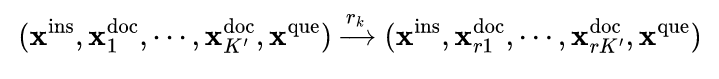(py) Florian:~ Florian$ pip list | grep pypdfpypdf 3.17.4pypdfium2 4.26.0(py) Florian:~ Florian$ python /Users/Florian/Downloads/pypdf_test.py--------------------------------------------------Table 1: Maximum path lengths, per-layer complexity and minimum number of sequential operationsfor different layer types. nis the sequence length, dis the representation dimension, kis the kernelsize of convolutions and rthe size of the neighborhood in restricted self-attention.Layer Type Complexity per Layer Sequential Maximum Path LengthOperationsSelf-Attention O(n2·d) O(1) O(1)Recurrent O(n·d2) O(n) O(n)Convolutional O(k·n·d2) O(1) O(logk(n))Self-Attention (restricted) O(r·n·d) O(1) O(n/r)3.5 Positional EncodingSince our model contains no recurrence and no convolution, in order for the model to make use of theorder of the sequence, we must inject some information about the relative or absolute position of thetokens in the sequence. To this end, we add "positional encodings" to the input embeddings at thebottoms of the encoder and decoder stacks. The positional encodings have the same dimension dmodelas the embeddings, so that the two can be summed. There are many choices of positional encodings,learned and fixed [9].In this work, we use sine and cosine functions of different frequencies:PE(pos,2i)=sin(pos/100002i/d model)PE(pos,2i+1)=cos(pos/100002i/d model)where posis the position and iis the dimension. That is, each dimension of the positional encodingcorresponds to a sinusoid. The wavelengths form a geometric progression from 2πto10000 ·2π. Wechose this function because we hypothesized it would allow the model to easily learn to attend byrelative positions, since for any fixed offset k,PEpos+kcan be represented as a linear function ofPEpos..........
from unstructured.partition.pdf import partition_pdffilename = "/Users/Florian/Downloads/Attention_Is_All_You_Need.pdf"# infer_table_structure=True automatically selects hi_res strategyelements = partition_pdf(filename=filename, infer_table_structure=True)tables = [el for el in elements if el.category == "Table"]print(tables[0].text)print('--------------------------------------------------')print(tables[0].metadata.text_as_html)
Layer Type Self-Attention Recurrent Convolutional Self-Attention (restricted) Complexity per Layer O(n2 · d) O(n · d2) O(k · n · d2) O(r · n · d) Sequential Maximum Path Length Operations O(1) O(n) O(1) O(1) O(1) O(n) O(logk(n)) O(n/r)--------------------------------------------------<table><thead><th>Layer Type</th><th>Complexity per Layer</th><th>Sequential Operations</th><th>Maximum Path Length</th></thead><tr><td>Self-Attention</td><td>O(n? - d)</td><td>O(1)</td><td>O(1)</td></tr><tr><td>Recurrent</td><td>O(n- d?)</td><td>O(n)</td><td>O(n)</td></tr><tr><td>Convolutional</td><td>O(k-n-d?)</td><td>O(1)</td><td>O(logy(n))</td></tr><tr><td>Self-Attention (restricted)</td><td>O(r-n-d)</td><td>ol)</td><td>O(n/r)</td></tr></table>
[LayoutElement(bbox=Rectangle(x1=851.1539916992188, y1=181.15073777777613, x2=1467.844970703125, y2=587.8204599999975), text='These approaches have been generalized to coarser granularities, such as sentence embed- dings (Kiros et al., 2015; Logeswaran and Lee, 2018) or paragraph embeddings (Le and Mikolov, 2014). To train sentence representations, prior work has used objectives to rank candidate next sentences (Jernite et al., 2017; Logeswaran and Lee, 2018), left-to-right generation of next sen- tence words given a representation of the previous sentence (Kiros et al., 2015), or denoising auto- encoder derived objectives (Hill et al., 2016). ', source=<Source.YOLOX: 'yolox'>, type='Text', prob=0.9519357085227966, image_path=None, parent=None), ......LayoutElement(bbox=Rectangle(x1=853.4905395507812, y1=1681.5868488888855, x2=1467.8729248046875, y2=2125.8954599999965), text='More recently, sentence or document encoders which produce contextual token representations have been pre-trained from unlabeled text and fine-tuned for a supervised downstream task (Dai and Le, 2015; Howard and Ruder, 2018; Radford et al., 2018). The advantage of these approaches is that few parameters need to be learned from scratch. At least partly due to this advantage, OpenAI GPT (Radford et al., 2018) achieved pre- viously state-of-the-art results on many sentence- level tasks from the GLUE benchmark (Wang language model- Left-to-right et al., 2018a). ', source=<Source.YOLOX: 'yolox'>, type='Text', prob=0.9476840496063232, image_path=None, parent=None)]
import osos.environ["OPENAI_API_KEY"] = "YOUR_OPENAI_KEY"from llama_index import VectorStoreIndex, SimpleDirectoryReaderfrom llama_index.postprocessor.flag_embedding_reranker import FlagEmbeddingRerankerfrom llama_index.schema import QueryBundledir_path = "YOUR_DIR_PATH"# Using LlamaIndex to build a simple retrieverdocuments = SimpleDirectoryReader(dir_path).load_data()index = VectorStoreIndex.from_documents(documents)retriever = index.as_retriever(similarity_top_k = 3)# 基本检索query = "Can you provide a concise description of the TinyLlama model?"nodes = retriever.retrieve(query)for node in nodes: print('----------------------------------------------------') display_source_node(node, source_length = 500)from llama_index.schema import ImageNode, MetadataMode, NodeWithScorefrom llama_index.utils import truncate_text# display_source_node 函数改编自 llama_index 源代码def display_source_node( source_node: NodeWithScore, source_length: int = 100, show_source_metadata: bool = False, metadata_mode: MetadataMode = MetadataMode.NONE,) -> None: """Display source node""" source_text_fmt = truncate_text( source_node.node.get_content(metadata_mode=metadata_mode).strip(), source_length ) text_md = ( f"Node ID: {source_node.node.node_id} \n" f"Score: {source_node.score} \n" f"Text: {source_text_fmt} \n" ) if show_source_metadata: text_md += f"Metadata: {source_node.node.metadata} \n" if isinstance(source_node.node, ImageNode): text_md += "Image:" print(text_md) # display(Markdown(text_md)) # if isinstance(source_node.node, ImageNode) and source_node.node.image is not None: # display_image(source_node.node.image)
基本检索结果如下,代表重新排序前的前 3 个节点:
----------------------------------------------------Node ID: 438b9d91-cd5a-44a8-939e-3ecd77648662 Score: 0.8706055408845863 Text: 4 ConclusionIn this paper, we introduce TinyLlama, an open-source, small-scale language model. To promotetransparency in the open-source LLM pre-training community, we have released all relevant infor-mation, including our pre-training code, all intermediate model checkpoints, and the details of ourdata processing steps. With its compact architecture and promising performance, TinyLlama canenable end-user applications on mobile devices, and serve as a lightweight platform for testing aw... ----------------------------------------------------Node ID: ca4db90f-5c6e-47d5-a544-05a9a1d09bc6 Score: 0.8624531691777889 Text: TinyLlama: An Open-Source Small Language ModelPeiyuan Zhang∗Guangtao Zeng∗Tianduo Wang Wei LuStatNLP Research GroupSingapore University of Technology and Design{peiyuan_zhang, tianduo_wang, @sutd.edu.sg">luwei}@sutd.edu.sg[email protected]AbstractWe present TinyLlama, a compact 1.1B language model pretrained on around 1trillion tokens for approximately 3 epochs. Building on the architecture and tok-enizer of Llama 2 (Touvron et al., 2023b), TinyLlama leverages various advancescontr... ----------------------------------------------------Node ID: e2d97411-8dc0-40a3-9539-a860d1741d4f Score: 0.8346160605298356 Text: Although these works show a clear preference on large models, the potential of training smallermodels with larger dataset remains under-explored. Instead of training compute-optimal languagemodels, Touvron et al. (2023a) highlight the importance of the inference budget, instead of focusingsolely on training compute-optimal language models. Inference-optimal language models aim foroptimal performance within specific inference constraints This is achieved by training models withmore tokens...
------------------------------------------------------------------------------------------------Start reranking...----------------------------------------------------Node ID: ca4db90f-5c6e-47d5-a544-05a9a1d09bc6 Score: -1.584416151046753 Text: TinyLlama: An Open-Source Small Language ModelPeiyuan Zhang∗Guangtao Zeng∗Tianduo Wang Wei LuStatNLP Research GroupSingapore University of Technology and Design{peiyuan_zhang, tianduo_wang, @sutd.edu.sg">luwei}@sutd.edu.sg[email protected]AbstractWe present TinyLlama, a compact 1.1B language model pretrained on around 1trillion tokens for approximately 3 epochs. Building on the architecture and tok-enizer of Llama 2 (Touvron et al., 2023b), TinyLlama leverages various advancescontr... ----------------------------------------------------Node ID: e2d97411-8dc0-40a3-9539-a860d1741d4f Score: -1.7028117179870605 Text: Although these works show a clear preference on large models, the potential of training smallermodels with larger dataset remains under-explored. Instead of training compute-optimal languagemodels, Touvron et al. (2023a) highlight the importance of the inference budget, instead of focusingsolely on training compute-optimal language models. Inference-optimal language models aim foroptimal performance within specific inference constraints This is achieved by training models withmore tokens... ----------------------------------------------------Node ID: 438b9d91-cd5a-44a8-939e-3ecd77648662 Score: -2.904750347137451 Text: 4 ConclusionIn this paper, we introduce TinyLlama, an open-source, small-scale language model. To promotetransparency in the open-source LLM pre-training community, we have released all relevant infor-mation, including our pre-training code, all intermediate model checkpoints, and the details of ourdata processing steps. With its compact architecture and promising performance, TinyLlama canenable end-user applications on mobile devices, and serve as a lightweight platform for testing aw...
