
LongRAG 通过长上下文增强检索增强生成LLMs
在传统RAG框架中,检索单元通常较短,如DPR使用100字维基百科段落,导致检索器在大型语料库中搜索小单元,而阅读器从这些短单元生成答案,这种设计可能导致次优性能。短单元可能丢失上下文信息,增加检索阶段引入硬负样本的可能性,且阅读器可能无法充分利用LLMs的最新进展。为了解决这些问题,提出了LongRAG框架,包含长检索器和长阅读器。LongRAG处理整个维基百科为4K标记单元,比之前长30倍,显著减少单元总数,减轻检索器负担,提高检索性能。在NQ和HotpotQA数据集上,LongRAG使用少量顶级单元实现强大检索性能,减少检索到硬负样本的可能性,保持语义完整性。LongRAG将检索到的单元输入到长上下文LLM中进行零样本答案生成,无需训练即可在NQ和HotpotQA上达到与完全训练的SoTA模型相当的性能。此外,在非维基百科数据集Qasper和MultiFieldQA-en上,LongRAG将每个文档作为单个长单元处理,提高了F1分数。研究为RAG与长上下文LLMs结合提供了未来路线图的见解。
ℹ️
LongRAG: Enhancing Retrieval-Augmented Generation with Long-context LLMs
滑铁卢大学
项目网站:https://tiger-ai-lab.github.io/LongRAG/
原文:[2406.15319v3]
