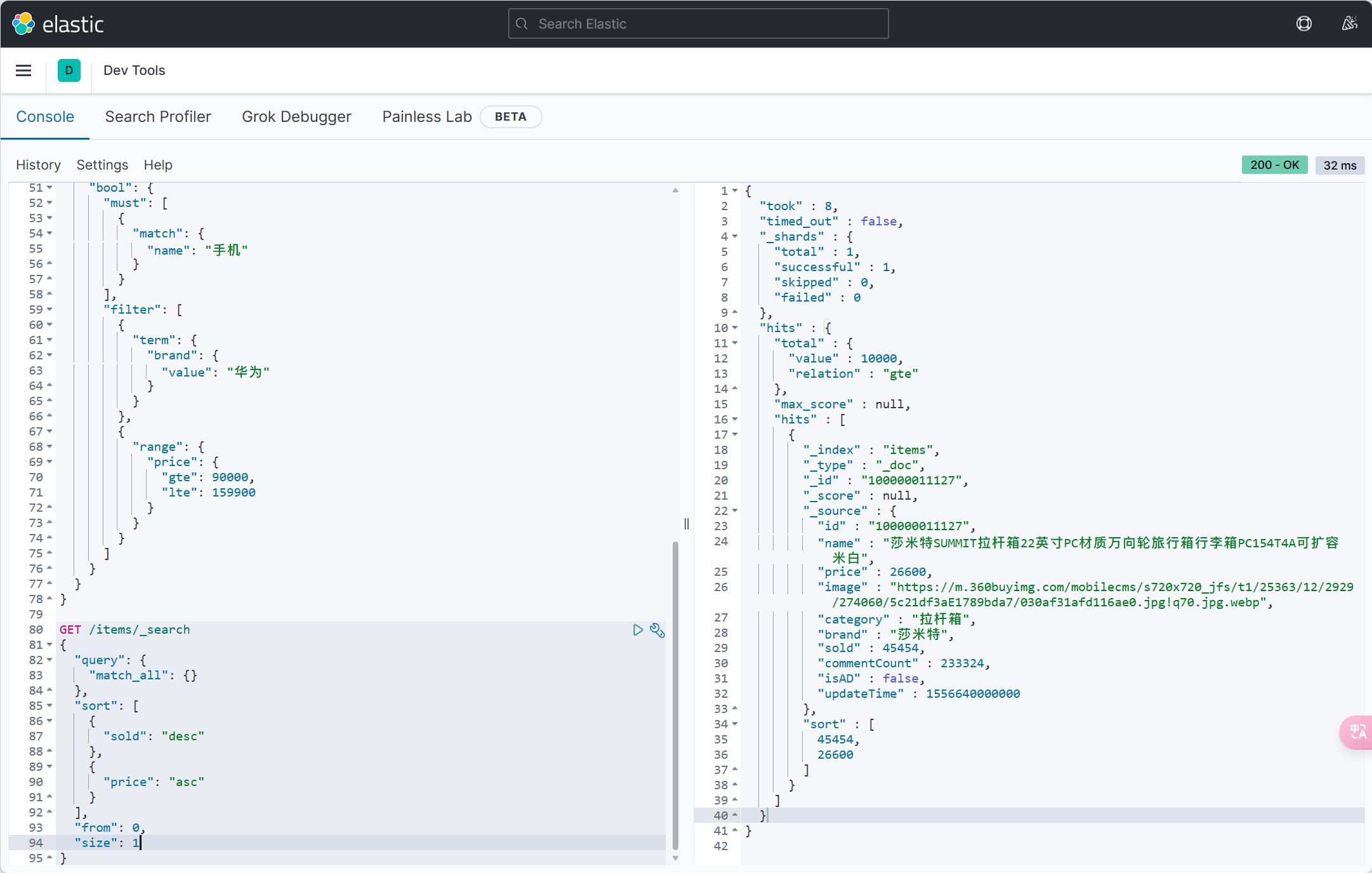
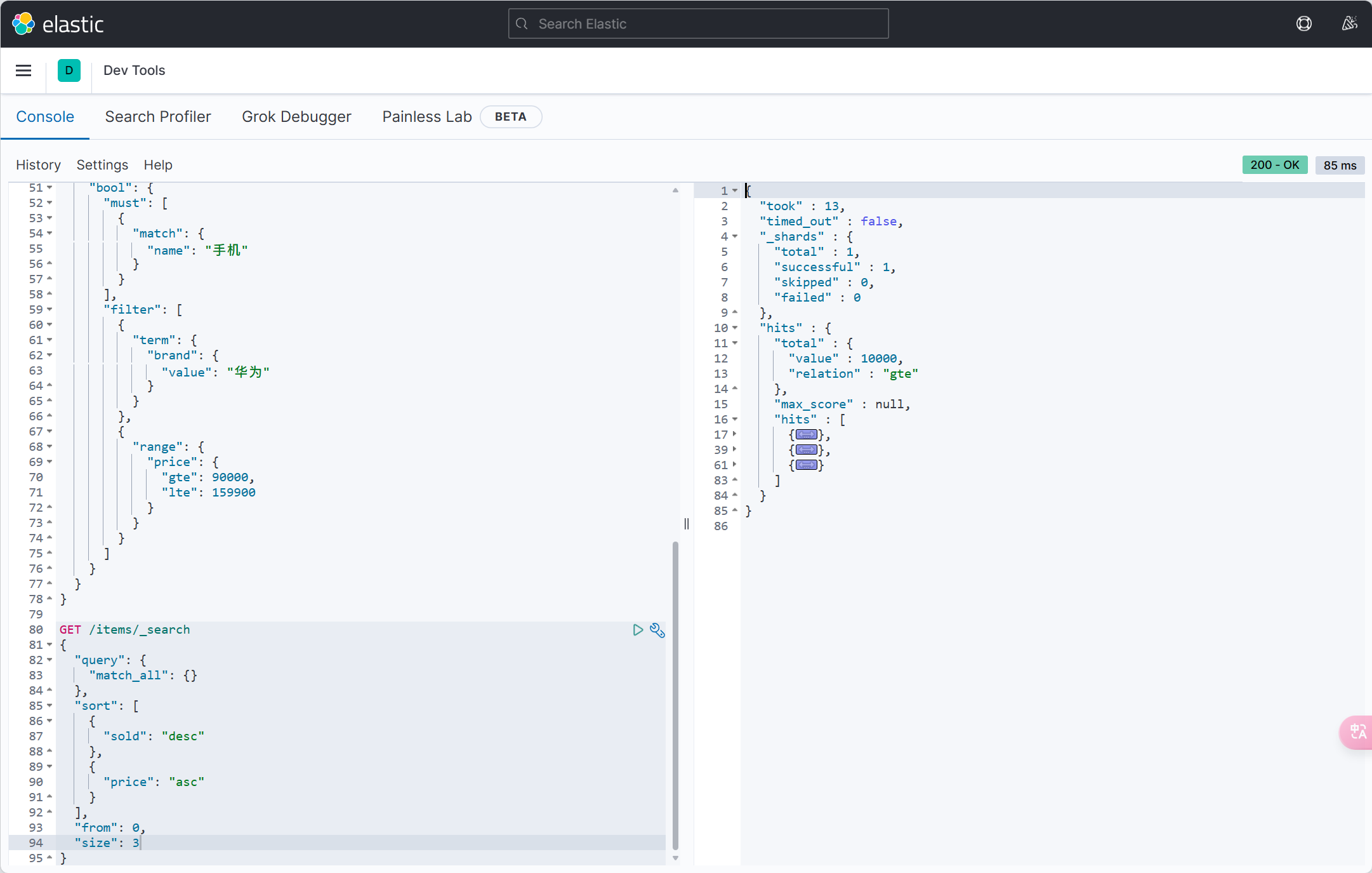
下一页
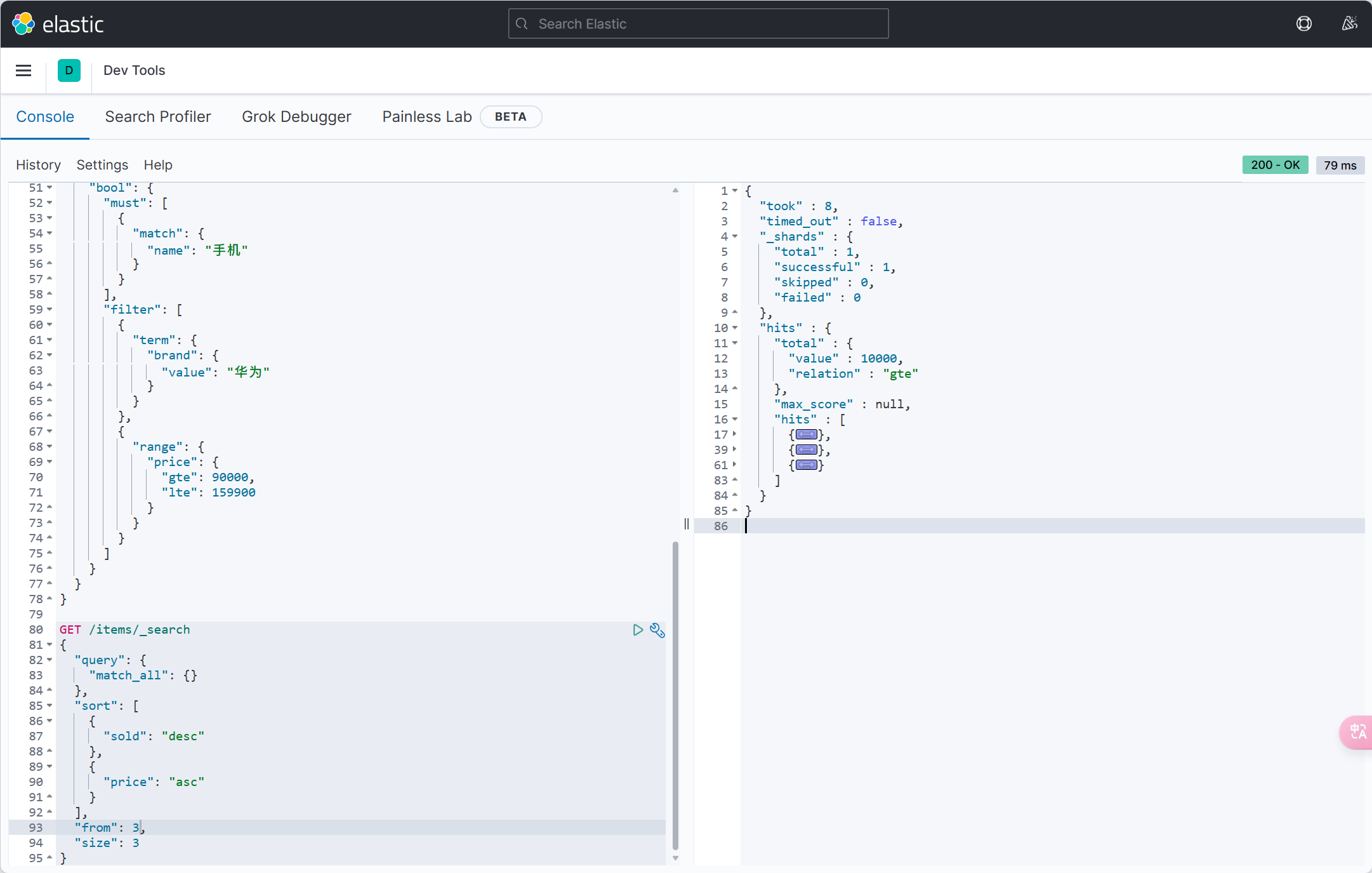
深度分页
[Paginate search results | Elasticsearch Guide 7.12] | Elastic
from + size < 10000 条
elasticsearch的数据一般会采用分片存储,也就是把一个索引中的数据分成N份,存储到不同节点上。这种存储方式比较有利于数据扩展,但给分页带来了一些麻烦。
比如一个索引库中有100000条数据,分别存储到4个分片,每个分片25000条数据。现在每页查询10条,查询第99页。那么分页查询的条件如下:
GET /items/_search
{
"from": 990, // 从第990条开始查询
"size": 10, // 每页查询10条
"sort": [
{
"price": "asc"
}
]
}从语句来分析,要查询第990~1000名的数据。
从实现思路来分析,肯定是将所有数据排序,找出前1000名,截取其中的990~1000的部分。但问题来了,我们如何才能找到所有数据中的前1000名呢?
要知道每一片的数据都不一样,第1片上的第900~1000,在另1个节点上并不一定依然是900~1000名。所以我们只能在每一个分片上都找出排名前1000的数据,然后汇总到一起,重新排序,才能找出整个索引库中真正的前1000名,此时截取990~1000的数据即可。
如图:
试想一下,假如我们现在要查询的是第999页数据呢,是不是要找第9990~10000的数据,那岂不是需要把每个分片中的前10000名数据都查询出来,汇总在一起,在内存中排序?如果查询的分页深度更深呢,需要一次检索的数据岂不是更多?
由此可知,当查询分页深度较大时,汇总数据过多,对内存和CPU会产生非常大的压力。
因此elasticsearch会禁止from+ size 超过10000的请求。
针对深度分页,elasticsearch提供了两种解决方案:
search after:分页时需要排序,原理是从上一次的排序值开始,查询下一页数据。官方推荐使用的方式。scroll:原理将排序后的文档id形成快照,保存下来,基于快照做分页。官方已经不推荐使用。
总结:
大多数情况下,我们采用普通分页就可以了。查看百度、京东等网站,会发现其分页都有限制。例如百度最多支持77页,每页不足20条。京东最多100页,每页最多60条。
因此,一般我们采用限制分页深度的方式即可,无需实现深度分页。
高亮显示
观察页面源码,你会发现两件事情:
- 高亮词条都被加了
<em>标签 <em>标签都添加了红色样式
css样式肯定是前端实现页面的时候写好的,但是前端编写页面的时候是不知道页面要展示什么数据的,不可能给数据加标签。而服务端实现搜索功能,要是有elasticsearch做分词搜索,是知道哪些词条需要高亮的。
因此词条的高亮标签肯定是由服务端提供数据的时候已经加上的。
实现高亮的思路:
- 用户输入搜索关键字搜索数据
- 服务端根据搜索关键字到elasticsearch搜索,并给搜索结果中的关键字词条添加
html标签 - 前端提前给约定好的
html标签添加CSS样式
GET /{索引库名}/_search
{
"query": {
"match": {
"搜索字段": "搜索关键字"
}
},
"highlight": {
"fields": {
"高亮字段名称": {
"pre_tags": "<em>",
"post_tags": "</em>"
}
}
}
}
标签默认em
- 搜索必须有查询条件,而且是全文检索类型的查询条件,例如
match - 参与高亮的字段必须是
text类型的字段 - 默认情况下参与高亮的字段要与搜索字段一致,除非添加:
required_field_match=false
RestClient查询
match_all
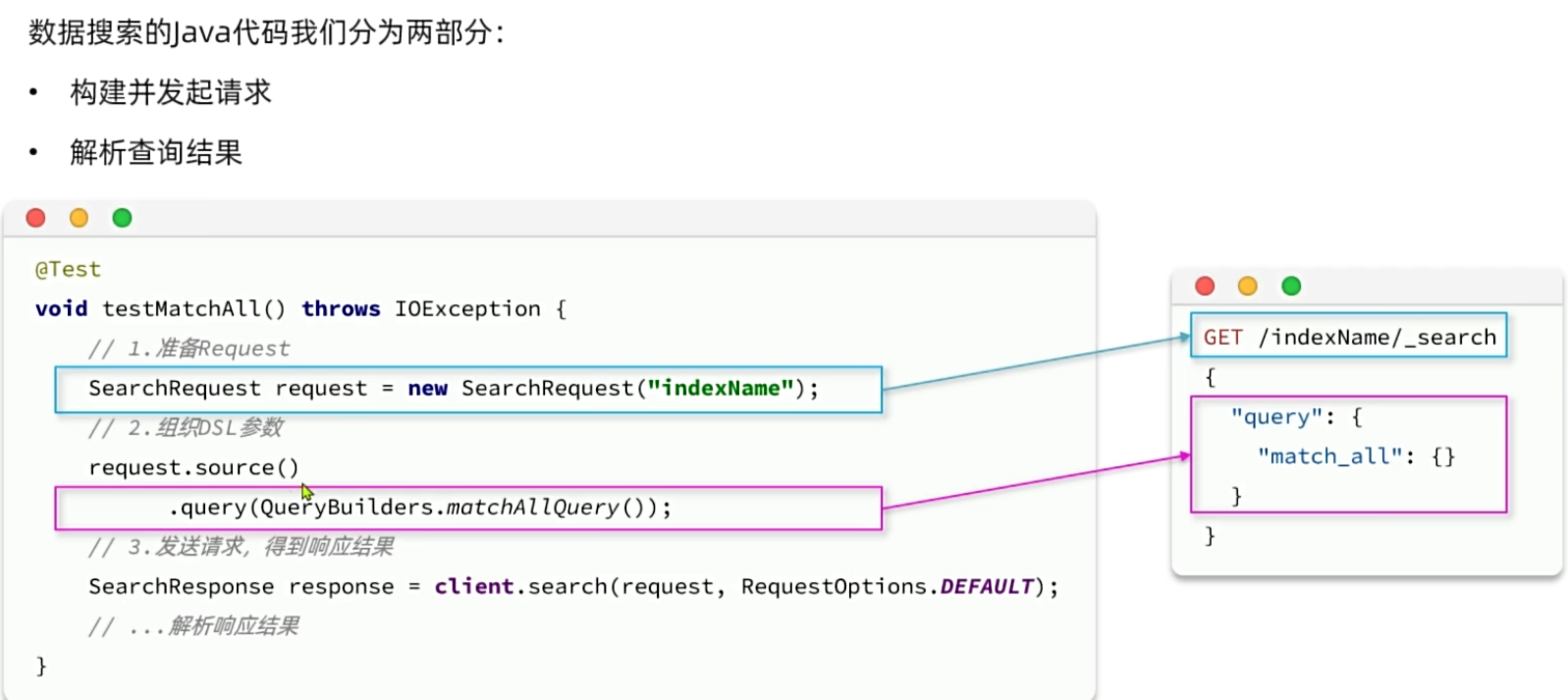
- 第一步,创建
SearchRequest对象,指定索引库名 - 第二步,利用
request.source()构建DSL,DSL中可以包含查询、分页、排序、高亮等query():代表查询条件,利用QueryBuilders.matchAllQuery()构建一个match_all查询的DSL
- 第三步,利用
client.search()发送请求,得到响应
这里关键的API有两个,一个是request.source(),它构建的就是DSL中的完整JSON参数。其中包含了query、sort、from、size、highlight等所有功能
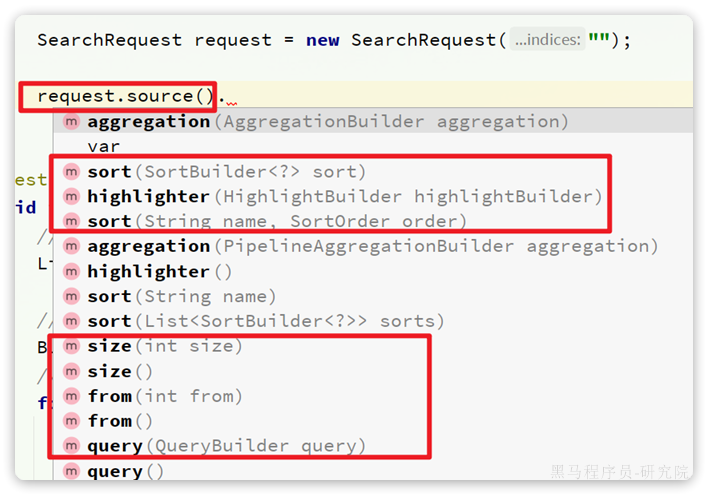
另一个是QueryBuilders,其中包含了我们学习过的各种叶子查询、复合查询等

package com.hmall.item.es;
/**
* ESSearchTest 类用于测试 Elasticsearch 文档的插入操作
*
* @author:CharmingDaiDai
* @project:hmall
* @since:2024/5/27 下午9:22
*/
@SpringBootTest(properties = "spring.profiles.active=local")
