
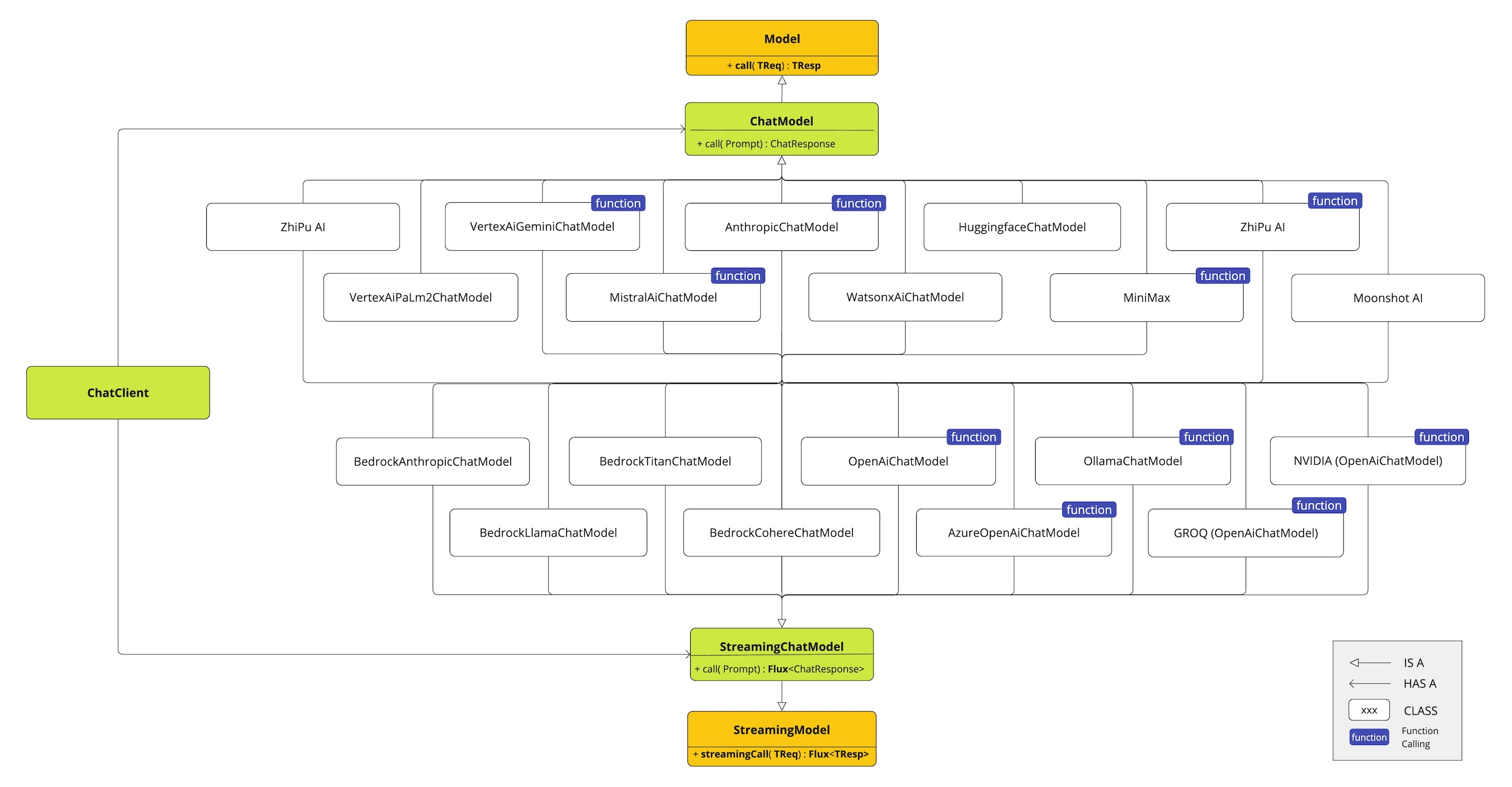
SpringAI
Mysql 相关面试题
版本:1.0.0-SNAPSHOT
Spring AI 支持 Spring Boot 3.4.x
依赖:
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-bom</artifactId>
<version>1.0.0-SNAPSHOT</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
Chat Client API (聊天客户端 API)
该 API 提供流畅的与 AI 模型通信的接口。它支持同步和流式编程模型
Creating a ChatClient (创建 ChatClient)
ChatClient 是使用 ChatClient.Builder 对象创建的。可以为任何 ChatModel Spring Boot 自动配置获取一个自动配置的 ChatClient.Builder 实例,或者程序化地创建一个
使用自动配置的 ChatClient.Builder
@RestController
class MyController {
private final ChatClient chatClient;
public MyController(ChatClient.Builder chatClientBuilder) {
this.chatClient = chatClientBuilder.build();
}
@GetMapping("/ai")
String generation(String userInput) {
return this.chatClient.prompt()
.user(userInput)
.call()
.content();
}
}用户输入设置了用户消息的内容
call() 方法向 AI 模型发送请求
content() 方法返回 AI 模型的响应作为 String
以编程方式创建 ChatClient
通过设置属性 ChatClient.Builder 来禁用 spring.ai.chat.client.enabled=false 自动配置。这在同时使用多个聊天模型时很有用。然后,为每个 ChatClient.Builder 创建一个 ChatModel 实例:
ChatModel myChatModel = ... // usually autowired
ChatClient.Builder builder = ChatClient.builder(this.myChatModel);
// or create a ChatClient with the default builder settings:
ChatClient chatClient = ChatClient.create(this.myChatModel);
ChatClient Fluent API (ChatClient 流畅式 API)
ChatClient 流畅式 API 允许通过重载的 prompt 方法以三种不同的方式创建提示,使用无参数的 ChatClient 方法来启动流畅式 API:
-
prompt() :此无参数方法允许开始使用流畅式 API,让构建用户、系统和其他提示部分 -
prompt(Prompt prompt) :此方法接受一个Prompt 参数,允许传入一个Prompt 实例,该实例是使用提示的非流畅式 API 创建的 - 这是一个类似于之前重载的便捷方法。它接受用户的文本内容
ChatClient Responses (聊天客户端响应)
该 ChatClient API 提供了多种方式使用流畅 API 格式化来自 AI 模型的响应
返回 ChatResponse
AI 模型的响应是一个由类型 ChatResponse 定义的丰富结构。它包括有关响应如何生成的元数据,还可以包含多个响应,称为生成,每个生成都有自己的元数据
ChatResponse chatResponse = chatClient.prompt()
.user("Tell me a joke")
.call()
.chatResponse();
返回实体
例如,给定以下 Java record:
record ActorFilms(String actor, List<String> movies) {}
使用 entity() 方法轻松地将 AI 模型的输出映射到该记录,如下所示:
ActorFilms actorFilms = chatClient.prompt()
.user("Generate the filmography for a random actor.")
.call()
.entity(ActorFilms.class);还有一个签名如下 entity(ParameterizedTypeReference<T> type) 的重载 entity 方法,允许指定类型,例如泛型列表:
List<ActorFilms> actorFilms = chatClient.prompt()
.user("Generate the filmography of 5 movies for Tom Hanks and Bill Murray.")
.call()
.entity(new ParameterizedTypeReference<List<ActorFilms>>() {});
流式响应
Flux<String> output = chatClient.prompt()
.user("Tell me a joke")
.stream()
.content();还可以使用 Flux<ChatResponse> chatResponse() 方法进行 ChatResponse 的流式传输
将流式的相应转换为 java 实体
var converter = new BeanOutputConverter<>(new ParameterizedTypeReference<List<ActorsFilms>>() {});
Flux<String> flux = this.chatClient.prompt()
.user(u -> u.text("""
Generate the filmography for a random actor.