[v1] 2024 年 6 月 21 日 17:23:21 [v2] 2024 年 6 月 30 日 15:01:36 [v3] 2024 年 9 月 1 日 17:21:18
引言
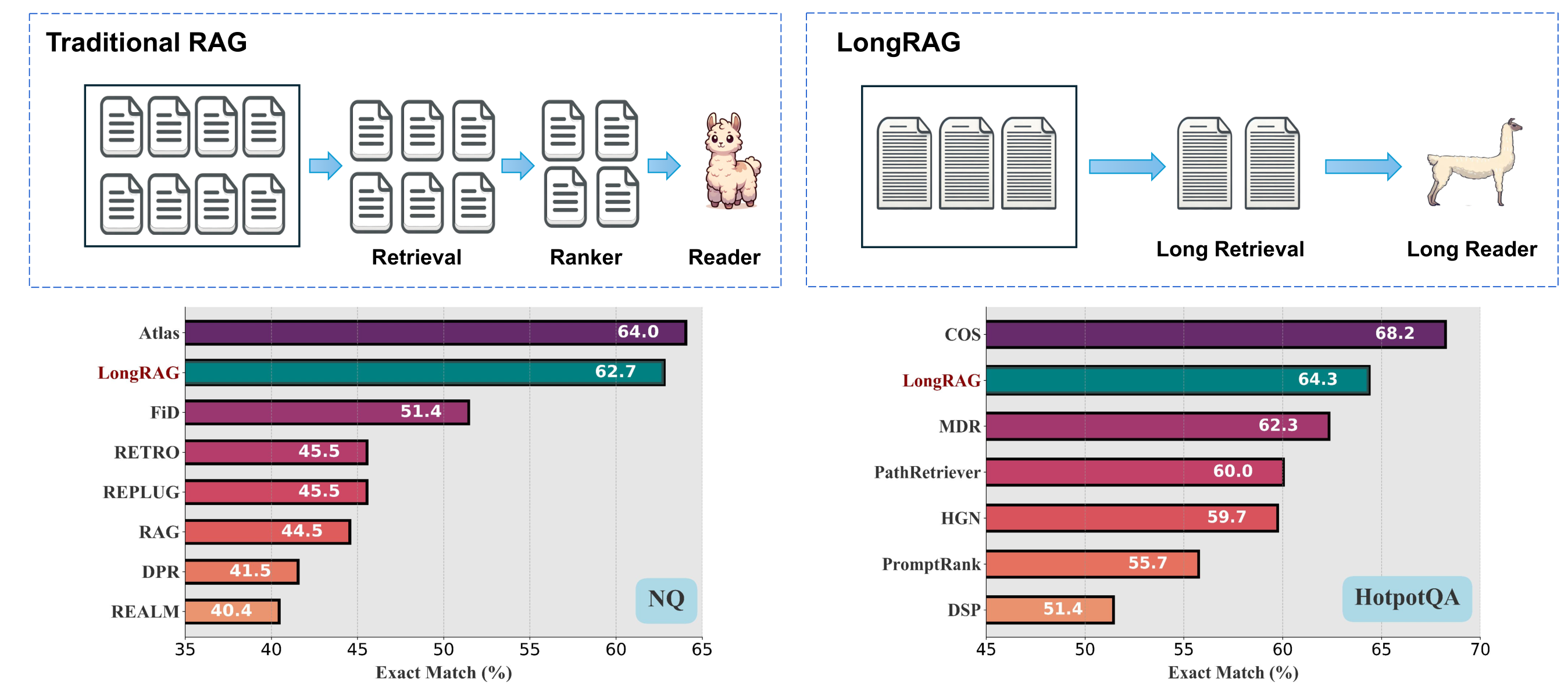
传统RAG框架通常使用短检索单元,如100词的段落,检索器需要在大型语料库中找到精确的小型检索单元,然后由阅读器生成最终回答
这种设计导致检索器负担过重,需要召回大量单元并可能结合重排序器以提高性能
短检索单元可能因文档截断导致语义不完整和上下文信息丢失
随着长上下文语言模型的发展,阅读器现在能够处理更长的输入
提出了LongRAG框架,旨在
- 长检索单元:通过使用整个文档或对多个相关文档进行分组,构建包含超过4K标记的长检索单元,显著减少语料库大小,简化检索器任务
- 长检索器:通过搜索语料库中的所有长检索单元来识别与给定查询相关的粗略信息,仅使用少数几个排名靠前的检索单元,无需重新排序,减少遇到硬负样本的可能性
- 📒硬负样本:
- 长篇阅读器:从检索结果的串联中进一步提取答案,该串联通常约为30K个词元,使用现有的长上下文语言模型(如 Gemini 或 GPT4)以零样本方式生成答案
在四个不同场景的数据集上进行了测试,包括基于维基百科的
通过将相关文档分组形成,显著减少了语料库的大小,并提高了答案召回率
在,答案召回率@1;在,召回率@2
利用,LongRAG在NQ上实现了62.7%的EM,在HotpotQA上实现了64.3%的EM,与最强完全训练的RAG模型相媲美