@Slf4j
public class ESSearchTest {
private RestHighLevelClient client;
@Resource
private IItemService itemService;
@Test
void testMatchAll() throws IOException {
SearchRequest request = new SearchRequest("items");
request.source().query(QueryBuilders.matchAllQuery());
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
System.out.println("response = " + response.toString());
}
/**
* 在每个测试方法执行前初始化 RestHighLevelClient
*/
@BeforeEach
void setUp() throws Exception {
// 创建连接到 Elasticsearch 的客户端
client = new RestHighLevelClient(RestClient.builder(HttpHost.create("http://127.0.0.1:9200")));
}
/**
* 在每个测试方法执行后关闭 RestHighLevelClient
*/
@AfterEach
void tearDown() throws Exception {
// 关闭客户端连接
if (client != null){
client.close();
}
}
}
@Test
void testMatchAll() throws IOException {
// 创建搜索请求,指定索引名称为 "items"
SearchRequest request = new SearchRequest("items");
// 设置搜索请求的查询类型为 match_all,即匹配所有文档
request.source().query(QueryBuilders.matchAllQuery());
// 执行搜索请求,获取搜索响应
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
// 打印搜索响应的字符串表示
System.out.println("response = " + response.toString());
// 解析搜索结果
// 获取搜索命中的结果集
SearchHits searchHits = response.getHits();
// 获取命中结果的总数
long total = searchHits.getTotalHits().value;
System.out.println("total = " + total);
// 获取所有命中的搜索结果
SearchHit[] hits = searchHits.getHits();
// 遍历每一个命中的搜索结果
for (SearchHit hit : hits) {
// 将搜索结果转换为 JSON 字符串
String json = hit.getSourceAsString();
// 打印 JSON 字符串
// System.out.println(json);
ItemDoc doc = JSONUtil.toBean(json, ItemDoc.class);
System.out.println("doc = " + doc);
}
}total = 10000
doc = ItemDoc(id=317578, name=RIMOWA 21寸托运箱拉杆箱 SALSA AIR系列果绿色 820.70.36.4, price=28900, image=https://m.360buyimg.com/mobilecms/s720x720_jfs/t6934/364/1195375010/84676/e9f2c55f/597ece38N0ddcbc77.jpg!q70.jpg.webp, category=拉杆箱, brand=RIMOWA, sold=0, commentCount=0, isAD=false, updateTime=2023-05-06T11:06:17)
doc = ItemDoc(id=317580, name=RIMOWA 26寸托运箱拉杆箱 SALSA AIR系列果绿色 820.70.36.4, price=28600, image=https://m.360buyimg.com/mobilecms/s720x720_jfs/t6934/364/1195375010/84676/e9f2c55f/597ece38N0ddcbc77.jpg!q70.jpg.webp, category=拉杆箱, brand=RIMOWA, sold=0, commentCount=0, isAD=false, updateTime=2023-10-07T10:04:39)
