
混合 RAG(Blended RAG)
检索增强生成(RAG)是一种结合私人文档知识库与生成问答(Q&A)系统的方法。随着文档语料库规模的扩大,RAG 的准确性面临挑战,其中检索器的作用至关重要,它通过提取最相关文档为大型语言模型(LLM)提供上下文。本研究提出了“混合 RAG”方法,结合语义搜索技术和混合查询策略,包括稠密向量索引和稀疏编码器索引,以改善检索结果。该方法在信息检索(IR)数据集如NQ和TREC-COVID上设定了新基准,并在生成问答数据集如SQUAD上展示了超越微调性能的卓越结果。关键词:RAG,检索器,语义搜索,稠密索引,向量搜索。
ℹ️
2024 年 8 月 4 日
IBM
Blended RAG: Improving RAG (Retriever-Augmented Generation) Accuracy with Semantic Search and Hybrid Query-Based Retrievers
混合 RAG:利用语义搜索和混合查询检索器提高RAG(检索增强生成)准确性
相关工作
当前 RAG 系统的局限性
目前大多数用于检索增强生成 (RAG) 管道的检索方法依赖于关键词和基于相似度的搜索,这可能会限制 RAG 系统的整体准确性
虽然大多数提高 RAG 准确性的先前工作都集中在 G 部分,通过调整 LLM 提示,微调等,[9] 它们对 RAG 系统的整体准确性影响有限,因为如果 R 部分提供不相关的上下文,则答案将不 准确
在提高检索增强生成(RAG)准确性的研究中,以往的工作主要集中于调整大型语言模型(LLM)的提示和微调,但这些方法对整体准确性的提升有限。原因在于,如果检索(R)部分提供的上下文不相关,那么生成的答案也将不准确。此外,RAG系统中使用的检索方法大多依赖于关键字和基于相似度的搜索,这限制了系统的整体准确性
本研究旨在探索最适合RAG的搜索方法,这是一个新兴的研究领域。研究目标是通过结合基于语义搜索的检索器和混合搜索查询,以提高检索器和RAG的准确性
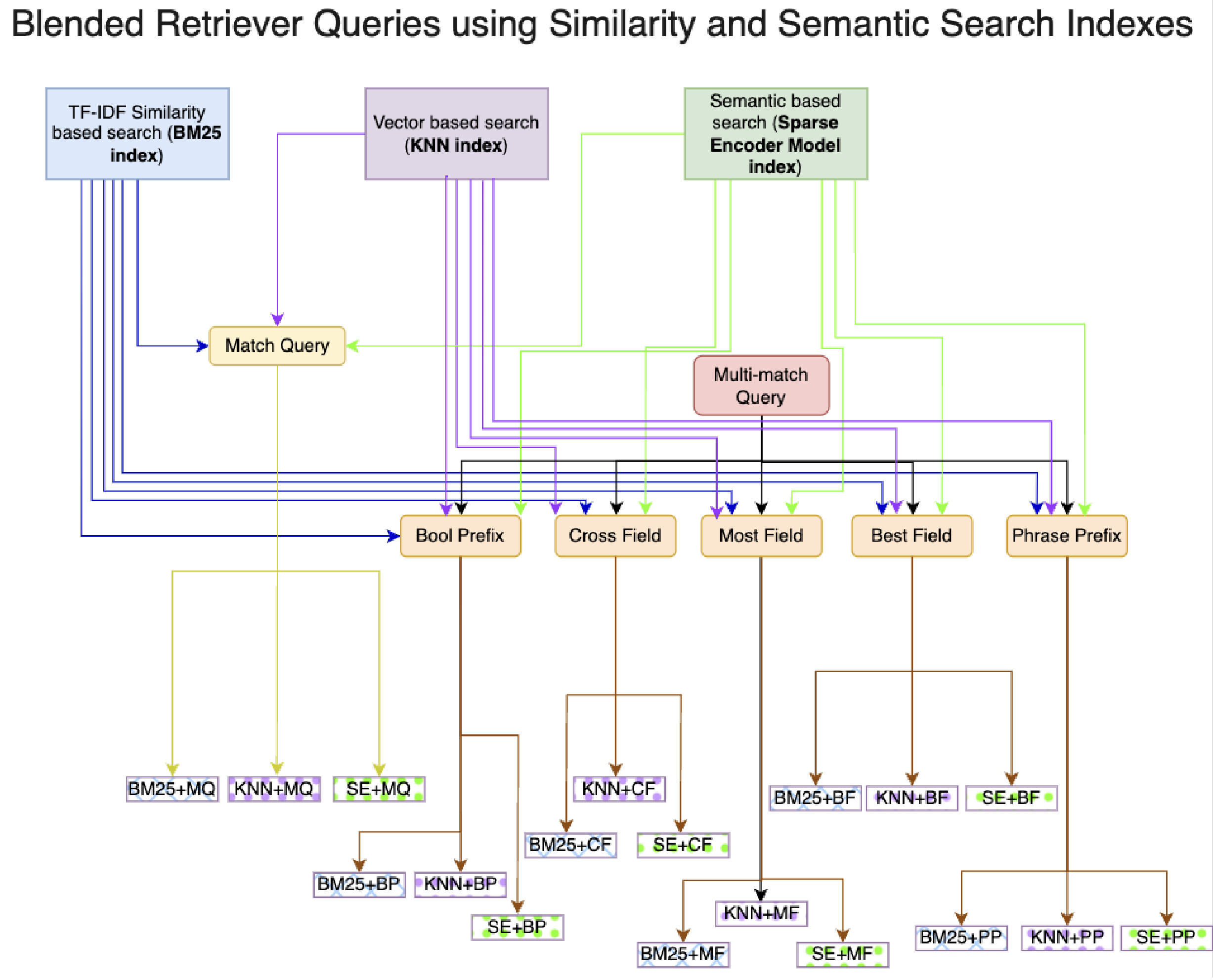
BLENDED RETRIEVERS
探索了三种不同的搜索策略 并将这些策略整合起来形成混合查询:
基于关键词的相似性搜索
BM25
擅长利用模糊匹配技术增强的全文搜索功能,为更复杂的查询操作奠定了基础
基于密集向量的搜索
KNN
构建了一个由句子转换器驱动的稠密向量索引。它识别从文档和查询内容中提取的向量表示的接近程度
基于语义的稀疏编码器
Elastic Learned Sparse Encoder (ELSER)
稀疏编码器检索模型索引融合了语义理解和基于相似度的检索,以封装术语之间细微的关系,从而捕捉到更真实的用户意图和文档相关性表示
