
八股-微服务
微服务相关面试题
SpringCloud
SpringCloud 5 大组件
SpringCloudAlibba:
注册中心、配置中心 Nacos
远程调用 OpenFeign
负载均衡 Ribbon
服务熔断 Sentinel
网关 Gateway
服务注册和发现是什么意思?SpringCloud 如何实现服务注册发现?
nacos 工作流程
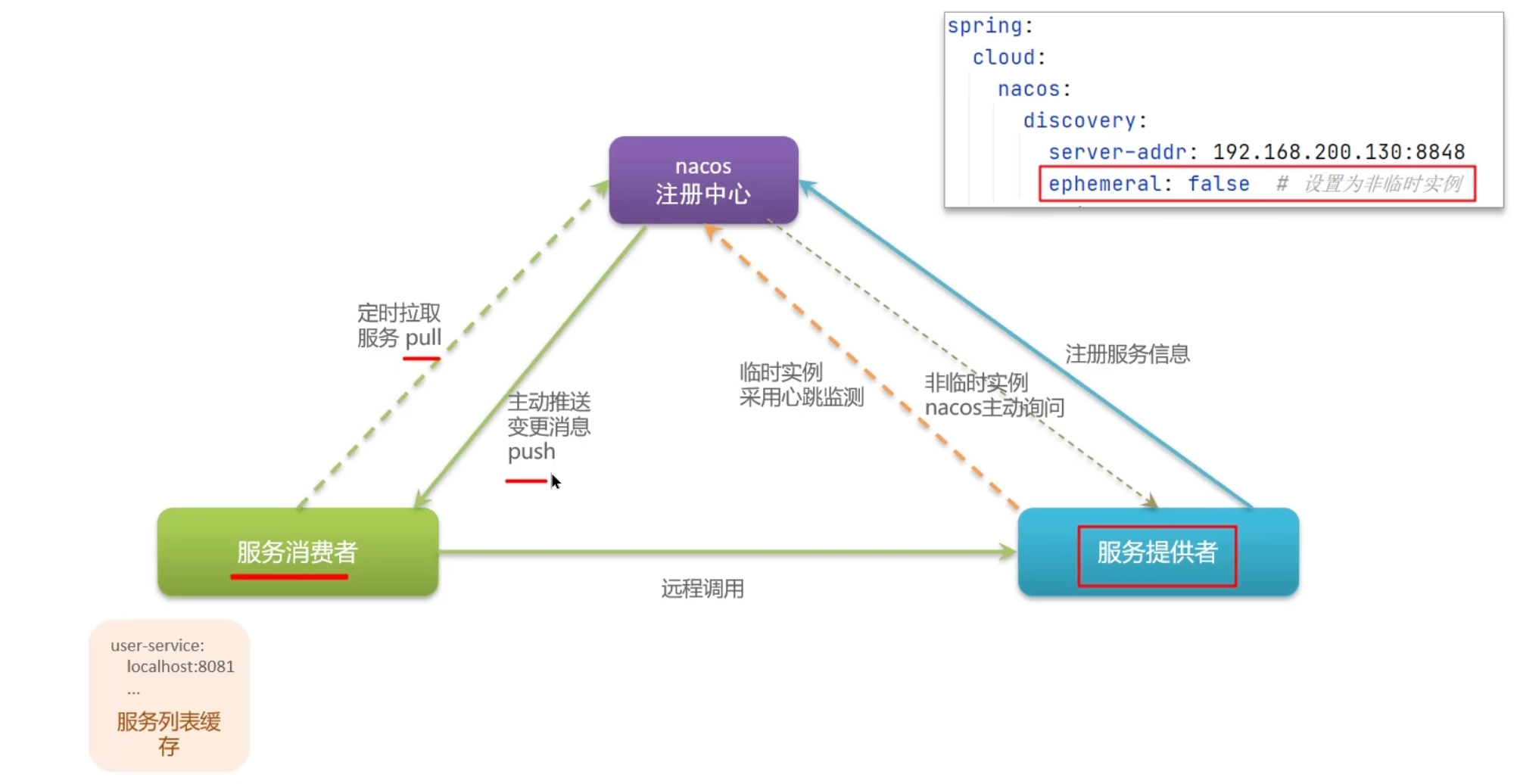
Nacos与Eureka的共同点(注册中心):
① 都支持服务注册与服务拉取
② 都支持服务提供者通过心跳方式做健康检测
Nacos与Eureka的区别(注册中心):
① Nacos支持服务端主动检测提供者状态:临时实例采用心跳模式,非临时实例采用主动检测模式
② 临时实例心跳不正常会被剔除,非临时实例则不会被剔除
③ Nacos支持服务列表变更的消息推送模式,服务列表更新更及时
④ Nacos集群默认采用AP方式,当集群中存在非临时实例时,采用CP模式;Eureka采用AP方式
Nacos还支持了配置中心,而Eureka仅有注册中心,这也是选择使用Nacos的一个重要原因
服务注册与发现的基本概念
什么是服务注册
服务注册是指在微服务架构中,各个服务实例在启动时将自身的关键信息(如服务名、IP地址、端口号、版本号等)主动注册到一个统一的注册中心的过程。注册中心维护了一个服务清单,保存了所有可用服务实例的信息
什么是服务发现
服务发现是指微服务在需要调用另一个服务时,不再通过硬编码方式指定目标服务的地址,而是通过注册中心查询目标服务的可用实例列表,然后根据负载均衡策略选择一个实例进行调用的过程
为什么需要服务注册与发现
在微服务架构中,服务注册与发现机制解决了以下问题:
- 动态伸缩:服务可以根据需求动态增加或减少实例,无需修改配置
- 自动容错:当服务实例宕机时,可以自动从可用列表中剔除
- 负载均衡:可以在多个服务实例之间分散请求
- 统一管理:提供了服务的统一管理视图
Spring Cloud中的服务注册与发现
Spring Cloud提供了服务注册与发现的标准化实现,主要通过以下组件实现:
- 服务注册中心接口:通过
spring-cloud-commons中的ServiceRegistry接口统一抽象 - 服务发现客户端接口:通过
DiscoveryClient接口进行服务发现
Spring Cloud支持多种注册中心实现:
- Spring Cloud Netflix Eureka
- Spring Cloud Consul
- Spring Cloud Zookeeper
- Spring Cloud Alibaba Nacos
- Spring Cloud Kubernetes
Nacos实现服务注册与发现
Nacos简介
Nacos (NAmingCOnfigurationService) 是阿里巴巴开源的一个更易于构建云原生应用的动态服务发现、配置管理和服务管理平台。它不仅提供了服务注册与发现功能,还集成了配置中心功能
在Spring Cloud中集成Nacos注册中心
1. 添加依赖
<!-- Spring Cloud Alibaba Nacos Discovery -->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
</dependency>2. 配置服务注册信息
在application.yml中配置:
spring:
application:
name: service-provider # 服务名称
cloud:
nacos:
discovery:
server-addr: 127.0.0.1:8848 # Nacos服务地址
namespace: public # 命名空间
group: DEFAULT_GROUP # 服务分组
cluster-name: DEFAULT # 集群名称3. 启用服务注册与发现
在启动类上添加注解:
@SpringBootApplication
@EnableDiscoveryClient // 启用服务注册与发现
public class ServiceProviderApplication {
public static void main(String[] args) {
SpringApplication.run(ServiceProviderApplication.class, args);
}
}Nacos服务注册实现原理
服务启动与注册:
- 服务启动时,Nacos客户端向Nacos服务端发送注册请求
- 注册信息包含服务名、IP、端口、集群名等
- Nacos服务端将服务实例信息存储并管理
服务心跳机制:
- 服务实例定期(默认5秒)向Nacos发送心跳包
- Nacos根据心跳判断实例健康状态
- 实例长时间(默认15秒)未发送心跳,标记为不健康
- 更长时间(默认30秒)未收到心跳,将实例从列表中剔除
临时与持久化实例:
- 临时实例:依靠心跳维持,实例宕机后会被自动剔除(默认)
- 持久化实例:手动注册,即使宕机也不会被自动剔除,需要手动删除
Nacos服务发现实现原理
服务消费者初始化:
- 服务消费者启动时,从Nacos获取所有服务列表及其实例
- 本地维护一份服务清单缓存
服务订阅:
- 消费者向Nacos订阅关注的服务
- Nacos建立服务变更推送通道(默认使用UDP)
实时推送更新:
- 当服务实例发生变化时,Nacos会向订阅的消费者推送更新
- 消费者收到推送后更新本地缓存
定时拉取:
- 消费者定期(默认30秒)向Nacos拉取最新服务实例列表
- 作为推送机制的补偿,确保数据最终一致性
Nacos服务调用示例
服务提供者
@RestController
public class ProviderController {