doc = ItemDoc(id=546872, name=博兿(BOYI)拉杆包男23英寸大容量旅行包户外手提休闲拉杆袋 BY09186黑灰色, price=27500, image=https://m.360buyimg.com/mobilecms/s720x720_jfs/t3301/221/3887995271/90563/bf2cadb/57f9fbf4N8e47c225.jpg!q70.jpg.webp, category=拉杆箱, brand=博兿, sold=0, commentCount=0, isAD=false, updateTime=2019-05-01T00:00)
doc = ItemDoc(id=561178, name=RIMOWA 30寸托运箱拉杆箱 SALSA AIR系列果绿色 820.70.36.4, price=13000, image=https://m.360buyimg.com/mobilecms/s720x720_jfs/t6934/364/1195375010/84676/e9f2c55f/597ece38N0ddcbc77.jpg!q70.jpg.webp, category=拉杆箱, brand=RIMOWA, sold=0, commentCount=0, isAD=false, updateTime=2023-10-07T10:04:54)
doc = ItemDoc(id=577967, name=莎米特SUMMIT 旅行拉杆箱28英寸PC材质大容量旅行行李箱PC154 黑色, price=71300, image=https://m.360buyimg.com/mobilecms/s720x720_jfs/t30454/163/719393962/79149/13bcc06a/5bfca9b6N493202d2.jpg!q70.jpg.webp, category=拉杆箱, brand=莎米特, sold=0, commentCount=0, isAD=false, updateTime=2019-05-01T00:00)
doc = ItemDoc(id=584382, name=美旅AmericanTourister拉杆箱 商务男女超轻PP行李箱时尚大容量耐磨飞机轮旅行箱 25英寸海关锁DL7灰色, price=36600, image=https://m.360buyimg.com/mobilecms/s720x720_jfs/t1/22734/21/2036/130399/5c18af2aEab296c01/7b148f18c6081654.jpg!q70.jpg.webp, category=拉杆箱, brand=美旅箱包, sold=0, commentCount=0, isAD=false, updateTime=2019-05-01T00:00)
doc = ItemDoc(id=584387, name=美旅AmericanTourister拉杆箱 商务男女超轻PP行李箱时尚大容量耐磨飞机轮旅行箱 29英寸海关锁DL7灰色, price=16200, image=https://m.360buyimg.com/mobilecms/s720x720_jfs/t1/22734/21/2036/130399/5c18af2aEab296c01/7b148f18c6081654.jpg!q70.jpg.webp, category=拉杆箱, brand=美旅箱包, sold=0, commentCount=0, isAD=false, updateTime=2019-05-01T00:00)
doc = ItemDoc(id=584391, name=美旅AmericanTourister拉杆箱 商务男女超轻PP行李箱时尚大容量耐磨飞机轮旅行箱 20英寸海关锁DL7灰色, price=29900, image=https://m.360buyimg.com/mobilecms/s720x720_jfs/t1/22734/21/2036/130399/5c18af2aEab296c01/7b148f18c6081654.jpg!q70.jpg.webp, category=拉杆箱, brand=美旅箱包, sold=0, commentCount=0, isAD=false, updateTime=2019-05-01T00:00)
doc = ItemDoc(id=584392, name=美旅AmericanTourister拉杆箱 商务男女超轻PP行李箱时尚大容量耐磨飞机轮旅行箱 29英寸海关锁DL7灰色, price=17000, image=https://m.360buyimg.com/mobilecms/s720x720_jfs/t1/22734/21/2036/130399/5c18af2aEab296c01/7b148f18c6081654.jpg!q70.jpg.webp, category=拉杆箱, brand=美旅箱包, sold=0, commentCount=0, isAD=false, updateTime=2023-10-07T10:04:59)
doc = ItemDoc(id=584394, name=美旅AmericanTourister拉杆箱 商务男女超轻PP行李箱时尚大容量耐磨飞机轮旅行箱 25英寸海关锁DL7灰色, price=79400, image=https://m.360buyimg.com/mobilecms/s720x720_jfs/t1/22734/21/2036/130399/5c18af2aEab296c01/7b148f18c6081654.jpg!q70.jpg.webp, category=拉杆箱, brand=美旅箱包, sold=0, commentCount=0, isAD=false, updateTime=2019-05-01T00:00)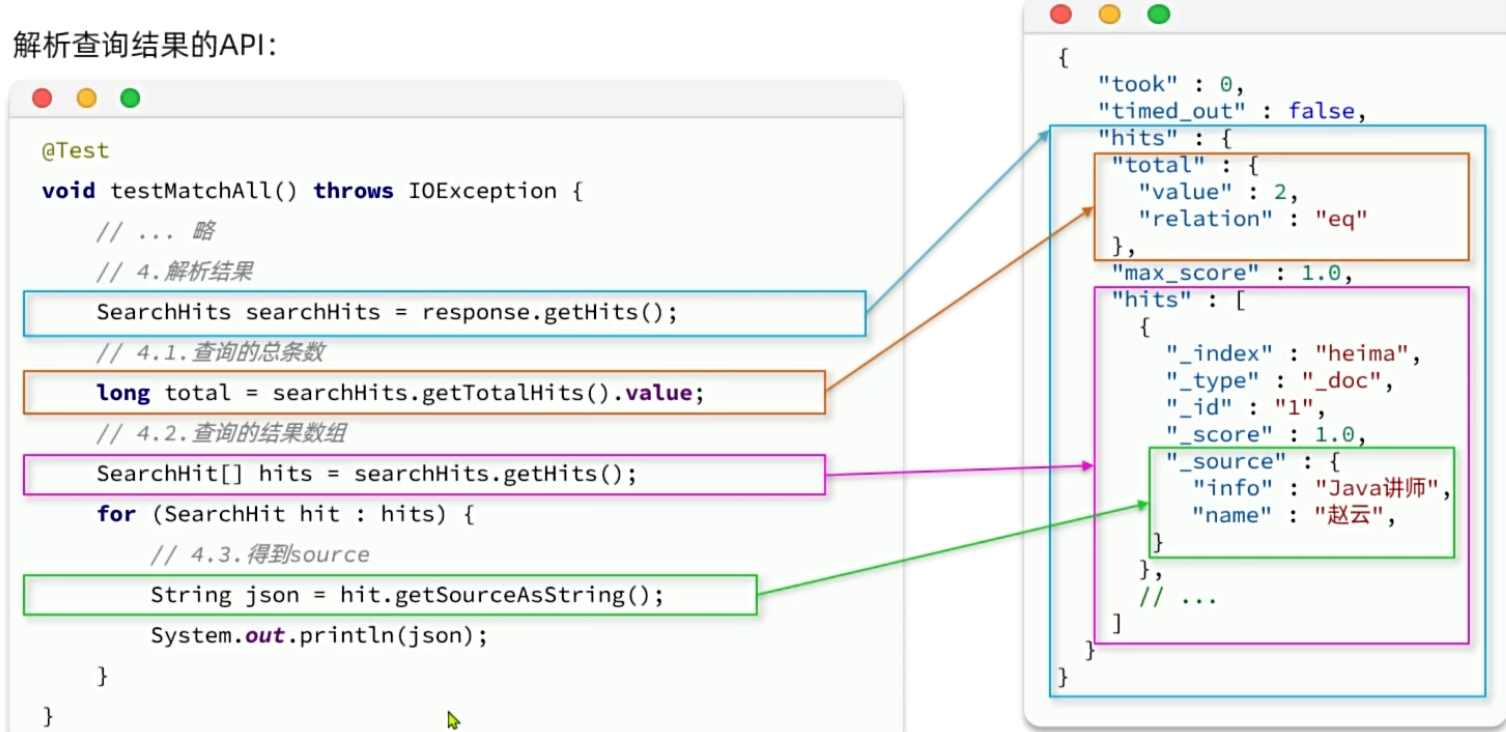
