
RAG
RAG 相关内容
Retrieval-Augmented Generation 检索增强生成
深入理解LLM RAG检索生成
https://www.bilibili.com/read/cv29676672/
大语言模型的问题
- 偏见
- 幻觉(信息可信度)
- 过时(时效性)
大语言模型的知识来源
- 训练的知识
- 用户的输入
- 外部索引、知识库
外挂数据
- 外部向量数据库
- 外部知识图谱
- 文档数据
- WEB数据等
经过Doc Loader,加载各种数据源的数据,经过embedding向量化后存储进向量数据库。这是Retrieval-augmented基础数据处理器。用户通过 QA向LLM提问,会通过QA问题向向量数据库召回相似度较高的上下文,通过Prompt提示词一起发给LLM,LLM通过问题与上下文一起生成答案返回给用户
RAG实现
数据加载(Document Loaders)
langchain\_community.document\_loaders
数据处理(Text Splitters)
数据分割
加载完数据后,下一步通常需要将数据进行拆分,尤其是在处理长文本的情况下。如何将文本进行分割处理,听起来很简单,比如我按400个字符,直接切片就好了,但往往这样应用效果不甚理想
通常希望能将将语义相关的文本片段保留在一起。 重点其实就在这个“语义相关”,比如中文,希望是句号为分割符,比如一段长代码,希望以编程语言特点来分割,比如Python中的def、class
以langchain为例,langchain目前支持HTML、字符、MarkdownHeader和多种代码分割,甚至正在实验中的语义分割
- 按MarkdownHeader分割
from langchain.text_splitter import MarkdownHeaderTextSplitter
markdown_document = "# Foo\n\n ## Bar\n\nHi this is Jim\n\nHi this is Joe\n\n ### Boo \n\n Hi this is Lance \n\n ## Baz\n\n Hi this is Molly"
headers_to_split_on = [
("#", "Header 1"),
("##", "Header 2"),
("###", "Header 3"),
]
markdown_splitter = MarkdownHeaderTextSplitter(headers_to_split_on=headers_to_split_on)
md_header_splits = markdown_splitter.split_text(markdown_document)
md_header_splits
{'content': 'Hi this is Jim \nHi this is Joe', 'metadata': {'Header 1': 'Foo', 'Header 2': 'Bar'}}
{'content': 'Hi this is Molly', 'metadata': {'Header 1': 'Foo', 'Header 2': 'Baz'}}- metadata
在进行文本分割的同时,还可以给分割的文本添加一下metadata的数据,方便记录该文本段的一些基本信息,如文章来源、作者信息等。
一个是能在进行文本召回时可以作为过滤搜索,另一方面还在作为发给LLM的补充数据,让LLM生成的内容更为丰富
metadatas = [{"document": 1}, {"document": 2}]
documents = text_splitter.create_documents([state_of_the_union, state_of_the_union], metadatas=metadatas) print(documents[0])2.2.3 分割参数
在进行文本分割时,还需要重点关注两个参数 chunk_size 和 chunk_overlap,这两个参数分别表示分割长度和两段分割文本重合长度。
在实际RAG应用中,chunk_size需要结合向量数据库的来选择合适大小,比如腾讯云的向量数据库,一次只支持单块512token(400左右字符)的大小写入,那chunk_size就应该设设置400多。chunk_overlap的大小建议设置在chunk_size的1/5左右,在召回多段文本时,可以增加数据的丰富度。
实际情况请结合具体项目进行设置和测试验证
2.3 数据向量化 (Text embedding models)
在进行数据分割后,需要对文本数据段进行向量化,目前主流的中文向量化模型有

使用OpenAI Embeddings向量化处理
from langchain_openai import OpenAIEmbeddings
embeddings_model = OpenAIEmbeddings(openai_api_key="...")
embeddings = embeddings_model.embed_documents(
[
"Hi there!",
"Oh, hello!",
"What's your name?",
"My friends call me World",
"Hello World!"
]
)
len(embeddings), len(embeddings[0])
(5, 1536)目前Langchain支持37种embedding model,这些向量化模型核心功能就将文本向量化,提供给向量数据库进行存储
2.4 向量数据库 (Vector stores)
2.5 数据召回(Retrievers)
在讲解完数据加载、数据处理、数据向量化和向量数据库后,开始进入数据召回的环节。数据召回是向 LLM提问时,需要根据提问的问题向向量数据库召回相关的文档数据,并和问题加载进Prompt发送给LLM
比如下面这段提示词:
template = """
Answer the question based only on the following context:
{context}
Question: {question}
"""context就是召回的上下文
数据召回的方法有许多种,应用在不同应用场景,当前Langchain主流支持的Retrievers有以下8种
这里简述一下不同Retrievers的主要应用场景,大家可以具体问题具体分析,再去查阅一下相关文档
- Vectorstore 基础的向量召回方法,根据用户问题直接向向量数据库召回数据
- ParentDocument 如果你文档数据有许多不同的小块信息,你可以根据问题检索出小块信息,再根据小块信息去索引出原文档或者更大块的数据,将大块数据作为上下文发送给LLM
- Multi Vector 如果你有相关问题的数据集,可以为问题和文档分别存储到不同的向量数据库,在检索时可以根据问题检索出合适文档上下文
- Self Query 如果你提出的问题可以通过基于元数据(而不是与文本的相似性)来获取文档,可以使用这种Retrievers,利用LLM的能力,自动生成对应的检索方法,来召回数据
- Contextual Compression 如果您发现您检索的文档包含太多不相关的信息,并且分散了LLM的注意力,可以利用上下文压缩的方法,将召回的数据利用LLM进行数据处理
- Time-Weighted Vectorstore 如果你的文档数据中包含时间相关的数据,可以考虑用此Retriever
- Multi-Query Retriever 用户提出的问题很复杂,需要多个不同的信息来回答,可以使用此Retriever,利用LLM生成多个相关的问题,再分别从向量数据库召回数据
- Ensemble 如果您有多种检索方法,并希望尝试将它们组合起来,可以使用此Retriever
- Long-Context Reorder 当你需要召回多段上下文数据时,但发现LLM并没有根据你的上下文来回答问题时,可以考虑使用 Retriever对你召回的数据进行重新排序,将相似度较高的排在前面,让LLM能更好的利用上下文来回答问题
2.5.1 数据召回算法
在数据召回中,目前业内有两种较为通用的召回算法
- 相似度匹配算法(Similarity Search with Euclidean Distance)
这是向量数据库自身具备的特点,通过比较向量之间的距离来判断它们的相似度
COLLECTION_NAME = "state_of_the_union_test"
db = PGVector.from_documents(
embedding=embeddings,
documents=docs,
collection_name=COLLECTION_NAME,
connection_string=CONNECTION_STRING,
)
query = "What did the president say about Ketanji Brown Jackson"
docs_with_score = db.similarity_search_with_score(query)
for doc, score in docs_with_score:
print("-" * 80)
print("Score: ", score)
print(doc.page_content)
print("-" * 80)- 最大边界相关算法(Maximal Marginal Relevance)
采用这个算法,会优化召回的数据段之间的相似程度和多样性,对数据重新打分
docs_with_score = db.max_marginal_relevance_search_with_score(query)
for doc, score in docs_with_score:
print("-" * 80)
print("Score: ", score)
print(doc.page_content)
print("-" * 80)算法Python实现
def maximal_marginal_relevance(
query_embedding: np.ndarray,
embedding_list: list,
lambda_mult: float = 0.5,
k: int = 4,
) -> List[int]:
"""Calculate maximal marginal relevance."""
if min(k, len(embedding_list)) <= 0:
return []
if query_embedding.ndim == 1:
query_embedding = np.expand_dims(query_embedding, axis=0)
similarity_to_query = cosine_similarity(query_embedding, embedding_list)[0]
most_similar = int(np.argmax(similarity_to_query))
idxs = [most_similar]
selected = np.array([embedding_list[most_similar]])
while len(idxs) < min(k, len(embedding_list)):
best_score = -np.inf
idx_to_add = -1
similarity_to_selected = cosine_similarity(embedding_list, selected)
for i, query_score in enumerate(similarity_to_query):
if i in idxs:
continue
redundant_score = max(similarity_to_selected[i])
equation_score = (
lambda_mult * query_score - (1 - lambda_mult) * redundant_score
)
if equation_score > best_score:
best_score = equation_score
idx_to_add = i
idxs.append(idx_to_add)
selected = np.append(selected, [embedding_list[idx_to_add]], axis=0)
return idxs代码功能:
该代码定义了一个名为 maximal_marginal_relevance 的函数,用于实现 MMR 算法。
它接受以下参数:
query_embedding: 查询的嵌入表示(向量形式)。
embedding_list: 待选句子的嵌入表示列表。
lambda_mult: 用于权衡相关性和多样性的参数(0-1 之间)。
k: 要选择的句子数量。
它返回一个整数列表,表示选出的句子索引。
算法步骤:
初始化:
处理边界情况:如果 k 或 embedding_list 长度为 0 或更小,则直接返回空列表。
如果 query_embedding 是 1 维向量,则扩展其维度以适应余弦相似度计算。
计算每个句子与查询的余弦相似度。
选择与查询最相似的句子作为初始句子,并记录其索引。
迭代选择句子:
循环直到选出 k 个句子或所有句子都被考虑:
初始化当前最佳分数为负无穷大。
计算剩余每个句子与已选句子集的最大相似度(代表冗余程度)。
使用 MMR 公式计算每个句子的综合得分: equation_score = lambda_mult * query_score - (1 - lambda_mult) * redundant_score
选择得分最高的句子,并记录其索引。
将选中的句子加入已选集合。
返回结果:
返回所有选中句子的索引列表https://www.anyscale.com/blog/a-comprehensive-guide-for-building-rag-based-llm-applications-part-1
构建基于RAG的LLM生产应用程序
加载数据
Ray Dataset
https://docs.ray.io/en/master/ray-overview/index.html
Raydataset 是一个开源的 Python 库,用于构建和管理大型分布式数据集。它基于 Ray 框架,可以利用 Ray 的并行计算能力来加速数据集的加载、处理和查询
Raydataset 的主要功能包括:
- 支持多种数据格式,包括 CSV、JSON、TFRecord 等
- 支持多种数据加载方式,包括本地加载、远程加载、流式加载等
- 支持多种数据处理方式,包括数据过滤、数据转换、数据聚合等
- 支持多种数据查询方式,包括随机查询、范围查询、全文搜索等
Raydataset 可以应用于各种场景,例如:
- 机器学习:用于训练和评估机器学习模型
- 自然语言处理:用于处理和分析自然语言数据
- 图像处理:用于处理和分析图像数据
- 数据分析:用于分析和挖掘数据
分块
def chunk_section(section, chunk_size, chunk_overlap):
text_splitter = RecursiveCharacterTextSplitter(
separators=["\n\n", "\n", " ", ""],
chunk_size=chunk_size,
chunk_overlap=chunk_overlap,
length_function=len)
chunks = text_splitter.create_documents(
texts=[sample_section["text"]],
metadatas=[{"source": sample_section["source"]}])
return [{"text": chunk.page_content, "source": chunk.metadata["source"]} for chunk in chunks]向量化
class EmbedChunks:
def __init__(self, model_name):
if model_name == "text-embedding-ada-002":
self.embedding_model = OpenAIEmbeddings(
model=model_name,
openai_api_base=os.environ["OPENAI_API_BASE"],
openai_api_key=os.environ["OPENAI_API_KEY"])
else:
self.embedding_model = HuggingFaceEmbeddings(
model_name=model_name,
model_kwargs={"device": "cuda"},
encode_kwargs={"device": "cuda", "batch_size": 100})
def __call__(self, batch):
embeddings = self.embedding_model.embed_documents(batch["text"])
return {"text": batch["text"], "source": batch["source"], "embeddings":
embeddings}embedding_model_name = "thenlper/gte-base"
存储
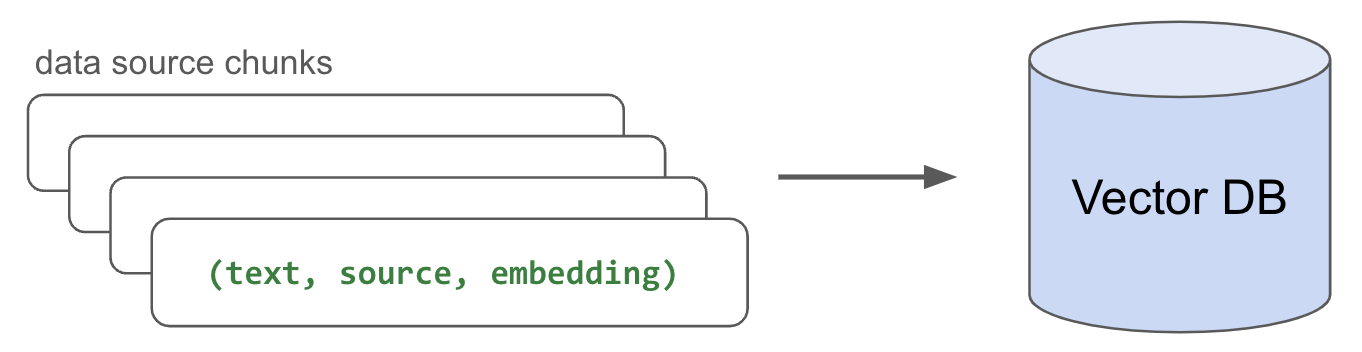 pgvector
pgvector
text, source, embedding
问题检索

问题向量化 -> 检索TopK
生成回答
使用了0.0的温度来进行可重复的实验,但你应该根据你的使用情况来调整。对于需要始终以事实为基础的用例,推荐非常低的温度值,而更多的创造性任务可以从更高的温度中获益
query = "What is the default batch size for map_batches?"
response = generate_response(
llm="meta-llama/Llama-2-70b-chat-hf"
temperatune=0. 0,
stream=True,
system_content="Answer the query using the context provided. Be succinct.",简明扼要
user_content=f"query: {query}, context: (context)")Agent
写到了一个函数里
Evaluation
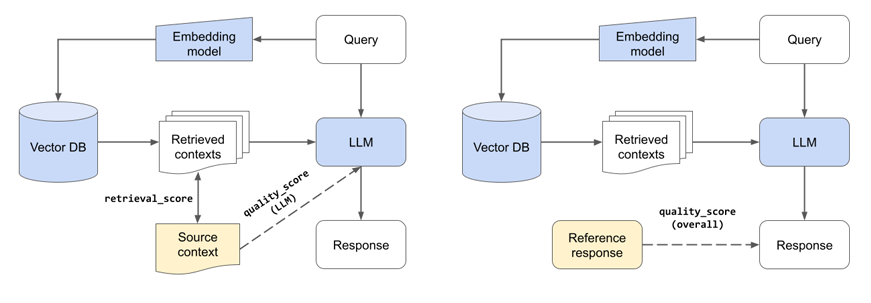
LLM Experiments
Embedding models
["thenlper/gte-base", "thenlper/gte-large", "BAAI/bge-large-en", "text-embedding-ada-002"]
这是一个有趣的结果,因为当前排行榜上的第一名(BAAI/bge large en)不一定是特定任务的最佳人选。在的实验中,使用较小的lper/gte-large产生了最好的检索和质量分数
OSS vs. closed LLMs
llms = ["gpt-3.5-turbo",
"gpt-4",
"gpt-4-1106-preview",
"meta-llama/Llama-2-7b-chat-hf",
"meta-llama/Llama-2-13b-chat-hf",
"meta-llama/Llama-2-70b-chat-hf",
"codellama/CodeLlama-34b-Instruct-hf",
"mistralai/Mistral-7B-Instruct-v0.1",
"mistralai/Mixtral-8x7B-Instruct-v0.1"]Note: Some of our LLMs have much larger context lengths, ex. gpt-4 is 8,192 tokens and gpt-3.5-turbo-16k is 16,384 tokens. We could increase the number of chunks that we use for these since we saw that increasing num_chunks continued to improve the retrieval and quality scores. However, we will keep this value fixed for now since the performance started to taper off anyway and so we can compare these performances under the exact same configurations.
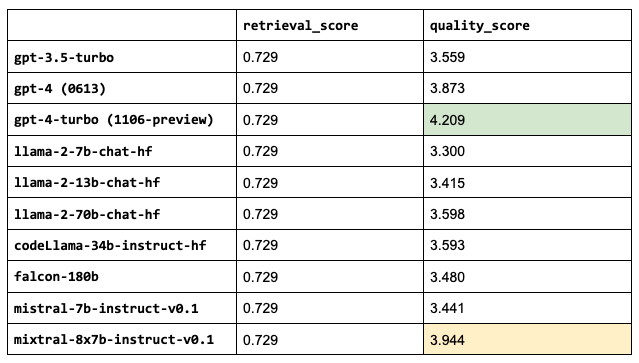
注意:的一些LLM具有更大的上下文长度,例如gpt-4是8192个令牌,gpt-3.5-turb-16k是16384个令牌。可以增加用于这些的块的数量,因为看到增加num_chunk可以继续提高检索和质量分数。然而,由于性能开始逐渐下降,暂时将保持该值不变,因此可以在完全相同的配置下比较这些性能
Fine-tuning
Prompt engineering
当涉及到设计提示时,可以做的太多了(思考的x、多模式、自我精炼、查询分解等),所以只尝试一些有趣的想法。将允许LLM忽略任何不相关的内容。这里的想法是展示从即时工程到评估报告的速度有多快
# Prompt
generation_system_content = "Answer the query using the context provided. Be succinct. Contexts are organized in a list of dictionaries [{'text': <context>}, {'text': <context>}, ...]. Feel free to ignore any contexts in the list that don't seem relevant to the query. "
# Evaluate
experiment_name = "prompt-ignore-contexts"
run_experiment(
experiment_name=experiment_name,
generation_system_content=generation_system_content, # new prompt
kwargs)这种具体的快速工程努力似乎无助于提高系统的质量。正如前面提到的,有太多其他方法可以设计的提示,鼓励您探索更多。这里重要的是,有一种干净简单的方法来评估想要实验的任何东西。然而,根据经验发现,提高的检索系统和数据飞轮(修复文档本身的地方)的质量对系统的整体质量产生了更大的影响
Lexical search 词汇搜索
现在,将用传统的词汇搜索来补充基于矢量嵌入的搜索,该搜索在查询和文档块之间搜索精确的标记匹配。的直觉是,词汇搜索可以帮助识别具有精确关键字匹配的块,而语义表示可能无法捕捉到这些块。特别是对于的嵌入模型中词汇表之外的标记(因此通过子标记表示)。但基于嵌入的方法对于捕捉隐含含义仍然非常有利,因此将结合基于矢量嵌入的搜索和词汇搜索中的几个检索块
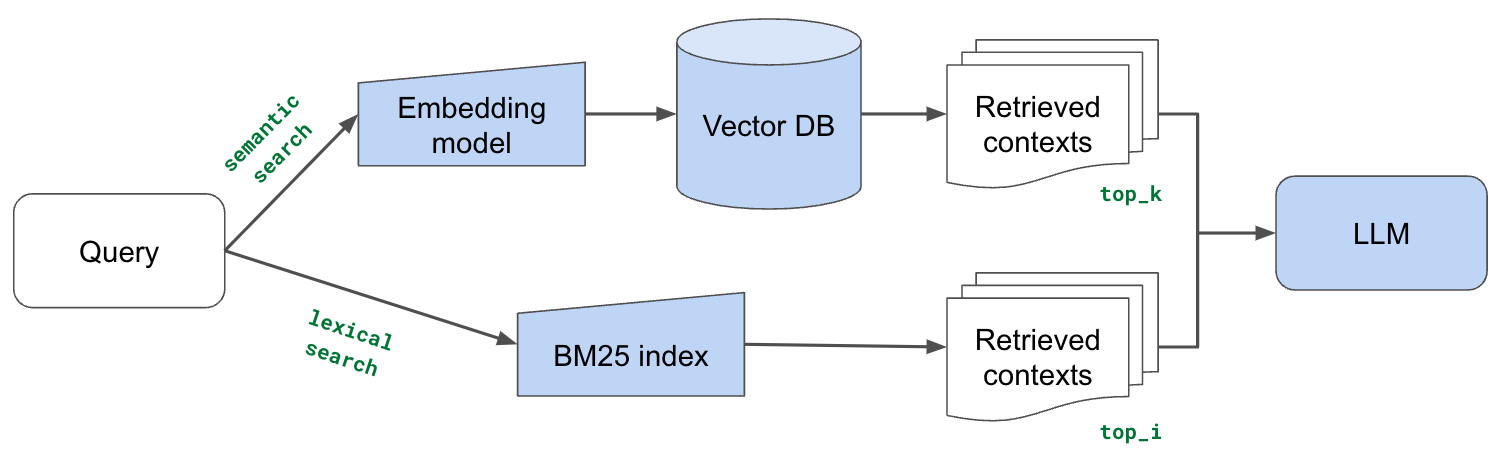
BM25
将其与检索到的源与现有的基于向量嵌入的搜索进行比较表明,这两种方法虽然不同,但都检索到了相关的源。因此,将把这两种方法结合起来,并将其输入到的LLM生成的上下文中
添加词汇搜索似乎没有希望的那么有影响力,但这只是探索的词汇搜索的一个方面(关键词匹配),但还有许多其他有用的功能,如过滤、计数等。还值得探索如何将词汇搜索结果与语义搜索结果相结合
Reranking
到目前为止,在所有的方法中,都使用了嵌入模型(+词汇搜索)来识别数据集中前k个相关的块。块的数量(k)一直是一个小数字,因为发现添加太多块没有帮助,而且的LLM限制了上下文长度。然而,这一切都是在假设前k个检索到的块确实是最相关的块,并且它们的顺序也是正确的。如果增加块的数量没有帮助,因为一些相关的块在有序列表中要低得多。而且,语义表示虽然非常丰富,但并没有针对这一特定任务进行训练。
在本节中,实现了重新排序,这样就可以使用语义和词汇搜索方法在数据集上撒下更大的网(检索许多块),然后根据用户的查询重新排序。这里的直觉是,可以通过特定于用例的排名来解释语义表示中的差距。将训练一个监督模型,该模型预测文档的哪一部分与给定用户的查询最相关。将使用这个预测来重新排列相关的块,以便将文档中这一部分的块移到列表的顶部
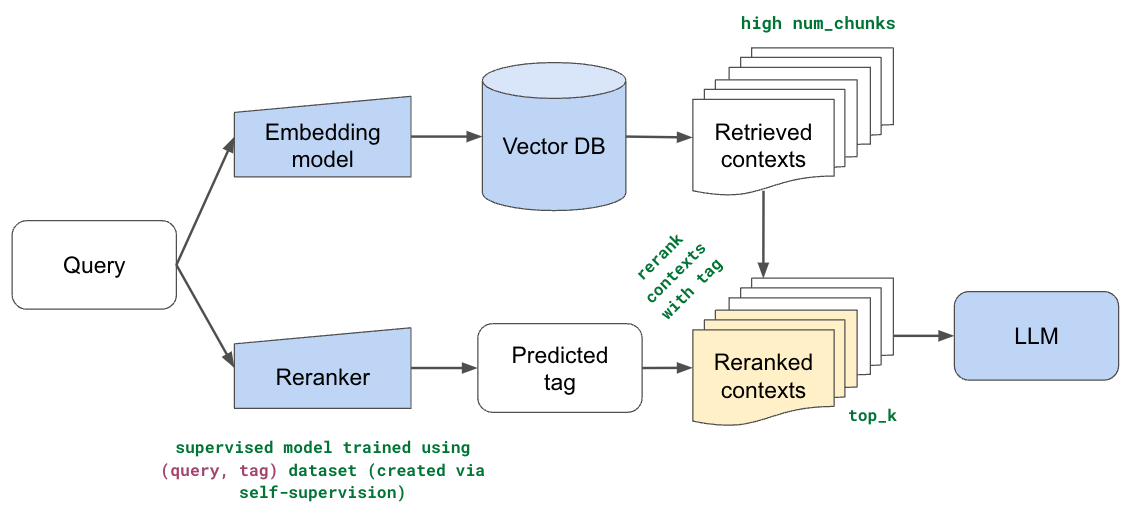
RAG中文基准 CRUD-RAG
https://arxiv.org/abs/2401.17043
• Chunk size: 64, 128, 256, 512.
• Chunk overlap: 0%, 10%, 30%, 50%, 70%.
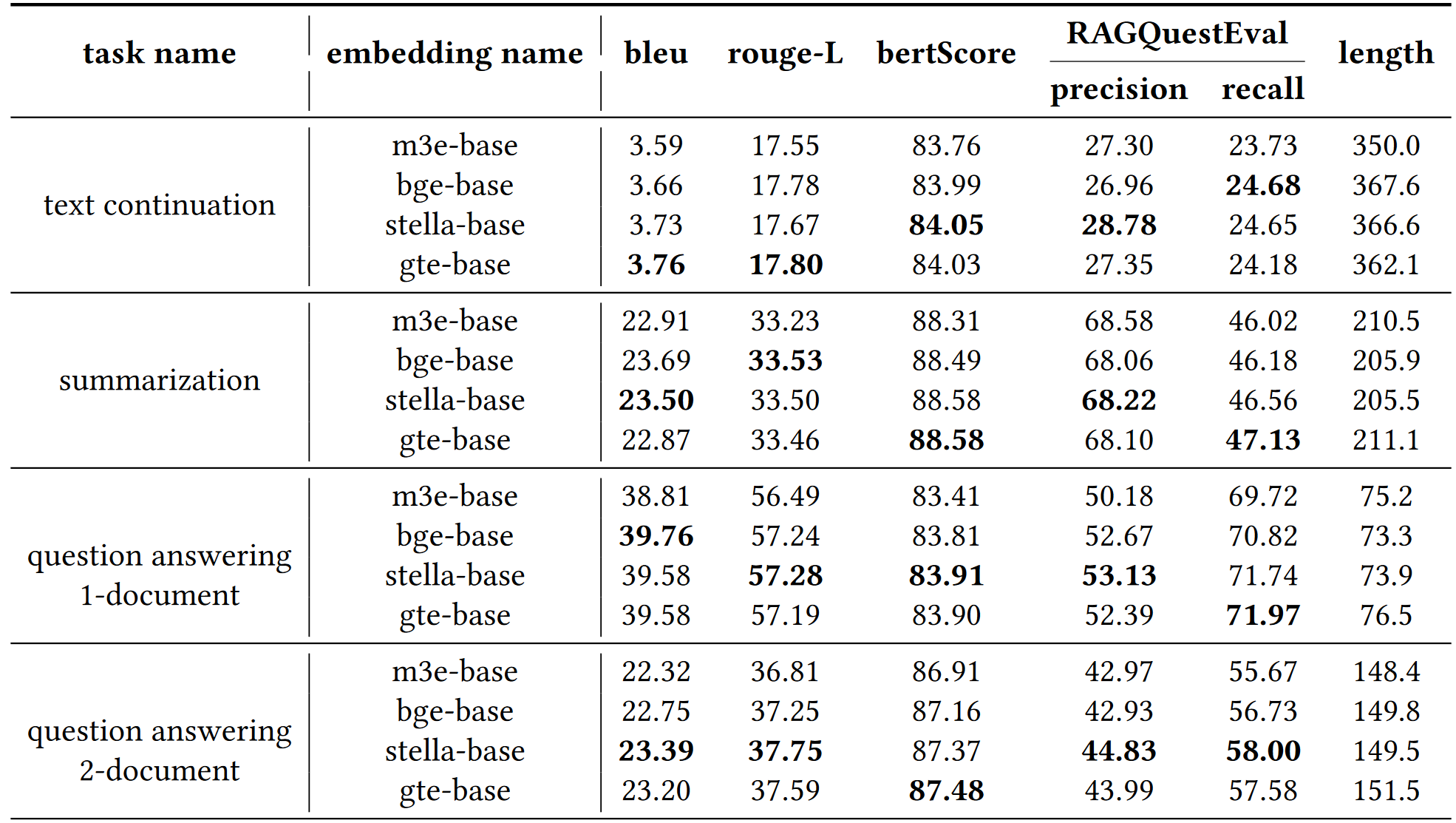
• Embedding model: m3e-base, bge-base, stella-base, gte-base.
• Retriever: dense, bm25, hybrid, hybrid+rerank. • Top-k: 2, 4, 6, 8, 10.
• Base LLMs: GPT-3.5, GPT-4, ChatGLM2-6B, Baichuan2-13B, Qwen-7B, Qwen-14B.
4.2 块大小对RAG性能的影响:
- 实验结果表明,在文本续写任务中,较大的块大小可以显著提高整体语义相似性指标(如BLEU、ROUGE、BERTScore)和RAGQuestEval指标,这表明较大的块有助于保持原文的结构,对于创造性任务尤为重要
- 在多文档摘要任务中,较大的块大小虽然增加了生成文本的长度,但也可能导致BLEU分数的显著下降,而ROUGE-L和BERTScore保持相对稳定
4.3 块重叠对RAG性能的影响:
- 在文本续写任务中,随着块重叠的增加,生成文本与参考答案的对齐度(BLEU、ROUGE、BERTScore)显著提高,RAGQuestEval指标也有所改善
- 在多文档摘要任务中,所有评估指标都随着块重叠的增加而略有提高,尤其是在召回率方面
4.4 检索器对RAG性能的影响:
- 文本续写任务中,密集检索器(Dense retriever)优于基于关键词的BM25检索器,因为密集检索器能够捕捉到更多的语义和上下文信息
- 在多文档摘要任务中,BM25检索器在整体语义相似性指标上表现更好,但在关键信息的精确度上,密集检索器更优
检索器
在RAG(Retrieval-Augmented Generation)系统中,检索器(Retriever)是一个关键组件,其主要功能是根据用户的输入(如问题或查询)从外部知识库或文档集合中检索出最相关的信息片段或文档。这些检索到的信息随后被用作大型语言模型(LLM)生成回答的上下文或辅助信息
检索器的工作原理通常涉及以下几个步骤:
- 查询处理:接收用户的输入并将其转换为适合检索的格式,这可能包括分词、去除停用词、词干提取等预处理步骤
- 相似度计算:使用特定的算法(如TF-IDF、BM25、密集向量检索等)来计算用户查询与知识库中每个文档的相似度得分
- 排名和选择:根据相似度得分对文档进行排序,并选择得分最高的前k个文档作为检索结果。这里的k值(Top-k)是一个重要的参数,决定了提供给LLM的上下文信息量
- 上下文生成:将检索到的文档片段或整个文档作为上下文信息,与用户的输入一起输入到LLM中,以生成最终的回答
检索器在RAG系统中的作用至关重要,因为它直接影响到LLM生成回答的质量和准确性。一个高效的检索器能够快速准确地找到与用户查询最相关的信息,从而提高整个系统的性能。在实际应用中,检索器可能需要根据特定的应用场景进行优化,以确保检索结果的相关性和多样性
BM25(BM25 Retrieval):
- BM25是一种基于概率的排名函数,用于信息检索系统中的文档检索。它是由Brett M. Carter和Stephen T. Robertson在1992年提出的,旨在模拟用户在搜索引擎中输入查询时,文档与查询的相关性
- BM25考虑了查询词在文档中的频率(TF)以及在整个文档集合中的逆文档频率(IDF),以此来计算查询词与文档之间的相关性得分
- BM25的优点是计算简单且高效,但它主要基于关键词的频率,可能无法充分捕捉到文档的语义信息
Dense(Dense Retrieval):
- Dense检索器使用深度学习模型(如BERT、GPT等)将文档和查询转换为高维向量表示。然后,通过计算这些向量之间的相似度(如余弦相似度)来确定文档的相关性
- Dense检索器能够捕捉到文档的深层语义信息,因为它利用了预训练语言模型对文本的理解能力。这使得Dense检索器在处理需要理解上下文和语义的任务时表现更好
- 然而,Dense检索器的计算成本较高,因为它依赖于复杂的神经网络模型
Hybrid(Hybrid Retrieval):
- Hybrid检索器结合了BM25和Dense检索器的优点。它首先使用BM25检索器快速筛选出一批候选文档,然后使用Dense检索器对这些文档进行更精细的语义相关性排序
- Hybrid检索器旨在平衡检索速度和准确性。通过BM25的快速筛选,可以减少Dense检索器需要处理的文档数量,从而降低整体的计算成本,同时保持较高的检索质量
4.5 嵌入模型对RAG性能的影响:
- 在创造性任务如文本续写中,不同嵌入模型之间的性能差异较小,但在需要精确定位相关文档的问答任务中,m3e-base模型表现最差
- 对于幻觉修改任务,m3e-base模型在所有指标上表现最好,这表明它在纠正文本中的错误方面更有效
4.6 Top-k值对RAG性能的影响:
- 在文本续写任务中,增加Top-k值可以提高生成文本的多样性和准确性
- 在多文档摘要任务中,增加Top-k值会导致更长但质量较低的摘要,而在问答任务中,增加Top-k值可以提高召回率和精确度
4.7 LLM对RAG性能的影响:
- 在文本续写和多文档摘要任务中,模型参数越大,性能越好,GPT-4模型在所有任务中表现最佳
- 在单文档问答任务中,Qwen和Baichuan2模型在某些情况下表现优于GPT系列模型,而在多文档问答任务中,GPT-4模型表现出色
4.8 优化RAG系统的建议:
- 文章根据实验结果提供了关于如何优化RAG系统性能的建议,包括选择合适的Top-k值、块大小、块重叠、嵌入模型、检索器和LLM
Table 6. The experimental results for evaluating different embedding models in our benchmark.
网易 QAnything
https://github.com/netease-youdao/QAnything
致力于支持任意格式文件或数据库的本地知识库问答系统,可断网安装使用
目前已支持格式: PDF(pdf),Word(docx),PPT(pptx),XLS(xlsx),Markdown(md),电子邮件(eml),TXT(txt),图片(jpg,jpeg,png),CSV(csv),网页链接(html)
特点
- 数据安全,支持全程拔网线安装使用
- 支持跨语种问答,中英文问答随意切换,无所谓文件是什么语种
- 支持海量数据问答,两阶段向量排序,解决了大规模数据检索退化的问题,数据越多,效果越好
- 高性能生产级系统,可直接部署企业应用
- 易用性,无需繁琐的配置,一键安装部署,拿来就用
- 支持选择多知识库问答
架构
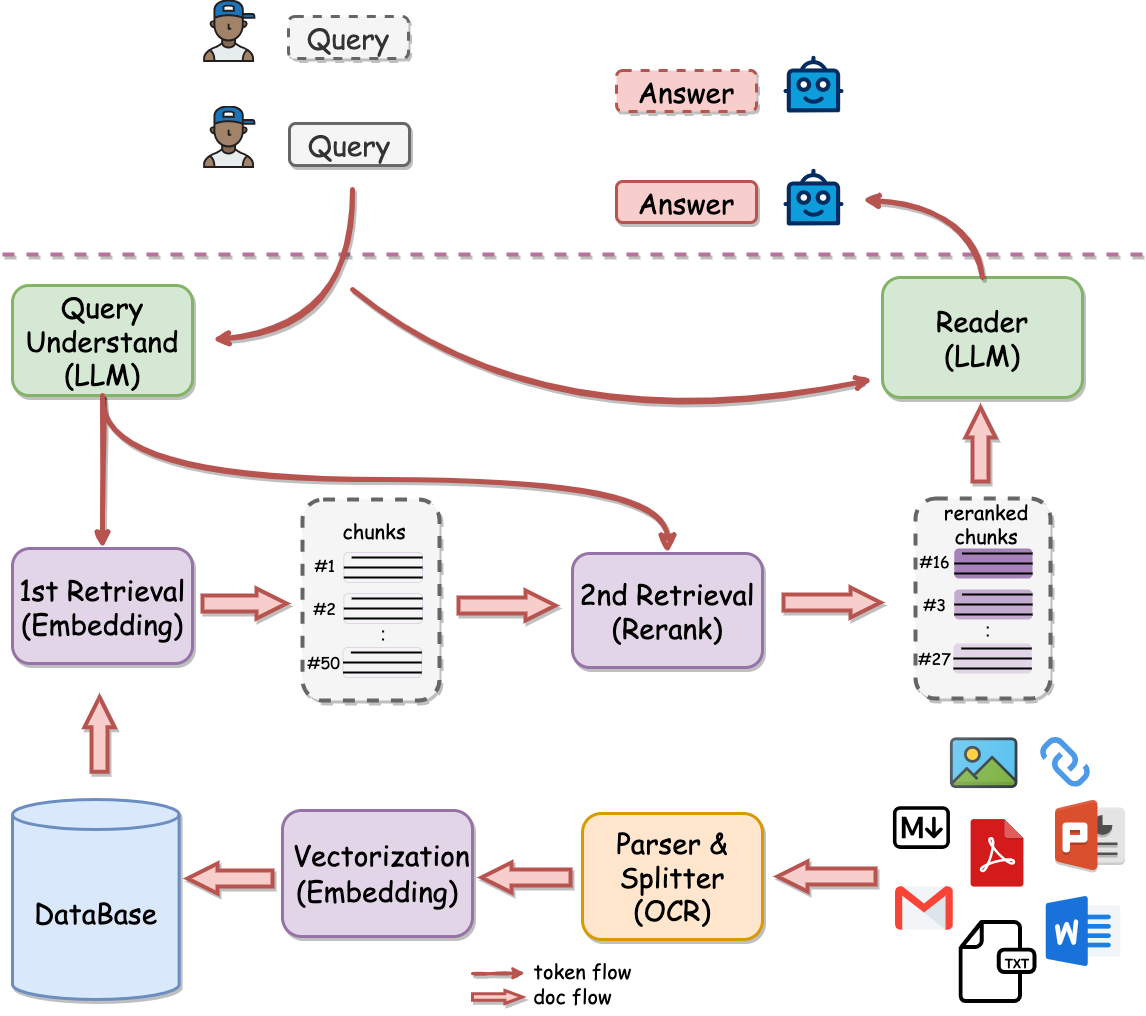
知识库数据量大的场景下两阶段优势非常明显,如果只用一阶段embedding检索,随着数据量增大会出现检索退化的问题,如下图中绿线所示,二阶段rerank重排后能实现准确率稳定增长,即数据越多,效果越好
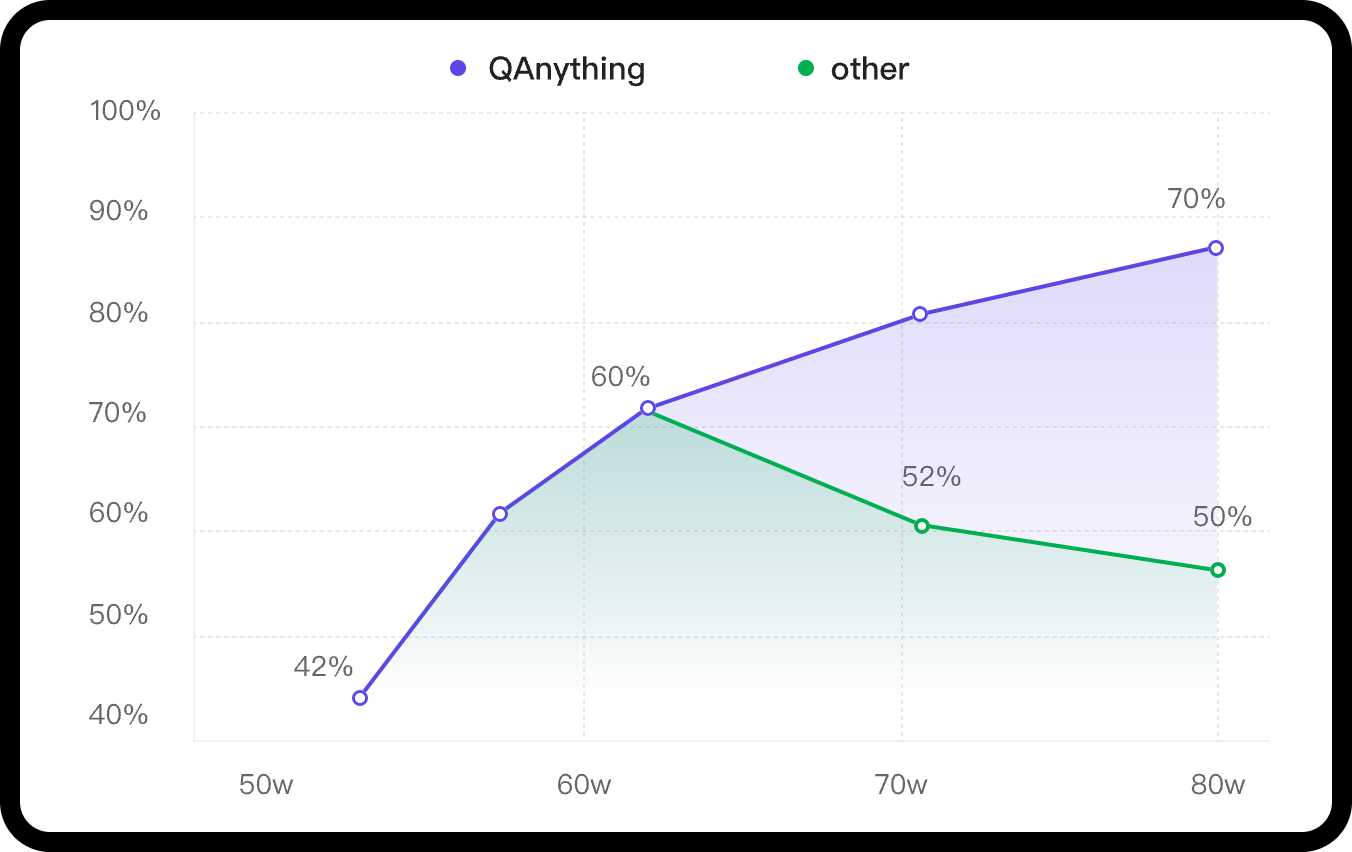
一阶段检索(embedding)
| 模型名称 | Retrieval | STS | PairClassification | Classification | Reranking | Clustering | 平均 |
|---|---|---|---|---|---|---|---|
| bge-base-en-v1.5 | 37.14 | 55.06 | 75.45 | 59.73 | 43.05 | 37.74 | 47.20 |
| bge-base-zh-v1.5 | 47.60 | 63.72 | 77.40 | 63.38 | 54.85 | 32.56 | 53.60 |
| bge-large-en-v1.5 | 37.15 | 54.09 | 75.00 | 59.24 | 42.68 | 37.32 | 46.82 |
| bge-large-zh-v1.5 | 47.54 | 64.73 | 79.14 | 64.19 | 55.88 | 33.26 | 54.21 |
| jina-embeddings-v2-base-en | 31.58 | 54.28 | 74.84 | 58.42 | 41.16 | 34.67 | 44.29 |
| m3e-base | 46.29 | 63.93 | 71.84 | 64.08 | 52.38 | 37.84 | 53.54 |
| m3e-large | 34.85 | 59.74 | 67.69 | 60.07 | 48.99 | 31.62 | 46.78 |
| bce-embedding-base_v1 | 57.60 | 65.73 | 74.96 | 69.00 | 57.29 | 38.95 | 59.43 |
二阶段检索(rerank)
| 模型名称 | Reranking | 平均 |
|---|---|---|
| bge-reranker-base | 57.78 | 57.78 |
| bge-reranker-large | 59.69 | 59.69 |
| bce-reranker-base_v1 | 60.06 | 60.06 |
开源版本QAnything的大模型基于通义千问,并在大量专业问答数据集上进行微调;在千问的基础上大大加强了问答的能力。 如果需要商用请遵循千问的license,具体请参阅:通义千问
😄😄😄
Active Retrieval Augmented Generation
arXiv:2305.06983v2 [cs.CL] 22 Oct 2023
提出了两种前瞻性主动检索增强生成(FLARE)方法来实现主动检索增强生成框架。第一种方法在生成答案时使用检索鼓励指令,促使LMs生成检索查询,称为FLAREinstruct。第二种方法直接使用LMs的生成作为搜索查询,称为FLAREdirect,它迭代地生成下一句话以洞察未来的主题,如果存在不确定的标记,则检索相关文档以重新生成下一句话
表达检索信息需求的一个直接方法是在需要额外信息时生成“[Search(query)]”,例如,“加纳国旗的颜色具有以下含义。红色代表[Search(加纳国旗红色含义)]烈士的鲜血,...”