在非维基百科基础的数据集,LongRAG通过将整个文档作为单一单元处理,而不是切分为更小单元,提高了F1得分
LongRAG
LongRAG 处理长检索单元,通常只将少量(通常少于 10 个)输入到阅读器中
传统的 RAG 框架采用较小的检索单元,并优先检索包含答案的精细短文本
LongRAG 框架更强调召回,旨在检索出粗粒度的相关上下文
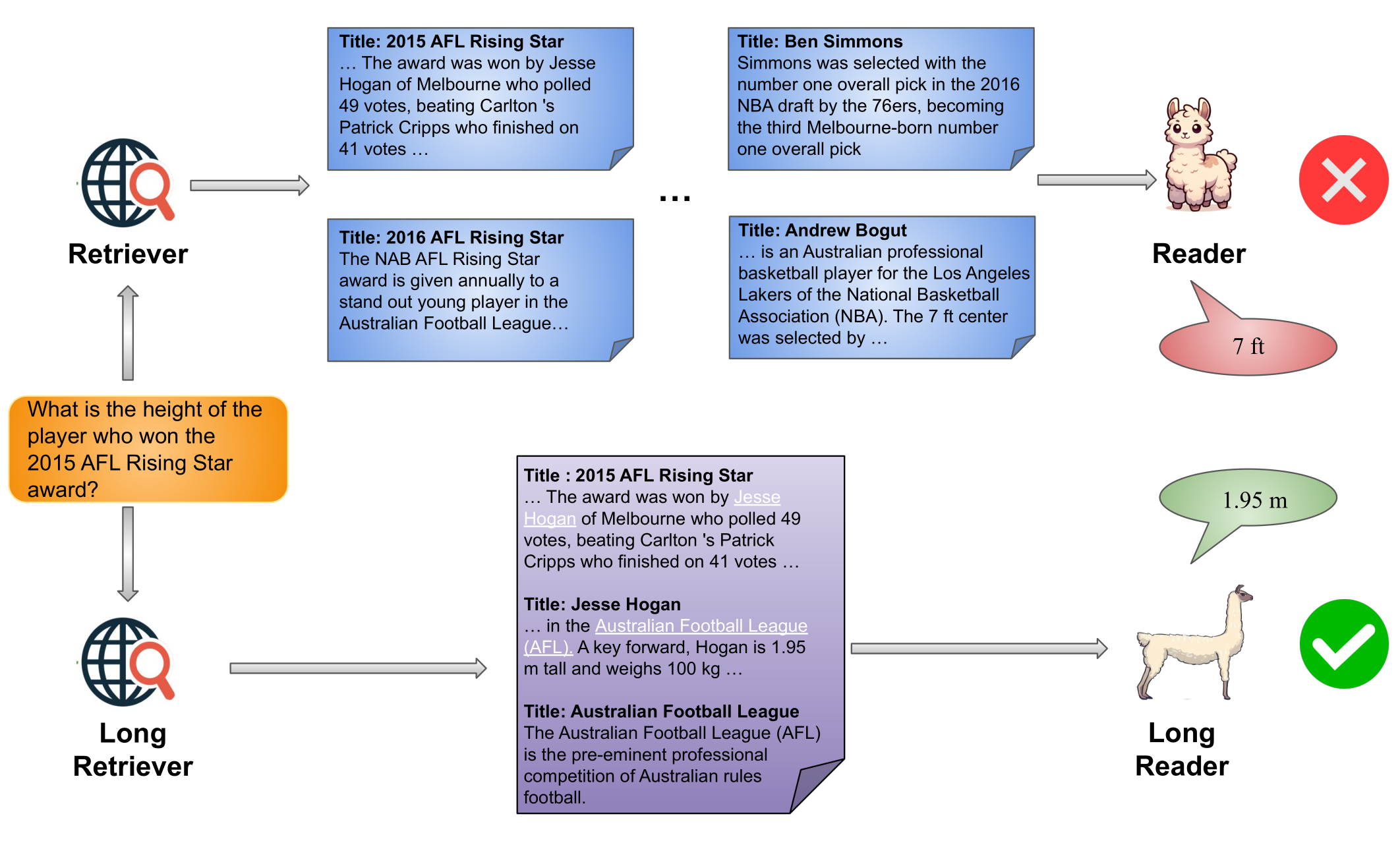
Long Retriever
将用于检索的语料库表示为 $\mathcal{C}={d_{1},d_{2},\ldots,d_{D}}$,它是一个包含 D 个文档的集合
形式上,长上下文检索器是一个函数 $\mathcal{F}:(q,\mathcal{C})\to\mathcal{C}{\mathcal{F}}$ ,它以问题 q 和语料库 C 作为输入,并返回一个过滤后的文本集 $C{\mathcal{F}}\subset\mathcal{C}$
在传统的 RAG 中,$C_{\mathcal{F}}$ 通常很小,包含大约数百个标记,其中应该包含与问题 q 相关的精确信息
在这个框架中,$C_{\mathcal{F}}$ 通常超过 4K 个标记,其中包含与问题 q 相关的相关信息,但不一定是精确信息
长检索器函数 $\mathcal{F}:(q,\mathcal{C})$ 然后分为三个步骤:
一个函数被应用于语料库以形成 M 个检索单元:$\mathcal{G}(\mathcal{C})={g_1,g_2,\ldots,g_{M}}$