{format}
""")
.param("format", this.converter.getFormat()))
.stream()
.content();
String content = this.flux.collectList().block().stream().collect(Collectors.joining());
List<ActorFilms> actorFilms = this.converter.convert(this.content);
Prompt Templates (提示模板)
ChatClient 流畅 API 允许将用户和系统文本作为模板提供,其中的变量将在运行时替换
String answer = ChatClient.create(chatModel).prompt()
.user(u -> u
.text("Tell me the names of 5 movies whose soundtrack was composed by {composer}")
.param("composer", "John Williams"))
.call()
.content();
call() return values (call() 返回值)
指定 ChatClient 的 call() 方法后,响应类型有几种不同的选择
String content() :返回响应的 String 内容
ChatResponse chatResponse() :返回包含多个生成和响应元数据的ChatResponse 对象,例如创建响应所使用的标记数量
ChatClientResponse chatClientResponse() 返回一个ChatClientResponse 对象,该对象包含ChatResponse 对象和 ChatClient 执行上下文,让能够访问在顾问执行过程中使用的附加数据(例如,在 RAG 流中检索的相关文档)
entity() 用于返回一个 Java 类型-
entity(ParameterizedTypeReference<T> type) 用于返回实体类型的Collection -
entity(Class<T> type) 用于返回特定的实体类型 - 用于指定一个 StructuredOutputConverter 的实例以将 String 转换为实体类型
-
也可以调用 stream() 方法,而不是 call()
stream() return values (stream() 返回值)
-
Flux<String> content():返回 AI 模型生成的字符串的Flux -
Flux<ChatResponse> chatResponse() 返回Flux 个ChatResponse 对象,该对象包含关于响应的额外元数据 -
Flux<ChatClientResponse> chatClientResponse() 返回Flux 个ChatClientResponse 对象,其中包含ChatResponse 对象和 ChatClient 执行上下文,让能够访问在顾问执行期间使用的额外数据(例如,在 RAG 流中检索的相关文档)
Using Defaults (使用默认值)
在 @Configuration 类中创建一个具有默认系统文本的 ChatClient 简化了运行时代码。通过设置默认值,只需在调用 ChatClient 时指定用户文本,从而消除了在运行时代码路径中为每个请求设置系统文本的需要
默认系统文本
@Configuration
class Config {
@Bean
ChatClient chatClient(ChatClient.Builder builder) {
return builder.defaultSystem("You are a friendly chat bot that answers question in the voice of a Pirate")
.build();
}
}并创建一个 @RestController 来调用
@RestController
class AIController {
private final ChatClient chatClient;
AIController(ChatClient chatClient) {
this.chatClient = chatClient;
}
@GetMapping("/ai/simple")
public Map<String, String> completion(@RequestParam(value = "message", defaultValue = "Tell me a joke") String message) {
return Map.of("completion", this.chatClient.prompt().user(message).call().content());
}
}结果
{"completion":"Why did the pirate go to the comedy club? To hear some arrr-rated jokes! Arrr, matey!"}
默认系统文本,包含参数
@Configuration
class Config {
@Bean
ChatClient chatClient(ChatClient.Builder builder) {
return builder.defaultSystem("You are a friendly chat bot that answers question in the voice of a {voice}")
.build();
}
}
@RestController
class AIController {
private final ChatClient chatClient;
AIController(ChatClient chatClient) {
this.chatClient = chatClient;
}
@GetMapping("/ai")
Map<String, String> completion(@RequestParam(value = "message", defaultValue = "Tell me a joke") String message, String voice) {
return Map.of("completion",
this.chatClient.prompt()
.system(sp -> sp.param("voice", voice))
.user(message)
.call()
.content());
}
}
结果
{
"completion": "You talkin' to me? Okay, here's a joke for ya: Why couldn't the bicycle stand up by itself? Because it was two tired! Classic, right?"
}
其他默认设置
在 ChatClient.Builder 级别,可以指定默认的提示配置
-
defaultOptions(ChatOptions chatOptions) :传入ChatOptions 类中定义的可移植选项或模型特定的选项,如OpenAiChatOptions 。有关模型特定ChatOptions 实现的更多信息,请参阅 JavaDocs -
defaultFunction(String name, String description, java.util.function.Function<I, O> function) :name 用于在用户文本中引用函数。description 解释了函数的目的,并帮助 AI 模型选择正确的函数以实现准确响应。function 参数是模型在必要时将执行的 Java 函数实例 -
defaultFunctions(String… functionNames) :在应用程序上下文中定义的java.util.Function的 bean 名称 -
defaultUser(String text),defaultUser(Resource text),defaultUser(Consumer<UserSpec> userSpecConsumer):这些方法允许定义用户文本。Consumer<UserSpec> 允许使用 lambda 表达式来指定用户文本和任何默认参数 -
defaultAdvisors(Advisor… advisor):指导员允许修改用于创建 Prompt 的数据。QuestionAnswerAdvisor 实现通过附加与用户文本相关的上下文信息来启用 Retrieval Augmented Generation 的模式 -
defaultAdvisors(Consumer<AdvisorSpec> advisorSpecConsumer):此方法允许使用 AdvisorSpec 定义一个 Consumer 来配置多个指导员。指导员可以修改用于创建最终 Prompt 的数据。Consumer<AdvisorSpec> 允许指定 lambda 表达式来添加指导员,例如QuestionAnswerAdvisor ,它通过附加基于用户文本的相关上下文信息来支持 Retrieval Augmented Generation
可以在运行时使用不带 default 前缀的相应方法来覆盖这些默认值
-
options(ChatOptions chatOptions) -
function(String name, String description, java.util.function.Function<I, O> function) -
functions(String… functionNames) -
user(String text),user(Resource text),user(Consumer<UserSpec> userSpecConsumer) -
advisors(Advisor… advisor) -
advisors(Consumer<AdvisorSpec> advisorSpecConsumer)
Advisors (顾问)
顾问 API 提供了一种灵活且强大的方式来拦截、修改和增强 Spring 应用程序中的 AI 驱动交互
当使用用户文本调用 AI 模型时,常见的模式是在提示中添加或增强上下文数据
这种上下文数据可以是不同类型的。常见类型包括:
- 自己的数据:这是 AI 模型未接受过训练的数据。即使模型见过类似的数据,附加的上下文数据在生成响应时仍具有优先级
- 对话历史:聊天模型的 API 是无状态的。如果告诉 AI 模型您的名字,它不会在后续交互中记住它。为了确保在生成响应时考虑之前的交互,必须将对话历史与每个请求一起发送
ChatClient 中的顾问配置
ChatClient 流畅 API 提供了一种 AdvisorSpec 接口来配置顾问。此接口提供了添加参数、一次性设置多个参数以及添加一个或多个顾问到链中的方法
interface AdvisorSpec {
AdvisorSpec param(String k, Object v);
AdvisorSpec params(Map<String, Object> p);
AdvisorSpec advisors(Advisor... advisors);
AdvisorSpec advisors(List<Advisor> advisors);
}顾问添加到链中的顺序至关重要,因为它决定了它们的执行顺序。每个顾问都会以某种方式修改提示或上下文,并且一个顾问所做的更改会传递给链中的下一个顾问
ChatClient.builder(chatModel)
.build()
.prompt()
.advisors(
new MessageChatMemoryAdvisor(chatMemory),
new QuestionAnswerAdvisor(vectorStore)
)
.user(userText)
.call()
.content();在此配置中, MessageChatMemoryAdvisor 将首先执行,将对话历史添加到提示中。然后, QuestionAnswerAdvisor 将根据用户的问题和添加的对话历史进行搜索,可能提供更相关的结果
下面展示了使用多个顾问的 @Service 示例实现
import static org.springframework.ai.chat.client.advisor.AbstractChatMemoryAdvisor.CHAT_MEMORY_CONVERSATION_ID_KEY;
import static org.springframework.ai.chat.client.advisor.AbstractChatMemoryAdvisor.CHAT_MEMORY_RETRIEVE_SIZE_KEY;
@Service
public class CustomerSupportAssistant {
private final ChatClient chatClient;
public CustomerSupportAssistant(ChatClient.Builder builder, VectorStore vectorStore, ChatMemory chatMemory) {
this.chatClient = builder
.defaultSystem("""
You are a customer chat support agent of an airline named "Funnair". Respond in a friendly,
helpful, and joyful manner.
Before providing information about a booking or cancelling a booking, you MUST always
get the following information from the user: booking number, customer first name and last name.
Before changing a booking you MUST ensure it is permitted by the terms.
If there is a charge for the change, you MUST ask the user to consent before proceeding.
""")
.defaultAdvisors(
new MessageChatMemoryAdvisor(chatMemory), // CHAT MEMORY
new QuestionAnswerAdvisor(vectorStore), // RAG
new SimpleLoggerAdvisor())
.defaultFunctions("getBookingDetails", "changeBooking", "cancelBooking") // FUNCTION CALLING
.build();
}
public Flux<String> chat(String chatId, String userMessageContent) {
return this.chatClient.prompt()
.user(userMessageContent)
.advisors(a -> a
.param(CHAT_MEMORY_CONVERSATION_ID_KEY, chatId)
.param(CHAT_MEMORY_RETRIEVE_SIZE_KEY, 100))
.stream().content();
}
}
Logging (记录/日志)
要启用日志记录,在创建 ChatClient 时将 SimpleLoggerAdvisor 添加到顾问链中。建议将其添加到链的末尾:
ChatResponse response = ChatClient.create(chatModel).prompt()
.advisors(new SimpleLoggerAdvisor())
.user("Tell me a joke?")