直接FLARE
由于无法对黑盒LMs进行微调,发现通过检索指令生成的查询可能不可靠。因此,提出了一种更直接的前瞻性主动检索方法,使用下一句话来决定何时以及检索什么信息
在步骤t时,首先生成一个临时的下一句话ˆst = LM([x, y<t])而不基于检索到的文档。然后决定是否触发检索并基于ˆst制定查询。如果LM对ˆst有信心,接受它而不检索额外信息;如果没有信心,使用ˆst来制定搜索查询qt来检索相关文档,然后重新生成下一句话。选择句子作为迭代的基础,因为它们作为语义单元既不像短语那样短,也不像段落那样长。然而,的方法也可以使用短语或段落作为基础。由于LMs往往具有良好的校准,低概率/置信度通常表明缺乏知识(Jiang et al., 2021; Kadavath et al., 2022; Varshney et al., 2022),主动触发检索,如果ˆst中的任何标记的概率低于阈值θ ∈ [0, 1]。θ = 0意味着从不触发检索,而θ = 1则在每个句子都触发检索

检索的一种方法是直接使用下一句话ˆst作为查询qt。这种方法存在延续错误的风险。例如,如果LM生成了“乔·拜登就读于宾夕法尼亚大学”而不是正确的事实“他就读于特拉华大学”,使用这个错误的句子作为查询可能会检索到误导性的信息。提出了两种简单的方法来克服这个问题,
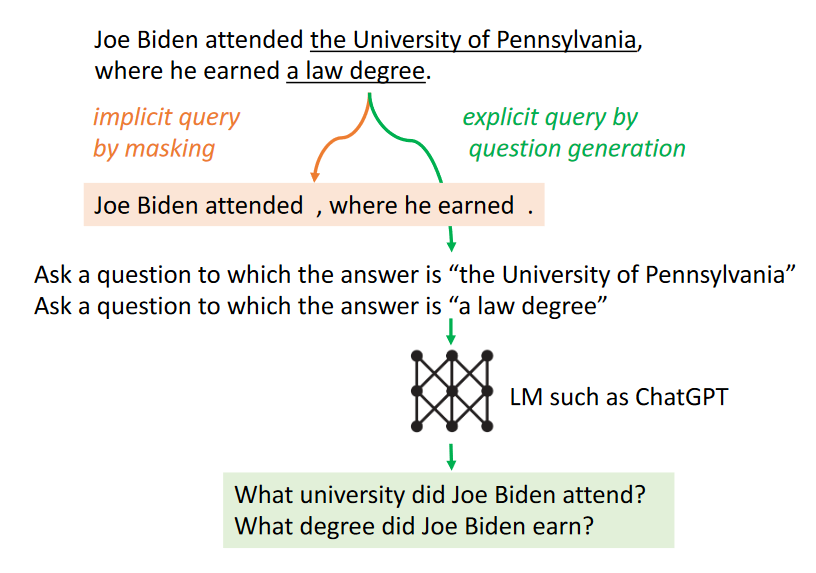
遮蔽句子作为隐式查询。第一种方法是遮蔽ˆst中概率低于阈值β ∈ [0, 1]的低置信度标记,其中β值越高,遮蔽越激进。这消除了句子中的潜在干扰,提高了检索的准确性
生成问题作为显式查询。另一种方法是生成针对ˆst中低置信度跨度的显式问题。例如,如果LM对“宾夕法尼亚大学”不确定,可以生成一个问题,如“乔·拜登就读于哪所大学?”来帮助检索相关信息
基于前窗口的方法
前窗口方法在每个l个标记触发一次检索,其中l代表窗口大小
基于前句子的方法
前句子方法在每个句子触发一次检索,并使用前一个句子作为查询
问题分解方法
问题分解方法手动注释了任务特定的示例,以指导LMs在生成输出时生成分解的子问题。例如,self-ask(Press et al., 2022)这类方法,在示例中手动插入子问题。对于测试案例,检索在模型生成子问题时动态触发。上述方法可以在生成过程中检索额外信息,但它们有明显的缺点:(1)使用之前生成的标记作为查询可能无法反映LMs未来生成的意图。(2)在固定间隔检索信息可能效率低下,因为它可能发生在不适当的点。(3)问题分解方法需要任务特定的提示工程,这限制了它们在新任务中的通用性
Retrieval-Augmented Generation for Large Language Models: A Survey(大型语言模型的检索增强生成研究综述)
[v1]2023年12月18日
[2312.10997] Retrieval-Augmented Generation for Large Language Models: A Survey (arxiv.org)
[v5]2024年3月27日
[2312.10997v5] Retrieval-Augmented Generation for Large Language Models: A Survey (arxiv.org)
RAG研究的技术树
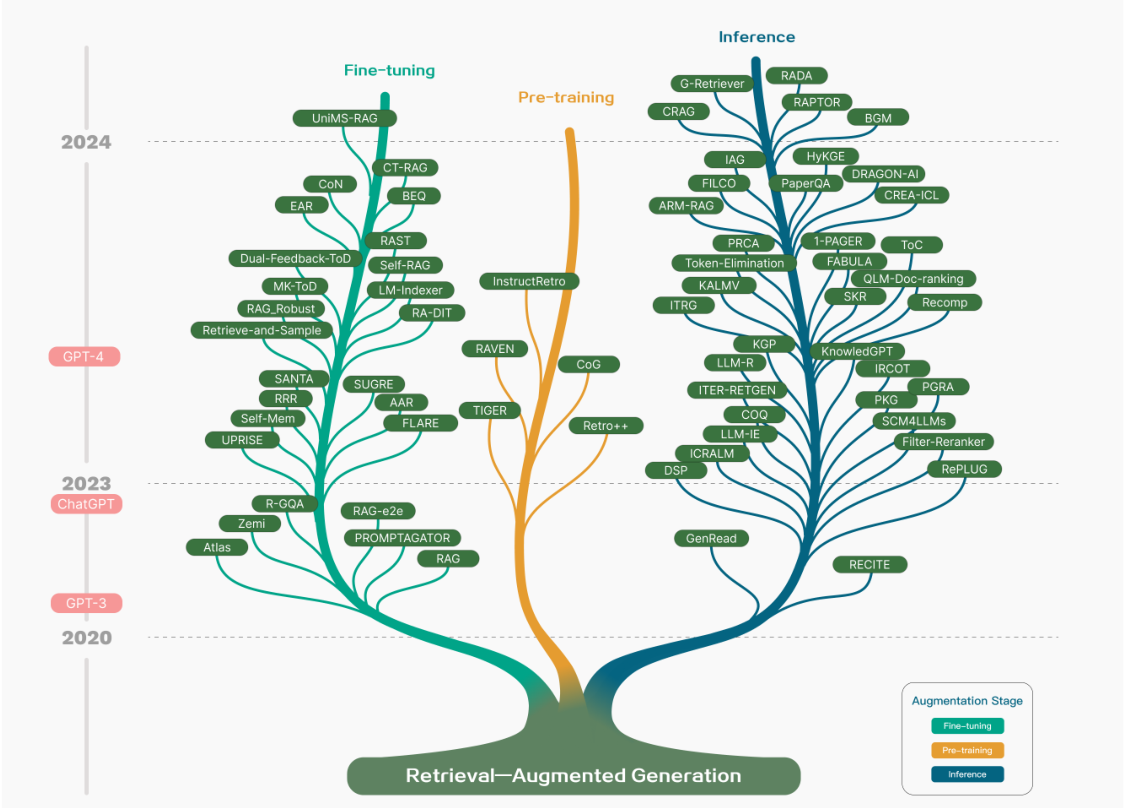
图1. RAG研究的技术树。涉及RAG的阶段主要包括预训练、微调和推理。随着LLMs的出现,RAG的研究最初集中在利用LLMs强大的上下文学习能力,主要集中在推理 阶段。随后的研究更加深入,逐渐与LLMs的微调结合更多。研究人员还一直在探索通过检索增强技术在预训练阶段增强语言模型的方法
- 在其2017年的起源时,与Transformer架构的出现相一致,主要重点是通过预训练模型(PTM)吸收额外的知识来增强语言模型
- 随后chatGPT的到来标志着RAG轨迹的一个重要时刻,将LLMs推向了前沿。大部分RAG工作集中在推理上,少数致力于微调过程
- 随着GPT-4的引入,RAG技术领域经历了重大变革。重点发展成为一种混合方法,结合了RAG和微调的优势
OVERVIEW OF RAG
典型的RAG应用工作流程
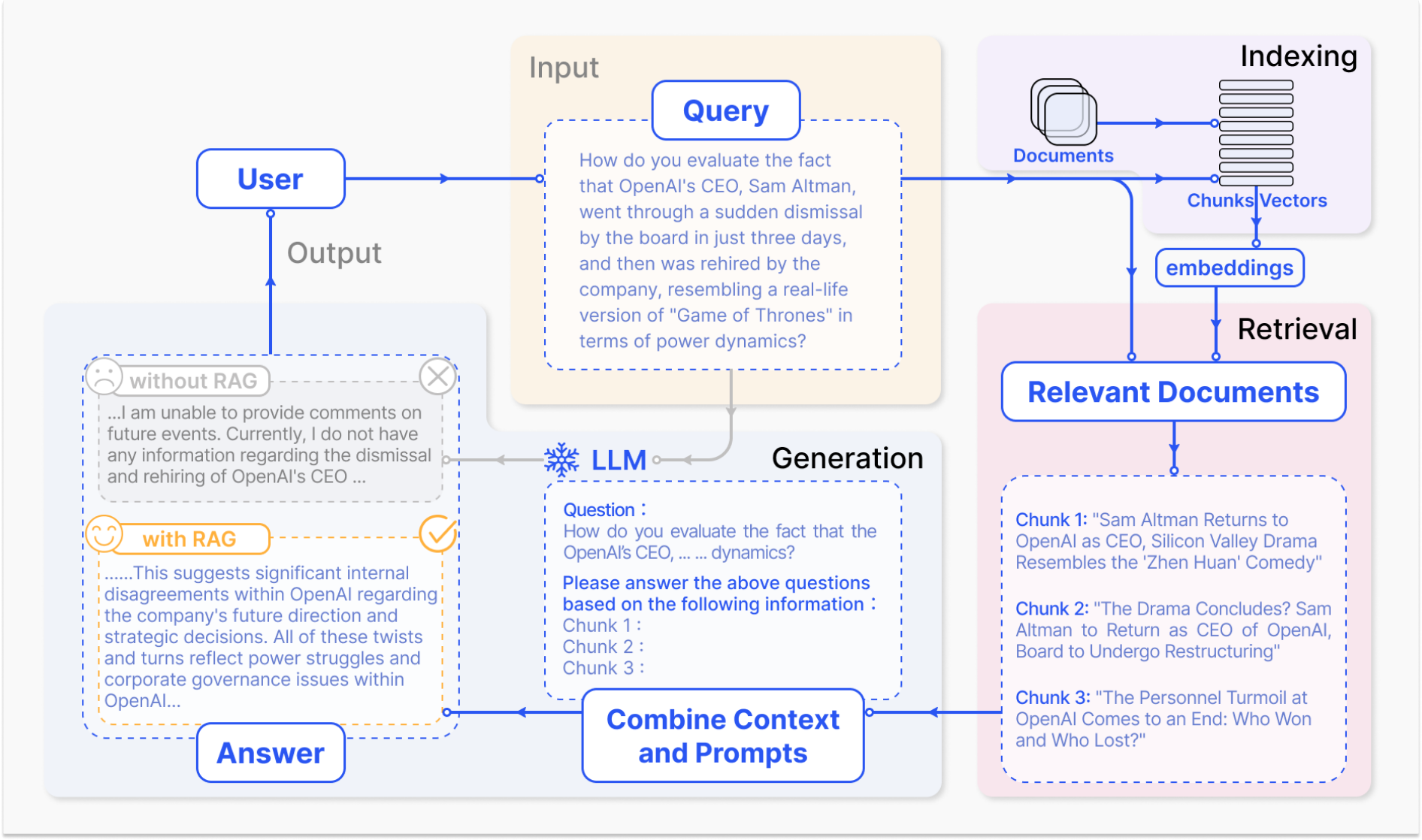
图 2.应用于问答的 RAG 流程的代表性实例
- 用户询问ChatGPT关于一个最近引起公众广泛讨论的高调事件(例如,OpenAI首席执行官的突然解雇和复职)
- 作为最著名和广泛使用的LLM,ChatGPT受限于其预训练数据,缺乏对最近事件的了解。RAG通过从外部知识库检索最新的文档摘要来解决这一差距。在这种情况下,它获取了与查询相关的新闻文章
- “检索什么”、“何时检索”以及“如何使用检索到的信息”
RAG工作流程包括三个关键步骤
- 索引。文档被分割成块,编码成向量,并存储在向量数据库中
- 检索。根据语义相似性检索 与问题最相关的前 k 个块
- 生成。将原始问题和检索到的块一起输入到LLM中以生成最终答案
三阶段
三种比较:
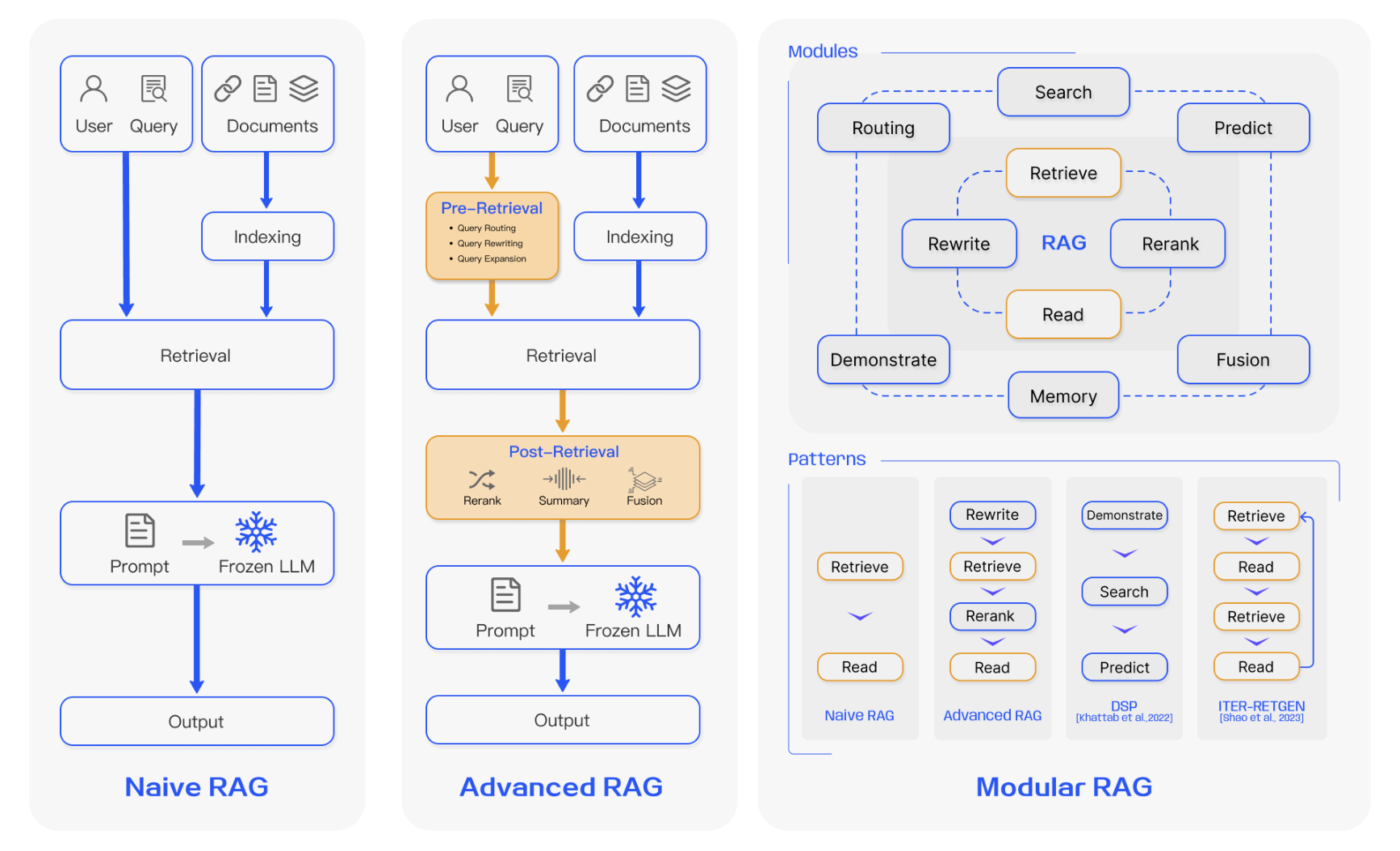
图 3. RAG 三种范式之间的比较。 (左)Naive RAG主要由三个部分组成:索引、检索和生成。 (中)Advanced RAG围绕检索前和检索后提出了多种优化策略,其流 程与Naive RAG类似,仍然遵循链式结构。 (右)模块化RAG继承并发展了之前的范式,整体上表现出更大的灵活性。这在多个特定功能模块的引入以及现有模块的替 换上表现得很明显。整个过程不限于顺序检索和生成;它包括迭代和自适应检索等方法
三阶段-Naive RAG
Naive RAG遵循传统的包括索引、检索和生成的过程。它也被称为“检索-阅读”框架
- 索引:是数据准备中的关键初始步骤,它在离线时进行。它从数据索引开始,原始数据被清理和提取,各种文件格式如PDF、HTML、Word和Markdown被转换为标准化的纯文本。为了适应语言模型的上下文限制,这些文本随后被分割成更小、更易管理的块,这个过程被称为块化。这些块随后通过嵌入模型转换为向量表示,该模型在推理效率和模型大小之间取得了平衡。这有助于在检索阶段进行相似性比较。最后,创建一个索引来存储这些文本块及其向量嵌入作为键值对,允许高效和可扩展的搜索能力
- 检索:在接收到用户查询后,系统使用与索引阶段相同的编码模型将输入转换为向量表示。然后,它计算查询向量与索引语料库中的向量化块之间的相似度分数。系统优先检索与查询最相似的前K个块。这些块随后被用作解决用户请求的扩展上下文基础
- 生成:提出的查询和选定的文档被合成为一个连贯的提示,大型语言模型负责制定响应。模型回答问题的方法可能因任务特定标准而有所不同,允许它要么利用其固有的参数化知识,要么将其响应限制在提供的文档所包含的信息内。在持续的对话中,任何现有的对话历史都可以集成到提示中,使模型能够有效地进行多轮对话互动
缺陷
检索
精确度和召回率低
选择错位或不相关的块,并丢失关键信息
增强
将检索到的信息与不同的任务集成可能具有挑战性,有时会导致输出脱节或不连贯
当从多个来源检索类似信 息时,该过程还可能遇到冗余,从而导致重复响应
确定各个段落的重要性和相关性并确保风格和语气的一致性进一步增加了复杂性
面对复杂的问题,基于原始查询的单一检索可能不 足以获取足够的上下文信息
生成
在生成响应时,模型可能会面临幻觉问题,即生成检索到的上下文不支持的内容
人们担心生成模型可能过度依赖增强信息,导致输出只 是回显检索到的内容,而不添加有洞察力或综合的信息
三阶段-Advanced RAG
为了克服Naive RAG的局限性,Advanced RAG引入了特定的改进措施、着眼于提高检索质量
引入了滑动窗口、细粒度分割和整合元数据来改进其索引技术,并提出了各种方法来优化检索过程
Pre-retrieval process(检索前过程)
主要关注点是优化索引结构和原始查询
优化索引的目标是提高被索引内容的质量。这涉及到以下策略:增强数据粒度、优化索引结构、添加元数据、对齐优化和混合检索
查询优化的目标是使用户原始问题更清晰,更适合检索任务。常用的方法包括查询重写、查询转换、查询扩展等技术[7]、[9]-[11]
Post-Retrieval Process(检索后过程)
一旦检索到相关上下文,有效整合这些上下文与查询至关重要
检索后过程中的主要方法包括重新排列块和上下文压缩
重新排列检索到的信息,将最相关内容重新定位到提示的边缘,是一个关键策略。这个概念已在如LlamaIndex、LangChain和HayStack等框架中得到实现。直接将所有相关文档输入到LLMs可能会导致信息过载,用不相关内容稀释对关键细节的关注。为了缓解这个问题,检索后的工作集中在选择关键信息、强调重要部分,并缩短要处理的上下文
Advanced RAG通过在检索前和检索后阶段的优化策略,提高了检索的质量和效率,从而为生成阶段提供了更加准确和相关的上下文信息。这种方法不仅提高了检索的精度,还有助于生成阶段生成更高质量、更可靠的回答
三阶段-Modular RAG(模块化RAG)
模块化RAG架构超越了前两种RAG范式,提供了更强的适应性和多功能性
它整合了多种策略来改进其组件,例如增加搜索模块以进行相似性搜索,并通过微调来改进检索器
引入了像重构的RAG模块[13]和重新排列的RAG流程[14]这样的创新,以应对特定挑战
转向模块化RAG方法的趋势正在变得普遍,支持其组件的顺序处理和集成端到端训练
尽管它具有独特性,模块化RAG仍然建立在高级和朴素RAG的基础原则上,展示了RAG家族内的进步和改进
[13] W. Yu, D. Iter, S. Wang, Y. Xu, M. Ju, S. Sanyal, C. Zhu, M. Zeng, and M. Jiang, “Generate rather than retrieve: Large language models are strong context generators,” arXiv preprint arXiv:2209.10063, 2022.
[14] Z. Shao, Y. Gong, Y. Shen, M. Huang, N. Duan, and W. Chen, “Enhancing retrieval-augmented large language models with iterative retrieval-generation synergy,” arXiv preprint arXiv:2305.15294, 2023.
新模块
模块化RAG框架引入了额外的专业组件来增强检索和处理能力
搜索模块适应特定场景,使用LLM生成的代码和查询语言,能够在各种数据源如搜索引擎、数据库和知识图谱上直接搜索[15]
[15] X. Wang, Q. Yang, Y. Qiu, J. Liang, Q. He, Z. Gu, Y. Xiao, and W. Wang, “Knowledgpt: Enhancing large language models with retrieval and storage access on knowledge bases,” arXiv preprint arXiv:2308.11761, 2023.
RAGFusion通过采用多查询策略来解决传统搜索限制,将用户查询扩展到不同视角,利用并行向量搜索和智能重新排名来揭示显性和转型知识[16]
[16] A. H. Raudaschl, “Forget rag, the future is rag-fusion,” https://towardsdatascience.com/ forget-rag-the-future-is-rag-fusion-1147298d8ad1, 2023.
记忆模块利用LLM的记忆来指导检索,创建一个无界的记忆池,通过迭代自我增强使文本更紧密地与数据分布对齐[17],[18]
[17] X. Cheng, D. Luo, X. Chen, L. Liu, D. Zhao, and R. Yan, “Lift yourself up: Retrieval-augmented text generation with self memory,” arXiv preprint arXiv:2305.02437, 2023.
[18] S. Wang, Y. Xu, Y. Fang, Y. Liu, S. Sun, R. Xu, C. Zhu, and M. Zeng, “Training data is more valuable than you think: A simple and effective method by retrieving from training data,” arXiv preprint arXiv:2203.08773, 2022.
RAG系统中的路由在不同数据源中导航,为查询选择最佳路径,无论是涉及摘要、特定数据库搜索还是合并不同的信息流[19]
[19] X. Li, E. Nie, and S. Liang, “From classification to generation: Insights into crosslingual retrieval augmented icl,” arXiv preprint arXiv:2311.06595, 2023.
预测模块旨在通过直接通过LLM生成上下文来减少冗余和噪声,确保相关性和准确性[13]
任务适配器模块使RAG适应各种下游任务,自动化提示检索零样本输入,并通过少样本查询生成创建任务特定的检索器[20],[21]
这种全面的方法不仅简化了检索过程,还显著提高了检索信息的质量和相关性,以更高的精度和灵活性迎合了广泛的任务和查询
新模式
模块化RAG通过允许模块替换或重新配置来提供显著的适应性,以解决特定挑战
这超越了朴素和高级RAG的固定结构,其特点是简单的“检索”和“阅读”机制
模块化RAG通过整合新模块或调整现有模块之间的交互流程,扩展了这种灵活性,增强了其在不同任务的适用性
像重写-检索-阅读[7]模型利用LLM的能力通过重写模块和LM反馈机制来改进检索查询,提高任务性能
类似地,像生成-阅读[13]这样的方法用LLM生成的内容取代了传统检索,而ReciteRead[22]强调从模型权重中检索,增强了模型处理知识密集型任务的能力
混合检索策略整合了关键词、语义和向量搜索,以迎合多样化的查询
此外,使用子查询和假设文档嵌入(HyDE)[11]通过专注于生成答案和真实文档之间的嵌入相似性来提高检索相关性
[11] L. Gao, X. Ma, J. Lin, and J. Callan, “Precise zero-shot dense retrieval without relevance labels,” arXiv preprint arXiv:2212.10496, 2022.
模块排列和交互的调整,如演示-搜索-预测(DSP)[23]框架和迭代检索-阅读-检索-阅读流程的ITERRETGEN[14],展示了模块输出动态使用的模块功能的增强,展示了提高模块协同作用的复杂理解
模块化RAG流程的灵活编排展示了自适应检索技术的好处,如FLARE[24]和Self-RAG[25]
[24] Z. Jiang, F. F. Xu, L. Gao, Z. Sun, Q. Liu, J. Dwivedi-Yu, Y. Yang, J. Callan, and G. Neubig, “Active retrieval augmented generation,” arXiv preprint arXiv:2305.06983, 2023.
[25] A. Asai, Z. Wu, Y. Wang, A. Sil, and H. Hajishirzi, “Self-rag: Learning to retrieve, generate, and critique through self-reflection,” arXiv preprint arXiv:2310.11511, 2023.
这种方法通过根据不同场景评估检索的必要性,超越了固定的RAG检索过程。灵活架构的另一个好处是,RAG系统可以更容易地与其他技术(如微调或强化学习)[26]集成
例如,这可以涉及微调检索器以获得更好的检索结果,微调生成器以获得更个性化的输出,或者进行协作微调[27]
模块化RAG通过其创新的模块化设计,展示了在多样化任务和复杂场景中应用的潜力,同时保持了系统的灵活性和可扩展性
RAG vs Fine-tuning
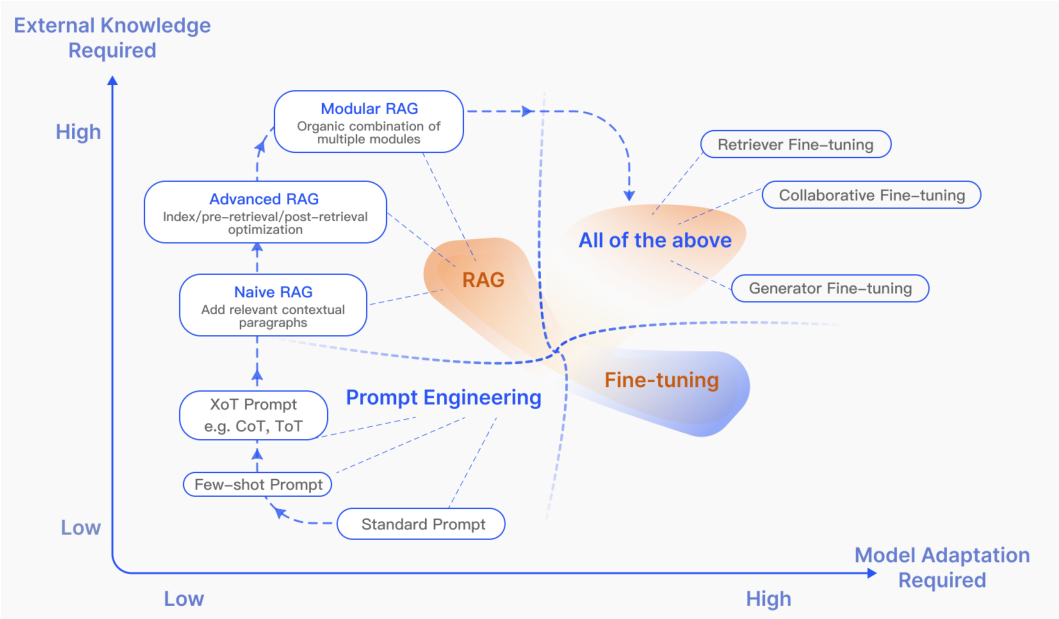
图4. RAG与其他模型优化方法在“需要外部知识”和“需要模型适应”方面的比较。即时工程需要对模型和外部知识进行少量修改,重点是利用 LLMs 本身的功能。另一方 面,微调涉及进一步训练模型。在RAG(Naive RAG)的早期阶段,对模型修改的需求较低。随着研究的进展,模块化 RAG 与微调技术的集成度越来越高
在LLMs的优化方法中,RAG通常与微调(FT)和提示工程(prompt engineering)进行比较
提示工程利用模型的固有能力,对外部知识和模型适应的需求最小
RAG可以类比为为模型提供定制的教科书,用于信息检索,非常适合精确的信息检索任务
相比之下,FT类似于学生随时间吸收知识,适用于需要复制特定结构、风格或格式的场景
RAG在动态环境中表现出色,提供实时知识更新和有效利用外部知识源,具有很高的可解释性。然而,它带来了更高的延迟和关于数据检索的伦理考虑
另一方面,FT更加静态,需要重新训练以进行更新,但能够深度定制模型的行为和风格。它需要大量的计算资源来进行数据集准备和训练,虽然可以减少幻觉(hallucinations),但可能面临不熟悉数据的挑战。在对不同主题的各种知识密集型任务进行的多次评估中,[28]揭示了尽管无监督微调显示出一些改进,但RAG始终优于它,无论是在训练期间遇到的现有知识还是完全新的知识
[28] O. Ovadia, M. Brief, M. Mishaeli, and O. Elisha, “Fine-tuning or retrieval? comparing knowledge injection in llms,” arXiv preprint arXiv:2312.05934, 2023.
此外,研究发现LLMs难以通过无监督微调学习新的事实上的信息。选择RAG和FT取决于应用上下文中对数据动态性、定制化和计算能力的具体需求。RAG和FT并不互相排斥,可以互补,增强模型在不同层次上的能力。在某些情况下,它们的联合使用可能导致最佳性能。涉及RAG和FT的优化过程可能需要多次迭代才能达到满意的结果
检索
检索来源
RAG依靠外部知识来增强LLMs,而检索源的类型和检索单元的 粒度都会影响最终的生成结果
- 数据结构:最初,文本是检索的主流来源。随后,检索源扩展到包括半结构化数据(PDF)和结构化数据(知识图谱, KG)进行增强。除了从原始外部资源检索之外,最近的研究也越来越倾向于利用 LLMs 本身生成的内容来进行检索和增强
非结构化数据,例如文本,是最广泛使用的检索源,主要从语料库中收集
对于开放域问答(ODQA)任务,主要检索来源是 Wikipedia Dump,当前主要版本包括HotpotQA(2017年10 月1日)、DPR(2018年12月20日)。除了百科全书式数据之外,常见的非结构化数据还包括跨语言文本[19]和特定领域数据 (例如医学[67]和法律领域[29])
半结构化数据。通常指包含文本和表格信息组合的数据,例如 PDF
由于两个主要原因,处理半结构化数据给传统 RAG 系统带来了挑战。首先,文本拆分过程可能会无意中分离表,导致检索期间数据损坏。其次,将表格合并到数据中可能会使语义相似性搜索复杂化。处理半结构化数据时,一种方法涉及利用 LLMs 的代码功能对数据库内的表执行 Text-2-SQL 查询,例 如 TableGPT [85]。或者,可以将表格转换为文本格式,以便使用基于文本的方法进行进一步分析[75]。然而,这两种方法都不是最佳解决方案,表明该领域存在大量研究机会
[85] L. Zha, J. Zhou, L. Li, R. Wang, Q. Huang, S. Yang, J. Yuan, C. Su, X. Li, A. Su et al., “Tablegpt: Towards unifying tables, nature language and commands into one gpt,” arXiv preprint arXiv:2307.08674, 2023.
[75] Z. Luo, C. Xu, P. Zhao, X. Geng, C. Tao, J. Ma, Q. Lin, and D. Jiang, “Augmented large language models with parametric knowledge guiding,” arXiv preprint arXiv:2305.04757, 2023.
结构化数据,例如知识图谱(KG)[86],通常经过验证并且可以提供更精确的信息。 KnowledGPT [15] 生成知识库搜索查询并将知识存储在个性化库中,从而增强了 RAG 模型的知识丰富度。针对LLMs在理解和回答文本图问题方面的局限性,GRetriever [84]集成了图神经网络 4https://hotpotqa.github.io/wikireadme.html 5https://github.com/facebookresearch/DPR (GNNs)、LLMs和RAG,通过LLM的软提示增强图形理解和问答能力,并采用采奖斯坦纳树(PCST)优化问题来进行有针对性的图检索。相反,它需要额外的努力来构建、验证和维护结构化数据库。 LLMs-生成的内容。针对 RAG 中外部辅助信息的局限性,一些研究集中于利用 LLMs 的内部知识。 SKR [58] 将问题分类为已知或未知,有选择地应用检索增强。 GenRead [13] 用 LLM 生成器替换检索器,发现 LLM 生成的上下文通常包含更准确的答案,因为它与因果语言建模的预训练目标更好地保持一致。 Selfmem [17]迭代地创建一个带有检索增强生成器的无界内存池,使用内存选择器来选择作为原始问题的对偶问题的输出,从而自我增强生成模型。这些方法强调了 RAG 中创新数据源利用的广度,努力提高模型性能和任务效率
[86] M. Gaur, K. Gunaratna, V. Srinivasan, and H. Jin, “Iseeq: Information seeking question generation using dynamic meta-information retrieval and knowledge graphs,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 36, no. 10, 2022, pp. 10 672–10 680.
[15] X. Wang, Q. Yang, Y. Qiu, J. Liang, Q. He, Z. Gu, Y. Xiao, and W. Wang, “Knowledgpt: Enhancing large language models with retrieval and storage access on knowledge bases,” arXiv preprint arXiv:2308.11761, 2023.
- 检索粒度:除了检索源的数据格式之外,另一个重要因素是检索数据的粒度
理论上,粗粒度检索单元可以为问题提供更多相关信息,但它们也可能包含冗余内容,这可能会分散下游任务中的检索器和语言模型的注意力[50],[87]
另一方面,细粒度的检索单元粒度增加了检索的负担,并且不能保证语义完整性和满足所需的知识。选择在推理过程中选择合适的检索粒度是提高密集检索器的检索和下游任务性能的简单而有效的策略。在文本中,检索粒度从细到粗,包括Token、Phrase、 Sentence、Proposition、Chunks、Document。其中, DenseX[30]提出了使用命题作为检索单元的概念。命题被定义为文本中的原子表达式,每个命题都封装了一个独特的事实片段,并以简洁、独立的自然语言格式呈现。该方法旨在提高检索精度和相关性。在知识图谱(KG)上,检索粒度包括实体、 三元组和子图。检索的粒度也可以适应下游任务,例如检索推荐任务中的项目 ID [40] 和句子对 [38]
索引优化
在索引阶段,文档将被处理、分段并转换为嵌入以存储在矢量数据库中
- 分块策略(Chunking Strategy):最常见的方法是将文档分成固定数量的标记(例 如,100、256、512)上的块[88]。较大的块可以捕获更多的上下文,但它们也会产生更多的噪音,需要更长的处理时间和更高的成本。虽然较小的块可能无法完全传达必要的上下文, 但它们确实具有较少的噪音。然而,块会导致句子内的截断, 从而促进递归分割和滑动窗口方法的优化,通过跨多个检索过程合并全局相关信息来实现分层检索[89]。然而,这些方法仍然无法在语义完整性和上下文长度之间取得平衡。因此,人们提出了像Small2Big这样的方法,其中句子(小)被用作检索单元,并且前面和后面的句子作为(大)上下文提供给 LLMs[90]
[88] R. Teja,“评估抹布的理想块⼤⼩ 使⽤ LlamaIndex 的系统”,https://www.LlamaIndex.ai/blog/evaluating-the-idealchunk-size-for-a-rag-system-using-LlamaIndex-6207e5d3fec5, 2023.
[90] S. Yang, “Advanced rag 01: Small-tobig retrieval,” https://towardsdatascience.com/ advanced-rag-01-small-to-big-retrieval-172181b396d4, 2023.
元数据附加(Metadata Attachments):块可以用元数据信息来丰富,如页码、文件名、作者、类别时间戳。随后,检索可以根据这些元数据进行过滤,限制检索范围。在检索期间为文档时间戳分配不同的权重可以实现时间感知的RAG,确保知识的新鲜度,避免过时信息。除了从原始文档中提取元数据外,还可以人工构建元数据。例如,添加段落摘要,以及引入假设问题。这种方法也称为反向HyDE。具体来说,使用LLM生成可以由文档回答的问题,然后在检索期间计算原始问题和假设问题之间的相似度,以减少问题和答案之间的语义差距
结构索引(Structural Index):
增强信息检索的有效方法是为文档建立层次结构。通过构建结构,RAG系统可以加速检索和处理相关数据
分层索引结构。文件按父子关系排列,块链接到它们。数据摘要存储在每个节点上,有助于快速遍历数据并协助 RAG 系统确定要提取哪些块。这种方法还可以减轻由块提取问题引起的错 觉
知识图谱索引。利用KG构建文档的层次结构有助于保持一致性。它描绘了不同概念和实体之间的联系,显着减少了产生幻觉的可能性。另一个优点是将信息检索过程转化为LLM可以理解的指令,从而提高知识检索的准确性,并使LLM能够生成上下文连贯的响应,从而提高整体效率 RAG 系统。为了捕获文档内容和结构之间的逻辑关系,KGP[91]提出了一种使用KG在多 个文档之间建立索引的方法。该知识图谱由节点(表示文档中的段落或结构,例如⻚面和表格)和边(表示段落之间的语义/ 词汇相似性或文档结构内的关系)组成,有效解决多文档中的知识检索和推理问题环境
[91] Y. Wang, N. Lipka, R. A. Rossi, A. Siu, R. Zhang, and T. Derr, “Knowledge graph prompting for multi-document question answering,” arXiv preprint arXiv:2308.11730, 2023.
查询优化
朴素RAG的一个主要挑战是它直接依赖于用户的原始查询作为检索的基础
制定一个精确且清晰的问题很困难,草率的查询会导致检索效果不佳
有时,问题本身很复杂,语言组织不佳
另一个困难在于语言的复杂性和歧义性。语言模型在处理专业词汇或具有多种含义的模糊缩写时常常遇到困难
例如,它们可能无法辨别“LLM”是指大型语言模型还是法律背景下的法学硕士
查询扩展(Query Expansion):将单个查询扩展为多个查询可以丰富查询内容,提供更多上下文以解决任何缺乏具体细节的问题,从而确保生成的答案具有最佳相关性
多查询(Multi-Query):通过使用提示工程扩展LLMs的查询,然后可以并行执行这些查询。查询扩展不是随机的,而是经过精心设计的
子查询(Sub-Query):子问题规划过程代表了生成必要的子问题以在组合时对原始问题进行上下文化和完整回答的过程。这种添加相关上下文的过程,在原则上与查询扩展类似。具体来说,可以使用最少到最多的提示方法[92]将复杂问题分解为一系列更简单的子问题
验证链(Chain-of-Verification, CoVe):扩展的查询经过LLM验证,以实现减少幻觉的效果。经过验证的扩展查询通常表现出更高的可靠性[93]
[92] D. Zhou, N. Sch¨arli, L. Hou, J. Wei, N. Scales, X. Wang, D. Schuurmans, C. Cui, O. Bousquet, Q. Le et al., “Least-to-most prompting enables complex reasoning in large language models,” arXiv preprint arXiv:2205.10625, 2022.
[93] S. Dhuliawala, M. Komeili, J. Xu, R. Raileanu, X. Li, A. Celikyilmaz, and J. Weston, “Chain-of-verification reduces hallucination in large language models,” arXiv preprint arXiv:2309.11495, 2023.
查询转换:核心概念是根据转换后的查询而不是用户的原始查询来检索块
查询重写。原始查询并不总是最适合 LLM 检索,尤其是在现实场景中。因此,可以提示 LLM 重写查询。除了使用LLM进行查询重写之外,还专⻔使用较小的语言模型,例如RRR (Rewrite-retrieve-read)[7]。淘宝中查询重写方法的实施, 称为BEQUE[9],显着增强了⻓尾查询的召回率,从而导致 GMV 的上升
另一种查询转换方法是使用提示工程让LLM根据原始查询生成查询以供后续检索
HyDE [11] 构建假设文档(假设原始查询的答案)。它侧重于嵌入答案之间的相似性,而不是寻求问题或查询的嵌入相似性
使用后退提示方法[10],对原始查询进行抽象以生成高级概念问题(后退问题)。在RAG系统中,后退问题和原始查询都用于检索,并且这两种结果都被用作语言模型答案生成的基础
[7] X. Ma, Y. Gong, P. He, H. Zhao, and N. Duan, “Query rewriting for retrieval-augmented large language models,” arXiv preprint arXiv:2305.14283, 2023.
[9] W. Peng, G. Li, Y. Jiang, Z. Wang, D. Ou, X. Zeng, E. Chen et al., “Large language model based long-tail query rewriting in taobao search,” arXiv preprint arXiv:2311.03758, 2023.
[11] L. Gao, X. Ma, J. Lin, and J. Callan, “Precise zero-shot dense retrieval without relevance labels,” arXiv preprint arXiv:2212.10496, 2022.
[10] H. S. Zheng, S. Mishra, X. Chen, H.-T. Cheng, E. H. Chi, Q. V. Le, and D. Zhou, “Take a step back: Evoking reasoning via abstraction in large language models,” arXiv preprint arXiv:2310.06117, 2023.
- 查询路由:基于不同的查询,路由到不同的RAG管道,适用于旨在适应不同场景的多功能RAG系统。元数据路由器/过滤器。第一步涉及从查询中提取关键字(实体),然后根据块中的关键字和元数据进行过滤以缩小搜索范围。 语义路由器是另一种涉及利用查询语义信息的路由方法。具体做法参⻅Semantic Router。当然,也可以采用混合路由方法, 结合语义和基于元数据的方法来增强查询路由
嵌入(Embedding)
在RAG中,检索是通过计算问题和文档块嵌入之间的相似度(例如余弦相似度)来实现的,其中嵌入模型的语义表示能力起着关键作用。这主要包括稀疏编码器(BM25)和密集检索器(基于BERT架构的预训练语言模型)。最近的研究引入了如AngIE、Voyage、BGE等著名的嵌入模型[94]–[96],这些模型从多任务指令调优中受益。Hugging Face的MTEB排行榜7评估了8个任务中的嵌入模型,涵盖了58个数据集。此外,C-MTEB专注于中文能力,涵盖了6个任务和35个数据集。没有一种嵌入模型适用于所有情况。然而,某些特定模型更适合特定用例
混合/混合检索(Mix/hybrid Retrieval):稀疏和密集嵌入方法捕获不同的相关性特征,可以通过利用互补的相关性信息互相受益。例如,稀疏检索模型可以用于为训练密集检索模型提供初始搜索结果。此外,预训练语言模型(PLMs)可以用于学习术语权重以增强稀疏检索。具体来说,它还展示了稀疏检索模型可以增强密集检索模型的零样本检索能力,并帮助密集检索器处理包含稀有实体的查询,从而提高鲁棒性
微调嵌入模型(Fine-tuning Embedding Model):在上下文显著偏离预训练语料库的情况下,特别是在医疗保健、法律实践等高度专业化的学科中,使用自己的领域数据集对嵌入模型进行微调变得至关重要,以减少这种差异
除了补充领域知识外,微调的另一个目的是对齐检索器和生成器,例如,使用LLM的结果作为微调的监督信号,称为LSR(LM-supervised Retriever)
PROMPTTAGATOR[21]使用LLM作为少样本查询生成器来创建特定于任务的检索器,解决监督微调中的挑战,特别是在数据稀缺的领域
另一种方法,LLM-Embedder[97],利用LLM在多个下游任务中生成奖励信号。检索器通过两种类型的监督信号进行微调:数据集的硬标签和LLM的软奖励。这种双信号方法促进了更有效的微调过程,将嵌入模型定制到多样化的下游应用中
REPLUG[72]使用检索器和LLM来计算检索文档的概率分布,然后通过计算KL散度进行监督训练。这种简单有效的训练方法通过使用LM作为监督信号来增强检索模型的性能,消除了对特定交叉注意力机制的需求
此外,受到RLHF(从人类反馈中强化学习)的启发,利用基于LM的反馈通过强化学习加强检索器
[21] Z. Dai, V. Y. Zhao, J. Ma, Y. Luan, J. Ni, J. Lu, A. Bakalov, K. Guu, K. B. Hall, and M.-W. Chang, “Promptagator: Few-shot dense retrieval from 8 examples,” arXiv preprint arXiv:2209.11755, 2022.
[97] P. Zhang, S. Xiao, Z. Liu, Z. Dou, and J.-Y. Nie, “Retrieve anything to augment large language models,” arXiv preprint arXiv:2310.07554, 2023.
[72] W. Shi, S. Min, M. Yasunaga, M. Seo, R. James, M. Lewis, L. Zettlemoyer, and W.-t. Yih, “Replug: Retrieval-augmented black-box language models,” arXiv preprint arXiv:2301.12652, 2023.
适配器(Adapter)❓❓❓
微调模型可能会面临一些挑战,例如通过API集成功能或解决有限的本地计算资源带来的限制。因此,一些方法选择加入外部适配器来帮助对齐
为了优化LLM的多任务能力,UPRISE[20]训练了一个轻量级提示检索器,可以自动从预先构建的提示池中检索适合给定零样本任务输入的提示
AAR(Augmentation-Adapted Retriever)[47]引入了一个通用适配器,旨在适应多个下游任务
而PRCA[69]则增加了一个可插拔的奖励驱动的上下文适配器,以提高特定任务的性能
BGM[26]保持检索器和LLM固定,并在两者之间训练了一个桥接Seq2Seq模型。桥接模型的目的是将检索到的信息转换为LLM可以有效工作的形式,使其不仅能够重新排名,还能够动态选择每个查询的段落,并可能采用更高级的策略,如重复
此外,PKG引入了一种创新的方法,通过指令微调将知识整合到白盒模型中[75]。在这种方法中,检索器模块被直接替换,根据查询生成相关文档。这种方法有助于解决微调过程中遇到的困难,并提高模型性能
生成
检索完成后,直接将所有检索到的信息输入到大型语言模型(LLM)进行问题回答并不是一个好的做法。接下来将从两个角度介绍调整:调整检索内容和调整LLM
A. 上下文策划(Context Curation)
冗余信息可能会干扰LLM的最终生成,过长的上下文也可能导致LLM出现“迷失在中间”的问题[98]。像人类一样,LLM往往只关注长文本的开头和结尾部分,而忘记了中间部分。因此,在RAG系统中,通常需要对检索到的内容进行进一步处理
[98] N. F. Liu, K. Lin, J. Hewitt, A. Paranjape, M. Bevilacqua, F. Petroni, and P. Liang, “Lost in the middle: How language models use long contexts,” arXiv preprint arXiv:2307.03172, 2023.