与传统的关键词匹配不同,语义搜索深入挖掘用户查询的细微差别,解读上下文和意图
实验
数据集
NQ
Natural Questions (NQ) 数据集
谷歌研究团队发布
包含了来自真实用户的超过30万个问题,这些问题是从谷歌搜索中收集的,并且答案是由注释者从维基百科页面中找到的
NQ 数据集的设计是为了训练和评估自动问答系统,它要求问答系统不仅要理解问题,还要能够阅读并理解整个维基百科文章来找到问题的答案,这使得NQ比以往的问答数据集更具挑战性
精确匹配(EM)、F1 分数和检索准确率(Top-5 和 Top-20)
TREC-Covid
美国国家标准与技术研究院(NIST)组织的社区评估项目
TREC-COVID 利用 COVID-19 开放研究数据集(CORD-19),这是一个定期更新的生物医学文献文章集合
HotPotQA
由卡内基梅隆大学、斯坦福大学和蒙特利尔大学的 NLP 研究人员团队创建的问题回答数据集
- 多跳问题:问题需要从多个支持文档中找到并推理答案
- 多样性:问题多样,不受限于任何现有的知识库或知识架构
- 支持事实:提供了推理所需的句子级支持事实,允许问答系统在强监督下进行推理并解释预测
- 事实比较问题:提供了一种新型的事实比较问题,测试问答系统提取相关事实和进行必要比较的能力
包含超过 500 万份文档和 7,500 个查询项目
构建稠密向量索引需要约 50GB 的存储空间,稀疏向量索引占用 10.5GB
稠密向量索引以其快速的索引速度著称,但查询性能相对较慢。相反,稀疏向量索引虽然索引速度较慢,但查询速度更快
@inproceedings{yang2018hotpotqa,
title={{HotpotQA}: A Dataset for Diverse, Explainable Multi-hop Question Answering},
author={Yang, Zhilin and Qi, Peng and Zhang, Saizheng and Bengio, Yoshua and Cohen, William W. and Salakhutdinov, Ruslan and Manning, Christopher D.},
booktitle={Conference on Empirical Methods in Natural Language Processing ({EMNLP})},
year={2018}
}SqUAD
由斯坦福大学自然语言处理组发布的大规模机器阅读理解数据集
SqUAD 是一个常用的 RAG 系统或使用 LLMs 的生成式问答基准数据集