@Value("${server.port}")
private String port;
@GetMapping("/echo/{message}")
public String echo(@PathVariable String message) {
return "Hello Nacos Discovery " + message + " from port: " + port;
}
}服务消费者
@RestController
public class ConsumerController {
@Autowired
private LoadBalancerClient loadBalancerClient;
@Autowired
private RestTemplate restTemplate;
@GetMapping("/consumer/echo/{message}")
public String echo(@PathVariable String message) {
// 通过负载均衡器获取服务实例
ServiceInstance serviceInstance = loadBalancerClient.choose("service-provider");
String url = String.format("http://%s:%s/echo/%s",
serviceInstance.getHost(),
serviceInstance.getPort(),
message);
return restTemplate.getForObject(url, String.class);
}
}更简单的方式是使用@LoadBalanced注解:
@Configuration
public class RestTemplateConfig {
@Bean
@LoadBalanced
public RestTemplate restTemplate() {
return new RestTemplate();
}
}
@RestController
public class ConsumerController {
@Autowired
private RestTemplate restTemplate;
@GetMapping("/consumer/echo/{message}")
public String echo(@PathVariable String message) {
// 直接使用服务名调用
return restTemplate.getForObject(
"http://service-provider/echo/" + message,
String.class);
}
}Nacos在服务注册发现中的高级特性
- 健康检查:支持自定义健康检查,确保只有健康的实例被调用
- 权重配置:可以为实例设置权重,实现流量按比例分配
- 保护阈值:当健康实例比例低于阈值时,Nacos会将不健康实例也视为可用,防止雪崩
- 分组和命名空间:通过分组和命名空间实现服务隔离
- 元数据管理:支持为服务实例添加自定义元数据,用于服务治理
- 多集群支持:支持同一服务部署在不同集群,优先调用同集群实例
Nacos作为服务注册发现组件,凭借其易用性、可靠性和丰富的功能,已成为Spring Cloud生态中受欢迎的选择,特别适合大规模微服务架构
LoadBalancer 负载均衡
Spring Cloud LoadBalancer 简介
Spring Cloud LoadBalancer 是 Spring Cloud 提供的负载均衡框架,作为 Netflix Ribbon 的替代品。自 Spring Cloud Hoxton 版本开始,随着 Netflix 组件进入维护模式,Spring 官方推出了这个纯自研的负载均衡解决方案
Spring Cloud LoadBalancer 是一个客户端负载均衡器,它的核心功能是:
- 从服务注册中心获取可用的服务实例列表
- 使用特定的负载均衡算法选择一个服务实例
- 将请求发送到选中的服务实例
作为 Spring 官方组件,它与 Spring 生态系统无缝集成,支持响应式编程,并且在性能和扩展性方面做了优化
Spring Cloud LoadBalancer 支持的负载均衡策略
Spring Cloud LoadBalancer 内置了几种常用的负载均衡策略:
1. 轮询策略(Round Robin)
实现类:RoundRobinLoadBalancer
原理:按照固定顺序依次选择每个服务实例,是 Spring Cloud LoadBalancer 的默认策略
适用场景:服务实例的硬件配置相当,负载均衡的请求复杂度类似的场景
2. 随机策略(Random)
实现类:RandomLoadBalancer
原理:从服务实例列表中随机选择一个实例
适用场景:适用于请求负载差异较大,或者希望请求分配更加均匀的场景
3. 权重轮询策略(Weighted Round Robin)
实现类:在 Spring Cloud 2022.x 版本后默认支持
原理:根据服务实例的权重值进行轮询,权重高的实例被选中的概率更大
适用场景:集群中不同实例性能差异较大,需要将更多请求分配给性能更好的节点
如何自定义负载均衡策略
在 Spring Cloud LoadBalancer 中,可以通过多种方式自定义负载均衡策略:
1. 配置方式指定内置策略
在 application.yml 中进行配置:
spring:
cloud:
loadbalancer:
clients:
service-name: # 指定服务名
hint:
loadBalancerTag: zone1 # 区域标签
configuration:
type: random # 指定负载均衡策略类型(默认是round-robin)2. 编程方式配置负载均衡策略