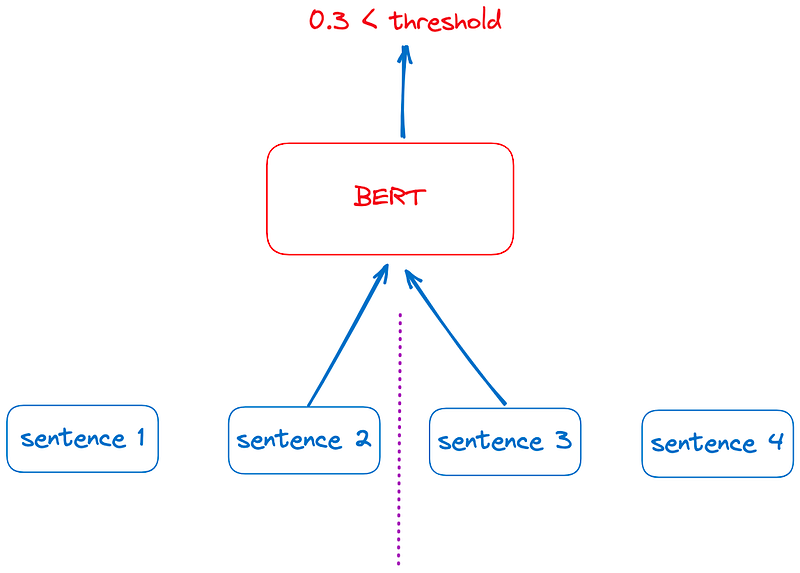
from modelscope.outputs import OutputKeysfrom modelscope.pipelines import pipelinefrom modelscope.utils.constant import Tasksp = pipeline( task = Tasks.document_segmentation, model = 'damo/nlp_bert_document-segmentation_english-base')print('-' * 100)result = p(documents='We demonstrate the importance of bidirectional pre-training for language representations. Unlike Radford et al. (2018), which uses unidirectional language models for pre-training, BERT uses masked language models to enable pretrained deep bidirectional representations. This is also in contrast to Peters et al. (2018a), which uses a shallow concatenation of independently trained left-to-right and right-to-left LMs. • We show that pre-trained representations reduce the need for many heavily-engineered taskspecific architectures. BERT is the first finetuning based representation model that achieves state-of-the-art performance on a large suite of sentence-level and token-level tasks, outperforming many task-specific architectures. Today is a good day')print(result[OutputKeys.TEXT]
PROPOSITIONS_PROMPT = PromptTemplate( """Decompose the "Content" into clear and simple propositions, ensuring they are interpretable out ofcontext.1. Split compound sentence into simple sentences. Maintain the original phrasing from the inputwhenever possible.2. For any named entity that is accompanied by additional descriptive information, separate thisinformation into its own distinct proposition.3. Decontextualize the proposition by adding necessary modifier to nouns or entire sentencesand replacing pronouns (e.g., "it", "he", "she", "they", "this", "that") with the full name of theentities they refer to.4. Present the results as a list of strings, formatted in JSON.Input: Title: ¯Eostre. Section: Theories and interpretations, Connection to Easter Hares. Content:The earliest evidence for the Easter Hare (Osterhase) was recorded in south-west Germany in1678 by the professor of medicine Georg Franck von Franckenau, but it remained unknown inother parts of Germany until the 18th century. Scholar Richard Sermon writes that "hares werefrequently seen in gardens in spring, and thus may have served as a convenient explanation for theorigin of the colored eggs hidden there for children. Alternatively, there is a European traditionthat hares laid eggs, since a hare’s scratch or form and a lapwing’s nest look very similar, andboth occur on grassland and are first seen in the spring. In the nineteenth century the influenceof Easter cards, toys, and books was to make the Easter Hare/Rabbit popular throughout Europe.German immigrants then exported the custom to Britain and America where it evolved into theEaster Bunny."Output: [ "The earliest evidence for the Easter Hare was recorded in south-west Germany in1678 by Georg Franck von Franckenau.", "Georg Franck von Franckenau was a professor ofmedicine.", "The evidence for the Easter Hare remained unknown in other parts of Germany untilthe 18th century.", "Richard Sermon was a scholar.", "Richard Sermon writes a hypothesis aboutthe possible explanation for the connection between hares and the tradition during Easter", "Hareswere frequently seen in gardens in spring.", "Hares may have served as a convenient explanationfor the origin of the colored eggs hidden in gardens for children.", "There is a European traditionthat hares laid eggs.", "A hare’s scratch or form and a lapwing’s nest look very similar.", "Bothhares and lapwing’s nests occur on grassland and are first seen in the spring.", "In the nineteenthcentury the influence of Easter cards, toys, and books was to make the Easter Hare/Rabbit popularthroughout Europe.", "German immigrants exported the custom of the Easter Hare/Rabbit toBritain and America.", "The custom of the Easter Hare/Rabbit evolved into the Easter Bunny inBritain and America." ]Input: {node_text}Output:""")
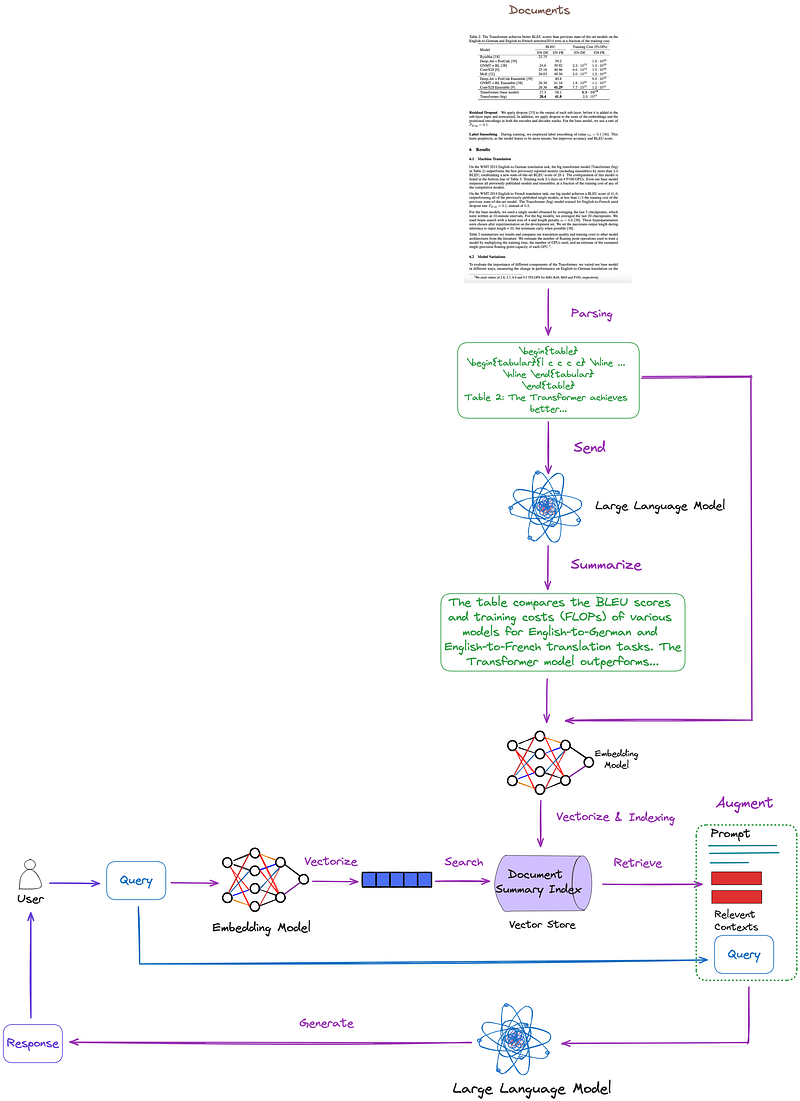
from llama_index.core.readers import SimpleDirectoryReaderfrom llama_index.core.llama_pack import download_llama_packimport osos.environ["OPENAI_API_KEY"] = "YOUR_OPENAI_KEY"# Download and install dependenciesDenseXRetrievalPack = download_llama_pack( "DenseXRetrievalPack", "./dense_pack")# If you have already downloaded DenseXRetrievalPack, you can import it directly.# from llama_index.packs.dense_x_retrieval import DenseXRetrievalPack# Load documentsdir_path = "YOUR_DIR_PATH"documents = SimpleDirectoryReader(dir_path).load_data()# Use LLM to extract propositions from every document/nodedense_pack = DenseXRetrievalPack(documents)response = dense_pack.run("YOUR_QUERY")
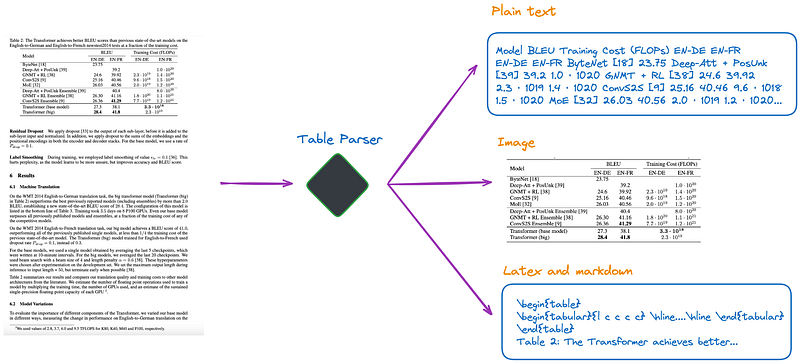
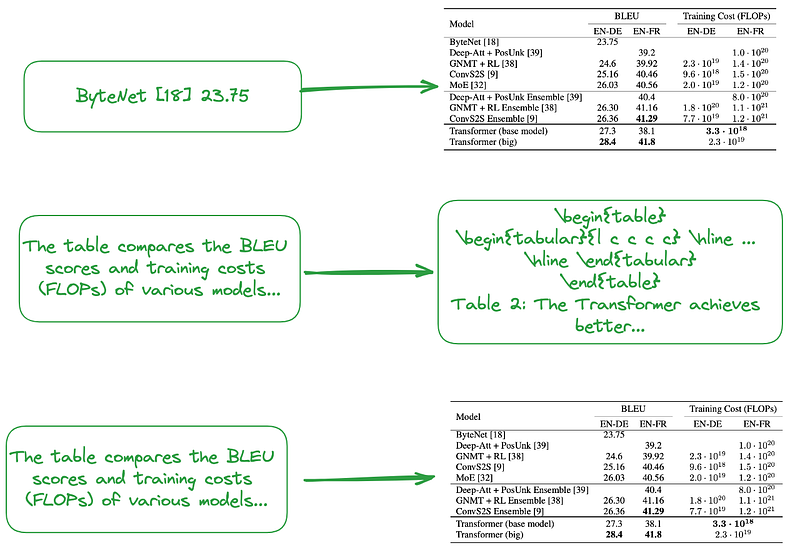
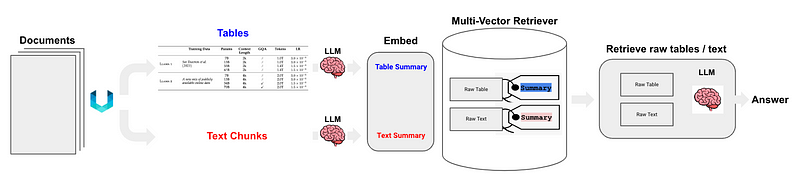
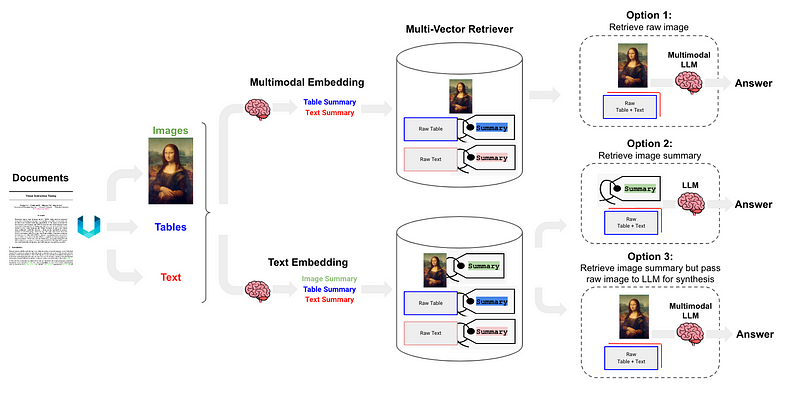