在传统的 RAG 中,检索单元g 通常是从文档 d 中拆分出的一个短段落,包含数百个标记,LongRag中 g 可以
如果原始文档已经很长(例如,超过 4K 个标记),将整个文档视为一个单元。如果原始文档相对较短(例如,少于 1K 个标记),将相关文档组合在一起形成一个单元
使用,有两个主要优势:
只有,,相比传统 RAG 可能需要数百个短单元
通过在一个检索单元中保留整个文档或甚至相关文档,
利用一个编码器 $E_{Q}(\cdot)$ 将输入问题映射到一个 d 维向量
使用另一个编码器 $E_{C}(\cdot)$ 将检索单元映射到一个 d 维向量
使用它们向量的点积来定义问题和检索单元之间的相似性: $sim(q,g)=E_Q(q)^TE_C(g)$
在 LongRAG 设置中,由于 g 的长度,$E_{C}(g)$ 是具有挑战性的,因此采用近似方法 $sim(q,g)=E_Q(q)TE_C(g)\approx\max_{g{\prime}\subseteq g}(E_Q(q)TE_C(g{\prime}))$
最大化检索单元 $\text{g'}$ 内所有片段 g 的得分来进行近似,考虑不同的片段 $\text{g'}$ 的粒度水平,包括 512 个标记、4K 个标记以及完整编码整个 g
预先计算每个检索单元 $\text{g'}$ 的嵌入,并在 FAISS 中预测确切的内积搜索索引
🙂🙂🙂🙂🙂🙂🙂🙂🙂🙂🙂🙂🙂🙂🙂🙂🙂🙂🙂🙂🙂🙂🙂🙂❓🙂🙂🙂🙂🙂🙂🙂🙂🙂🙂🙂🙂🙂🙂🙂🙂🙂🙂🙂🙂🙂🙂