创建配置类,注册自定义的 ReactorLoadBalancer bean:
@Configuration
public class CustomLoadBalancerConfig {
@Bean
@Primary
public ReactorLoadBalancer<ServiceInstance> randomLoadBalancer(
Environment environment,
LoadBalancerClientFactory loadBalancerClientFactory) {
String serviceName = environment.getProperty(LoadBalancerClientFactory.PROPERTY_NAME);
return new RandomLoadBalancer(
loadBalancerClientFactory.getLazyProvider(serviceName, ServiceInstanceListSupplier.class),
serviceName);
}
}然后在应用中应用此配置:
@Configuration
@LoadBalancerClient(name = "service-name", configuration = CustomLoadBalancerConfig.class)
public class WebClientConfig {
// 配置代码
}3. 实现自定义负载均衡策略
步骤一:创建自定义的 ServiceInstanceListSupplier(可选,如果需要特殊的实例过滤或排序):
public class CustomServiceInstanceListSupplier implements ServiceInstanceListSupplier {
private final ServiceInstanceListSupplier delegate;
public CustomServiceInstanceListSupplier(ServiceInstanceListSupplier delegate) {
this.delegate = delegate;
}
@Override
public String getServiceId() {
return delegate.getServiceId();
}
@Override
public Flux<List<ServiceInstance>> get() {
return delegate.get().map(instances -> {
// 在这里实现自定义的筛选或排序逻辑
return instances;
});
}
}步骤二:创建自定义的 ReactorLoadBalancer 实现:
public class CustomLoadBalancer implements ReactorServiceInstanceLoadBalancer {
private final String serviceId;
private final ObjectProvider<ServiceInstanceListSupplier> serviceInstanceListSupplierProvider;
public CustomLoadBalancer(ObjectProvider<ServiceInstanceListSupplier> serviceInstanceListSupplierProvider,
String serviceId) {
this.serviceInstanceListSupplierProvider = serviceInstanceListSupplierProvider;
this.serviceId = serviceId;
}
@Override
public Mono<Response<ServiceInstance>> choose(Request request) {
ServiceInstanceListSupplier supplier = serviceInstanceListSupplierProvider.getIfAvailable();
return supplier.get().next()
.map(serviceInstances -> {
// 实现自己的负载均衡算法
ServiceInstance instance = ... // 你的选择算法
return new DefaultResponse(instance);
});
}
}步骤三:配置使用自定义负载均衡器:
@Configuration
public class CustomLoadBalancerConfiguration {
@Bean
public ServiceInstanceListSupplier discoveryClientServiceInstanceListSupplier(
ConfigurableApplicationContext context) {
return ServiceInstanceListSupplier.builder()
.withDiscoveryClient()
.withCaching()
.with(serviceInstanceList -> new CustomServiceInstanceListSupplier(serviceInstanceList))
.build(context);
}
@Bean
public ReactorLoadBalancer<ServiceInstance> customLoadBalancer(Environment environment,