- 重新排名(Reranking):重新排名基本上是对文档块进行重新排序,以突出最相关的结果,有效地减少整体文档池,同时在信息检索中充当增强器和过滤器的双重角色,为更精确的语言模型处理提供精炼的输入[70]。重新排名可以使用基于规则的方法,这些方法依赖于预定义的指标,如多样性、相关性和MRR,或者使用基于模型的方法,如BERT系列的编码器-解码器模型(例如SpanBERT)、专门的重新排名模型,如Cohere rerank或bge-raranker-large,以及通用的大型语言模型如GPT[12],[99]
- 上下文选择/压缩(Context Selection/Compression):RAG过程中的一个常见误解是认为检索尽可能多的相关文档,并将它们连接起来形成长检索提示是有益的。然而,过多的上下文可能会引入更多噪声,降低LLM对关键信息的感知。(LL)LLMLingua[100],[101]使用小型语言模型(SLMs)如GPT-2 Small或LLaMA-7B,检测并移除不重要的标记,将其转换为对人类来说难以理解但对LLMs理解得很好的形式。这种方法为提示压缩提供了一种直接且实用的方法,无需对LLMs进行额外训练,同时平衡了语言完整性和压缩比。PRCA通过训练信息提取器来解决这个问题[69]。同样,RECOMP采用相似的方法,通过对比学习训练信息凝练器[71]。每个训练数据点包括一个正面样本和五个负面样本,编码器在这个过程中使用对比损失进行训练[102]。除了压缩上下文外,减少文档数量也有助于提高模型答案的准确性。Ma等人[103]提出了“过滤器-重新排名”范式,该范式结合了LLMs和SLMs的优势
在这种范式中,SLMs作为过滤器,而LLMs作为重新排序代理。研究表明,指示LLMs重新排列由SLMs识别出的具有挑战性的样本可以显著提高各种信息提取(IE)任务的性能。另一种简单而有效的方法是由LLM在生成最终答案之前评估检索到的内容。这允许LLM通过LLM批评过滤掉相关性差的文档。例如,在Chatlaw[104]中,LLM被提示自我建议参考法律条款以评估其相关性
[70] S. Zhuang, B. Liu, B. Koopman, and G. Zuccon, “Open-source large language models are strong zero-shot query likelihood models for document ranking,” arXiv preprint arXiv:2310.13243, 2023.
[12] V. Blagojevi, “Enhancing rag pipelines in haystack: Introducing diversityranker and lostinthemiddleranker,” https://towardsdatascience.com/ enhancing-rag-pipelines-in-haystack-45f14e2bc9f5, 2023.
[99] Y. Gao, T. Sheng, Y. Xiang, Y. Xiong, H. Wang, and J. Zhang, “Chatrec: Towards interactive and explainable llms-augmented recommender system,” arXiv preprint arXiv:2303.14524, 2023.
[103] Y. Ma, Y. Cao, Y. Hong, and A. Sun, “Large language model is not a good few-shot information extractor, but a good reranker for hard samples!” ArXiv, vol. abs/2303.08559, 2023. [Online]. Available: https://api.semanticscholar.org/CorpusID:257532405
B. LLM微调(LLM Fine-tuning)
基于场景和数据特征对LLM进行针对性微调可以产生更好的结果。这也是使用本地LLM的最大优势之一
当LLM在特定领域缺乏数据时,可以通过微调向LLM提供额外的知识
Huggingface的微调数据也可以用作初始步骤
微调的另一个好处是能够调整模型的输入和输出。例如,它可以启用LLM适应特定的数据格式,并按照指示以特定风格生成响应[37]
对于涉及结构化数据的检索任务,SANTA框架[76]实现了三部分训练方案,有效地封装了结构和语义细微差别。初始阶段侧重于检索器,利用对比学习来优化查询和文档嵌入。通过强化学习使LLM输出与人类或检索器偏好对齐是一种潜在的方法。例如,手动注释最终生成的答案,然后通过强化学习提供反馈。除了与人类偏好对齐外,还可以与微调模型和检索器的偏好对齐[79]
当情况阻止使用强大的专有模型或更大的参数开源模型时,一个简单有效的方法是由更强大的模型(例如GPT-4)进行蒸馏。LLM的微调也可以与检索器的微调协调一致,以对齐偏好。一个典型的方法,如RA-DIT[27],使用KL散度对齐检索器和生成器之间的评分函数
[37] X. Du and H. Ji, “Retrieval-augmented generative question answering for event argument extraction,” arXiv preprint arXiv:2211.07067, 2022.
[76] X. Li, Z. Liu, C. Xiong, S. Yu, Y. Gu, Z. Liu, and G. Yu, “Structureaware language model pretraining improves dense retrieval on structured data,” arXiv preprint arXiv:2305.19912, 2023.
[79] T. Shi, L. Li, Z. Lin, T. Yang, X. Quan, and Q. Wang, “Dual-feedback knowledge retrieval for task-oriented dialogue systems,” arXiv preprint arXiv:2310.14528, 2023.
在RAG中的增强过程(AUGMENTATION PROCESS IN RAG)
在RAG领域中,通常的做法是执行单一的(一次)检索步骤,然后进行生成,这可能导致效率低下,有时对于需要多步推理的复杂问题来说通常是不够的,因为它提供的信息范围有限[105]。为了解决这个问题,许多研究优化了检索过程,在图5中总结了这些内容
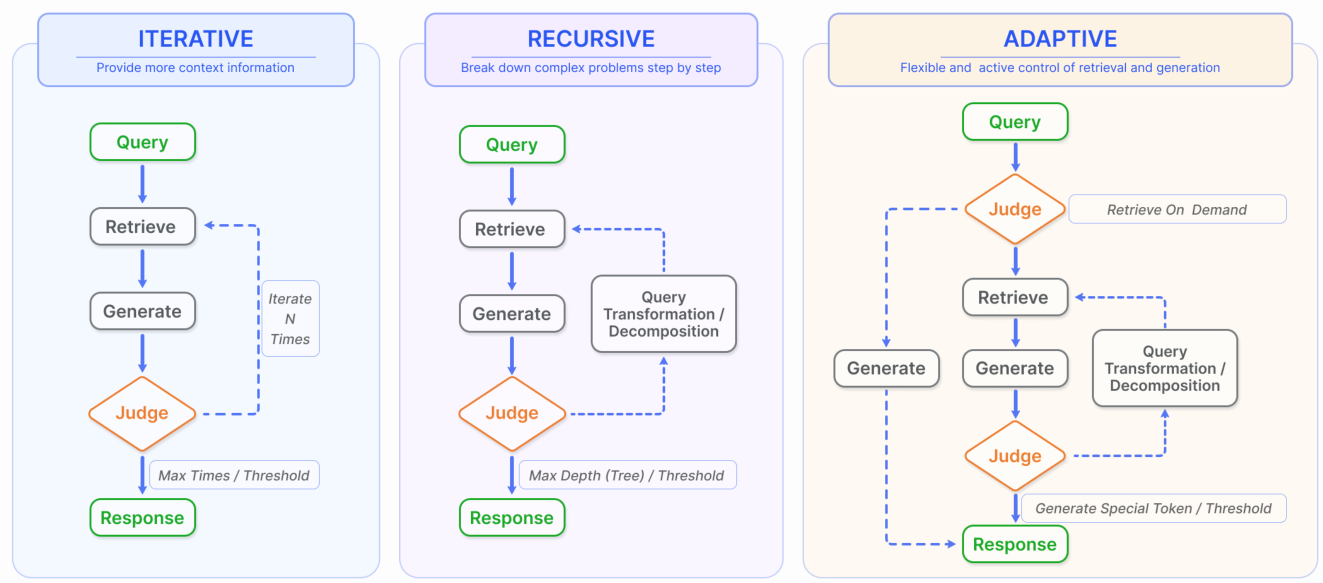
图5.除了最常见的一次检索之外,RAG还包括三种类型的检索增强过程。 (左)迭代检索涉及检索和生成之间的交替,允许在每一步从知识库中获得更丰富、更有针对性 的上下文。 (中)递归检索涉及逐步细化用户查询并将问题分解为子问题,然后通过检索和生成不断解决复杂问题。 (右)自适应检索的重点是使 RAG 系统能够自主确定是否需要外部知识检索以及何时停止检索和生成,通常利用 LLM 生成的特殊令牌进行控制
A. 迭代检索(Iterative Retrieval)
迭代检索是一个过程,在这个过程中,基于初始查询和迄今为止生成的文本,知识库被重复搜索,为LLMs提供了更全面的知识基础
这种方法通过多次检索迭代提供额外的上下文参考,增强了随后答案生成的鲁棒性
然而,它可能受到语义不连续性和无关信息累积的影响
ITERRETGEN[14]采用了一种协同方法,利用“检索增强的生成”和“生成增强的检索”,用于需要复制特定信息的任务。该模型利用解决输入任务所需的内容作为检索相关知识的上下文基础,这反过来又促进了后续迭代中改进响应的生成
B. 递归检索(Recursive Retrieval)
递归检索通常用于信息检索和NLP中,以提高搜索结果的深度和相关性。该过程涉及根据先前搜索获得的结果迭代细化搜索查询。递归检索旨在通过反馈循环逐步汇聚到最相关的信息,从而增强搜索体验
IRCoT[61]使用思维链来指导检索过程,并使用获得的检索结果细化思维链
[61] H. Trivedi, N. Balasubramanian, T. Khot, and A. Sabharwal, “Interleaving retrieval with chain-of-thought reasoning for knowledge-intensive multi-step questions,” arXiv preprint arXiv:2212.10509, 2022.
ToC[57]创建了一个澄清树,系统地优化了查询中的模糊部分。它在复杂的搜索场景中特别有用,其中用户的需求从一开始就不是完全清晰的,或者寻找的信息非常专业化或微妙。该过程的递归性质允许持续学习和适应用户的需求,通常导致对搜索结果的满意度提高。为了解决特定的数据场景,递归检索和多跳检索技术一起使用
[57] G. Kim, S. Kim, B. Jeon, J. Park, and J. Kang, “Tree of clarifications: Answering ambiguous questions with retrieval-augmented large language models,” arXiv preprint arXiv:2310.14696, 2023.
递归检索涉及使用结构化索引以分层方式处理和检索数据,这可能包括在基于此摘要执行检索之前摘要文档的部分或冗长的PDF。随后,在文档内的二次检索细化了搜索,体现了过程的递归性质
相比之下,多跳检索旨在深入到图结构化数据源中,提取相互关联的信息[106]
[106] X. Li, R. Zhao, Y. K. Chia, B. Ding, L. Bing, S. Joty, and S. Poria, “Chain of knowledge: A framework for grounding large language models with structured knowledge bases,” arXiv preprint arXiv:2305.13269, 2023.
搜索结果: 1. 全部搜索结果: 1
C. 自适应检索(Adaptive Retrieval)
自适应检索方法,如Flare[24]和Self-RAG[25],通过使LLMs能够主动确定检索的最佳时刻和内容,从而增强了RAG框架,提高了信息来源的效率和相关性
[24] Z. Jiang, F. F. Xu, L. Gao, Z. Sun, Q. Liu, J. Dwivedi-Yu, Y. Yang, J. Callan, and G. Neubig, “Active retrieval augmented generation,” arXiv preprint arXiv:2305.06983, 2023.
[25] A. Asai, Z. Wu, Y. Wang, A. Sil, and H. Hajishirzi, “Self-rag: Learning to retrieve, generate, and critique through self-reflection,” arXiv preprint arXiv:2310.11511, 2023.
这些方法是更广泛趋势的一部分,其中LLMs在操作中采用主动判断,如AutoGPT、Toolformer和GraphToolformer[107]–[109]等模型代理
例如,Graph-Toolformer将其检索过程分为不同的步骤,其中LLMs主动使用检索器,应用Self-Ask技术,并使用少样本提示启动搜索查询。这种主动立场允许LLMs决定何时搜索所需信息,类似于代理如何使用工具
WebGPT[110]集成了一个强化学习框架,训练GPT-3模型在文本生成期间自主使用搜索引擎。它使用特殊标记来引导这个过程,这些标记有助于执行搜索引擎查询、浏览结果和引用参考资料等操作,从而通过使用外部搜索引擎扩展了GPT-3的功能
Flare通过监控生成过程中的置信度来自动化定时检索,如生成术语的概率所示[24]。当概率低于某个阈值时将激活检索系统以收集相关信息,从而优化检索周期
Self-RAG[25]引入了“反思标记”,允许模型自省其输出。这些标记有两种变体:“检索”和“批评”。模型可以自主决定何时激活检索,或者由预设的阈值触发该过程。在检索期间,生成器在多个段落上进行片段级束搜索,以得出最连贯的序列。批评分数用于更新细分分数,具有在推理期间调整这些权重的灵活性,定制模型的行为。Self-RAG的设计消除了对额外分类器或依赖自然语言推理(NLI)模型的需求,从而简化了决策过程,提高了模型在生成准确响应时的自主判断能力
任务和评估(TASK AND EVALUATION)
RAG在自然语言处理(NLP)领域的快速发展和日益增长的应用推动了LLM社区对RAG模型评估的重视。本章将主要介绍RAG的主要下游任务、数据集以及如何评估RAG系统
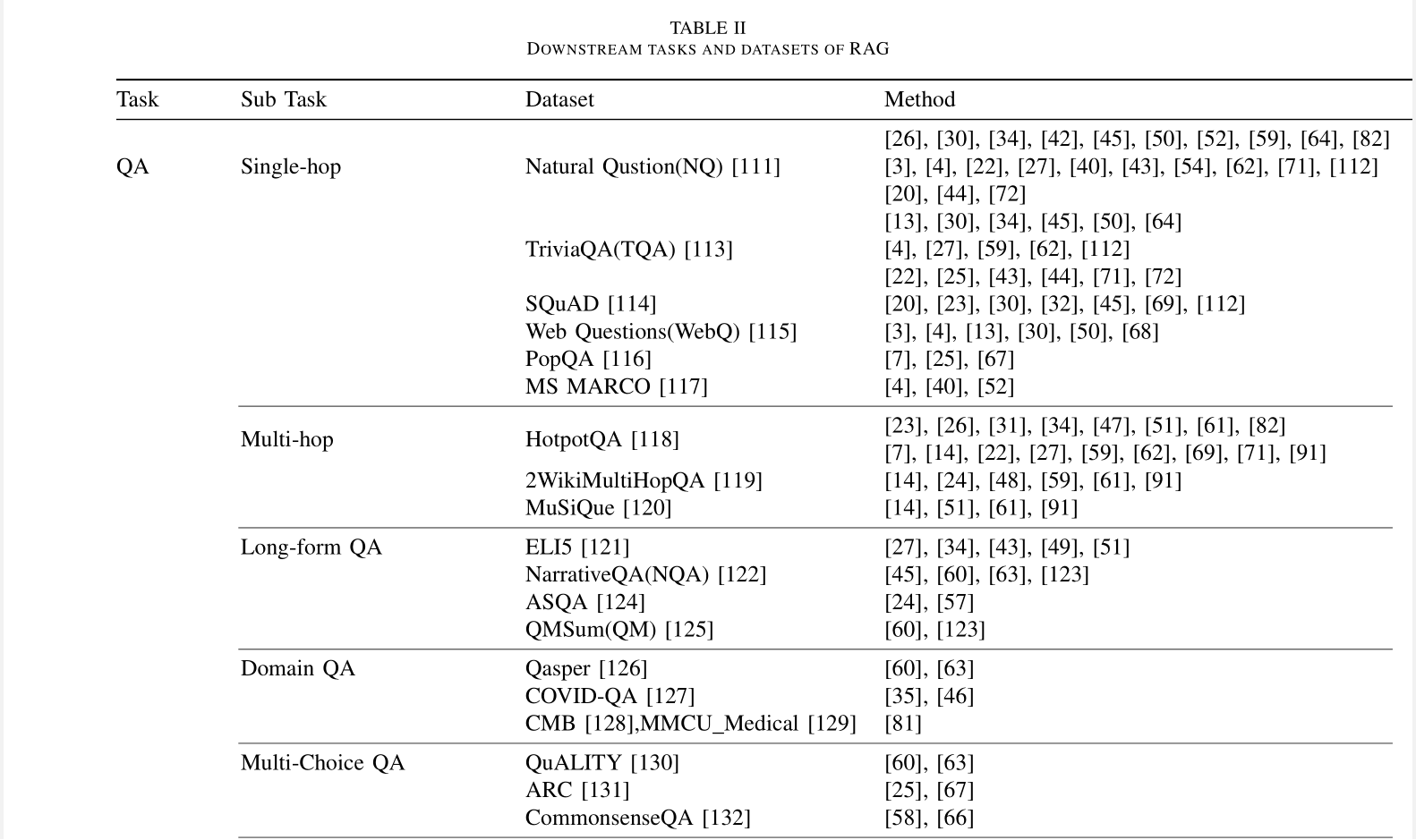
A. 下游任务(Downstream Task)
RAG的核心任务仍然是问答(QA),包括传统的单跳/多跳QA、多项选择、特定领域的QA以及适合RAG的长形场景
除了QA,RAG还在不断地扩展到多个下游任务,如信息提取(IE)、对话生成、代码搜索等
RAG的主要下游任务及其对应的数据集在表II中进行了总结
B. 评估目标(Evaluation Target)
历史上,RAG模型的评估主要集中在它们在特定下游任务中的执行情况这些评估采用适合手头任务的既定指标
例如,问答评估可能依赖于精确度(EM)和F1分数[7]、[45]、[59]、[72],而事实核查任务通常以准确度作为主要指标[4]、[14]、[42]
BLEU和ROUGE指标也常用于评估答案质量[26]、[32]、[52]、[78]
像RALLE这样的工具,旨在自动评估RAG应用,同样基于这些任务特定的指标进行评估[160]
[160] Y. Hoshi, D. Miyashita, Y. Ng, K. Tatsuno, Y. Morioka, O. Torii, and J. Deguchi, “Ralle: A framework for developing and evaluating retrieval-augmented large language models,” arXiv preprint arXiv:2308.10633, 2023.
尽管如此,专门评估RAG模型独特特性的研究还相对缺乏。主要的评估目标包括:
检索质量:评估检索质量对于确定检索组件获取的上下文的有效性至关重要。采用搜索引擎、推荐系统和信息检索系统中的标准指标来衡量RAG检索模块的性能。通常使用诸如命中率、MRR(平均准确率)和NDCG(归一化折损累积增益)等指标[161]、[162]
生成质量:生成质量的评估集中在生成器从检索到的上下文中合成连贯且相关答案的能力上。这种评估可以根据内容的目标进行分类:未标记和已标记内容。对于未标记内容,评估包括生成答案的忠实度、相关性和无害性。相比之下,对于已标记内容,重点是模型产生的信息的准确性[161]
此外,检索和生成质量评估可以通过手动或自动评估方法进行[29]、[161]、[163]
C. 评估方面(Evaluation Aspects)
当代RAG模型的评估实践强调三个主要的质量得分和四个基本能力,这些综合起来对RAG模型的两个主要目标:检索和生成进行评估
- 质量得分:质量得分包括上下文相关性、答案忠实度和答案相关性。这些质量得分从不同的角度评估RAG模型在信息检索和生成过程中的效率[164]–[166]
- 上下文相关性评估检索到的上下文的精确度和特异性,确保相关性并最小化与无关内容相关的处理成本
- 答案忠实度确保生成的答案忠实于检索到的上下文,保持一致性并避免矛盾
- 答案相关性要求生成的答案直接相关于提出的问题,有效解决核心问题
- 所需能力:RAG评估还包括四个能力,这些能力表明其适应性和效率:
- 噪声鲁棒性:评估模型处理与问题相关的噪声文档的能力,这些文档缺乏实质信息
- 负面拒绝:评估模型在检索到的文档不包含回答问题所必需的知识时,克制不回答的能力
- 信息整合:评估模型从多个文档中综合信息以解决复杂问题的能力
- 反事实鲁棒性:测试模型识别和忽略文档中已知不准确性的能力,即使在被告知潜在的错误信息时
上下文相关性和噪声鲁棒性对于评估检索质量很重要,而答案忠实度、答案相关性、否定拒绝、信息集成和反事实鲁棒性对于评估生成质量很重要
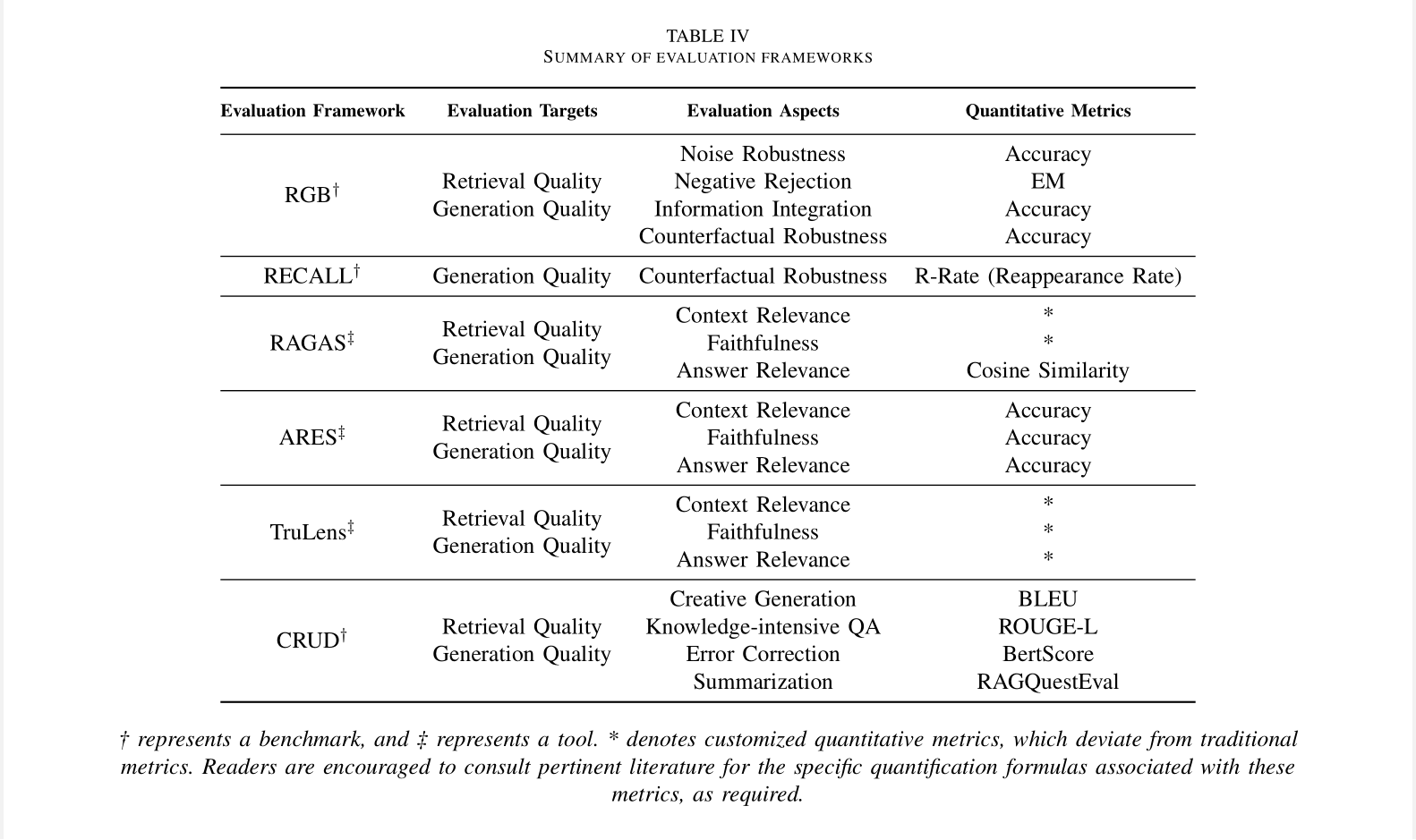
D. 评估基准和工具(Evaluation Benchmarks and Tools)
为了促进RAG的评估,已经提出了一系列基准测试和工具。这些工具提供了量化指标,不仅衡量RAG模型的性能,还增强了对模型在不同评估方面的能力的了解。著名的基准如RGB、RECALL和CRUD[167]–[169]专注于评估RAG模型的基本能力
同时,像RAGAS[164]、ARES[165]和TruLens这样的先进自动化工具利用LLMs来裁定质量得分。这些工具和基准共同构成了一个强大的框架,用于系统地评估RAG模型,如表IV所总结
[164] S. Es, J. James, L. Espinosa-Anke, and S. Schockaert, “Ragas: Automated evaluation of retrieval augmented generation,” arXiv preprint arXiv:2309.15217, 2023.
[165] J. Saad-Falcon, O. Khattab, C. Potts, and M. Zaharia, “Ares: An automated evaluation framework for retrieval-augmented generation systems,” arXiv preprint arXiv:2311.09476, 2023.
讨论与未来展望(DISCUSSION AND FUTURE PROSPECTS)
尽管RAG技术取得了显著进展,但仍然存在一些挑战,需要深入研究。本章将主要介绍RAG目前面临的挑战和未来的研究方向
A. RAG与长上下文(RAG vs Long Context)
随着相关研究的深入,LLMs的上下文不断扩展[170]–[172]。目前,LLMs可以轻松处理超过200,000个标记的上下文。这种能力意味着,以前依赖RAG的长文档问答,现在可以将整个文档直接纳入提示。这也引发了关于在LLMs不受上下文限制的情况下,RAG是否仍然必要的讨论
实际上,RAG仍然发挥着不可替代的作用。一方面,一次性提供大量上下文会显著影响其推理速度,而分块检索和按需输入可以显著提高操作效率
另一方面,基于RAG的生成可以快速定位LLMs的原始参考资料,帮助用户验证生成的答案
整个检索和推理过程是可观察的,而仅依赖长上下文的生成仍然是一个黑箱
相反,上下文的扩展为RAG的发展提供了新的机会,使其能够解决更复杂的问题和需要阅读大量材料来回答的整合或总结性问题[49]
在超长上下文中开发新的RAG方法,是未来研究的一个趋势
B. RAG鲁棒性(RAG Robustness)
检索过程中存在的噪声或矛盾信息可能对RAG的输出质量产生不利影响。这种情况被形象地称为“错误的信息可能比没有信息更糟糕”
提高RAG对这种对抗性或反事实输入的抵抗力,正在获得研究动力,并已成为关键的性能指标[48],[50],[82]。Cuconasu等人[54]分析了应该检索哪些类型的文档,评估了文档与提示的相关性、它们在上下文中的位置以及包含在上下文中的数量。研究发现,包括无关文档可以意外地将准确性提高30%以上,这与最初降低质量的假设相矛盾。这些结果强调了开发将检索与语言生成模型整合的专门策略的重要性,突出了对RAG鲁棒性进行进一步研究和探索的必要性
C. 混合方法(Hybrid Approaches)
将RAG与微调相结合,正在成为一种领先的策略
确定RAG和微调的最佳整合方式,无论是顺序、交替还是通过端到端联合训练,以及如何利用参数化和非参数化的优势,都是值得探索的领域[27]
另一种趋势是将具有特定功能的小型语言模型(SLMs)引入RAG,并由RAG系统的结果进行微调
例如,CRAG[67]训练了一个轻量级检索评估器,用于评估查询的检索文档的整体质量,并根据置信度触发不同的知识检索操作
[67] S.-Q. Yan, J.-C. Gu, Y. Zhu, and Z.-H. Ling, “Corrective retrieval augmented generation,” arXiv preprint arXiv:2401.15884, 2024.
D. RAG的扩展法则(Scaling laws of RAG)
基于RAG的端到端模型和预训练模型仍然是当前研究者的焦点[173]。这些模型的参数是关键因素之一。虽然为LLMs建立了扩展法则[174],但它们对RAG的适用性仍然不确定
像RETRO++ [44]这样的初步研究已经开始解决这个问题,但RAG模型的参数数量仍然落后于LLMs
特别引人注目的是,较小的模型在某些情况下可能优于较大模型的“逆扩展法则”,值得进一步研究
E. 生产就绪的RAG(Production-Ready RAG)
RAG的实用性和与工程要求的一致性促进了它的采用
然而,提高检索效率、改善大型知识库中的文档召回率以及确保数据安全(例如防止LLMs无意中披露文档来源或元数据)是关键的工程挑战,仍需解决[175]
RAG生态系统的发展在很大程度上受到其技术栈进展的影响。像LangChain和LlamaIndex这样的关键工具在ChatGPT出现后迅速流行起来,提供了广泛的RAG相关的API,并成为LLM领域的重要组成部分
新兴的技术栈虽然在功能上不如LangChain和LlamaIndex丰富,但通过其专业产品脱颖而出。例如,Flowise AI优先考虑低代码方法,允许用户通过用户友好的拖放界面部署包括RAG在内的AI应用
其他技术如HayStack、Meltano和Cohere Coral也因其对该领域的独有贡献而受到关注
除了AI专业供应商外,传统的软件和云服务提供商也在扩展他们的产品,包括以RAG为中心的服务。Weaviate的Verba 11专为个人助理应用设计,而Amazon的Kendra 12提供智能企业搜索服务,使用户能够使用内置连接器浏览各种内容库
在RAG技术的发展中,明显的趋势是朝着不同的专业化方向发展,例如:1) 定制化 - 根据特定要求定制RAG。2) 简化 - 使RAG更易于使用,降低初始学习曲线。3) 专业化 - 优化RAG以更好地服务于生产环境
RAG模型及其技术栈的相互成长是显而易见的;技术进步不断为现有基础设施建立新标准。反过来,技术栈的增强推动了RAG能力的发展。RAG工具包正在汇聚成一个基础技术栈,为高级企业应用奠定基础。然而,一个完全集成、全面平台的概念仍在未来,需要进一步的创新和发展
F. 多模态RAG(Multi-modal RAG)
RAG已经超越了最初的基于文本的问答限制,拥抱了多样化的模态数据。这种扩展催生了创新的多模态模型,这些模型将RAG概念整合到各个领域
图像。RA-CM3 [176]是同时检索和生成文本和图像的开创性多模态模型。BLIP-2 [177]利用冻结的图像编码器和LLMs进行高效的视觉语言预训练,实现了零样本图像到文本的转换。“先可视化再写作”方法[178]利用图像生成引导LM的文本生成,在开放式文本生成任务中显示出前景
音频和视频。GSS方法检索并拼接音频剪辑,将机器翻译数据转换为语音翻译数据[179]。UEOP在端到端自动语音识别中标志着一个重要的进步,通过采用外部、离线策略进行语音到文本的转换[180]
此外,基于KNN的注意力融合利用音频嵌入和语义相关的文本嵌入来完善ASR,从而加速领域适应。Vid2Seq通过添加专门的时间标记来增强语言模型,促进了事件边界和文本描述的预测[181]
代码。RBPS [182]通过编码和频率分析检索与开发人员目标一致的代码示例,在小规模学习任务中表现出色。这种方法在测试断言生成和程序修复等任务中证明了其有效性。对于结构化知识,CoK方法[106]首先从知识图中提取与输入查询相关的事实,然后将这些事实作为提示集成到输入中,提高了知识图谱问答任务的性能
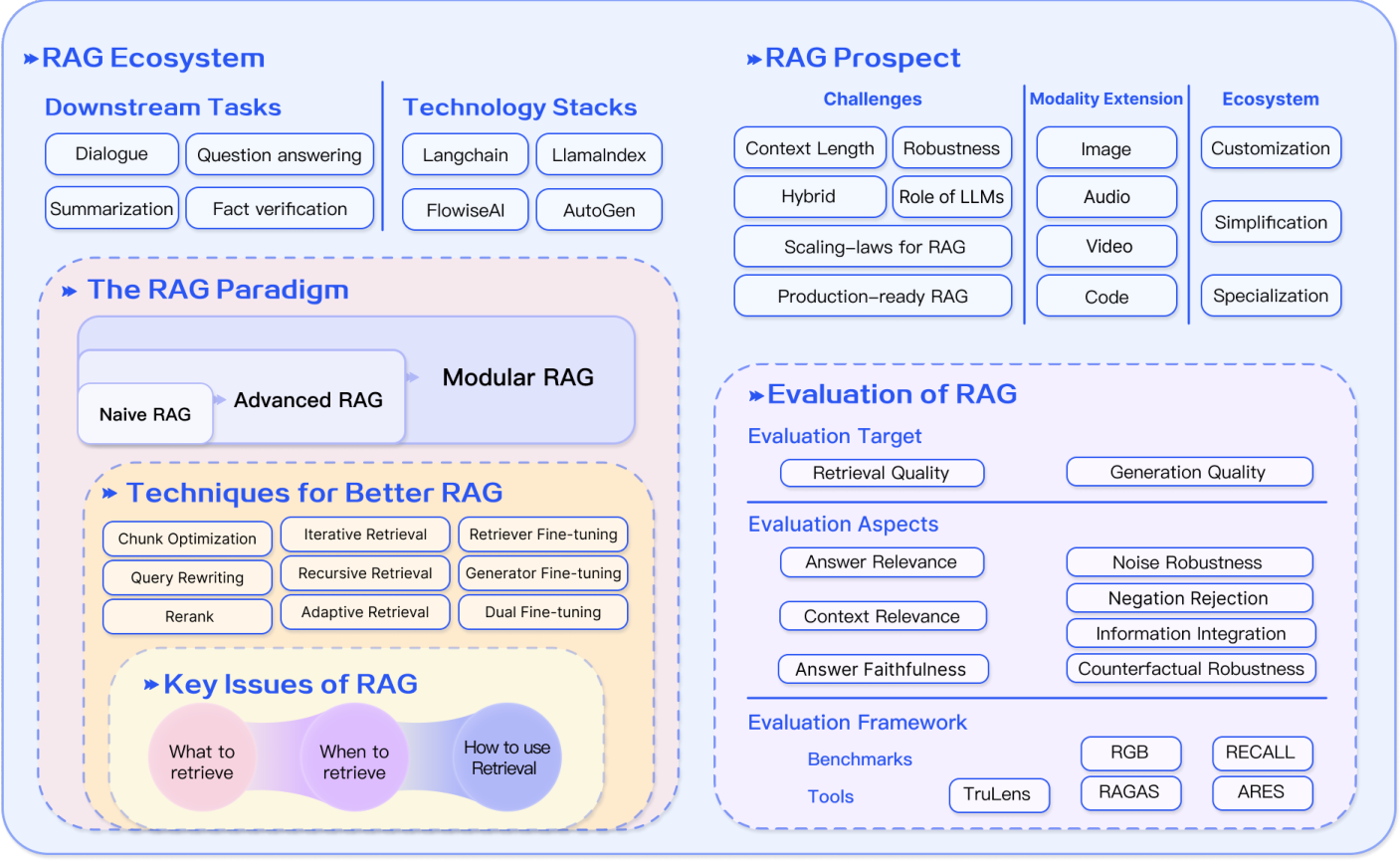
图 6. RAG 生态系统概述
FaaF:RAG系统评估的事实函数
FaaF: Facts as a Function for the evaluation of RAG systems
[2403.03888] FaaF: Facts as a Function for the evaluation of RAG systems (arxiv.org)
检索增强生成系统:自动数据集创建、评估和布尔代理设置
Retrieval Augmented Generation Systems: Automatic Dataset Creation, Evaluation and Boolean Agent Setup
Multi-Head RAG: Solving Multi-Aspect Problems with LLMs(多头 RAG:使⽤ LLMs 解决多⽅⾯问题)
2024-06-07
http://arxiv.org/abs/2406.05085
现有的 RAG 解决方案并不关注可能需要获取内容截然不同的多个文档的查询.此类查询经常发⽣,但具有挑战性,因为这些⽂档的嵌⼊在嵌⼊空间中可能很远,因此很难将它们全部检索出来
本⽂介绍了多头 RAG (MRAG),这是⼀种新颖的⽅案,旨在通过⼀个简单⽽强⼤的想法来解决这⼀差距:利⽤ Transformer 的多头注意⼒层(⽽不是解码器层)的激活作为获取多⽅⾯⽂档的密钥
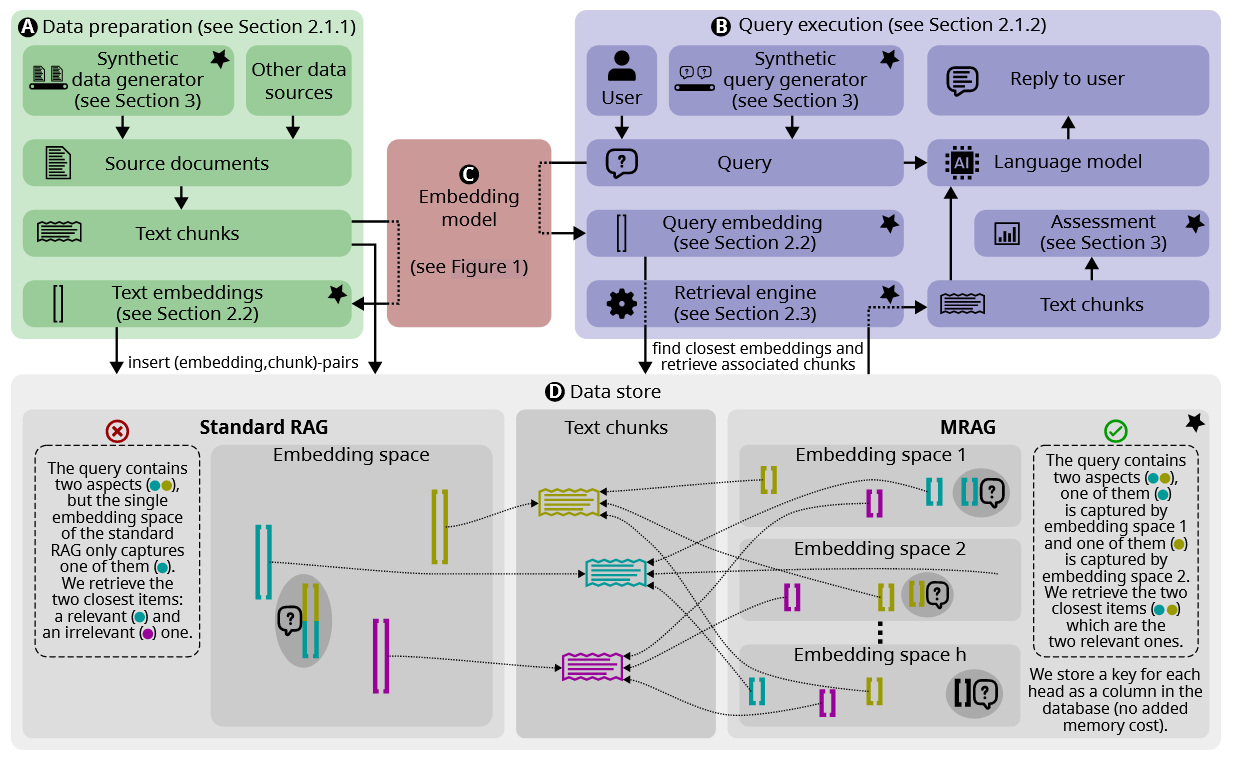
图2:MRAG管道概述,由两部分组成:数据准备和查询执⾏。两个部分都使⽤嵌⼊模型和数据存储。数据存储包含链接到反映三个不同⽅⾯(⻘⾊、洋红⾊、⻩⾊)的⽂本块的⽂本嵌⼊。⽤星号标记的块是这项⼯作的新颖之处
最近出现了许多 RAG ⽅案 [10],使⽤最后⼀个解码器层的输出进⾏嵌⼊⽣成。相⽐之下,MRAG利⽤注意⼒头的不同嵌⼊空间来关注⽂档和查询的不同⽅⾯。因此,它可以与其他⽅案结合以进⼀步改进 RAG 管道。
有时,交叉编码器重新排序阶段可以增强检索能⼒ [9, 19, 22, 26, 27, 30]。在此类解决⽅案中,通常在检索⼀组相关块后,使⽤专⻔的模型对它们重新排序。在这项⼯作中,只关注第⼀个检索阶段,因此 MRAG 可以与此类交叉编码器⽆缝结合使⽤。
结构增强的 RAG ⽅案采⽤不同的策略来构建⽂本以提⾼检索质量。⼀个常⻅的想法是从⽂本构建知识图,这使得能够在实体和关系之间进⾏检索[3,6,16,17,37]。 RAPTOR [31] 为相关块的集群⽣成多级摘要,构建具有不断增加的抽象级别的摘要树,以更好地捕获⽂本的含义。 Graph RAG [7] 创建了⼀个知识图,并总结了图中的社区,这些社区提供了不同抽象级别的数据。所有这些系统都试图通过利⽤描述实体关系或⽂本内部组织的附加结构来提⾼ RAG 质量。通常,他们需要复杂的预处理阶段来准备此类结构。 MRAG仅基于嵌⼊模型实现改进,没有额外的存储需求,并且可以与这些⽅案中的任何⼀种结合
源码