# 设置环境并导入import osos.environ["OPENAI_API_KEY"] = "YOUR_OPEN_AI_KEY"import subprocessimport uuidfrom langchain_core.output_parsers import StrOutputParserfrom langchain_core.prompts import ChatPromptTemplatefrom langchain_openai import ChatOpenAIfrom langchain.retrievers.multi_vector import MultiVectorRetrieverfrom langchain.storage import InMemoryStorefrom langchain_community.vectorstores import Chromafrom langchain_core.documents import Documentfrom langchain_openai import OpenAIEmbeddingsfrom langchain_core.runnables import RunnablePassthroughdef june_run_nougat(file_path, output_dir): # Run Nougat and store results as Mathpix Markdown cmd = ["nougat", file_path, "-o", output_dir, "-m", "0.1.0-base", "--no-skipping"] res = subprocess.run(cmd) if res.returncode != 0: print("Error when running nougat.") return res.returncode else: print("Operation Completed!") return 0def june_get_tables_from_mmd(mmd_path): f = open(mmd_path) lines = f.readlines() res = [] tmp = [] flag = "" for line in lines: if line == "\\begin{table}\n": flag = "BEGINTABLE" elif line == "\\end{table}\n": flag = "ENDTABLE" if flag == "BEGINTABLE": tmp.append(line) elif flag == "ENDTABLE": tmp.append(line) flag = "CAPTION" elif flag == "CAPTION": tmp.append(line) flag = "MARKDOWN" print('-' * 100) print(''.join(tmp)) res.append(''.join(tmp)) tmp = [] return resfile_path = "YOUR_PDF_PATH"output_dir = "YOUR_OUTPUT_DIR_PATH"if june_run_nougat(file_path, output_dir) == 1: import sys sys.exit(1)mmd_path = output_dir + '/' + os.path.splitext(file_path)[0].split('/')[-1] + ".mmd"tables = june_get_tables_from_mmd(mmd_path)# 使用 LLM 对表格进行汇总# Promptprompt_text = """You are an assistant tasked with summarizing tables and text. \ Give a concise summary of the table or text. The table is formatted in LaTeX, and its caption is in plain text format: {element} """prompt = ChatPromptTemplate.from_template(prompt_text)# Summary chainmodel = ChatOpenAI(temperature = 0, model = "gpt-3.5-turbo")summarize_chain = {"element": lambda x: x} | prompt | model | StrOutputParser()# Get table summariestable_summaries = summarize_chain.batch(tables, {"max_concurrency": 5})print(table_summaries)# 使用多向量检索器构建文档摘要索引结构# The vectorstore to use to index the child chunksvectorstore = Chroma(collection_name = "summaries", embedding_function = OpenAIEmbeddings())# The storage layer for the parent documentsstore = InMemoryStore()id_key = "doc_id"# The retriever (empty to start)retriever = MultiVectorRetriever( vectorstore = vectorstore, docstore = store, id_key = id_key, search_kwargs={"k": 1} # Solving Number of requested results 4 is greater than number of elements in index..., updating n_results = 1)# Add tablestable_ids = [str(uuid.uuid4()) for _ in tables]summary_tables = [ Document(page_content = s, metadata = {id_key: table_ids[i]}) for i, s in enumerate(table_summaries)]retriever.vectorstore.add_documents(summary_tables)retriever.docstore.mset(list(zip(table_ids, tables)))# 建立一个简单的 RAG 管道并执行查询# Prompt templatetemplate = """Answer the question based only on the following context, which can include text and tables, there is a table in LaTeX format and a table caption in plain text format:{context}Question: {question}"""prompt = ChatPromptTemplate.from_template(template)# LLMmodel = ChatOpenAI(temperature = 0, model = "gpt-3.5-turbo")# Simple RAG pipelinechain = ( {"context": retriever, "question": RunnablePassthrough()} | prompt | model | StrOutputParser())print(chain.invoke("when layer type is Self-Attention, what is the Complexity per Layer?")) # Query about table 1print(chain.invoke("Which parser performs worst for BLEU EN-DE")) # Query about table 2print(chain.invoke("Which parser performs best for WSJ 23 F1")) # Query about table 4
整体代码如下
import osos.environ["OPENAI_API_KEY"] = "YOUR_OPEN_AI_KEY"import subprocessimport uuidfrom langchain_core.output_parsers import StrOutputParserfrom langchain_core.prompts import ChatPromptTemplatefrom langchain_openai import ChatOpenAIfrom langchain.retrievers.multi_vector import MultiVectorRetrieverfrom langchain.storage import InMemoryStorefrom langchain_community.vectorstores import Chromafrom langchain_core.documents import Documentfrom langchain_openai import OpenAIEmbeddingsfrom langchain_core.runnables import RunnablePassthroughdef june_run_nougat(file_path, output_dir): # Run Nougat and store results as Mathpix Markdown cmd = ["nougat", file_path, "-o", output_dir, "-m", "0.1.0-base", "--no-skipping"] res = subprocess.run(cmd) if res.returncode != 0: print("Error when running nougat.") return res.returncode else: print("Operation Completed!") return 0def june_get_tables_from_mmd(mmd_path): f = open(mmd_path) lines = f.readlines() res = [] tmp = [] flag = "" for line in lines: if line == "\\begin{table}\n": flag = "BEGINTABLE" elif line == "\\end{table}\n": flag = "ENDTABLE" if flag == "BEGINTABLE": tmp.append(line) elif flag == "ENDTABLE": tmp.append(line) flag = "CAPTION" elif flag == "CAPTION": tmp.append(line) flag = "MARKDOWN" print('-' * 100) print(''.join(tmp)) res.append(''.join(tmp)) tmp = [] return resfile_path = "YOUR_PDF_PATH"output_dir = "YOUR_OUTPUT_DIR_PATH"if june_run_nougat(file_path, output_dir) == 1: import sys sys.exit(1)mmd_path = output_dir + '/' + os.path.splitext(file_path)[0].split('/')[-1] + ".mmd"tables = june_get_tables_from_mmd(mmd_path)# Promptprompt_text = """You are an assistant tasked with summarizing tables and text. \ Give a concise summary of the table or text. The table is formatted in LaTeX, and its caption is in plain text format: {element} """prompt = ChatPromptTemplate.from_template(prompt_text)# Summary chainmodel = ChatOpenAI(temperature = 0, model = "gpt-3.5-turbo")summarize_chain = {"element": lambda x: x} | prompt | model | StrOutputParser()# Get table summariestable_summaries = summarize_chain.batch(tables, {"max_concurrency": 5})print(table_summaries)# The vectorstore to use to index the child chunksvectorstore = Chroma(collection_name = "summaries", embedding_function = OpenAIEmbeddings())# The storage layer for the parent documentsstore = InMemoryStore()id_key = "doc_id"# The retriever (empty to start)retriever = MultiVectorRetriever( vectorstore = vectorstore, docstore = store, id_key = id_key, search_kwargs={"k": 1} # Solving Number of requested results 4 is greater than number of elements in index..., updating n_results = 1)# Add tablestable_ids = [str(uuid.uuid4()) for _ in tables]summary_tables = [ Document(page_content = s, metadata = {id_key: table_ids[i]}) for i, s in enumerate(table_summaries)]retriever.vectorstore.add_documents(summary_tables)retriever.docstore.mset(list(zip(table_ids, tables)))# Prompt templatetemplate = """Answer the question based only on the following context, which can include text and tables, there is a table in LaTeX format and a table caption in plain text format:{context}Question: {question}"""prompt = ChatPromptTemplate.from_template(template)# LLMmodel = ChatOpenAI(temperature = 0, model = "gpt-3.5-turbo")# Simple RAG pipelinechain = ( {"context": retriever, "question": RunnablePassthrough()} | prompt | model | StrOutputParser())print(chain.invoke("when layer type is Self-Attention, what is the Complexity per Layer?")) # Query about table 1print(chain.invoke("Which parser performs worst for BLEU EN-DE")) # Query about table 2print(chain.invoke("Which parser performs best for WSJ 23 F1")) # Query about table 4
from selective_context import SelectiveContextsc = SelectiveContext(model_type='gpt2', lang='en')text = "INTRODUCTION Continual Learning ( CL ) , also known as Lifelong Learning , is a promising learning paradigm to design models that have to learn how to perform multiple tasks across different environments over their lifetime [To uniform the language and enhance the readability of the paper we adopt the unique term continual learning ( CL ) .]. Ideal CL models in the real world should be deal with domain shifts , researchers have recently started to sample tasks from two different datasets . For instance , proposed to train and evaluate a model on Imagenet first and then challenge its performance on the Places365 dataset . considers more scenarios , starting with Imagenet or Places365 , and then moving on to the VOC/CUB/Scenes datasets. Few works propose more advanced scenarios built on top of more than two datasets."context, reduced_content = sc(text)# We can also adjust the reduce ratio# context_ratio, reduced_content_ratio = sc(text, reduce_ratio = 0.5)
sc(text) 函数源代码
class SelectiveContext: ... ... def __call__(self, text: str, reduce_ratio: float = 0.35, reduce_level :str = 'phrase') -> List[str]: context = self.beautify_context(text) self.mask_ratio = reduce_ratio sents = [sent.strip() for sent in re.split(self.sent_tokenize_pattern, context) if sent.strip()] # You want the reduce happen at sentence level, phrase level, or token level? assert reduce_level in ['sent', 'phrase', 'token'], f"reduce_level should be one of ['sent', 'phrase', 'token'], got {reduce_level}" sent_lus, phrase_lus, token_lus = self._lexical_unit(sents) lexical_level = { 'sent': sent_lus, 'phrase': phrase_lus, 'token': token_lus } # context is the reduced context, masked_sents denotes what context has been filtered out context, masked_sents = self.self_info_mask(lexical_level[reduce_level].text, lexical_level[reduce_level].self_info, reduce_level) return context, masked_sents
步骤 1:计算自我信息
给定上下文 C = x0、x1、......、xn,其中每个 xi 代表一个标记,使用因果语言模型(如 GPT-2、OPT 和 LLaMA)来计算每个标记 xi 的自我信息
class SelectiveContext: ... ... def _lexical_unit(self, sents): if self.sent_level_self_info: sent_self_info = [] all_noun_phrases = [] all_noun_phrases_info = [] all_tokens = [] all_token_self_info = [] for sent in sents: # print(sent) tokens, self_info = self.get_self_information(sent) ''' ipdb> sent 'INTRODUCTION Continual Learning ( CL ) , also known as Lifelong Learning , is a promising learning paradigm to design models that have to learn how to perform multiple tasks across different environments over their lifetime [To uniform the language and enhance the readability of the paper we adopt the unique term continual learning ( CL ) .].' ipdb> tokens ['IN', 'TR', 'ODUCT', 'ION', ' Contin', 'ual', ' Learning', ' (', ' CL', ' )', ',', ' also', ' known', ' as', ' Lif', 'elong', ' Learning', ',', ' is', ' a', ' promising', ' learning', ' paradigm', ' to', ' design', ' models', ' that', ' have', ' to', ' learn', ' how', ' to', ' perform', ' multiple', ' tasks', ' across', ' different', ' environments', ' over', ' their', ' lifetime', ' [', 'To', ' uniform', ' the', ' language', ' and', ' enhance', ' the', ' read', 'ability', ' of', ' the', ' paper', ' we', ' adopt', ' the', ' unique', ' term', ' continual', ' learning', ' (', ' CL', ' )', '.', '].'] ipdb> self_info [7.514791011810303, 1.632637619972229, 0.024813441559672356, 0.006853647995740175, 12.09920597076416, 2.1144468784332275, 9.457701683044434, 2.4503376483917236, 10.236454963684082, 0.8689146041870117, 5.269547939300537, 4.641763210296631, 0.22138957679271698, 0.010370315983891487, 10.071824073791504, 0.6905602216720581, 0.01698811538517475, 1.5882389545440674, 0.4495090842247009, 0.45371606945991516, 6.932497978210449, 6.087430477142334, 3.66465425491333, 3.3969509601593018, 7.337691307067871, 5.881226539611816, 1.7340556383132935, 4.599822521209717, 6.482723236083984, 4.045308589935303, 4.762691497802734, 0.21346867084503174, 3.7985599040985107, 4.6389899253845215, 0.33642446994781494, 4.918881416320801, 2.076707601547241, 3.3553669452667236, 5.5081071853637695, 5.625778675079346, 0.7966060638427734, 6.347291946411133, 12.772034645080566, 13.792041778564453, 4.11267614364624, 6.583715915679932, 3.3618998527526855, 8.434362411499023, 