LoadBalancerClientFactory loadBalancerClientFactory) {
String name = environment.getProperty(LoadBalancerClientFactory.PROPERTY_NAME);
return new CustomLoadBalancer(
loadBalancerClientFactory.getLazyProvider(name, ServiceInstanceListSupplier.class),
name);
}
}4. 自定义复杂负载均衡策略示例
下面是一个基于实例响应时间的负载均衡策略示例:
public class ResponseTimeLoadBalancer implements ReactorServiceInstanceLoadBalancer {
private final String serviceId;
private final ObjectProvider<ServiceInstanceListSupplier> serviceInstanceListSupplierProvider;
private final ConcurrentHashMap<String, AtomicLong> responseTimeMap = new ConcurrentHashMap<>();
public ResponseTimeLoadBalancer(ObjectProvider<ServiceInstanceListSupplier> serviceInstanceListSupplierProvider,
String serviceId) {
this.serviceInstanceListSupplierProvider = serviceInstanceListSupplierProvider;
this.serviceId = serviceId;
}
@Override
public Mono<Response<ServiceInstance>> choose(Request request) {
ServiceInstanceListSupplier supplier = serviceInstanceListSupplierProvider.getIfAvailable();
return supplier.get().next().map(instances -> {
// 选择响应时间最短的实例
ServiceInstance instance = instances.stream()
.min(Comparator.comparingLong(this::getInstanceResponseTime))
.orElse(null);
if (instance == null && !instances.isEmpty()) {
instance = instances.get(0);
}
return new DefaultResponse(instance);
});
}
private long getInstanceResponseTime(ServiceInstance instance) {
String key = instance.getHost() + ":" + instance.getPort();
return responseTimeMap.computeIfAbsent(key, k -> new AtomicLong(0)).get();
}
// 提供更新响应时间的方法
public void updateResponseTime(String host, int port, long responseTime) {
String key = host + ":" + port;
responseTimeMap.computeIfAbsent(key, k -> new AtomicLong(0)).set(responseTime);
}
}在实际应用中使用负载均衡
在 Spring Cloud 应用中,可以结合 RestTemplate 或 WebClient 使用负载均衡:
使用 RestTemplate
@Configuration
public class RestConfig {
@Bean
@LoadBalanced
public RestTemplate restTemplate() {
return new RestTemplate();
}
}
@Service
public class UserService {
@Autowired
private RestTemplate restTemplate;
public User getUser(Long id) {
// 直接使用服务名调用,负载均衡器会选择一个实例
return restTemplate.getForObject("http://user-service/users/" + id, User.class);
}
}使用 WebClient(响应式)
@Configuration
public class WebClientConfig {
@Bean
@LoadBalanced
public WebClient.Builder webClientBuilder() {
return WebClient.builder();
}
}
@Service
public class UserService {
@Autowired
private WebClient.Builder webClientBuilder;
public Mono<User> getUser(Long id) {
return webClientBuilder.build()
.get()