RAPTOR: Recursive Abstractive Processing for Tree-Organized Retrieval (RAPTOR:用于树组织检索的递归抽象处理)
2024-01-31
RAPTOR: Recursive Abstractive Processing for Tree-Organized Retrieval (arxiv.org)
摘要
检索增强语言模型可以更好地适应世界状态的变化并融入长尾知识。然而,大多数现有方法仅从检索语料库中检索短的连续块,限制了对整个文档上下文的整体理解。引入了递归嵌入、聚类和总结文本块的新颖方法,从下到上构建具有不同摘要级别的树。在推理时,RAPTOR 模型从这棵树中检索,在不同抽象级别集成冗长文档中的信息。对照实验表明,在多项任务上,递归摘要检索比传统检索增强型语言模型有显着改进。在涉及复杂、多步骤推理的问答任务中,展示了最先进的结果;例如,通过将 RAPTOR 检索与 GPT-4 结合使用,可以将 QuALITY 基准的最佳性能绝对准确率提高 20%
长尾知识:
长尾知识(Long-tail Knowledge)是一个概念,它描述了在特定领域或主题中那些不是非常常见或广泛讨论的知识。这个术语通常与语言模型和信息检索系统相关,用来强调这些系统在处理大量、多样化和非主流信息时的能力
以下是长尾知识的一些关键点:
- 非主流信息:长尾知识通常指的是那些在主流讨论中不常出现的信息。这些信息可能涉及非常具体或专业的主题,或者是那些只有少数人感兴趣的领域
- 广泛性和多样性:长尾知识强调的是知识的广泛性和多样性,而不是仅仅集中在最常见的主题上。这意味着系统需要能够处理从非常普遍到非常罕见的各种信息
- 语言模型的挑战:对于语言模型来说,理解和生成长尾知识是一个挑战。因为这些模型通常是通过大量文本数据训练的,而这些文本数据可能主要集中在常见的语言模式和主题上。因此,当涉及到长尾知识时,模型可能无法生成准确或相关的信息
- 检索系统的重要性:在信息检索系统中,长尾知识的概念强调了检索系统需要能够从大量的文本中检索出那些不那么常见的信息。这对于提供全面和准确的答案至关重要,尤其是在处理复杂问题或需要深入理解特定领域的情境中
- 更新和维护:长尾知识还涉及到知识的更新和维护问题。随着时间的推移,某些知识可能会变得过时或不再相关,因此系统需要能够不断更新其知识库,以包含最新的信息
在论文 "RAPTOR: RECURSIVE ABSTRACTIVE PROCESSING FOR TREE-ORGANIZED RETRIEVAL" 中,作者提到长尾知识是为了强调他们的模型在处理那些需要从大量文本中检索出不常见信息的任务时的优势。通过使用递归摘要和树状结构,RAPTOR 能够更好地理解和整合这些长尾知识,从而在复杂问题的回答中表现出色
简介
大型语言模型 (LLMs) 已成为变革性工具,在许多任务上显示出令人印象深刻的性能。随着 LLMs 规模的不断扩大,它们可以独立作为非常有效的知识存储,并在其参数中编码事实(Petroni 等人,2019;Jiang 等人,2020;Talmor 等人,2020) ;Rae 等人,2021;Chowdhery 等人,2022;Bubeck 等人,2023)并且可以通过对下游任务进行微调来进一步改进模型(罗伯茨等人,2020)。然而,即使是大型模型也不包含针对特定任务的足够的特定领域知识,并且世界在不断变化,从而使 LLM 中的事实无效。通过额外的微调或编辑来更新这些模型的知识是很困难的,特别是在处理大量文本语料库时(Lewis 等人,2020;Mitchell 等人,2022)。另一种方法是在开放域问答系统中首创的(Chen 等人,2017 年;Yu 等人,2018 年),即在单独的信息检索系统中将大量文本分割成块(段落)后对其进行索引。然后,检索到的信息连同作为上下文的问题一起呈现给 LLM(“检索增强”,Lewis 等人,2020;Izacard 等人,2022;Min 等人,2023;Ram 等人) ., 2023),使得可以轻松地为系统提供特定于某些领域的当前知识,并实现轻松的可解释性和出处跟踪,而 LLMs 的参数化知识是不透明的,难以追溯到其来源(阿库雷克等人,2022)
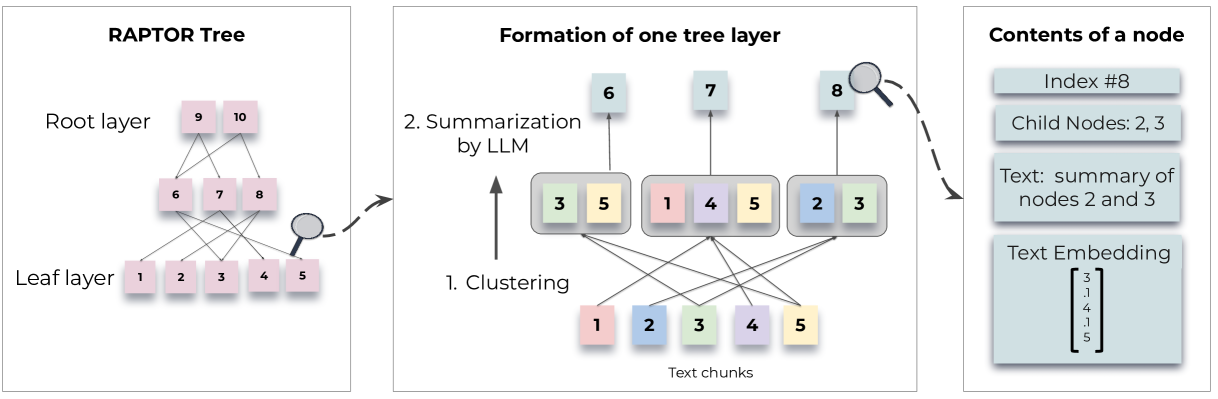
图 1:树构建过程:RAPTOR 根据向量嵌入递归地对文本块进行聚类,并生成这些聚类的文本摘要,从而自下而上构建树。聚集在一起的节点是兄弟节点;父节点包含该集群的文本摘要
解决的问题/现有方法的不足:
大多数现有方法仅检索一些短的、连续的文本块,这限制了它们表示和利用大规模话语结构的能力。这对于需要整合文本多个部分的知识的主题问题尤其相关,例如理解整本书,如 NarrativeQA 数据集。考虑一下灰姑娘的童话故事,以及“灰姑娘是如何达到幸福结局的?”这个问题。顶部 𝑘 检索到的短连续文本将不包含足够的上下文来回答问题
解决方法:
设计了一个索引和检索系统,该系统使用树结构来捕获有关文本的高级和低级详细信息。如图 1 所示,RAPTOR 对文本块进行聚类,生成这些聚类的文本摘要,然后重复,从下到上生成一棵树。这种结构使 RAPTOR 能够加载到 LLM 的上下文块中来表示不同级别的文本,以便它可以有效且高效地回答不同级别的问题
相关工作
连续分割可能无法捕获文本的完整语义深度。阅读从技术或科学文档中提取的片段可能会缺乏重要的上下文,导致它们难以阅读甚至产生误导
方法
分块
首先将检索语料库分割成长度为 100 的短连续文本,类似于传统的检索增强技术
如果一个句子超过 100 个标记的限制,会将整个句子移动到下一个块,而不是在句子中间剪切它(保留了每个块中文本的上下文和语义连贯性)
嵌入:
SBERT(multi-qa-mpnet-base-cos-v1)嵌入
这些块及其相应的 SBERT 嵌入形成了树结构的叶节点
聚类:
为了对相似的文本块进行分组,采用聚类算法。聚类后,语言模型总结分组的文本。然后重新嵌入这些总结的文本,嵌入、聚类和总结的循环继续进行,直到进一步的聚类变得不可行,从而产生原始文档的结构化、多层树表示
聚类算法
集群方法的独特之处之一是使用软集群,其中节点可以属于多个集群,而不需要固定数量的集群。这种灵活性至关重要,因为各个文本片段通常包含与各种主题相关的信息,从而保证将它们包含在多个摘要中
聚类算法基于高斯混合模型 (GMM),这种方法既提供灵活性又提供概率框架。 GMM 假设数据点是由多个高斯分布的混合生成的
给定一组文本段,每个文本段表示为维密集向量嵌入,文本向量的可能性 x,考虑到它的成员资格高斯分布由表示。总体概率分布是加权组合 ,其中表示高斯分布的混合权重
高斯混合模型 (GMM)
高斯混合模型(Gaussian Mixture Model,简称 GMM)是一种概率模型,它假设所有的数据点都是来自多个高斯分布(正态分布)的混合。GMM 是有限混合模型的一种,它通过结合多个简单的分布来拟合更复杂的分布
以下是 GMM 的一些关键特点:
- 混合分布:GMM 由多个高斯分布组成,每个高斯分布称为一个组件(component)或簇(cluster)
- 概率密度函数:GMM 的概率密度函数是其各个高斯成分的概率密度函数的加权和。如果有一个 GMM 包含 ( k ) 个高斯成分,对于任意数据点 ( x ),其概率密度可以表示为:
其中, 是第 个高斯成分的混合权重, 是均值, 是协方差矩阵, 表示正态分布的概率密度函数- 混合权重:每个高斯成分都有一个非负的混合权重,所有权重之和为 1
- 参数估计:GMM 的参数通常通过最大似然估计来确定,常用的算法是期望最大化(Expectation-Maximization,EM)算法
- 软聚类:GMM 提供了一种软聚类方法,即每个数据点可以以不同的概率属于多个高斯成分,这与硬聚类(每个数据点只属于一个簇)不同
- 应用广泛:GMM 在许多领域都有应用,包括模式识别、图像处理、语音识别和自然语言处理等
- 模型选择:确定最佳的高斯成分数量是一个重要的问题,常用的方法包括贝叶斯信息准则(Bayesian Information Criterion,BIC)或赤池信息准则(Akaike Information Criterion,AIC)
- 高维数据挑战:在高维空间中,GMM 可能面临“维度的诅咒”,即随着数据维度的增加,所需的样本量呈指数级增长,这可能导致模型估计不准确
在 RAPTOR 模型中,GMM 被用于文本聚类任务,通过将文本数据点映射到高维空间,并使用 GMM 来发现文本数据中的潜在主题或结构,从而实现文本的层次化组织和检索
向量嵌入的高维性对传统 GMM 提出了挑战,因为当用于测量高维空间中的相似性时,距离度量可能表现不佳(Aggarwal 等人,2001)
为了缓解这个问题,采用了统一流形逼近和投影(UMAP),这是一种用于降维的流形学习技术(McInnes et al., 2018)。 UMAP 中的最近邻居参数 𝑛_𝑛𝑒𝑖𝑔ℎ𝑏𝑜𝑟𝑠 的数量决定了局部结构和全局结构的保留之间的平衡
算法通过𝑛_𝑛𝑒𝑖𝑔ℎ𝑏𝑜𝑟𝑠的变化来创建分层聚类结构:它首先识别全局聚类,然后在这些全局聚类中执行局部聚类。这个两步聚类过程捕获了文本数据之间的广泛关系,从广泛的主题到具体的细节
统一流形逼近和投影(Uniform Manifold Approximation and Projection,简称 UMAP)是一种用于降维的非线性技术,特别是在高维数据的可视化和分析方面表现出色。UMAP 基于以下几个关键概念:
- 流形学习:UMAP 假设高维数据位于低维流形上,即数据点在高维空间中可能看起来分散,但实际上它们位于一个较低维度的结构上
- 邻域图:UMAP 首先在高维空间中构建一个邻域图,该图中的节点表示数据点,边表示数据点之间的邻近关系
- 低维嵌入:UMAP 旨在找到一个低维空间的嵌入,使得这个嵌入能够保留高维空间中邻域图的局部结构
- 交叉熵:UMAP 使用交叉熵作为优化目标,以确保低维嵌入中的点分布与高维空间中的分布尽可能一致
- 随机梯度下降:UMAP 通过随机梯度下降(SGD)来优化嵌入,这使得它在处理大规模数据集时相对高效
- 超参数:UMAP 有几个关键的超参数,包括邻域大小(
n_neighbors)和距离度量(如欧氏距离或余弦相似度)。这些超参数可以显著影响最终的降维结果- 多尺度嵌入:UMAP 可以创建多尺度嵌入,通过在不同的分辨率上探索数据来揭示不同层次的结构
- 应用:UMAP 被广泛应用于各种领域,包括生物信息学、图像分析、推荐系统等,特别是在需要在低维空间中可视化高维数据时
在 RAPTOR 模型中,UMAP 被用于降维处理,以改善高维空间中相似性度量的效率和准确性。通过 UMAP,RAPTOR 能够将文本嵌入向量映射到低维空间,从而更好地捕捉文本数据中的语义结构,这对于后续的聚类和检索步骤至关重要
如果本地集群的组合上下文超过摘要模型的令牌阈值,的算法会在集群内递归应用集群,确保上下文保持在令牌阈值之内
为了确定最佳聚类数量,采用贝叶斯信息准则(BIC)进行模型选择。BIC 不仅会惩罚模型的复杂性,还会奖励拟合优度(Schwarz,1978)。给定 GMM 的 BIC 为 ,其中是文本段 (或数据点)的数量,是模型参数的数量,是模型似然函数的最大值。在 GMM 的上下文中,参数的数量是输入向量的维数和聚类数量的函数
根据 BIC 确定的最佳簇数,然后使用期望最大化算法来估计 GMM 参数,即均值、协方差和混合权重
基于模型的摘要
使用高斯混合模型对节点进行聚类后,每个聚类中的节点被发送到语言模型进行摘要生成
使用 gpt-3.5-turbo
虽然摘要模型通常会生成可靠的摘要,但一项重点注释研究显示,约 4% 的摘要包含轻微的幻觉。这些不会传播到父节点,并且对问答任务没有明显的影响
查询
树遍历和折叠树。树遍历方法逐层遍历树,剪枝并选择每一层最相关的节点。折叠树方法集体评估所有层的节点,以找到最相关的节点
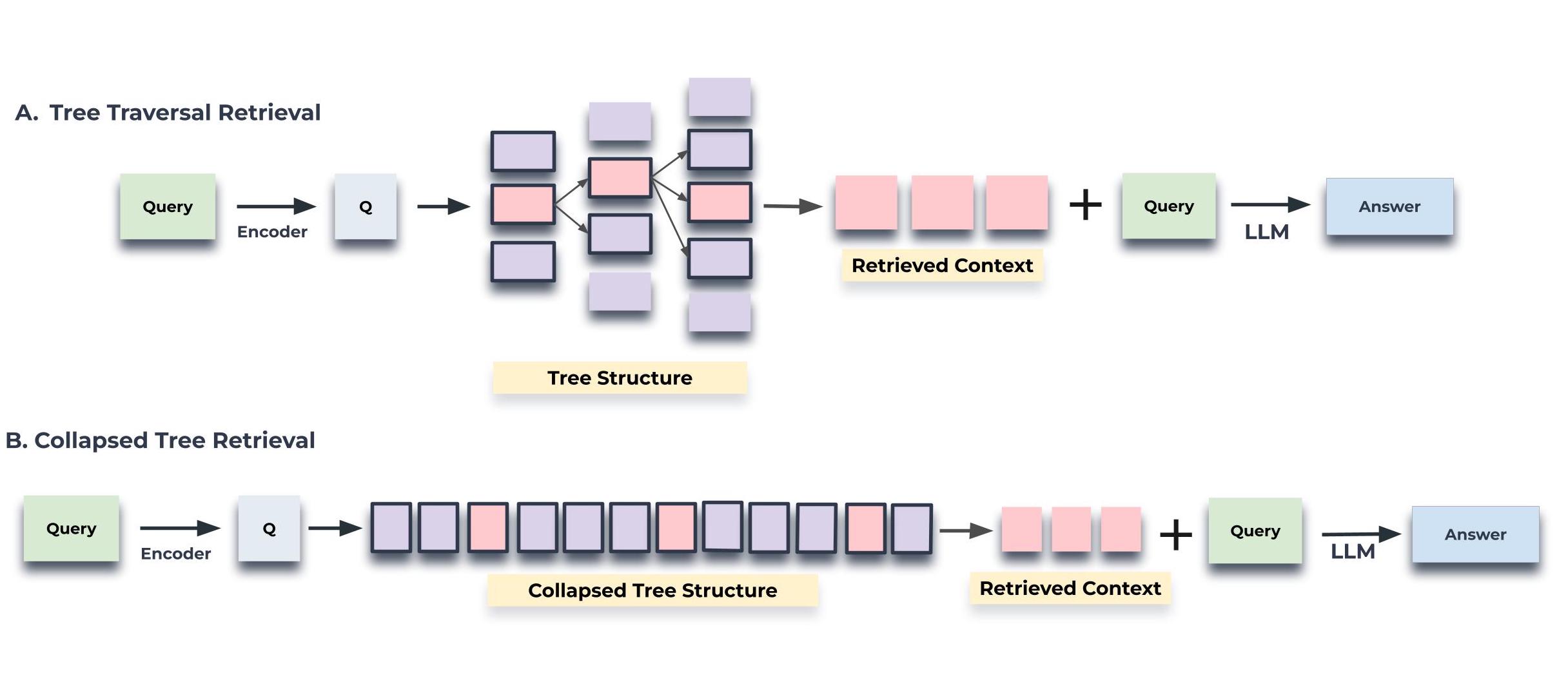 图 2:树遍历和折叠树检索机制的图示。树遍历从树的根级别开始,并根据与查询向量的余弦相似度检索顶部 - 𝑘 (此处为顶部 - 1 )节点。在每个级别,它都会从上一层的 top- 𝑘 的子节点中检索 top- 𝑘 节点。折叠树将树折叠成单层并检索节点,直到基于与查询向量的余弦相似度达到令牌的阈值数量。执行余弦相似度搜索的节点在两个图中都突出显示
图 2:树遍历和折叠树检索机制的图示。树遍历从树的根级别开始,并根据与查询向量的余弦相似度检索顶部 - 𝑘 (此处为顶部 - 1 )节点。在每个级别,它都会从上一层的 top- 𝑘 的子节点中检索 top- 𝑘 节点。折叠树将树折叠成单层并检索节点,直到基于与查询向量的余弦相似度达到令牌的阈值数量。执行余弦相似度搜索的节点在两个图中都突出显示
树遍历
树遍历方法首先根据与查询嵌入的余弦相似度选择前 k 个最相关的根节点。这些选定节点的子节点将在下一层考虑,并根据它们与查询向量的余弦相似度再次从该池中选择前 k 个节点。重复这个过程直到到达叶节点。最后,来自所有选定节点的文本被连接起来以形成检索到的上下文。该算法的步骤概述如下:
- 从 RAPTOR 树的根层开始。计算查询嵌入与该初始层中存在的所有节点的嵌入之间的余弦相似度
- 根据最高余弦相似度分数选择顶部 𝑘 节点,形成集合 𝑆1
- 继续查看集合 𝑆1 中元素的子节点。计算查询向量和这些子节点的向量嵌入之间的余弦相似度
- 选择与查询具有最高余弦相似度分数的顶部 𝑘 子节点,形成集合 𝑆2
- 对 𝑑 层递归地继续此过程,生成集合 𝑆1,𝑆2,…,𝑆𝑑
- 连接集合 𝑆1 到 𝑆𝑑 以将相关上下文组合到查询中
通过调整每层选择的深度 𝑑 和节点数 𝑘 ,树遍历方法可以控制检索信息的特异性和广度。该算法首先考虑树的顶层,从宏观的角度出发,然后随着树的下降到较低层,逐渐关注更精细的细节
折叠树
折叠树方法提供了一种更简单的方法,通过同时考虑树中的所有节点来搜索相关信息,如图 2 所示。该方法不是逐层进行,而是将多层树扁平化为单层,本质上是将所有节点放在同一水平上进行比较
在选择 top-k 节点时,还需要考虑模型输入的最大令牌数限制,确保检索到的文本长度不会超出模型的处理能力
为了提高检索效率,可以使用快速的最近邻库(如 FAISS)来执行相似度搜索
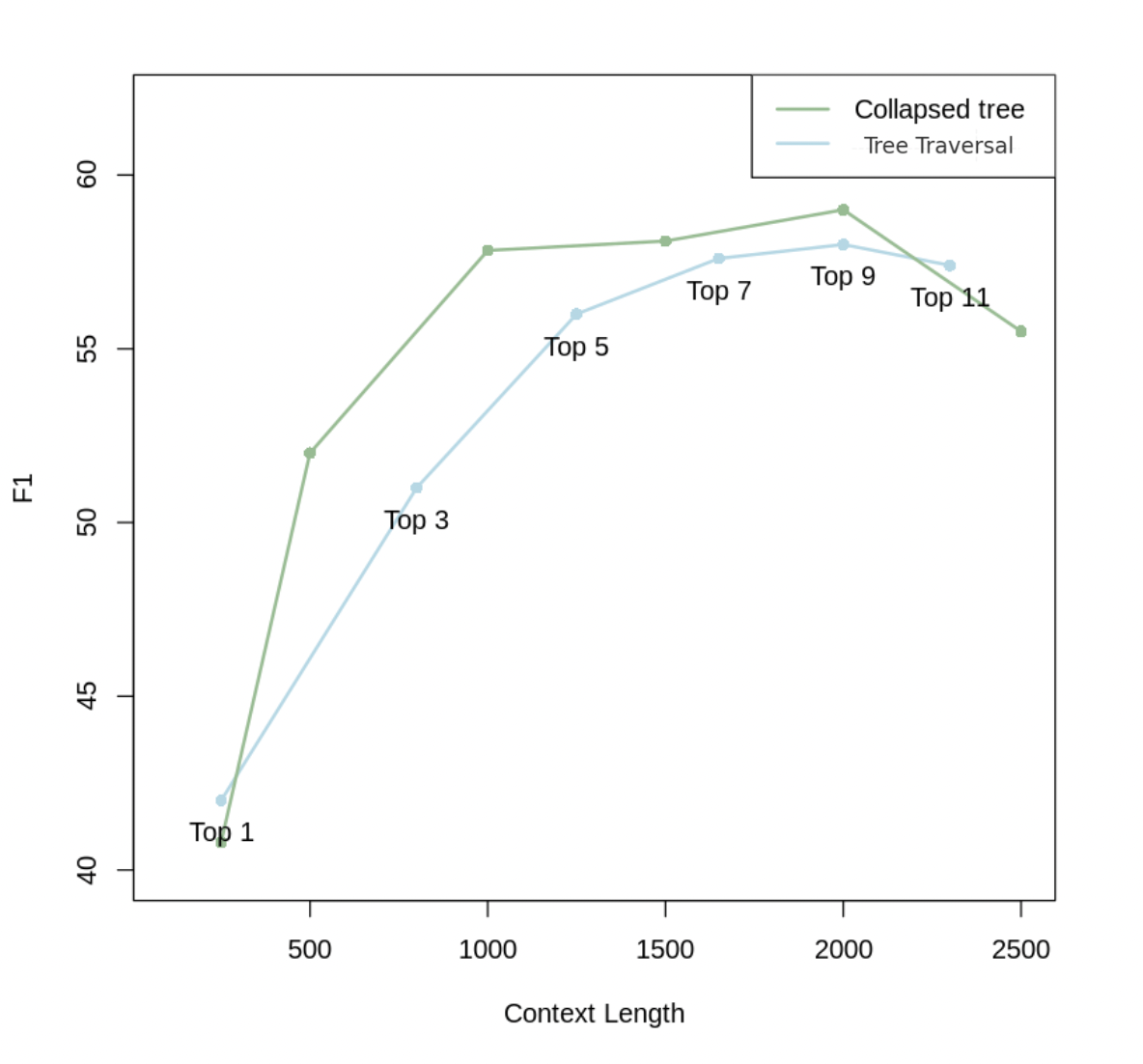 图3:查询方法比较。使用具有不同 top-k 值的树遍历以及具有不同上下文长度的折叠树,对 QASPER 数据集中的 20 个故事进行结果。具有 2000 个标记的折叠树会产生最佳结果,因此对主要结果使用此查询策略
图3:查询方法比较。使用具有不同 top-k 值的树遍历以及具有不同上下文长度的折叠树,对 QASPER 数据集中的 20 个故事进行结果。具有 2000 个标记的折叠树会产生最佳结果,因此对主要结果使用此查询策略
实验
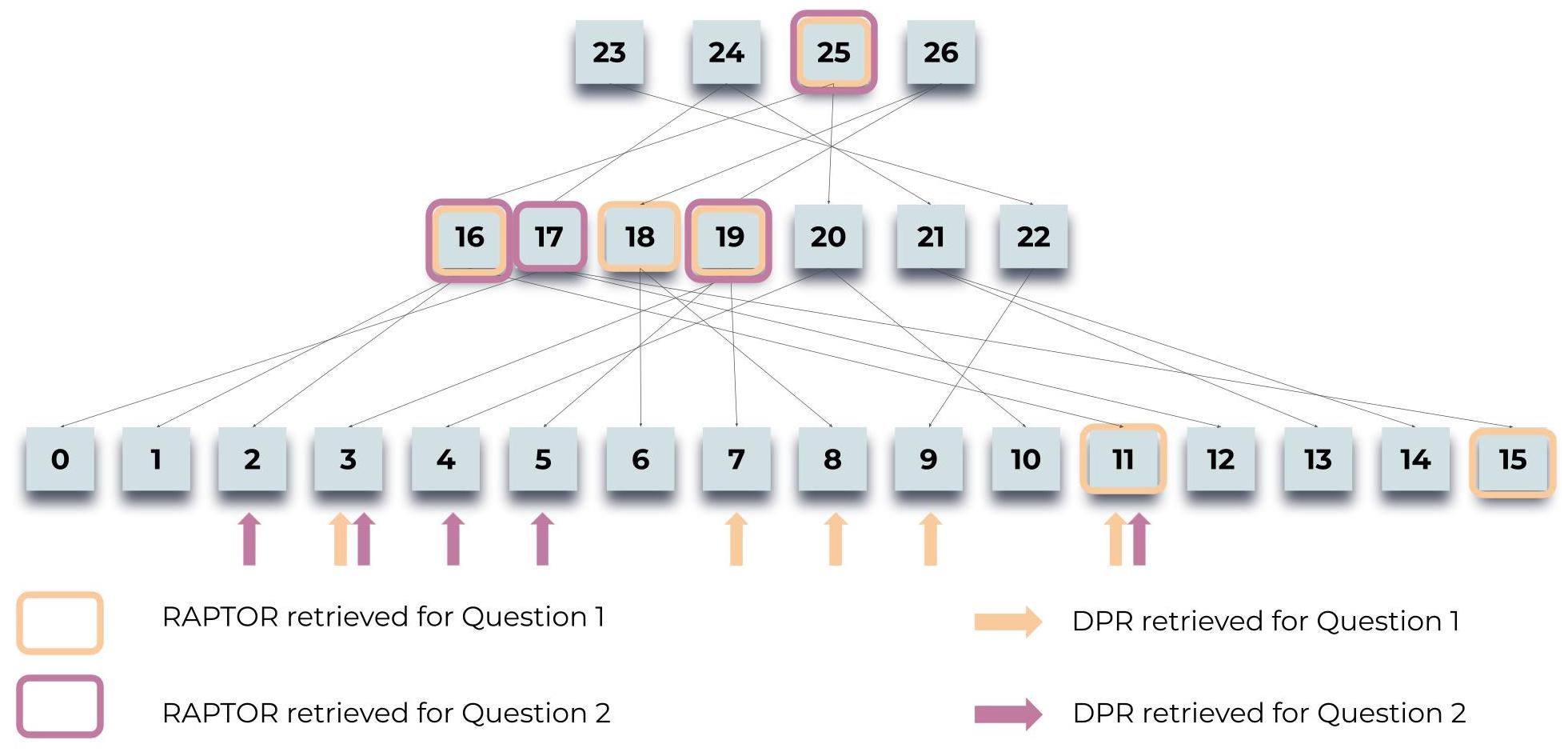
图 4:查询过程:说明 RAPTOR 如何检索有关灰姑娘故事的两个问题的信息:“故事的中心主题是什么?”和“灰姑娘如何找到幸福的结局?”。突出显示的节点表示 RAPTOR 的选择,而箭头指向 DPR 的叶节点。值得注意的是,RAPTOR 的上下文通常包含 DPR 检索到的信息,无论是直接检索的信息还是在更高层摘要中检索的信息
评估数据集
QuALITY
由多项选择题组成,每个问题都附有平均长度约为 5,000 个标记的上下文段落
该数据集要求对整个文档进行推理以执行 QA 任务,使能够衡量检索系统在中等长度文档上的性能
该数据集包括一个具有挑战性的子集 QuALITY-HARD,其中包含大多数人类注释者在速度设置中回答不正确的问题
报告整个测试集和 HARD 子集的准确性
QASPER
Qasper Dataset — Allen Institute for AI (allenai.org)
包含 1,585 篇 NLP 论文中的 5,049 个问题,每个问题都探究嵌入在全文中的信息
QASPER 中的答案类型分为可回答/不可回答、是/否、抽象和提取
准确度使用标准 F1 进行测量
NarrativeQA
包含基于书籍和电影脚本全文的问答对,总计 1,572 个文档
NarrativeQA-Story 任务需要对整个叙述进行全面理解,以便准确回答其问题,从而测试模型理解文学领域较长文本的能力
使用标准 BLEU(B-1、B-4)、ROUGE(R-L)和 METEOR(M)指标来衡量该数据集的性能
源码
Retrieval-Augmented Generation for AI-Generated Content: A Survey(人工智能生成内容的检索增强生成 综述)
2024-06-21
http://arxiv.org/abs/2402.19473
北京大学、腾讯
https://github.com/PKU-DAIR/RAG-Survey
摘要
AIGC的挑战:更新知识、处理长尾数据、数据泄露和高昂成本
RAG的作用:通过检索相关数据增强生成过程,提高准确性和鲁棒性
引言 (INTRODUCTION)
A. 背景
人工智能生成内容(Artificial Intelligence Generated Content, AIGC)
"AIGC"一词强调内容是由先进的生成模型而非人类或基于规则的方法产生的
各种内容生成工具:
- 大型语言模型(Large Language Models, LLMs)GPT系列[1]–[3]和LLAMA系列[4]–[6]用于文本和代码
- DALLE[7]–[9]
- Stable Diffusion[10]用于图像
- Sora[11]用于视频
序列到序列的任务已经从使用长短期记忆(Long Short-Term Memory, LSTM)网络[12]转变为基于Transformer的模型[13]
图像生成任务也从生成对抗网络(Generative Adversarial Networks, GANs)[14]转变为潜在扩散模型(Latent Diffusion Models, LDMs)[10]
尽管生成模型取得了显著进步,AIGC仍然面临着知识过时、缺乏长尾知识[27]以及泄露私人训练数据的风险[28]等挑战
检索增强生成(Retrieval-Augmented Generation, RAG)旨在通过其灵活的数据存储库[29]来缓解这些问题。可检索的知识充当非参数记忆,易于更新,能够容纳广泛的长尾知识,并且可以编码机密数据。此外,检索可以降低生成成本。RAG可以减小大型模型的尺寸[30],支持长上下文[31],并消除某些生成步骤[32]
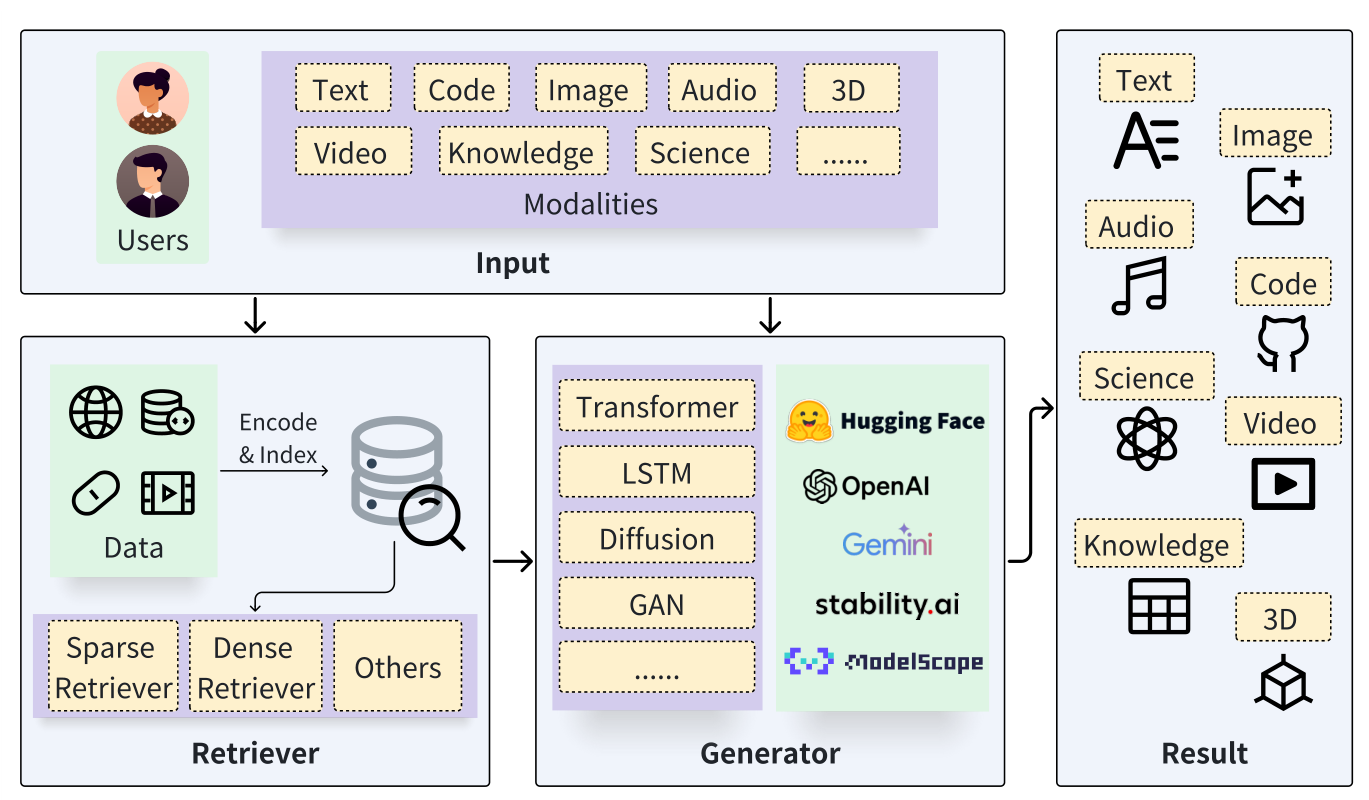
图 1:通⽤ RAG 架构的整体增强。跨越不同模式的⽤户查询作为检索器和⽣成器的输⼊。检索器从数据源中提取相关信息。⽣成器与检索结果交互并最终产⽣各种模式的结果
B. 贡献
- 对RAG进行了全面回顾,并提炼了各种检索器和生成器的RAG基础的抽象
- 调查了RAG文献中的增强方法,详细阐述了用于实现更有效RAG系统的技术
- 对于各种模态和任务,调查了现有的结合RAG技术的AIGC方法,展示了RAG如何为当前的生成模型做出贡献
- 讨论了RAG的局限性和有希望的研究方向,为它的潜在未来发展提供了见解
C. 相关工作
随着RAG领域的不断发展,已经出现了几项调查;然而,它们只涉及该领域的特定方面。特别是,它们要么专门关注单一的RAG基础,要么只为有限的场景提供RAG增强方法的简要概述
大多数现有工作集中在由LLMs促进的基于查询的RAG文本相关任务上,而没有深入研究其他模态
Li等人[57]的调查提供了RAG的基本概述,并讨论了文本生成任务范围内的特定应用
Asai等人[58]的教程集中在基于检索的语言模型上,详细说明了它们的结构和训练策略
Gao等人[59]最近的调查探讨了LLMs背景下的RAG,特别强调了查询基础RAG的增强方法。认识到RAG已经超越了文本领域,的工作扩大了其范围,涵盖了整个AIGC景观,促进了对RAG研究的更全面覆盖
Zhao等人[60]提出的另一项调查介绍了跨多个模态的RAG应用,但忽略了对RAG基础的讨论
另一项工作[61]只涵盖了其他模态的部分工作
虽然现有的研究探索了RAG的各个方面,但仍需要一个全面的概述,涵盖RAG基础、增强及其在不同领域的适用性。在本文中,的目标是通过提出系统的RAG调查来填补这一空白
预备知识 (PRELIMINARY)
A. 概述
整个RAG系统由两个核心模块组成:检索器和生成器,其中检索器从数据存储中搜索相关信息,生成器产生所需内容
RAG过程如下展开:
- 检索器最初接收输入查询并搜索相关信息
- 原始查询和检索结果通过特定的增强方法输入到生成器中
- 生成器产生期望的结果
B. 生成器
生成式AI在多样任务中的显著性能开启了AIGC的时代
在RAG系统中,生成模块扮演着至关重要的角色
不同的生成模型应用于不同场景,如用于文本到文本任务的Transformer模型,用于图像到文本任务的VisualGPT[62],用于文本到图像任务的Stable Diffusion[10],用于文本到代码任务的Codex[2]等
4种在RAG中经常使用的典型生成器:Transformer模型、LSTM、扩散模型和GAN
Transformer模型:Transformer模型是在自然语言处理(NLP)领域表现最佳的模型之一,由自注意力机制、前馈网络、层归一化模块和残差网络组成[63]
如图2所示,最终输出序列是通过在来自标记化和嵌入的潜在表示序列上执行词汇分类,在每个生成步骤上产生的
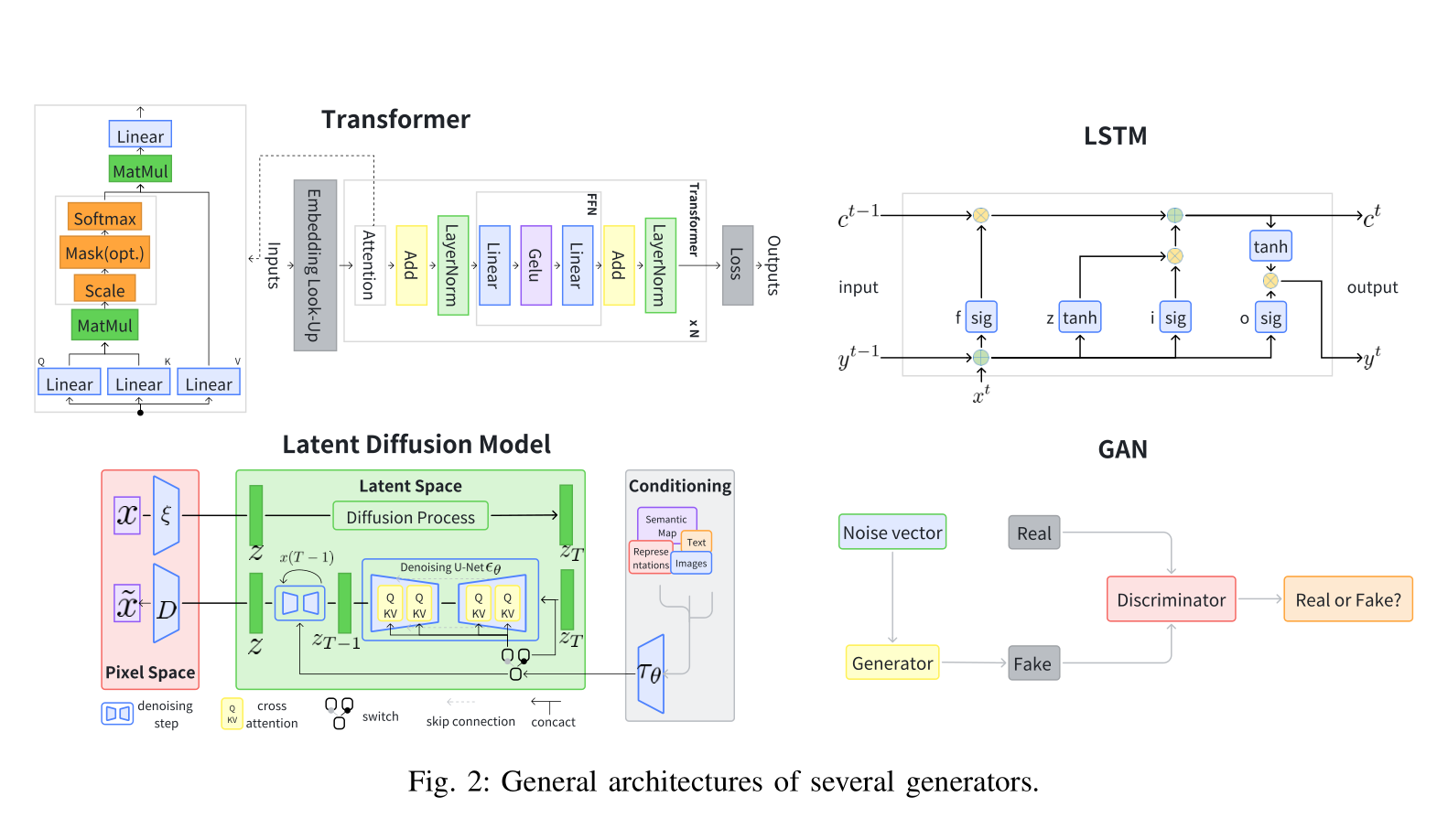
image-20240727171216753 LSTM:如图2所示,长短期记忆(Long Short-Term Memory, LSTM)[64]是循环神经网络(RNN)模型的一种特殊形式
它通过引入细胞状态和门控机制来解决长期依赖处理中的梯度爆炸/消失问题
该模型包括三个门(输入、遗忘和输出)来过滤信息,以及一个中央细胞状态模块来保留和管理信息。它使用与Transformer模型相同的词汇分类方法来自回归地生成输出
扩散模型:扩散模型是一类深度生成模型,可以创建数据(包括图像、文本、视频、分子等)的真实和多样化样本[65]
如图2所示,扩散模型通过逐渐向数据添加噪声直到其变得随机,然后逆转该过程从噪声生成新数据。该过程基于概率建模和神经网络
GAN:生成对抗网络(Generative Adversarial Networks, GANs)[14]是备受期待的深度学习模型,可以模拟和生成真实的图像、音频和其他数据[66]
如图2所示,典型的GAN由两个主要部分组成:生成器和鉴别器。这两个部分通过对抗学习相互竞争,允许生成器不断提高其生成真实样本的能力,而鉴别器不断提高其区分真假样本的能力
C. 检索器
检索是给定一个信息需求,识别和获取相关信息的过程
具体来说,考虑可以被概念化为键值存储的信息资源,其中每个键对应一个值(键和值可以相同)。给定一个查询,目标是使用相似性函数搜索最相似的前k个键,并获取配对的值
根据不同的相似性函数,现有的检索方法可以分为稀疏检索、密集检索等
在广泛使用的稀疏和密集检索中,整个过程可以分为两个不同的阶段:(i) 首先将每个对象编码成特定的表示;然后 (ii) 构建索引以组织数据源,以便进行高效的搜索
稀疏检索器:稀疏检索方法通常用于文档检索,其中键/值代表要搜索的文档
这些方法利用术语匹配度量,如TF-IDF[67]、查询可能性[68]和BM25[19],它们分析文本中的词统计信息并构建倒排索引以实现高效搜索。本质上,BM25是大规模网络搜索中的一个强大的基线,整合了逆文档频率权重、查询标记出现次数和其他相关度量。为了实现高效的搜索,稀疏检索通常利用倒排索引来组织文档。具体来说,查询中的每个术语执行查找以获取候选文档列表,然后根据它们的统计分数进行排名
【相关性03:文本匹配(TF-IDF、BM25、词距)】https://www.bilibili.com/video/BV1XT421Q7fw?vd_source=342375fcd499d4001e7c0244f416e6de
[19] S. E. Robertson and H. Zaragoza, “The probabilistic relevance framework: BM25 and beyond,” FTIR, vol. 3, no. 4, pp. 333–389, 2009.
密集检索器:与稀疏检索不同,密集检索方法使用密集嵌入向量表示查询和键,并构建近似最近邻(Approximate Nearest Neighbor, ANN)索引以加速搜索。这可以应用于所有模态。对于文本数据,最近在预训练模型(如BERT[15])方面的进展已被用于分别对查询和键进行编码[20]。这种方法通常被称为密集通道检索(Dense Passage Retrieval, DPR)
类似于文本,已经提出了模型对代码数据[25]、音频数据[69]、图像数据[24]、视频数据[70]等进行编码。密集表示之间的相似度分数通常使用诸如余弦、内积、L2距离等度量计算
在训练期间,密集检索使用对比学习来增加正样本的相似度并减少负样本的相似度。提出了几种硬负技术[71]以进一步提高模型质量。为了在推理期间进行高效搜索,采用ANN方法。开发了各种索引以服务于ANN搜索,包括树[72]、[73]、局部敏感哈希[74]、邻接图索引(例如HNSW[75]、DiskANN[76])以及组合图和倒排索引(例如SPANN[22])
[73] W. Li, C. Feng, D. Lian et al., “Learning balanced tree indexes for large-scale vector retrieval,” in SIGKDDg, 2023.
[75] Y. A. Malkov and D. A. Yashunin, “Efficient and robust approximate nearest neighbor search using hierarchical navigable small world graphs,” TPAMI, vol. 42, no. 4, pp. 824–836, 2018.
其他:除了稀疏检索和密集检索之外,还有检索相关对象的替代方法[77]、[78]
一些研究工作直接使用自然语言文本[79]或代码片段的抽象语法树(AST)[80]、[81]之间的编辑距离
在知识图中,实体通过关系连接,作为预构建的索引用于检索。因此,使用知识图的RAG方法可以采用k跳邻居搜索进行检索[82]、[83]
另一种检索方法是命名实体识别(Named Entity Recognition, NER)[84],其中查询是输入,实体作为键
[82] X. Ye, S. Yavuz et al., “RNG-KBQA: generation augmented iterative ranking for knowledge base question answering,” in ACL, 2022.
[83] Y. Shu et al., “TIARA: multi-grained retrieval for robust question answering over large knowledge bases,” arXiv:2210.12925, 2022.
[84] X. V. Lin, R. Socher et al., “Bridging textual and tabular data for cross-domain text-to-sql semantic parsing,” arXiv:2012.12627, 2020.