.call()
.chatResponse();要查看日志,请将顾问包的日志级别设置为 DEBUG, 将此内容添加到 application.properties 或 application.yaml 文件中:
logging.level.org.springframework.ai.chat.client.advisor=DEBUG
可以通过以下构造函数自定义从 AdvisedRequest 和 ChatResponse 中记录哪些数据:
SimpleLoggerAdvisor(
Function<AdvisedRequest, String> requestToString,
Function<ChatResponse, String> responseToString
)示例:
SimpleLoggerAdvisor customLogger = new SimpleLoggerAdvisor(
request -> "Custom request: " + request.userText,
response -> "Custom response: " + response.getResult()
);
顾问 API
可以使用 ChatClient API 配置现有的顾问,如下例所示:
var chatClient = ChatClient.builder(chatModel)
.defaultAdvisors(
new MessageChatMemoryAdvisor(chatMemory), // chat-memory advisor
new QuestionAnswerAdvisor(vectorStore) // RAG advisor
)
.build();
String response = this.chatClient.prompt()
// Set advisor parameters at runtime
.advisors(advisor -> advisor.param("chat_memory_conversation_id", "678")
.param("chat_memory_response_size", 100))
.user(userText)
.call()
.content();
AI Models
Spring AI 如何处理聊天模型的配置和执行,结合启动和运行时选项:
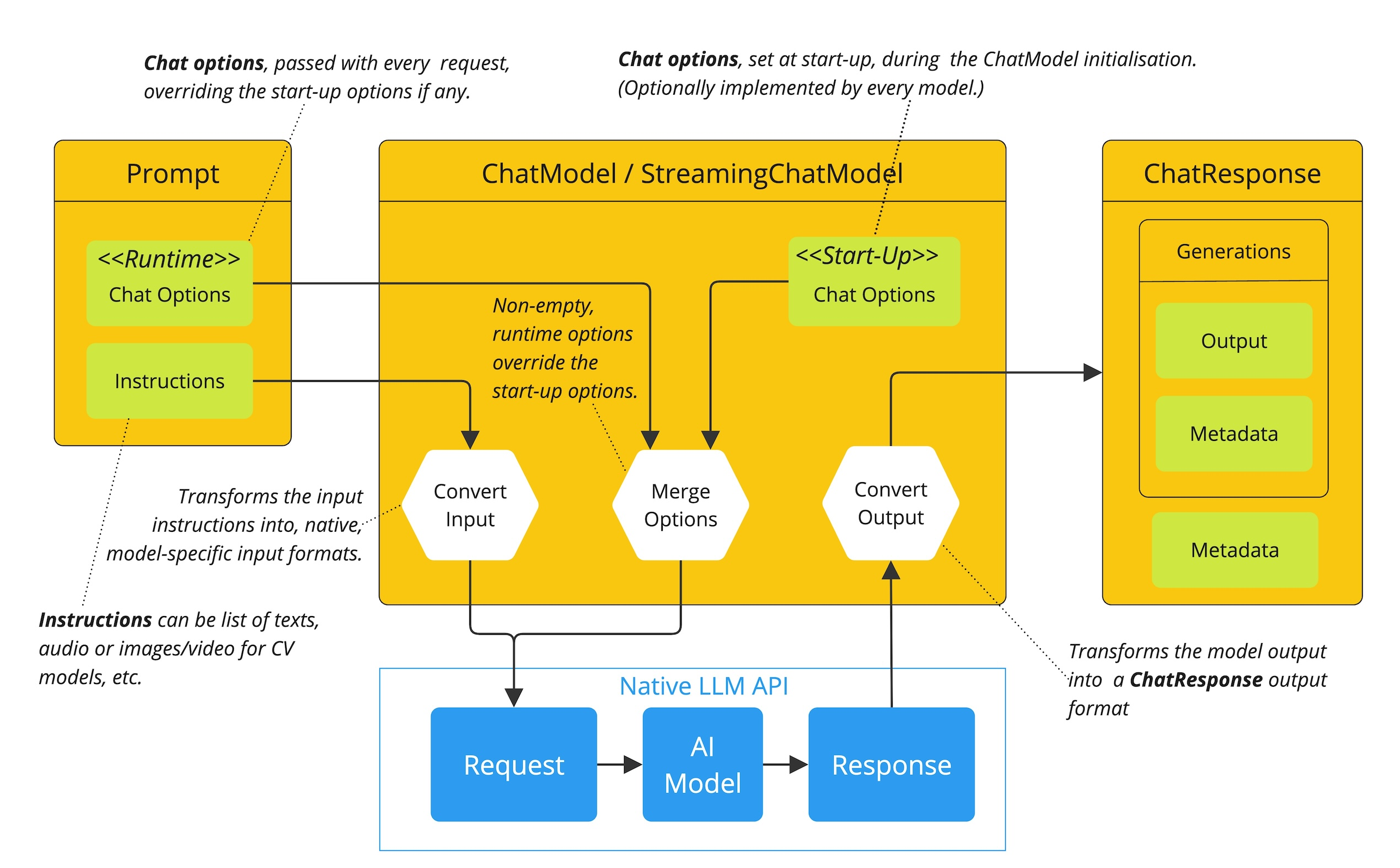
- 启动配置 - ChatModel/StreamingChatModel 使用“启动”聊天选项进行初始化。这些选项在 ChatModel 初始化时设置,旨在提供默认配置
- 运行时配置 - 对于每个请求,提示可以包含运行时聊天选项:这些选项可以覆盖启动选项
- 选项合并过程 - “合并选项”步骤将启动和运行时选项合并。如果提供了运行时选项,则它们将覆盖启动选项
- 输入处理 - “转换输入”步骤将输入指令转换为模型特定的本地格式
- 输出处理 - “转换输出”步骤将模型的响应转换为标准格式 ChatResponse
ZhiPu AI Chat
Spring AI 项目定义了一个名为 spring.ai.zhipuai.api-key 的配置属性
Spring AI 为 ZhiPuAI Chat 客户端提供了 Spring Boot 自动配置。要启用它,将以下依赖项添加到项目的 Maven pom.xml 文件中:
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-model-zhipuai</artifactId>
</dependency>
Chat Properties 聊天属性
| Property 属性 | Description 描述 | Default 默认 |
|---|---|---|
| spring.ai.retry.max-attempts | 最大重试尝试次数。 | 10 |
| spring.ai.retry.backoff.initial-interval | 指数退避策略的初始睡眠时长。 | 2 sec. |
| spring.ai.retry.backoff.multiplier | 退避间隔乘数。 | 5 |
| spring.ai.retry.backoff.max-interval | 最大退避持续时间。 | 3 min. |
| spring.ai.retry.on-client-errors | 如果为假,则抛出 NonTransientAiException 异常,并且不要尝试重试 4xx 客户端错误代码 | false |
| spring.ai.retry.exclude-on-http-codes | 应该不触发重试的 HTTP 状态码列表(例如,抛出 NonTransientAiException 异常)。 | 空 |
| spring.ai.retry.on-http-codes | 应该触发重试的 HTTP 状态码列表(例如,抛出 TransientAiException)。 | 空 |
| Property 属性 | Description 描述 | Default 默认 |
|---|---|---|
| spring.ai.zhipuai.base-url | 连接到的 URL | open.bigmodel.cn/api/paas |
| spring.ai.zhipuai.api-key | API 密钥 | - |
| Property 属性 | Description 描述 | Default 默认 |
|---|---|---|
| spring.ai.model.chat | 启用智谱 AI 聊天模型。 | zhipuai |
| spring.ai.zhipuai.chat.base-url | 可选,覆盖 spring.ai.zhipuai.base-url 以提供聊天特定 URL | open.bigmodel.cn/api/paas |
| spring.ai.zhipuai.chat.api-key | 可选参数覆盖 spring.ai.zhipuai.api-key,以提供聊天特定的 API 密钥 | - |
| spring.ai.zhipuai.chat.options.model | 这是 ZhiPuAI Chat 模型的使用方法 | GLM-3-Turbo (the GLM-3-Turbo, GLM-4, GLM-4-Air, GLM-4-AirX, GLM-4-Flash, and GLM-4V point to the latest model versions) |
| spring.ai.zhipuai.chat.options.maxTokens | 生成聊天完成内容的最大标记数。输入标记和生成标记的总长度受模型上下文长度的限制。 | - |
| spring.ai.zhipuai.chat.options.temperature | 应该使用多少采样温度,介于 0 和 1 之间。更高的值,如 0.8,会使输出更加随机,而更低的值,如 0.2,会使输出更加集中和确定。我们通常建议更改此参数或 top_p,但不要同时更改两者。 | 0.7 |
| spring.ai.zhipuai.chat.options.topP | 一种替代温度采样的方法,称为核采样,模型会考虑具有 top_p 概率质量的标记的结果。所以 0.1 意味着只有占概率质量前 10% 的标记会被考虑。我们通常建议更改此参数或温度,但不要同时更改两者。 | 1.0 |
| spring.ai.zhipuai.chat.options.stop | 模型将停止生成由 stop 指定的字符,目前仅支持单个停用词,格式为["停用词 1"] | - |
| spring.ai.zhipuai.chat.options.user | 代表终端用户的唯一标识符,有助于 ZhiPuAI 监控和检测滥用。 | - |
| spring.ai.zhipuai.chat.options.requestId | 参数由客户端传递,必须确保唯一性。它用于区分每个请求的唯一标识符。如果客户端未提供,平台将默认生成。 | - |
| spring.ai.zhipuai.chat.options.doSample | 当 do_sample 设置为 true 时,采样策略被启用。如果 do_sample 为 false,采样策略参数 temperature 和 top_p 将不会生效。 | true |
| spring.ai.zhipuai.chat.options.proxy-tool-calls | 如果为 true,Spring AI 将不会内部处理函数调用,而是将它们代理到客户端。然后客户端负责处理函数调用,将它们调度到适当的函数,并返回结果。如果为 false(默认值),Spring AI 将内部处理函数调用。仅适用于支持函数调用的聊天模型 | false |
示例
spring.ai.zhipuai.api-key=YOUR_API_KEY