把前 k 个检索单元连接到长文本中作为检索结果,表示为 $\mathcal{C}_{\mathcal{F}} = \mathrm{Concat}(g{1},g,\ldots,g^{k})$
Long Reader
将相关的指令 $i$、问题 $q$ 和长检索结果 $\mathcal{C}_{\mathcal{F}}$ 输入到 LLM 中
选择 Gemini-1.5-Pro(Reid et al., 2024)和 GPT-4o(OpenAI, 2024),因为它们在处理长上下文输入方面的能力非常强
对于和采取了
对于通常包含少于1K个标记的,指示阅读器直接从检索到的语料库中提供的上下文生成答案
对于通常超过4K个标记的,经验发现使用与短上下文相似的提示,让模型直接从长上下文中提取最终答案,通常会导致性能下降
相反,最有效的方法是将LLM作为聊天模型使用,首先输出一个由几个词到几句话组成的,随后提示它从长答案中进一步提取,生成
实验
数据集

从维基百科选择了,从科学文献中选择了,以及从多领域文档中选择了。这两个基于维基百科的数据集利用了包含数百万短文档的大型检索语料,而另外两个数据集则采用了由数百个长文档组成的较小语料
自然问题(Kwiatkowski et al., 2019)旨在,问题源自真实的谷歌搜索查询,答案是在维基百科文章中由注释者识别的文本片段。该数据集包含。对于NQ,使用2018年12月20日的维基百科数据转储,其中包含大约