方法论 (METHODOLOGIES)
A. RAG基础
基于检索器如何增强生成器,将RAG基础分为四类,如图3所示

基于查询的RAG:基于提示增强的思想,基于查询的RAG将用户的查询与检索到的信息无缝集成,直接输入到生成器的初始阶段。这种方法在RAG应用中非常普遍。检索后,获取的内容与用户的原始查询合并,形成复合输入,然后由生成器处理以创建响应。基于查询的RAG广泛应用于各种模态
对于文本生成,REALM [33] 使用双BERT框架来简化知识检索和整合,将预训练模型与知识提取器相结合
Lewis等人 [34] 利用DPR进行信息检索,并使用BART作为生成器,有效增强了生成
SELF-RAG [85] 使用批评模块来确定是否需要检索。除了与本地生成器兼容外,基于查询的RAG还适用于使用LLM通过API调用的场景
REPLUG [86] 遵循这种方法,将语言模型视为“黑盒”,并有效地将相关的外部文档集成到查询中
In-Context RALM [87] 使用BM25进行文档检索,并训练一个预测性重新排名器来重新排序和整合排名最高的文档
在代码领域,几项工作 [42]、[88]–[91] 利用基于查询的范式将文本或代码的上下文信息整合到提示中,从而提高了下游任务的有效性
最近在知识库问答(KBQA)领域的研究也显示出将检索和语言模型相结合对系统性能和准确性有显著影响。例如,Uni-Parser [92]、RNG-KBQA [82] 和 ECBRF [93] 通过将查询和检索到的信息合并到提示中,有效提高了问答系统的性能和准确性
在人工智能科学领域,Chat-Orthopedist [94] 辅助青少年特发性脊柱侧弯的共享决策,通过将检索到的数据整合到模型提示中,提高了LLM的有效性和信息精度
在图像生成任务中,RetrieveGAN [45] 通过将检索到的数据(如选定的图像补丁及其边界框)整合到生成器的输入阶段,提高了生成图像的相关性和准确性
IC-GAN [95] 通过将噪声向量与实例特征连接起来,调节生成图像的特定条件和细节
对于3D生成,RetDream [50] 最初使用CLIP [24] 检索相关的3D资产,然后在输入阶段将检索到的内容与用户输入合并。基于查询的RAG通常与LLM生成器配对,提供模块化灵活性,允许快速集成预训练组件进行快速部署。在此设置中,提示设计对于利用检索到的数据至关重要
基于潜在表示的RAG:在基于潜在表示的RAG框架中,检索到的对象作为潜在表示被整合到生成模型中。这增强了模型的理解能力,并提高了生成内容的质量
在文本领域,FiD [35] 和 RETRO [36] 是两个经典的基于潜在表示的RAG结构,许多后续工作都基于它们进行了修改
FiD [35] 处理每个检索到的段落及其标题以及查询,通过不同的编码器,然后将生成的潜在表示合并,由单个解码器进行解码以产生最终输出
RETRO [36] 检索每个分段子查询的相关信息,然后应用一个称为块交叉注意力(Chunked Cross-Attention, CCA)的新模块,将检索到的内容与每个子查询标记整合。此外,在基于潜在表示的RAG范围内,还有其他值得注意的新结构
一些研究 [31]、[96] 将k最近邻(kNN)搜索整合到Transformer块中,允许输入分块,并理论上解决了Transformer模型长期受到批评的上下文长度限制问题
Kuratov等人 [97] 将Transformer与RNN集成,使用模型的中间输出作为检索内容。在代码和科学领域,FiD已广泛采用,应用涵盖各种代码相关领域 [98]–[102] 和人工智能科学 [55]
在图像领域,一些研究 [103]–[106] 采用交叉注意力机制通过整合它们的潜在表示来融合检索结果
相反,Li等人 [107] 实现了一个文本-图像仿射组合模块(Affine Combination Module, ACM),直接连接隐藏特征
在知识领域,一些研究 [108]–[112] 采用了FiD及其衍生物进行下游任务。EaE [113] 通过实体特定的参数化增强了生成器的理解,而TOME [114] 则转向了对提及的细微编码,优先考虑提及的粒度而不是仅实体表示
在3D生成领域,ReMoDiffuse [51] 引入了一个语义调制的注意力机制,根据文本描述提高了生成相应3D动作的准确性。AMD [115] 通过融合原始扩散过程和参考扩散过程,实现了从文本到3D动作的高效转换
在音频领域,Koizumi等人 [43] 使用了一个LLM,将编码的密集特征整合到注意力模块中,以指导音频字幕的生成。ReAudioLDM [116] 使用不同的编码器从文本和音频中提取深度特征,然后将它们整合到其潜在扩散模型(LDM)的注意力机制中
对于视频字幕,R-ConvED [48] 使用卷积编码器-解码器网络处理检索到的视频-句子对,并使用注意力机制生成隐藏状态以产生字幕。CARE [117] 引入了一个概念检测器来产生概念概率,并将概念表示整合到混合注意力机制中。EgoInstructor [49] 使用门控交叉注意力合并文本和视频特征,提高了以自我为中心的视频字幕的相关性和连贯性
基于潜在表示的RAG,可适应不同模态和任务,混合检索器和生成器隐藏状态,但需要额外训练以对齐潜在空间。它使开发复杂的算法成为可能,这些算法可以无缝地整合检索到的信息
基于Logit的RAG:在基于Logit的RAG中,生成模型在解码过程中通过Logit整合检索信息。通常,Logit通过简单的求和或模型计算逐步生成的概率
在文本领域,kNN-LM [37] 及其变体 [38] 在每个解码步骤中将语言模型概率与相似前缀的检索距离混合。TRIME [118] 和 NPM [119] 是传统kNNLM方法的激进演变,使用来自本地数据库的紧密对齐的标记作为输出,特别是在长尾分布场景中显著提高了性能
在文本之外,其他模态(如代码和图像)也利用基于Logit的RAG
在代码领域,一些研究 [80]、[120] 也采用了kNN的概念来增强最终输出控制,从而实现更优越的性能。此外,EDITSUM [98] 通过在Logit级别整合原型摘要,提高了代码摘要的质量
对于图像字幕,MA [121] 直接应用kNN-LM框架来解决图像字幕问题,取得了有利的结果
总之,基于Logit的RAG利用历史数据推断当前状态,并在Logit级别合并信息,非常适合序列生成。它专注于生成器训练,并允许利用概率分布的新方法来应对未来的任务
推测性RAG:推测性RAG寻求使用检索而不是纯生成的机会,旨在节省资源并加速响应速度
REST [32] 用检索替换了推测性解码中的小型模型,使草案生成成为可能
GPTCache [39] 通过构建语义缓存来存储LLM响应,解决了使用LLM API时高延迟的问题
COG [123] 将文本生成过程分解为一系列复制和粘贴操作,从文档中检索单词或短语而不是生成
Cao等人 [124] 提出了一种新范式,消除了最终结果对第一阶段检索内容质量的依赖,用直接检索的短语级内容替换生成
总之,推测性RAG目前主要适用于序列数据。它将生成器和检索器解耦,使预训练模型作为组件直接使用。在这个范式中,可以探索更广泛的策略来有效利用检索到的内容
基于Logit的RAG(Logit-based Retrieval-Augmented Generation)是一种特殊的检索增强生成(Retrieval-Augmented Generation, RAG)方法,它在生成模型的解码过程中利用检索信息来影响生成结果。具体来说,这种方法通过将检索到的信息以Logit(即未经过softmax处理的原始概率值)的形式直接整合到生成模型的决策过程中,从而影响最终生成的内容
B. RAG增强
在本节中,介绍增强构建的RAG系统性能的方法。根据增强目标将现有方法分为五组:输入、检索器、生成器、结果和整个流程
输入增强:最初输入检索器的内容显著影响检索阶段的最终结果。在本节中,介绍两种输入增强方法:查询转换和数据增强
查询转换:通过修改输入查询来增强检索结果
Query2doc [125] 和 HyDE [126] 使用原始查询生成伪文档,然后将其用作检索的查询。伪文档包含更丰富的相关信息,有助于检索更准确的结果
TOC [127] 利用检索内容将模糊查询分解为多个清晰的子查询,这些子查询被发送到生成器并聚合以产生最终结果
对于复杂或模糊的查询,RQ-RAG [128] 将它们分解为清晰的子查询进行细粒度检索,并综合响应以提供对原始查询的连贯答案
Tayal等人 [129] 使用动态少样本示例和上下文检索来细化初始查询,增强生成器对用户意图的理解
数据增强:在检索之前改进数据,包括去除无关信息、消除歧义、更新过时文档、合成新数据等技术
Make-An-Audio [44] 使用字幕和音频-文本检索为无语言音频生成字幕,以缓解数据稀疏性,并添加随机概念音频以改善原始音频
LESS [130] 通过分析梯度信息优化数据集选择,旨在提高模型对指令提示的响应性能
ReACC [91] 通过重命名和插入死代码等数据增强技术来预训练代码检索模型
Telco-RAG [131] 通过应用“3GPP规范词汇表”来增强检索准确性,并将它们与用户查询通过路由器模块匹配
检索器增强:在RAG系统中,检索内容的质量决定了输入生成器的信息。较低的内容质量增加了模型幻觉或其他退化的风险。在本节中,介绍提高检索有效性的高效方法
递归检索:递归检索是执行多次搜索以检索更丰富和更高质量的内容
ReACT [132] 使用思维链(Chain-of-Thought, CoT)[133] 来分解查询进行递归检索,并提供更丰富的信息
RATP [134] 使用蒙特卡洛树搜索进行模拟以选择最佳检索内容,然后将其模板化并转发给生成器以输出
块优化:块优化是指调整块大小以改善检索结果
LlamaIndex [135] 整合了一系列块优化方法,其中之一是按照“从小到大”的原则操作。这里的核心概念是定位更细粒度的内容,但返回更丰富的信息。例如,句子窗口检索获取小文本块,并返回检索段落周围s相关句子窗口。在自动合并检索中,文档以树结构排列。该过程首先检索父节点,该节点封装了其子节点的内容,通过首先获取子节点来实现。为了解决缺乏上下文信息的问题
RAPTOR [136] 采用递归嵌入、聚类和文本块的摘要,直到进一步聚类变得不可行,从而构建了一个多层次的树结构
PromptRAG [137] 通过预先生成目录表来增强检索准确性,使模型能够根据查询自主选择相关章节
[137] B. Kang, J. Kim et al., “Prompt-rag: Pioneering vector embeddingfree retrieval-augmented generation in niche domains, exemplified by korean medicine,” arXiv:2401.11246, 2024.
检索器微调:检索器是RAG系统中的核心,依赖于一个熟练的嵌入模型[139]–[142]来表示相关内容并提供给生成器,从而提高系统性能。此外,具有强大表达能力的嵌入模型可以通过领域特定或任务相关的数据进行微调,以提高目标领域的性能
REPLUG [86] 将LM视为黑盒,并根据最终结果更新检索器模型
APICoder [88] 用Python文件和API名称、签名、描述对检索器进行微调
[88] D. Zan, B. Chen, Z. Lin et al., “When language model meets private library,” in EMNLP Findings, 2022.
EDITSUM [98] 微调检索器以减少检索后摘要之间的Jaccard距离
SYNCHROMESH [81] 在损失中添加AST的树距离,并使用目标相似性调整(Target Similarity Tuning, TST)对检索器进行微调
R-ConvED [48] 与生成器使用相同的数据对检索器进行微调
Kulkarni等人 [143] 应用infoNCE损失对检索器进行微调
混合检索:混合检索表示同时使用多种检索方法或从多个不同来源提取信息
RAP-Gen [144]、BlendedRAG [145] 和 ReACC [91] 使用密集检索器和稀疏检索器来提高检索质量
Rencos [80] 使用稀疏检索器检索语法级别的相似代码片段,并使用密集检索器检索语义级别的相似代码片段
ASHEXPLAINER [99] 首先使用密集检索器捕获语义信息,然后使用稀疏检索器获取词汇信息
RetDream [50] 首先使用文本进行检索,然后使用图像嵌入进行检索
CARG [146] 具有一个检索评估器,根据置信度评估文档与查询的相关性:如果准确,则直接使用结果进行知识提炼;如果不正确,则进行网络搜索;对于模糊情况,则采用混合方法
Huang等人 [147] 通过在检索阶段引入DKS(Dense Knowledge Similarity)和RAC(Retriever as Answer Classifier),评估答案相关性和知识适用性,从而提高问答性能
UniMSRAG [148] 引入了一种新型标记,称为“作用标记”,它决定了从哪个来源检索信息
Koley等人 [149] 通过整合草图和文本来增强图像检索,从而获得改进的结果
生成器增强:在RAG系统中,生成器的质量通常决定了最终输出结果的质量。因此,生成器的能力决定了整个RAG系统有效性的最高限度
提示工程:专注于提高LLM输出质量的提示工程技术[166],如提示压缩、Stepback Prompt [167]、Active Prompt [168]、Chain of Thought Prompt [133] 等,都适用于RAG系统中的LLM生成器
LLMLingua [169] 应用小型模型来压缩查询的总长度,以加速模型推理,减轻无关信息对模型的负面影响,并缓解“Lost in the Middle” [170] 现象
ReMoDiffuse [51] 通过使用ChatGPT将复杂描述分解为解剖文本脚本
ASAP [171] 将示例元组(输入代码、函数定义、分析结果和相应注释)整合到提示中,以获得更好的结果
CEDAR [89] 使用设计好的提示模板将代码演示、查询和自然语言指令组织成提示
XRICL [153] 利用COT技术在跨语言语义解析和推理中添加翻译对作为中间步骤
ACTIVERAG [172] 采用Cognition Nexus机制来校准LLM的内在认知,并在答案生成中应用COT提示
Make-An-Audio [44] 能够使用其他模态作为输入,这可以为后续过程提供更丰富的信息
解码调整:解码调整涉及通过微调超参数来增强生成器控制,增加多样性并约束输出词汇表等调整
InferFix [90] 通过调整解码器中的温度来平衡结果的多样性和质量
SYNCHROMESH [81] 通过实现完成引擎来限制解码器的输出词汇表,以消除实现错误。生成器微调:生成器的微调可以增强模型具有更精确的领域知识或更好地适应检索器的能力
RETRO [36] 固定检索器的参数,并在生成器中使用块交叉注意力机制来结合查询和检索器的内容
APICoder [88] 用新文件与API信息和代码块的混合体对生成器CODEGEN-MONO 350M [173] 进行微调
CARE [117] 训练编码器与图像、音频和视频-文本对,然后微调解码器(生成器),同时减少字幕和概念检测损失,同时保持编码器和检索器固定
Animate-AStory [174] 使用图像数据优化视频生成器,然后微调LoRA [175] 适配器以捕获给定字符的外观细节
RetDream [50] 用渲染图像微调LoRA适配器 [175]
结果增强:在许多情况下,RAG的结果可能无法达到预期效果,一些结果增强技术可以帮助缓解这个问题
输出重写:输出重写是指在某些情况下重写生成器生成的内容,以满足下游任务的需求
SARGAM [176] 通过使用特殊的Transformer以及删除、占位符和插入分类器来完善代码相关任务的输出,以更好地与现实世界的代码环境对齐
Ring [177] 通过根据生成器产生的每个标记的对数概率平均值重新排名候选项来获得多样化的结果
CBRKBQA [54] 通过将生成的关系与查询实体在知识图中的局部邻域中呈现的关系对齐来修订结果
[88] D. Zan, B. Chen, Z. Lin et al., “When language model meets private library,” in EMNLP Findings, 2022.
- RAG流程增强:RAG流程增强是指优化RAG的整体过程,以实现更好的性能结果
自适应检索:一些关于RAG的研究表明,检索并不总是增强最终结果。过度检索可能导致资源浪费,并在模型的内在参数化知识足以回答问题时引起潜在的混淆。因此,本章将深入探讨两种确定检索必要性的方法:基于规则和基于模型的方法
基于规则:FLARE [178] 通过生成过程中的概率主动决定是否和何时进行搜索
Efficient-KNNLM [38] 将KNN-LM [37] 和 NPM [119] 的生成概率与超参数λ结合,以确定生成和检索的比例
Mallen等人 [179] 对问题进行统计分析,以便为高频问题提供直接答案,并为低频问题应用RAG
Jiang等人 [180] 根据模型不确定性、输入不确定性和输入统计数据评估模型信心,以指导检索决策
Kandpal等人 [181] 研究了相关文档数量与模型知识掌握程度之间的相关性,以评估检索的必要性
基于模型:Self-RAG [85] 使用训练有素的生成器根据不同用户查询下的检索令牌来决定是否执行检索
Ren等人 [182] 使用“判断提示”来确定LLM是否能够回答相关问题以及他们的答案是否正确或不正确,从而帮助确定检索的必要性
SKR [183] 使用LLM自身的能力预先判断他们是否能够回答问题,如果他们能够回答,则不执行检索
Rowen [184] 将问题翻译成多种语言,并检查这些语言之间的答案一致性,使用结果来决定是否需要信息检索
AdaptiveRAG [185] 根据查询复杂性通过分类器动态决定是否检索,该分类器是一个较小的LM
迭代RAG:迭代RAG通过重复循环检索和生成阶段,而不是单轮,逐步完善结果
RepoCoder [186] 使用迭代检索-生成方法进行代码补全,用先前生成的代码完善查询
ITER-RETGEN [ 187 ]通过使用生成器的输出来确定知识缺口,检索必要的信息,并形成未来的生成周期,从而迭代地提高内容质量
SelfMemory [ 188 ]利用一个检索增强的生成器迭代地形成一个扩展的记忆池,记忆选择器从记忆池中选择一个输出来通知下一代循环
RAT [ 189 ]首先使用零样本CoT提示的LLM生成内容,然后通过从外部知识库中检索知识来修改每个思考步骤
[188] X. Cheng, D. Luo, X. Chen et al., “Lift yourself up: Retrievalaugmented text generation with self-memory,” in NeurIPS, 2023.
应用 (APPLICATIONS)
A. RAG在文本中的应用
首先,文本生成是RAG最重要和最广泛部署的应用之一。这里分别介绍了七个任务中的流行工作
问答 (Question Answering):问答涉及从大量文本源中提取信息以回答提出的问题的过程
FiD [35] 和 REALM [33] 根据查询识别最相关的前k篇文章片段,并将每个片段连同问题一起传递给LLMs以生成k个响应。然后将这些响应综合成最终答案
Toutanova等人 [190] 用知识图谱的子图替换了REALM中的文本语料库,取得了令人印象深刻的结果
[190] O. Agarwal, H. Ge, S. Shakeri, and R. Al-Rfou, “Knowledge graph based synthetic corpus generation for knowledge-enhanced language model pre-training,” in NAACL-HLT, 2021.
如图5所示,RETRO [36] 采用注意力机制将问题与相关检索文档整合在模型内以产生最终答案
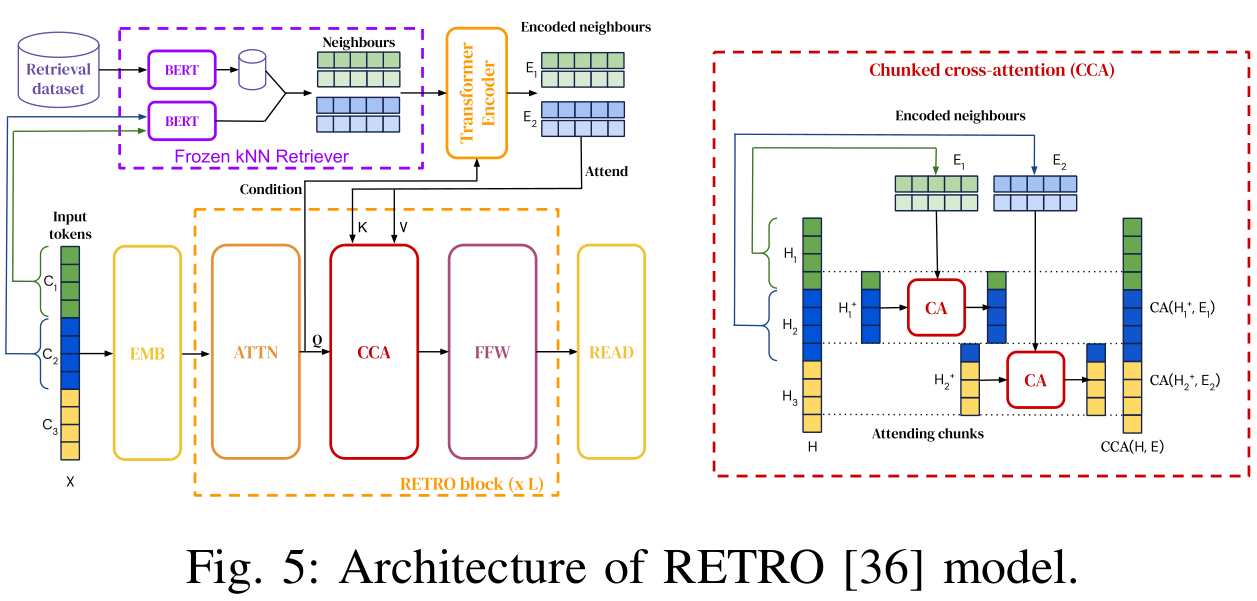
image-20240728120920959 SKR [183] 观察到使用RAG并不总是有益于问答,因此探索了引导模型评估其对相关知识的掌握,随后调整其使用外部资源进行检索增强
TOG [191] 引入了一个创新的知识图谱增强LLM框架,通过促进LLM与知识图谱之间的交互并在束搜索中扩展推理路径空间而表现出色
[191] J. Sun, C. Xu, L. Tang et al., “Think-on-graph: Deep and respon-sible reasoning of large language model with knowledge graph,” arXiv:2307.07697, 2023.
NPM [119] 率先使用非参数数据分布代替softmax层,使具有较少参数的模型能够有效执行
CL-ReLKT [192] 采用语言通用编码器,弥合了跨语言问题-文档对之间的差距,从而更好地利用多语言数据
CORE [193] 通过引入一种新的密集段落检索算法和多语言自回归生成模型,缓解了语言资源的不平衡
EAE [113] 通过检索查询实体的实体嵌入并将这些与隐藏状态整合以进一步处理,提高了答案质量
UR-QA [194] 提出了一种同时检索QA对和文本块,通过比较它们的校准置信度来选择最终答案的方法
事实验证 (Fact Verification):事实验证通常指的是确定给定的自然语言文本和相关声明或断言是否与文本中的事实相匹配
CONCRETE [198] 利用跨语言检索机制,利用多语言证据的丰富性,有效地弥合了在事实检查数据集中资源不足的语言之间的差距
Atlas [30] 表明,使用RAG支持LLM在知识密集型任务中的显著提高了它们的少样本学习能力
Hagström等人 [199] 在LLaMA [4] 和 Atlas [30] 上证明了搜索增强比增加模型大小更有益于解决不一致性问题
Stochastic RAG [200] 使用无替换的随机抽样来解决RAG检索中的非可微topk选择过程,实现了端到端优化,并在事实验证场景中取得了优异的结果
常识推理 (Commonsense Reasoning):常识推理指的是机器能够以类似人类的方式推断或对问题或任务做出决策,利用其获得的外部知识及其应用
KG-BART [201] 通过将知识图谱中不同概念之间的复杂相互关系纳入其中,扩展了概念领域。它采用图注意力机制帮助LLM制作更细腻、逻辑上更连贯的句子
[201] Y. Liu, Y. Wan et al., “KG-BART: knowledge graph-augmented BART for generative commonsense reasoning,” in AAAI, 2021.
Wan等人 [202] 构建了具有争议性问题和冲突答案的CONFLICTINGQA数据集,以研究文本特征如何影响LM处理有争议问题
人机对话 (Human-Machine Conversation):人机对话包括机器理解自然语言并熟练运用这种技能与人类进行交流的能力
ConceptFlow [203] 利用常识知识图谱来构建对话,根据注意力分数指导对话流程,推动对话向前发展
Cai等人 [204] 将文本生成任务重新想象为填空测试,通过检索和提炼过去的对话历史,取得了显著成果
Komeili等人 [205] 通过利用先进的搜索引擎技术从互联网获取相关内容,提高了对话生成质量
BlenderBot3 [206] 扩大了其搜索范围,不仅挖掘相关的互联网内容,还利用实体提取等技术来改进生成对话的质量
Kim等人 [207]、PARC [208] 和 CREAICL [209] 通过纳入跨语言知识,提高了非英语对话的质量,有效解决了非英语数据集的稀缺性问题,并提高了生成对话的质量
CEG [210] 通过后处理机制解决了幻觉问题,通过检索验证了LLM生成的答案
神经机器翻译 (Neural Machine Translation, NMT):神经机器翻译是从源语言到目标语言的自动文本翻译过程 [118]、[211]、[212]。它是NLP领域的关键任务,是追求人工智能的重要目标,具有重要的科学和实际意义
事件提取 (Event Extraction):事件提取是NLP中的一个过程,涉及在文本中识别和分类特定事件,并将它们与相关实体关联起来。这些事件通常由动词表示,实体是参与事件的参与者
摘要 (Summarization):摘要的任务是将长篇文本中的关键信息提炼出来,生成一个简洁、连贯的摘要,概括主要主题。摘要有两种主要方法:提取式和抽象式。提取式摘要涉及自动选择和编译源文本中的关键短语,不创建新句子,而是重新利用原始文本的段落。而抽象式摘要则涉及理解原始文本的含义,并将其重构为新句子 [96]、[214]–[216],这可以更流畅地传达来源的意图,但由于其复杂性,在实施方面面临更大的挑战
B. RAG在代码中的应用
历史上,代码相关任务通常采用单独的检索和生成方法。对于检索,可以使用抽象语法树(AST)或文本编辑距离来识别相似的代码片段。对于生成,采用序列到序列模型生成代码或自然语言。最近的RAG研究结合了检索和生成技术来提高整体性能
代码生成 (Code Generation):代码生成的目标是将自然语言(NL)描述转换为代码实现
基于查询的RAG是代码生成的常用方法。它为基于Transformer的生成模型构建提示,包括检索到的类似示例 [40]、[152]、[218]–[221]、相关的API详细信息 [88]、[222]、文档 [42]、导入 [223] 和全局函数 [224]
SKCODER [225] 检索相关代码片段以生成最终代码的草图模板
RRGCode [226] 使用交叉编码器对检索结果进行排名
CODEAGENT [227] 为网页搜索、文档检索、程序生成和正确性测试设计代理
ARKS [228] 采用迭代RAG重新制定查询并更新检索源。基于Logit的RAG也适用于代码生成
RECODE [79] 使用编辑距离检索NL描述和配对代码,然后在基于LSTM的生成过程中利用从AST中提取的n-gram动作子树
kNNTRANX [120] 使用seq2tree模型将NL转换为代码AST。在每个解码步骤中,隐藏状态在AST前缀数据存储中被搜索,以创建新概率,然后通过置信网络与seq2tree模型的输出合并
ToolCoder [229] 生成包含特殊标记的代码。当遇到这些标记时,ToolCoder执行在线搜索或离线检索,以API调用填充空白,这是一种专门形式的推测性RAG
代码摘要 (Code Summarization):代码摘要任务反过来将代码转换为NL描述。许多研究工作使用额外的编码器处理检索结果,然后将其组合以供后续解码器使用,类似于Fusion-in-Decoder [35]
代码补全 (Code Completion):代码补全类似于代码版本的“下一句预测”任务。基于查询的RAG是代码补全的主流范式
自动程序修复 (Automatic Program Repair):基于查询的RAG通常用于自动程序修复,以帮助生成模型修复错误代码
文本到SQL和基于代码的语义解析 (Text-to-SQL and Code-based Semantic Parsing):语义解析将NL转换为清晰、结构化的表示,如SQL或其他特定领域的语言,通常需要代码的帮助
其他 (Others):还有一些其他代码相关任务采用基于查询的RAG范式,将类似示例纳入提示构建
C. RAG在知识中的应用
结构化知识,包括知识图谱(KGs)和表格,在语言相关任务中广泛使用。它通常作为检索源以增强生成。除了常规的稀疏和密集检索,NER(命名实体识别)技术和图感知邻居检索被应用来识别和提取相关实体和关系
- 知识库问答 (Knowledge Base Question Answering):KBQA通常使用知识库来确定问题的正确答案
- 知识增强的开放域问答 (Knowledge-augmented Open-domain Question Answering):结构化知识通常被用来增强ODQA
- 表格问答 (Table for Question Answering):表格作为另一种形式的结构化知识,也促进了问答
- 其他 (Others):还有一些其他知识相关任务采用基于查询的RAG范式
D. RAG在图像中的应用
- 图像生成 (Image Generation):图像生成指的是使用人工智能和机器学习领域的算法创建新图像的过程
- 图像字幕 (Image Captioning):图像字幕是生成图像的文本描述的过程
- 其他 (Others):还存在许多其他图像相关任务,采用检索增强方法
E. RAG在视频中的应用
- 视频字幕 (Video Captioning):视频字幕将视觉内容转换为描述性话语
- 视频问答和对话 (Video QA & Dialogue):视频问答和对话生成与视频内容一致的单轮或多轮响应
- 其他 (Others):RAG还适用于其他视频相关任务
F. RAG在音频中的应用
- 音频生成 (Audio Generation):音频生成通常使用自然语言提示合成音频
- 音频字幕 (Audio Captioning):音频字幕基本上是一个序列到序列的任务,为音频数据生成自然语言数据
G. RAG在3D中的应用
- 文本到3D (Text-to-3D):检索可以应用于增强3D资产生成
H. RAG在科学中的应用
RAG也成为许多跨学科应用中一个有希望的研究方向,如分子生成、医疗任务和计算研究
基准测试 (BENCHMARK)
鉴于RAG研究兴趣和应用的日益增长,也出现了几个从某些方面评估RAG的基准测试
Chen等人[336]提出了一个RAG基准测试,从四个维度进行评估:
(1) 噪声鲁棒性,测试LLMs是否能从噪声文档中提取必要信息
(2) 负例拒绝,评估LLMs是否能在检索内容不足时拒绝响应
(3) 信息整合,检查LLMs是否能够通过整合多个检索内容来获取知识并做出响应
(4) 反事实鲁棒性,确定LLMs是否能够识别检索内容中的反事实错误
另外三个基准测试,RAGAS[337]、ARES[338]和TruLens[339],使用单独的评估LLM从三个方面进行评估:
(1) 忠实度,基于检索内容评估事实准确性
(2) 答案相关性,确定结果是否解决了查询问题
(3) 上下文相关性,评估检索内容的相关性和简洁性
CRUD-RAG[340]将RAG任务分为四种类型:创建、读取、更新和删除,通过文本续写、问答、幻觉纠正和开放域多文档摘要来评估它们
MIRAGE[341]在医学领域评估RAG,专注于医学问答系统的性能
KILT[342]通过对齐Wikipedia快照来验证信息的准确性,使用BLEU分数来确定相关文本,并通过过滤来保证质量,从而为基于证据的预测或引用提供多样化的检索系统
[337] S. ES, J. James, L. E. Anke, and S. Schockaert, “RAGAS: automated evaluation of retrieval augmented generation,” arxiv:2309.15217, 2023.
讨论 (DISCUSSION)
A. 局限性
尽管RAG已被广泛采用,但它本质上存在几个局限性
- 检索结果中的噪声:信息检索本身因项目表示中的信息丢失和ANN搜索而存在缺陷。不可避免的噪声,表现为不相关内容或误导性信息,可能在RAG系统中造成故障点[343]。然而,尽管提高检索精度似乎是提高RAG有效性的直观方式,但最近的研究发现,噪声检索结果可能提高生成质量[344]。可能的解释是,多样化的检索结果可能有助于提示构建[345]。因此,检索噪声的影响仍然不明确,导致在实际使用中关于度量选择和检索器-生成器交互的混乱
- 额外开销:虽然检索在某些情况下可以降低生成成本[30]–[32],但在大多数情况下,它带来了不可忽视的开销。换句话说,检索和交互过程不可避免地增加了延迟。当RAG与复杂的增强方法结合时,如递归检索[346]和迭代RAG[186],这种开销会被放大。此外,随着检索源规模的扩大,存储和访问复杂性也会增加[347]。这样的开销阻碍了RAG在对延迟敏感的实时服务中的实用性
- 检索器和生成器之间的差距:由于检索器和生成器的目标可能不一致,它们的潜在空间可能不同,设计它们之间的交互需要精心设计和优化。目前的方法要么是分离检索和生成,要么是在中间阶段集成它们。前者更模块化,后者可能从联合训练中受益,但损害了通用性。选择一种成本效益的交互方法来弥合差距是一个挑战,需要在实践中深思熟虑
- 系统复杂性增加:引入检索不可避免地增加了系统的复杂性和需要调整的超参数数量。例如,最近的一项研究发现,使用top-k而不是单一检索提高了归因性,但损害了基于查询的RAG的流畅性[348],而其他方面,如度量选择,仍未被充分探索。因此,当涉及RAG时,需要更多的专业知识来调整生成服务
- 上下文长度:RAG的一个主要缺点,特别是基于查询的RAG,是它极大地延长了上下文,使得对于有限制上下文长度的生成器来说是不可行的。此外,延长的上下文也普遍减慢了生成过程。在提示压缩[169]和长上下文支持[349]方面的研究进展部分缓解了这些挑战,尽管在准确性或成本上略有折衷
B. 潜在的未来方向
最后,希望概述几个RAG研究和应用的潜在未来方向
- 新颖的增强方法设计:现有研究已经探索了检索器和生成器之间各种交互模式。然而,由于这两个组件的不同目标,实际的增强过程对最终生成结果有显著影响。探索更先进的增强基础有望充分释放RAG的潜力
- 灵活的RAG流程:RAG系统正在逐步采用灵活的流程,如递归、自适应和迭代RAG。通过精确调整和精心设计,检索源、检索器、生成器和RAG子系统的独一无二组合承诺解决复杂任务并提高整体性能。热切期待开创性的探索,将推动更创新的RAG系统的演变
- 更广泛的应用:RAG是一种通用技术,应用于各种应用。然而,一些生成任务尚未探索RAG,在许多领域,RAG的应用还比较初级,没有考虑到该领域的独特特性。相信,设计特定于领域的RAG技术将极大地有利于更广泛的应用
- 高效的部署和处理:目前,对于LLM的基于查询的RAG,有几种部署解决方案,如LangChain[350]、LLAMA-Index[135]和PipeRAG[351]。然而,对于其他RAG基础和/或生成任务,缺乏即插即用解决方案。此外,由于检索开销和检索器及生成器中不断增加的复杂性,实现高效的RAG仍然具有挑战性,需要进一步的系统级优化
- 结合长尾和实时知识:RAG的一个关键动机是利用实时和长尾知识,但很少有研究探索知识更新和扩展的流程。许多现有作品仅将生成器的训练数据用作检索源,忽视了检索可以提供的动态和灵活的信息。因此,越来越多的研究正在设计具有持续更新知识和灵活来源的RAG系统。还期望RAG更进一步,适应当今网络服务中的个性化信息
- 与其他技术的结合:RAG与其他旨在提高AIGC效果的技术(如微调、强化学习、思维链和基于代理的生成)是正交的。这些方法的结合[352]仍处于初期阶段,需要进一步的研究,以通过新颖的算法设计充分利用它们的潜力。值得注意的是,最近出现了一种观点,即“像Gemini 1.5这样的长上下文模型将取代RAG”。然而,这种断言忽视了RAG在管理动态信息方面的灵活性,包括最新的和长尾知识[353]。期望RAG从长上下文生成中受益,而不是被其取代
Retrieval-Augmented Generation for Natural Language Processing: A Survey(NLP RAG 综述)
2024-07-18
http://arxiv.org/abs/2407.13193
检索增强生成 (Retrieval-Augmented Generation) 概述
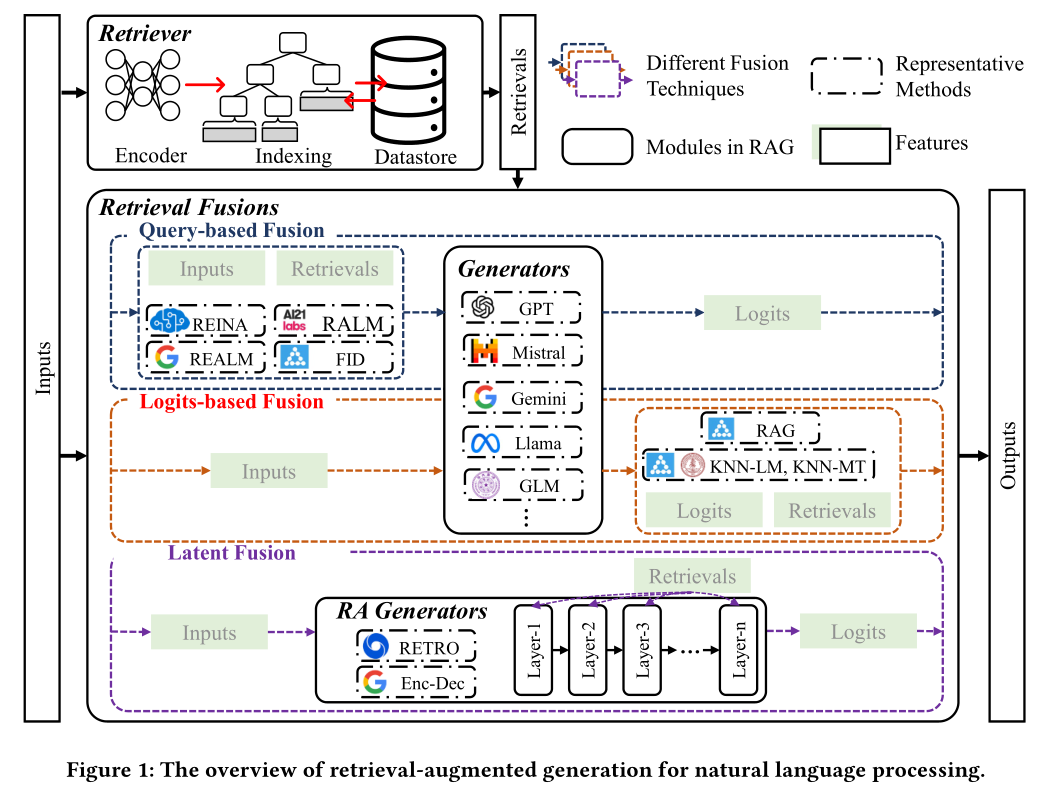
如图1所示,RAG通常由三个模块组成:检索器(retriever)、生成器(generator)和检索融合(retrieval fusions)
检索器模块通常包括三个部分:一个编码器用于将输入编码为嵌入(embeddings),一个高效的索引支持近似最近邻搜索,以及一个数据存储(datastore),用于以键值对形式存储外部知识
检索器模块的主要挑战是找到检索效率和检索质量之间的最佳权衡。检索效率指的是能够多快地获得相关信息,这涉及到加速编码、高效索引、数据存储中的批量查询等。检索质量指的是能够检索到多么相关的信息,这涉及到块表示学习、先进的近似最近邻搜索算法等
检索融合的目标是利用检索到的信息来增强生成。这些融合技术可以分为三大类:基于查询的融合、潜在融合和基于logits的融合
基于查询的融合在将信息输入生成器之前,将检索到的信息与输入结合起来
基于logits的融合侧重于生成器的输出logits,并融合检索到的logits以获得更强大的logits
潜在融合指的是将检索表示引入到生成器的潜在表示中,从而隐式地提高模型的性能
生成器模块可以分为两大类生成器:默认生成器和检索增强(RA)生成器
默认生成器包括大多数预训练/微调的大型语言模型,如GPT系列模型、Mistral模型和Gemini系列模型
RA生成器指的是包含融合检索模块的预训练/微调生成器,例如RETRO和EncDec。这些生成器生成响应或进行预测
RAG的工作流程涉及三个步骤:(1) 根据给定的输入从外部数据库检索相关信息;(2) 根据融合技术将检索到的信息与输入或中间状态结合起来;(3) 生成器根据输入和相应的检索进行预测
RETRO [10] Sebastian Borgeaud, Arthur Mensch, Jordan Hoffmann, Trevor Cai, Eliza Rutherford, Katie Millican, George van den Driessche, Jean-Baptiste Lespiau, Bogdan Damoc, Aidan Clark, Diego de Las Casas, Aurelia Guy, Jacob Menick, Roman Ring, Tom Hennigan, Saffron Huang, Loren Maggiore, Chris Jones, Albin Cassirer, Andy Brock, Michela Paganini, Geoffrey Irving, Oriol Vinyals, Simon Osindero, Karen Simonyan, Jack W. Rae, Erich Elsen, and Laurent Sifre. 2022. Improving Language Models by Retrieving from Trillions of Tokens. In Proceedings of the 39th International Conference on Machine Learning (ICML) (Proceedings of Machine Learning Research), Vol. 162. 2206–2240.
EncDec [93] Zonglin Li, Ruiqi Guo, and Sanjiv Kumar. 2022. Decoupled Context Processing for Context Augmented Language Modeling. In Advances in Neural Information Processing Systems 35 (NeurIPS).
检索器 (Retriever)
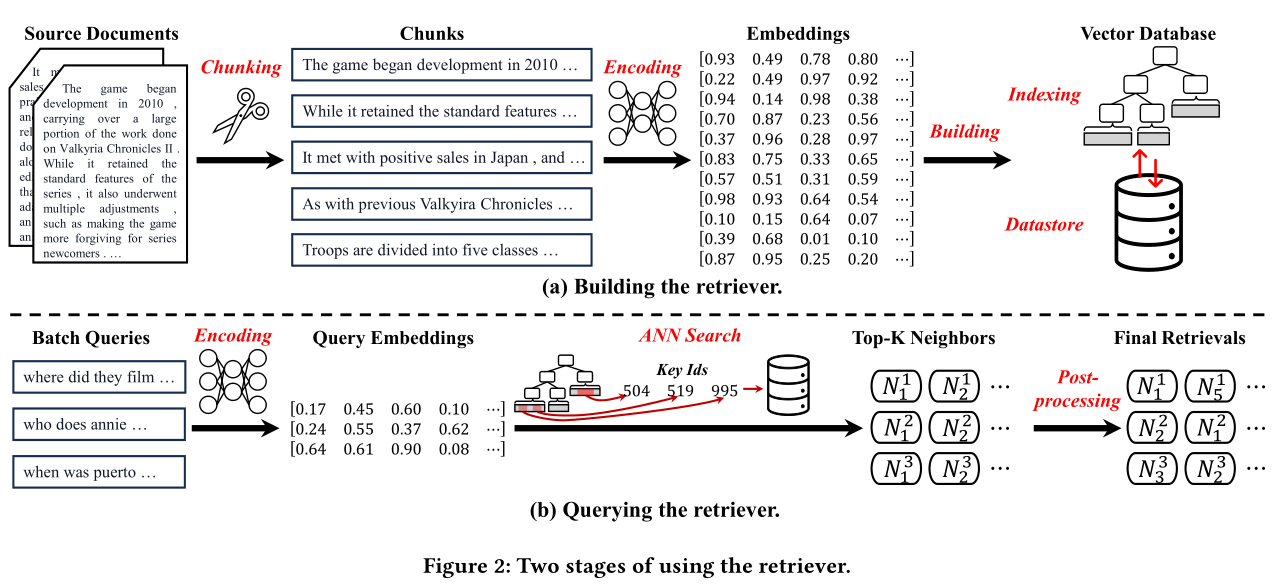
分块
不同的编码器模型对不同⻓度的⽂本具有不同的编码能⼒。例如,sentence-transformer [125] 中的模型在单个句⼦上表现更好,⽽ text-embedding-ada002 [113] 则擅⻓较⻓的⽂本
⽤户查询的⻓度应与分块⼤⼩保持⼀致,这隐式地将块中的上下⽂信息量与查询中的上下⽂信息量对⻬,从⽽提⾼查询和检索之间的相关性。例如,基于短语构建的检索数据库对于⻓⽂档的查询可能毫⽆⽤处
分块技术基本上有三种类型,包括固定⻓度分块、语义分块、以及基于内容的分块
语义分块根据语义来切割⽂档,例如代表句⼦结尾的句点字符或换⾏符。现有最先进的⾃然语⾔处理⼯具包,例如NLTK[112]和spaCy[33],提供了⽅便的句⼦切割⽅法
[112] NLTK. 2001. NLTK. https://www.nltk.org/
[33] explosion. 2016. Spacy. https://spacy.io/
基于内容的分块根据独特的结构特征对⽂档进⾏分段。例如,电⼦病历可以轻松地根据部分进⾏分段,或者可以根据功能块对编程代码进⾏分段
编码块
根据嵌⼊的稀疏性,有两种编码⽅法,即稀疏编码和密集编码。稀疏编码通过创建⼤多数元素为零的⾼维向量来表示⽂本
基本的稀疏编码是one-hot编码[50],它⽤与词汇表⼤⼩⼀样⼤的⾼维向量表示⼀个单词,但只将与该单词的存在相对应的值标记为1
这种编码产的嵌⼊称为 one-hot 向量。其他常⻅的稀疏编码包括:
词袋(BoW)[51]
词频-逆⽂档频率 (TF-IDF)[120]
密集编码⽣成向量,其中每个维度都可以捕获⼀系列语义特征,并且⼤多数元素都是⾮零浮点
索引
嵌⼊的降维
降低嵌⼊的维数可以提⾼搜索效率,但存在损害语义表示的⻛险。基本但有效的降维(DR)是主成分分析(PCA)
PCA是⼀种简单的统计技术,可将原始数据转换为新的坐标系,同时保留最重要的特征
另⼀种流⾏且先进的降维⽅法是局部敏感哈希(LSH)。 LSH 通过将数据映射到桶中显着降低了维度,但保留了原始输⼊数据的相似性。 LSH 背后的直觉是最近的邻居将被映射到相同的桶中
与 LSH 不同,乘积量化(PQ)[68]是⽤于 ANN 搜索的另⼀种流⾏且有效的 DR 技术。 PQ的核⼼思想是将⾼维空间划分为更⼩的、独⽴量化的⼦空间。每个⼦空间创建不同量化整数的码本以形成代表性向量和紧凑向量。上述技术能够实现⾼效存储和快速近似搜索,但可能会丢失语义信息
最近的⼯作[17]提出了⼀种名为AutoCompressor 的新技术,该技术通过将原始上下⽂压缩为语义上更短的嵌⼊来减少嵌⼊的维度
⾼级 ANN 索引
ANN 索引通常是指⽤于组织和管理数据的⽅法或结构,以便优化近似最近邻搜索过程以提⾼检索质量和检索效率。本⽂将介绍⼏种先进的 ANN 索引技术
带乘积量化的倒排⽂件系统(IVFPQ)[32]是⼀个简单但有效的索引框架它结合了两种强⼤的技术来实现⾼效且可扩展的 ANN 搜索过程。 IVFPQ的主要思想是⾸先对数据进⾏聚类,进⾏粗粒度分区然后将每个簇内的数据压缩为⼦向量以进⾏细粒度量化。粗粒度的聚类(IVF 组件)显着减少了搜索空间,⽽细粒度的量化(PQ 组件)则确保了较⾼的检索性能
分层可导航⼩世界(HNSW)[102]使⽤分层图结构在⾼维空间中有效地执⾏⼈⼯神经⽹络搜索。具体来说,HNSW 将⾼维向量视为节点,并将它们与其最近的邻居连接起来。多层图结构是按概率确定的,以确保较⾼层的节点较少,从⽽实现⾼效搜索
基于树的索引旨在以树状结构组织⾼维向量,例如 KD-Trees[123]、Ball Trees [62] 和 VP-Trees [98]。典型的基于树的索引是近似最近邻 Oh Yeah (Annoy) [135],它使⽤基于随机投影构建的森林将向量空间分成多个超平⾯以进⾏⾼效的 ANN搜索
[123] Parikshit Ram and Kaushik Sinha. 2019. Revisiting kd-tree for Nearest Neighbor Search. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining (KDD), Ankur Teredesai, Vipin Kumar, Ying Li, Rómer Rosales, Evimaria Terzi, and George Karypis (Eds.). ACM, 1378–1388.
[62] Qiang Huang and Anthony K. H. Tung. 2023. Lightweight-Yet-Efficient: Revitalizing Ball-Tree for Point-to-Hyperplane Nearest Neighbor Search. In 39th IEEE International Conference on Data Engineering (ICDE). IEEE, 436–449.
[98] Shi-guang Liu and Yin-wei Wei. 2015. Fast nearest neighbor searching based on improved VP-tree. Pattern Recognit. Lett. 60-61 (2015), 8–15.
使⽤键值对构建数据存储
⽮量数据库中使⽤的数据存储是⼀种专⻔的数据库,它将数据作为键值对的集合进⾏存储和管理,其中键是⾼维嵌⼊的唯⼀标识符,值是特定领域的知识。由于数据存储中存储的数据量可能⾮常⼤,因此存储引擎(例如LMDB [100]或RocksDB[35])应该能够⾼效检索和数据持久化。 ANN 搜索数据存储中的关键点是应使⽤什么来存储值。例如,对于问答任务,当向提示添加检索时,简单但有效的⽅法是将问题嵌⼊存储为键,将问答对存储为值。这可以帮助⽣成过程,因为检索被⽤作模型的演示。最近的⼯作提出了各种最先进的向量数据库,包括索引和数据存储,例如 Milvus [46,143]、FAISS [32, 77]、LlamaIndex [95] 等
后处理
重新排序旨在根据特定任务的⽬标对检索到的知识进⾏重新排序。直觉是,知识是根据与任务⽆关的指标(例如欧⼏⾥德距离)检索的
现有的重排序⽅法[18、56、85、141]⼤多设计不同的架构或策略来对检索到的知识进⾏重新排序

[18] Yung-Sung Chuang, Wei Fang, Shang-Wen Li, Wen-tau Yih, and James R. Glass. 2023. Expand, Rerank, and Retrieve: Query Reranking for Open-Domain Question Answering. In Findings of the Association for Computational Linguistics (ACL). Association for Computational Linguistics, 12131–12147.
[56] Nabil Hossain, Marjan Ghazvininejad, and Luke Zettlemoyer. 2020. Simple and Effective Retrieve-Edit-Rerank Text Generation. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics (ACL). 25322538.
[85] Angeliki Lazaridou, Elena Gribovskaya, Wojciech Stokowiec, and Nikolai Grigorev. 2022. Internet-augmented language models through few-shot prompting for open-domain question answering. CoRR abs/2203.05115 (2022).
[141] Tu Vu, Mohit Iyyer, Xuezhi Wang, Noah Constant, Jerry W. Wei, Jason Wei, Chris Tar, Yun-Hsuan Sung, Denny Zhou, Quoc V. Le, and Thang Luong. 2023. FreshLLMs: Refreshing Large Language Models with Search Engine Augmentation. CoRR abs/2310.03214 (2023).