spring.ai.zhipuai.chat.options.model=glm-4-flash
spring.ai.zhipuai.chat.options.temperature=0.7@RestController
public class ChatController {
private final ZhiPuAiChatModel chatModel;
@Autowired
public ChatController(ZhiPuAiChatModel chatModel) {
this.chatModel = chatModel;
}
@GetMapping("/ai/generate")
public Map generate(@RequestParam(value = "message", defaultValue = "Tell me a joke") String message) {
return Map.of("generation", this.chatModel.call(message));
}
@GetMapping("/ai/generateStream")
public Flux<ChatResponse> generateStream(@RequestParam(value = "message", defaultValue = "Tell me a joke") String message) {
var prompt = new Prompt(new UserMessage(message));
return this.chatModel.stream(prompt);
}
}
手动配置
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-zhipuai</artifactId>
</dependency>
var zhiPuAiApi = new ZhiPuAiApi(System.getenv("ZHIPU_AI_API_KEY"));
var chatModel = new ZhiPuAiChatModel(this.zhiPuAiApi, ZhiPuAiChatOptions.builder()
.model(ZhiPuAiApi.ChatModel.GLM_3_Turbo.getValue())
.temperature(0.4)
.maxTokens(200)
.build());
ChatResponse response = this.chatModel.call(
new Prompt("Generate the names of 5 famous pirates."));
// Or with streaming responses
Flux<ChatResponse> streamResponse = this.chatModel.stream(
new Prompt("Generate the names of 5 famous pirates."));
低级 API
ZhiPuAiApi zhiPuAiApi =
new ZhiPuAiApi(System.getenv("ZHIPU_AI_API_KEY"));
ChatCompletionMessage chatCompletionMessage =
new ChatCompletionMessage("Hello world", Role.USER);
// Sync request
ResponseEntity<ChatCompletion> response = this.zhiPuAiApi.chatCompletionEntity(
new ChatCompletionRequest(List.of(this.chatCompletionMessage), ZhiPuAiApi.ChatModel.GLM_3_Turbo.getValue(), 0.7, false));
// Streaming request
Flux<ChatCompletionChunk> streamResponse = this.zhiPuAiApi.chatCompletionStream(
new ChatCompletionRequest(List.of(this.chatCompletionMessage), ZhiPuAiApi.ChatModel.GLM_3_Turbo.getValue(), 0.7, true));
OpenAI Embeddings
自动配置
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-model-openai</artifactId>
</dependency>
EmbeddingResponse embeddingResponse = embeddingModel.call(
new EmbeddingRequest(List.of("Hello World", "World is big and salvation is near"),
OpenAiEmbeddingOptions.builder()
.model("Different-Embedding-Model-Deployment-Name")
.build()));
示例
spring.ai.openai.api-key=YOUR_API_KEY
spring.ai.openai.embedding.options.model=text-embedding-ada-002
@RestController
public class EmbeddingController {
private final EmbeddingModel embeddingModel;
@Autowired
public EmbeddingController(EmbeddingModel embeddingModel) {
this.embeddingModel = embeddingModel;
}
@GetMapping("/ai/embedding")
public Map embed(@RequestParam(value = "message", defaultValue = "Tell me a joke") String message) {
EmbeddingResponse embeddingResponse = this.embeddingModel.embedForResponse(List.of(message));
return Map.of("embedding", embeddingResponse);
}
}
手动配置
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-openai</artifactId>
</dependency>
var openAiApi = OpenAiApi.builder()
.apiKey(System.getenv("OPENAI_API_KEY"))
.build();
var embeddingModel = new OpenAiEmbeddingModel(
this.openAiApi,
MetadataMode.EMBED,
OpenAiEmbeddingOptions.builder()
.model("text-embedding-ada-002")
.user("user-6")
.build(),
RetryUtils.DEFAULT_RETRY_TEMPLATE);
EmbeddingResponse embeddingResponse = this.embeddingModel
.embedForResponse(List.of("Hello World", "World is big and salvation is near"));
Vector Databases 向量数据库
Milvus
依赖
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-vector-store-milvus</artifactId>
</dependency>
连接并配置 MilvusVectorStore 。简单的配置可以通过 Spring Boot 的 application.yml 提供
spring:
ai:
vectorstore:
milvus:
client:
host: "localhost"
port: 19530
username: "root"
password: "milvus"
databaseName: "default"
collectionName: "vector_store"
embeddingDimension: 1024
indexType: IVF_FLAT
metricType: COSINE
@Autowired VectorStore vectorStore;
// ...