封装结果解析:
private void handleResponse(SearchResponse response) {
SearchHits searchHits = response.getHits();
// 1.获取总条数
long total = searchHits.getTotalHits().value;
System.out.println("共搜索到" + total + "条数据");
// 2.遍历结果数组
SearchHit[] hits = searchHits.getHits();
for (SearchHit hit : hits) {
// 3.得到_source,也就是原始json文档
String source = hit.getSourceAsString();
// 4.反序列化并打印
ItemDoc item = JSONUtil.toBean(source, ItemDoc.class);
System.out.println(item);
}
}复合查询
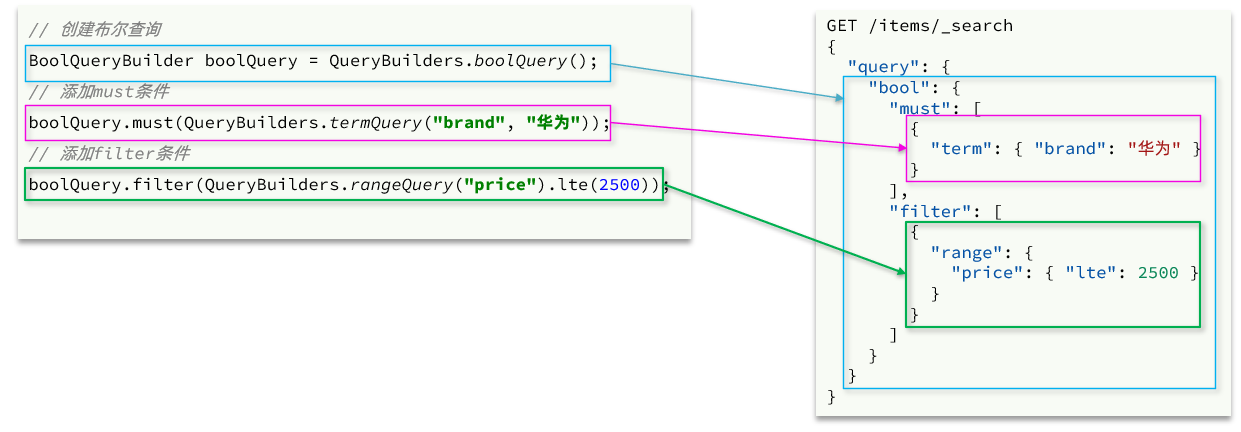
@Test
void testMixMatch() throws IOException {
// 创建搜索请求,指定索引名称为 "items"
SearchRequest request = new SearchRequest("items");
// 创建一个布尔查询构建器
BoolQueryBuilder bool = QueryBuilders.boolQuery();
// 添加一个 must 条件,匹配 "name" 字段包含 "脱脂牛奶"
bool.must(QueryBuilders.matchQuery("name", "脱脂牛奶"));
// 添加一个 filter 条件,匹配 "brand" 字段为 "德亚"
bool.filter(QueryBuilders.termQuery("brand", "德亚"));
// 添加一个范围过滤条件,匹配 "price" 字段的值在 100 到 30000 之间
bool.filter(QueryBuilders.rangeQuery("price").gte(100).lte(30000));
// 将布尔查询设置到搜索请求中
request.source().query(bool);
// 执行搜索请求,获取搜索响应
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
// 处理搜索响应
handleResponse(response);
}链式
// 使用链式构建方式创建布尔查询
BoolQueryBuilder bool = QueryBuilders.boolQuery()
.must(QueryBuilders.matchQuery("name", "脱脂牛奶"))
.filter(QueryBuilders.termQuery("brand", "德亚"))
.filter(QueryBuilders.rangeQuery("price").gte(100).lte(30000));共搜索到15条数据
ItemDoc(id=37228712324, name=【包邮】德国进口Weidendorf德亚脱脂牛奶200ml*12盒进口早餐纯牛奶全脂 脱脂牛奶200ml*12盒, price=29300, image=https://m.360buyimg.com/mobilecms/s720x720_jfs/t30757/169/501371318/588248/ddbb022e/5bf4ef7bNe22a28fa.jpg!q70.jpg.webp, category=牛奶, brand=德亚, sold=0, commentCount=0, isAD=false, updateTime=2019-05-01T00:00)
ItemDoc(id=30415947062, name=【6灌装两瓶减3元】德国原装进口(Weidendorf)德亚牛奶全脂纯牛奶脱脂牛奶 全脂牛奶*12罐, price=27000, image=https://m.360buyimg.com/mobilecms/s720x720_jfs/t27379/324/2136309393/332532/38bfbc43/5bf79104N3cec8ead.jpg!q70.jpg.webp, category=牛奶, brand=德亚, sold=0, commentCount=0, isAD=false, updateTime=2019-05-01T00:00)
ItemDoc(id=896023, name=德国原装进口牛奶 德亚(Weidendorf)脱脂纯牛奶 1L*12盒 整箱装, price=21400, image=https://m.360buyimg.com/mobilecms/s720x720_jfs/t20791/119/2019391714/283574/1b79da38/5b4415b0N39d92810.jpg!q70.jpg.webp, category=牛奶, brand=德亚, sold=0, commentCount=0, isAD=false, updateTime=2019-05-01T00:00)