检索融合
基于查询的融合
为了解决连接检索后的冗⻓输⼊问题,最近的研究[5,96,101,150,159]引⼊了为检索到的知识库中的元素分配重要性权重的⽅法,并根据这些权重过滤掉不太相关的上下⽂
特征串联涉及将编码检索与输⼊特征合并。⼀种简单⽽有效的⽅法是FID [66]或密集表示,然后将连接的特征作为⽣成器的输⼊
FID 的最先进性能证明了特征串联的有效性。后续⼯作[25,48,67,97,127]通过联合调整检索器和编码器进⼀步改进了FID,这可以增强检索到的知识的表示
FID 在论文中指的是一种特征级融合技术(Feature-level fusion),它是一种检索增强技术,用于改善自然语言处理任务中的生成模型性能。具体来说,FID 技术通过以下步骤实现融合:
- 特征编码(Feature Encoding):首先将检索到的文档或文本段落编码成特征向量(embeddings)
- 特征融合(Feature Concatenation):然后将这些编码后的特征与输入查询的特征向量进行拼接(concatenation)
- 生成模型输入(Input to Generator):将融合后的特征作为输入送入生成模型(如语言模型),用于生成响应或完成其他任务
FID 方法的优势在于它能够将检索到的信息以特征的形式有效地整合到生成模型中,从而提高模型对上下文的理解能力和生成结果的质量。这种方法特别适用于那些需要结合大量外部信息来生成准确响应的任务,例如开放域问答、文本摘要等
此外,陈等⼈。 [14]将相关知识的表示连接起来作为即时学习的演示,产⽣更好的泛化能⼒
算法 4.1 介绍了如何利⽤基于查询的融合来融合检索到的知识

对于那些使⽤⽂本连接的⼈ [49, 122],算法 4.1 ⾸先连接检索到的⽂本和输⼊(第 2 ⾏),然后将连接的输⼊输⼊⽣成器
值得注意的是,由于现有语⾔模型的最⼤输⼊⻓度存在限制,连接太多检索将导致连接输⼊被截断,这可能会削减给定的输⼊
因此,设计提示模板是该分⽀⼯作的关键步骤。对于那些使⽤特征串联的⼈[48, 66],算法4.1⾸先利⽤编码器来获取特征(第5⾏),然后连接输⼊和检索的特征(第6⾏),最后将连接的特征传递到解码器模型(第5⾏) 7).由于序列⻓度较⻓,该⼯作分⽀通常会产⽣较⾼的内存成本
基于逻辑的融合
基于逻辑的融合是指将检索到的知识合并到输出层中。基本上,检索到的知识将被输⼊到同⼀模型中以获得⽤于增强或校准预测的逻辑
因此,基于logits的融合可以分为两个分⽀,即基于集成的融合和基于校准的融合
基于集成的融合将检索到的知识中的逻辑视为预测集成的⼀部分。这种基于集成的融合可以显着提⾼模型的泛化性和鲁棒性[80,81,158]
基于集成的融合的⼀项值得注意的⼯作是 kNN-LM[81],它聚合了 top-𝑘 最近邻⽬标的 logits,然后对最终预测进⾏插值
与 kNN-LM 类似,Khandelwal 等⼈[ 80] 提出 kNN-MT 使⽤检索的 logits 来增强机器翻译,这也是后续⼯作的⼀个分⽀ [64,172]
与基于集成的融合不同,基于校准的融合使⽤检索到的知识中的逻辑作为模型预测的校准形式
具体来说,Jiang 等⼈ [72]提出了⼀种置信度增强的kNN-MT,它利⽤神经机器翻译置信度来细化kNN分布和插值权重
李等⼈[89]建议利⽤源上下⽂来校准检索增强神经机器翻译
潜在融合
潜在融合研究将检索到的知识合并到⽣成器的隐藏状态中,以获得更好的⽣成可以进⼀步分为两类:基于注意⼒和加权相加RETRO 代表了基于预训练检索的开创性努⼒LLMs[10]
RETRO 代表了基于预训练检索的开创性努⼒LLMs,引⼊了⼀个新的交叉注意⼒模块,将检索到的知识直接集成到模型的隐藏状态中。这项⼯作的⼀个重要发现是证明了检索数据库的缩放定律
除了 RETRO 之外,其他研究 [12、26、93、151、154] 通过利⽤新的注意⼒模块引⼊外部知识,对该领域做出了贡献
王等⼈, [147]将隐藏的注意键和值存储到外部存储器中,并使⽤注意机制从存储器中检索知识

算法 4.3 显示了使⽤潜在融合将检索到的知识引⼊⽣成器的隐藏状态的步骤。对于基于注意⼒的潜在融合,算法 4.3 ⾸先使⽤注意⼒模块的输出状态对检索进⾏编码(第 5 ⾏),然后使⽤交叉注意⼒模块将检索特征融合到隐藏状态中(第 6 ⾏)。与基于注意⼒的潜在融合不同,基于加权相加的潜在融合采⽤更轻量级的⽅式来合并检索到的知识(第10-19⾏)。算法 4.3 ⾸先对检索进⾏编码,然后将其输⼊⽣成器(第 11 ⾏),这可以离线完成并直接作为值存储在数据存储中。然后,算法 4.3 学习⼀组权重,以在⽣成器的隐藏状态上添加检索特征(第 15 ⾏)
生成器 (Generators)
本节介绍了代表性的生成器和检索增强(Retrieval-Augmented, RA)生成器,它们通常在大型数据集上进行预训练。现有的生成器大多是采用或修改基于变换器(transformer-based)架构的大型语言模型。例如,Llama系列模型、GPT系列模型和Gemini系列模型去除了所有编码器模块,仅保留了包含注意力模块和前馈网络模块的解码器模块。其他先进技术,如均方根层归一化、旋转位置嵌入和组查询注意力机制,已经被整合进现有大型语言模型的设计中,以提升它们的性能。检索增强生成器通常在现有大型语言模型的架构中整合新的模块。它们也在大型数据集和由大量自然语言语料库构建的外部知识数据库上进行预训练。这些生成器大多利用潜在融合来将知识整合入大型语言模型的隐藏状态中,这已在第4.3节中讨论过
6 RAG 训练 (RAG Training)
本节介绍 RAG 训练,可以分为两大类:不更新数据存储的 RAG 和更新数据存储的 RAG
前者指的是在训练阶段,只有 RAG 每个模块中的可训练参数会被更新,而数据存储中的知识将保持不变
后者指的是数据存储中的知识将被更新,然后 RAG 的每个模块参数将按照前者的方式进行类似的更新
6.1 不更新数据存储的
RAG 在不更新数据存储的情况下训练 RAG 的目标是基于现有知识数据存储更新生成器短期记忆中的知识。如图 4(a)-(c) 所示,有三种训练情况,即分别训练检索器、训练生成器和联合训练检索器与生成器
6.1.1 训练检索器
在不更新数据存储的情况下,训练检索器通常指的是训练检索器编码器和重建索引
由于稀疏编码通常依赖于没有参数的统计方法,因此编码器的训练仅涉及密集编码方法
不同的训练方法可能有不同的目标,例如提高语义表示、加速编码过程或学习特定领域的表示
前两个目标通常通过替换原始编码器为更强大或更小的编码器来实现,如 DistilBERT 或 TinyBERT
最后一个目标需要在特定领域的语料库上使用对比学习来训练原始编码器。训练检索器编码器后,作为向量数据库中键的嵌入也将改变
因此,所有索引都应使用新的嵌入重新构建。此外,如果编码器保持不变,则可以使用新的 ANN 搜索算法或重新调整超参数来更新索引。训练完检索器后,可以直接将其整合到 RAG 中,而无需更新生成器
6.1.2 训练生成器
训练生成器涉及更新其参数或检索融合模块中的参数。由于生成器通常是一个大型语言模型(LLM),训练 LLM 是一个资源和时间密集型的过程。幸运的是,提出了几种参数效率高的微调技术,如 LoRA,以解决 LLM 的微调问题。尽管检索融合模块中的参数少于生成器中的参数,但仅微调这些参数可能会遇到一些训练问题,如收敛速度低和过拟合。如果有足够的资源,联合调整生成器和检索融合模块中的参数是训练生成器和检索融合模块的更好方式
6.1.3 联合训练检索器和生成器
除了独立训练检索器和生成器之外,联合训练检索器和生成器可以是提高下游任务性能的另一个好选择。这种情况的关键是确保从输入到输出的前向过程中的可微性。通常,复杂的索引,如 FAISS,在微调阶段不是合适的选择。现有工作通常利用复杂的索引预选一个小的最近邻候选子集,然后通过执行矩阵乘法操作选择最终的前 k 个最近邻
6.2 更新数据存储的 RAG
如图 4(d) 所示,这种情况涉及两个阶段:更新知识数据库,然后训练检索器和生成器
更新知识数据库有三种情况,即用可训练的嵌入更新、用新值更新和用新语料库更新
在第一种情况下,值通常是可训练的嵌入,并且与 RAG 中的参数同时或异步更新
最后两种情况通常指用最新信息更新知识数据库。以问答语料库为例,用新值更新指的是更新现有问题的答案,而用新语料库更新指的是添加新的问答对。更新现有键的值需要首先查询现有的键值对,然后执行就地更新。对于新语料库,数据存储首先需要执行插入操作,然后为新键重建或更新索引。更新数据存储后,训练检索器和生成器与不更新数据存储的 RAG 类似。然而,这一训练步骤并不总是必要的,这有利于 LLM 的上下文学习能力
任务 (Tasks)
本节列出了自然语言处理(NLP)领域的几个经典任务,并介绍了用于解决这些任务的高级检索增强生成(RAG)技术
7.1 语言建模 (Language Modeling)
语言建模是一项需要预测给定词或字符序列的下一个词或字符的概率分布的任务,也称为下一个词预测任务。语言建模已成为预训练大型语言模型的基础任务,可以使用困惑度(perplexity)指标来衡量模型的生成能力。正式定义如下:给定一个由词或字符组成的序列 𝑤1,…,𝑤𝑛w1,…,wn 称为前缀,语言建模任务旨在通过下一个词的预测来建模其概率:
𝑃(𝑤1,…,𝑤𝑛)=𝑃(𝑤1)∏𝑖=2𝑛𝑃(𝑤𝑖∣𝑤1,…,𝑤𝑖−1)P(w1,…,wn)=P(w1)∏i=2nP(wi∣w1,…,wi−1)
其中条件概率 𝑃(𝑤𝑖∣𝑤1,…,𝑤𝑖−1)P(wi∣w1,…,wi−1) 由参数化的语言模型来建模。近期的工作主要利用 RAG 在预训练阶段进一步提高语言建模能力。一些工作通过在每个变换器块中添加一个新的交叉注意力模块来修改生成器的架构,以引入检索到的知识。这些工作的直觉是,给定相似的前缀和它们的下一个词(检索阶段),预训练模型可以使用交叉注意力模块来校准模型的预测,以捕获下一个词和前缀之间的模式(模型前向阶段)。另一些工作专注于在生成器的输入或输出中增加检索到的信息。例如,一些工作将检索到的知识与输入连接起来,并将检索增强的输入输入到生成器中。其他工作在最终输出层融合输入和检索的logits,并基于插值结果生成最终的概率分布
7.2 机器翻译 (Machine Translation)
机器翻译利用计算语言学算法自动将一种语言的文本或语音翻译成另一种语言。MT的目标是产生准确流畅的翻译,同时保留原始文本的含义,并遵循目标语言的语法和风格规范。MT系统已经从基于规则的机器翻译(RBMT)发展到统计机器翻译(SMT),最近又发展到神经机器翻译(NMT)。特别是,NMT方法通过利用深度学习技术显著提高了翻译质量,这将是本节的重点。RAG技术可以通过将外部知识整合到翻译过程中来进一步增强MT。最简单的方法是将类似的翻译示例连接到输入中,或在输出层融合类似翻译示例的logits。例如,一些工作根据源文本检索类似的翻译,并将相应的目标文本或源文本和目标文本对作为示例连接到输入中。其他工作将检索到的源文本输入模型,并获取下一个目标词的logits,然后聚合所有logits以生成最终预测
7.3 文本摘要 (Text Summarization)
文本摘要是将较大的文本文档压缩成较短版本的过程,同时保留关键信息和整体信息。这项任务可以广泛地分为两种类型:抽取式摘要,涉及选择并编译原始文本的部分;抽象式摘要,涉及以新的、简洁的形式重写文本的精髓。目标是生成一个连贯流畅的摘要,包含源材料中最关键的信息。RAG技术可以通过利用外部知识和类似文档来通知摘要过程,显著增强文本摘要任务
7.4 问答系统 (Question Answering)
问答(QA)是 NLP 中的一项基本任务,涉及构建能够自动以自然语言回答人类问题的系统。QA系统可以广泛地分为两类:开放域,系统可以回答关于几乎任何事情的问题;封闭域,专注于特定知识领域。QA中的主要挑战是理解问题意图,并从大量数据中检索准确、相关的信息以提供简洁的答案。由于篇幅限制,本文仅讨论开放域QA系统的作品。RAG技术结合了信息检索和基于模型的生成,非常适合QA系统。特别是,开放域QA系统通常首先需要从互联网或大规模数据库中搜索知识,然后根据检索到的知识生成相应的答案
7.5 信息提取 (Information Extraction)
信息提取(IE)是 NLP 中自动从非结构化和半结构化文本源中提取结构化信息的关键任务。这项任务包括多个子任务,包括命名实体识别(NER)、实体链接(EL)、共指消解(CR)、关系提取(RE)等。目标是识别和分类文本中的关键元素,并理解它们之间的关系,从而将文本数据转换为适合分析和解释的结构化格式。使用 RAG 技术,可以显著提高 IE 任务的性能,同时提高可解释性
7.6 文本分类 (Text Classification)
文本分类任务在 NLP 应用中很常见。情感分析是 NLP 中的一项突出的文本分类任务,涉及识别和分类文本所传达的情感基调。例如,给定句子 "I love to watch movies",分析模型应该确定它是否具有积极的态度或消极的态度。情感分析中的态度可以从积极到消极,或者是中性的、微妙的,甚至是混合的。情感分析任务对于理解消费者反馈、监控品牌声誉以及洞察各种问题的公众意见至关重要。RAG 技术可以通过不同的外部知识融合策略显著增强情感分析
7.7 对话系统 (Dialogue Systems)
对话系统,也称为会话代理或聊天机器人,旨在以文本或语音形式模拟与人类的对话。这些系统可以分为两种主要类型:任务导向系统,协助用户完成特定任务,如预订票务或订购食物;开放域系统,旨在就广泛的话题进行一般性对话。开发有效对话系统的核心挑战在于理解用户意图、维护上下文并生成连贯、相关的响应。现有的工作主要通过基于连接的方法改进对话系统。一些工作将检索到的历史对话与当前输入连接起来。其他工作首先使用编码器对历史响应进行编码,然后将连接的嵌入输入到解码器中以生成新响应
应用 (Applications)
8.1 基于大型语言模型的自主智能体 (LLM-based Autonomous Agents)
基于大型语言模型的自主智能体是利用大型语言模型(LLMs)的能力来执行任务的智能软件系统,无需持续的人工干预
这些智能体使用LLMs作为大脑或控制器,并通过对多模态感知、工具使用和外部记忆的扩展来增强其能力
特别是,智能体的外部长期记忆作为RAG中的知识点数据存储,为智能体提供了整合长期外部知识的能力。因此,应用RAG有助于访问更广泛的信息,提高智能体的决策制定和问题解决能力
使用RAG从外部记忆检索信息。基于LLM的智能体可以使用RAG访问和检索它们自己的外部记忆中的信息。这个外部记忆作为知识库,智能体可以利用它来增强其理解和决策制定。当面临查询或任务时,智能体可以使用RAG从记忆中检索相关信息,然后将这些信息整合到LLM的生成过程中。这允许智能体产生更有根据的响应或解决方案,这些响应或解决方案是由更广泛的知识范围所告知的,从而得出更准确和上下文相关的结果。能够利用庞大的外部记忆使智能体能够根据新信息不断学习和适应,使其随着时间的推移变得更加有效。使用工具搜索网络和RAG以获取最新信息。除了从自己的记忆中检索信息外,基于LLM的智能体还可以使用工具搜索网络以获取最新信息。这种能力对于需要最新知识的任务特别有用,例如新闻摘要、市场分析或响应快速发展的情况。一旦智能体从网络检索到最新信息,它可以使用RAG将这些数据整合到其生成过程中。通过结合LLM对自然语言的理解和来自网络的实时数据,智能体可以生成不仅上下文相关,而且反映了最新发展的响应。这种方法提高了智能体在动态环境中提供准确和及时信息的能力,提高了其有效性。在这两种情况下,RAG通过使智能体能够访问和利用更广泛的信息,无论是来自它们自己的外部记忆还是来自网络上的实时资源,发挥着至关重要的作用。这导致了更明智的决策制定,并增强了智能体的整体性能
8.2 框架 (Frameworks)
像Langchain和LlamaIndex这样的框架对提高RAG的实际实施产生了重大影响
Langchain和LlamaIndex是将复杂的检索机制与生成模型相结合的代表,促进了外部数据在语言生成过程中的无缝整合
Langchain是一个旨在通过将语言模型与外部知识源和数据库整合来增强语言模型能力的框架。它作为一个中间件,促进了语言模型与各种数据检索系统之间的交互,使它们能够更明智、准确地生成响应。Langchain的核心功能涉及从外部数据库到语言模型生成过程中信息流的编排,增强了它们利用上下文和特定知识进行响应的能力。这种整合在使语言模型能够执行需要访问最新或详细信息的任务中发挥了关键作用,这些信息并不包含在模型的初始训练数据中
LlamaIndex是一个专注于组织和索引大量数据以提高语言模型检索能力的专门数据框架。该框架支持高效的查询机制,允许语言模型快速访问结构化存储库中的相关信息。LlamaIndex旨在高度可扩展,并且可以处理各种数据类型,从文本文档到结构化数据库。索引数据支持从简单的事实检索到复杂的分析任务的广泛应用,使其成为增强语言模型中信息检索阶段的不可或缺的工具
Langchain和LlamaIndex都与RAG概念密切相关。Langchain通过为语言模型在生成过程中与外部数据库和知识源的交互提供结构化的方式,增强了RAG。另一方面,LlamaIndex作为RAG系统的强大的后端,确保检索过程既快速又相关。Langchain和LlamaIndex共同增强了RAG的能力,确保语言模型不仅基于其内部知识生成文本,而且能够引入外部数据以提供上下文丰富和信息稳健的响应
讨论和未来方向 (Discussion and Future Direction)
尽管 RAG 在自然语言处理方面取得了成功,但仍有一些挑战需要考虑。本文强调了这些挑战,以激发未来的研究,并为 NLP 中的 RAG 提供可能的未来研究方向
9.1 检索质量 (Retrieval Quality)
检索质量指的是提高 RAG 中检索到的信息的相关性,这涉及到以下四个关键因素的设计
首先考虑的是确定向量数据库中使用的最优键。这个过程通常涉及主观决策,并需要人为努力来有效设计。简单的想法是为给定的任务选择输入,将每个任务视为问答问题
其次是嵌入模型的选择。在确定键之后,下一步是利用嵌入模型将文本转换为向量表示。像 BERT、RoBERTa 或特定领域的嵌入模型对于确定如何捕捉细微差别和上下文含义至关重要。将嵌入模型适应于特定类型的数据或查询可以显著提高检索质量。这要求在包含系统将遇到的查询和文档类型的特定领域语料库上训练模型
第三,设计有效的相似性度量标准也是提高检索质量的关键。相似性度量的目标是测量查询和检索信息之间的相关性。一些经典相似性度量标准,如在推荐系统中用于排名的余弦相似度或欧几里得距离,也可以在 RAG 中使用。除了这些度量标准,一些工作探索了更复杂的相似性度量标准,如最优传输距离,以获得特定于任务的相似性
最后,近似最近邻(ANN)搜索也是决定什么知识应该作为最近邻返回的关键步骤。高级 ANN 搜索旨在以牺牲检索质量的代价加速检索效率。选择适当的 ANN 算法,如乘积量化或 HNSW,需要在检索效率和检索质量之间取得良好的权衡。所有这些因素共同促成了检索器的检索质量
9.2 RAG 效率 (RAG Efficiency)
RAG 效率对下游 NLP 应用至关重要,它限制了可以检索的数据量。有两种简单的方法可以在不使用新算法的情况下保证 RAG 效率,即减少数据量或增加更强大的计算和存储资源。然而,前者可能会影响检索质量,而后者需要更多的资源成本
RAG 效率包括检索器的效率和检索融合的效率。检索器效率指的是检索相关信息的时间成本,可以分为三部分,即编码时间、ANN 搜索时间和数据存储的数据获取时间。不必对所有三个组件进行联合优化,因为不同数据库大小的瓶颈会有所不同
对于较小的检索数据库,如少于100万条目,编码阶段通常是主要瓶颈,因为向量数据库可以全部存储在内存中
模型量化、蒸馏或模型剪枝等主题用于加速编码
相比之下,对于较大的数据库,索引搜索时间和从数据存储中获取数据的时间成为主要瓶颈,因为搜索涉及大量数据,获取涉及 I/O 开销。在这种情况下,高效的 ANN 搜索算法和系统级优化是主要关注点。检索融合效率旨在提高集成检索时的推理效率,值得优化以提高 RAG 效率
例如,基于查询的融合的计算开销通常不可忽视,因为长序列长度。一些工作,如 Fid-light 和 ReFusion,主要针对在集成检索信息时减少计算
9.3 融合选择 (Choices of Fusions)
本文介绍了三种检索融合方式,每种融合都值得进一步探索。基于查询的融合将检索到的知识的文本或嵌入与输入连接起来。这些方法具有更好的可解释性,并且易于应用,即使仅提供了大型语言模型的 API。然而,连接导致输入序列过长,从而导致注意力和输入截断的计算开销大。一些工作旨在提高集成检索时的效率,而其他工作则专注于提高增加模型输入长度时的效率。相反,基于潜在的融合在更深层次、更抽象的层面上整合信息,这可能捕捉到检索信息和查询之间更微妙的关系。然而,这些融合明显缺乏可解释性,通常需要预训练或微调以调整检索嵌入或重新加权检索。因此,提高这类基于潜在的融合的可解释性也值得在未来探索。基于 logits 的融合在决策层面整合信息,从而提供更灵活、更强大的数据整合。然而,这些融合可能过度简化融合过程,通过将检索信息简化为 logit 值,减少了检索信息的丰富性。同时,这种融合需要执行所有检索的推理,这也是一个耗时的过程。除了在实际应用中应用一种融合方式外,结合不同的融合方式也值得探索以获得更好的性能。这些融合方法不是相互排斥的,因为它们侧重于增强生成器的不同阶段,即输入、隐藏状态和输出。此外,在生成过程中,何时融合检索到的知识也是一个值得进一步探索的重要问题
9.4 RAG 训练 (RAG Training)
如第 6 节所述,RAG 训练包括两个分支的工作,带或不带数据存储更新的 RAG。对于不带数据存储更新的 RAG,主要挑战是如何联合优化 RAG 中的所有参数。这可能涉及具有多个目标的新损失函数、新优化以高效调整检索器和生成器中的参数,或其他训练策略。对于带数据存储更新的 RAG,一个挑战是如何使检索表示与生成器的表示对齐。尽管数据存储中的更新操作的时间成本不容忽视,但一些工作通过异步更新减少了更新频率,从而实现了知识表示和模型表示的对齐。另一个挑战是何时在 RAG 中重新训练/微调生成器,当添加了新的语料库时。由于现有的基于 LLM 的生成器的上下文学习能力和高昂的训练开销,重新训练/微调生成器或直接推断生成器成为不同场景下的一个挑战性选择。最近,一些高效的训练策略已经被提出以加速微调过程,这些策略可以考虑
9.5 跨模态检索 (Cross-Modality Retrieval)
在 NLP 任务中检索跨模态信息可以大大增强表示的质量和丰富性,从而提高性能。首先,跨模态信息,如将文本与图像、视频或音频结合起来,为内容提供了更丰富的上下文。例如,当语言含糊不清时,伴随的图像可以澄清仅通过文本难以传达的含义。其次,不同模态可以提供各种类型不从单一来源获得的信息。例如,视觉数据可以提供空间、颜色和动作线索,而文本数据可以提供详细的描述、情感或抽象概念。结合这些可以导致对数据的更全面理解。此外,通常在多模态数据上训练的模型表现出增加的鲁棒性和泛化能力。这些模型擅长在不同输入之间关联信息,减少对单一模态特性的过拟合。这一属性在 NLP 的现实世界应用中特别有价值,例如在自动驾驶车辆中,系统必须解释来自标志或对话的文本信息和来自周围环境的感官数据,以做出明智的决策。此外,多模态数据可以解决单一模态中无法解决的歧义。例如,短语 "bank" 可以指代金融机构或河岸,视觉上下文可以帮助消歧义。最后,人类的交流本质上是多模态的,结合了手势、面部表情和语调等元素。能够处理多种交流方式的系统可以以更自然、直观的方式与人类互动。总之,将跨模态信息整合到 RAG 中的 NLP 任务不仅增强了数据表示的丰富性和质量,而且显著提高了系统的理解能力、交互能力和适应不同应用的能力
Searching for Best Practices in Retrieval-Augmented Generation
http://arxiv.org/abs/2407.01219
2024-07-01
https://github.com/FudanDNN-NLP/RAG
尽管已经提出了许多 RAG 方法,通过查询依赖的检索来 增强大型语言模型,但这些方法仍然面临复杂的实现和较长的响应时间
研究现有的 RAG 方法及其潜在组合,以识别最佳的 RAG 实践
证明了多模态检索技术可以显著增强对视觉输入的问答能力,并通过“检索作为生成”策略加速多模态内容的生成
引言
生成性大型语言模型容易产生过时信息或虚构事实
检索增强生成(RAG)技术通过结合预训练和基于检索模型的优势来解决这些问题,从而提供了一个增强模型性能的强大框架[6]
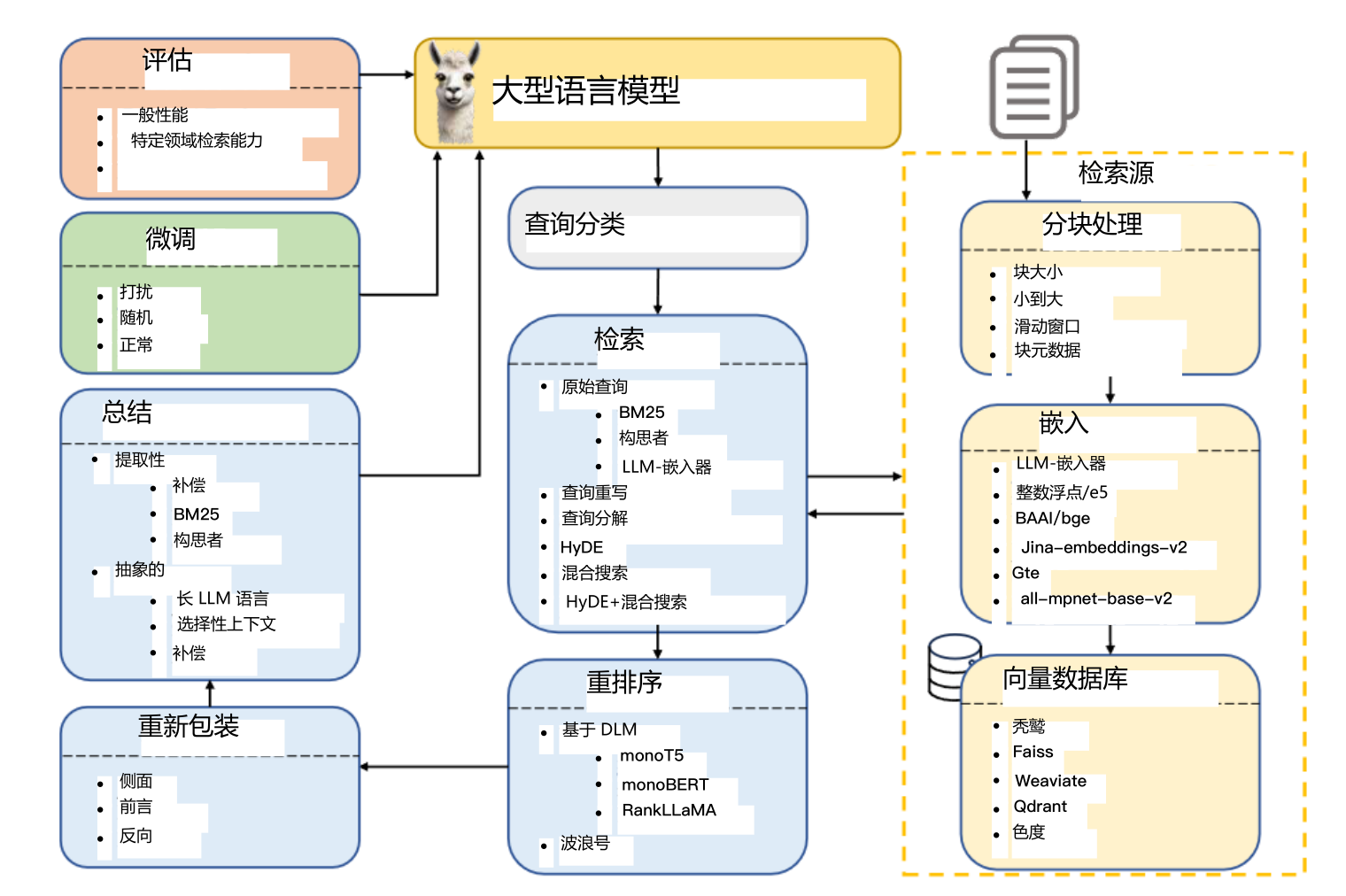
图 1:检索增强生成工作流程。本研究探讨了每个组件的贡献,并通过广泛的实验提供了最佳 RAG 实践的见解。每个组件考虑的可选方法以粗体字表示,而下划线的方法表示各个模块的默认选择。以蓝色字体表示的方法是通过实证研究确定的最佳选择
增加复杂性和挑战的是每个处理步骤实施的可变性,例如,在检索与输入查询相关的文档时,可以采用多种方法:
- 先重写查询,然后使用重写后的查询进行检索[9]
- 先生成查询的伪响应,然后比较这些伪响应与后端文档之间的相似性以进行检索[10]
- 直接使用嵌入模型,通常采用对比方式训练,使用正负查询-响应对[11,12]
[9] Xinbei Ma, Yeyun Gong, Pengcheng He, Hai Zhao, and Nan Duan. Query rewriting for retrieval-augmented large language models. arXiv preprint arXiv:2305.14283, 2023.
[10] Luyu Gao, Xueguang Ma, Jimmy Lin, and Jamie Callan. Precise zero-shot dense retrievalwithout relevance labels. arXiv preprint arXiv:2212.10496, 2022.
[11] Liang Wang, Nan Yang, Xiaolong Huang, Binxing Jiao, Linjun Yang, Daxin Jiang, Rangan Majumder, and Furu Wei. Text embeddings by weakly-supervised contrastive pre-training. arXiv preprint arXiv:2212.03533, 2022.
[12] Shitao Xiao, Zheng Liu, Peitian Zhang, and Niklas Muennighoff. C-pack: Packaged resources to advance general chinese embedding, 2023.
采用三步法来识别最佳的 RAG 实践:
- 比较每个 RAG 步骤(或模块)的代表性方法,并选择最多三种表现最佳的方法
- 通过逐一测试每种方法在单个步骤上的影响,同时保持其他 RAG 模块不变,来评估每种方法对整体 RAG 性能的影响。这使能够根据每个步骤的贡献及其与其他模块在响应生成过程中的互动,确定最有效的方法。一旦为某个模块选择了最佳方法,就会在后续实验中使用该方法
- 实证探索一些适合不同应用场景的有前景的组合,在这些场景中,效率可能优先于性能,反之亦然。基于这些发现,建议几种在性能和效率之间取得平衡的 RAG 部署策略
贡献
- 通过广泛的实验,彻底研究了现有的 RAG 方法及其组合,以识别和推荐最佳的 RAG 实践
- 引入了一个全面的评估指标框架和相应的数据集,以全面评估检索增强生成模型的性能,涵盖一般、专业(或领域特定)和与 RAG 相关的能力
- 证明了多模态检索技术的整合可以显著提高视觉输入上的问答能力,并通过 检索作为生成的策略加快多模态内容的生成
相关工作
查询与检索转换
有效的检索需要查询准确、清晰且详细,即使在转换为嵌入后,查询与相关文档之间的语义差异仍然可能存在
通过查询转换来增强查询信息的方法:
- Query2Doc [17]、HyDE [10] 从原始查询生成伪文档以增强检索
- TOC [18] 将查询分解为子查询,聚合检索到的内容以获得最终结果
转化检索源文档:
- LlamaIndex [19] 提供了一个接口,用于生成伪查询以检索文档,从而改善与真实查询的匹配
- 采用对比学习,使查询和文档嵌入在语义空间中更接近 [12, 20, 21]
后处理检索到的文档:
- 层次化提示摘要 [22] 、抽象与提取压缩器 [23] 来减少上下文长度和消除冗余 [24]
[17] Liang Wang, Nan Yang, and Furu Wei. Query2doc: Query expansion with large language models. arXiv preprint arXiv:2303.07678, 2023.
[18] Gangwoo Kim, Sungdong Kim, Byeongguk Jeon, Joonsuk Park, and Jaewoo Kang. Tree of clarifications: Answering ambiguous questions with retrieval-augmented large language models. arXiv preprint arXiv:2310.14696, 2023.
[22] Huiqiang Jiang, Qianhui Wu, Chin-Yew Lin, Yuqing Yang, and Lili Qiu. Llmlingua: Compressing prompts for accelerated inference of large language models. arXiv preprint arXiv:2310.05736, 2023.
检索器增强策略
文档分块和嵌入方法对检索性能有显著影响
小块可能会破坏句子结构,而大块可能包含无关的上下文
LlamaIndex [19] 优化了像 Small2Big 和滑动窗口这样的分块方法
检索到的块可能无关且数量可能很大,因此需要重新排序以过滤无关文档
重新排序方法采用深度语言模型,如 BERT [25]、T5 [26] 或 LLaMA [27]
TILDE [28, 29] 通过预计算和存储查询词的可能性来实现高效,根据它们的总和对文档进行排名
[28] Shengyao Zhuang and Guido Zuccon. Tilde: Term independent likelihood model for passage re-ranking. In Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 1483–1492, 2021.
[29] Shengyao Zhuang and Guido Zuccon. Fast passage re-ranking with contextualized exact term matching and efficient passage expansion. arXiv preprint arXiv:2108.08513, 2021.
检索器和生成器的微调
在 RAG 框架内的微调对于优化检索器和生成器至关重要
微调生成器,以更好地利用检索器的上下文[30-32],确保生成内容的真实性和稳健性
微调检索器,以学习为生成器检索有益的段落[33-35]
整体方法将 RAG 视为一个综合系统,同时微调检索器和生成器,以提高整体性能[36-38],尽管这增加了复杂性和集成挑战
RAG 工作流程
查询分类
并非所有查询都需要增强检索,因为LLMs本身具备的能力
虽然 RAG 可以提高信息的准确性并减少幻觉,但频繁的检索可能会增加响应时间
首先对查询进行分类,以确定是否需要检索
按类型对任务进行分类,以确定查询是否需要检索
将其分类为基于是否提供足够信息的 15 个任务,具体任务和示例在图 2 中说明
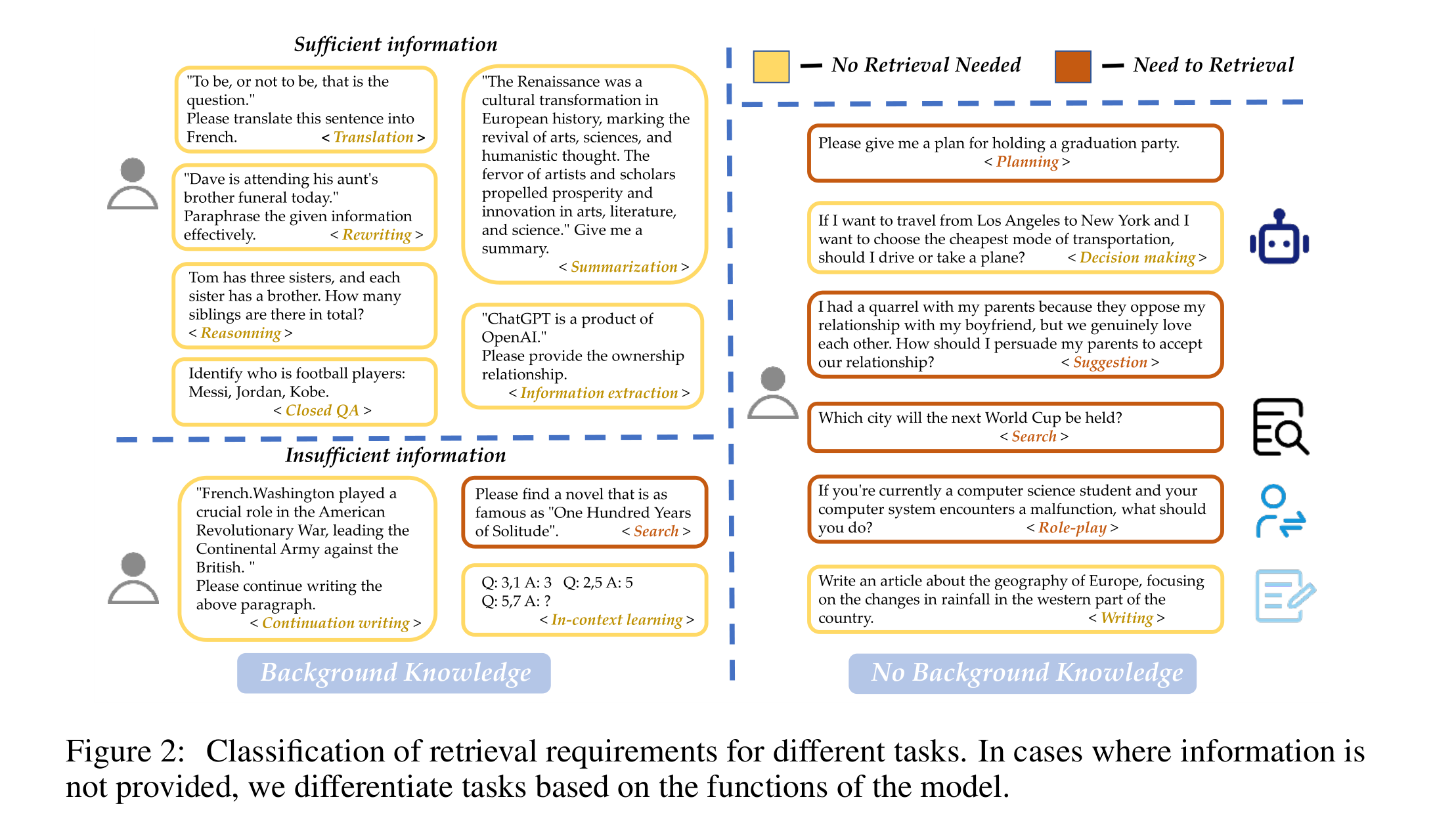
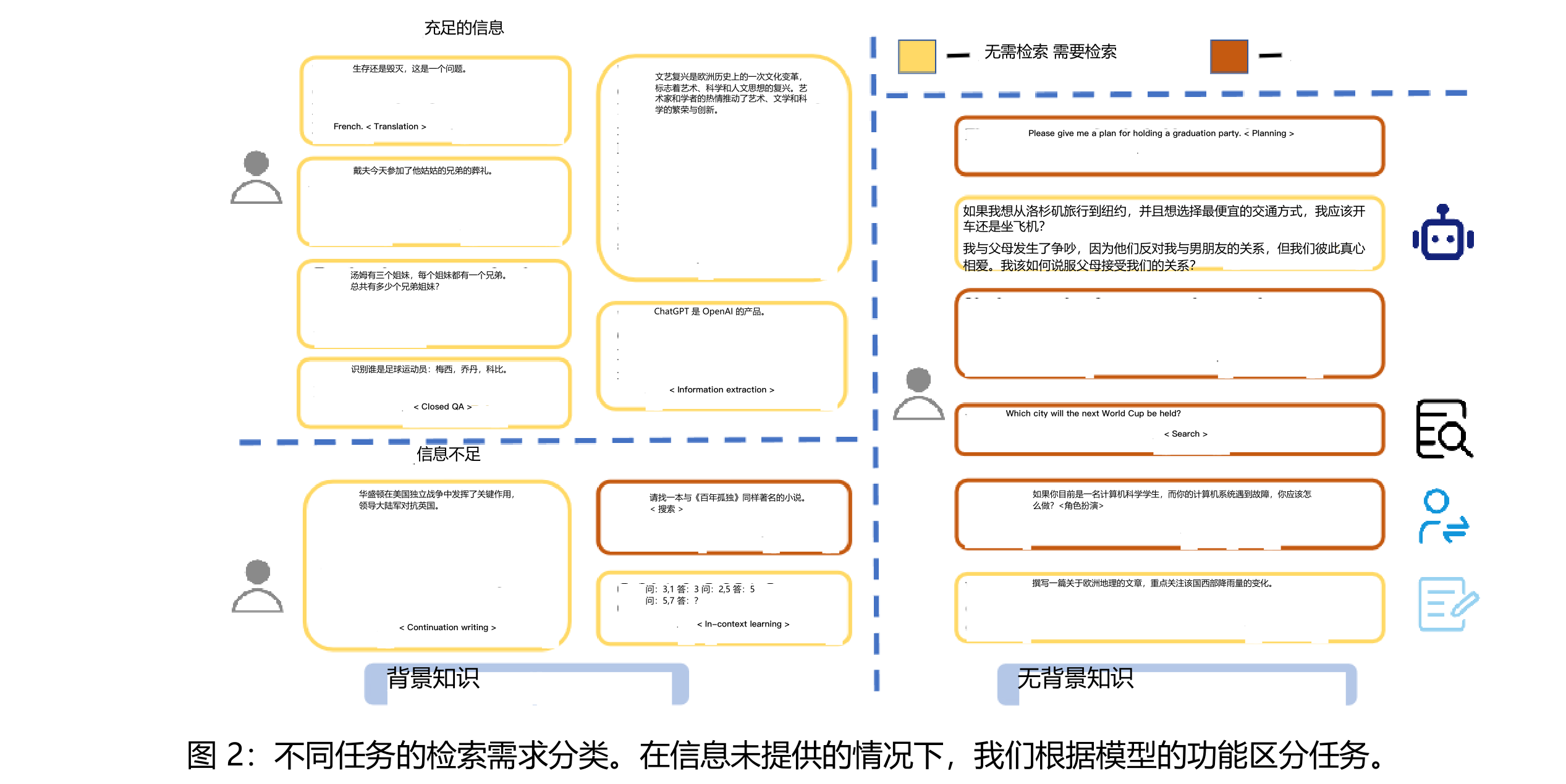
对于完全基于用户提供信息的任务,标记为“足够”,不需要检索;否则,标记为“不足”,可能需要检索
训练一个分类器来自动化这个决策过程。实验细节在附录 A.1 中呈现
TODO
分块
标记级块划分是直接的,但可能会拆分句子,从而影响检索质量
语义级块划分使用LLMs来确定断点,保持上下文但耗时
句子级块划分在保持文本语义的同时,实现了简洁性和高效性的平衡
在本研究中,使用句子级别的分块,平衡简单性和语义保留
较大的块提供更多上下文,增强理解,但增加处理时间。较小的块提高检索回忆率并减少时间,但可能缺乏足够的上下文
使用 LlamaIndex 的评估模块[43]来计算上述指标
使用 text-embedding-ada-002 模型,支持长输入长度
选择zephyr-7b-alpha 和 gpt-3.5-turboas生成模型和评估模型分别
块重叠的大小为 20 个标记
文档 lyft_2021 的前六十页被用作语料库,然后提示LLMs根据所选语料库生成大约一百七十个查询
不同块大小的影响如表 3 所示:
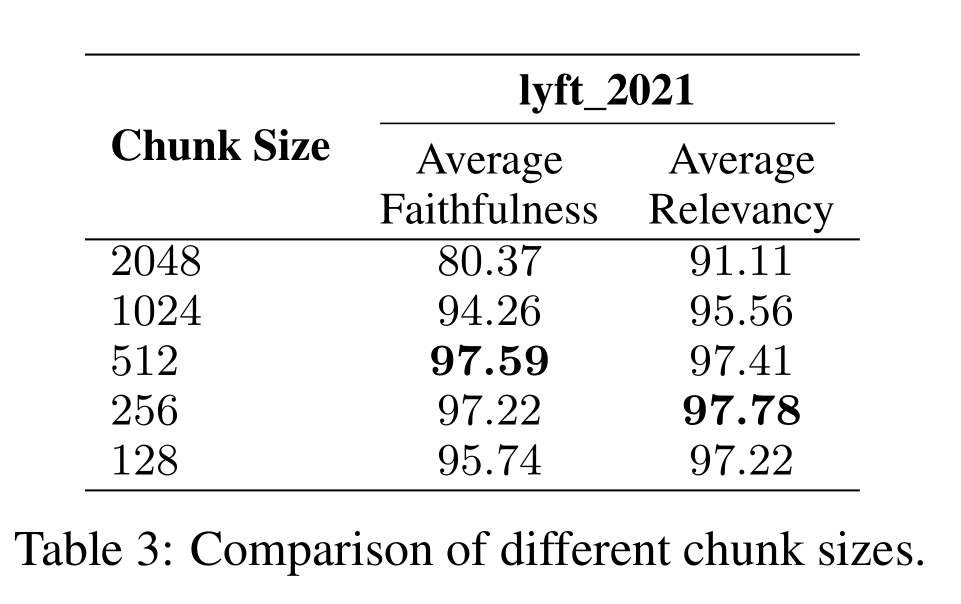
先进的技术,如小到大和滑动窗口,通过组织块之间的关系来提高检索质量。使用小尺寸块来匹配查询,并返回包含小块及上下文信息的大块
为了证明先进分块技术的有效性,使用LLM-Embedder [20]模型作为嵌入模型。较小的分块大小为 175 个标记,较大的分块大小为 512 个标记,分块重叠为 20 个标记。像小到大和滑动窗口这样的技术通过保持上下文并确保检索到相关信息来提高检索质量。详细结果见表 4
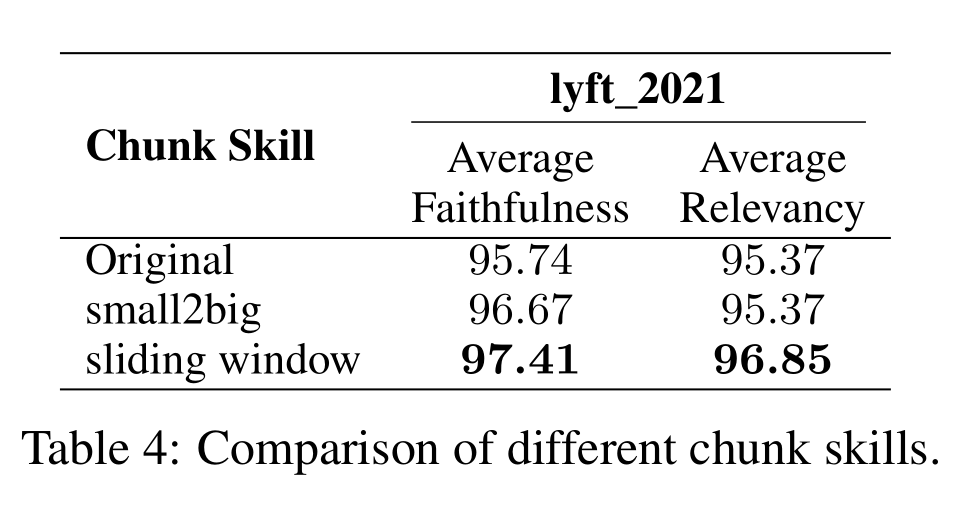
嵌入模型选择
使用 FlagEmbedding 的评估模块,该模块使用数据集 命名空间-Pt/msmarcoas 查询和数据集命名空间-Pt/msmarco-corpusas 语料库,以选择合适
的开源嵌入模型
如表 2 所示,LLM-Embedder[20] 的结果与 BAAI/bge-large-en [12] 相当,但前者的大小是后者的三分之一
[20] Peitian Zhang, Shitao Xiao, Zheng Liu, Zhicheng Dou, and Jian-Yun Nie. Retrieve anything to augment large language models. arXiv preprint arXiv:2310.07554, 2023.