1.2423189878463745, 5.8330583572387695, 0.0013973338063806295, 0.3090735077857971, 1.1139129400253296, 4.160390853881836, 3.744772434234619, 7.2841596603393555, 1.4088190793991089, 7.86871337890625, 4.305004596710205, 9.69282341003418, 0.08665203303098679, 1.6127821207046509, 1.6296097040176392, 0.46206924319267273, 3.0398476123809814, 6.892032623291016] ''' sent_self_info.append(np.mean(self_info)) all_tokens.extend(tokens) all_token_self_info.extend(self_info) noun_phrases, noun_phrases_info = self._calculate_lexical_unit(tokens, self_info) ''' ipdb> noun_phrases ['INTRODUCTION Continual Learning', ' (', ' CL', ' )', ',', ' also', ' known', ' as', ' Lifelong Learning', ',', ' is', ' a promising learning paradigm', ' to', ' design', ' models', ' that', ' have', ' to', ' learn', ' how', ' to', ' perform', ' multiple tasks', ' across', ' different environments', ' over', ' their lifetime', ' [', 'To', ' uniform', ' the language', ' and', ' enhance', ' the readability', ' of', ' the paper', ' we', ' adopt', ' the unique term continual learning', ' (', ' CL', ' )', '.', ']', '.'] ipdb> noun_phrases_info [4.692921464797109, 2.4503376483917236, 10.236454963684082, 0.8689146041870117, 5.269547939300537, 4.641763210296631, 0.22138957679271698, 0.010370315983891487, 3.5931241369495788, 1.5882389545440674, 0.4495090842247009, 4.284574694931507, 3.3969509601593018, 7.337691307067871, 5.881226539611816, 1.7340556383132935, 4.599822521209717, 6.482723236083984, 4.045308589935303, 4.762691497802734, 0.21346867084503174, 3.7985599040985107, 2.487707197666168, 4.918881416320801, 2.7160372734069824, 5.5081071853637695, 3.2111923694610596, 6.347291946411133, 12.772034645080566, 13.792041778564453, 5.348196029663086, 3.3618998527526855, 8.434362411499023, 2.3589248929638416, 0.3090735077857971, 2.6371518969535828, 3.744772434234619, 7.2841596603393555, 4.672402499616146, 1.6127821207046509, 1.6296097040176392, 0.46206924319267273, 3.0398476123809814, 3.446016311645508, 3.446016311645508] ''' # We need to add a space before the first noun phrase for every sentence except the first one if all_noun_phrases: noun_phrases[0] = f" {noun_phrases[0]}" all_noun_phrases.extend(noun_phrases) all_noun_phrases_info.extend(noun_phrases_info) return [ LexicalUnits('sent', text=sents, self_info=sent_self_info), LexicalUnits('phrase', text=all_noun_phrases, self_info=all_noun_phrases_info), LexicalUnits('token', text=all_tokens, self_info=all_token_self_info) ]
步骤 3:有选择地保留信息
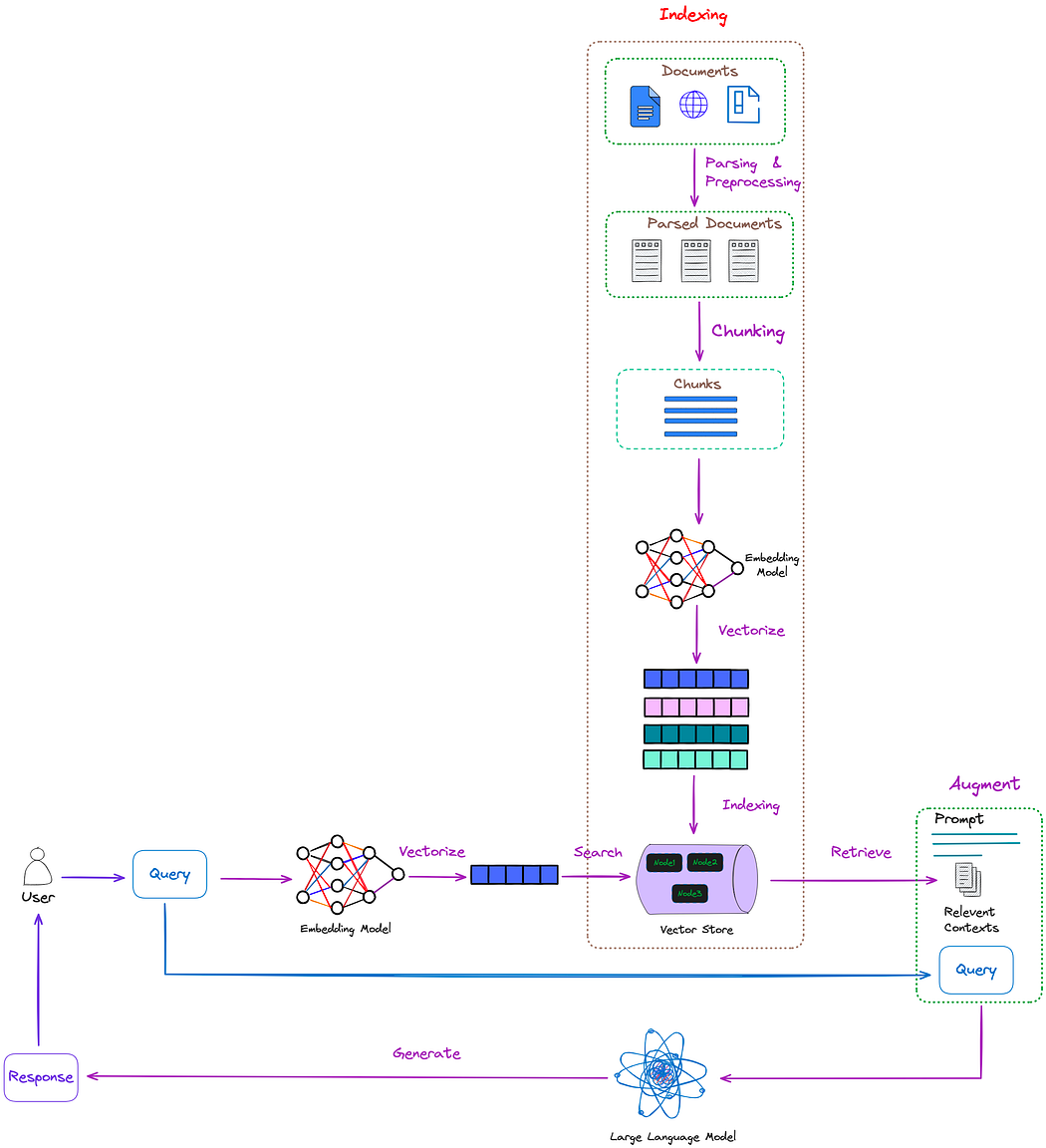
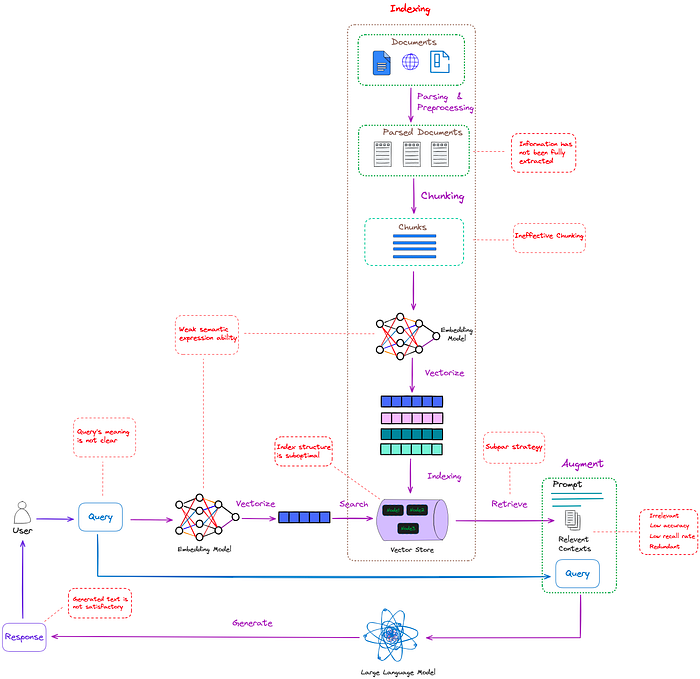
如何评估它们的信息量?
本文提出了一种自适应方法,使用基于百分位数的过滤方法来选择信息量最大的内容。这比使用固定阈值或保留固定数量的前 k 个词汇单元更可取
根据词性单位的自信息值从高到低排列词性单位
计算所有词性单元这些值的 pth 百分位数
选择性地保留自信息值大于或等于 pth 百分位数的词汇单位
相应的代码如下
class SelectiveContext: ... ... def self_info_mask(self, sents: List[str], self_info: List[float], mask_level): # mask_level: mask sentences, phrases, or tokens sents_after_mask = [] masked_sents = [] self.ppl_threshold = np.nanpercentile(self_info, self.mask_ratio * 100) # if title is not None: # with open(os.path.join(self.path, title+'_prob_token.tsv'), 'w', encoding='utf-8') as f: # for token, info in zip(tokens, self_info): # f.write(f"{token}\t{info}\n") # with open(os.path.join(self.path, title+'_prob_sent.tsv'), 'w', encoding='utf-8') as f: # for sent, info in zip(sents, sent_self_info): # f.write(f"{sent}\n{info}\n\n") for sent, info in zip(sents, self_info): if info < self.ppl_threshold: masked_sents.append(sent) sents_after_mask.append(self.mask_a_sent(sent, mask_level)) else: sents_after_mask.append(sent) masked_context = " ".join(sents_after_mask) if mask_level == 'sent' else "".join(sents_after_mask) return masked_context, masked_sents
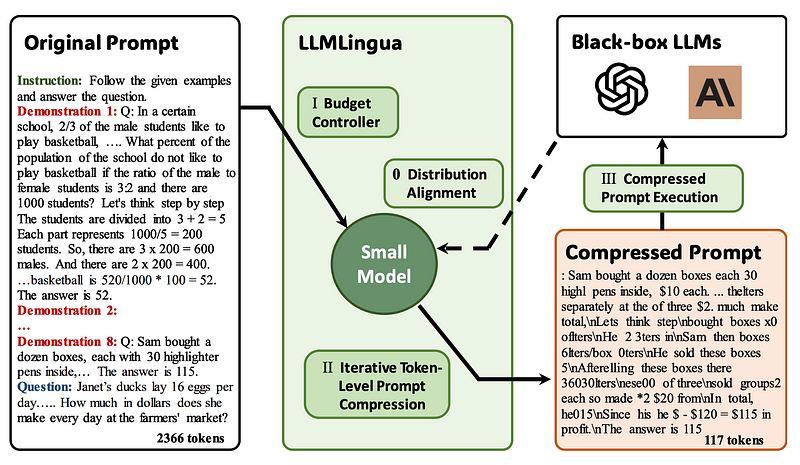
from llmlingua import PromptCompressorGSM8K_PROMPT = "Question: Angelo and Melanie want to plan how many hours over the next week they should study together for their test next week. They have 2 chapters of their textbook to study and 4 worksheets to memorize. They figure out that they should dedicate 3 hours to each chapter of their textbook and 1.5 hours for each worksheet. If they plan to study no more than 4 hours each day, how many days should they plan to study total over the next week if they take a 10-minute break every hour, include 3 10-minute snack breaks each day, and 30 minutes for lunch each day?\nLet's think step by step\nAngelo and Melanie think they should dedicate 3 hours to each of the 2 chapters, 3 hours x 2 chapters = 6 hours total.\nFor the worksheets they plan to dedicate 1.5 hours for each worksheet, 1.5 hours x 4 worksheets = 6 hours total.\nAngelo and Melanie need to start with planning 12 hours to study, at 4 hours a day, 12 / 4 = 3 days.\nHowever, they need to include time for breaks and lunch. Every hour they want to include a 10-minute break, so 12 total hours x 10 minutes = 120 extra minutes for breaks.\nThey also want to include 3 10-minute snack breaks, 3 x 10 minutes = 30 minutes.\nAnd they want to include 30 minutes for lunch each day, so 120 minutes for breaks + 30 minutes for snack breaks + 30 minutes for lunch = 180 minutes, or 180 / 60 minutes per hour = 3 extra hours.\nSo Angelo and Melanie want to plan 12 hours to study + 3 hours of breaks = 15 hours total.\nThey want to study no more than 4 hours each day, 15 hours / 4 hours each day = 3.75\nThey will need to plan to study 4 days to allow for all the time they need.