.uri("http://user-service/users/{id}", id)
.retrieve()
.bodyToMono(User.class);
}
}
服务雪崩、熔断降级
回答:
服务雪崩:指一个服务故障导致整条链路中的所有服务均出现故障的情形
服务降级:这是一种服务自我保护或保护下游服务的策略,旨在确保服务在面对请求突增时不会变得不可用,避免服务崩溃。在实际开发中,通常与feign接口结合,编写相应的降级逻辑
服务熔断:默认处于关闭状态,需手动开启。当检测到10秒内请求的失败率超过50%时,将触发熔断机制。随后,每隔5秒尝试重新请求微服务。若微服务无法响应,则继续执行熔断机制。一旦微服务恢复正常,熔断机制将被关闭,服务恢复到正常请求状态
微服务雪崩是指在微服务架构中,一个服务的故障如滚雪球般迅速蔓延到整个系统的现象。当某个基础服务失败或响应变慢时,会导致调用它的上游服务也开始积压请求,耗尽线程池和连接资源。这种连锁反应会层层传递,最终可能导致整个服务集群不可用,就像雪崩一样从一个小点开始,最终造成大面积的系统崩溃
雪崩的典型触发场景包括:某个服务实例宕机、数据库连接耗尽、外部依赖超时、流量突增等。其危害性极大,会导致用户请求大面积失败,系统恢复困难,甚至造成数据不一致
为防止雪崩,微服务架构中通常采用以下关键策略:熔断器机制(如Hystrix/Sentinel)及时阻断故障扩散;限流措施控制请求量;服务降级提供备选方案;超时控制避免长时间等待;资源隔离确保故障范围受限;以及服务实例备份实现冗余容错。这些措施共同构成了微服务韧性设计的核心,确保局部故障不会演变为全局灾难
服务熔断(Circuit Breaking) 是微服务架构中的一种保护机制,当某个服务频繁失败到达阈值时,会"熔断"该服务的调用,快速返回错误响应,防止故障扩散。就像电路保险丝,当电流过大时自动断开电路,保护整体系统
服务降级(Service Degradation) 是指当服务出现问题或超负荷时,主动降低服务质量,提供有损但可用的服务,确保核心功能正常运行。例如,暂时关闭推荐功能,只保留搜索和下单等核心功能
Sentinel简介
阿里巴巴开源的Sentinel是一款流量治理组件,提供了熔断降级、流量控制、系统负载保护等多种容错能力。相比Netflix Hystrix,Sentinel具有更丰富的规则配置、实时监控和动态调整能力
Sentinel实现服务熔断
熔断策略
Sentinel支持三种熔断策略:
- 慢调用比例(SLOW_REQUEST_RATIO) :统计指定时间内请求响应时间超过阈值的比例,当比例超过阈值,触发熔断
- 异常比例(ERROR_RATIO) :统计指定时间内请求出现异常的比例,超过阈值触发熔断
- 异常数(ERROR_COUNT) :统计指定时间内异常请求数量,超过阈值触发熔断
代码实现
// 1. 添加依赖
// <dependency>
// <groupId>com.alibaba.cloud</groupId>
// <artifactId>spring-cloud-starter-alibaba-sentinel</artifactId>
// </dependency>
// 2. 定义资源
@RestController
public class OrderController {
@GetMapping("/order/{id}")
@SentinelResource(value = "getOrder",
blockHandler = "getOrderBlockHandler",
fallback = "getOrderFallback")
public Order getOrder(@PathVariable Long id) {
// 业务逻辑
return orderService.queryOrderById(id);
}
// 熔断/限流处理
public Order getOrderBlockHandler(Long id, BlockException e) {
log.warn("getOrder被限流或熔断", e);
return Order.defaultOrder(id);
}
// 异常降级处理
public Order getOrderFallback(Long id, Throwable e) {
log.error("getOrder调用异常", e);
return Order.defaultOrder(id);
}
}熔断规则配置
通过代码方式配置熔断规则:
@PostConstruct
public void initDegradeRule() {
List<DegradeRule> rules = new ArrayList<>();
// 慢调用比例熔断
DegradeRule rule = new DegradeRule("getOrder")
.setGrade(CircuitBreakerStrategy.SLOW_REQUEST_RATIO.getType())
.setCount(100) // 慢请求阈值(ms)
.setTimeWindow(10) // 熔断时长(s)
.setMinRequestAmount(5) // 最小请求数
.setStatIntervalMs(1000) // 统计周期(ms)
.setSlowRatioThreshold(0.5);// 慢请求比例阈值
rules.add(rule);
// 异常比例熔断
DegradeRule rule2 = new DegradeRule("getOrder")
.setGrade(CircuitBreakerStrategy.ERROR_RATIO.getType())
.setCount(0.5) // 异常比例阈值(0.5表示50%)
.setTimeWindow(10)