选择 LLM-Embedder [20],因为它在性能和大小之间达到了平衡
元数据添加
通过增强块块的元数据,如标题、关键词和假设性问题,可以改善检索,提供更多的后处理检索文本的方法,并帮助LLMs更好地理解检索到的信息
向量数据库
向量数据库存储嵌入向量及其元数据,通过各种索引和近似最近邻(ANN)方法,实现与查询相关文档的高效检索

检索方法
原始查询由于表达不佳和缺乏语义信息而往往表现不佳[6],对检索过程产生负面影响
为了解决这些问题,评估了三种查询转换方法,使用第 3.2 节中推荐的LLM-嵌入器作为查询和文档编码器
- 查询重写:查询重写对查询进行优化,以更好地匹配相关文档。受到重写-检索-阅读框架[9]的启发,提示LLM对查询进行重写,以提高性能
- 查询分解:该方法涉及根据从原始查询中派生的子问题检索文档,这种方法更复杂,难以理解和处理
- 伪文档生成:该方法基于用户查询生成一个假设文档,并使用假设答案的嵌入来检索相似文档。一个显著的实现是 HyDE [10]
最近的研究,如[44]所示,表明将基于词汇的搜索与向量搜索相结合显著提高了性能
在本研究中,使用 BM25 进行稀疏检索,并使用 Contriever [45],一种无监督对比编码器,进行密集检索,作为基于 Thakur 等人[46]的两个强大基线
评估了不同搜索方法在 TREC DL 2019 和 2020 段落排名数据集上的表现
结果显示:
监督方法显著优于无监督方法
结合 HyDE 和混合搜索,LLM-Embedder 达到了最高分数
查询重写和查询分解并没有有效提升检索性能
推荐将带有HyDE 的混合搜索作为默认检索方法
考虑到效率,混合搜索结合了稀疏检索(BM25)和密集检索(原始嵌入),在相对较低的延迟下实现了显著的性能
表 7 显示了使用 HyDE 对假设文档和查询的不同连接策略的影响。将多个伪文档与原始查询连接起来可以显著提高检索性能,尽管以增加延迟为代价,这表明检索有效性和效率之间存在权衡。然而,随意增加假设文档的数量并不会带来显著的好处,反而大幅提高了延迟,这表明使用单个假设文档是足够的
在稀疏检索中采用不同权重的混合搜索
表格 8 展示了不同 值在混合检索中的影响,其中 控制稀疏检索和密集检索组件之间的权重。相关性评分计算如下:
其中, 和 分别是稀疏检索和密集检索的归一化相关性评分, 是总检索评分
评估了五个不同的 值,以确定它们对性能的影响。结果表明, 值为 0.3 时性能最佳,这表明适当调整 可以在一定程度上提高检索效果。因此,检索和主要实验中选择了
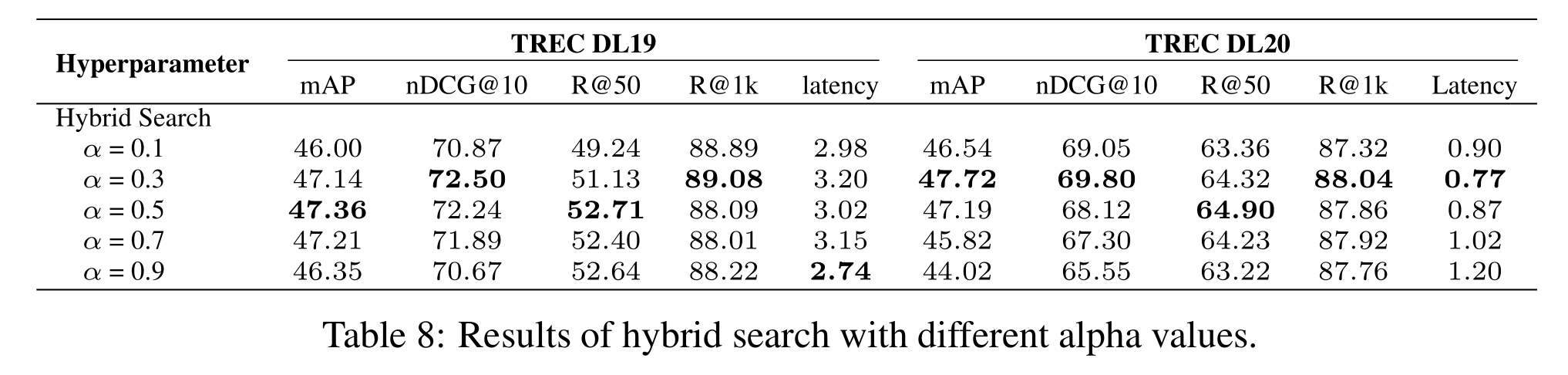
重新排序方法
采用重新排序阶段以增强检索文档的相关性,确保最相关的信息出现在列表的顶部p[]
DLM 重新排序,利用分类;TILDE 重新排序,侧重于查询可能性。这些方法分别优先考虑性能和效率
DLM 重排序:该方法利用深度语言模型(DLMs)[25-27]进行重排序
这些模型经过微调,以将文档与查询的相关性分类为“真实”或“虚假”
在微调过程中,模型使用连接的查询和文档输入进行训练,并根据相关性进行标记
在推理时,文档根据“真实”标记的概率进行排名TILDE 重新排序:TILDE [28, 29] 通过预测模型词汇表中每个查询词的标记概率,独立计算每个查询词的可能性
文档的得分是通过求和得到的查询标记的预计算对数概率,允许在推理时快速重新排序
TILDEv2 通过仅索引文档中存在的标记、使用 NCE 损失以及扩展文档来改进这一点,从而提高效率并减少索引大小
文档的评分是通过求和来完成的。实验是在 MS MARCO 段落排名数据集 [47] 上进行的,这是一个用于机器阅读理解的大规模数据集。遵循并对 PyGaggle [26] 和 TILDE [28] 提供的实现进行了修改,使用了模型 monoT5、monoBERT、RankLLaMA 和 TILDEv2
重新排名的结果如表 9 所示
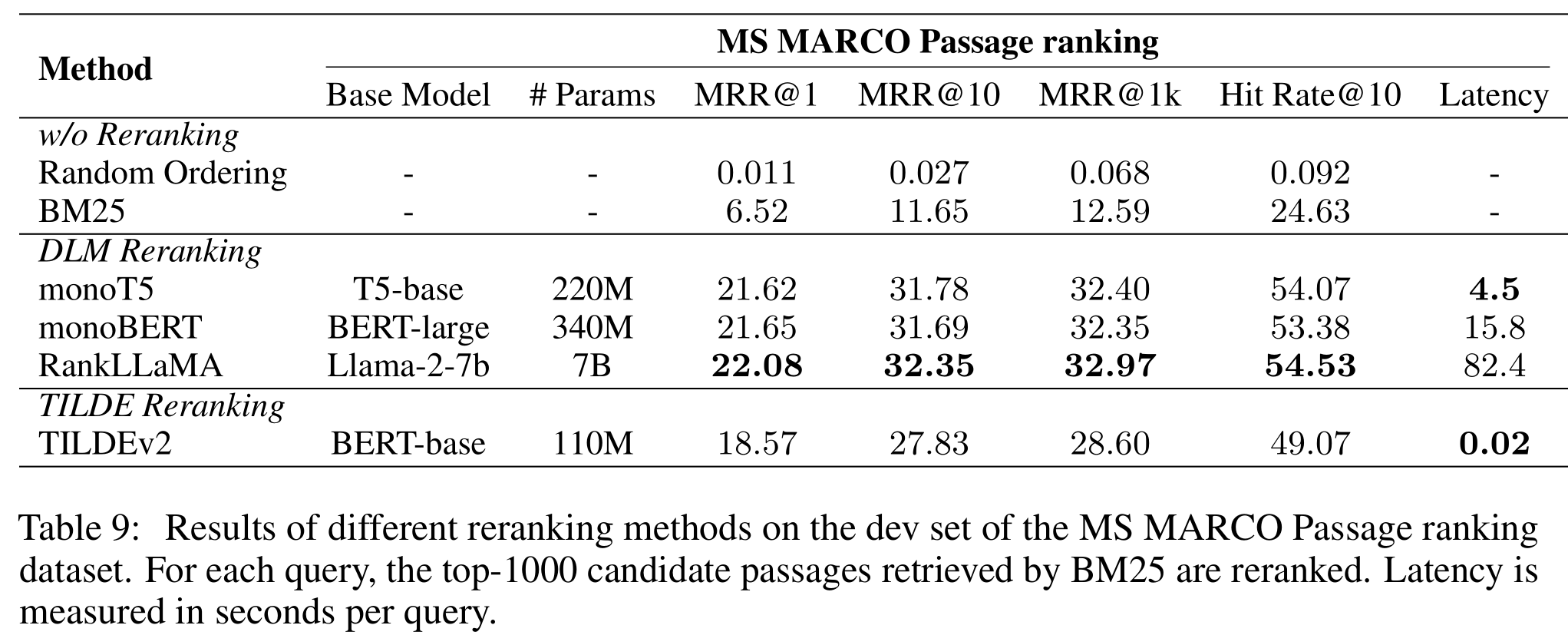
推荐 monoT5 作为一种平衡性能和效率的综合方法。RankLLaMA 适合于实现最佳性能,而TILDEv2 则非常适合在固定集合上获得最快的体验。实验设置和结果的详细信息见附录 A.3
文件重新包装
后续过程的表现,例如LLM响应生成,可能会受到文档提供顺序的影响
为了解决这个问题,在重新排序后将一个紧凑的重新打包模块纳入工作流程,具有三种重新打包方法:“前向”、“反向”和“侧向”
“前向”方法根据重新排序阶段的相关性得分按降序重新打包文档
“反向”则按升序排列
受到刘等人[48]的启发,他们得出结论认为,当相关信息位于输入的开头或结尾时,能够实现最佳性能,还包括了“侧向”选项
由于重新打包方法主要影响后续模块,在第 4 节中通过与其他模块的组合测试选择最佳的重新打包方法。在本节中,选择“侧面”方法作为默认的重新打包方法
摘要
摘要任务可以分为提取式和抽象式
提取式方法将文本分割成句子,然后根据重要性对其进行评分和排序
抽象式压缩器从多个文档中综合信息,以重新表述和生成连贯的摘要
这些任务可以是基于查询的或非基于查询的,在本文中,由于 RAG 检索与查询相关的信息,专注于基于查询的方法
- Recomp: Recomp [ 23 ] 具有提取式和抽象式压缩器。提取式压缩器选择有用的句子,而抽象式压缩器则从多个文档中综合信息
- LongLLMLingua:LongLLMLingua [49] 通过关注与查询相关的关键信息来改进 LLMLingua
- 选择性上下文通过识别和去除输入上下文中的冗余信息来提高LLM的效率。它通过使用词汇单位的有效性进行评估由基础因果语言模型计算的自信息。这种方法是非查询基础的,允许对基于查询和非查询基础的方法进行比较
它评估了词汇单位的信息量。在三个基准数据集上评估这些方法:NQ、TriviaQA 和HotpotQA
不同摘要方法的比较结果如表 10 所示
推荐 Recomp,因为它表现出色。LongLLMLingua 的表现不佳,但由于未在这些实验数据集上训练,显示出更好的泛化能力。因此,将其视为一种替代方法
附录 A.4 中提供了额外的实现细节和关于非查询基础方法的讨论
生成器微调
将 x 表示为输入到 RAG 系统的查询,将 D 表示为该输入的上下文。生成器的微调损失是真实输出 y 的负对数似然
TODO
寻找最佳 RAG 实践
对每个模块使用了第 3 节中确定的默认实践。按照图 1 所示的工作流程,依次优化各个模块,并在备选方案中选择最有效的选项
使用了经过微调的 Llama2-7B-Chat 模型,其中每个查询都通过一些随机选择的相关文档进行了增强作为生成器
使用 Milvus 构建了一个向量数据库,其中包含 1000 万条英文维基百科文本和400 万条医学数据文本
还研究了去除查询分类、重排序和摘要模块的影响,以评估它们的贡献
综合评价
- 进行了广泛的实验以评估 RAG 系统在多种自然语言处理任务上的性能,包括:
- 常识推理
- 事实核查
- 开放领域问答
- 多跳问答
- 医学问答
- 实验涉及了多个数据集,详细信息在附录 A.6 中提供
- 使用了 RAGAs 推荐的指标来评估 RAG 的能力,包括:
- 忠实性
- 上下文相关性
- 答案相关性
- 答案正确性
- 通过计算检索文档与黄金文档之间的余弦相似度来测量检索相似性
- 在常识推理、事实检查和医学问答任务中使用准确性作为评估指标
- 对于开放域问答和多跳问答,评估指标包括词元级 F1 分数和精确匹配(EM)分数
- RAG 的最终得分是通过平均上述五个能力得出的
- 采用了从每个数据集中随机抽取最多 500 个示例的方法进行评估
结果与分析
- 查询分类模块:提高了有效性和效率,使整体得分平均提升到0.443,查询延迟时间从16.41秒减少到11.58秒
- 检索模块:虽然“与 HyDE 混合”的方法在 RAG 分数上达到最高(0.58),但计算成本高,每个查询需11.71秒。推荐使用“混合”或“原始”方法,以减少延迟同时保持性能
- 重排序模块:缺少该模块会导致性能显著下降,MonoT5 通过重排序取得最高平均分,显示了重排序在提升生成响应质量中的关键作用
- 重新打包模块:反向配置表现出更优越的性能,获得0.560的 RAG 分数,说明将更相关的上下文更靠近查询能带来最佳结果
- 摘要模块:Recomp 性能优越,尽管去除摘要模块可以降低延迟,但由于 Recomp 能解决生成器的最大长度限制,它仍然是首选。在时间敏感的应用中,去除摘要模块可以减少响应时间
实验结果表明,RAG 系统中的每个模块都对整体性能有独特贡献,查询分类模块提升了准确性和效率,检索和重排序模块增强了处理多样化查询的能力,而重新打包和摘要模块则优化了系统输出,确保提供高质量的响应
讨论
⭐️⭐️⭐️⭐️⭐️实施 RAG 的最佳实践
- 最佳性能实践:
- 结合查询分类模块
- 使用“与 HyDE 混合”的检索方法
- 采用 monoT5 进行重排序
- 选择 Reverse 进行重新打包
- 利用 Recomp 进行摘要
- 这种配置虽然计算密集,但能产生最高的平均得分 0.483
- 平衡效率实践:
- 引入查询分类模块
- 实施混合检索方法
- 使用 TILDEv2 进行重排序
- 选择反向进行重新打包
- 采用 Recomp 进行摘要
- 通过转向混合检索方法并保持其他模块不变,可以在显著减少延迟的同时,保持相当的性能
多模态扩展
- 多模态应用扩展:RAG 系统已扩展至包括文本到图像和图像到文本的检索功能
- 检索源:使用大量成对的图像和文本描述作为检索源
- 功能优势:
- 扎根性:检索方法确保信息的真实性和特异性,相较于实时生成减少事实错误或不准确
- 效率:检索方法在答案已存在时更高效,生成方法可能需要更多计算资源
- 可维护性:基于检索的方法通过扩大检索源规模和提高质量来适应新需求,比生成模型更易维护
- 应用策略:在用户查询与存储图像的文本描述高度一致时,使用“检索即生成”策略加快图像生成过程;图像到文本功能则在用户提供图像并进行对话时使用
- 未来计划:计划将多模态策略扩展至视频和语音等其他模态,并探索高效的跨模态检索技术
Revolutionizing Retrieval-Augmented Generation with Enhanced PDF Structure Recognition(革命性地增强检索增强生成的 PDF 结构识别)
摘要
目前主要方法依赖于访问高质量文本语料库的前提
专业文档主要存储在 PDF 中,PDF 解析的低准确性显著影响了基于专业知识的问答的有效性
对来自相应真实专业文档的数百个问题进行了实证 RAG 实验
配备全景和精准 PDF 解析器的 RAG 系统 ChatDOC(chatdoc.com)能够检索到更准确和完整的片段,从而提供更好的答案。 实证实验表明,ChatDOC 在近 47%的问题上优
于基线,在 38%的情况下持平,仅在 15%的情况下表现不佳
1 引言
从 PDF 文件中检索的过程充满了挑战。常见的问题包括文本提取的不准确性以及 PDF 文件中表格的行列关系混乱
因此,在进行 RAG 之前,需要将大型文档转换为可检索的内容
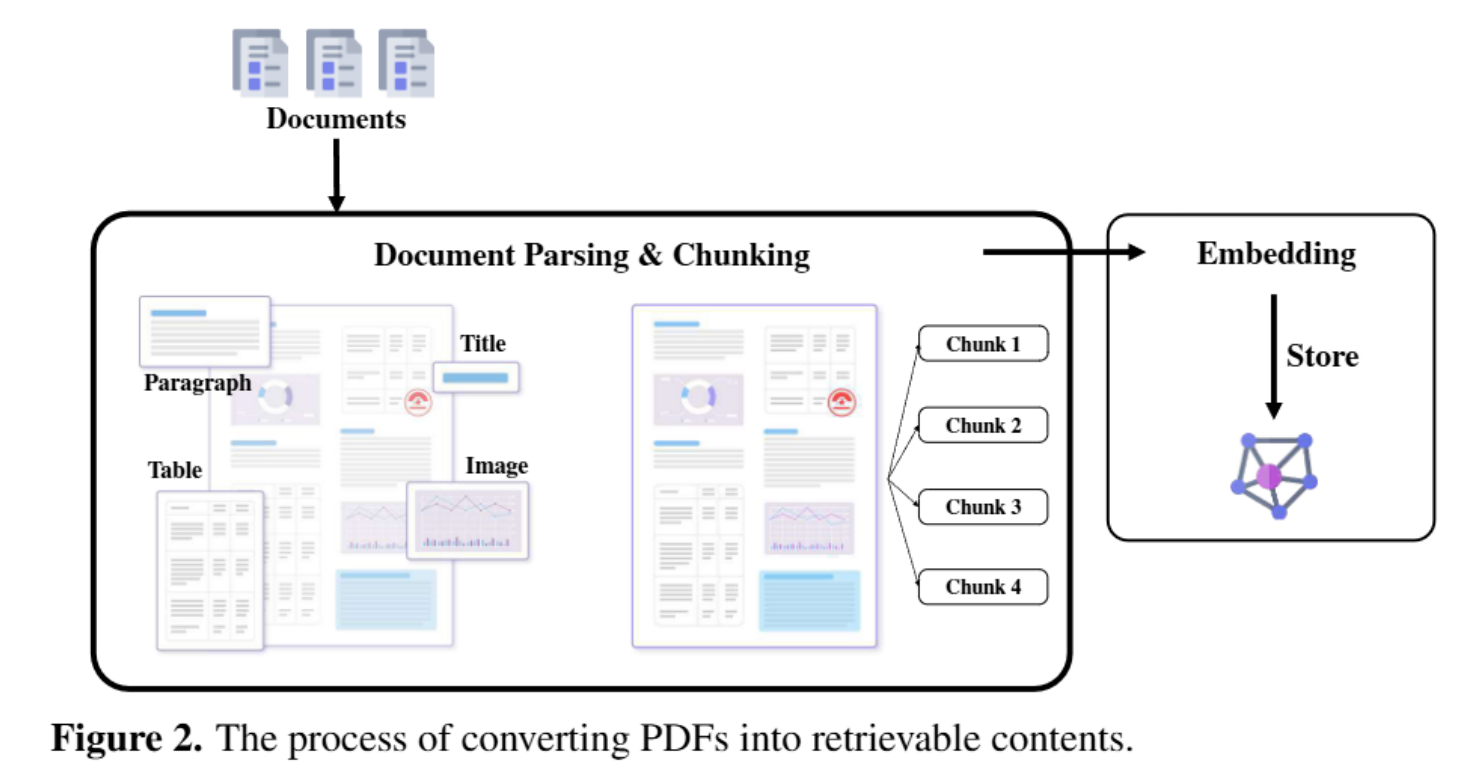
本文主要探讨 PDF 解析和分块的质量是否会影响 RAG 的结果
基于规则的方法和基于深度学习的方法,随后通过实际示例对其有效性进行实证评估
2 PDF 解析与分块
为了使LLMs能够有效管理未标记的文档,需要一个将分散字符组织成具有其结构的连贯文本的解析器
理想情况下,PDF 解析器应具备以下关键特性:
- 文档结构识别:它应能够熟练地将页面划分为不同类型的内容块,如段落、表格和图表。这确保了划分后的文本块是完整且独立的语义单元
- 复杂文档布局中的鲁棒性:它应该能够很好地处理具有复杂布局的文档页面,例如多列页面、无边框表格,甚至是合并单元格的表格
目前,PDF 解析主要有两种方法:基于规则的方法和基于深度学习的方法
PyPDF 是一种广泛使用的基于规则的解析器,是 LangChain 中 PDF 解析的标准方法
ChatDOCPDF 解析器(https://pdfparser.io/),基于深度学习模型
PyPDF
PyPDF 将 PDF 中的字符序列化为一个没有文档结构信息的长序列
这个序列经过分段,形成离散的块,利用一些分段规则,例如LangChain 中的“RecursiveCharacterTextSplitter”函数
该函数根据预定义的分隔符列表对文档进行划分,例如换行符“\n”
在初步分段之后,只有当合并块的长度不超过预定的 N 个字符限制时,才会合并相邻的块
在此之后,我们使用“PyPDF”来指代使用PyPDF+RecursiveCharacterTextSplitter 进行文档解析和分块的方法,前提是没有上下文歧义
以下内容中,块的最大长度设置为 300 个标记

- 它无法识别段落和表格的边界。它错误地将表格分成两部分,并将第二部分与后续段落合并为一个块
- 它无法识别表格中的结构。在“2 分块结果”部分,在块 1 中,表格的上半部分被表示为一系列短语,其中一个单元格可能被拆分
- 它无法识别内容的阅读顺序
ChatDOC PDF 解析器
在超过一千万个文档页面的语料库上进行训练
- 文本定位和识别的光学字符识别(OCR)
- 物理文档对象检测
- 跨列和跨页修整
- 阅读顺序确定
- 表格结构识别
- 文档逻辑结构识别
ChatDOC PDF 解析器旨在始终以 JSON 或 HTML 格式提供解析结果,即使对于具有挑战性的 PDF 文件
它将文档解析为内容块,每个块对应一个表格、段落、图表或其他类型。对于表格,它输出每个单元格中的文本,并指明哪些单元格合并为一个新单元格
对于具有层级标题的文档,它输出文档的层级结构

3 关于 PDF 识别对 RAG 影响的实验
文档的解析和分块方式是否会影响 RAG 系统提供答案的质量?
进行了系统实验以评估其影响
RAG 回答质量的定量评估
ChatDOC:使用 ChatDOC PDF 解析器解析文档,并利用结构信息进行分块
基线:使用PyPDF 解析文档,并使用 RecursiveCharacterTextSplitter 函数进行分块
其他组件,如嵌入、检索和问答,对于两个系统都是相同的
数据:
来自各个领域的 188 份文档(100 篇学术论文、28 份财务报告以及 60 份来自其他类别的文档,如教科书、课件和立法材料)
通过众包收集了 800 个手动生成的问题(经过仔细筛选,去除了低质量的问题,得到了 302 个用于评估的问题)
问题被分为两类(如表 2 所示):
- 提取性问题是指可以通过文档中的直接摘录来回答的问题。通常,它们需要精确的答案,因为它们寻求特定的信息。在使用LLM进行评估时,它可能无法区分答案之间微妙但重要的差异,因此依赖人工评估。使用 0-10 的评分标准来评估结果。注释员会同时获得两种方法的检索内容和答案,并对这两种方法进行评分。展示检索内容,因为通常在没有文档内容的情况下无法评估答案,并将两种方法一起展示以促进详细比较,特别是在部分正确的结果上
- 综合分析问题需要从多个来源和方面综合信息并进行总结。由于答案较长,并且需要对给定文档内容有全面的理解,发现人类评估这一过程既困难又耗时。因此,使用 GPT-4 来评估答案质量,评分范围为 1 到 10。还在一次请求中对两种方法的结果进行评分。但只提供检索到的内容而不提供答案,因为与提取性问题相比,答案较长(因此成本较高),而更好的检索内容可以暗示更好的答案(因为使用的LLM是相同的)
两种方法的一对结果被评分 4 次以避免偏见[5],并使用它们的平均值。具体而言,对于一对内容(A,B)进行相同问题的比较,同时输入两者将 A 和 B 输入 GPT-4 进行两次比较和评分。还会调换它们的顺序,将 B 和 A 输入 GPT-4,并重复请求两次
结果
在 86 个提取性问题中,ChatDOC 在 42 个案例中表现优于基线
36 个案例中持平,仅在 8 个案例中不如基线
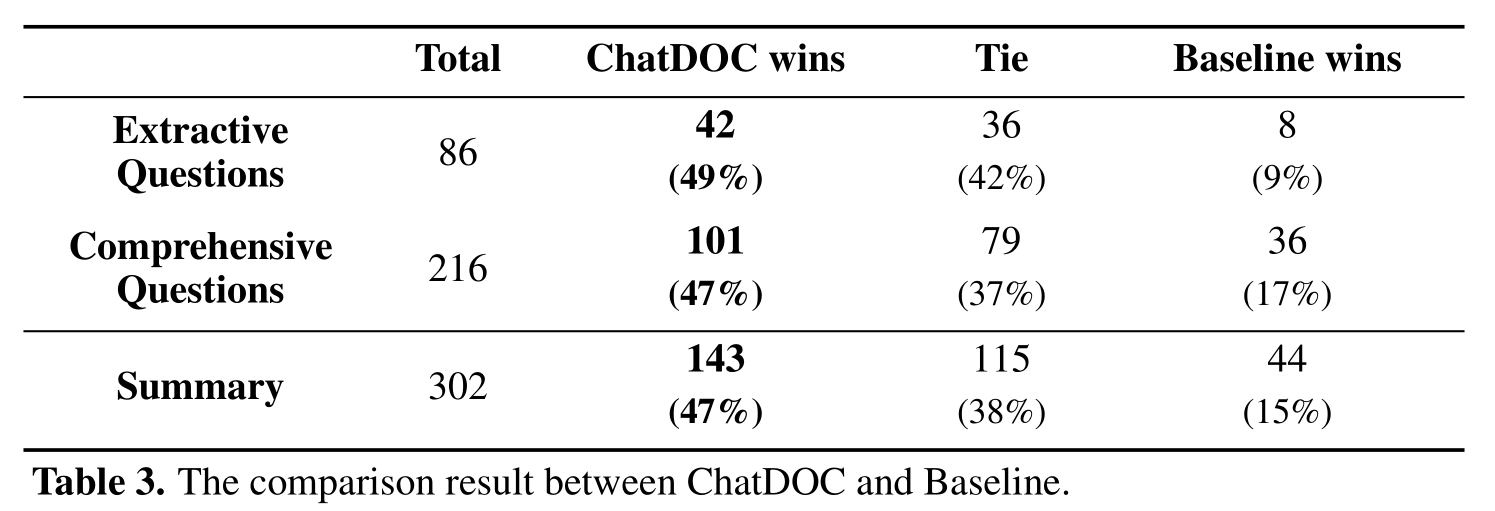
对局限性的讨论
排名和令牌限制问题。如果 ChatDOC 首先检索到一个大型但不相关的表格,它会占用上下文窗口,从而无法访问相关信息(这主要是因为嵌入模型没有将相关片段排名为最佳结果)
细分缺陷。ChatDOC 错误地将标题识别为普通段落,因此标题和表格被存储在不同的块中。这导致仅检索到部分所需信息,即表格的标题和脚注,但未能获取表格中的关键内容。改善表格标题识别可以解决这些问题
Self-rag: Learning to Retrieve, Generate, and Critique through Self-Reflection(自我反思:学习检索、生成和批判)
Published as a conference paper at ICLR 2024
摘要
无论是否需要检索,或者检索到的段落是否相关,无差别地检索和整合固定数量的检索段落,都会降低 LM 的多样性,或者可能导致生成无用的回应
引入了一个新的框架,称为自省式检索增强生成(SELF-RAG),它通过检索和自省来提高 LM 的质量和事实性。框架训练了一个单一的任意 LM,它适应性地按需检索段落,并使用特殊的标记,称为反思标记,生成和反思检索到的段落和它自己的生成内容。生成反思标记使得 LM 在推理阶段可控,能够根据不同的任务需求调整其行为
实验表明,SELF-RAG(具有 7B 和 13B 参数)在一系列多样化的任务上显著优于最先进的 LLMs 和检索增强模型。特别是,SELF-RAG 在开放领域问答、推理和事实验证任务上超过了 ChatGPT 和检索增强的 Llama2-chat,并且在提高长篇生成的事实性和引用准确性方面相对于这些模型有显著提升
1 引言
检索增强生成(RAG)方法可能会阻碍 LLM 的通用性,或者引入不必要或离题的段落,导致生成质量低下,因为它们不加区分地检索段落,而不管事实基础是否有帮助
模型没有明确地训练来利用和遵循提供段落中的事实,输出不能保证与检索到的相关段落一致
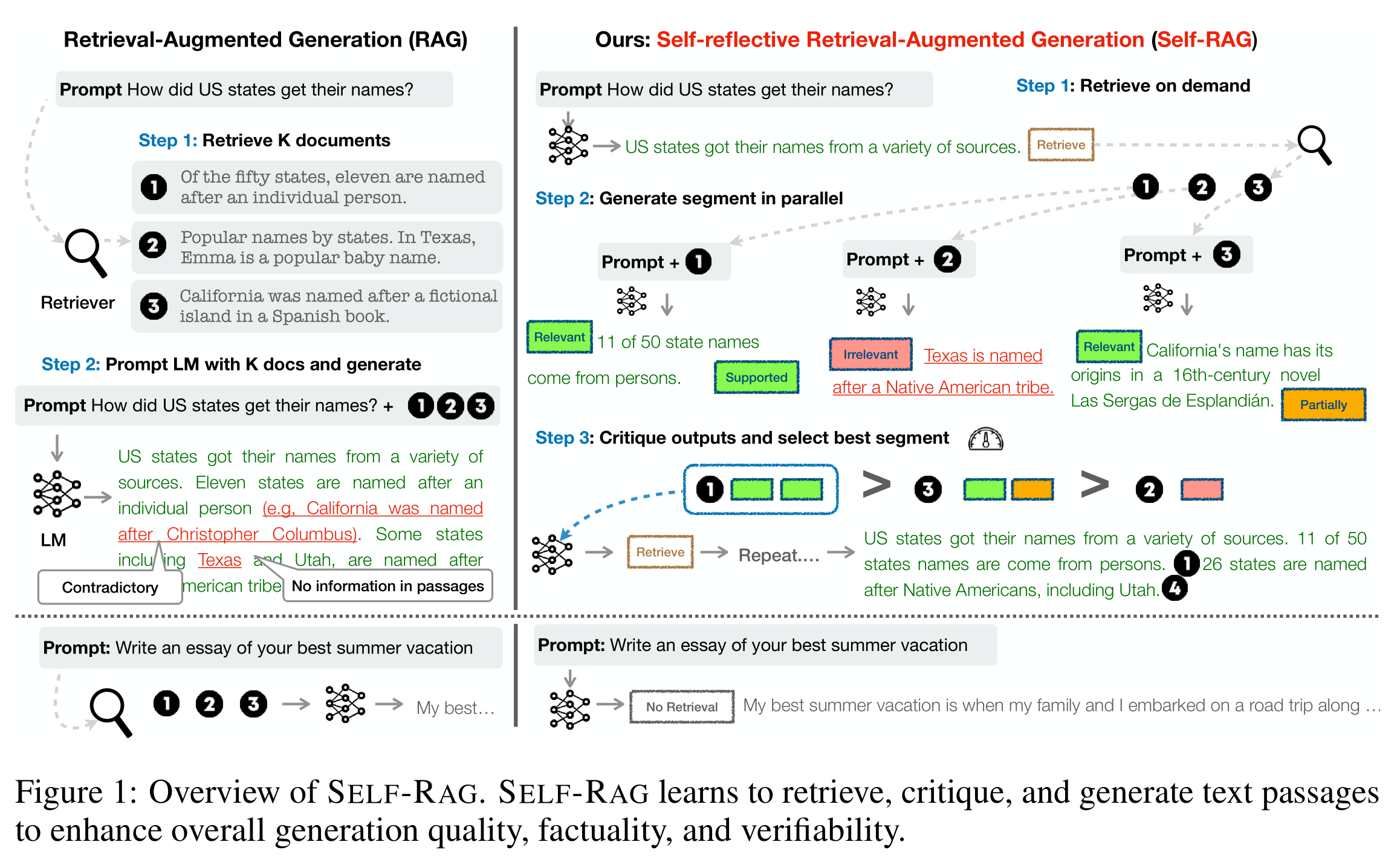
以端到端的方式训练一个任意语言模型(LM),使其学会在给定任务输入时,通过生成任务输出和间歇性特殊标记(即反思标记)来反思其自身的生成过程
反思标记被分为检索标记和批评标记,分别表示需要检索和生成质量的指示
在给定的输入提示和先前生成的基础上,SELF-RAG 首先判断是否通过检索到的段落来增强继续生成会有所帮助
如果是,它输出一个检索标记,以便按需调用检索器模型(步骤 1)
随后,SELF-RAG 同时处理多个检索到的段落,评估它们的相关性,然后生成相应的任务输出(步骤 2)
然后它生成批评标记,以批评自己的输出,并选择最佳的一个(步骤 3),在事实性和整体质量方面
这个过程与传统的 RAG(见图 1 左侧)不同,传统的 RAG 始终为生成检索固定数量的文档,而不管检索的必要性如何(例如,底部的示例不需要事实知识),并且从不重新评估生成质量。此外,SELF-RAG 为其每个部分提供引用,并对其输出是否得到段落的支撑进行自我评估,从而便于事实验证
将反思标记统一为扩展模型词汇表的下一个标记预测,训练任意语言模型(LM)生成带有反思标记的文本
在一个包含反思标记和检索段落的多样化文本集合上训练生成 LM
反思标记受到强化学习中使用的奖励模型的启发,由训练过的评判模型 offline 插入原始语料库中
SELF-RAG 进一步实现了一个可定制的解码算法,以满足由反思标记预测定义的硬性或软性约束
特别是,推理时算法能够(1)灵活调整不同下游应用中的检索频率;(2)通过在段落级别使用加权线性反思标记概率和作为段落分数,利用反思标记定制模型行为以符合用户偏好
六项任务(包括推理和长篇生成)的实证结果表明,SELF-RAG 在参数更多、被广泛采用的引用准确性更高的预训练和指令微调 LLM 以及 RAG 方法上显著优于
SELF-RAG 在四项任务上超过了采用检索增强的 ChatGPT,在所有任务上超过了 Llama2-chat
2 相关工作
对于检索到的段落,将其添加到输入之前,或者联合预训练检索器和语言模型(LM),然后在任务数据集上进行少量样本的微调(Izacard et al., 2022b)
我们引入了一种方法,用于训练任意的语言模型学习按需使用检索来处理多样化的指令遵循查询,并通过反思标记引导的生成控制来进一步提高生成质量和归因
训练和生成时的评价。使用强化学习(例如,近端策略优化或 PPO;Schulmanet al. 2017)从人类反馈中训练 LLM(RLHF)已被证明在使 LLM 与人类偏好对齐方面是有效的(Ouyang et al., 2022; Wu et al., 2023)
offline 地在任务示例上训练目标 LM,这些示例通过评价者模型的反思标记进行了增强,与 RLHF 相比,训练成本大大降低
与之前使用控制标记来指导 LM 生成的工作(Lu et al. 2022; Korbak et al., 2023)相比,SELF-RAG 使用反思标记来决定检索的需要和对生成质量的自我评估
3 Self-Rag:学习检索、生成和评价
SELF-RAG是一种通过检索和自反来增强大型语言模型(LLM)质量和真实性的框架,同时不牺牲 LLM 原有的创造性和多样性
端到端训练让语言模型(LM)M 能够根据检索到的段落生成文本,如有需要,还能通过学习生成特殊标记来批判输出结果
反思标记(表 I)表示需要检索或确认输出结果的相关性、支持或完整性
3.1 问题形式化和概述
给定输入 ,训练 按顺序生成文本输出 ,由多个段 组成,其中 表示第 个段的令牌序列
在 中生成的令牌包括原始词汇中的文本以及反思标记(表 I)

图 1 和算法 1 展示了 SELF-RAG 在推断过程中的概述

训练概述:通过将反思标记作为扩展模型词汇表(即原始词汇加上反思标记)中的下一个标记预测,使得任意语言模型能够生成带有反思标记的文本
在一个经过精选的语料库上训练生成模型 M ,该语料库中交织了由检索器 R 检索到的段落和由评判模型 C 预测的反思标记(附录算法 2 中总结)
训练 C 为评估检索到的段落和给定任务输出的质量生成反思标记
使用评判模型,通过离线将反思标记插入任务输出中更新训练语料库
使用传统的语言模型目标(第 3.2.2 节)训练最终的生成模型 (M) ,以使 M 能够在推理时独立于评判模型生成反思标记
3.2 SELF-RAG 训练
3.2.1 训练评判模型
手动注释每个片段的反思标记代价高昂(Wu et al.2023)。一种最先进的 LLM,如 GPT-4(OpenAI 2023),可以有效地用来生成此类反馈(Liu et al. 2023b),依赖此类专有语言模型可能会增加 API成本并降低可重复性(Chen et al. 2023)
方法需要对训练数据集中的每个输入-输出实例的多个段落以及每个片段进行细粒度评估,从而指数级地增加了生成 SELF-RAG 训练数据所需的评估数量
通过提示 GPT-4 生成反思标记,将它们的知识提炼到内部的 C 中
对于每组反思标记,从原始训练数据中随机抽样实例:{Xsample , Y sample }∼
不同的反思标记组有其定义和输入,如表 1 所示。为它们使用不同的指令提示
使用特定类型的指令提示GPT-4(“给定一个指令,判断从网络中查找一些外部文档是否有助于生成更好的响应。”)随后是少量示例 I 原始任务输入 x 和输出 y ,以预测适当的反思标记作为文本:p (r | I, x, y)
手动评估显示,GPT-4 反思标记的预测与人类评估高度一致。为每种类型收集 4k − 20k 监督训练数据,并将它们组合形成C 的训练数据
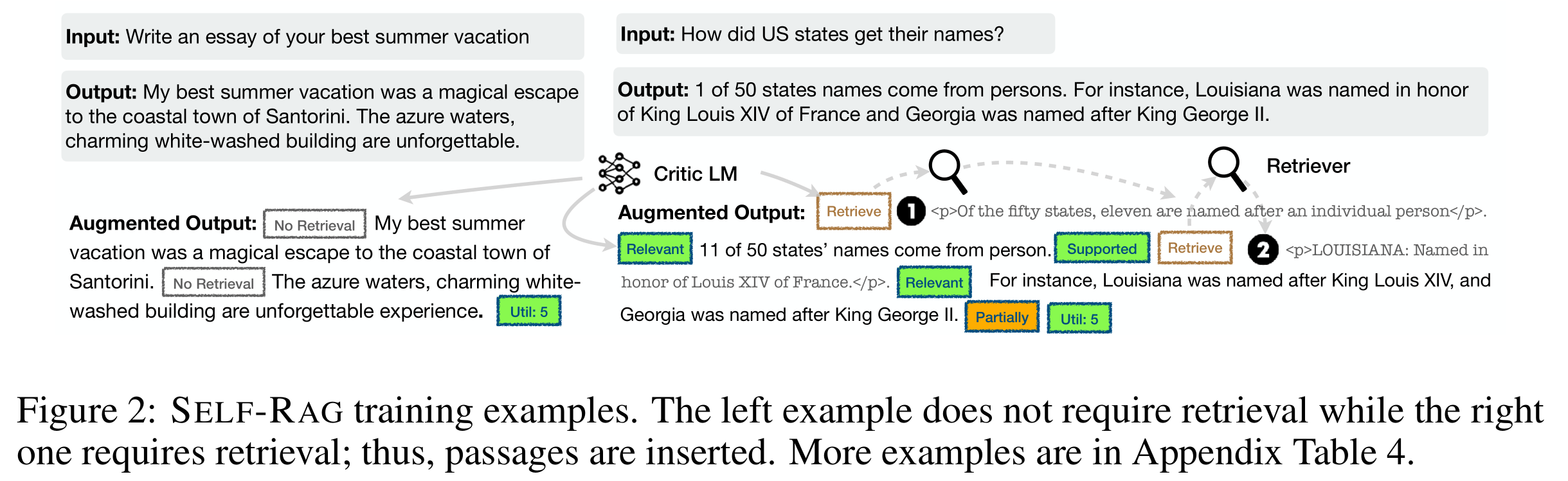
尽管初始模型可以是任何预训练的语言模型,但使用与生成器语言模型相同的模型(即 Llama 2-7B;Touvron 等人,2023 年)来初始化 C
批评者在大多数反思标记类别上与基于 GPT-4 的预测达成高于 90% 的一致性
3.2.2 训练生成器模型
数据收集
给定一个输入-输出对 (x, y) ,使用检索和评估模型增强原始输出 y ,以创建精确模拟 SELF-RAG 推理过程的监督数据
对于每个片段,运行 C 来评估是否有额外的段落可以帮助增强生成
如果需要检索,则添加检索特殊标记 Retrieve = Yes,并且 R 检索前 K个段落 D
对于每个段落,C 进一步评估该段落是否相关,并预测 [isREL]
如果段落相关,C 进一步评估该段落是否支持模型生成,并预测 [isSup]
评估标记 IsREL 和 IsSup 附加在检索的段落或生成内容之后
在输出的最后,y (或 ),C 预测整体效用标记 IsUse,并将带有反思标记的增强输出和原始输入对添加到
生成器学习
通过在增强了反思标记的策划语料库上训练生成器模型M ,使用标准的下一个标记目标进行训练
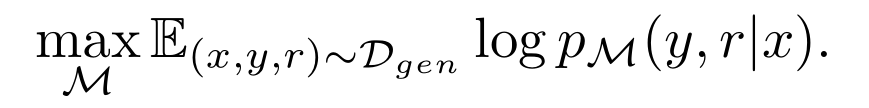
M 学习预测目标输出以及反思标记
在训练过程中,将检索的文本块(在图 2 中由 < p > 和 < /p > 包围)屏蔽以计算损失,并用一组反思标记扩展原始词汇 V ,包括
3.3 SELF-RAG 推理
需要事实准确性的任务(Min et al., 2023),希望模型更频繁地检索段落,以确保输出与现有证据紧密对齐
在更开放的任务中,如撰写个人经历文章,重点转向检索较少,优先考虑整体创意或实用得分
带阈值的自适应检索
SELF-RAG 通过预测 Retrieve 来动态决定何时检索文本段落
框架允许设置一个阈值,如果生成 Retrieve = Yes 令牌的概率超过所有输出令牌中的 Retrieve 标准化阈值,就触发检索
树解码与评价标记
在每一个片段步骤 t 中,当需要检索时,基于硬性或软性条件 R 检索 K 段落,生成器 M 并行处理每个段落并输出 K 不同的延续候选
进行片段级的束搜索(束大小为 = B )以在每个时间戳 B 获取顶部 B 片段延续,并在生成结束时返回最佳序列
每个片段 关于段落 d 的分数会通过一个评价分数 S 进行更新,该评价分数是每种评价标记类型标准化概率的线性加权和
对于每个评价标记组 G (例如,LISREL),将其在时间戳 t 的分数表示为 ,并按以下方式计算片段分数
f(y_t,d,\boxed{\text{Critique}})=p(y_t|x,d,y_{<t}))+\mathcal{S}(\boxed{\text{Critique}}),\text{where}\text{(3)}\\\mathcal{S}(\boxed{\text{Critique}})=\sum_{G\in\mathcal{G}}w^Gs_t^G\text{ for }\mathcal{G}=\{\boxed{\text{IsREL}},\boxed{\text{IsSUP}},\boxed{\text{IsUsE}}\},\text{(4)}
代表生成最期望的反思标记 的概率 G 具有不同标记
方程 4 中的权重 是可以在推理时调整的超参数,以便在测试时实现定制化行为
4 实验部分
4.1 任务与数据集
对 SELF-RAG 模型和多种基线在一系列下游任务上进行了评估
闭集任务包括两个数据集,关于公共健康的事实验证数据集(PubHealth; Zhang et al. 2023)和从科学考试中创建的多项选择题推理数据集
使用准确度作为评估指标,并在测试集上报告结果
短篇生成任务包括两个开放域问答(QA)数据集,PopQA (Mallen et al. 和 TriviaQA-unfiltered (Joshi et al. 2017),系统需要回答关于事实知识的任意问题
对于 PopQA,使用长尾子集,包含 1,399 个每月维基页面浏览量少于 100 的罕见实体查询
由于 TriviaQA-unfiltered(开放)测试集未公开,遵循之前工作的验证和测试分割(Min et al., 2019; Guu et al., 2020),使用 11,313 个测试查询进行评估
根据模型生成中是否包含黄金答案来评估性能,而不是严格地要求精确匹配,遵循 Mallen et al. (2023); Schick et al. (2023) 的方法
长篇生成任务包括传记生成任务(Min 等人,2023 年)和长篇问答任务ALCE-ASQA(Gao 等人,2023 年;Stelmakh 等人,2022 年)
使用 FactScore(Min 等人,2023 年)来评估传记,对于 ASQA,使用官方的正确性指标(str-em)、基于 MAUVE(Pillutla 等人,2021 年)的流畅性,以及引用的精确度和召回率(Gao 等人,2023 年)
4.2 基线模型
不带检索的基线
Llama2 7 B,13B,指令微调模型,Alpaca 7 B,13B,使用私有数据训练和强化的模型,Chat-GPT(Ouyang 等人,2022 年)和 Llama2-chat 13 B
还比较了与并发工作 CoVE65 B (Dhuliawala 等人,2023 年),该工作引入了迭代提示工程来提高 LLM 生成的真实性
基线带检索
评估了在测试时间或训练期间增强检索的模型
第一类包括标准的 RAG 基线,其中 LM(Llama2、Alpaca)在给定查询和 prepend到顶部检索文档(使用与我们的系统相同的检索器)的情况下生成输出
它还包括 Llama2-FT,其中 Llama2 在不包含反射标记或检索段落的情况下对所有的训练数据进行了微调
还报告了使用私有数据训练的检索增强基线的结果:Ret-ChatGPT 和 Ret-Llama2-chat,它们部署了上述相同的增强技术,以及perplexity.ai,一个基于 InstructGPT 的生产搜索系统
第二类包括与检索文本段落一起训练的并发方法,即 SAIL(Luo et al. 2023),它在 Alpaca 指令微调数据之前插入顶部检索文档来对 LM 进行指令微调,以及 Toolformer(Schick et al.,2023),它使用 API 调用(例如,Wikipedia API)来预训练 LM
4.3 实验设置
训练数据与设置
训练数据由多样的指令遵循的输入-输出对组成
从 Open-Instruct 处理过的数据(Wang et al. 2023)和知识密集型数据集(Petroni et al., 2021; Stelmakh et al., 2022; Mihaylov et al., 2018)中抽样实例
使用了 150k 个指令-输出对