\nThe answer is 4\n\nQuestion: You can buy 4 apples or 1 watermelon for the same price. You bought 36 fruits evenly split between oranges, apples and watermelons, and the price of 1 orange is $0.50. How much does 1 apple cost if your total bill was $66?\nLet's think step by step\nIf 36 fruits were evenly split between 3 types of fruits, then I bought 36/3 = 12 units of each fruit\nIf 1 orange costs $0.50 then 12 oranges will cost $0.50 * 12 = $6\nIf my total bill was $66 and I spent $6 on oranges then I spent $66 - $6 = $60 on the other 2 fruit types.\nAssuming the price of watermelon is W, and knowing that you can buy 4 apples for the same price and that the price of one apple is A, then 1W=4A\nIf we know we bought 12 watermelons and 12 apples for $60, then we know that $60 = 12W + 12A\nKnowing that 1W=4A, then we can convert the above to $60 = 12(4A) + 12A\n$60 = 48A + 12A\n$60 = 60A\nThen we know the price of one apple (A) is $60/60= $1\nThe answer is 1\n\nQuestion: Susy goes to a large school with 800 students, while Sarah goes to a smaller school with only 300 students. At the start of the school year, Susy had 100 social media followers. She gained 40 new followers in the first week of the school year, half that in the second week, and half of that in the third week. Sarah only had 50 social media followers at the start of the year, but she gained 90 new followers the first week, a third of that in the second week, and a third of that in the third week. After three weeks, how many social media followers did the girl with the most total followers have?\nLet's think step by step\nAfter one week, Susy has 100+40 = 140 followers.\nIn the second week, Susy gains 40/2 = 20 new followers.\nIn the third week, Susy gains 20/2 = 10 new followers.\nIn total, Susy finishes the three weeks with 140+20+10 = 170 total followers.\nAfter one week, Sarah has 50+90 = 140 followers.\nAfter the second week, Sarah gains 90/3 = 30 followers.\nAfter the third week, Sarah gains 30/3 = 10 followers.\nSo, Sarah finishes the three weeks with 140+30+10 = 180 total followers.\nThus, Sarah is the girl with the most total followers with a total of 180.\nThe answer is 180"llm_lingua = PromptCompressor()## Or use the phi-2 model,# llm_lingua = PromptCompressor("microsoft/phi-2")## Or use the quantation model, like TheBloke/Llama-2-7b-Chat-GPTQ, only need <8GB GPU memory.## Before that, you need to pip install optimum auto-gptq# llm_lingua = PromptCompressor("TheBloke/Llama-2-7b-Chat-GPTQ", model_config={"revision": "main"})compressed_prompt = llm_lingua.compress_prompt(GSM8K_PROMPT.split("\n\n")[0], instruction="", question="", target_token=200)print('-' * 100)print("original:")print(GSM8K_PROMPT.split("\n\n")[0])print('-' * 100)print("compressed_prompt:")print(compressed_prompt)
from llmlingua import PromptCompressorGSM8K_PROMPT = "Question: Angelo and Melanie want to plan how many hours over the next week they should study together for their test next week. They have 2 chapters of their textbook to study and 4 worksheets to memorize. They figure out that they should dedicate 3 hours to each chapter of their textbook and 1.5 hours for each worksheet. If they plan to study no more than 4 hours each day, how many days should they plan to study total over the next week if they take a 10-minute break every hour, include 3 10-minute snack breaks each day, and 30 minutes for lunch each day?\nLet's think step by step\nAngelo and Melanie think they should dedicate 3 hours to each of the 2 chapters, 3 hours x 2 chapters = 6 hours total.\nFor the worksheets they plan to dedicate 1.5 hours for each worksheet, 1.5 hours x 4 worksheets = 6 hours total.\nAngelo and Melanie need to start with planning 12 hours to study, at 4 hours a day, 12 / 4 = 3 days.\nHowever, they need to include time for breaks and lunch. Every hour they want to include a 10-minute break, so 12 total hours x 10 minutes = 120 extra minutes for breaks.\nThey also want to include 3 10-minute snack breaks, 3 x 10 minutes = 30 minutes.\nAnd they want to include 30 minutes for lunch each day, so 120 minutes for breaks + 30 minutes for snack breaks + 30 minutes for lunch = 180 minutes, or 180 / 60 minutes per hour = 3 extra hours.\nSo Angelo and Melanie want to plan 12 hours to study + 3 hours of breaks = 15 hours total.\nThey want to study no more than 4 hours each day, 15 hours / 4 hours each day = 3.75\nThey will need to plan to study 4 days to allow for all the time they need.\nThe answer is 4\n\nQuestion: You can buy 4 apples or 1 watermelon for the same price. You bought 36 fruits evenly split between oranges, apples and watermelons, and the price of 1 orange is $0.50. How much does 1 apple cost if your total bill was $66?\nLet's think step by step\nIf 36 fruits were evenly split between 3 types of fruits, then I bought 36/3 = 12 units of each fruit\nIf 1 orange costs $0.50 then 12 oranges will cost $0.50 * 12 = $6\nIf my total bill was $66 and I spent $6 on oranges then I spent $66 - $6 = $60 on the other 2 fruit types.\nAssuming the price of watermelon is W, and knowing that you can buy 4 apples for the same price and that the price of one apple is A, then 1W=4A\nIf we know we bought 12 watermelons and 12 apples for $60, then we know that $60 = 12W + 12A\nKnowing that 1W=4A, then we can convert the above to $60 = 12(4A) + 12A\n$60 = 48A + 12A\n$60 = 60A\nThen we know the price of one apple (A) is $60/60= $1\nThe answer is 1\n\nQuestion: Susy goes to a large school with 800 students, while Sarah goes to a smaller school with only 300 students. At the start of the school year, Susy had 100 social media followers. She gained 40 new followers in the first week of the school year, half that in the second week, and half of that in the third week. Sarah only had 50 social media followers at the start of the year, but she gained 90 new followers the first week, a third of that in the second week, and a third of that in the third week. After three weeks, how many social media followers did the girl with the most total followers have?