ItemDoc(id=19028883500, name=德国原装进口Weidendorf德亚脱脂牛奶200ml*12盒礼盒装进口早餐纯牛奶, price=3800, image=https://m.360buyimg.com/mobilecms/s720x720_jfs/t11932/46/779156535/159561/a23dd90e/59f829e5N00426a5d.jpg!q70.jpg.webp, category=牛奶, brand=德亚, sold=0, commentCount=0, isAD=false, updateTime=2019-05-01T00:00)
ItemDoc(id=12971632318, name=中粮我买网 德亚 脱脂牛奶1L(德国进口), price=19200, image=https://m.360buyimg.com/mobilecms/s720x720_jfs/t5854/62/3012675862/91720/8fc22a29/5936717dN09a0f550.jpg!q70.jpg.webp, category=牛奶, brand=德亚, sold=0, commentCount=0, isAD=false, updateTime=2019-05-01T00:00)
ItemDoc(id=12972937888, name=中粮我买网 德亚 脱脂牛奶1L*6(德国进口), price=6000, image=https://m.360buyimg.com/mobilecms/s720x720_jfs/t5821/202/3057572883/135865/193c1bd2/5936849dNe21a7d83.jpg!q70.jpg.webp, category=牛奶, brand=德亚, sold=0, commentCount=0, isAD=false, updateTime=2019-05-01T00:00)
ItemDoc(id=37228712326, name=【包邮】德国进口Weidendorf德亚全脂牛奶200ml*12盒进口早餐纯牛奶全脂 全脂牛奶200ml*12盒, price=12100, image=https://m.360buyimg.com/mobilecms/s720x720_jfs/t30757/169/501371318/588248/ddbb022e/5bf4ef7bNe22a28fa.jpg!q70.jpg.webp, category=牛奶, brand=德亚, sold=0, commentCount=0, isAD=false, updateTime=2019-05-01T00:00)
ItemDoc(id=10867276763, name=德国进口牛奶 德亚(Weidendorf)200ml*12/箱全脂纯牛奶营养早餐奶, price=22600, image=https://m.360buyimg.com/mobilecms/s720x720_jfs/t3574/252/611937060/202711/f6455b2e/580f1469N80827ecf.jpg!q70.jpg.webp, category=牛奶, brand=德亚, sold=0, commentCount=0, isAD=false, updateTime=2019-05-01T00:00)
ItemDoc(id=28397885411, name=德国进口 德亚(Weidendorf)全脂纯牛奶 200ml*30盒 整箱 早餐奶 进口牛奶, price=500, image=https://m.360buyimg.com/mobilecms/s720x720_jfs/t1/9576/16/7555/54537/5c072d2cEcbf98628/658c0846e4cb1c93.jpg!q70.jpg.webp, category=牛奶, brand=德亚, sold=0, commentCount=0, isAD=false, updateTime=2019-05-01T00:00)
ItemDoc(id=12972795066, name=中粮我买网 德亚 全脂牛奶 1L*6(德国进口), price=12400, image=https://m.360buyimg.com/mobilecms/s720x720_jfs/t5926/201/1843138009/138105/43e70ec4/593681feN2631a539.jpg!q70.jpg.webp, category=牛奶, brand=德亚, sold=0, commentCount=0, isAD=false, updateTime=2019-05-01T00:00)排序和分页
@Test
void testSortAndPage() throws IOException {
int pageNo = 1, pageSize = 5;
// 创建搜索请求,指定索引名称为 "items"
SearchRequest request = new SearchRequest("items");
// 使用链式构建方式创建布尔查询
BoolQueryBuilder bool = QueryBuilders.boolQuery()