List <Document> documents = List.of(
new Document("Spring AI rocks!! Spring AI rocks!! Spring AI rocks!! Spring AI rocks!! Spring AI rocks!!", Map.of("meta1", "meta1")),
new Document("The World is Big and Salvation Lurks Around the Corner"),
new Document("You walk forward facing the past and you turn back toward the future.", Map.of("meta2", "meta2")));
// Add the documents to Milvus Vector Store
vectorStore.add(documents);
// Retrieve documents similar to a query
List<Document> results = this.vectorStore.similaritySearch(SearchRequest.builder().query("Spring").topK(5).build());
手动配置
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-milvus-store</artifactId>
</dependency>
@Bean
public VectorStore vectorStore(MilvusServiceClient milvusClient, EmbeddingModel embeddingModel) {
return MilvusVectorStore.builder(milvusClient, embeddingModel)
.collectionName("test_vector_store")
.databaseName("default")
.indexType(IndexType.IVF_FLAT)
.metricType(MetricType.COSINE)
.batchingStrategy(new TokenCountBatchingStrategy())
.initializeSchema(true)
.build();
}
@Bean
public MilvusServiceClient milvusClient() {
return new MilvusServiceClient(ConnectParam.newBuilder()
.withAuthorization("minioadmin", "minioadmin")
.withUri(milvusContainer.getEndpoint())
.build());
}
Metadata filtering 元数据过滤
可以使用通用的、可移植的元数据过滤器与 Milvus 存储一起使用
使用文本表达式语言:
vectorStore.similaritySearch(
SearchRequest.builder()
.query("The World")
.topK(TOP_K)
.similarityThreshold(SIMILARITY_THRESHOLD)
.filterExpression("author in ['john', 'jill'] && article_type == 'blog'").build());
FilterExpressionBuilder b = new FilterExpressionBuilder();
vectorStore.similaritySearch(SearchRequest.builder()
.query("The World")
.topK(TOP_K)
.similarityThreshold(SIMILARITY_THRESHOLD)
.filterExpression(b.and(
b.in("author","john", "jill"),
b.eq("article_type", "blog")).build()).build());
使用 MilvusSearchRequest
MilvusSearchRequest 继承自 SearchRequest,允许使用 Milvus 特定的搜索参数,例如原生表达式和搜索参数 JSON
MilvusSearchRequest request = MilvusSearchRequest.milvusBuilder()
.query("sample query")
.topK(5)
.similarityThreshold(0.7)
.nativeExpression("metadata[\"age\"] > 30") // Overrides filterExpression if both are set
.filterExpression("age <= 30") // Ignored if nativeExpression is set
.searchParamsJson("{\"nprobe\":128}")
.build();
List results = vectorStore.similaritySearch(request);
nativeExpression 和 searchParamsJson 在 MilvusSearchRequest 中的重要性
MilvusSearchRequest request = MilvusSearchRequest.milvusBuilder()
.query("sample query")
.topK(5)
.nativeExpression("metadata['category'] == 'science'")
.build();
MilvusSearchRequest request = MilvusSearchRequest.milvusBuilder()
.query("sample query")
.topK(5)
.searchParamsJson("{\"nprobe\":128}")
.build();
| Property 属性 | Description 描述 | Default value 默认值 |
|---|---|---|
| spring.ai.vectorstore.milvus.database-name | 要使用的 Milvus 数据库的名称。 | default |
| spring.ai.vectorstore.milvus.collection-name | 保存向量的集合名称 | vector_store |
| spring.ai.vectorstore.milvus.initialize-schema | 是否初始化 Milvus 的后端 | false |
| spring.ai.vectorstore.milvus.embedding-dimension | 要存储在 Milvus 集合中的向量的维度 | 1536 |
| spring.ai.vectorstore.milvus.index-type | 为 Milvus 集合创建的索引类型。 | IVF_FLAT |
| spring.ai.vectorstore.milvus.metric-type | 用于 Milvus 集合的度量类型。 | COSINE |
| spring.ai.vectorstore.milvus.index-parameters spring.ai.vectorstore.milvus 索引参数 | 要用于 Milvus 集合的索引参数。 | |
| spring.ai.vectorstore.milvus.id-field-name | 集合的 ID 字段名称。 | doc_id |
| spring.ai.vectorstore.milvus.is-auto-id | 布尔标志,表示是否使用自动 ID 字段 | false |
| spring.ai.vectorstore.milvus.content-field-name | 集合的内容字段名称 | content |
| spring.ai.vectorstore.milvus.metadata-field-name spring.ai.vectorstore.milvus.元数据字段名称 | 集合的元数据字段名称 | metadata |
| spring.ai.vectorstore.milvus.embedding-field-name | 集合的嵌入字段名称 | embedding |
| spring.ai.vectorstore.milvus.client.host | 主机名称或地址。 | localhost |
| spring.ai.vectorstore.milvus.client.port | 连接端口。 | 19530 |
| spring.ai.vectorstore.milvus.client.uri | Milvus 实例的 uri | - |
| spring.ai.vectorstore.milvus.client.token | 作为识别和认证目的的密钥服务令牌。 | - |
| spring.ai.vectorstore.milvus.client.connect-timeout-ms | 客户端通道的连接超时值。超时值必须大于零。 | 10000 |
| spring.ai.vectorstore.milvus.client.keep-alive-time-ms | 客户端通道的保活时间值。保活时间值必须大于零。 | 55000 |
| spring.ai.vectorstore.milvus.client.keep-alive-timeout-ms | 客户端通道的保活超时值。超时值必须大于零。 | 20000 |
| spring.ai.vectorstore.milvus.client.rpc-deadline-ms | 服务器回复的等待时间限制。设置超时后,客户端在遇到因网络波动导致的快速 RPC 失败时会等待。超时值必须大于或等于零。 | 0 |
| spring.ai.vectorstore.milvus.client.client-key-path | 双向认证的客户端密钥路径,仅在"secure"为 true 时生效 | - |
| spring.ai.vectorstore.milvus.client.client-pem-path | 客户端.pem 路径用于 TLS 双向认证,仅在"secure"为 true 时生效 | - |
| spring.ai.vectorstore.milvus.client.ca-pem-path | TLS 双向认证的 ca.pem 路径,仅在"secure"为 true 时生效 | - |
| spring.ai.vectorstore.milvus.client.server-pem-path | server.pem 路径用于 TLS 单向认证,仅在"secure"为 true 时生效。 | - |
| spring.ai.vectorstore.milvus.client.server-name | 设置 SSL 主机名检查的目标名称覆盖,仅在"secure"为 True 时生效。注意:此值传递给 grpc.ssl_target_name_override | - |
| spring.ai.vectorstore.milvus.client.secure | 确保此连接的授权安全,设置为 True 以启用 TLS。 | false |
| spring.ai.vectorstore.milvus.client.idle-timeout-ms | 客户端通道的空闲超时值。超时值必须大于零。 | 24h 24 小时 |
| spring.ai.vectorstore.milvus.client.username spring.ai.vectorstore.milvus.client.username spring.ai 向量存储.milvus 客户端用户名 | 此连接的用户名和密码。 | root |
| spring.ai.vectorstore.milvus.client.password | 此连接的密码。 | milvus |
检索增强生成
Advisors 顾问
Spring AI 提供了对常见 RAG 流程的即插即用支持,使用 Advisor API
要使用 QuestionAnswerAdvisor 或 RetrievalAugmentationAdvisor ,需要将 spring-ai-advisors-vector-store 依赖项添加到项目中:
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-advisors-vector-store</artifactId>
</dependency>
QuestionAnswerAdvisor
当用户问题发送给 AI 模型时,QuestionAnswerAdvisor 查询向量数据库以获取与用户问题相关的文档
向量数据库的响应被附加到用户文本中,为 AI 模型生成响应提供上下文
ChatResponse response = ChatClient.builder(chatModel)
.build().prompt()
.advisors(new QuestionAnswerAdvisor(vectorStore))
.user(userText)
.call()
.chatResponse();在本例中, QuestionAnswerAdvisor 将在向量数据库中的所有文档上执行相似度搜索。要限制搜索的文档类型, SearchRequest 接受一个类似于 SQL 的过滤表达式,该表达式可以在所有 VectorStores 中跨平台使用
此过滤表达式可以在创建 QuestionAnswerAdvisor 时进行配置,因此将始终应用于所有 ChatClient 请求,或者可以在运行时按请求提供
var qaAdvisor = QuestionAnswerAdvisor.builder(vectorStore)
.searchRequest(SearchRequest.builder().similarityThreshold(0.8d).topK(6).build())
.build();
动态过滤表达式
ChatClient chatClient = ChatClient.builder(chatModel)
.defaultAdvisors(QuestionAnswerAdvisor.builder(vectorStore)
.searchRequest(SearchRequest.builder().build())
.build())
.build();
// Update filter expression at runtime
String content = this.chatClient.prompt()
.user("Please answer my question XYZ")
.advisors(a -> a.param(QuestionAnswerAdvisor.FILTER_EXPRESSION, "type == 'Spring'"))
.call()
.content();
Custom Template 自定义模板
QuestionAnswerAdvisor 使用默认模板来增强用户问题与检索到的文档。可以通过提供自己的 PromptTemplate 对象并通过 .promptTemplate() 构造方法来自定义此行为
自定义的 PromptTemplate 可以使用任何 TemplateRenderer 实现(默认情况下,它使用基于 StringTemplate 引擎的 StPromptTemplate )。重要的要求是模板必须包含一个占位符以接收顾问提供的检索到的上下文,该上下文在键 question_answer_context 下提供
PromptTemplate customPromptTemplate = PromptTemplate.builder()
.renderer(StTemplateRenderer.builder().startDelimiterToken('<').endDelimiterToken('>').build())
.template("""
Context information is below.
---------------------
<question_answer_context>
---------------------
Given the context information and no prior knowledge, answer the query.