包含超过十万个真实问题,这些问题由众包工作者针对维基百科文章提出,目的是让机器阅读理解系统能够找到文档中的确切答案。SQuAD 旨在推动机器阅读理解和问答系统的研究,它要求系统不仅要理解问题,还要能够阅读并理解整个文档,从而找到问题的答案
使用精确匹配 (EM) 和 F1 分数的评估指标
CoQA
大规模的对话式问答数据集,旨在衡量机器在理解文本段落和回答一系列相互关联的问题方面的能力
由斯坦福大学的研究团队开发,包含来自7个不同领域的文本段落中的8000多个对话,共127,000多个问题和答案
特点是问题以对话形式出现,答案可以是自由形式的文本,并且每个答案都有相应的证据在段落中被突出显示
CoQA数据集中的问题往往需要对话历史和语用推理,这使得它比现有的阅读理解数据集更具挑战性
CoQA: A Conversational Question Answering Challenge (stanfordnlp.github.io)
https://arxiv.org/pdf/1808.07042v1.pdf
📒Elastic Learned Sparse Encoder(ELSER)
Elastic Learned Sparse Encoder(ELSER)是由 Elastic 训练和优化的一种文本扩展模型,用于在 Elasticsearch 中进行语义搜索。ELSER 通过稀疏向量表示技术,实现了基于文本意图和上下文含义的搜索,与传统的关键词匹配搜索相比,ELSER 能够更深入地理解用户的搜索需求,从而返回更加相关、准确的结果
ELSER 的工作原理包括文本预处理、语义分析、相似度计算和排序返回结果。它使用预训练的深度学习模型(如基于 Transformer 架构的 BERT 或 RoBERTa)对文本进行语义分析,捕获文本中的上下文信息和语义关系。然后,ELSER 计算输入文本与索引中文档的语义相似度,通常通过计算文本向量之间的余弦相似度来实现,并根据相似度得分对搜索结果进行排序
ELSER 的优势在于其稀疏向量表示,这使得它在领域外或零样本中表现良好,无需进行复杂的数据微调。此外,ELSER 作为跨领域模型,在没有应用特定领域重新训练的情况下,能够优于密集向量模型。它还具有高效性与可解释性,利用 Elasticsearch 和 Lucene 的倒排索引技术,实现了高效的向量相似度计算
在实际应用中,ELSER 可以广泛应用于企业内部搜索、电商平台商品搜索、问答系统等多种场景。例如,在企业内部搜索中,员工可以通过输入描述性文本来寻找特定课程或资料,ELSER 能够理解员工的意图并返回最相关的结果
要在 Elasticsearch 中使用 ELSER 进行语义搜索,需要部署 ELSER 模型、创建索引映射、配置推理管道,并使用 ELSER 作为推理模型的推理管道重新索引数据。ELSER v2 版本相比之前的版本提供了更高的检索精度和更高效的索引