.must(QueryBuilders.matchQuery("name", "脱脂牛奶"))
.filter(QueryBuilders.termQuery("brand", "德亚"))
.filter(QueryBuilders.rangeQuery("price").gte(100).lte(30000));
// 将布尔查询设置到搜索请求中
request.source().query(bool);
// 设置排序规则,先按照 "sold" 字段降序排列,再按照 "price" 字段升序排列
request.source().sort("sold", SortOrder.DESC).sort("price", SortOrder.ASC);
// 设置分页参数,从第 (pageNo - 1) * pageSize 条开始,获取 pageSize 条数据
request.source().from((pageNo - 1) * pageSize).size(pageSize);
// 执行搜索请求,获取搜索响应
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
// 处理搜索响应
handleResponse(response);
}共搜索到15条数据
ItemDoc(id=28397885411, name=德国进口 德亚(Weidendorf)全脂纯牛奶 200ml*30盒 整箱 早餐奶 进口牛奶, price=500, image=https://m.360buyimg.com/mobilecms/s720x720_jfs/t1/9576/16/7555/54537/5c072d2cEcbf98628/658c0846e4cb1c93.jpg!q70.jpg.webp, category=牛奶, brand=德亚, sold=0, commentCount=0, isAD=false, updateTime=2019-05-01T00:00)
ItemDoc(id=12973053544, name=中粮我买网 德亚 低脂牛奶 1L*6(德国进口), price=3000, image=https://m.360buyimg.com/mobilecms/s720x720_jfs/t5647/89/3018035740/146127/abf6c64c/59368595N86fd4b53.jpg!q70.jpg.webp, category=牛奶, brand=德亚, sold=0, commentCount=0, isAD=false, updateTime=2019-05-01T00:00)
ItemDoc(id=10792941724, name=德国进口(Weidendorf)酸奶德亚200ml*10/箱酸牛奶营养早餐酸奶礼盒装1箱装, price=3200, image=https://m.360buyimg.com/mobilecms/s720x720_jfs/t3397/141/32932855/208533/94dc977/57fc9236N28b061d5.jpg!q70.jpg.webp, category=牛奶, brand=德亚, sold=0, commentCount=0, isAD=false, updateTime=2019-05-01T00:00)
ItemDoc(id=19028883500, name=德国原装进口Weidendorf德亚脱脂牛奶200ml*12盒礼盒装进口早餐纯牛奶, price=3800, image=https://m.360buyimg.com/mobilecms/s720x720_jfs/t11932/46/779156535/159561/a23dd90e/59f829e5N00426a5d.jpg!q70.jpg.webp, category=牛奶, brand=德亚, sold=0, commentCount=0, isAD=false, updateTime=2019-05-01T00:00)
ItemDoc(id=12972937888, name=中粮我买网 德亚 脱脂牛奶1L*6(德国进口), price=6000, image=https://m.360buyimg.com/mobilecms/s720x720_jfs/t5821/202/3057572883/135865/193c1bd2/5936849dNe21a7d83.jpg!q70.jpg.webp, category=牛奶, brand=德亚, sold=0, commentCount=0, isAD=false, updateTime=2019-05-01T00:00)高亮显示
高亮结果不在source中
修改结果解析
// 处理搜索响应的方法
void handleResponse(SearchResponse response) {
// 打印搜索响应的字符串表示
System.out.println("response = " + response.toString());
// 解析搜索结果
// 获取搜索命中的结果集
SearchHits searchHits = response.getHits();
// 获取命中结果的总数
long total = searchHits.getTotalHits().value;
System.out.println("Total Hits: " + total);