\nLet's think step by step\nAfter one week, Susy has 100+40 = 140 followers.\nIn the second week, Susy gains 40/2 = 20 new followers.\nIn the third week, Susy gains 20/2 = 10 new followers.\nIn total, Susy finishes the three weeks with 140+20+10 = 170 total followers.\nAfter one week, Sarah has 50+90 = 140 followers.\nAfter the second week, Sarah gains 90/3 = 30 followers.\nAfter the third week, Sarah gains 30/3 = 10 followers.\nSo, Sarah finishes the three weeks with 140+30+10 = 180 total followers.\nThus, Sarah is the girl with the most total followers with a total of 180.\nThe answer is 180"QUESTION = "Question: Josh decides to try flipping a house. He buys a house for $80,000 and then puts in $50,000 in repairs. This increased the value of the house by 150%. How much profit did he make?"llm_lingua = PromptCompressor()compressed_prompt = llm_lingua.compress_prompt( GSM8K_PROMPT.split("\n\n")[0], question = QUESTION, # ratio=0.55 # Set the special parameter for LongLLMLingua condition_in_question = "after_condition", reorder_context = "sort", dynamic_context_compression_ratio = 0.3, # or 0.4 condition_compare = True, context_budget = "+100", rank_method = "longllmlingua",)print('-' * 100)print("original:")print(GSM8K_PROMPT.split("\n\n")[0])print('-' * 100)print("compressed_prompt:")print(compressed_prompt)
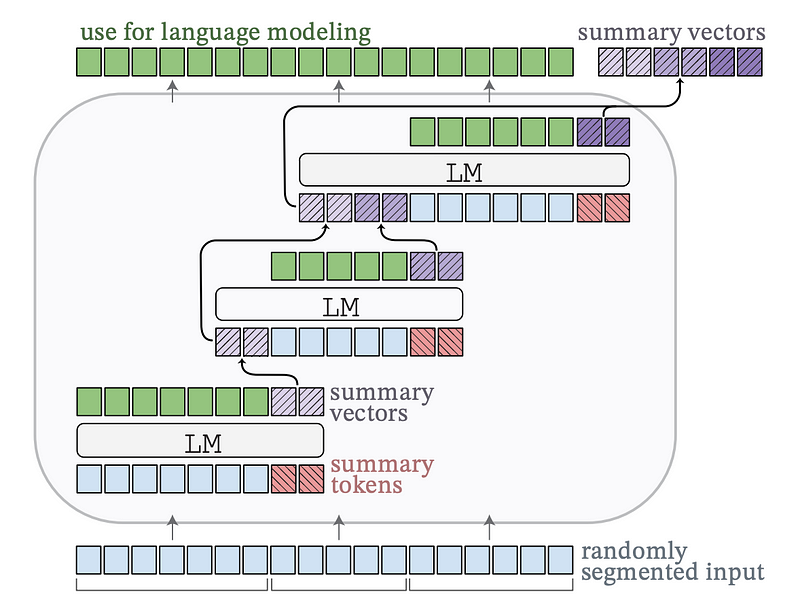
import torchfrom transformers import AutoTokenizerfrom auto_compressor import LlamaAutoCompressorModel, AutoCompressorModel# Load AutoCompressor trained by compressing 6k tokens in 4 compression stepstokenizer = AutoTokenizer.from_pretrained("princeton-nlp/AutoCompressor-Llama-2-7b-6k")# Need bfloat16 + cuda to run Llama model with flash attentionmodel = LlamaAutoCompressorModel.from_pretrained("princeton-nlp/AutoCompressor-Llama-2-7b-6k", torch_dtype=torch.bfloat16).eval().cuda()prompt = 'The first name of the current US president is "'prompt_tokens = tokenizer(prompt, add_special_tokens=False, return_tensors="pt").input_ids.cuda()context = """Joe Biden, born in Scranton, Pennsylvania, on November 20, 1942, had a modest upbringing in a middle-class family. He attended the University of Delaware, where he double-majored in history and political science, graduating in 1965. Afterward, he earned his law degree from Syracuse University College of Law in 1968.\nBiden's early political career began in 1970 when he was elected to the New Castle County Council in Delaware. In 1972, tragedy struck when his wife Neilia and 1-year-old daughter Naomi were killed in a car accident, and his two sons, Beau and Hunter, were injured. Despite this devastating loss, Biden chose to honor his commitment and was sworn in as a senator by his sons' hospital bedsides.\nHe went on to serve as the United States Senator from Delaware for six terms, from 1973 to 2009. During his time in the Senate, Biden was involved in various committees and was particularly known for his expertise in foreign affairs, serving as the chairman of the Senate Foreign Relations Committee on multiple occasions.\nIn 2008, Joe Biden was selected as the running mate for Barack Obama, who went on to win the presidential election. As Vice President, Biden played an integral role in the Obama administration, helping to shape policies and handling issues such as economic recovery, foreign relations, and the implementation of the Affordable Care Act (ACA), commonly known as Obamacare.\nAfter completing two terms as Vice President, Joe Biden decided to run for the presidency in 2020. He secured the Democratic nomination and faced the incumbent President Donald Trump in the general election. Biden campaigned on a platform of unity, promising to heal the divisions in the country and tackle pressing issues, including the COVID-19 pandemic, climate change, racial justice, and economic inequality.\nIn the November 2020 election, Biden emerged victorious, and on January 20, 2021, he was inaugurated as the 46th President of the United States. At the age of 78, Biden became the oldest person to assume the presidency in American history.\nAs President, Joe Biden has worked to implement his agenda, focusing on various initiatives, such as infrastructure investment, climate action, immigration reform, and expanding access to healthcare. He has emphasized the importance of diplomacy in international relations and has sought to rebuild alliances with global partners.\nThroughout his long career in public service, Joe Biden has been recognized for his commitment to bipartisanship, empathy, and his dedication to working-class issues. He continues to navigate the challenges facing the nation, striving to bring the country together and create positive change for all Americans."""context_tokens = tokenizer(context, add_special_tokens=False, return_tensors="pt").input_ids.cuda()summary_vectors = model(context_tokens, output_softprompt=True).softpromptprint(f"Compressing {context_tokens.size(1)} tokens to {summary_vectors.size(1)} summary vectors")# >>> Compressing 660 tokens to 50 summary vectorsgeneration_with_summary_vecs = model.generate(prompt_tokens, do_sample=False, softprompt=summary_vectors, max_new_tokens=12)[0]print("Generation w/ summary vectors:\n" + tokenizer.decode(generation_with_summary_vecs))# >>> The first name of the current US president is "Joe" and the last name is "Biden".next_tokens_without_context = model.generate(prompt_tokens, do_sample=False, max_new_tokens=11)[0]print("Generation w/o context:\n" + tokenizer.decode(next_tokens_without_context))# >>> The first name of the current US president is "Donald" and the last name is "Trump".