HotpotQA(杨等人,2018)包含>,专注于全维基设置,其中需要两个维基百科段落来回答问题。由于测试集的金标准段落不可用,遵循先前的工作(熊等人,2020b)并在开发集上进行评估,该开发集包含。HotpotQA中主要有两种问题类型:通常需要对比两个实体;可以通过遵循连接一个文档到另一个文档的连接实体来回答。对于HotpotQA,使用2017年10月1日转储的摘要段落,这些段落包含大约
Qasper(Dasigi et al., 2021)是一个问答数据集,每个问题都是,如果存在答案,则在论文的其余部分中识别。原始的Qasper数据集是一个单文档问答数据集,重构为一个RAG任务,其中系统首先检索必要的文档,然后回答给定的问题,设计与LoCoV1(Saad-Falcon et al., 2024)类似
MultifieldQA-en(白等,2023)是一个的问题回答数据集,包括法律文档、政府报告、百科全书和学术论文。原始的MultifieldQA-en是一个单文档QA数据集,重构为RAG任务,其中系统首先检索必要的文档,然后回答给定的问题,设计类似于LoCoV1(Saad-Falcon等,2024)
检索性能
指标
,仅使用,使用两种指标答案召回率是指在所有计划用于阅读器的检索文档中,答案字符串的召回率。例如,如果检索单元处于“段落”级别,并且数量为100,则答案召回率衡量答案字符串是否在这100个段落中存在。对于HotpotQA,仅针对具有跨度答案的问题计算AR,特别是“桥接”类型的问题,而忽略是/否和比较问题,遵循之前的工作(Khalifa 等人,2022)。用于HotpotQA的召回率衡量两个黄金文档是否出现在所有检索结果中。例如,如果检索单元处于“文档”级别,并且数量为10,则召回率衡量两个黄金文档是否在这10个检索结果中存在