.setMinRequestAmount(5)
.setStatIntervalMs(1000);
rules.add(rule2);
DegradeRuleManager.loadRules(rules);
}也可以通过Sentinel控制台动态配置规则
Sentinel实现服务降级
降级方式
Sentinel通过以下方式实现服务降级:
- @SentinelResource注解:指定降级方法
- Feign集成:为Feign客户端提供降级实现
- 全局降级配置:统一处理所有资源的降级逻辑
Feign集成降级
# application.yml
feign:
sentinel:
enabled: true # 启用Sentinel对Feign的支持// 定义Feign接口和降级实现
@FeignClient(name = "product-service", fallback = ProductServiceFallback.class)
public interface ProductService {
@GetMapping("/products/{id}")
Product getProduct(@PathVariable("id") Long id);
}
// 降级实现类
@Component
public class ProductServiceFallback implements ProductService {
@Override
public Product getProduct(Long id) {
return new Product(id, "默认商品", new BigDecimal("0.00"), "暂时无法获取商品信息");
}
}全局服务降级
@Configuration
public class SentinelConfig {
@Bean
public SentinelResourceAspect sentinelResourceAspect() {
return new SentinelResourceAspect();
}
@PostConstruct
public void init() {
// 设置全局降级处理
BlockExceptionHandler blockExceptionHandler = (request, response, e) -> {
// 不同异常类型的处理
String msg;
if (e instanceof FlowException) {
msg = "系统繁忙,请稍后再试";
} else if (e instanceof DegradeException) {
msg = "服务暂时不可用,请稍后再试";
} else if (e instanceof ParamFlowException) {
msg = "请求参数异常";
} else {
msg = "系统异常,请稍后再试";
}
// 返回JSON结果
response.setStatus(200);
response.setContentType("application/json;charset=utf-8");
response.getWriter().write("{\"code\": 429, \"message\": \"" + msg + "\"}");
};
WebCallbackManager.setBlockHandler(blockExceptionHandler);
}
}熔断降级状态机制
Sentinel的熔断器有三种状态:
- 关闭状态(Closed) :正常调用,并统计异常/慢调用比例
- 开启状态(Open) :触发熔断条件后,所有请求快速失败
- 半开状态(Half-Open) :熔断时长结束后,尝试恢复,允许一个请求通过,成功则关闭熔断器,失败则重新进入开启状态
微服务怎么监控
项目中采用的Skywalking进行监控:
- Skywalking主要可以监控接口、服务、物理实例的状态。特别是在压测时,可以看到众多服务中哪些服务和接口比较慢,我们可以针对性地进行分析和优化
- 我们在Skywalking中设置了告警规则,特别是在项目上线后,若出现报错,我们分别设置了可向相关负责人发送短信和邮件,以便第一时间了解项目的bug情况,并迅速修复
为什么要监控
zipkin 和 skywalking 是链路追踪工具,也有监控作用
skywalking
一个分布式系统的应用程序性能监控工具(Application Performance Managment),提供了完善的链路追踪能力。Apache的顶级项目(由前华为产品经理吴晟主导开源)
- 服务(Service):业务资源应用系统(微服务)
- 端点(Endpoint):应用系统对外暴露的功能接口(接口)
- 实例(Instance):物理机
业务相关
微服务限流
回答:
业务限流介绍
在何种情况下进行限流,需明确QPS的具体数值。
例如,当时我们举办了一个活动,假期期间用户会抢购优惠券,QPS峰值可达2000,平时在10-50之间。为应对突发流量,需进行限流常规限流 为防止恶意攻击,保障系统正常运行,当时系统承受的最大QPS是多少(压测结果)
Nginx限流
控制速率(应对突发流量),采用漏桶算法进行过滤,确保请求以固定速率处理,以应对突发流量
控制并发数,限制单个进程的连接数和总并发连接数
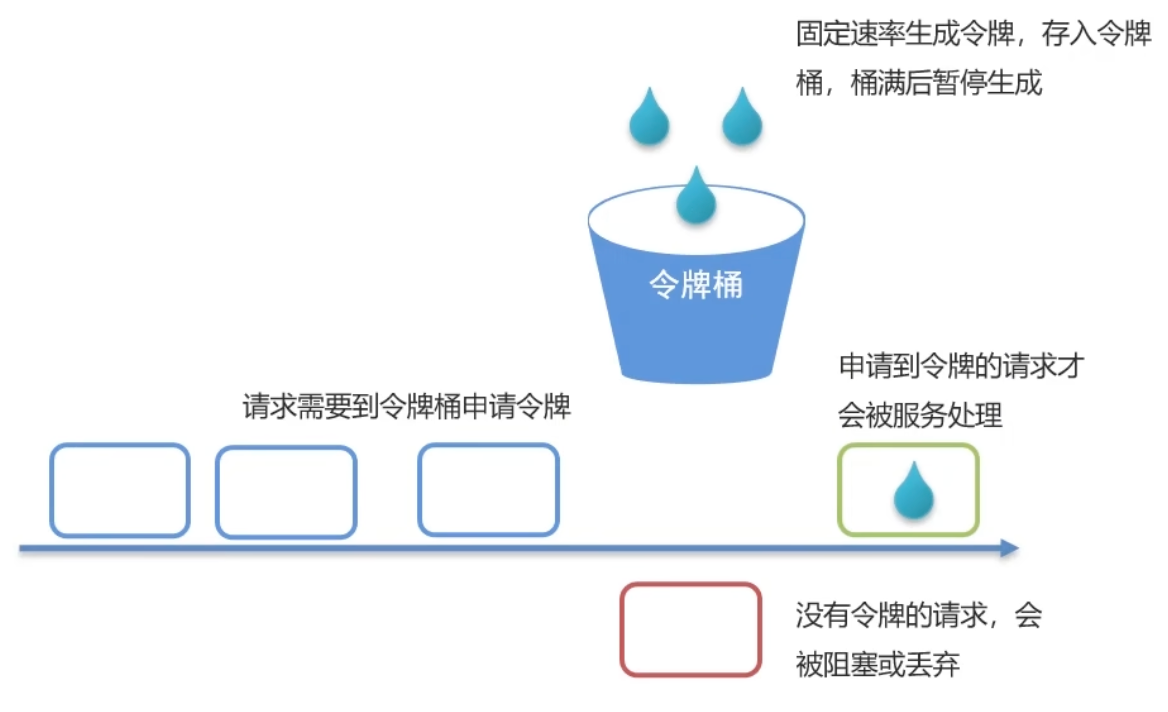
网关限流
在Spring Cloud Gateway中,支持使用局部过滤器RequestRateLimiter进行限流,该过滤器采用令牌桶算法
可根据路径进行限流,可设置每秒填充的平均速率和令牌桶的总容量
为什么要做限流
- 并发的确大(突发流量)
- 防止用户恶意刷接口
限流的实现方式
- tomcat:可以设置最大连接数(单体项目作用比较大)