使用 Llama2 7B和 13B(Touvron et al., 2023)作为生成基础语言模型,并使用 Llama27B 作为基础评判语言模型
检索器模型 R 使用现成的 Contriever-MS MARCO(Izacard et al. 2022a)并针对每个输入检索最多十个文档
推理设置
为权重项 [IsREL]、[IsSup]、[IsUse] 分别分配值 1.0、1.0 和 0.5
为了鼓励频繁检索,将大多数任务的检索阈值设置为 0.2,并将 ALCE(Gao et al. 2023)的阈值设置为 0,因为引用需求
使用 vllm(Kwon et al. 2023)加速推理
在每一片段级别,采用宽度为 2的束搜索
对于标记级别的生成,使用贪婪解码
默认情况下,使用Contriever-MS MARCO(Izacard et al.,2022a)的前五个文档;对于传记和开放域问答,按照 Luo et al.(2023)的方法,使用网络搜索引擎检索的额外五个顶级文档;对于 ASQA,使用 GTR-XXL(Ni et al.,2022)提供的所有基线中的前 5 个文档,以进行公平比较
5 结果与分析
5.1 主要结果
与无检索的基线对比
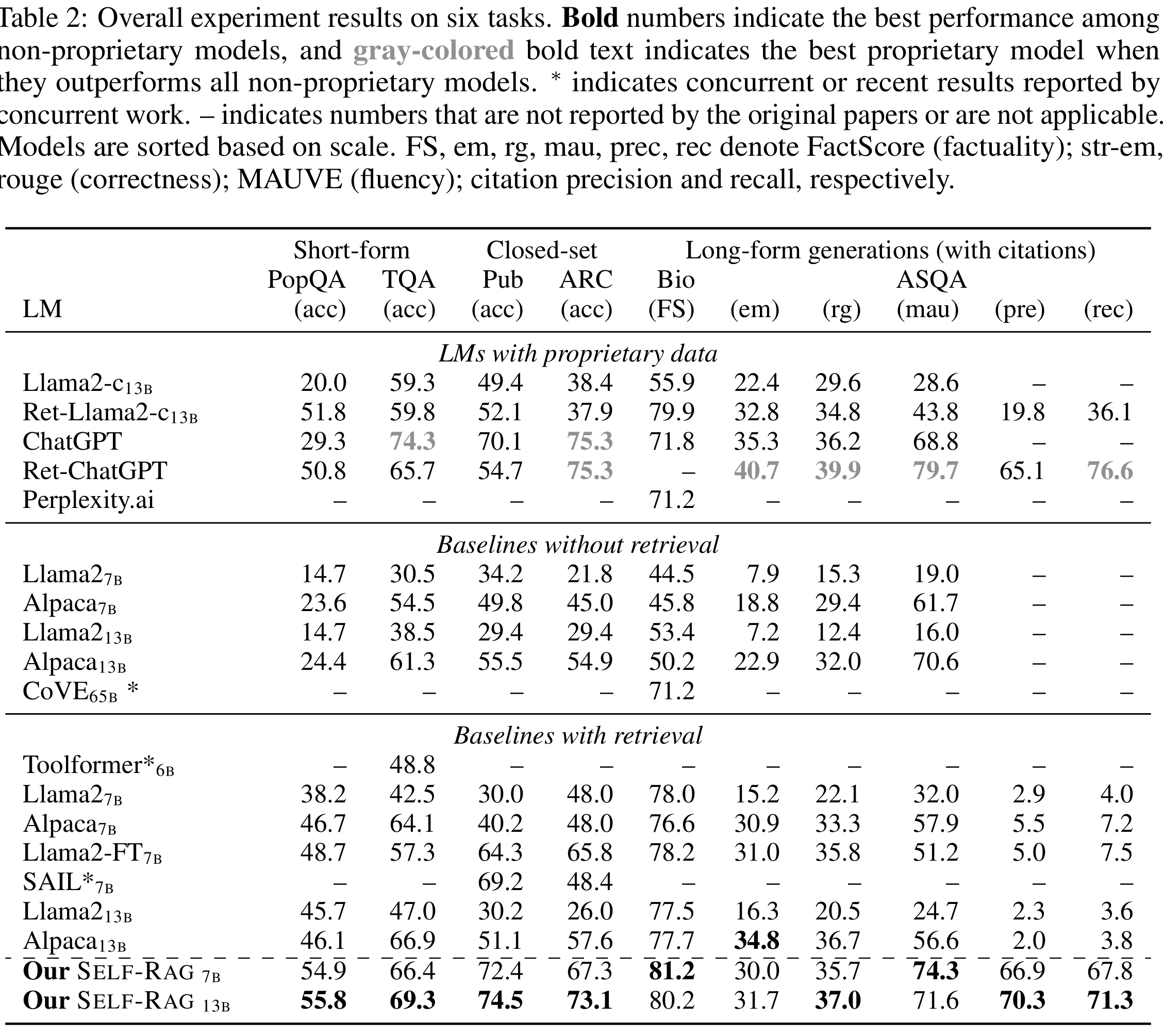
SELF-RAG(底部两行)在所有任务中均显示出比监督微调的大语言模型有显著性能优势
与使用检索的基线比较
SELF-RAG 在许多任务上也超过了现有的 RAG,在所有任务中获得了非专有 LM-based 模型中的最佳性能
具有检索功能的强大指令微调 LM(例如 LLama2-chat、Alpaca)相对于非检索基线显示出较大的提升
FS、em、rg、mau、prec、rec 分别表示
FactScore(事实性);str-em、rouge(正确性);MAUVE(流畅性);引用精确度和召回率
与所有其他模型相比,ChatGPT 在这一特定任务中始终表现出卓越的效果,超过了较小的语言模型
SELF-RAG 缩小了这种性能差距,甚至在引用精确度上超过了 ChatGPT
5.2 分析
剔除研究
对框架进行了一系列剔除实验,以确定哪些因素扮演关键角色
评估了两种模型变体,它们的训练方式不同:
无检索器(No Retriever)使用标准的指令遵循方法训练语言模型,给定指令-输出对,而不使用检索到的段落
无评价器(No Critic)训练一个语言模型,该模型使用总是增加顶部检索文档的输入-输出对进行训练,而不使用反思标记
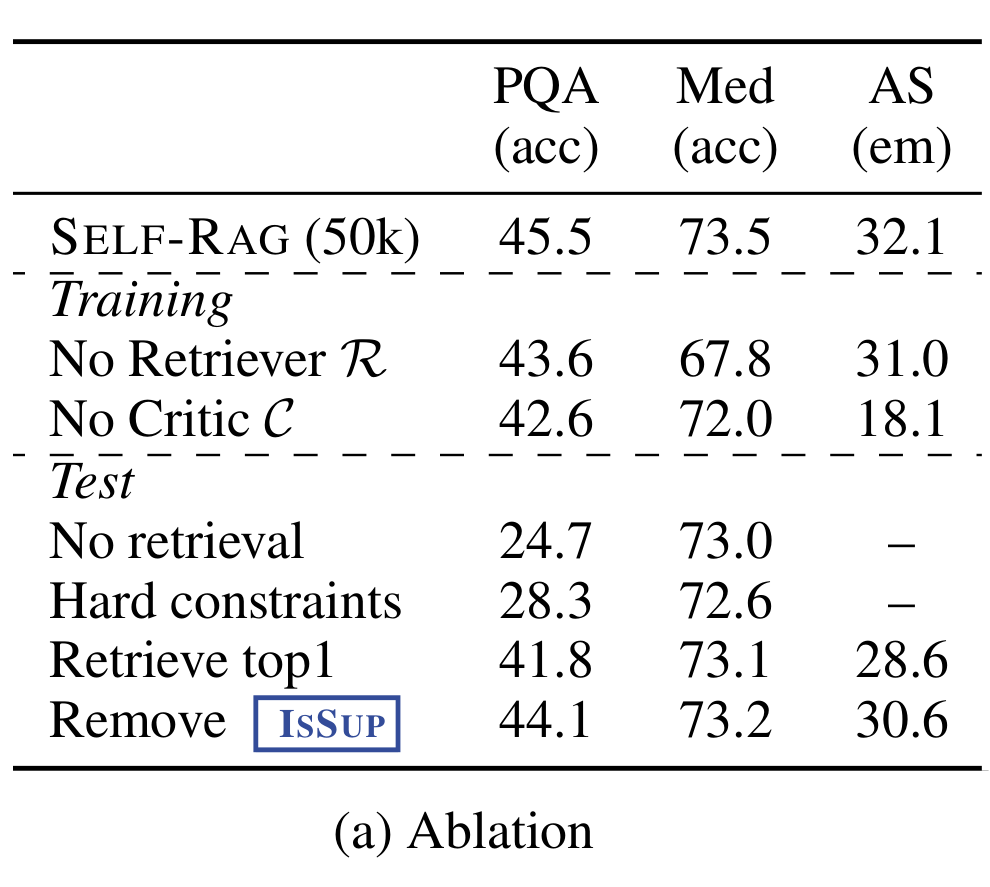
发现所有组件都发挥着重要作用
Prompt-RAG: Pioneering Vector Embedding-Free Retrieval-Augmented Generation in Niche Domains, Exemplified by Korean Medicine(Prompt-RAG:在小众领域开创无向量嵌入检索增强生成,以韩国医学为例)
韩国 Gachon 大学韩医学学院生理学系
斯坦福大学医学院神经生物学系
🙅♀️Similarity is Not All You Need- Endowing Retrieval Augmented Generation with Multi Layered Thoughts(相似性并非全部:赋予检索增强生成多层思想)
蚂蚁集团
arXiv:2405.19893v1
2024 年 5 月 30 日
摘要
现有的检索增强模型通常使用相似性作为查询与文档之间的桥梁
相似性并不总是“灵丹妙药”,完全依赖相似性有时会降低检索增强生成的性能
提出了METRAG, a Multi–layEred Thoughts enhanced Retrieval-Augmented Generation framework,一个多层次思维增强的检索增强生成框架
通过全面结合相似性和效用导向思维,提出一个“更智能”的模型
在知识密集型任务上的广泛实验证明了 MR 的优越性
引言
认为相似性并不是检索增强生成的“灵丹妙药”,完全依赖相似性有时会降低性能
如图 1 的上半部分所示,当用户输入查询“告诉我关于作者乔治·R·R·马丁的事情”时,基于相似性的检索系统会根据相似性度量(即语义相关性或基于 TFIDF 的度量)对给定语料库中的文档进行排序
即使检索到的文档几乎没有提供有用的信息,“乔治·R·R·马丁是一位作者”,它仍会因高相似性得分而排名较高
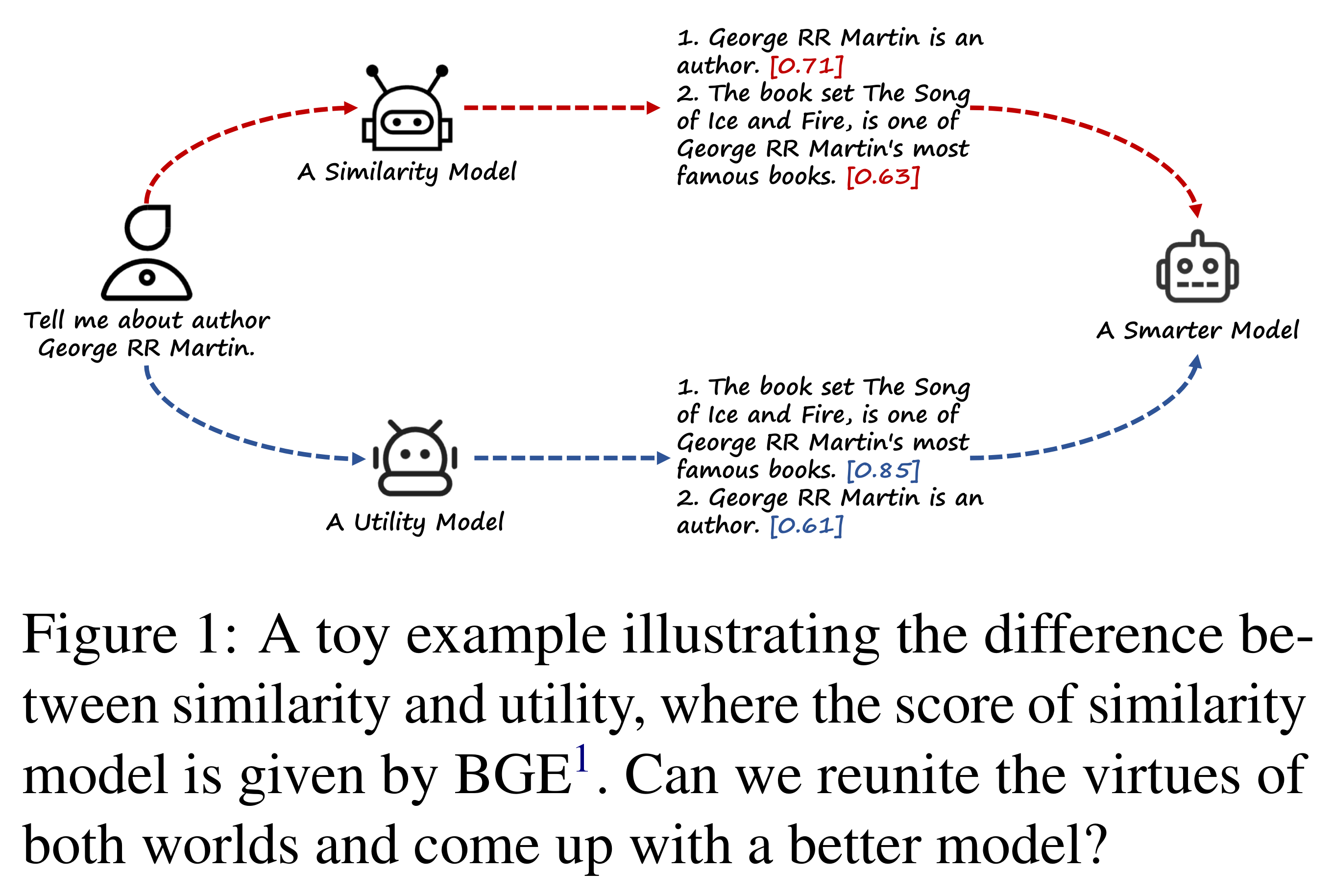
旨在赋予检索增强生成多层次的思维(即以实用性和简洁性为导向的思维)以提升性能
然而,这一解决方案相当复杂,需要解决以下几个关键挑战:
- 训练一个能够感知以实用性为导向的思维而不仅仅是相似性的模型,需要外部标注数据。然而,获取用于明确监督学习过程的外部标注数据是困难的。尽管LLMs可以作为数据标注者,提供高质量的语料库用于模型训练,并在许多情况下展示了其巨大能力,但其固有的不受控制和不稳定特性有时会降低性能
- 针对高质量的检索文档,为减少数十个文档对LLMs所造成的负担,并更好地捕捉检索文档之间的共同点和特征,文档摘要生成是可行的。然而,简单的摘要生成无法保证最重要的信息。 输入查询可以被保留,因此需要训练一个与任务本身对齐的摘要模型,从而具备以紧凑性为导向的思维
提出了 METRAG。特别是,利用一个LLM作为针对输入查询的文档效用的监督,提出了一种与LLM的反馈对齐的效用模型,这种方法不仅具备相似性,还具备以实用为导向的思想
结合了基于相似性和实用性的思想,同时考虑了相似性模型与实用模型的输出
从强大的教师模型(例如,GPT4)中提取摘要能力。之后,通过多个生成的摘要,进一步利用后续的奖励模型来约束摘要模型与最终任务的一致性
在多个知识广泛的任务上评估所提出的 METRAG,广泛的实验和分析证明了该方法的优越性
相关工作
RAG 的本质在于检索段落的质量,然而许多现有方法依赖于基于相似度的检索,这往往忽视了相关段落的潜在效用
所提出的方法
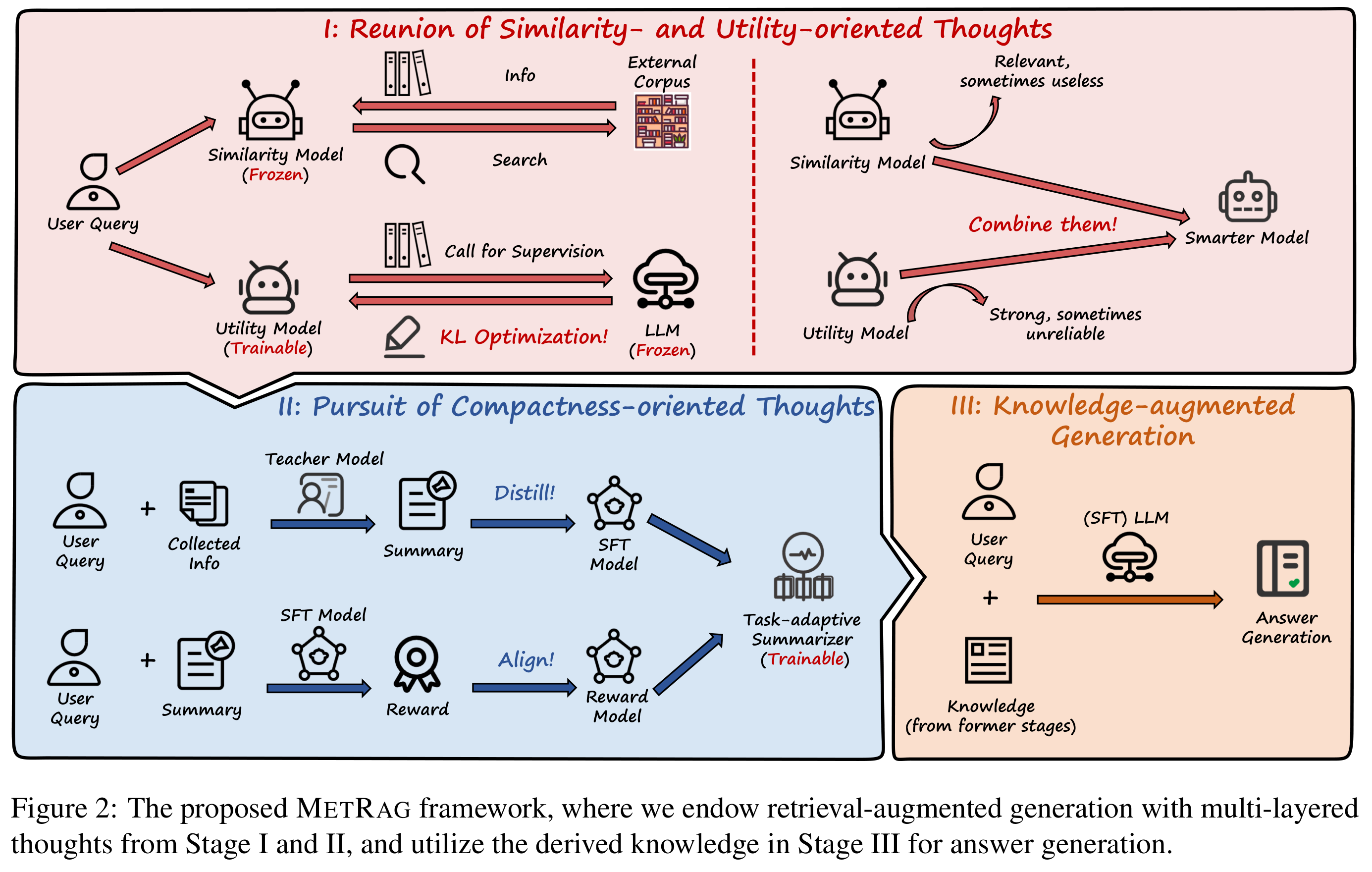
相似性模型作为现成的检索器
s(q, d) = M(E(q), E(d)) 根据推导出的相似度得分,检索与输入查询 q 的相似度得分最高的前 k 个文档 D,以增强后续任务
LLM的监督赋能实用模型
受到LLMs在多种任务中取得的巨大成功的启发,旨在结合一个LLM来对文档的效用进行监督(在本文中,通过一个文档在帮助LLM回答该问题时的有用性来定义其相对于问题的效用,这一效用通过生成正确答案的概率与特定LLM的归一化来建模。)相对于输入查询,从而赋予检索器 R 效用导向的思维
首先,考虑检索器 R 认为与输入查询 q 最相似的前 n 个文档集合 D (D⊆ D),每个文档 d 的近似相似性可能性可以形式化如下:
是控制概率分布平滑度的温度超参数,较高的产生较软的概率分布,而较低的则导致“更硬”的最大操作, 表示模型训练的文档池
为了赋予检索器 对检索效用的LLM洞察,进一步将作为关于文档效用的监督信号引入相对于输入查询
使得训练的效用模型除了相似性之外,还能够考虑文档所提供的效用,将其公式化如下:
最后,通过最小化这两个分布的 KL 散度,将相似性分布推向由 LLM 监督增强的效用分布
其中 Q 是查询集,由于 LLM 作为外部监督,在训练过程中 LLM 的参数被冻结,只更新检索器R 的参数,最终得到效用模型 U,因此整个优化过程保持轻量级
此外在训练过程中将空字符串 es 添加到 D 中,使效用模型能够判断为查询引入文档是否能提升效用,从而实现选择性检索
相似性与实用性思维的重聚
结合相似性和实用性的思路,并通过整合策略 I(·) 考虑相似性模型的输出,文档 d 和输入查询 q 之间的最终得分可以定义如下:
追求紧凑型思想
由于LLMs的上下文限制而孤立地使用它们,或者仅仅聚合 Top-k 文档而不考虑它们之间的关系,这难以捕捉它们之间的共性和特征,甚至混淆LLMs,导致信息丢失
文本摘要可以提供帮助,然而,简单的摘要并不能保证保留与输入查询相关的最重要的信息,因此有必要训练一个与任务本身相一致的摘要模型
提出了任务自适应摘要器,它不仅降低了最终任务的计算成本,而且还减轻了LLMs从大量检索到的文档中识别相关信息以获得以紧凑性为导向的思想的负担
看不懂了。。。。。
实验
一般开放域问答:NQ、TriviaQA 未过滤、HotpotQA 和实体中心问答数据集:PopQA
通过指标 EM(遵循Mallen 等人(2023)的做法,评估模型生成中是否包含金标准答案,而不是严格的精确匹配
基线与检索
第一类包括标准的 RAG 基线,其中语言模型(例如 Llama2)在给定带有检索到的顶部文档的查询时生成输出
后者类别包括使用检索到的段落进行训练的方法,如 Self-RAG(Asai 等,2023b)、RECOMP(Xu 等,2023)
🙅♀️Lift Yourself Up: Retrieval-augmented Text Generation with Self-Memory(提升自我:带自记忆的检索增强文本生成)
北京大学 复旦大学 腾讯人工智能实验室
第 37 届神经信息处理系统大会 (NeurIPS 2023)
https://github.com/Hannibal046/SelfMemory
摘要
通过直接访问人为编写的参考内容作为记忆,增强检索生成在众多文本生成任务中取得了显著进展
传统的记忆检索方法涉及选择与输入具有最高相似性的记忆 但 这种方法受限于提取记忆的固定语料库的质量
通过探索原始问题的二重性:更好的生成也促使更好的记忆,提出了一个新颖的框架 Selfmem,利用迭代使用增强检索生成器创建无限记忆池,并使用记忆选择器选择一个输出作为后续生成轮次的记忆,从而解决这一局限。这样,模型能够利用自身的输出,称为自我记忆,以实现更好的生成
在三种不同的文本生成任务上评估 Selfmem 的有效性 神经机器翻译、抽象文本摘要和对话生成 采用两种生成范式:微调小模型和少量示例
在 JRC-Acquis 翻译数据集的四个方向上达到了最先进的成果,在 XSum 中实现了 50.3 的 ROUGE-1,在 BigPatent 中实现了 62.9 的 ROUGE-1
引言
更好的记忆提示更好的生成
许多研究都集中在如何检索更好的记忆,从稀疏检索到密集检索[10, 63],从固定检索器到可学习检索器[41, 8],以及从句子级记忆到更细粒度的词元级记忆[36, 35]
所有先前的工作存在一个基本限制:记忆是从固定语料库中提取的,并受到语料库质量的限制。由于检索空间有限,有界记忆显著限制了记忆增强生成模型的潜力
探讨原始问题的双重性,该问题假定更好的生成
该框架迭代地使用检索增强生成器来创建无界记忆池,并使用记忆选择器来选择一个输出作为后续生成回合的记忆。通过结合原始问题和对偶问题,检索增强生成模型可以使用自己的输出来提升自己,称为自记忆
Selfmem 由两个互补组件组成:增强检索的生成器和记忆选择器
生成器在两种不同的范式下运行:微调小模型或少量样本提示LLM
对于前者,使用标记数据和检索到的记忆来训练生成器
对于后者,只在推理时使用一个固定的黑箱LLM,并搭配检索到的上下文学习样本
然后,使用生成器的输出根据特定性能指标训练记忆选择器
通过简单地将检索到的记忆替换为无限生成的记忆,实现了更高质量的生成输出(原始问题),经过记忆选择器的精炼后,这些输出随后作为下一轮的记忆(对偶问题)
相关工作
- 检索增强文本生成:
- 检索增强文本生成利用外部数据库(通常是训练语料库)来提升文本生成任务的性能,如机器翻译、对话生成和语言建模
- 传统的检索增强方法通过信息检索技术来获取与输入文本最相似的记忆(文本片段),然后基于这些记忆进行文本生成
- 研究者们探索了从稀疏检索到密集检索、从固定检索器到可学习检索器、以及从句子级记忆到词元级记忆的不同方法
- 检索增强的神经机器翻译(NMT)系统使用搜索引擎从训练集中检索记忆,并将其与外部记忆网络结合
- 对于大型语言模型(LLM),研究者提出了上下文示例选择策略来改善翻译质量
- 神经文本重排序:
- 神经文本重排序方法通过减少训练与推理之间的差异(曝光偏差)并直接优化所需指标,已经在多个文本生成任务中取得了显著进展
- 在机器翻译中,判别式重排序方法被用来优化统计机器翻译(SMT)系统
- 在NMT中,研究者关注生成性重排序和判别性重排序两种主要方法
- 在文本摘要中,重排序框架被提出来解决训练-测试分布不匹配的问题
- 这些重排序方法通常是一个单向过程,选定的候选者成为系统的最终输出
- Selfmem框架的创新点:
- Selfmem框架提出了一种新颖的方法,通过迭代使用检索增强生成器创建无限的记忆池,并使用记忆选择器来选择一个输出作为后续生成回合的记忆
- 这种方法允许模型利用自身的输出(自我记忆)来提升生成质量,从而解决了传统方法中固定语料库质量限制的问题
方法
- 生成作为记忆(Generation as Memory):
- 作者观察到,在推理过程中,与数据分布更相似的记忆不是训练数据,而是模型自身的输出
- 通过实验,作者发现直接使用生成的输出作为记忆,可以在一定程度上提升生成质量,这支持了“更好的记忆促进更好的生成”的观点
- 检索增强生成器(Retrieval-augmented Generator):
- 该组件负责根据输入文本和检索到的记忆生成目标文本。作者提出了两种架构:联合编码器和双编码器
- 联合编码器将输入文本和记忆串联后输入到编码器,而双编码器则分别对输入文本和记忆进行编码,然后由解码器生成文本
- 记忆选择器(Memory Selector):
- 记忆选择器的任务是从生成器产生的候选池中选择一个最佳候选项作为下一轮生成的记忆
- 作者提出了一种基于特定性能指标(如BLEU分数)来训练记忆选择器的方法,以优化记忆选择过程
- 结合生成器和选择器:
- 作者定义了两种生成模式:假设模式和候选模式。假设模式为每个输入生成单个输出,用于系统评估;候选模式为给定输入生成多个输出,用于训练记忆选择器和进行记忆选择
- Selfmem框架通过迭代过程,交替使用生成器和选择器,以提升生成质量和记忆的有效性
- 算法流程:
- 算法开始时,使用检索器从数据集中检索记忆
- 训练检索增强生成器,然后使用生成器在候选模式下产生候选池
- 训练记忆选择器,然后在迭代过程中使用选择器从候选池中选择记忆
- 重复迭代过程,直到在验证集上收敛
- 最终,生成器在假设模式下生成最终的输出
- 实验设置:
- 作者在多种文本生成任务上评估了Selfmem框架,包括神经机器翻译、摘要生成和对话生成,并使用了不同的数据集和评估指标
- 进一步分析:
- 作者对Selfmem框架的关键组件进行了深入分析,包括对生成器和记忆选择器的调优,以及对生成输出的标记级分析
实验
- 数据集:
- 翻译:使用了JRC-Acquis数据集,包括英语与西班牙语、德语之间的翻译
- 摘要:使用了BigPatent和XSum数据集,前者包含美国专利文档,后者包含BBC新闻文章
- 对话:使用了DailyDialog数据集,包含日常对话场景
- 实现细节:
- 检索算法:使用BM25算法进行记忆检索
- 生成方法:采用束搜索(beam search)生成候选,束宽为50
- 迭代次数:根据验证集上的性能确定迭代次数
- 模型架构:对于翻译任务,使用了基于Transformer的架构;对于摘要和对话生成任务,使用了BART模型
- 评估指标:
- 翻译:使用BLEU、TER和chrF++作为评估指标
- 摘要:使用ROUGE指标(R-1/2/L)
- 对话:使用BLEU(B-1/2)和Distinct(D-1/2)分数
- 延迟分析:
- 对Selfmem框架的生成延迟进行了实证分析,包括在CPU和CUDA平台上的性能
- 比较了Selfmem与检索增强基线模型的延迟,包括候选生成、记忆选择和假设生成的时间
- 人类与GPT-4评价:
- 使用人类注释者和GPT-4模型对Selfmem和基线系统生成的输出进行成对排名
- 随机选择了一定数量的样本进行评价,并统计了Selfmem相对于基线的胜率
结果
- 机器翻译:
- Selfmem在JRC-Acquis翻译数据集上取得了显著的性能提升,超越了传统的检索增强模型和其他基线系统
- 在四个翻译方向上,Selfmem都达到了最先进的结果,例如在英德(En→De)翻译任务上,Selfmem的BLEU分数比基线系统提高了1.5%以上
- 摘要生成:
- 在XSum和BigPatent数据集上,Selfmem同样展现出了优越的性能,特别是在BigPatent数据集上,Selfmem的ROUGE-1分数达到了62.9,比基线系统有显著提升
- Selfmem在处理官方专利文档这类具有较大相似性的文本时,表现出了更好的摘要生成能力
- 对话生成:
- 在DailyDialog数据集上,Selfmem在BLEU分数上超越了基线系统,显示出在对话生成任务中的有效性
- 尽管在Distinct分数上Selfmem稍逊于基线,但总体上,Selfmem在生成多样化和信息丰富的对话方面表现出了灵活性
- 延迟分析:
- Selfmem的延迟分析显示,在CPU和CUDA平台上,Selfmem的生成延迟与检索增强基线模型相当,这表明Selfmem在保持高性能的同时,也具有良好的实时性
- 人类与GPT-4评价:
- 通过人类注释者和GPT-4模型的评价,Selfmem在翻译、摘要和对话任务中的输出质量均优于检索增强基线模型
- Selfmem在各项任务中的胜率均超过了75%,这进一步证实了其生成质量的优势
Improving Retrieval Performance in RAG Pipelines with Hybrid Search(混合检索)
2023年11月28日
Improving Retrieval Performance in RAG Pipelines with Hybrid Search | Towards Data Science
混合搜索是什么
将两种或多种搜索算法结合起来,以提高搜索结果的相关性
虽然未明确指出哪些算法被结合,混合搜索通常指传统的基于关键字的搜索与现代的向量搜索相结合
基于关键词的搜索
虽然其确切的关键词匹配能力对特定术语(如产品名称或行业术语)是有益的,但它对拼写错误和同义词很敏感,这导致它忽略了重要的上下文
向量或语义搜索
虽然其语义搜索能力允许基于数据的语义意义进行多语言和多模态搜索,并使其对拼写错误具有鲁棒性,但它可能会遗漏重要的关键词
此外,它依赖于生成的向量嵌入的质量,并且对域外术语非常敏感
将基于关键词的搜索和向量搜索结合成混合搜索,可以利用两种搜索技术的优势来提高搜索结果的相关性,尤其是在文本搜索用例中
eg:
例如,考虑搜索查询“如何使用 .concat() 合并两个 Pandas 数据框?”
关键字搜索将有助于找到关于 .concat() 方法的相关结果
由于“合并”这个词有“组合”、“连接”和“串联”等同义词,如果我们可以利用语义搜索的上下文感知能力,将会很有帮助
混合搜索如何工作
混合搜索结合了基于关键词和向量搜索技术,通过融合它们的搜索结果并重新排序
基于关键词的搜索
在混合搜索的上下文中,基于关键词的搜索通常使用一种称为稀疏嵌入的表示
稀疏嵌入是大多数值为零,只有少数非零值的向量
[0, 0, 0, 0, 0, 1, 0, 0, 0, 24, 3, 0, 0, 0, 0, ...]稀疏嵌入可以通过不同的算法生成:BM25、TF-IDF
BM25 根据术语在特定文档中的频率相对于所有文档中的频率,强调术语的重要性
向量搜索
向量嵌入通常包含密集的信息,并且主要由非零值组成(密集向量),这就是向量搜索也被称为密集向量搜索的原因
[0.634, 0.234, 0.867, 0.042, 0.249, 0.093, 0.029, 0.123, 0.234, ...]搜索查询嵌入到与数据对象相同的向量空间中。然后,使用其向量嵌入根据指定的相似性度量(例如余弦距离)计算最接近的数据对象。返回的搜索结果按与搜索查询的相似性对最接近的数据对象进行排名
关键词基础与向量搜索结果的融合
关键词搜索和向量搜索都会返回一组独立的结果,通常是按其计算相关性排序的搜索结果列表。这些独立的搜索结果集合必须被合并
有许多不同的策略可以将两个列表的排名结果合并为一个单一的排名 [^https://rodgerbenham.github.io/bc17-adcs.pdf]
一般来说,
- 搜索结果通常会首先进行评分。这些分数可以基于指定的指标进行计算,例如余弦距离,或者仅仅是搜索结果列表中的排名
- 计算出的分数将使用参数
alpha加权,该参数决定了每个算法的权重,并影响结果的重新排序
hybrid_score = (1 - alpha) * sparse_score + alpha * dense_score
alpha的值介于 0 和 1 之间alpha = 1: 纯向量搜索alpha = 0: 纯关键字搜索
eg:α = 0.5
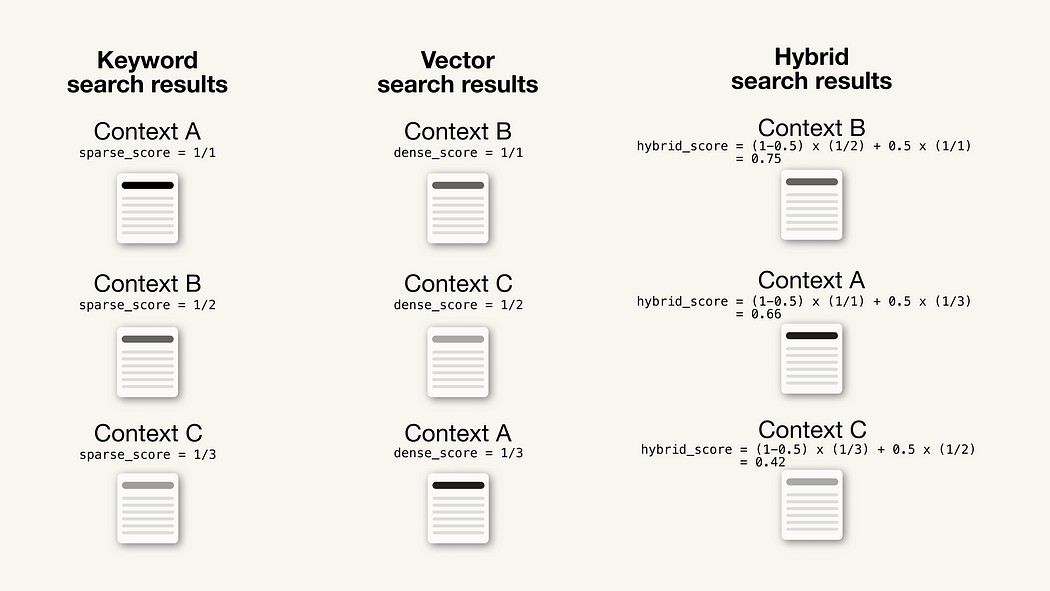
混合搜索如何提升 RAG 管道性能
RAG 流水线有许多参数可以调整以提高其性能,其中一个参数是提高检索到的上下文的相关性
根据上下文类型和查询,必须确定哪种搜索技术对 RAG 应用程序最有利。因此,参数 alpha ,即控制基于关键字和语义搜索之间权重的参数,可以视为需要调整的超参数
在使用 LangChain 的常见 RAG 管道中,可以通过将使用 vectorstore 组件设置为检索器,并使用 .as_retriever() 方法来定义检索器组件
这种方法只能实现语义搜索
# Define and populate vector store
# See details here https://towardsdatascience.com/retrieval-augmented-generation-rag-from-theory-to-langchain-implementation-4e9bd5f6a4f2
vectorstore = ...
# Set vectorstore as retriever
retriever = vectorstore.as_retriever()想在 LangChain 中启用混合搜索,需要定义一个具有混合搜索功能的特定 retriever 组件,例如 WeaviateHybridSearchRetriever
from langchain.retrievers.weaviate_hybrid_search import WeaviateHybridSearchRetriever
retriever = WeaviateHybridSearchRetriever(
alpha = 0.5, # defaults to 0.5, which is equal weighting between keyword and semantic search
client = client, # keyword arguments to pass to the Weaviate client
index_name = "LangChain", # The name of the index to use
text_key = "text", # The name of the text key to use
attributes = [], # The attributes to return in the results
)设置 alpha = 1 等于完全语义搜索
何时使用混合搜索(混合搜索用例)
一个优秀的例子是平台 Stack Overflow,它最近通过使用混合搜索扩展了其语义搜索功能
Ask like a human: Implementing semantic search on Stack Overflow - Stack Overflow
互易排名融合(Reciprocal Rank Fusion,RRF)
如何使用混合搜索更好地检索 LLM RAG (readmedium.com)
RRF 是一种结合不同评分函数排名的简单算法 [G. V. Cormack, C. L. A. Clarke, and S. Büttcher, Reciprocal Rank Fusion outperforms Condorcet and individual Rank Learning Methods (2009), Proceedings of the 32nd international ACM SIGIR conference on Research and development in information retrieval]
首先,获得每种评分算法的文档排名(BM25、向量)
corpus = [
"The cat, commonly referred to as the domestic cat or house cat, is a small domesticated carnivorous mammal.",
"The dog is a domesticated descendant of the wolf.",
"Humans are the most common and widespread species of primate, and the last surviving species of the genus Homo.",
"The scientific name Felis catus was proposed by Carl Linnaeus in 1758",
]
query = "The cat"
bm25_ranking = [1, 2, 4, 3] # scores = [0.92932018 0.21121974 0. 0.1901173]
cosine_ranking = [1, 3, 4, 2] # scores = [0.5716, 0.2904, 0.0942, 0.3157]每个文档 d 的 RRF 综合得分公式如下:
其中 k 是一个参数(原论文使用 k=60),r(d) 是 BM25 和余弦相似度的排名
定义 RRF 的函数和一个将浮点分数转换为 int 排名的辅助函数
import numpy as np
def scores_to_ranking(scores: list[float]) -> list[int]:
"""Convert float scores into int rankings (rank 1 is the best)"""
return np.argsort(scores)[::-1] + 1
def rrf(keyword_rank: int, semantic_rank: int) -> float:
"""Combine keyword rank and semantic rank into a hybrid score."""
k = 60
rrf_score = 1 / (k + keyword_rank) + 1 / (k + semantic_rank)
return rrf_score实现的简单混合搜索:
from rank_bm25 import BM25Okapi
from sentence_transformers import SentenceTransformer
from sentence_transformers.util import cos_sim
model = SentenceTransformer("sentence-transformers/all-MiniLM-L6-v2")
def hybrid_search(
query: str, corpus: list[str], encoder_model: SentenceTransformer
) -> list[int]:
# bm25
tokenized_corpus = [doc.split(" ") for doc in corpus]
tokenized_query = query.split(" ")
bm25 = BM25Okapi(tokenized_corpus)
bm25_scores = bm25.get_scores(tokenized_query)
bm25_ranking = scores_to_ranking(bm25_scores)
# embeddings
document_embeddings = model.encode(corpus)
query_embedding = model.encode(query)
cos_sim_scores = cos_sim(document_embeddings, query_embedding).flatten().tolist()
cos_sim_ranking = scores_to_ranking(cos_sim_scores)
# combine rankings into RRF scores
hybrid_scores = []
for i, doc in enumerate(corpus):
document_ranking = rrf(bm25_ranking[i], cos_sim_ranking[i])
print(f"Document {i} has the rrf score {document_ranking}")
hybrid_scores.append(document_ranking)
# convert RRF scores into final rankings
hybrid_ranking = scores_to_ranking(hybrid_scores)
return hybrid_ranking
hybrid_ranking = hybrid_search(
query="What is the scientifc name for cats?", corpus=corpus, encoder_model=model
)
print(hybrid_ranking)
>> Document 0 has the rrf score 0.03125
>> Document 1 has the rrf score 0.032266458495966696
>> Document 2 has the rrf score 0.03225806451612903
>> Document 3 has the rrf score 0.032266458495966696
>> [4 2 3 1]