实验设置中,利用开源的密集检索工具包Tevatron(Gao 等,2022)进行所有的检索实验。嵌入模型
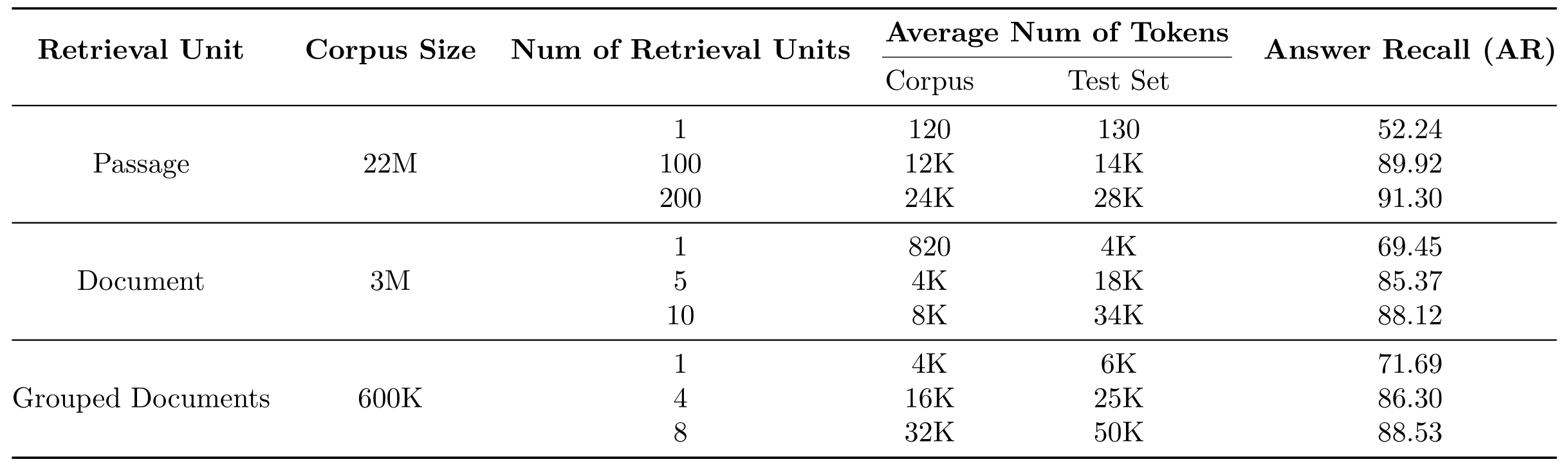
长上下文检索器(每个检索单元的平均标记数高达 6K)将语料库大小压缩了高达 30 倍(从 22M 压缩到 600K),并将 top-1 答案召回率提高了约 20 个百分点(从 52.24 提高到 71.69)
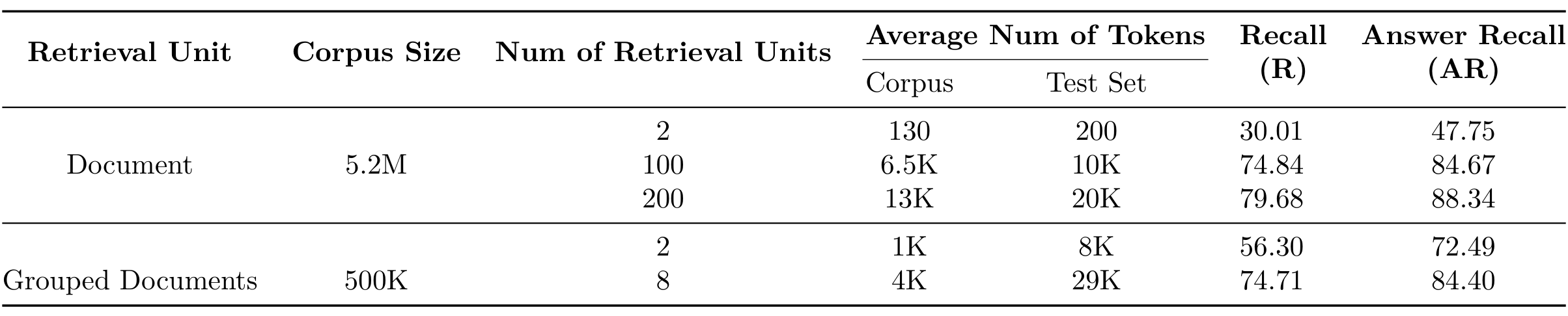

编码长检索单元时面临挑战,因为当检索单元g非常长时,使用编码器$E_{C}(\cdot)$ 将其映射到d维向量非常困难
因此,采用了近似方法来处理。实验表明,近似方法比直接编码整个长上下文更有效
比较了三种方法:
- 使用,选择g为512个token大小的文本
- 使用,选择g为整个文档,平均大小为4K个token
- 使用,不进行近似,直接编码整个由多个文档组成的g,g的平均大小为6K个token
实验结果显示,通过,比使用长嵌入模型直接编码整个长上下文产生更好的结果。预计未来在,专注于编码长上下文或多个文档,将进一步增强框架并减少内存消耗
消融研究
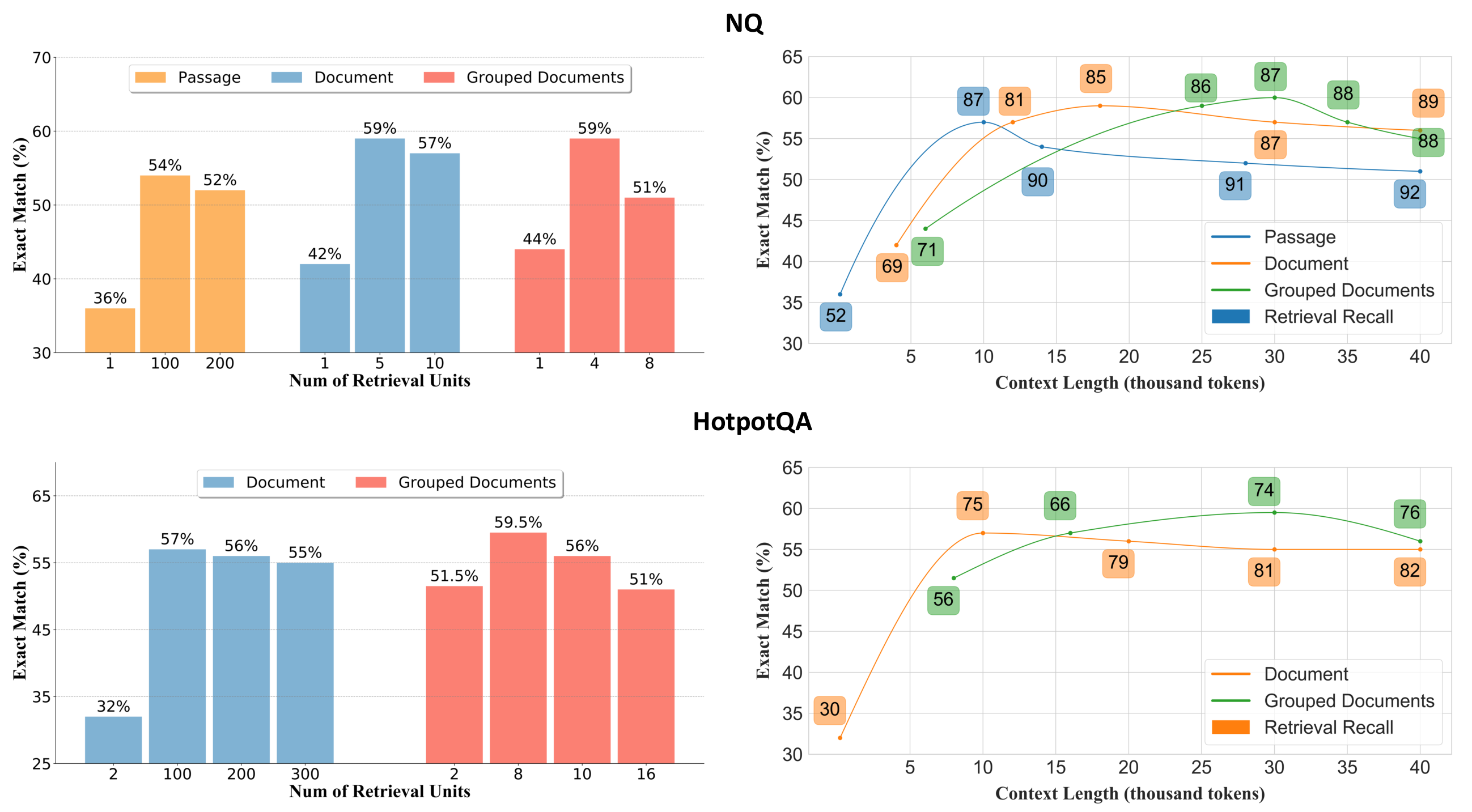
检索单元选择