// 获取所有命中的搜索结果
SearchHit[] hits = searchHits.getHits();
// 遍历每一个命中的搜索结果
for (SearchHit hit : hits) {
// 获取高亮结果
Map<String, HighlightField> highlightFields = hit.getHighlightFields();
// 如果高亮结果不为空,则获取高亮内容
if (highlightFields.containsKey("name")) {
HighlightField highlight = highlightFields.get("name");
String highlightedText = highlight.fragments()[0].string();
System.out.println("Highlighted Text: " + highlightedText);
} else {
// 如果没有高亮结果,则使用原始内容
String json = hit.getSourceAsString();
System.out.println(json);
}
}
}测试
@Test
void testHighlight() throws IOException {
int pageNo = 1, pageSize = 5;
// 创建搜索请求,指定索引名称为 "items"
SearchRequest request = new SearchRequest("items");
// 使用链式构建方式创建布尔查询
BoolQueryBuilder bool = QueryBuilders.boolQuery()
.must(QueryBuilders.matchQuery("name", "脱脂牛奶"))
.filter(QueryBuilders.termQuery("brand", "德亚"))
.filter(QueryBuilders.rangeQuery("price").gte(100).lte(30000));
// 将布尔查询设置到搜索请求中
request.source().query(bool);
// 设置排序规则,先按照 "sold" 字段降序排列,再按照 "price" 字段升序排列
request.source().sort("sold", SortOrder.DESC).sort("price", SortOrder.ASC);
// 设置分页参数,从第 (pageNo - 1) * pageSize 条开始,获取 pageSize 条数据
request.source().from((pageNo - 1) * pageSize).size(pageSize);
// 设置高亮字段和标签
HighlightBuilder highlightBuilder = new HighlightBuilder();
highlightBuilder.field("name").preTags("<em>").postTags("</em>");
request.source().highlighter(highlightBuilder);
// 执行搜索请求,获取搜索响应
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
// 处理搜索响应
handleResponse(response);
}Total Hits: 15
Highlighted Text: 德国进口 德亚(Weidendorf)全脂纯<em>牛奶</em> 200ml*30盒 整箱 早餐奶 进口<em>牛奶</em>
Highlighted Text: 中粮我买网 德亚 低脂<em>牛奶</em> 1L*6(德国进口)
Highlighted Text: 德国进口(Weidendorf)酸奶德亚200ml*10/箱酸<em>牛奶</em>营养早餐酸奶礼盒装1箱装
Highlighted Text: 德国原装进口Weidendorf德亚<em>脱脂</em><em>牛奶</em>200ml*12盒礼盒装进口早餐纯<em>牛奶</em>
Highlighted Text: 中粮我买网 德亚 <em>脱脂</em><em>牛奶</em>1L*6(德国进口)聚合
[Aggregations | Elasticsearch Guide 7.12] | Elastic
聚合(aggregations)可以让我们极其方便的实现对数据的统计、分析、运算。例如:
- 什么品牌的手机最受欢迎?
- 这些手机的平均价格、最高价格、最低价格?
- 这些手机每月的销售情况如何?
实现这些统计功能的比数据库的sql要方便的多,而且查询速度非常快,可以实现近实时搜索效果。
聚合常见的有三类:
- 桶(
Bucket)聚合:用来对文档做分组TermAggregation:按照文档字段值分组,例如按照品牌值分组、按照国家分组Date Histogram:按照日期阶梯分组,例如一周为一组,或者一月为一组
- 度量(
Metric)聚合:用以计算一些值,比如:最大值、最小值、平均值等Avg:求平均值Max:求最大值Min:求最小值Stats:同时求max、min、avg、sum等
- 管道(
pipeline)聚合:其它聚合的结果为基础做进一步运算
**注意:**参加聚合的字段必须是keyword、日期、数值、布尔类型
DSL实现聚合