Follow these rules:
1. If the answer is not in the context, just say that you don't know.
2. Avoid statements like "Based on the context..." or "The provided information...".
""")
.build();
String question = "Where does the adventure of Anacletus and Birba take place?";
QuestionAnswerAdvisor qaAdvisor = QuestionAnswerAdvisor.builder(vectorStore)
.promptTemplate(customPromptTemplate)
.build();
String response = ChatClient.builder(chatModel).build()
.prompt(question)
.advisors(qaAdvisor)
.call()
.content();
RetrievalAugmentationAdvisor (Incubating)
Naive RAG 朴素 RAG
Advisor retrievalAugmentationAdvisor = RetrievalAugmentationAdvisor.builder()
.documentRetriever(VectorStoreDocumentRetriever.builder()
.similarityThreshold(0.50)
.vectorStore(vectorStore)
.build())
.build();
String answer = chatClient.prompt()
.advisors(retrievalAugmentationAdvisor)
.user(question)
.call()
.content();默认情况下, RetrievalAugmentationAdvisor 不允许检索到的上下文为空。当发生这种情况时,它指示模型不要回答用户查询。可以允许空上下文如下:
Advisor retrievalAugmentationAdvisor = RetrievalAugmentationAdvisor.builder()
.documentRetriever(VectorStoreDocumentRetriever.builder()
.similarityThreshold(0.50)
.vectorStore(vectorStore)
.build())
.queryAugmenter(ContextualQueryAugmenter.builder()
.allowEmptyContext(true)
.build())
.build();
String answer = chatClient.prompt()
.advisors(retrievalAugmentationAdvisor)
.user(question)
.call()
.content();VectorStoreDocumentRetriever 接受一个 FilterExpression 以根据元数据过滤搜索结果。可以在实例化 VectorStoreDocumentRetriever 时提供,或使用 FILTER_EXPRESSION 咨询上下文参数在运行时按请求提供
Advisor retrievalAugmentationAdvisor = RetrievalAugmentationAdvisor.builder()
.documentRetriever(VectorStoreDocumentRetriever.builder()
.similarityThreshold(0.50)
.vectorStore(vectorStore)
.build())
.build();
String answer = chatClient.prompt()
.advisors(retrievalAugmentationAdvisor)
.advisors(a -> a.param(VectorStoreDocumentRetriever.FILTER_EXPRESSION, "type == 'Spring'"))
.user(question)
.call()
.content();
Advanced RAG 高级检索增强生成
Advisor retrievalAugmentationAdvisor = RetrievalAugmentationAdvisor.builder()
.queryTransformers(RewriteQueryTransformer.builder()
.chatClientBuilder(chatClientBuilder.build().mutate())
.build())
.documentRetriever(VectorStoreDocumentRetriever.builder()
.similarityThreshold(0.50)
.vectorStore(vectorStore)
.build())
.build();
String answer = chatClient.prompt()
.advisors(retrievalAugmentationAdvisor)
.user(question)
.call()
.content();
Modules 模块
Spring AI 实现了受论文《Modular RAG:将 RAG 系统转变为类似乐高可重构框架》中模块化概念启发的模块化 RAG 架构
Pre-Retrieval 预检索
预检索模块负责处理用户查询,以实现最佳检索结果
Query Transformation 查询转换
一种将输入查询转换为更有效的检索任务的组件,解决诸如查询格式不佳、模糊术语、复杂词汇或不受支持的语言等挑战
当使用 QueryTransformer 时,建议将 ChatClient.Builder 配置为低温(例如,0.0)以确保更确定性和准确的结果,提高检索质量。大多数聊天模型的默认温度通常过高,不利于最佳查询转换,从而导致检索效果降低
CompressionQueryTransformer 压缩查询转换器
CompressionQueryTransformer 使用大型语言模型将对话历史和后续查询压缩成一个独立的查询,该查询能够捕捉对话的精髓
这个转换器在会话历史较长且后续查询与对话上下文相关时很有用
Query query = Query.builder()
.text("And what is its second largest city?")
.history(new UserMessage("What is the capital of Denmark?"),
new AssistantMessage("Copenhagen is the capital of Denmark."))
.build();
QueryTransformer queryTransformer = CompressionQueryTransformer.builder()
.chatClientBuilder(chatClientBuilder)
.build();
Query transformedQuery = queryTransformer.transform(query);该组件使用的提示可以通过构建器中可用的 promptTemplate() 方法进行自定义
RewriteQueryTransformer
RewriteQueryTransformer 使用大型语言模型重写用户查询,以在查询目标系统(如向量存储或网络搜索引擎)时提供更好的结果
这个转换器在用户查询冗长、模糊或包含可能影响搜索结果质量的不相关信息时很有用
Query query = new Query("I'm studying machine learning. What is an LLM?");
QueryTransformer queryTransformer = RewriteQueryTransformer.builder()
.chatClientBuilder(chatClientBuilder)
.build();
Query transformedQuery = queryTransformer.transform(query);该组件使用的提示可以通过构建器中可用的 promptTemplate() 方法进行自定义
TranslationQueryTransformer 翻译查询转换器
TranslationQueryTransformer 使用大型语言模型将查询翻译为目标语言,该目标语言由用于生成文档嵌入的嵌入模型所支持。如果查询已经是目标语言,则返回不变。如果查询的语言未知,也返回不变
这种转换器在嵌入模型在特定语言上训练且用户查询使用不同语言时很有用
Query query = new Query("Hvad er Danmarks hovedstad?");
QueryTransformer queryTransformer = TranslationQueryTransformer.builder()
.chatClientBuilder(chatClientBuilder)
.targetLanguage("english")
.build();
Query transformedQuery = queryTransformer.transform(query);该组件使用的提示可以通过构建器中可用的 promptTemplate() 方法进行自定义
Query Expansion 查询扩展
一种将输入查询扩展成一系列查询的组件,通过提供替代查询表述或将复杂问题分解为更简单的子查询来解决查询表述不佳等挑战
MultiQueryExpander 多查询扩展器
使用大型语言模型将查询扩展成多个语义多样的变体,以捕捉不同的观点,这对于检索额外的上下文信息和提高找到相关结果的机会非常有用
MultiQueryExpander queryExpander = MultiQueryExpander.builder()
.chatClientBuilder(chatClientBuilder)
.numberOfQueries(3)
.build();
List<Query> queries = queryExpander.expand(new Query("How to run a Spring Boot app?"));默认情况下, MultiQueryExpander 会将原始查询包含在扩展查询列表中。可以通过构建器中的 includeOriginal 方法禁用此行为
MultiQueryExpander queryExpander = MultiQueryExpander.builder()
.chatClientBuilder(chatClientBuilder)
.includeOriginal(false)
.build();该组件使用的提示可以通过构建器中可用的 promptTemplate() 方法进行自定义
Retrieval 检索
检索模块负责查询数据系统,如向量存储,并检索最相关的文档
Document Search 文档搜索
负责从底层数据源(如搜索引擎、向量存储、数据库或知识图谱)检索 Documents 的组件
VectorStoreDocumentRetriever 向量存储文档检索器
VectorStoreDocumentRetriever 从向量存储中检索与输入查询语义相似的文档。它支持根据元数据、相似度阈值和前 k 个结果进行过滤
DocumentRetriever retriever = VectorStoreDocumentRetriever.builder()
.vectorStore(vectorStore)
.similarityThreshold(0.73)
.topK(5)
.filterExpression(new FilterExpressionBuilder()
.eq("genre", "fairytale")
.build())
.build();
List<Document> documents = retriever.retrieve(new Query("What is the main character of the story?"));过滤器表达式可以是静态的或动态的。对于动态的过滤器表达式,您可以传递一个 Supplier
DocumentRetriever retriever = VectorStoreDocumentRetriever.builder()
.vectorStore(vectorStore)
.filterExpression(() -> new FilterExpressionBuilder()
.eq("tenant", TenantContextHolder.getTenantIdentifier())
.build())
.build();
List<Document> documents = retriever.retrieve(new Query("What are the KPIs for the next semester?"));也可以通过 Query API 使用 FILTER_EXPRESSION 参数提供特定请求的过滤器表达式。如果同时提供了特定请求和检索器的过滤器表达式,则特定请求的过滤器表达式具有优先级
Query query = Query.builder()
.text("Who is Anacletus?")
.context(Map.of(VectorStoreDocumentRetriever.FILTER_EXPRESSION, "location == 'Whispering Woods'"))
.build();
List<Document> retrievedDocuments = documentRetriever.retrieve(query);Document Join 文档合并
一种组件,用于将基于多个查询和来自多个数据源检索到的文档合并成一个文档集合。在合并过程中,它还可以处理重复文档和相互排名策略
ConcatenationDocumentJoiner
ConcatenationDocumentJoiner 通过将它们连接成一个单一的文档集合来合并基于多个查询和来自多个数据源检索到的文档。在重复文档的情况下,保留第一次出现。每个文档的分数保持不变
Map<Query, List<List<Document>>> documentsForQuery = ...