- nginx:漏桶算法(重点说)
- 网关:令牌桶算法(重点说)
- 自定义拦截器
Nginx 限流

控制速率(突发流量)
http {
limit_req_zone $binary_remote_addr zone=service1RateLimit:10m rate=10r/s;
server {
listen 80;
server_name localhost;
location / {
limit_req zone=service1RateLimit burst=20 nodelay;
proxy_pass http://targetserver;
}
}
}语法:
limit_req_zone key zone rate-
key: 定义限流对象,binary_remote_addr 基于客户端 IP 限流 -
zone: 定义共享存储区来存储访问信息,10m 可以存储 16 万个 IP 地址的访问信息 -
rate: 最大访问速率,rate=10r/s 表示每秒最多请求 10 个请求 -
burst=20: 相当于桶的大小 -
nodelay: 快速处理
-
控制并发连接数
http {
limit_conn_zone $binary_remote_addr zone=perip:10m;
limit_conn_zone $server_name zone=perserver:10m;
server {
listen 80;
server_name localhost;
location / {
limit_conn perip 20;
limit_conn perserver 100;
proxy_pass http://targetserver;
}
}
}-
limit_conn perip 20: 对应的 key 是$binary_remote_addr,表示限制单个 IP 同时最多能持有 20 个连接 -
limit_conn perserver 100: 对应的 key 是$server_name,表示虚拟主机 (server) 同时能处理并发连接的总数为 100
网关限流
分布式系统理论-CAP、BASE
回答:
● CAP定理(一致性、可用性、分区容错性)
- 分布式系统节点通过网络连接,必然会出现分区问题(P)
- 当分区发生时,系统的一致性(C)和可用性(A)无法同时得到满足
● BASE理论
- 基本可用
- 软状态
- 最终一致
● 解决分布式事务的思想和模型:
- 最终一致思想:各分支事务分别执行并提交,若出现不一致,则设法恢复数据(AP)
- 强一致思想:各分支事务执行业务后不立即提交,等待彼此结果。随后统一提交或回滚(CP)
CAP 定理
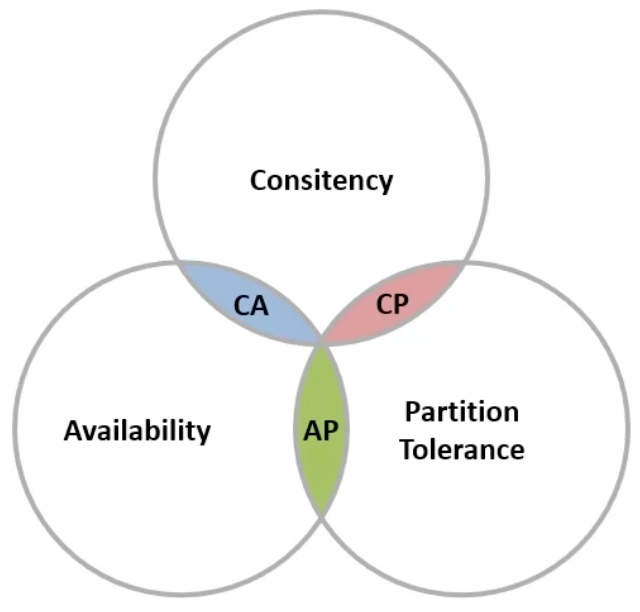
- 一致性(Consistency)
- 可用性(Availability)
- 分区容错性(Partition Tolerance)
Eric Brewer指出,分布式系统无法同时满足这三个指标
此结论被称作CAP定理
Consistency
用户访问分布式系统中的任意节点,得到的数据必须一致
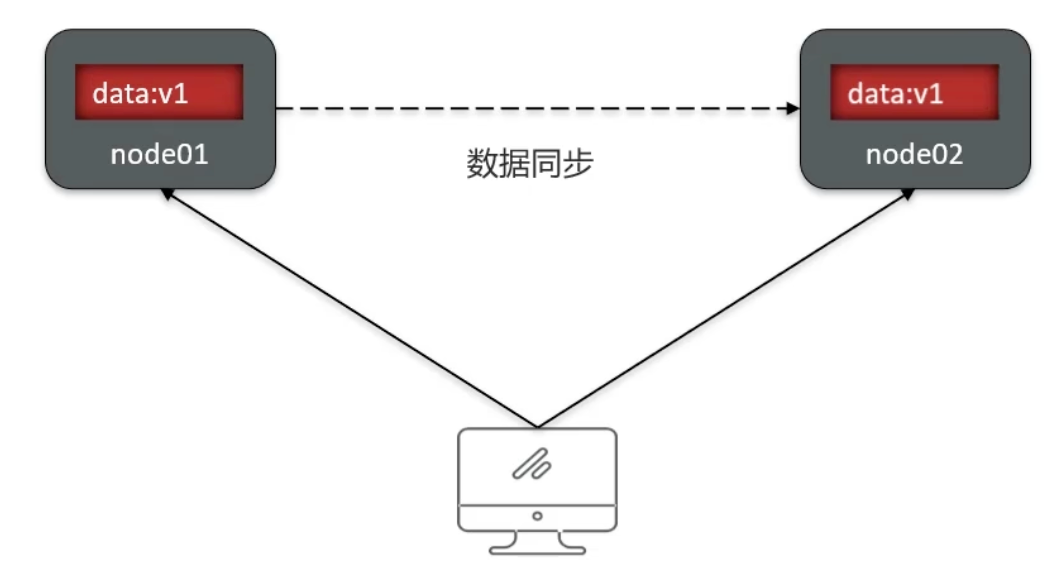
Availability
用户访问集群中的任意健康节点,必须能得到响应,而不是超时或拒绝
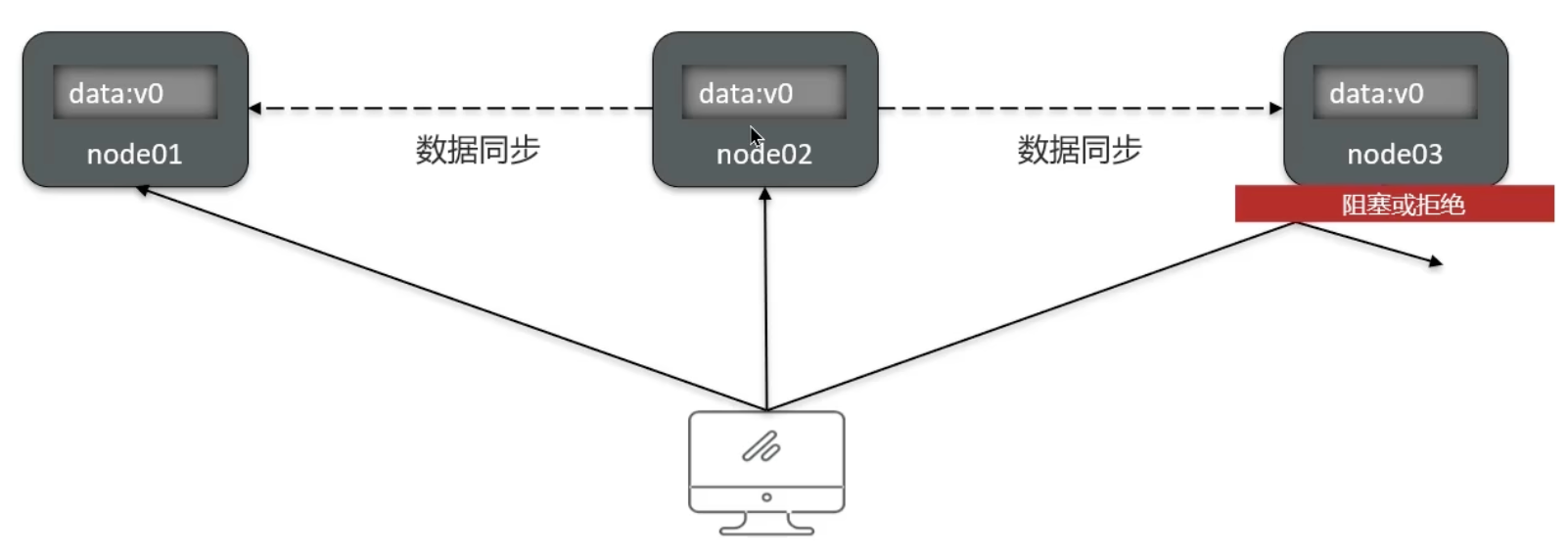
Partition Tolerance
Partition(分区):因网络故障或其他原因,导致分布式系统中的部分节点与其他节点失去连接,从而形成独立分区
Tolerance(容错):集群出现分区时,整个系统仍需持续对外提供服务
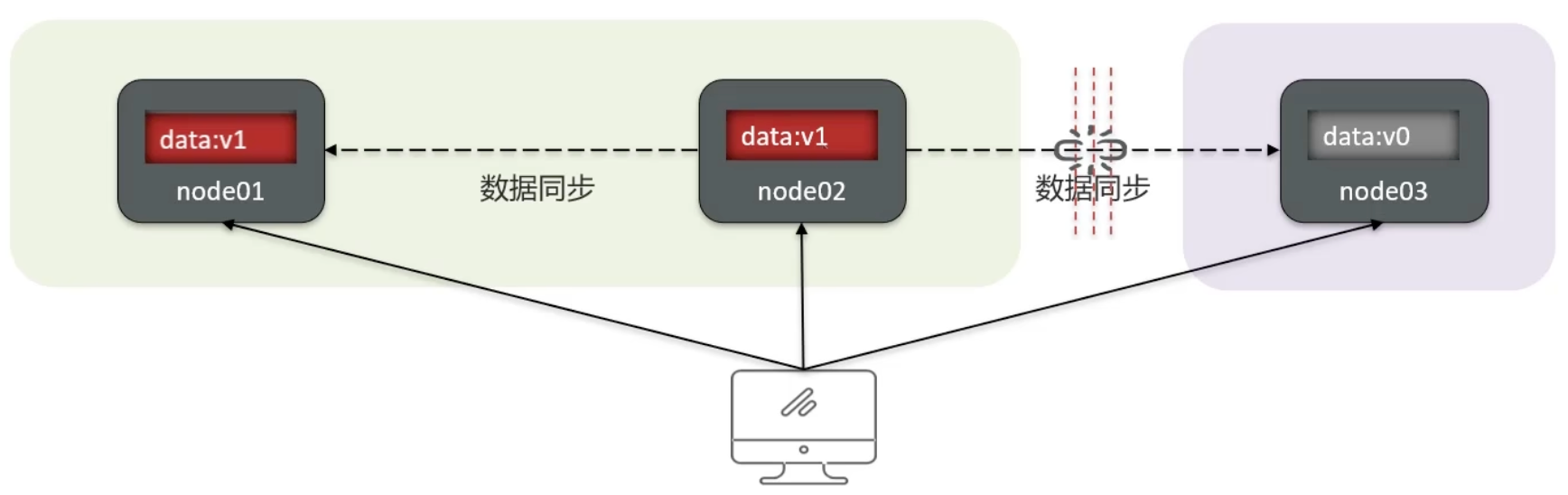
结论:
分布式系统节点之间必然需要网络连接,分区(P)是不可避免的现象
若要保证访问的高可用性(A),则可以持续对外提供服务,但无法保证数据的强一致性→AP
若要保证访问的数据强一致性(C),则需放弃高可用性→CP
BASE 理论
BASE理论是对CAP原则的一种解决思路,包含以下三个核心思想:
- 基本可用:分布式系统在遇到故障时,可以容忍一定程度的服务可用性降低,即确保核心功能的可用性
- 软状态:在一定的时间范围内,系统允许存在中间状态,例如临时的不一致状态
- 最终一致性:虽然无法确保数据的强一致性,但在软状态结束之后,系统最终能够达到数据的一致性
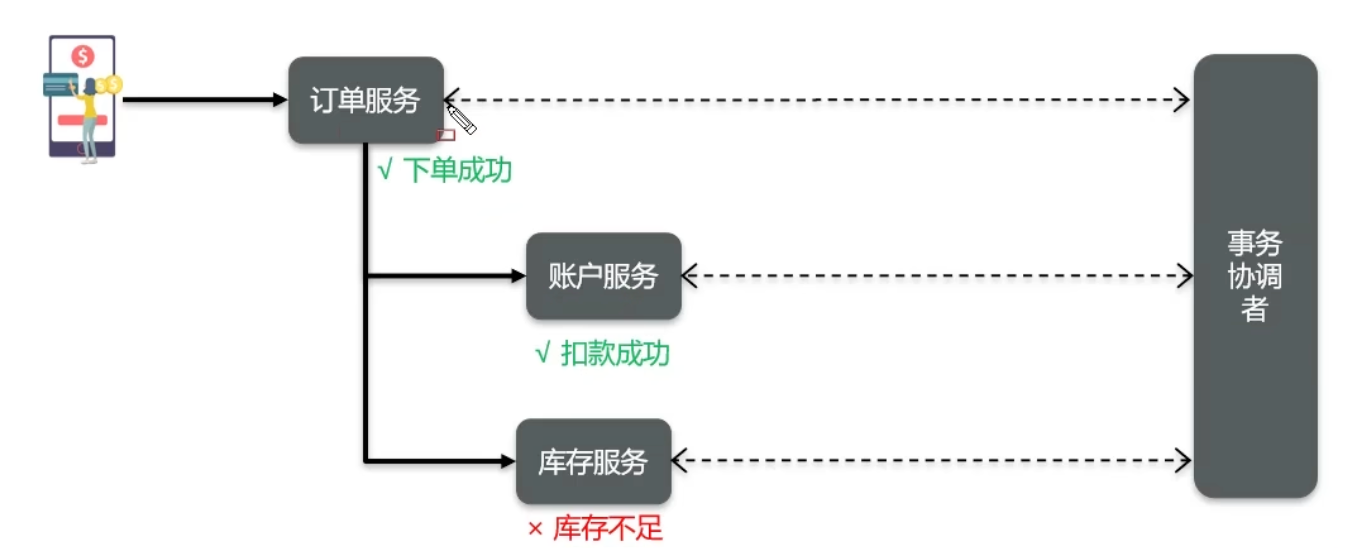
分布式事务解决方案
- 简历上写的微服务,只要是发生了多个服务之间的写操作,都需要进行分布式事务控制
- 描述项目中采用的哪种方案(seata | MQ)
Seata 的 XA 模式
- 特点:CP 模式,需要互相等待各个分支事务提交,可以保证强一致性
- 性能:性能较差
- 适用场景:银行业务
Seata 的 AT 模式
- 特点:AP 模式,底层使用 undo log 实现
- 性能:性能较好
- 适用场景:互联网业务
Seata 的 TCC 模式
- 特点:AP 模式,性能较好,但需要人工编码实现
- 适用场景:银行业务
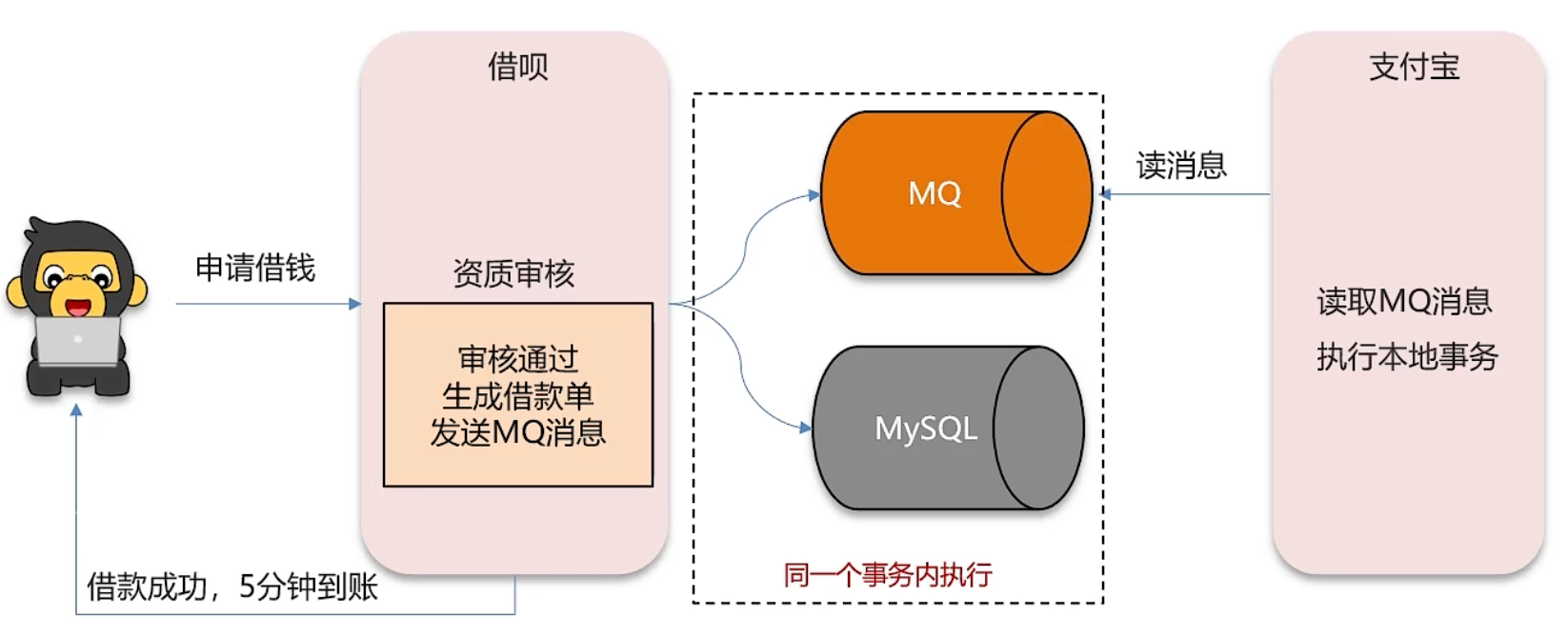
MQ 模式实现分布式事务
- 特点:在 A 服务写数据时,在同一个事务内发送消息到另外一个事务,采用异步方式
- 性能:性能最好
- 适用场景:互联网业务
选择方案:根据业务四选一描述
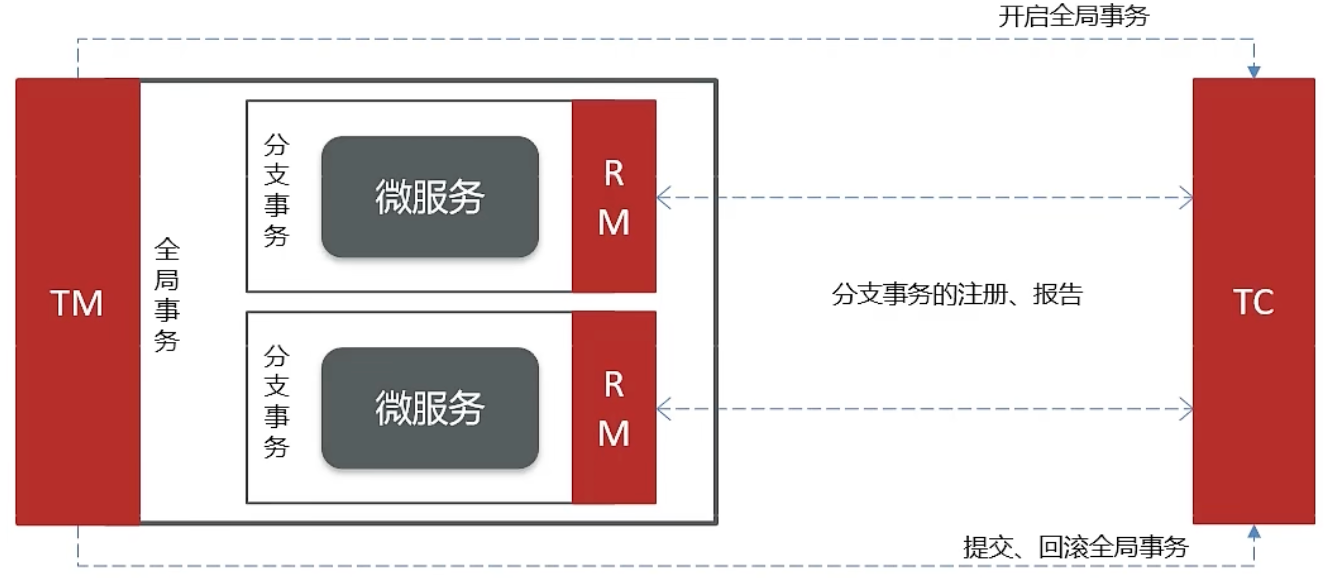
Seata 架构
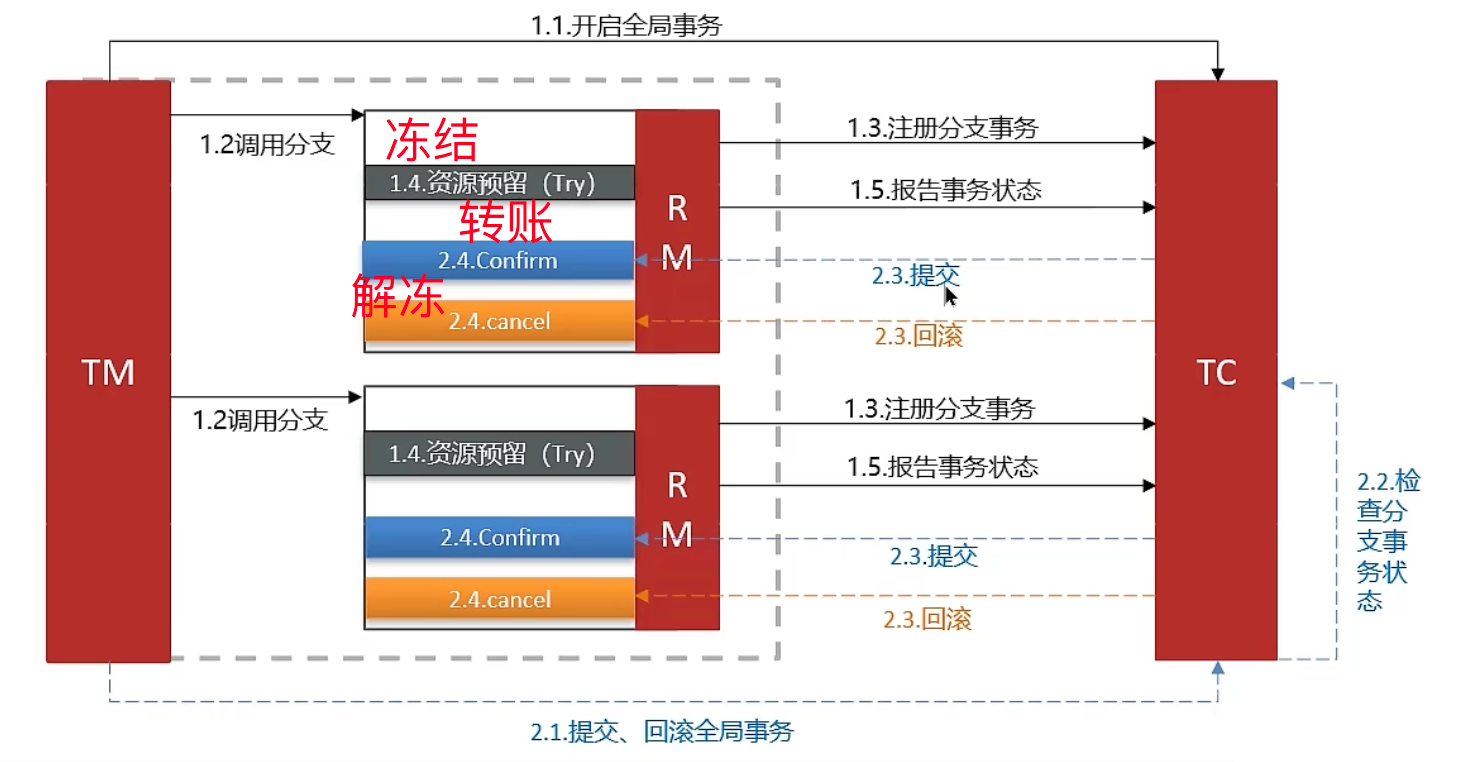
Seata事务管理包含以下三个关键角色:
- TC(Transaction Coordinator)- 事务协调者:负责维护全局与分支事务的状态,协调全局事务的提交或回滚
- TM(Transaction Manager)- 事务管理器:定义全局事务的范围、启动全局事务、提交或回滚全局事务
- RM(Resource Manager)- 资源管理器:管理分支事务处理的资源,与TC进行交流以注册分支事务,报告分支事务状态,并驱动分支事务的提交或回滚
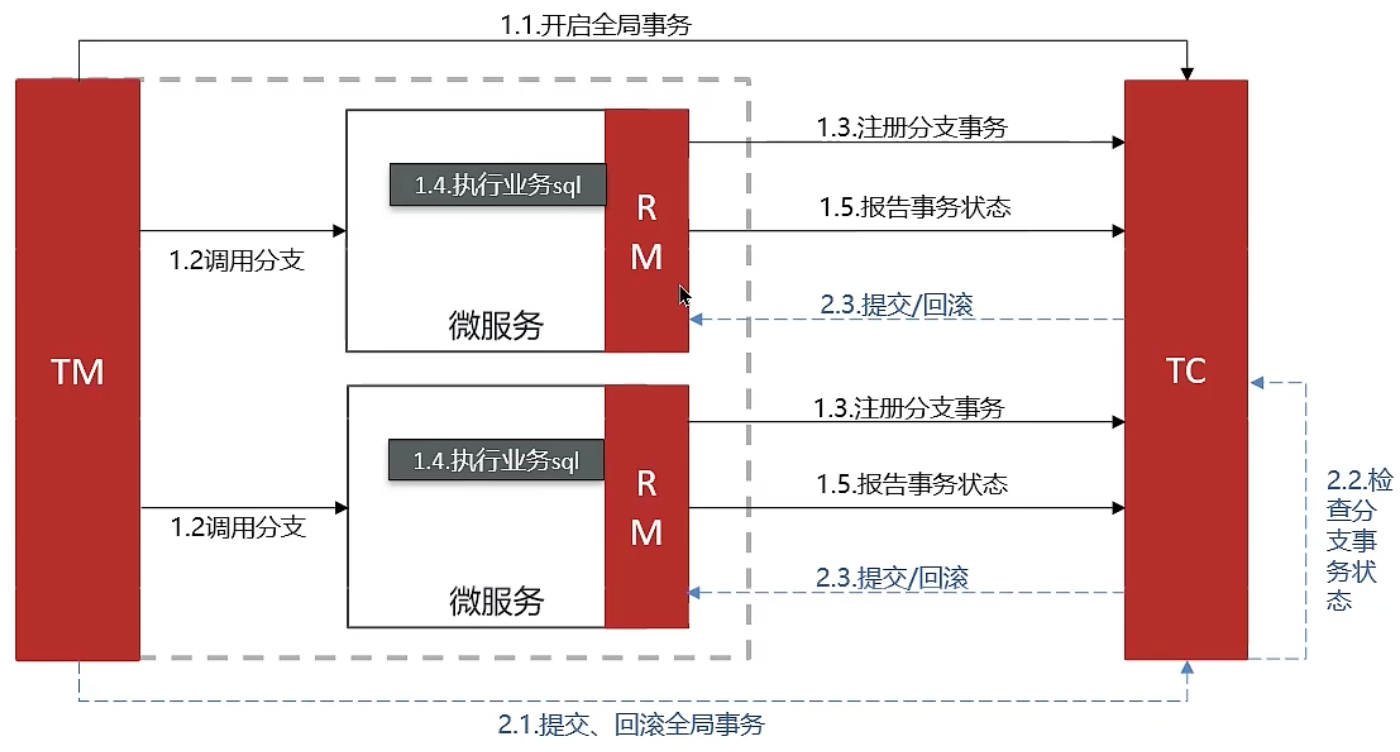
XA 模式
RM一阶段工作:
注册分支事务至TC
执行分支业务sql,暂不提交
向TC报告执行状态
TC二阶段工作:
检测各分支事务执行状态
a. 若均成功,通知所有RM提交事务
b. 若有失败,通知所有RM回滚事务
RM二阶段工作:
接收TC指令,执行事务提交或回滚
保证了数据强一致性,微服务之间需要等待 TC 检查事务状态
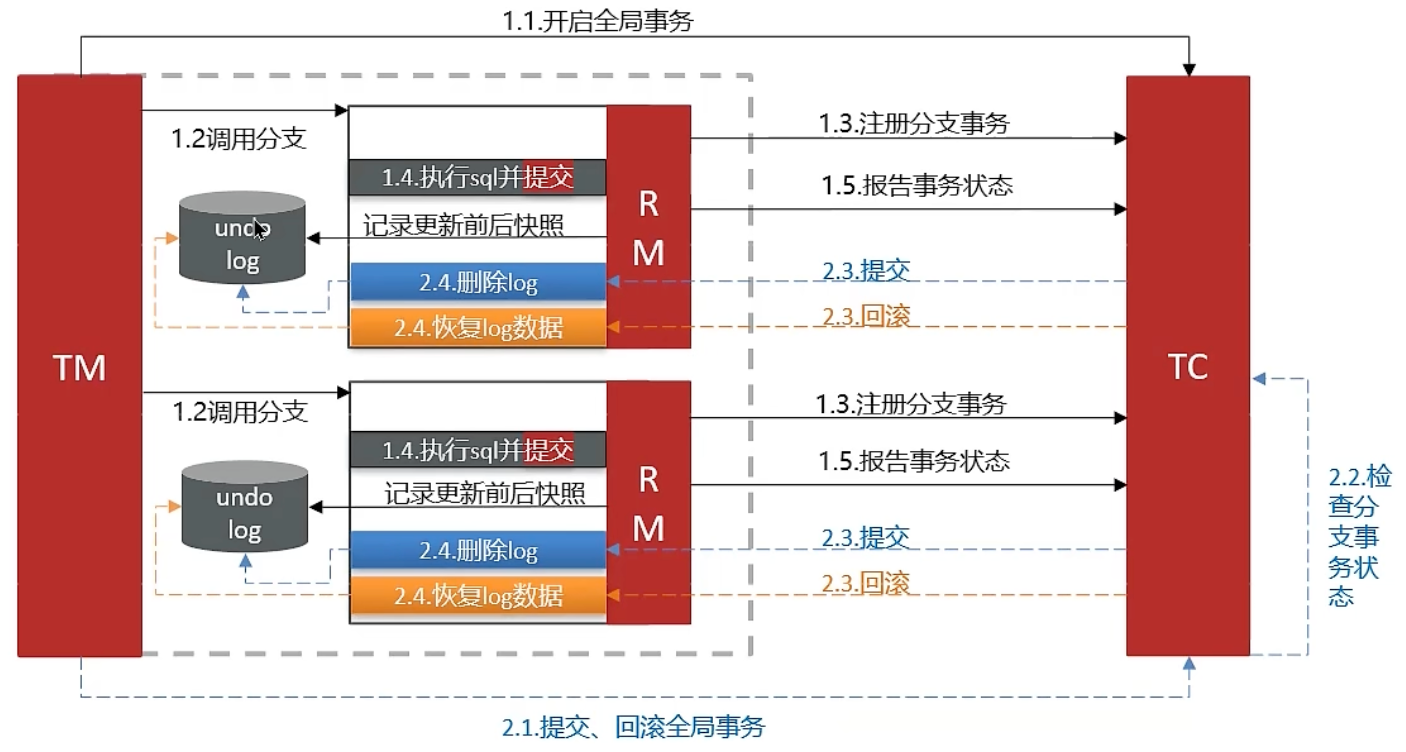
AT 模式(常用)
AT模式同样是分阶段提交的事务模型,不过缺弥补了XA模型中资源锁定周期过长的缺陷
阶段一事务管理器(RM)的工作流程:
- 注册分支事务
- 记录undo日志(数据快照)
- 执行业务SQL并提交
- 报告事务状态
阶段二提交时事务管理器(RM)的工作:
- 删除undo日志
阶段二回滚时事务管理器(RM)的工作:
- 根据undo日志恢复数据至更新前状态
AP 高可用,微服务之间不需要互相等待,性能较好
TCC 模式
Try:资源的检测与预留
Confirm:完成资源操作业务;要求尝试成功后,确认操作必须能够顺利完成
Cancel:预留资源的释放,可视为尝试操作的反向过程
MQ 分布式事务
分布式服务接口幂等性如何设计
回答:
幂等性:多次调用方法或接口不会改变业务状态,确保重复调用的结果与单次调用结果一致
若为新增数据,可利用数据库的唯一索引
对于新增或修改数据:
分布式锁:性能相对较低
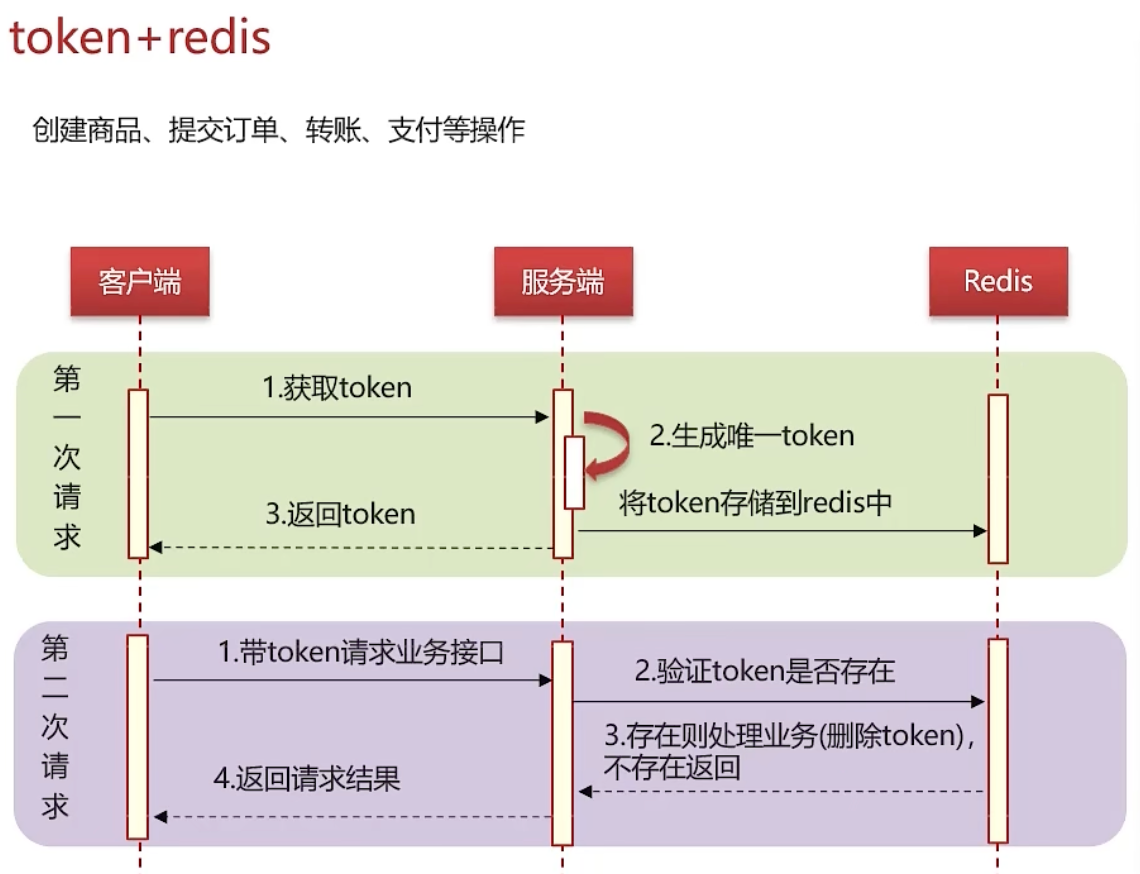
建议使用token结合redis进行实现,以提升性能
首次请求:生成一个唯一token,存入redis,并返回给前端
后续请求:在业务处理时,携带之前的token,前往redis进行验证。若token存在,则执行业务,并删除token;若不存在,则直接返回,不进行业务处理
幂等:多次调用方法或者接口不会改变业务状态,可以保证重复调用的结果和单次调用的结果一致
需要幂等场景
用户重复点击(网络波动)
MQ消息重复
应用使用失败或超时重试机制
接口幂等
| 请求方式 | 说明 |
|---|---|
| GET | 查询操作,天然幂等 |
| POST | 新增操作,请求一次与请求多次造成的结果不同,不是幂等的 |
| PUT | 更新操作,如果是以绝对值更新,则是幂等的。如果是通过增量的方式更新, 则不是幂等的 |
| DELETE | 删除操作,根据唯一值删除,是幂等的 |
数据库唯一索引 新增
token+redis 新增、修改
分布式锁 新增、修改
token+redis
分布式锁
public void saveOrder(Item item) throws InterruptedException {
// 获取锁(重入锁),执行锁的名称
RLock lock = redissonClient.getLock("heimalock");
// 尝试获取锁,参数分别是:获取锁的最大等待时间(期间会重试)、锁自动释放时间、时间单位
boolean isLock = lock.tryLock(10, TimeUnit.SECONDS);
try {
// 判断是否获取成功
if (!isLock) {
log.info("下单操作获取锁失败,order:{}", item);
throw new RuntimeException("新增或修改失败");
}
// 下单操作
} finally {
// 释放锁
lock.unlock();
}
}
分布式任务调度 XXL-Job
XXL-Job 解决的问题
解决集群任务的重复执行问题
cron 表达式定义灵活
定时任务失败了,重试和统计
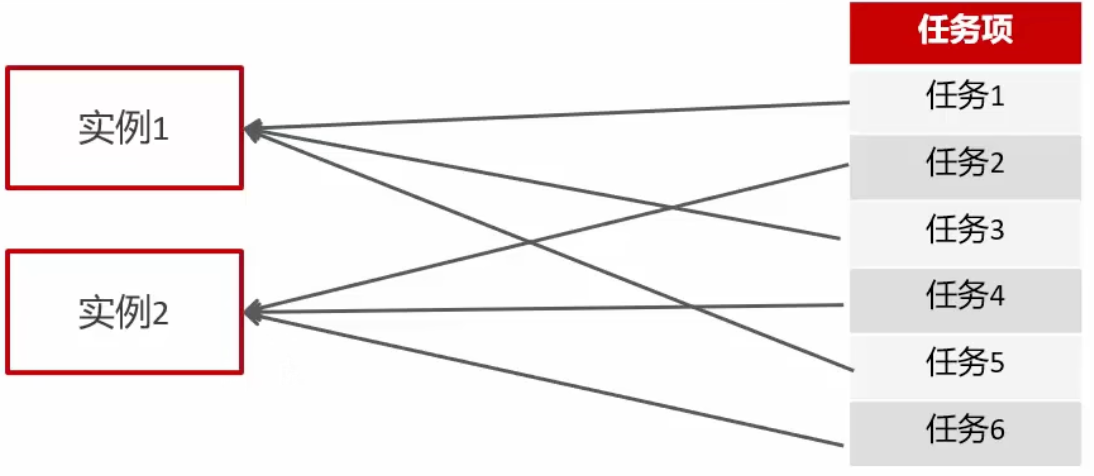
任务量大,分片执行
路由策略有哪些
- FIRST(第一个) :固定选择第一个机器
- LAST(最后一个) :固定选择最后一个机器
- ROUND(轮询) :按顺序轮流选择机器
- RANDOM(随机) :随机选择在线的机器
- CONSISTENT_HASH(一致性HASH) :每个任务按Hash算法固定选择某一台机器,所有任务均匀散列在不同机器上
- LEAST_FREQUENTLY_USED(最不经常使用) :使用频率最低的机器优先被选择
- LEAST_RECENTLY_USED(最近最久未使用) :最久未使用的机器优先被选择
- FAILOVER(故障转移) :按顺序依次进行心跳检测,第一个心跳检测成功的机器被选为执行器
- BUSYOVER(忙碌转移) :按顺序依次进行空闲检测,第一个空闲检测成功的机器被选为执行器
- SHARDING_BROADCAST(分片广播) :广播触发集群中所有空闲机器执行任务,系统自动传递分片参数
任务执行失败怎么解决
故障转移 + 失败重试,查看日志分析 ---> 邮件告警
如果有大数据量的任务同时都需要执行,怎么解决?
执行器集群部署时,任务路由策略选择分片广播情况下,一次任务调度将会广播触发对应集群中所有执
行器执行一次任务(找集群下的机器共同执行)
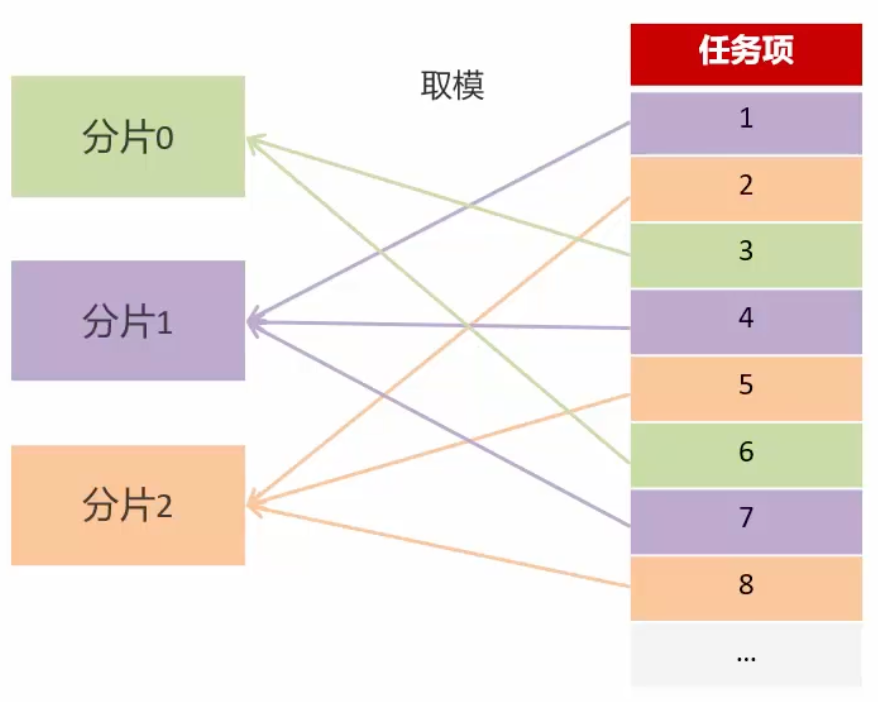
在代码中获取分片参数:
- index:当前分片序号(从0开始),代表执行器集群列表中当前执行器的序号
- total:总分片数,代表执行器集群的总机器数量