聚合属于搜索中的一部分
直接分组
GET /items/_search
{
"size": 0, // 设置返回结果的大小为 0,表示不返回文档内容,只返回聚合结果
"aggs": {
"cate_agg": { // 创建一个名为 cate_agg 的聚合
"terms": { // 使用 terms 聚合,按照指定字段的值进行分组
"field": "category", // 指定要进行分组的字段为 category
"size": 5 // 指定返回前 5 个分组(按照文档数量从大到小排序)
}
}
}
}等同于
SELECT category, COUNT(*) AS count
FROM items
GROUP BY category
ORDER BY count DESC
LIMIT 5;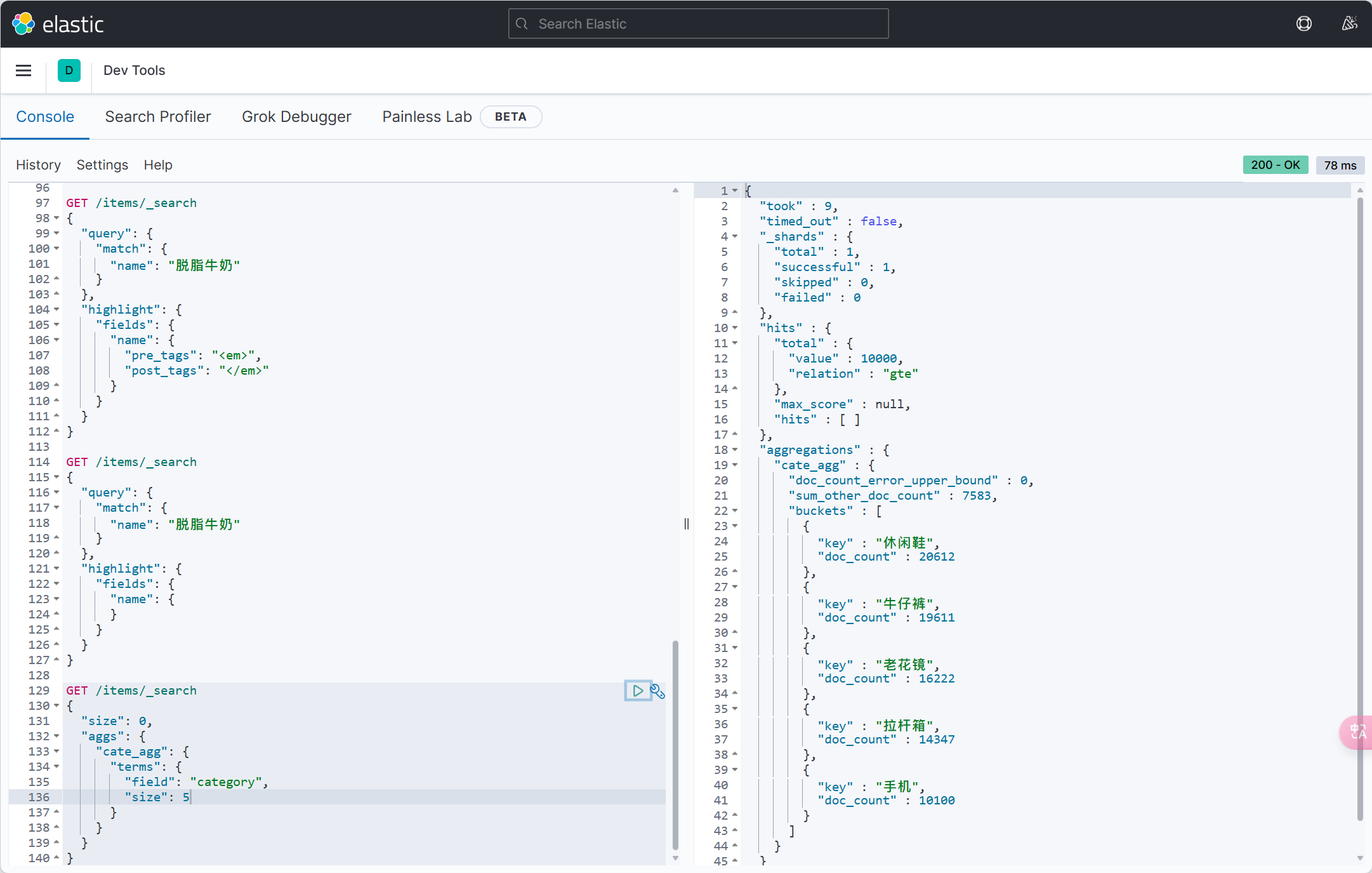
GET /items/_search
{
"size": 0,
"aggs": {
"cate_agg": {
"terms": {
"field": "category",
"size": 3
}
},
"brand_agg": {
"terms": {
"field": "brand",
"size": 3
}
}
}
}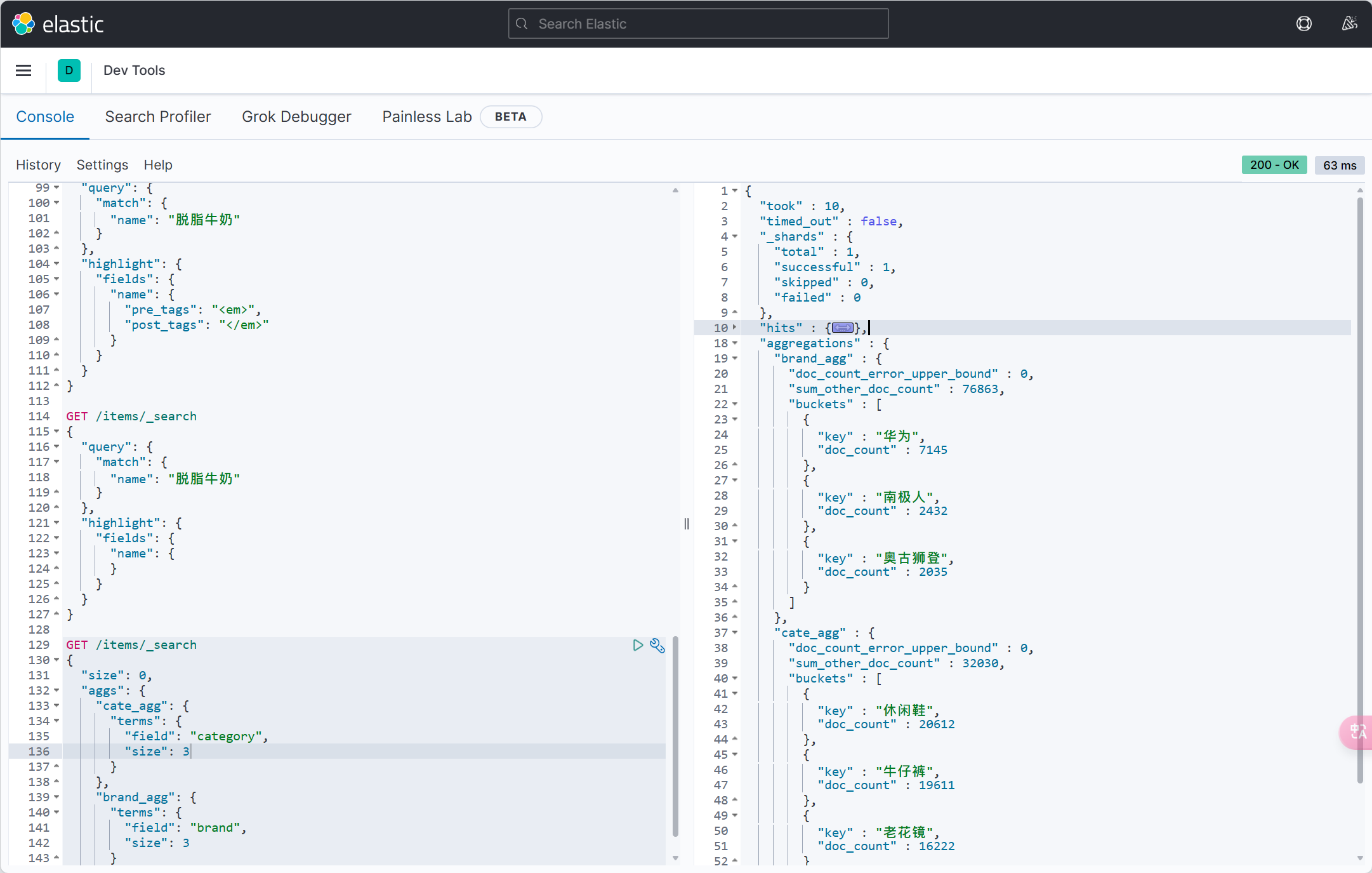
带条件聚合
GET /items/_search
{
"size": 0,
"aggs": {
"brand_agg": {
"terms": {
"field": "brand",
"size": 3
}
}
},
"query": {
"bool": {
"filter": [
{
"term": {
"category": "手机"
}
},
{
"range": {
"price": {
"gte": 300000
}
}
}
]
}
}
}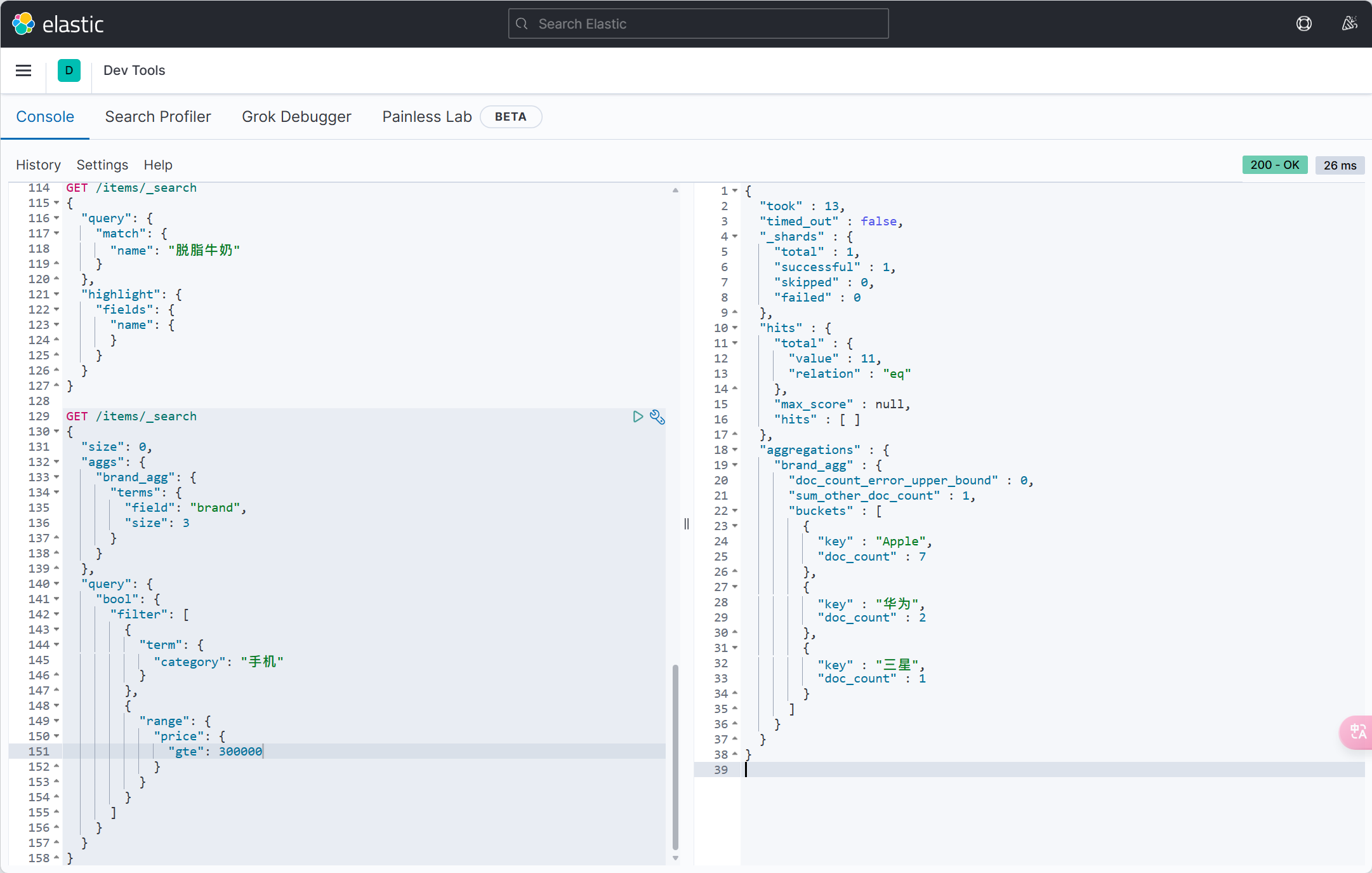
进一步做数据计算和统计
分组嵌套
stat聚合,可以同时获取min、max、avg等结果
GET /items/_search
{
"query": {
"bool": {
"filter": [
{
"term": {
"category": "手机"
}
}
]
}
},
"size": 0,
"aggs": {
"brand_agg": {
"terms": {
"field": "brand",
"size": 10
},
"aggs": {
"price_stats": {
"stats": {
"field": "price"
}
}
}
}
}
}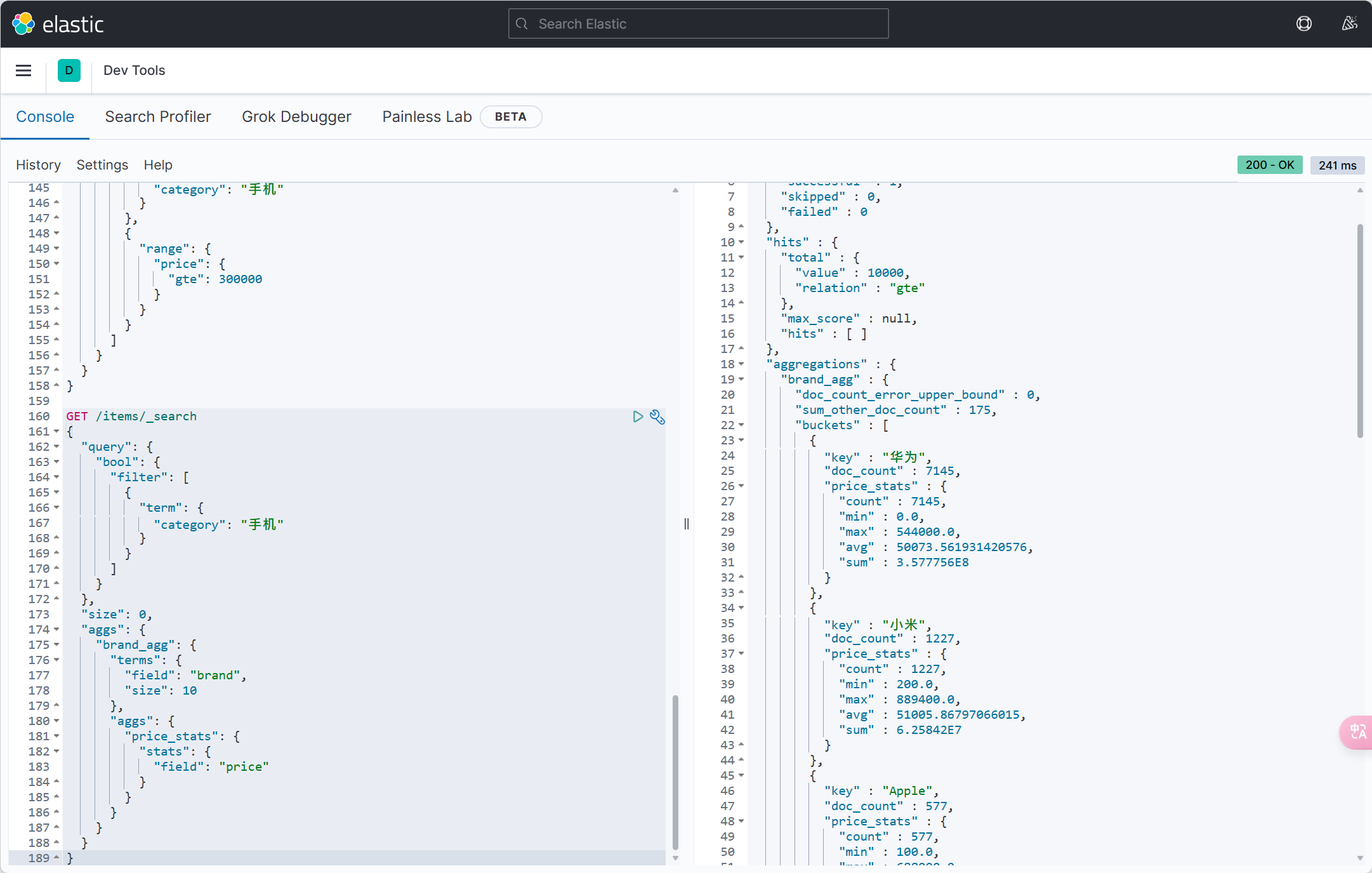
在brand_agg聚合的内部,我们新加了一个aggs参数。这个聚合就是brand_agg的子聚合,会对brand_agg形成的每个桶中的文档分别统计。
stats_meric:聚合名称stats:聚合类型,stats是metric聚合的一种field:聚合字段,这里选择price,统计价格
Java客户端实现聚合
@Test
void testAgg() throws IOException {
int pageNo = 1, pageSize = 5;
// 创建搜索请求,指定索引名称为 "items"
SearchRequest request = new SearchRequest("items");
// 设置返回结果的大小为 0,表示不返回文档内容,只返回聚合结果
request.source().size(0);
// 定义品牌聚合的名称
String brandAggName = "brandAgg";
// 添加品牌聚合,按照 "brand" 字段分组,返回前 5 个分组
request.source().aggregation(
AggregationBuilders.terms(brandAggName).field("brand").size(5)
);
// 执行搜索请求,获取搜索响应
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
// 获取聚合结果
Aggregations aggregations = response.getAggregations();
// 获取品牌聚合结果
🚩🚩🚩
// 用子类Terms接收,不用Aggregations
Terms brandTerms = aggregations.get(brandAggName);
// 获取每个分组的桶
List<? extends Terms.Bucket> buckets = brandTerms.getBuckets();
// 遍历每一个桶,打印品牌名称和文档数量
for (Terms.Bucket bucket : buckets) {
String brandName = bucket.getKeyAsString(); // 获取品牌名称
long docCount = bucket.getDocCount(); // 获取该品牌的文档数量
System.out.println(brandName + ":" + docCount); // 打印品牌名称和文档数量
}
}华为:7145
南极人:2432
奥古狮登:2035
森马:2005
恒源祥:1856