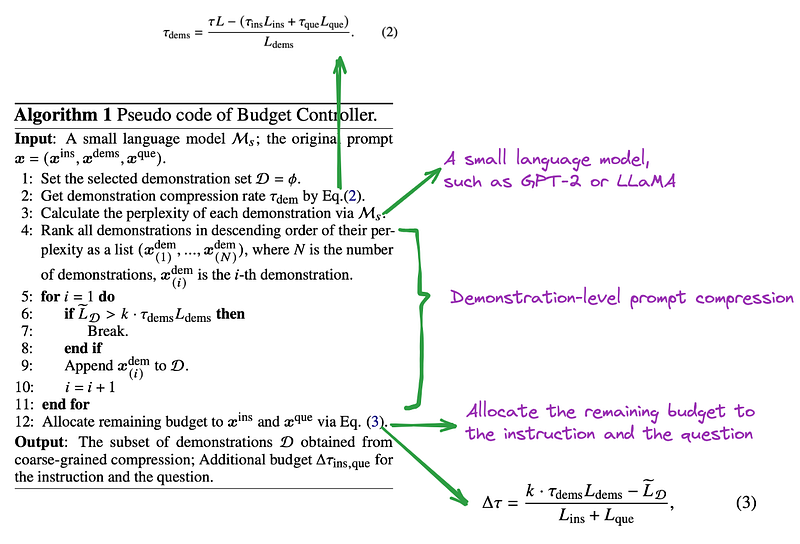
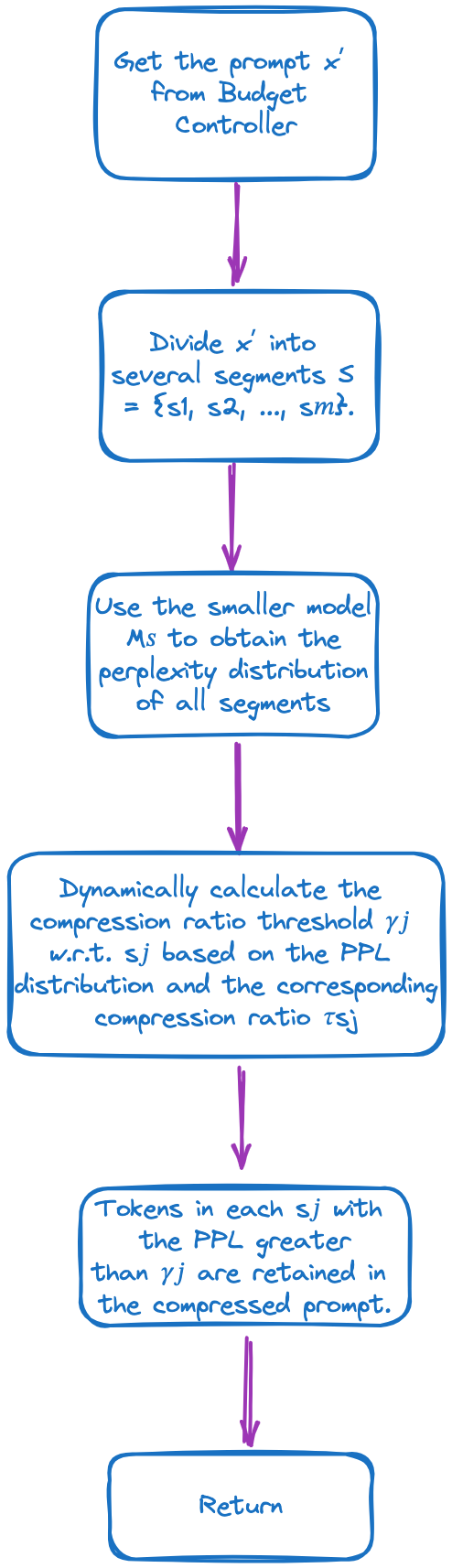
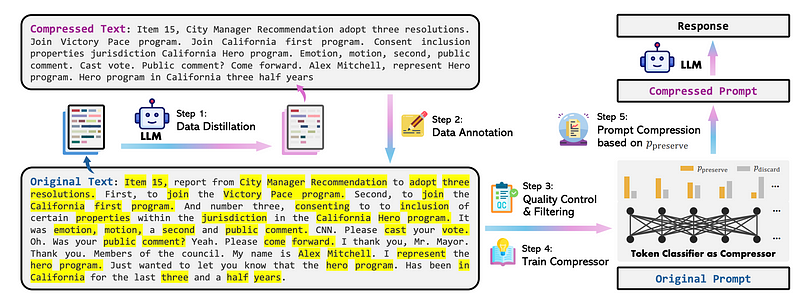
原始提示 x 的压缩策略分为三个步骤。目标压缩率为 1/τ,其中 τ 定义为压缩后的提示语字数与原始提示语 x 的字数之商
确定压缩提示 x˜ 中要保留的目标标记数:N˜ = τN
使用标记分类模型来预测每个词 xi 被标记为 "保留 "的概率 pi
保留原始提示 x 中 pi 值最高的前 N 个词,并保留其原始顺序,形成压缩提示 x˜
code
from llmlingua import PromptCompressorPROMPT = "John: So, um, I've been thinking about the project, you know, and I believe we need to, uh, make some changes. I mean, we want the project to succeed, right? So, like, I think we should consider maybe revising the timeline.\n\nSarah: I totally agree, John. I mean, we have to be realistic, you know. The timeline is, like, too tight. You know what I mean? We should definitely extend it."llm_lingua = PromptCompressor( model_name = "microsoft/llmlingua-2-xlm-roberta-large-meetingbank", use_llmlingua2 = True,)compressed_prompt = llm_lingua.compress_prompt(PROMPT, rate=0.33, force_tokens = ['\n', '?'])## Or use LLMLingua-2-small model# llm_lingua = PromptCompressor(# model_name="microsoft/llmlingua-2-bert-base-multilingual-cased-meetingbank",# use_llmlingua2=True,# )print('-' * 100)print("original:")print(PROMPT)print('-' * 100)print("compressed_prompt:")print(compressed_prompt)
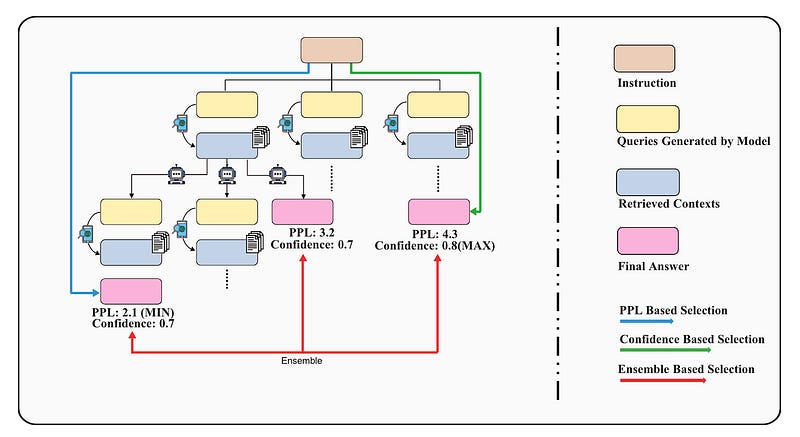
RAPTOR: This is a tree-based retrieval system that recursively embeds, clusters, and summarizes text chunks 这是一个基于树的检索系统,可递归嵌入、聚类和总结文本块
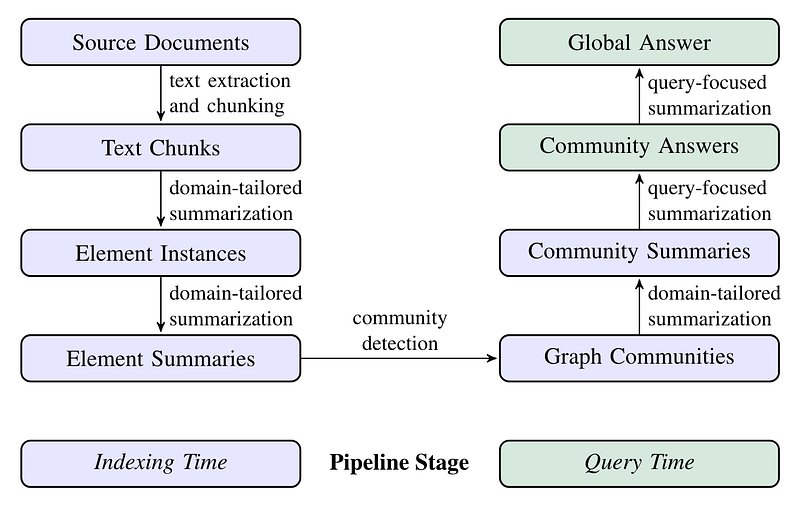
Graph RAG: This method combines knowledge graph generation, community detection, RAG, and Query-Focused Summarization (QFS) to facilitate a comprehensive understanding of the entire text corpus 该方法结合了知识图谱生成、社群检测、RAG 和查询式摘要(QFS),有助于全面了解整个文本语料库
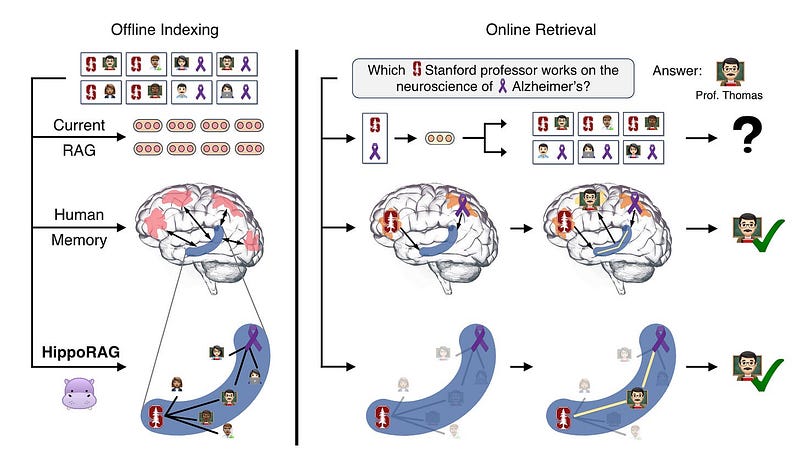
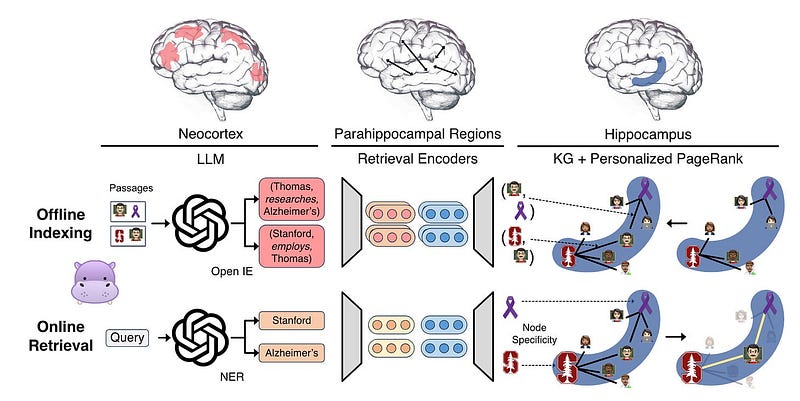
HippoRAG: This retrieval framework draws inspiration from the hippocampal indexing theory of human long-term memory. It collaborates with LLMs, knowledge graphs, and personalized PageRank algorithms 这一检索框架从人类长期记忆的海马索引理论中汲取灵感。它与 LLM、知识图谱和个性化 PageRank 算法协作
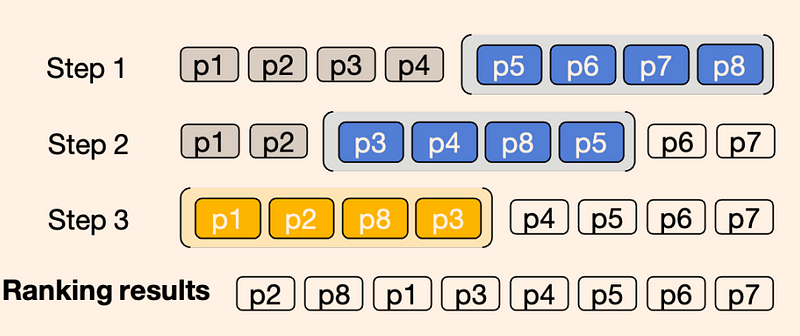
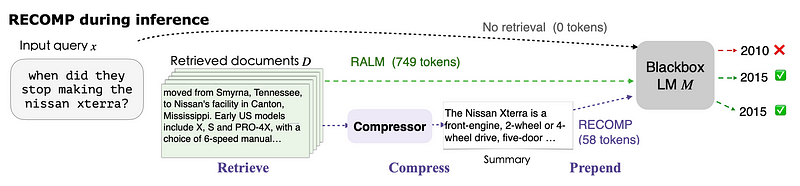
spRAG: This method enhances the performance of the standard RAG system through two key techniques, namely AutoContext and Relevant Segment Extraction (RSE) 该方法通过两项关键技术,即自动上下文和相关片段提取(RSE),提高了标准 RAG 系统的性能
def get_best_segments(all_relevance_values: list[list], document_splits: list[int], max_length: int, overall_max_length: int, minimum_value: float) -> list[tuple]: """ This function takes the chunk relevance values and then runs an optimization algorithm to find the best segments. - all_relevance_values: a list of lists of relevance values for each chunk of a meta-document, with each outer list representing a query - document_splits: a list of indices that represent the start of each document - best segments will not overlap with these Returns - best_segments: a list of tuples (start, end) that represent the indices of the best segments (the end index is non-inclusive) in the meta-document """ best_segments = [] total_length = 0 rv_index = 0 bad_rv_indices = [] while total_length < overall_max_length: # cycle through the queries if rv_index >= len(all_relevance_values): rv_index = 0 # if none of the queries have any more valid segments, we're done if len(bad_rv_indices) >= len(all_relevance_values): break # check if we've already determined that there are no more valid segments for this query - if so, skip it if rv_index in bad_rv_indices: rv_index += 1 continue # find the best remaining segment for this query relevance_values = all_relevance_values[rv_index] # get the relevance values for this query best_segment = None best_value = -1000 for start in range(len(relevance_values)): # skip over negative value starting points if relevance_values[start] < 0: continue for end in range(start+1, min(start+max_length+1, len(relevance_values)+1)): # skip over negative value ending points if relevance_values[end-1] < 0: continue # check if this segment overlaps with any of the best segments if any(start < seg_end and end > seg_start for seg_start, seg_end in best_segments): continue # check if this segment overlaps with any of the document splits if any(start < split and end > split for split in document_splits): continue # check if this segment would push us over the overall max length if total_length + end - start > overall_max_length: continue segment_value = sum(relevance_values[start:end]) # define segment value as the sum of the relevance values of its chunks if segment_value > best_value: best_value = segment_value best_segment = (start, end) # if we didn't find a valid segment, mark this query as done if best_segment is None or best_value < minimum_value: bad_rv_indices.append(rv_index) rv_index += 1 continue # otherwise, add the segment to the list of best segments best_segments.append(best_segment) total_length += best_segment[1] - best_segment[0] rv_index += 1 return best_segments