DocumentJoiner documentJoiner = new ConcatenationDocumentJoiner();
List<Document> documents = documentJoiner.join(documentsForQuery);Post-Retrieval 检索后
后检索模块负责处理检索到的文档,以实现最佳可能的生成结果
Document Post-Processing 文档后处理
组件用于基于查询对检索到的文档进行后处理,解决诸如中间丢失、模型上下文长度限制以及减少检索信息中的噪声和冗余等问题
可以根据查询的相关性对文档进行排序,删除无关或冗余的文档,或者压缩每个文档的内容以减少噪声和冗余
Generation 生成
生成模块负责根据用户查询和检索到的文档生成最终响应
Query Augmentation 查询增强
组件用于增强输入查询,添加额外数据,有助于为大型语言模型提供回答用户查询所需的上下文
ContextualQueryAugmenter 上下文查询增强器
增强用户查询,添加来自提供文档内容的上下文数据
QueryAugmenter queryAugmenter = ContextualQueryAugmenter.builder().build();默认情况下, ContextualQueryAugmenter 不允许检索到的上下文为空。当发生这种情况时,它指示模型不要回答用户查询
可以通过启用 allowEmptyContext 选项来允许模型在检索到的上下文为空时生成响应
QueryAugmenter queryAugmenter = ContextualQueryAugmenter.builder()
.allowEmptyContext(true)
.build();此组件使用的提示可以通过构建器中的 promptTemplate() 和 emptyContextPromptTemplate() 方法进行自定义
ETL 管道
todo
https://docs.spring.io/spring-ai/reference/api/etl-pipeline.html#_markdown
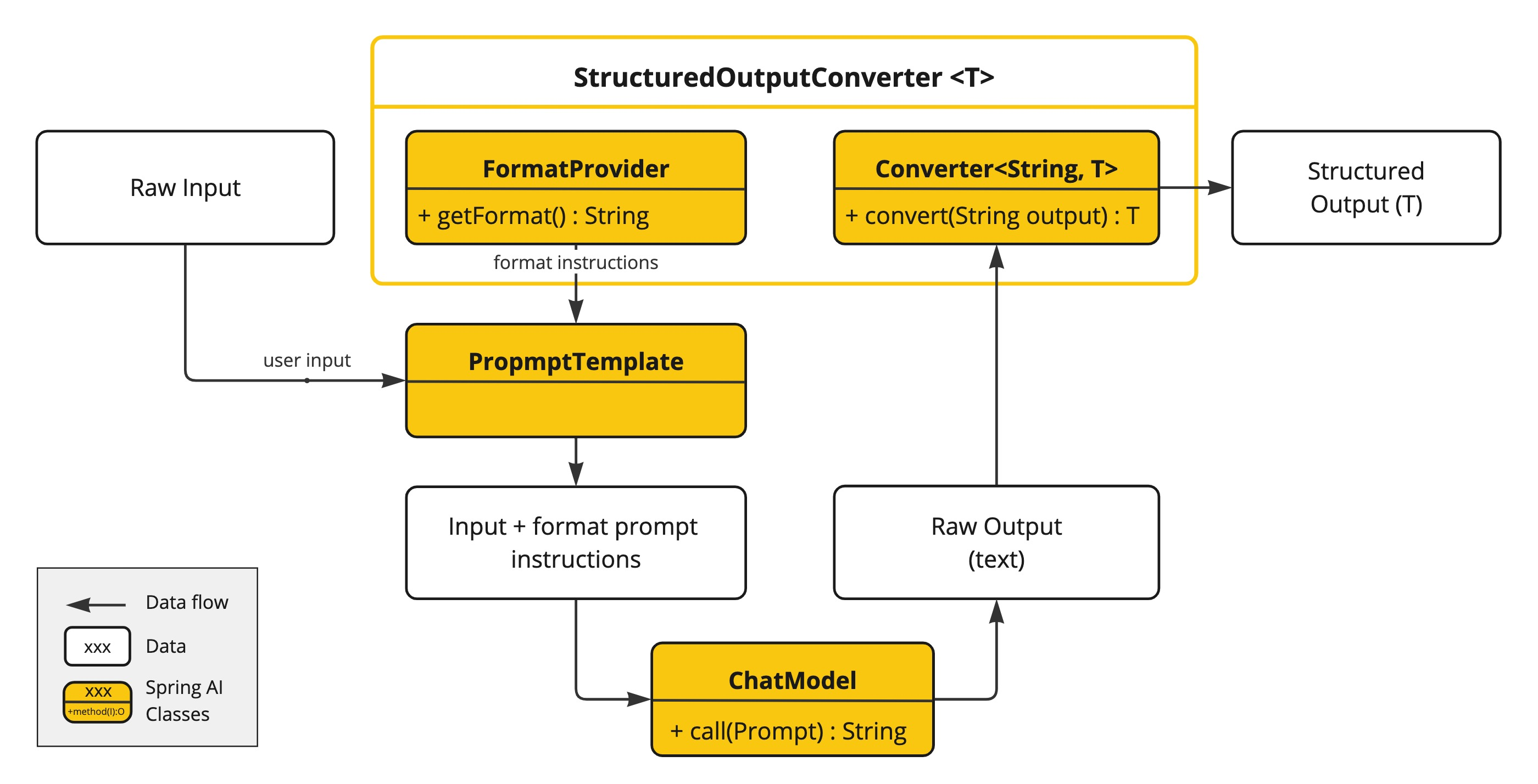
Structured Output Converter 结构化输出转换器
StructuredOutputConverter 接口允许获取结构化输出,例如将基于文本的 AI 模型输出映射到 Java 类或值数组。接口定义如下:
public interface StructuredOutputConverter<T> extends Converter<String, T>, FormatProvider {
}
prompt 示例:
Your response should be in JSON format.
The data structure for the JSON should match this Java class: java.util.HashMap
Do not include any explanations, only provide a RFC8259 compliant JSON response following this format without deviation.格式指令通常使用 PromptTemplate 附加到用户输入的末尾,如下所示:
StructuredOutputConverter outputConverter = ...
String userInputTemplate = """
... user text input ....
{format}
"""; // user input with a "format" placeholder.
Prompt prompt = new Prompt(
new PromptTemplate(
this.userInputTemplate,
Map.of(..., "format", outputConverter.getFormat()) // replace the "format" placeholder with the converter's format.
).createMessage());
可用的转换器
使用转换器
Bean Output Converter Bean 输出转换器
代表演员电影作品的目标记录:
record ActorsFilms(String actor, List<String> movies) {
}使用高级、流畅的 ChatClient API 应用 BeanOutputConverter:
ActorsFilms actorsFilms = ChatClient.create(chatModel).prompt()
.user(u -> u.text("Generate the filmography of 5 movies for {actor}.")
.param("actor", "Tom Hanks"))
.call()
.entity(ActorsFilms.class);或直接使用低级 ChatModel API:
BeanOutputConverter<ActorsFilms> beanOutputConverter =
new BeanOutputConverter<>(ActorsFilms.class);
String format = this.beanOutputConverter.getFormat();
String actor = "Tom Hanks";
String template = """
Generate the filmography of 5 movies for {actor}.
{format}
""";
Generation generation = chatModel.call(
new PromptTemplate(this.template, Map.of("actor", this.actor, "format", this.format)).create()).getResult();
ActorsFilms actorsFilms = this.beanOutputConverter.convert(this.generation.getOutput().getText());
生成的模式中的属性排序
BeanOutputConverter 支持通过 @JsonPropertyOrder 注解在生成的 JSON 架构中自定义属性排序。此注解允许指定属性在架构中应出现的确切顺序,而不管它们在类或记录中的声明顺序如何
例如,为确保在 ActorsFilms 记录中属性的特定顺序:
@JsonPropertyOrder({"actor", "movies"})
record ActorsFilms(String actor, List<String> movies) {}此注解适用于记录和常规 Java 类
Generic Bean Types 通用 Bean 类型
使用 ParameterizedTypeReference 构造函数来指定更复杂的目标类结构。例如,表示演员及其电影作品列表:
List<ActorsFilms> actorsFilms = ChatClient.create(chatModel).prompt()
.user("Generate the filmography of 5 movies for Tom Hanks and Bill Murray.")