比较了 LongRAG 的不同检索单元设置,特别关注了和。观察到两个主要结果:
无论选择哪种检索单元,都会存在一个,超过该点向阅读器提供更多的检索单元会变得有害。这是因为对阅读器施加了过大的负担,导致其无法有效理解和提取来自长上下文的信息。例如,在中,对于段落级检索单元,转折点出现在100到200之间;对于文档级检索单元,转折点在5到10之间;对于,转折点在4到8之间。总体而言,提供给阅读器的最合适的上下文长度约为
其次,与文档级或分组文档级检索单元相比,使用在表现上有所改善,显示出更好的性能
Recall vs. EM
在不同检索单元选择下,比较了在不同上下文长度之间的关系
观察到,当在读者中使用并采用时,可以减少在给定长度预算下引入的
因此,最终性能并不是随着召回评分单调增加的。随着长嵌入模型的进步和对长检索单元的检索召回的改善,未来可以期待更好的最终性能
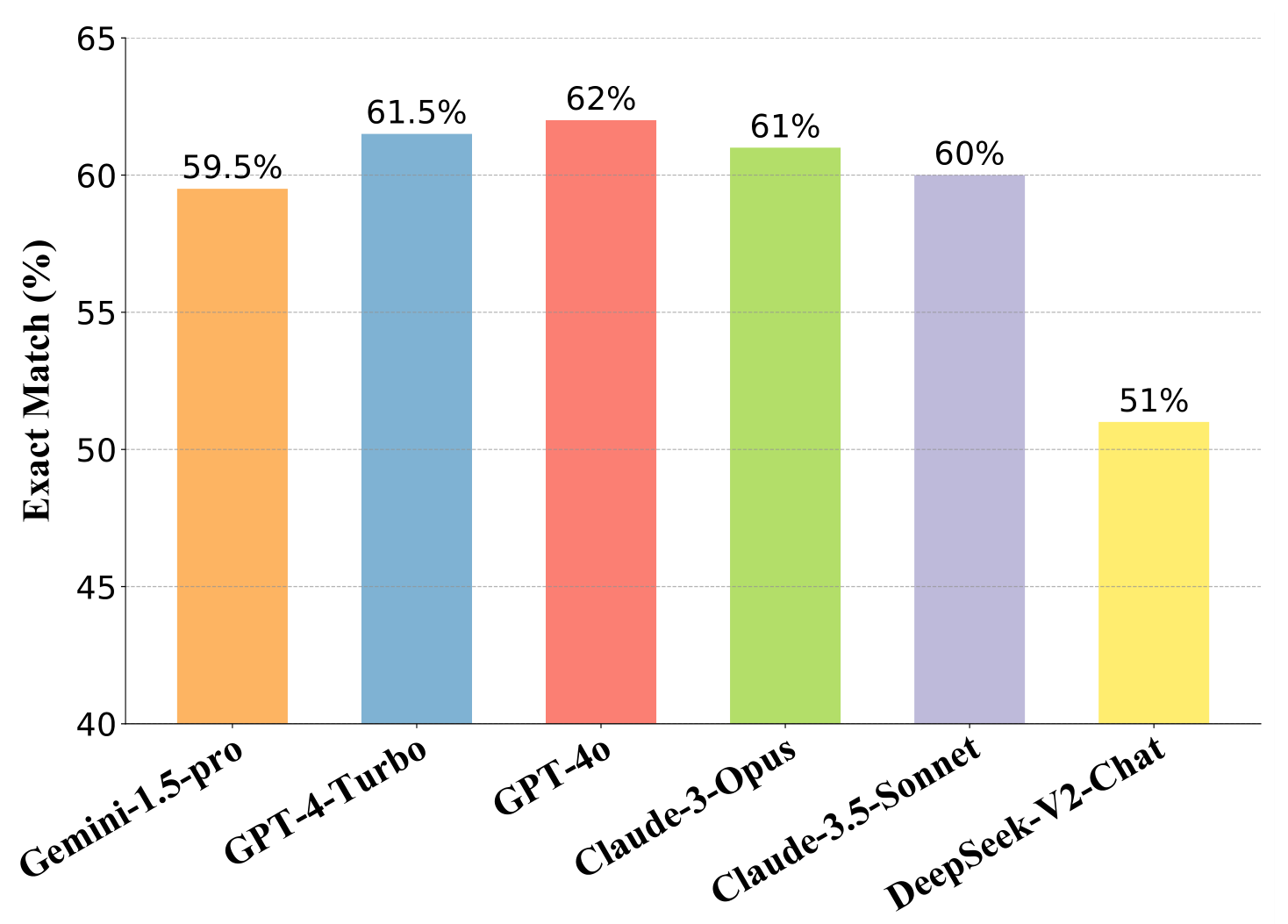
Reader Model
比较了六种不同读者的表现,包括和
在NQ数据集的200道测试题目中,,表明其在LongRAG框架中作为长读者的角色最为有效。GPT-4o的表现提升可以归因于其在,确保关键信息得到准确提取。因此,在主要表格中主要报告了GPT-4o的结果
和的结果非常相似,这些最先进的黑箱模型LLMs在LongRAG框架内也是有效的读者虽然是最佳的开源模型之一,但其性能与前五个黑箱模型相比显著下降。这表明,当前框架依赖于LLMs对长文本的理解能力,并且在将开源LLMs融入框架方面还有很大的提升空间