.call()
.entity(new ParameterizedTypeReference<List<ActorsFilms>>() {});或直接使用低级 ChatModel API:
BeanOutputConverter<List<ActorsFilms>> outputConverter = new BeanOutputConverter<>(
new ParameterizedTypeReference<List<ActorsFilms>>() { });
String format = this.outputConverter.getFormat();
String template = """
Generate the filmography of 5 movies for Tom Hanks and Bill Murray.
{format}
""";
Prompt prompt = new PromptTemplate(this.template, Map.of("format", this.format)).create();
Generation generation = chatModel.call(this.prompt).getResult();
List<ActorsFilms> actorsFilms = this.outputConverter.convert(this.generation.getOutput().getText());
Map Output Converter
Map<String, Object> result = ChatClient.create(chatModel).prompt()
.user(u -> u.text("Provide me a List of {subject}")
.param("subject", "an array of numbers from 1 to 9 under they key name 'numbers'"))
.call()
.entity(new ParameterizedTypeReference<Map<String, Object>>() {});
MapOutputConverter mapOutputConverter = new MapOutputConverter();
String format = this.mapOutputConverter.getFormat();
String template = """
Provide me a List of {subject}
{format}
""";
Prompt prompt = new PromptTemplate(this.template,
Map.of("subject", "an array of numbers from 1 to 9 under they key name 'numbers'", "format", this.format)).create();
Generation generation = chatModel.call(this.prompt).getResult();
Map<String, Object> result = this.mapOutputConverter.convert(this.generation.getOutput().getText());
List Output Converter
List<String> flavors = ChatClient.create(chatModel).prompt()
.user(u -> u.text("List five {subject}")
.param("subject", "ice cream flavors"))
.call()
.entity(new ListOutputConverter(new DefaultConversionService()));
ListOutputConverter listOutputConverter = new ListOutputConverter(new DefaultConversionService());
String format = this.listOutputConverter.getFormat();
String template = """
List five {subject}
{format}
""";
Prompt prompt = new PromptTemplate(this.template,
Map.of("subject", "ice cream flavors", "format", this.format)).create();
Generation generation = this.chatModel.call(this.prompt).getResult();
List<String> list = this.listOutputConverter.convert(this.generation.getOutput().getText());
支持的模型
Chat Memory
Spring AI 自动配置了一个 ChatMemory。默认情况下,它使用内存存储库来存储消息( InMemoryChatMemoryRepository )和一个 MessageWindowChatMemory 实现来管理对话历史。如果已经配置了不同的存储库(例如,Cassandra、JDBC 或 Neo4j),Spring AI 将使用该存储库
@Autowired
ChatMemory chatMemory;
Memory Types 内存类型
内存类型的选取可能会显著影响应用程序的性能和行为
Message Window Chat Memory 消息窗口聊天内存
MessageWindowChatMemory 维护一个最多指定大小的消息窗口。当消息数量超过最大值时,将移除较旧的消息,同时保留系统消息。默认窗口大小为 20 条消息
MessageWindowChatMemory memory = MessageWindowChatMemory.builder()
.maxMessages(10)
.build();这是 Spring AI 默认的消息类型,用于自动配置一个 ChatMemory bean
Memory Storage
Spring AI 提供了 ChatMemoryRepository 抽象,用于存储聊天记忆
In-Memory Repository
InMemoryChatMemoryRepository 使用 ConcurrentHashMap 在内存中存储消息
默认情况下,如果没有配置其他存储库,Spring AI 将自动配置一个类型为 InMemoryChatMemoryRepository 的 ChatMemoryRepository bean,可以直接在应用程序中使用它
@Autowired
ChatMemoryRepository chatMemoryRepository;如果想手动创建 InMemoryChatMemoryRepository ,可以按照以下步骤进行:
ChatMemoryRepository repository = new InMemoryChatMemoryRepository();
JDBC Repository
JdbcChatMemoryRepository 是一个内置实现,使用 JDBC 将消息存储在关系型数据库中。它适用于需要持久化存储聊天记录的应用程序
将以下依赖项添加到您的项目中:
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-model-chat-memory-jdbc</artifactId>
</dependency>Spring AI 为 JdbcChatMemoryRepository 提供了自动配置,您可以直接在应用程序中使用
@Autowired
JdbcChatMemoryRepository chatMemoryRepository;
ChatMemory chatMemory = MessageWindowChatMemory.builder()
.chatMemoryRepository(chatMemoryRepository)
.maxMessages(10)
.build();如果您想手动创建 JdbcChatMemoryRepository ,可以通过提供 JdbcTemplate 实例来完成:
ChatMemoryRepository chatMemoryRepository = JdbcChatMemoryRepository.builder()
.jdbcTemplate(jdbcTemplate)
.build();
ChatMemory chatMemory = MessageWindowChatMemory.builder()
.chatMemoryRepository(chatMemoryRepository)
.maxMessages(10)
.build();
Configuration Properties 配置属性
| Property 属性 | Description 描述 | Default Value |
|---|---|---|
spring.ai.chat.memory.repository.jdbc.initialize-schema | 是否在启动时初始化模式 | true |
Schema Initialization 模式初始化
自动配置将自动使用 JDBC 驱动程序创建 ai_chat_memory 表。目前仅支持 PostgreSQL 和 MariaDB
可以通过将属性 spring.ai.chat.memory.repository.jdbc.initialize-schema 设置为 false 来禁用模式初始化
如果你的项目使用 Flyway 或 Liquibase 等工具来管理数据库模式,可以禁用模式初始化,并参考这些 SQL 脚本来配置这些工具以创建 ai_chat_memory 表
Memory in Chat Client 聊天客户端中的内存
在使用 ChatClient API 时,可以为 ChatMemory 提供实现,以在多次交互中维护会话上下文
Spring AI 提供了一些内置的顾问,可以根据需要使用它们来配置 ChatClient 的内存行为
目前,在执行工具调用时,与大型语言模型交换的中间消息不会被存储在内存中。这是当前实现的限制,将在未来的版本中解决。如果您需要存储这些消息,请参阅用户控制工具执行的说明
-
MessageChatMemoryAdvisor使用 ChatMemory 实现管理对话记忆。在每次交互时,它从记忆中检索对话历史并将其作为消息集合包含在提示中 -
PromptChatMemoryAdvisor使用 ChatMemory 实现管理对话记忆。在每次交互时,它从记忆中检索对话历史并将其作为纯文本附加到系统提示中 -
VectorStoreChatMemoryAdvisor使用 VectorStore 实现管理对话记忆。在每次交互时,它从向量存储中检索对话历史并将其作为纯文本附加到系统消息中
例如,如果想使用 MessageWindowChatMemory 与 MessageChatMemoryAdvisor 结合使用,可以按照以下方式配置:
ChatMemory chatMemory = MessageChatMemoryAdvisor.builder().build();
ChatClient chatClient = ChatClient.builder(chatModel)
.defaultAdvisors(MessageChatMemoryAdvisor.builder(chatMemory).build())
.build();在进行对 ChatClient 的调用时,内存将由 MessageChatMemoryAdvisor 自动管理。根据指定的对话 ID 从内存中检索对话历史:
String conversationId = "007";
chatClient.prompt()
.user("Do I have license to code?")
.advisors(a -> a.param(AbstractChatMemoryAdvisor.CHAT_MEMORY_CONVERSATION_ID_KEY, conversationId))
.call()
.content();
Memory in Chat Model 聊天模型中的内存
如果直接使用 ChatModel 而不是 ChatClient ,可以显式地管理内存:
// Create a memory instance
ChatMemory chatMemory = MessageWindowChatMemory.builder().build();
String conversationId = "007";
// First interaction
UserMessage userMessage1 = new UserMessage("My name is James Bond");
chatMemory.add(conversationId, userMessage1);
ChatResponse response1 = chatModel.call(new Prompt(chatMemory.get(conversationId)));
chatMemory.add(conversationId, response1.getResult().getOutput());
// Second interaction
UserMessage userMessage2 = new UserMessage("What is my name?");
chatMemory.add(conversationId, userMessage2);
ChatResponse response2 = chatModel.call(new Prompt(chatMemory.get(conversationId)));
chatMemory.add(conversationId, response2.getResult().getOutput());
// The response will contain "James Bond"
TODO 工具调用
TODO MCP:Model Context Protocol
TODO 提示工程